
sandbox
A cloud-based code editing environment with an AI copilot and real-time collaboration.
Stars: 1102
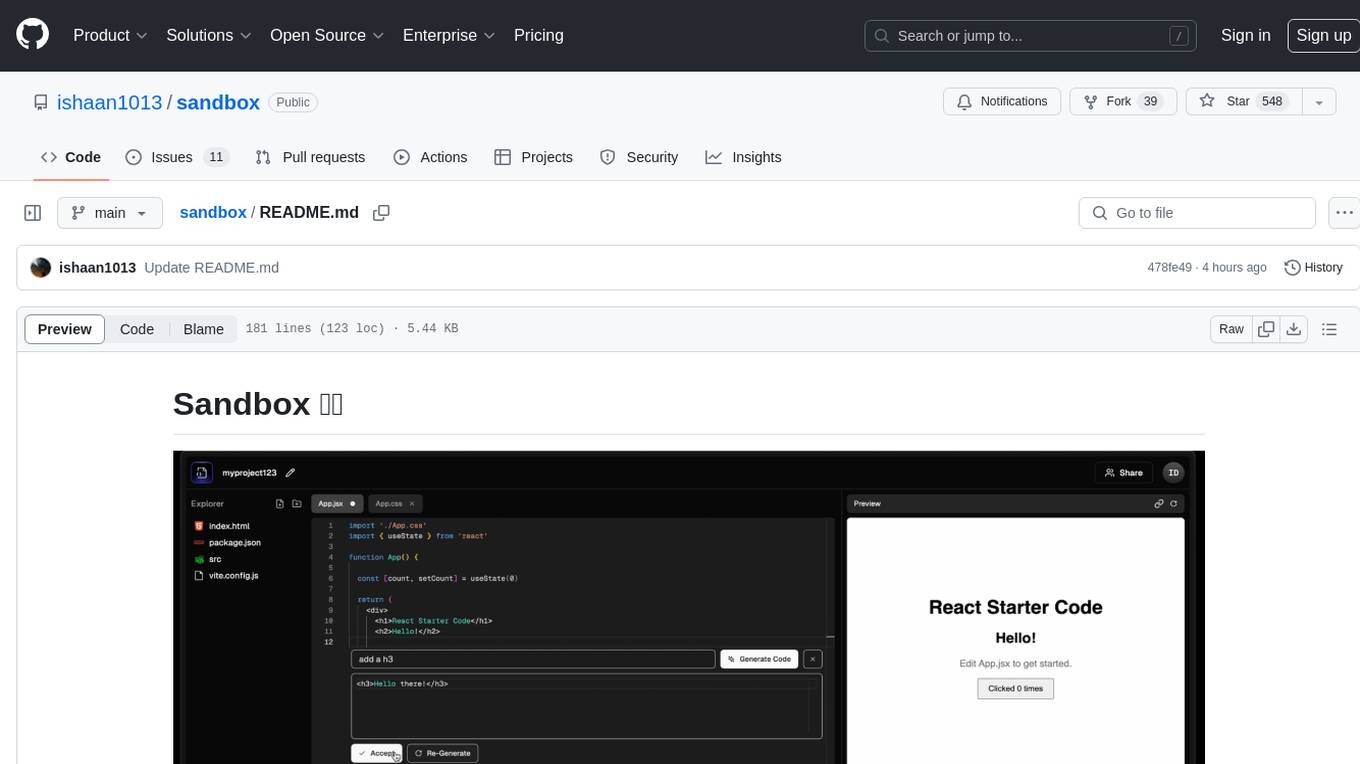
Sandbox is an open-source cloud-based code editing environment with custom AI code autocompletion and real-time collaboration. It consists of a frontend built with Next.js, TailwindCSS, Shadcn UI, Clerk, Monaco, and Liveblocks, and a backend with Express, Socket.io, Cloudflare Workers, D1 database, R2 storage, Workers AI, and Drizzle ORM. The backend includes microservices for database, storage, and AI functionalities. Users can run the project locally by setting up environment variables and deploying the containers. Contributions are welcome following the commit convention and structure provided in the repository.
