Best AI tools for< Classify Bugs >
20 - AI tool Sites
Trezy Classifier
Trezy Classifier is a powerful API designed for transaction enrichment, categorization, and company identification. It offers global coverage, 350+ categories, VAT estimation, and more. The API goes beyond simple categorization to provide enriched data for each transaction, making it easy to relate to ledger accounts. With features like supplier intelligence, VAT estimation, and simple integration, Trezy Classifier empowers users to gain real profitability insights from their transactions.
JobtitlesAI
JobtitlesAI is a machine-learning API that sorts job titles into two categories: field (sales, finance, I.T...) and position (executive, management, assistant...). It can be used in spreadsheets, Hubspot, or via API. JobtitlesAI is multilingual and GDPR compliant.
Charm
Charm is an AI-powered spreadsheet assistant that helps users clean messy data, create content, summarize feedback, classify sales leads, and generate dummy data. It is a Google Sheets add-on that automates tasks that are impossible to do with traditional formulas. Charm is used by hundreds of analysts, marketers, product managers, and more.
Pointly
Pointly is an intelligent, cloud-based B2B software solution that enables efficient automatic and advanced manual classification in 3D point clouds. It offers innovative AI techniques for fast and precise data classification and vectorization, transforming point cloud analysis into an enjoyable and efficient workflow. Pointly provides standard and custom classifiers, tools for classification and vectorization, API and on-premise classification options, collaboration features, secure cloud processing, and scalability for handling large-scale point cloud data.
Taylor
Taylor is a deterministic AI tool that empowers Business & Engineering teams to enhance data at scale through bulk classification. It offers a Control Panel for Text Enrichment, enabling users to structure freeform text, enrich metadata, and customize enrichments according to their needs. Taylor's high impact, easy-to-use platform allows for total control over classification and extraction models, driving business impact from day one. With powerful integrations and the ability to integrate with various tools, Taylor simplifies the process of wrangling unstructured text data.

FranzAI LLM Playground
FranzAI LLM Playground is an AI-powered tool that helps you extract, classify, and analyze unstructured text data. It leverages transformer models to provide accurate and meaningful results, enabling you to build data applications faster and more efficiently. With FranzAI, you can accelerate product and content classification, enhance data interpretation, and advance data extraction processes, unlocking key insights from your textual data.
Eigen Technologies
Eigen Technologies is an AI-powered data extraction platform designed for business users to automate the extraction of data from various documents. The platform offers solutions for intelligent document processing and automation, enabling users to streamline business processes, make informed decisions, and achieve significant efficiency gains. Eigen's platform is purpose-built to deliver real ROI by reducing manual processes, improving data accuracy, and accelerating decision-making across industries such as corporates, banks, financial services, insurance, law, and manufacturing. With features like generative insights, table extraction, pre-processing hub, and model governance, Eigen empowers users to automate data extraction workflows efficiently. The platform is known for its unmatched accuracy, speed, and capability, providing customers with a flexible and scalable solution that integrates seamlessly with existing systems.

Nightfall AI
Nightfall AI is an all-in-one data loss prevention platform that helps organizations prevent data leaks by putting data loss prevention on autopilot across SaaS & Gen AI apps, endpoints, and browsers. It offers features such as data exfiltration prevention, data detection & response, and data discovery & classification. Nightfall AI uses AI-powered LLM & behavioral models to deeply understand content sensitivity and data lineage, providing complete coverage across various applications and devices. The platform ensures frictionless deployment & maintenance with API-based integrations and lightweight agents, offering a streamlined user experience for quick understanding of exposure and user intent. Nightfall AI also involves and coaches end users to self-remediate, reducing the burden on SOC teams.
Varonis
Varonis is an AI-powered data security platform that provides end-to-end data security solutions for organizations. It offers automated outcomes to reduce risk, enforce policies, and stop active threats. Varonis helps in data discovery & classification, data security posture management, data-centric UEBA, data access governance, and data loss prevention. The platform is designed to protect critical data across multi-cloud, SaaS, hybrid, and AI environments.
