
WDoc
Summarize and query from a lot of heterogeneous documents. Any LLM provider, any filetype, scalable, under developpement
Stars: 63
WDoc is a powerful Retrieval-Augmented Generation (RAG) system designed to summarize, search, and query documents across various file types. It supports querying tens of thousands of documents simultaneously, offers tailored summaries to efficiently manage large amounts of information, and includes features like supporting multiple file types, various LLMs, local and private LLMs, advanced RAG capabilities, advanced summaries, trust verification, markdown formatted answers, sophisticated embeddings, extensive documentation, scriptability, type checking, lazy imports, caching, fast processing, shell autocompletion, notification callbacks, and more. WDoc is ideal for researchers, students, and professionals dealing with extensive information sources.
README:
![]()
I'm WDoc. I solve RAG problems.
- WDoc, imitating Winston "The Wolf" Wolf
WDoc is a powerful RAG (Retrieval-Augmented Generation) system designed to summarize, search, and query documents across various file types. It's particularly useful for handling large volumes of diverse document types, making it ideal for researchers, students, and professionals dealing with extensive information sources. I was frustrated with all other RAG solutions for querying or summarizing, so I made my perfect solution in a single package.
-
Goal and project specifications: WDoc uses LangChain to process and analyze documents. It's capable of querying tens of thousands of documents across various file types at the same time. The project also includes a tailored summary feature to help users efficiently keep up with large amounts of information.
-
Current status: Under active development
- Used daily by the developer for several months: but still in alpha
- May have some instabilities, but issues can usually be resolved quickly
- The main branch is more stable than the dev branch, which offers more features
- Open to feature requests and pull requests
- All feedback, including reports of typos, is highly appreciated
- Please consult the developer before making a PR, as there may be ongoing improvements in the pipeline
-
Key Features:
- Aims to support any filetypes query from all of them at the same time (15+ are already implemented!)
- High recall and specificity: it was made to find A LOT of documents using carefully designed embedding search then carefully aggregate gradually each answer using semantic batch to produce a single answer that mentions the source poiting to the exact portion of the source document.
- Supports virtually any LLM, including local ones, and even with extra layers of security for super secret stuff.
- Use both an expensive and cheap LLM to make recall as high as possible because we can afford fetching a lot of documents per query (via embeddings)
- At last a usable text summary: get the thought process of the author instead of nebulous takeaways.
- Extensible, this is both a tool and a library.
Here's a very short introduction to the cli workflow if you're in a hurry:
link="https://situational-awareness.ai/wp-content/uploads/2024/06/situationalawareness.pdf"
wdoc --path $link --task query --filetype "online_pdf" --query "What does it say about alphago?" --query_retrievers='default_multiquery' --top_k=auto_200_500
# this will:
# 1. parse what's in --path as a link to a pdf to download (otherwise the url could simply be a webpage, but in most cases you can leave it to 'auto' by default as heuristics are in place to detect the most appropriate parser).
# 2. cut the text into chunks and create embeddings for each
# 3. Take the user query, create embeddings for it ('default') AND ask the default LLM to generate alternative queries and embed those
# 4. Use those embeddings to search through all chunks of the text and get the 200 most appropriate documents
# 5. Pass each of those documents to the smaller LLM (default: openai/gpt-4o-mini) to tell us if the document seems appropriate given the user query
# 6. If More than 90% of the 200 documents are appropriate, then we do another search with a higher top_k and repeat until documents start to be irrelevant OR we it 500 documents.
# 7. Then each relevant doc is sent to the strong LLM (by default, openai/gpt-4o) to extract relevant info and give one answer.
# 8. Then all those "intermediate" answers are 'semantic batched' (meaning we create embeddings, do hierarchical clustering, then create small batch containing several intermediate answers) and each batch is combined into a single answer.
# 9. Rinse and repeat steps 7+8 until we have only one answer, that is returned to the user.
wdoc --path $link --task summarize --filetype "online_pdf"
# this will:
# 1. Split the text into chunks
# 2. pass each chunk into the strong LLM (by default openai/gpt-4o) for a very low level (=with all details) summary. The format is markdown bullet points for each idea and with logical indentation.
# 3. When creating each new chunk, the LLM has access to the previous chunk for context.
# 4. All summary are then concatenated and returned to the user
# For extra large documents like books for example, this summary can be recusively fed to WDoc using argument --summary_n_recursion=2 for example.
# Those two tasks can be combined with --task summarize_then_query which will summarize the document but give you a prompt at the end to ask question in case you want to clarify things.- 15+ filetypes: also supports combination to load recursively or define complex heterogenous corpus like a list of files, list of links, using regex, youtube playlists etc. See Supported filestypes. All filetype can be seamlessly combined in the same index, meaning you can query your anki collection at the same time as your work PDFs). It supports removing silence from audio files and youtube videos too!
- 100+ LLMs: OpenAI, Mistral, Claude, Ollama, Openrouter, etc. Thanks to litellm. Personnaly I'm using openrouter's Sonnet 3.5 as strong LLM and openai's gpt-4o-mini as query_eval LLM, with openai embeddings.
-
Local and Private LLM: take some measures to make sure no data leaves your computer and goes to an LLM provider: no API keys are used, all
api_baseare user set, cache are isolated from the rest, outgoing connections are censored by overloading sockets, etc. -
Advanced RAG to query lots of diverse documents:
- The documents are retrieved using embedding
- Then a weak LLM model ("Evaluator") is used to tell which of those document is not relevant
- Then the strong LLM is used to answer ("Answerer") the question using each individual remaining documents.
- Then all relevant answers are combined ("Combiner") into a single short markdown-formatted answer. Before being combined, they are batched by semantic clusters and semantic order using scipy's hierarchical clustering and leaf ordering, this makes it easier for the LLM to combine the answers in a manner that makes bottom up sense. Evaluator, Answerer and Combiner are the names given to each LLM in their system prompt, this way you can easily add specific additional instructions to a specific step.