README:
Sandbox is an open-source cloud-based code editing environment with custom AI code autocompletion and real-time collaboration.
Check out the Twitter thread with the demo video!
Check out this guide made by @jamesmurdza on setting it up locally!
Install dependencies
cd frontend
npm installAdd the required environment variables in .env (example file provided in .env.example). You will need to make an account on Clerk and Liveblocks to get API keys.
Then, run in development mode
npm run devThe backend consists of a primary Express and Socket.io server, and 3 Cloudflare Workers microservices for the D1 database, R2 storage, and Workers AI. The D1 database also contains a service binding to the R2 storage worker.
Install dependencies
cd backend/server
npm installAdd the required environment variables in .env (example file provided in .env.example)
Project files will be stored in the projects/<project-id> directory. The middleware contains basic authorization logic for connecting to the server.
Run in development mode
npm run devThis directory is dockerized, so feel free to deploy a container on any platform of your choice! I chose not to deploy this project for public access due to costs & safety, but deploying your own for personal use should be no problem.
Directories:
-
/backend/database: D1 database -
/backend/storage: R2 storage -
/backend/ai: Workers AI
Install dependencies
cd backend/database
npm install
cd ../storage
npm install
cd ../ai
npm installRead the documentation to learn more about workers.
For each directory, add the required environment variables in wrangler.toml (example file provided in wrangler.example.toml). For the AI worker, you can define any value you want for the CF_AI_KEY -- set this in other .env files to authorize access.
Run in development mode
npm run devDeploy to Cloudflare with Wrangler
npx wrangler deployThanks for your interest in contributing! Review this section before submitting your first pull request. If you need any help, feel free to reach out to @ishaandey_.
Please prioritize existing issues, but feel free to contribute new issues if you have ideas for a feature or bug that you think would be useful.
frontend/
├── app
├── assets
├── components
└── lib
backend/
├── server
├── database/
│ ├── src
│ └── drizzle
├── storage
└── ai
| Path | Description |
|---|---|
frontend |
The Next.js application for the frontend. |
backend/server |
The Express websocket server. |
backend/database |
API for interfacing with the D1 database (SQLite). |
backend/storage |
API for interfacing with R2 storage. Service-bound to /backend/database. |
backend/ai |
API for making requests to Workers AI . |
You can fork this repo by clicking the fork button in the top right corner of this page.
git clone https://github.com/<your-username>/sandbox.git
cd sandboxgit checkout -b my-new-branchBefore you create a Pull Request, please check that you use the Conventional Commits format
It should be in the form category(scope or module): message in your commit message from the following categories:
-
feat / feature: all changes that introduce completely new code or new features -
fix: changes that fix a bug (ideally you will additionally reference an issue if present) -
refactor: any code related change that is not a fix nor a feature -
docs: changing existing or creating new documentation (i.e. README, docs for usage of a lib or cli usage) -
chore: all changes to the repository that do not fit into any of the above categoriese.g.
feat(editor): improve tab switching speed
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for sandbox
Similar Open Source Tools
sandbox
Sandbox is an open-source cloud-based code editing environment with custom AI code autocompletion and real-time collaboration. It consists of a frontend built with Next.js, TailwindCSS, Shadcn UI, Clerk, Monaco, and Liveblocks, and a backend with Express, Socket.io, Cloudflare Workers, D1 database, R2 storage, Workers AI, and Drizzle ORM. The backend includes microservices for database, storage, and AI functionalities. Users can run the project locally by setting up environment variables and deploying the containers. Contributions are welcome following the commit convention and structure provided in the repository.
frontend
Nuclia frontend apps and libraries repository contains various frontend applications and libraries for the Nuclia platform. It includes components such as Dashboard, Widget, SDK, Sistema (design system), NucliaDB admin, CI/CD Deployment, and Maintenance page. The repository provides detailed instructions on installation, dependencies, and usage of these components for both Nuclia employees and external developers. It also covers deployment processes for different components and tools like ArgoCD for monitoring deployments and logs. The repository aims to facilitate the development, testing, and deployment of frontend applications within the Nuclia ecosystem.