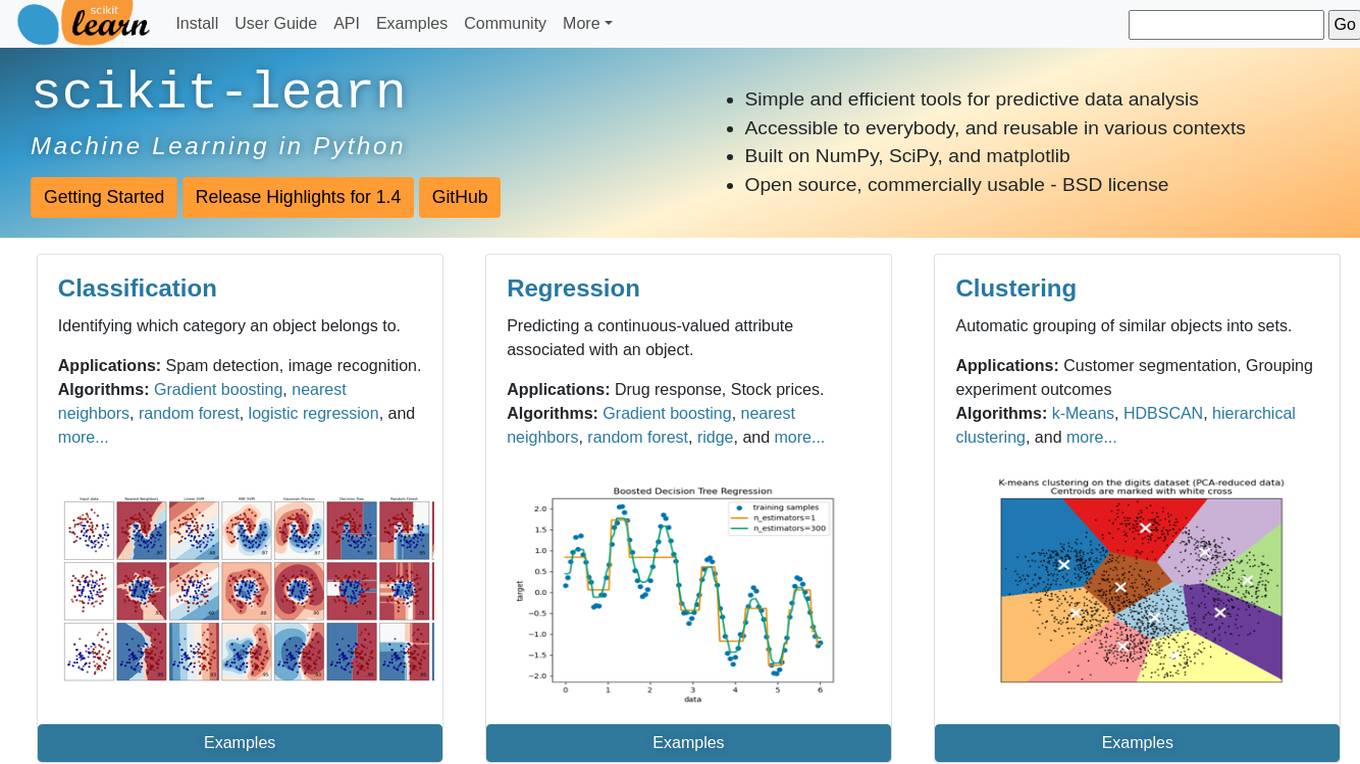
scikit-learn
Scikit-learn is a free software machine learning library for the Python programming language. It features various classification, regression and clustering algorithms including support vector machines, random forests, gradient boosting, k-means and DBSCAN, and is designed to interoperate with the Python numerical and scientific libraries NumPy and SciPy.