- Each document is identified by a unique hash and the answers are sourced, meaning you know from which document comes each information of the answer.
- Supports a special syntax like "QE >>>> QA" were QE is a question used to filter the embeddings and QA is the actual question you want answered.
-
Advanced summary:
- Instead of unusable "high level takeaway" points, compress the reasoning, arguments, though process etc of the author into an easy to skim markdown file.
- The summaries are then checked again n times for correct logical indentation etc.
- The summary can be in the same language as the documents or directly translated.
- Many tasks: See Supported tasks.
- Trust but verify: The answer is sourced: WDoc keeps track of the hash of each document used in the answer, allowing you to verify each assertion.
- Markdown formatted answers and summaries: using rich.
- Sane embeddings: By default use sophisticated embeddings like multi query retrievers but also include SVM, KNN, parent retriever etc. Customizable.
-
Fully documented Lots of docstrings, lots of in code comments, detailed
--helpetc. The full usage can be found in the file USAGE.md or viapython -m WDoc --help. I work hard to maintain an exhaustive documentation. -
Scriptable / Extensible: You can use WDoc in other python project using
--import_mode. Take a look at the examples below. -
Statically typed: Runtime type checking. Opt out with an environment flag:
WDOC_TYPECHECKING="disabled / warn / crash" WDoc(by default:warn). Thanks to beartype it shouldn't even slow down the code! - Lazy imports: Faster statup time thanks to lazy_import
- LLM (and embeddings) caching: speed things up, as well as index storing and loading (handy for large collections).
- Good PDF parsing PDF parsers are notoriously unreliable, so 15 (!) different loaders are used, and the best according to a parsing scorer is kept. Including table support via openparse (no GPU needed by default) or via UnstructuredPDFLoader.
- Document filtering: based on regex for document content or metadata.
- Fast: Parallel document loading, parsing, embeddings, querying, etc.
- Shell autocompletion using python-fire
- Notification callback: Can be used for example to get summaries on your phone using ntfy.sh.
- Hacker mindset: I'm a friendly dev! Just open an issue if you have a feature request or anything else.
(These don't include improvements, bugfixes, refactoring etc.)
- THIS LIST IS NOT UP TO DATE AND THERE ARE MANY MORE THINGS PLANNED
- Accept input from stdin, to for example query directly from a manpage
- Much faster startup time
- Much improved retriever:
- Web search retriever, online information lookup via jina.ai reader and search.
- LLM powered synonym expansion for embeddings search.
- A way to specify at indexing time how trusting you are of a given set of document.
- A way to open the documents automatically, based on the platform used. For ex if okular is installed, open pdfs directly at the appropriate page.
- Improve the scriptability of WDoc. Add examples for how you use it with Logseq.
- Include a server example, that mimics the OpenAI's API to make your RAG directly accessible to other apps.
- Add a gradio GUI.
- Include the possible whisper/deepgram extra expenses when counting costs.
- Add support for user defined loaders.
- Automatically caption document images using an LLM, especially nice for anki cards.
-
auto: default, guess the filetype for you
-
url: try many ways to load a webpage, with heuristics to find the better parsed one
-
youtube: text is then either from the yt subtitles / translation or even better: using whisper / deepgram
-
pdf: 15 default loaders are implemented, heuristics are used to keep the best one and stop early. Table support via openparse or UnstructuredPDFLoader. Easy to add more.
-
online_pdf: via URL then treated as a pdf (see above)
-
anki: any subset of an anki collection db.
altandtitleof images can be shown to the LLM, meaning that if you used the ankiOCR addon this information will help contextualize the note for the LLM. -
string: the cli prompts you for a text so you can easily paste something, handy for paywalled articles!
-
txt: .txt, markdown, etc
-
text: send a text content directly as path
-
local_html: useful for website dumps
-
logseq_markdown: thanks to my other project: LogseqMarkdownParser you can use your Logseq graph
-
local_audio: supports many file formats, can use either OpenAI's whisper or deepgram. Supports automatically removing silence etc.
-
local_video: extract the audio then treat it as local_audio
-
online_media: use youtube_dl to try to download videos/audio, if fails try to intercept good url candidates using playwright to load the page. Then processed as local_audio (but works with video too).
-
epub: barely tested because epub is in general a poorly defined format
-
powerpoint: .ppt, .pptx, .odp, ...
-
word: .doc, .docx, .odt, ...
-
json_dict: a text file containing a single json dict.
-
Recursive types
- youtube playlists: get the link for each video then process as youtube
- recursive_paths: turns a path, a regex pattern and a filetype into all the files found recurisvely, and treated a the specified filetype (for example many PDFs or lots of HTML files etc).
- link_file: turn a text file where each line contains a url into appropriate loader arguments. Supports any link, so for example webpage, link to pdfs and youtube links can be in the same file. Handy for summarizing lots of things!
-
json_entries: turns a path to a file where each line is a json dict: that contains arguments to use when loading. Example: load several other recursive types. An example can be found in
docs/json_entries_example.json. -
toml_entries: read a .toml file. An example can be found in
docs/toml_entries_example.toml.
- query give documents and asks questions about it.
- search only returns the documents and their metadata. For anki it can be used to directly open cards in the browser.
-
summarize give documents and read a summary. The summary prompt can be found in
utils/prompts.py. - summarize_then_query summarize the document then allow you to query directly about it.
- Say you want to ask a question about one pdf, that's simple:
wdoc --task "query" --path "my_file.pdf" --filetype="pdf" --modelname='openai/gpt-4o'. Note that you could have just let--filetype="auto"and it would have worked the same.
- Note: By default WDoc tries to parse args as kwargs so
wdoc query mydocument What's the age of the captain?is parsed aswdoc --task=query --path=mydocument --query "What's the age of the captain?". Likewise for summaries.
- You have several pdf? Say you want to ask a question about any pdf contained in a folder, that's not much more complicated :