desktop
ComfyUI Desktop is a packaged desktop application that allows users to easily use ComfyUI with bundled features like ComfyUI source code, ComfyUI-Manager, and uv. It automatically installs necessary Python dependencies and updates with stable releases. The app comes with Electron, Chromium binaries, and node modules. Users can store ComfyUI files in a specified location and manage model paths. The tool requires Python 3.12+ and Visual Studio with Desktop C++ workload for Windows. It uses nvm to manage node versions and yarn as the package manager. Users can install ComfyUI and dependencies using comfy-cli, download uv, and build/launch the code. Troubleshooting steps include rebuilding modules and installing missing libraries. The tool supports debugging in VSCode and provides utility scripts for cleanup. Crash reports can be sent to help debug issues, but no personal data is included.
qrev
QRev is an open-source alternative to Salesforce, offering AI agents to scale sales organizations infinitely. It aims to provide digital workers for various sales roles or a superagent named Qai. The tech stack includes TypeScript for frontend, NodeJS for backend, MongoDB for app server database, ChromaDB for vector database, SQLite for AI server SQL relational database, and Langchain for LLM tooling. The tool allows users to run client app, app server, and AI server components. It requires Node.js and MongoDB to be installed, and provides detailed setup instructions in the README file.

backend.ai-webui
Backend.AI Web UI is a user-friendly web and app interface designed to make AI accessible for end-users, DevOps, and SysAdmins. It provides features for session management, inference service management, pipeline management, storage management, node management, statistics, configurations, license checking, plugins, help & manuals, kernel management, user management, keypair management, manager settings, proxy mode support, service information, and integration with the Backend.AI Web Server. The tool supports various devices, offers a built-in websocket proxy feature, and allows for versatile usage across different platforms. Users can easily manage resources, run environment-supported apps, access a web-based terminal, use Visual Studio Code editor, manage experiments, set up autoscaling, manage pipelines, handle storage, monitor nodes, view statistics, configure settings, and more.