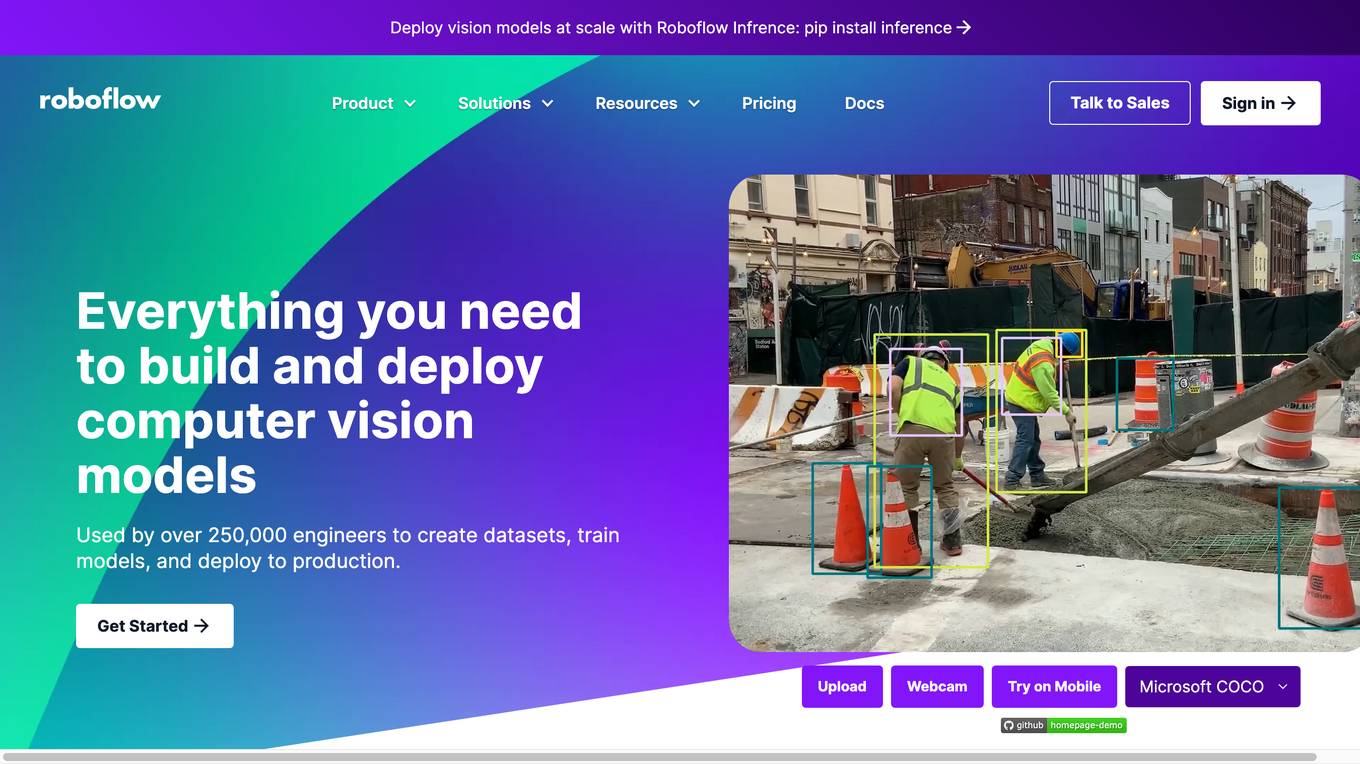
Roboflow
Roboflow is a platform that provides tools for building and deploying computer vision models. It offers a range of features, including data annotation, model training, and deployment. Roboflow is used by over 250,000 engineers to create datasets, train models, and deploy to production.
Cohere
Cohere is a leading provider of artificial intelligence (AI) tools and services. Our mission is to make AI accessible and useful to everyone, from individual developers to large enterprises. We offer a range of AI tools and services, including natural language processing, computer vision, and machine learning. Our tools are used by businesses of all sizes to improve customer service, automate tasks, and gain insights from data.