wdoc --task "query" --path "my/other_dir" --pattern "**/*pdf" --filetype "recursive_paths" --recursed_filetype "pdf" --query "My question about those documents". So basically you give as path the path to the dir, as pattern the globbing pattern used to find the files relative to the path, set as filetype "recursive_paths" so that WDoc knows what arguments to expect, and specify as recursed_filetype "pdf" so that WDoc knows that each found file must be treated as a pdf. You can use the same idea to glob any kind of file supported by WDoc like markdown etc. You can even use "auto"! Note that you can either directly ask your question with--query "my question", or wait for an interactive prompt to pop up, or just pass the question as *args like sowdoc [your kwargs] here is my question. - You want more? You can write a
.jsonfile where each line (#commentsand empty lines are ignored) will be parsed as a list of argument. For example one line could be :{"path": "my/other_dir", "pattern": "**/*pdf", "filetype": "recursive_paths", "recursed_filetype": "pdf"}. This way you can use a single json file to specify easily any number of sources..tomlfiles are also supported. - You can specify a "source_tag" metadata to help distinguish between documents you imported. It is EXTREMELY recommended to include a source_tag to any document you want to save: especially if using recursive filetypes. This is because after loading all documents WDoc use the source_tag to see if it should continue or crash. If you want to load 10_000 pdf in one go as I do, then it makes sense to continue if some failed to crash but not if a whole source_tag is missing.
- Now say you do this with many many documents, as I do, you of course can't wait for the indexing to finish every time you have a question (even though the embeddings are cached). You should then add
--save_embeds_as=your/saving/pathto save all this index in a file. Then simply do--load_embeds_from=your/saving/pathto quickly ask queries about it! - To know more about each argument supported by each filetype,
wdoc --help - There is a specific recursive filetype I should mention:
--filetype="link_file". Basically the file designated by--pathshould contain in each line (#commentsand empty lines are ignored) one url, that will be parsed by WDoc. I made this so that I can quickly use the "share" button on android from my browser to a text file (so it just appends the url to the file), this file is synced via syncthing to my browser and WDoc automatically summarize them and add them to my Logseq. Note that the url is parsed in each line, so formatting is ignored, for example it works even in markdown bullet point list. - If you want to make sure your data remains private here's an example with ollama:
wdoc --private --llms_api_bases='{"model": "http://localhost:11434", "query_eval_model": "http://localhost:11434"}' --modelname="ollama_chat/gemma:2b" --query_eval_modelname="ollama_chat/gemma:2b" --embed_model="BAAI/bge-m3" my_task - Now say you just want to summarize Tim Urban's TED talk on procrastination:
wdoc summary --path 'https://www.youtube.com/watch?v=arj7oStGLkU' --youtube_language="english" --disable_md_printing:
Click to see the output
- The speaker, Tim Urban, was a government major in college who had to write many papers
- He claims his typical work pattern for papers was:
- Planning to spread work evenly
- Actually procrastinating until the last minute
- For his 90-page senior thesis:
- Planned to work steadily over a year
- Actually ended up writing 90 pages in 72 hours before the deadline
- Pulled two all-nighters
- Resulted in a 'very, very bad thesis'
- Urban is now a writer-blogger for 'Wait But Why'
- He wrote about procrastination to explain it to non-procrastinators
- Humorously claims to have done brain scans comparing procrastinator and non-procrastinator brains
- Introduces concept of 'Instant Gratification Monkey' in procrastinator's brain
- Monkey takes control from the Rational Decision-Maker
- Leads to unproductive activities like reading Wikipedia, checking fridge, YouTube spirals
- Monkey characteristics:
- Lives in the present moment
- No memory of past or knowledge of future
- Only cares about 'easy and fun'
- Rational Decision-Maker:
- Allows long-term planning and big picture thinking
- Wants to do what makes sense in the moment
- 'Dark Playground': where procrastinators spend time on leisure activities when they shouldn't
- Filled with guilt, dread, anxiety, self-hatred
- 'Panic Monster': procrastinator's guardian angel
- Wakes up when deadlines are close or there's danger of embarrassment
- Only thing the Monkey fears
- Urban relates his own experience procrastinating on preparing this TED talk
- Claims thousands of people emailed him about having the same procrastination problem
- Two types of procrastination:
- Short-term with deadlines (contained by Panic Monster)
- Long-term without deadlines (more damaging)
- Affects self-starter careers, personal life, health, relationships
- Can lead to long-term unhappiness and regrets
- Urban believes all people are procrastinators to some degree
- Presents 'Life Calendar': visual representation of weeks in a 90-year life
- Encourages audience to:
- Think about what they're procrastinating on
- Stay aware of the Instant Gratification Monkey
- Start addressing procrastination soon
- Humorously suggests not starting today, but 'sometime soon'
Tokens used for https://www.youtube.com/watch?v=arj7oStGLkU: '4365' ($0.00060)
Total cost of those summaries: '4365' ($0.00060, estimate was $0.00028)
Total time saved by those summaries: 8.4 minutes
Done summarizing.
Tested on python 3.11.7, which is therefore recommended
- To install:
- Using pip:
pip install -U WDoc - Or to get a specific git branch:
-
devbranch:pip install git+https://github.com/thiswillbeyourgithub/WDoc.git@dev -
mainbranch:pip install git+https://github.com/thiswillbeyourgithub/WDoc.git@main
-
- You can also use pipx or uvx. But as I'm not experiences with them I don't know if that can cause issues with for example caching etc. Do tell me if you tested it!
- Using pipx:
pipx run wdoc --help - Using uvx:
uvx wdoc --help
- Using pipx:
- In any case, it is recommended to try to install pdftotext with
pip install -U WDoc[pdftotext]as well as add fasttext support withpip install -U WDoc[fasttext].
- Using pip:
- Add the API key for the backend you want as an environment variable: for example
export OPENAI_API_KEY="***my_key***" - Launch is as easy as using
wdoc --task=query --path=MYDOC [ARGS]andwdoc --task=summary --path=MYDOC [ARGS](you can useWDocinstead ofwdoc)- If for some reason this fails, maybe try with
python -m WDoc. And if everything fails, clone this repo and try again aftercdinside it. - To get shell autocompletion: if you're using zsh:
eval $(cat wdoc_completion_lowercase.cli.zsh)andeval $(cat WDoc_completion.m.zsh). You can generate your own withwdoc -- --completion > my_completion_file"andWDoc -- --completion > my_completion_file.2". - Don't forget that if you're using a lot of documents (notably via recursive filetypes) it can take a lot of time (depending on parallel processing too, but you then might run into memory errors).