gitingest
GitIngest is a tool that allows users to turn any Git repository into a prompt-friendly text ingest for LLMs. It provides easy code context by generating a text digest from a git repository URL or directory. The tool offers smart formatting for optimized output format for LLM prompts and provides statistics about file and directory structure, size of the extract, and token count. GitIngest can be used as a CLI tool on Linux and as a Python package for code integration. The tool is built using Tailwind CSS for frontend, FastAPI for backend framework, tiktoken for token estimation, and apianalytics.dev for simple analytics. Users can self-host GitIngest by building the Docker image and running the container. Contributions to the project are welcome, and the tool aims to be beginner-friendly for first-time contributors with a simple Python and HTML codebase.
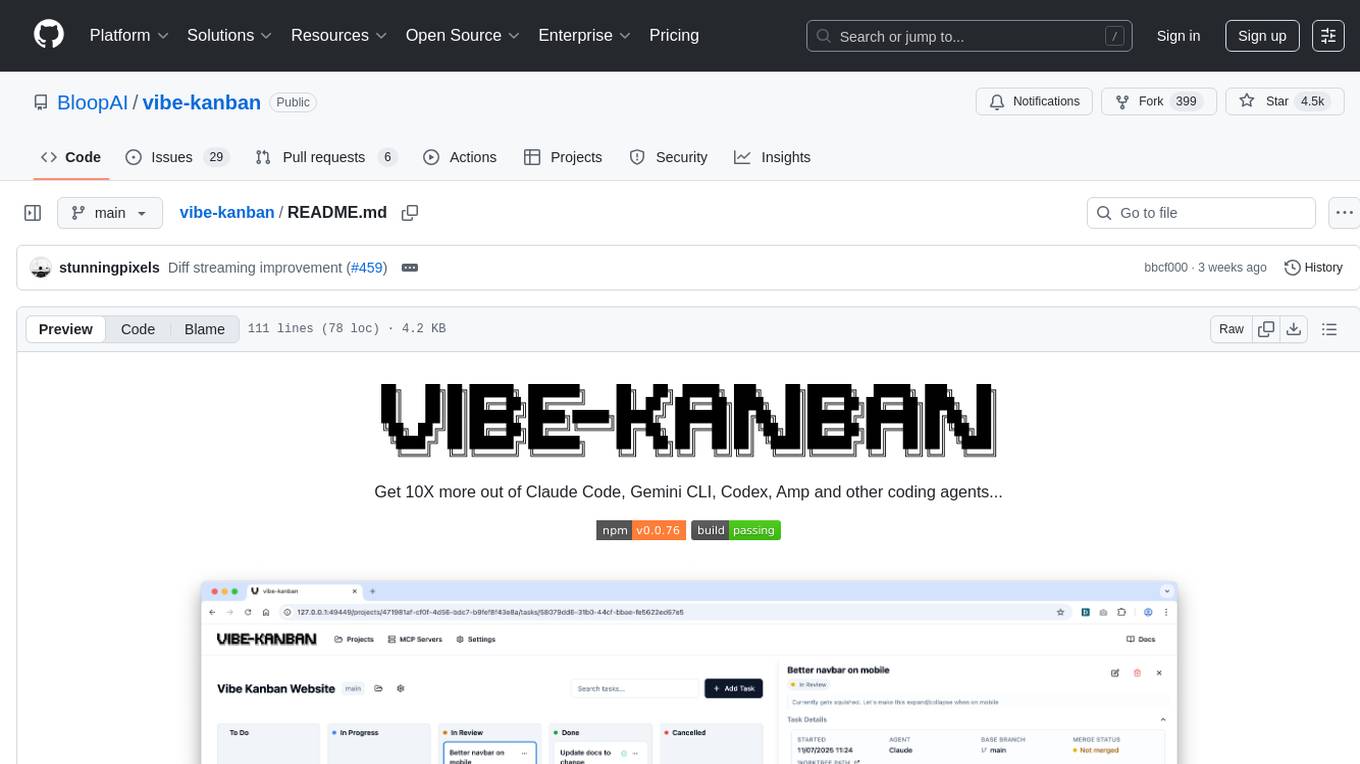
vibe-kanban
Vibe Kanban is a tool designed to streamline the process of planning, reviewing, and orchestrating tasks for human engineers working with AI coding agents. It allows users to easily switch between different coding agents, orchestrate their execution, review work, start dev servers, and track task statuses. The tool centralizes the configuration of coding agent MCP configs, providing a comprehensive solution for managing coding tasks efficiently.

agnai
Agnaistic is an AI roleplay chat tool that allows users to interact with personalized characters using their favorite AI services. It supports multiple AI services, persona schema formats, and features such as group conversations, user authentication, and memory/lore books. Agnaistic can be self-hosted or run using Docker, and it provides a range of customization options through its settings.json file. The tool is designed to be user-friendly and accessible, making it suitable for both casual users and developers.
shortest
Shortest is a project for local development that helps set up environment variables and services for a web application. It provides a guide for setting up Node.js and pnpm dependencies, configuring services like Clerk, Vercel Postgres, Anthropic, Stripe, and GitHub OAuth, and running the application and tests locally.