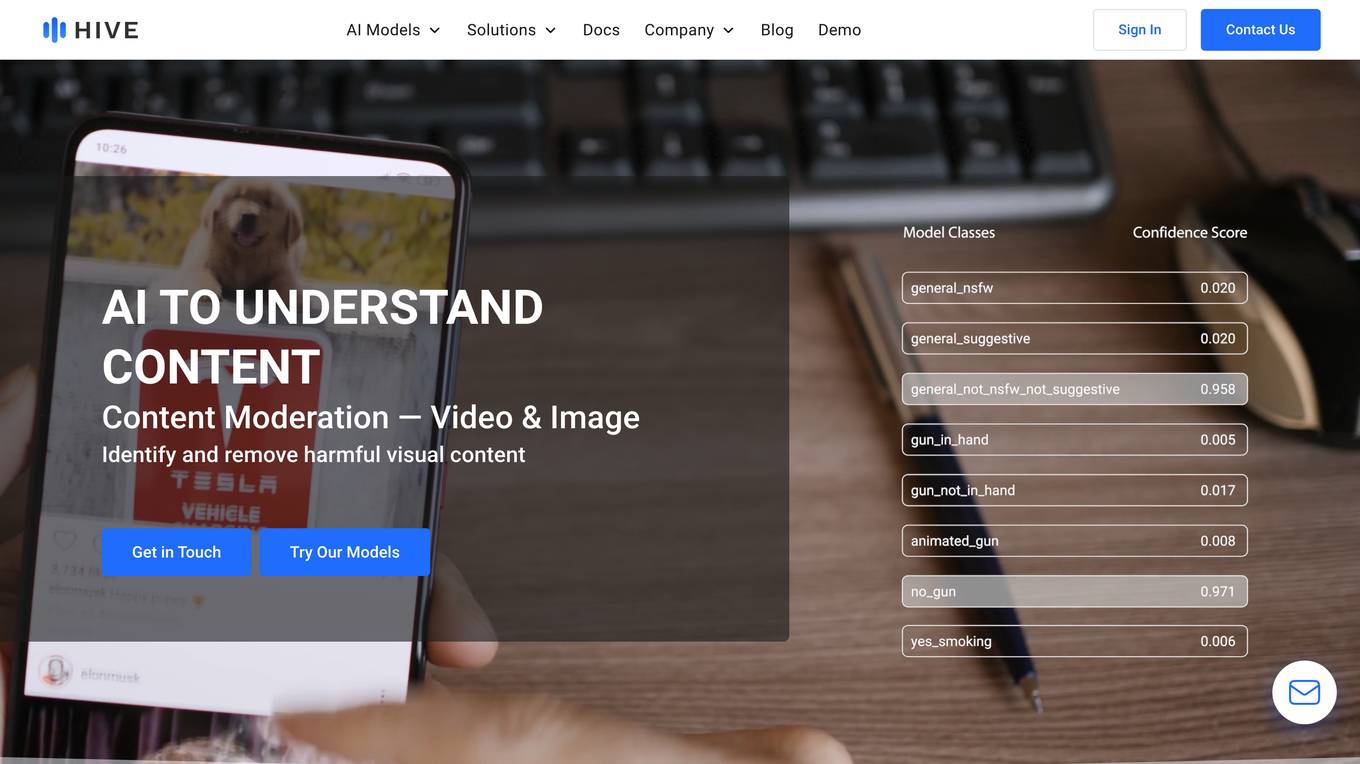
Hive AI
Hive AI provides a suite of AI models and solutions for understanding, searching, and generating content. Their AI models can be integrated into applications via APIs, enabling developers to add advanced content understanding capabilities to their products. Hive AI's solutions are used by businesses in various industries, including digital platforms, sports, media, and marketing, to streamline content moderation, automate image search and authentication, measure sponsorships, and monetize ad inventory.
Predibase
Predibase is a platform for fine-tuning and serving Large Language Models (LLMs). It provides a cost-effective and efficient way to train and deploy LLMs for a variety of tasks, including classification, information extraction, customer sentiment analysis, customer support, code generation, and named entity recognition. Predibase is built on proven open-source technology, including LoRAX, Ludwig, and Horovod.
Levity
Levity is an AI-powered email automation tool designed specifically for the freight industry. It connects to your inbox, categorizes incoming emails, extracts critical information, and pushes it to your TMS, allowing you to focus on building customer relationships instead of manual data entry and repetitive tasks.