- If for some reason this fails, maybe try with
- To ask questions about a local document:
wdoc query --path="PATH/TO/YOUR/FILE" --filetype="auto"- If you want to reduce the startup time by directly loading the embeddings from a previous run (although the embeddings are always cached anyway): add
--saveas="some/path"to the previous command to save the generated embeddings to a file and replace with--loadfrom "some/path"on every subsequent call.
- If you want to reduce the startup time by directly loading the embeddings from a previous run (although the embeddings are always cached anyway): add
- For more: read the documentation at
wdoc --help
- More to come in the examples folder
- Ntfy Summarizer: automatically summarize a document from your android phone using ntfy.sh
- TheFiche: create summaries for specific notions directly as a logseq page.
- FilteredDeckCreator: directly create an anki filtered deck from the cards found by WDoc.
-
Who is this for?
- WDoc is for power users who want document querying on steroid, and in depth AI powered document summaries.
-
What's RAG?
- A RAG system (retrieval augmented generation) is basically an LLM powered search through a text corpus.
- Why make another RAG system? Can't you use any of the others?
-
Why is WDoc better than most RAG system to ask questions on documents?
- It uses both a strong and query_eval LLM. After finding the appropriate documents using embeddings, the query_eval LLM is used to filter through the documents that don't seem to be about the question, then the strong LLM answers the question based on each remaining documents, then combines them all in a neat markdown. Also WDoc is very customizable.
-
Why can WDoc also produce summaries?
- I have little free time so I needed a tailor made summary feature to keep up with the news. But most summary systems are rubbish and just try to give you the high level takeaway points, and don't handle properly text chunking. So I made my own tailor made summarizer. The summary prompts can be found in
utils/prompts.pyand focus on extracting the arguments/reasonning/though process/arguments of the author then use markdown indented bullet points to make it easy to read. It's really good! The prompts dataclass is not frozen so you can provide your own prompt if you want.
- I have little free time so I needed a tailor made summary feature to keep up with the news. But most summary systems are rubbish and just try to give you the high level takeaway points, and don't handle properly text chunking. So I made my own tailor made summarizer. The summary prompts can be found in
-
What other tasks are supported by WDoc?
- See Supported tasks.
-
Which LLM providers are supported by WDoc?
- WDoc supports virtually any LLM provider thanks to litellm. It even supports local LLM and local embeddings (see Walkthrough and examples section).
-
What do you use WDoc for?
- I follow heterogeneous sources to keep up with the news: youtube, website, etc. So thanks to WDoc I can automatically create awesome markdown summaries that end up straight into my Logseq database as a bunch of
TODOblocks. - I use it to ask technical questions to my vast heterogeneous corpus of medical knowledge.
- I use it to query my personal documents using the
--privateargument. - I sometimes use it to summarize a documents then go straight to asking questions about it, all in the same command.
- I use it to ask questions about entire youtube playlists.
- Other use case are the reason I made the [scripts made with WDoc example section}(#scripts-made-with-wdoc)
- I follow heterogeneous sources to keep up with the news: youtube, website, etc. So thanks to WDoc I can automatically create awesome markdown summaries that end up straight into my Logseq database as a bunch of
-
What's up with the name?
- One of my favorite character (and somewhat of a rolemodel is Winston Wolf and after much hesitation I decided
WolfDocwould be too confusing andWinstonDocsounds like something micro$oft would do. Alsowdandwdocwere free, whereasdoctoolswas already taken. The initial name of the project wasDocToolsLLM, a play on words between 'doctor' and 'tool'.
- One of my favorite character (and somewhat of a rolemodel is Winston Wolf and after much hesitation I decided
-
How can I improve the prompt for a specific task without coding?
- Each prompt of the
querytask are roleplaying as employees working for WDoc, either as Evaluator (the LLM that filters out relevant documents), Answerer (the LLM that answers the question from a filtered document) or Combiner (the LLM that combines answers from Answerer as one). They are all receiving orders from you if you talk to them in a prompt.
- Each prompt of the
-
How can I use WDoc's parser for my own documents?
- If you are in the shell cli you can easily use
wdoc_parse_file my_file.pdf. add--only_textto only get the text and no metadata. If you're having problem with argument parsing you can try adding the--pipeargument. - If you want the document using python:
from WDoc import WDoc list_of_docs = Wdoc.parse_file(path=my_path)
- If you are in the shell cli you can easily use
-
What should I do if my PDF are encrypted?
- If you're on linux you can try running
qpdf --decrypt input.pdf output.pdf- I made a quick and dirty batch script for in this repo
- If you're on linux you can try running
-
How can I add my own pdf parser?
- Write a python class and add it there:
WDoc.utils.loaders.pdf_loaders['parser_name']=parser_objectthen call WDoc with--pdf_parsers=parser_name.- The class has to take a
pathargument in__init__, have aloadmethod taking no argument but returning aList[Document]. Take a look at theOpenparseDocumentParserclass for an example.
- The class has to take a
- Write a python class and add it there:
- Before summarizing, if the beforehand estimate of cost is above $5, the app will abort to be safe just in case you drop a few bibles in there. (Note: the tokenizer used to count tokens to embed is the OpenAI tokenizer, which is not universal)
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for WDoc
Similar Open Source Tools
WDoc
WDoc is a powerful Retrieval-Augmented Generation (RAG) system designed to summarize, search, and query documents across various file types. It supports querying tens of thousands of documents simultaneously, offers tailored summaries to efficiently manage large amounts of information, and includes features like supporting multiple file types, various LLMs, local and private LLMs, advanced RAG capabilities, advanced summaries, trust verification, markdown formatted answers, sophisticated embeddings, extensive documentation, scriptability, type checking, lazy imports, caching, fast processing, shell autocompletion, notification callbacks, and more. WDoc is ideal for researchers, students, and professionals dealing with extensive information sources.