telemetry-airflow
This repository codifies the Airflow cluster that is deployed at workflow.telemetry.mozilla.org (behind SSO) and commonly referred to as "WTMO" or simply "Airflow". Some links relevant to users and developers of WTMO: * The `dags` directory in this repository contains some custom DAG definitions * Many of the DAGs registered with WTMO don't live in this repository, but are instead generated from ETL task definitions in bigquery-etl * The Data SRE team maintains a WTMO Developer Guide (behind SSO)
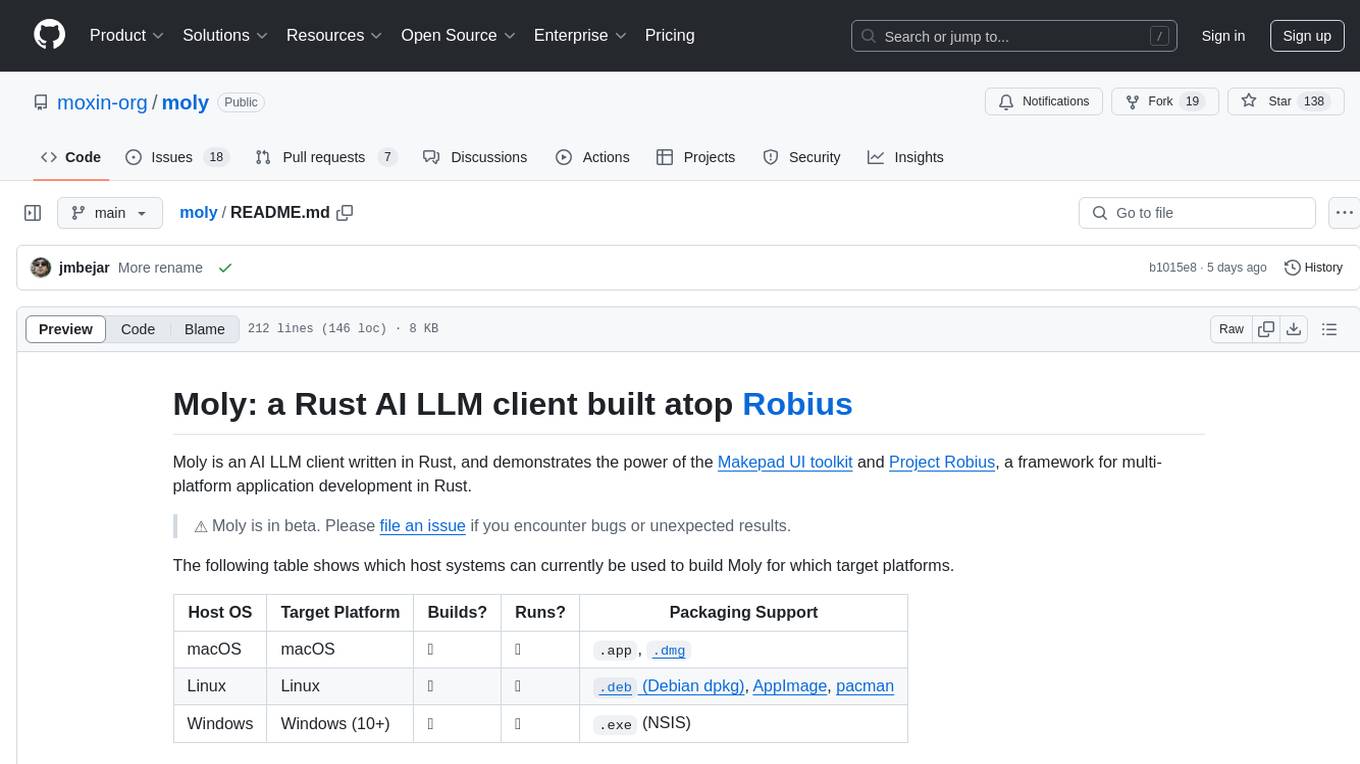
moly
Moly is an AI LLM client written in Rust, showcasing the capabilities of the Makepad UI toolkit and Project Robius, a framework for multi-platform application development in Rust. It is currently in beta, allowing users to build and run Moly on macOS, Linux, and Windows. The tool provides packaging support for different platforms, such as `.app`, `.dmg`, `.deb`, AppImage, pacman, and `.exe` (NSIS). Users can easily set up WasmEdge using `moly-runner` and leverage `cargo` commands to build and run Moly. Additionally, Moly offers pre-built releases for download and supports packaging for distribution on Linux, Windows, and macOS.
middleware
Middleware is an open-source engineering management tool that helps engineering leaders measure and analyze team effectiveness using DORA metrics. It integrates with CI/CD tools, automates DORA metric collection and analysis, visualizes key performance indicators, provides customizable reports and dashboards, and integrates with project management platforms. Users can set up Middleware using Docker or manually, generate encryption keys, set up backend and web servers, and access the application to view DORA metrics. The tool calculates DORA metrics using GitHub data, including Deployment Frequency, Lead Time for Changes, Mean Time to Restore, and Change Failure Rate. Middleware aims to provide DORA metrics to users based on their Git data, simplifying the process of tracking software delivery performance and operational efficiency.