Liner.ai
Liner is a free and easy-to-use tool that allows users to train machine learning models without writing any code. It provides a user-friendly interface that guides users through the process of importing data, selecting a model, and training the model. Liner also offers a variety of pre-trained models that can be used for common tasks such as image classification, text classification, and object detection. With Liner, users can quickly and easily create and deploy machine learning applications without the need for specialized knowledge or expertise.
Cogniflow
Cogniflow is a no-code AI platform that allows users to build and deploy custom AI models without any coding experience. The platform provides a variety of pre-built AI models that can be used for a variety of tasks, including customer service, HR, operations, and more. Cogniflow also offers a variety of integrations with other applications, making it easy to connect your AI models to your existing workflow.
Landing AI
Landing AI is a computer vision platform and AI software company that provides a cloud-based platform for building and deploying computer vision applications. The platform includes a library of pre-trained models, a set of tools for data labeling and model training, and a deployment service that allows users to deploy their models to the cloud or edge devices. Landing AI's platform is used by a variety of industries, including automotive, electronics, food and beverage, medical devices, life sciences, agriculture, manufacturing, infrastructure, and pharma.

Apply AI
This website provides a platform for users to apply artificial intelligence (AI) to their work. Users can access a variety of AI tools and resources, including pre-trained models, datasets, and tutorials. The website also provides a community forum where users can connect with other AI enthusiasts and experts.
Custom Vision
Custom Vision is a cognitive service provided by Microsoft that offers a user-friendly platform for creating custom computer vision models. Users can easily train the models by providing labeled images, allowing them to tailor the models to their specific needs. The service simplifies the process of implementing visual intelligence into applications, making it accessible even to those without extensive machine learning expertise.
1 - Open Source AI Tools
bugbug
Bugbug is a tool developed by Mozilla that leverages machine learning techniques to assist with bug and quality management, as well as other software engineering tasks like test selection and defect prediction. It provides various classifiers to suggest assignees, detect patches likely to be backed-out, classify bugs, assign product/components, distinguish between bugs and feature requests, detect bugs needing documentation, identify invalid issues, verify bugs needing QA, detect regressions, select relevant tests, track bugs, and more. Bugbug can be trained and tested using Python scripts, and it offers the ability to run model training tasks on Taskcluster. The project structure includes modules for data mining, bug/commit feature extraction, model implementations, NLP utilities, label handling, bug history playback, and GitHub issue retrieval.
20 - OpenAI Gpts
Dr. Classify
Just upload a numerical dataset for classification task, will apply data analysis and machine learning steps to make a best model possible.
Prompt Injection Detector
GPT used to classify prompts as valid inputs or injection attempts. Json output.

NACE Classifier
NACE (Nomenclature of Economic Activities) is the European statistical classification of economic activities. This is not an official product. Official information here: https://nacev2.com/en

TradeComply
Import Export Compliance | Tariff Classification | Shipping Queries | Logistics & Supply Chain Solutions
LiDAR GPT - LAStools Comprehensive Expert
Expert in LAStools with in-depth command line knowledge.
GICS Classifier
GICS is a classification standard developed by MSCI and S&P Dow Jones Indices. This GPT is not a MSCI and S&P product. Official website : https://www.msci.com/our-solutions/indexes/gics
UNSPSC Explorer
Expert in UNSPSC Codes (United Nations Standard Products and Services Code®).


DGL coding assistant
Assists with DGL coding, focusing on edge classification and link prediction.
Lexi - Article Classifier
Classifies articles into knowledge domains. source code: https://homun.posetmage.com/Agents/
Cloud Scholar
Super astronomer identifying clouds in English and Chinese, sharing facts in Chinese.

Not Hotdog
What would you say if I told you there is an app on the market that can tell you if you have a hot dog or not a hot dog.
MDR Navigator
Medical Device Expert on MDR 2017/745, IVDR 2017/746 and related MDCG guidance
Rock Identifier GPT
I identify various rocks from images and advise consulting a geologist for certainty.