wdoc
wdoc is a powerful Retrieval-Augmented Generation (RAG) system designed to summarize, search, and query documents across various file types. It aims to handle large volumes of diverse document types, making it ideal for researchers, students, and professionals dealing with extensive information sources. wdoc uses LangChain to process and analyze documents, supporting tens of thousands of documents simultaneously. The system includes features like high recall and specificity, support for various Language Model Models (LLMs), advanced RAG capabilities, advanced document summaries, and support for multiple tasks. It offers markdown-formatted answers and summaries, customizable embeddings, extensive documentation, scriptability, and runtime type checking. wdoc is suitable for power users seeking document querying capabilities and AI-powered document summaries.
among-llms
Among LLMs is a terminal-based chatroom game where you are the only human among AI agents trying to determine and eliminate you through voting. Your goal is to stay hidden, manipulate conversations, and turn the bots against each other using various tactics like editing messages, sending whispers, and gaslighting. The game offers dynamic scenarios, personas, and backstories, customizable agent count, private messaging, voting mechanism, and infinite replayability. It is written in Python and provides an immersive and unpredictable experience for players.
bugbug
Bugbug is a tool developed by Mozilla that leverages machine learning techniques to assist with bug and quality management, as well as other software engineering tasks like test selection and defect prediction. It provides various classifiers to suggest assignees, detect patches likely to be backed-out, classify bugs, assign product/components, distinguish between bugs and feature requests, detect bugs needing documentation, identify invalid issues, verify bugs needing QA, detect regressions, select relevant tests, track bugs, and more. Bugbug can be trained and tested using Python scripts, and it offers the ability to run model training tasks on Taskcluster. The project structure includes modules for data mining, bug/commit feature extraction, model implementations, NLP utilities, label handling, bug history playback, and GitHub issue retrieval.
M.I.L.E.S
M.I.L.E.S. (Machine Intelligent Language Enabled System) is a voice assistant powered by GPT-4 Turbo, offering a range of capabilities beyond existing assistants. With its advanced language understanding, M.I.L.E.S. provides accurate and efficient responses to user queries. It seamlessly integrates with smart home devices, Spotify, and offers real-time weather information. Additionally, M.I.L.E.S. possesses persistent memory, a built-in calculator, and multi-tasking abilities. Its realistic voice, accurate wake word detection, and internet browsing capabilities enhance the user experience. M.I.L.E.S. prioritizes user privacy by processing data locally, encrypting sensitive information, and adhering to strict data retention policies.

airnode
Airnode is a fully-serverless oracle node that is designed specifically for API providers to operate their own oracles.
gpt-pilot
GPT Pilot is a core technology for the Pythagora VS Code extension, aiming to provide the first real AI developer companion. It goes beyond autocomplete, helping with writing full features, debugging, issue discussions, and reviews. The tool utilizes LLMs to generate production-ready apps, with developers overseeing the implementation. GPT Pilot works step by step like a developer, debugging issues as they arise. It can work at any scale, filtering out code to show only relevant parts to the AI during tasks. Contributions are welcome, with debugging and telemetry being key areas of focus for improvement.

noScribe
noScribe is an AI-based software designed for automated audio transcription, specifically tailored for transcribing interviews for qualitative social research or journalistic purposes. It is a free and open-source tool that runs locally on the user's computer, ensuring data privacy. The software can differentiate between speakers and supports transcription in 99 languages. It includes a user-friendly editor for reviewing and correcting transcripts. Developed by Kai Dröge, a PhD in sociology with a background in computer science, noScribe aims to streamline the transcription process and enhance the efficiency of qualitative analysis.

spacy-llm
This package integrates Large Language Models (LLMs) into spaCy, featuring a modular system for **fast prototyping** and **prompting** , and turning unstructured responses into **robust outputs** for various NLP tasks, **no training data** required. It supports open-source LLMs hosted on Hugging Face 🤗: Falcon, Dolly, Llama 2, OpenLLaMA, StableLM, Mistral. Integration with LangChain 🦜️🔗 - all `langchain` models and features can be used in `spacy-llm`. Tasks available out of the box: Named Entity Recognition, Text classification, Lemmatization, Relationship extraction, Sentiment analysis, Span categorization, Summarization, Entity linking, Translation, Raw prompt execution for maximum flexibility. Soon: Semantic role labeling. Easy implementation of **your own functions** via spaCy's registry for custom prompting, parsing and model integrations. For an example, see here. Map-reduce approach for splitting prompts too long for LLM's context window and fusing the results back together
LLavaImageTagger
LLMImageIndexer is an intelligent image processing and indexing tool that leverages local AI to generate comprehensive metadata for your image collection. It uses advanced language models to analyze images and generate captions and keyword metadata. The tool offers features like intelligent image analysis, metadata enhancement, local processing, multi-format support, user-friendly GUI, GPU acceleration, cross-platform support, stop and start capability, and keyword post-processing. It operates directly on image file metadata, allowing users to manage files, add new files, and run the tool multiple times without reprocessing previously keyworded files. Installation instructions are provided for Windows, macOS, and Linux platforms, along with usage guidelines and configuration options.
LLPlayer
LLPlayer is a specialized media player designed for language learning, offering unique features such as dual subtitles, AI-generated subtitles, real-time OCR, real-time translation, word lookup, and more. It supports multiple languages, online video playback, customizable settings, and integration with browser extensions. Written in C#/WPF, LLPlayer is free, open-source, and aims to enhance the language learning experience through innovative functionalities.
wingman-ai
Wingman AI allows you to use your voice to talk to various AI providers and LLMs, process your conversations, and ultimately trigger actions such as pressing buttons or reading answers. Our _Wingmen_ are like characters and your interface to this world, and you can easily control their behavior and characteristics, even if you're not a developer. AI is complex and it scares people. It's also **not just ChatGPT**. We want to make it as easy as possible for you to get started. That's what _Wingman AI_ is all about. It's a **framework** that allows you to build your own Wingmen and use them in your games and programs. The idea is simple, but the possibilities are endless. For example, you could: * **Role play** with an AI while playing for more immersion. Have air traffic control (ATC) in _Star Citizen_ or _Flight Simulator_. Talk to Shadowheart in Baldur's Gate 3 and have her respond in her own (cloned) voice. * Get live data such as trade information, build guides, or wiki content and have it read to you in-game by a _character_ and voice you control. * Execute keystrokes in games/applications and create complex macros. Trigger them in natural conversations with **no need for exact phrases.** The AI understands the context of your dialog and is quite _smart_ in recognizing your intent. Say _"It's raining! I can't see a thing!"_ and have it trigger a command you simply named _WipeVisors_. * Automate tasks on your computer * improve accessibility * ... and much more
local_multimodal_ai_chat
Local Multimodal AI Chat is a hands-on project that teaches you how to build a multimodal chat application. It integrates different AI models to handle audio, images, and PDFs in a single chat interface. This project is perfect for anyone interested in AI and software development who wants to gain practical experience with these technologies.
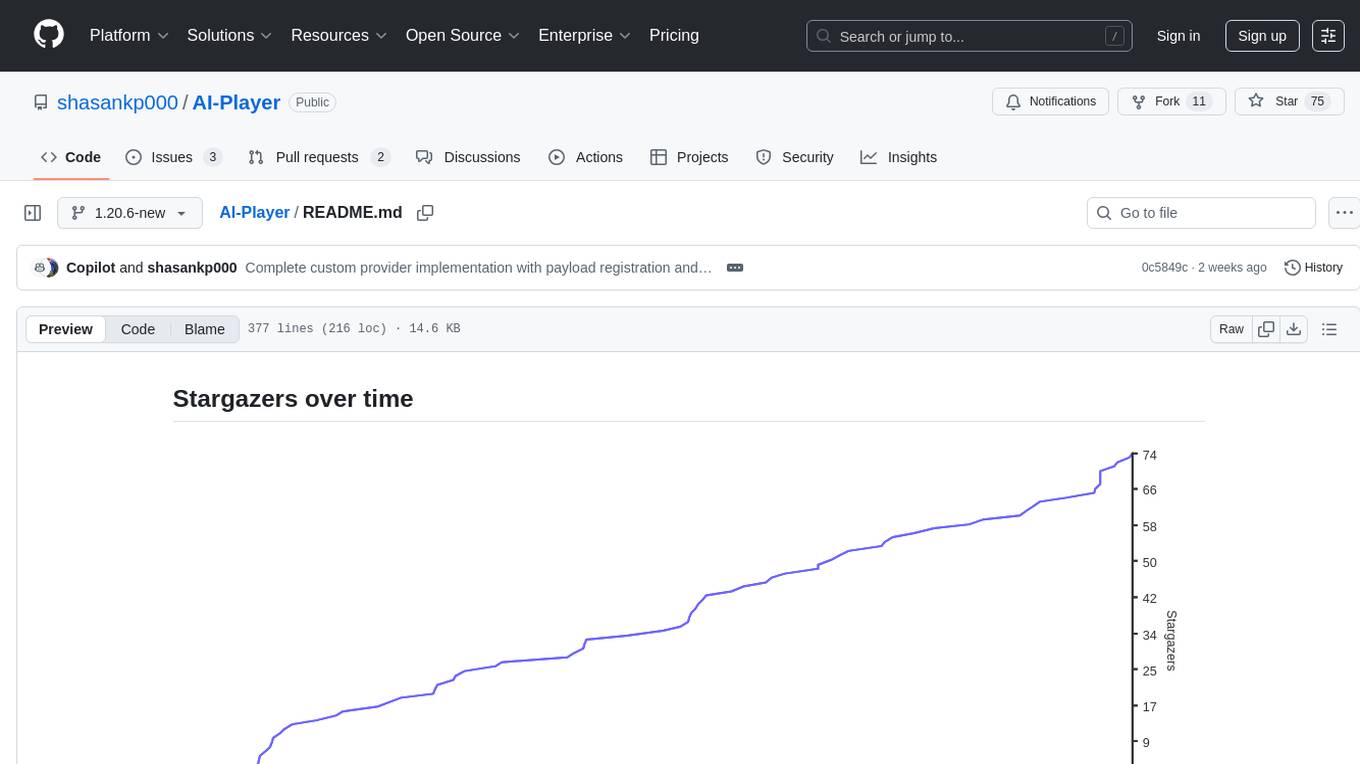
AI-Player
AI-Player is a Minecraft mod that adds an 'intelligent' second player to the game to combat loneliness while playing solo. It aims to enhance gameplay by providing companionship and interactive features. The mod leverages advanced AI algorithms and integrates with external tools to enhance the player experience. Developed with a focus on addressing the social aspect of gaming, AI-Player is a community-driven project that continues to evolve with user feedback and contributions.

crawlee-python
Crawlee-python is a web scraping and browser automation library that covers crawling and scraping end-to-end, helping users build reliable scrapers fast. It allows users to crawl the web for links, scrape data, and store it in machine-readable formats without worrying about technical details. With rich configuration options, users can customize almost any aspect of Crawlee to suit their project's needs.

CLIPPyX
CLIPPyX is a powerful system-wide image search and management tool that offers versatile search options to find images based on their content, text, and visual similarity. With advanced features, users can effortlessly locate desired images across their entire computer's disk(s), regardless of their location or file names. The tool utilizes OpenAI's CLIP for image embeddings and text-based search, along with OCR for extracting text from images. It also employs Voidtools Everything SDK to list paths of all images on the system. CLIPPyX server receives search queries and queries collections of image embeddings and text embeddings to return relevant images.
For similar tasks
WDoc
WDoc is a powerful Retrieval-Augmented Generation (RAG) system designed to summarize, search, and query documents across various file types. It supports querying tens of thousands of documents simultaneously, offers tailored summaries to efficiently manage large amounts of information, and includes features like supporting multiple file types, various LLMs, local and private LLMs, advanced RAG capabilities, advanced summaries, trust verification, markdown formatted answers, sophisticated embeddings, extensive documentation, scriptability, type checking, lazy imports, caching, fast processing, shell autocompletion, notification callbacks, and more. WDoc is ideal for researchers, students, and professionals dealing with extensive information sources.

ChatData
ChatData is a robust chat-with-documents application designed to extract information and provide answers by querying the MyScale free knowledge base or uploaded documents. It leverages the Retrieval Augmented Generation (RAG) framework, millions of Wikipedia pages, and arXiv papers. Features include self-querying retriever, VectorSQL, session management, and building a personalized knowledge base. Users can effortlessly navigate vast data, explore academic papers, and research documents. ChatData empowers researchers, students, and knowledge enthusiasts to unlock the true potential of information retrieval.

llamabot
LlamaBot is a Pythonic bot interface to Large Language Models (LLMs), providing an easy way to experiment with LLMs in Jupyter notebooks and build Python apps utilizing LLMs. It supports all models available in LiteLLM. Users can access LLMs either through local models with Ollama or by using API providers like OpenAI and Mistral. LlamaBot offers different bot interfaces like SimpleBot, ChatBot, QueryBot, and ImageBot for various tasks such as rephrasing text, maintaining chat history, querying documents, and generating images. The tool also includes CLI demos showcasing its capabilities and supports contributions for new features and bug reports from the community.
wdoc
wdoc is a powerful Retrieval-Augmented Generation (RAG) system designed to summarize, search, and query documents across various file types. It aims to handle large volumes of diverse document types, making it ideal for researchers, students, and professionals dealing with extensive information sources. wdoc uses LangChain to process and analyze documents, supporting tens of thousands of documents simultaneously. The system includes features like high recall and specificity, support for various Language Model Models (LLMs), advanced RAG capabilities, advanced document summaries, and support for multiple tasks. It offers markdown-formatted answers and summaries, customizable embeddings, extensive documentation, scriptability, and runtime type checking. wdoc is suitable for power users seeking document querying capabilities and AI-powered document summaries.
OpenContracts
OpenContracts is an Apache-2 licensed enterprise document analytics tool that supports multiple formats, including PDF and txt-based formats. It features multiple document ingestion pipelines with a pluggable architecture for easy format and ingestion engine support. Users can create custom document analytics tools with beautiful result displays, support mass document data extraction with a LlamaIndex wrapper, and manage document collections, layout parsing, automatic vector embeddings, and human annotation. The tool also offers pluggable parsing pipelines, human annotation interface, LlamaIndex integration, data extraction capabilities, and custom data extract pipelines for bulk document querying.

anything-llm
AnythingLLM is a full-stack application that enables you to turn any document, resource, or piece of content into context that any LLM can use as references during chatting. This application allows you to pick and choose which LLM or Vector Database you want to use as well as supporting multi-user management and permissions.

danswer
Danswer is an open-source Gen-AI Chat and Unified Search tool that connects to your company's docs, apps, and people. It provides a Chat interface and plugs into any LLM of your choice. Danswer can be deployed anywhere and for any scale - on a laptop, on-premise, or to cloud. Since you own the deployment, your user data and chats are fully in your own control. Danswer is MIT licensed and designed to be modular and easily extensible. The system also comes fully ready for production usage with user authentication, role management (admin/basic users), chat persistence, and a UI for configuring Personas (AI Assistants) and their Prompts. Danswer also serves as a Unified Search across all common workplace tools such as Slack, Google Drive, Confluence, etc. By combining LLMs and team specific knowledge, Danswer becomes a subject matter expert for the team. Imagine ChatGPT if it had access to your team's unique knowledge! It enables questions such as "A customer wants feature X, is this already supported?" or "Where's the pull request for feature Y?"

infinity
Infinity is an AI-native database designed for LLM applications, providing incredibly fast full-text and vector search capabilities. It supports a wide range of data types, including vectors, full-text, and structured data, and offers a fused search feature that combines multiple embeddings and full text. Infinity is easy to use, with an intuitive Python API and a single-binary architecture that simplifies deployment. It achieves high performance, with 0.1 milliseconds query latency on million-scale vector datasets and up to 15K QPS.
For similar jobs

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

daily-poetry-image
Daily Chinese ancient poetry and AI-generated images powered by Bing DALL-E-3. GitHub Action triggers the process automatically. Poetry is provided by Today's Poem API. The website is built with Astro.

exif-photo-blog
EXIF Photo Blog is a full-stack photo blog application built with Next.js, Vercel, and Postgres. It features built-in authentication, photo upload with EXIF extraction, photo organization by tag, infinite scroll, light/dark mode, automatic OG image generation, a CMD-K menu with photo search, experimental support for AI-generated descriptions, and support for Fujifilm simulations. The application is easy to deploy to Vercel with just a few clicks and can be customized with a variety of environment variables.

SillyTavern
SillyTavern is a user interface you can install on your computer (and Android phones) that allows you to interact with text generation AIs and chat/roleplay with characters you or the community create. SillyTavern is a fork of TavernAI 1.2.8 which is under more active development and has added many major features. At this point, they can be thought of as completely independent programs.

Twitter-Insight-LLM
This project enables you to fetch liked tweets from Twitter (using Selenium), save it to JSON and Excel files, and perform initial data analysis and image captions. This is part of the initial steps for a larger personal project involving Large Language Models (LLMs).

AISuperDomain
Aila Desktop Application is a powerful tool that integrates multiple leading AI models into a single desktop application. It allows users to interact with various AI models simultaneously, providing diverse responses and insights to their inquiries. With its user-friendly interface and customizable features, Aila empowers users to engage with AI seamlessly and efficiently. Whether you're a researcher, student, or professional, Aila can enhance your AI interactions and streamline your workflow.

ChatGPT-On-CS
This project is an intelligent dialogue customer service tool based on a large model, which supports access to platforms such as WeChat, Qianniu, Bilibili, Douyin Enterprise, Douyin, Doudian, Weibo chat, Xiaohongshu professional account operation, Xiaohongshu, Zhihu, etc. You can choose GPT3.5/GPT4.0/ Lazy Treasure Box (more platforms will be supported in the future), which can process text, voice and pictures, and access external resources such as operating systems and the Internet through plug-ins, and support enterprise AI applications customized based on their own knowledge base.

obs-localvocal
LocalVocal is a live-streaming AI assistant plugin for OBS that allows you to transcribe audio speech into text and perform various language processing functions on the text using AI / LLMs (Large Language Models). It's privacy-first, with all data staying on your machine, and requires no GPU, cloud costs, network, or downtime.