BuildCLI
BuildCLI is a command-line interface (CLI) tool designed for managing and automating common tasks in Java project development. It simplifies the development process by allowing users to create, compile, manage dependencies, run projects, generate documentation, manage configuration profiles, dockerize projects, integrate CI/CD tools, and generate structured changelogs. The tool aims to enhance productivity and streamline Java project management by providing a range of functionalities accessible directly from the terminal.
langstream
LangStream is a tool for natural language processing tasks, providing a CLI for easy installation and usage. Users can try sample applications like Chat Completions and create their own applications using the developer documentation. It supports running on Kubernetes for production-ready deployment, with support for various Kubernetes distributions and external components like Apache Kafka or Apache Pulsar cluster. Users can deploy LangStream locally using minikube and manage the cluster with mini-langstream. Development requirements include Docker, Java 17, Git, Python 3.11+, and PIP, with the option to test local code changes using mini-langstream.
director
Director is a context infrastructure tool for AI agents that simplifies managing MCP servers, prompts, and configurations by packaging them into portable workspaces accessible through a single endpoint. It allows users to define context workspaces once and share them across different AI clients, enabling seamless collaboration, instant context switching, and secure isolation of untrusted servers without cloud dependencies or API keys. Director offers features like workspaces, universal portability, local-first architecture, sandboxing, smart filtering, unified OAuth, observability, multiple interfaces, and compatibility with all MCP clients and servers.
tiledesk-dashboard
Tiledesk is an open-source live chat platform with integrated chatbots written in Node.js and Express. It is designed to be a multi-channel platform for web, Android, and iOS, and it can be used to increase sales or provide post-sales customer service. Tiledesk's chatbot technology allows for automation of conversations, and it also provides APIs and webhooks for connecting external applications. Additionally, it offers a marketplace for apps and features such as CRM, ticketing, and data export.
For similar tasks
sandbox
Sandbox is an open-source cloud-based code editing environment with custom AI code autocompletion and real-time collaboration. It consists of a frontend built with Next.js, TailwindCSS, Shadcn UI, Clerk, Monaco, and Liveblocks, and a backend with Express, Socket.io, Cloudflare Workers, D1 database, R2 storage, Workers AI, and Drizzle ORM. The backend includes microservices for database, storage, and AI functionalities. Users can run the project locally by setting up environment variables and deploying the containers. Contributions are welcome following the commit convention and structure provided in the repository.
Notate
Notate is a powerful desktop research assistant that combines AI-driven analysis with advanced vector search technology. It streamlines research workflow by processing, organizing, and retrieving information from documents, audio, and text. Notate offers flexible AI capabilities with support for various LLM providers and local models, ensuring data privacy. Built for researchers, academics, and knowledge workers, it features real-time collaboration, accessible UI, and cross-platform compatibility.

only_train_once
Only Train Once (OTO) is an automatic, architecture-agnostic DNN training and compression framework that allows users to train a general DNN from scratch or a pretrained checkpoint to achieve high performance and slimmer architecture simultaneously in a one-shot manner without fine-tuning. The framework includes features for automatic structured pruning and erasing operators, as well as hybrid structured sparse optimizers for efficient model compression. OTO provides tools for pruning zero-invariant group partitioning, constructing pruned models, and visualizing pruning and erasing dependency graphs. It supports the HESSO optimizer and offers a sanity check for compliance testing on various DNNs. The repository also includes publications, installation instructions, quick start guides, and a roadmap for future enhancements and collaborations.

ChaKt-KMP
ChaKt is a multiplatform app built using Kotlin and Compose Multiplatform to demonstrate the use of Generative AI SDK for Kotlin Multiplatform to generate content using Google's Generative AI models. It features a simple chat based user interface and experience to interact with AI. The app supports mobile, desktop, and web platforms, and is built with Kotlin Multiplatform, Kotlin Coroutines, Compose Multiplatform, Generative AI SDK, Calf - File picker, and BuildKonfig. Users can contribute to the project by following the guidelines in CONTRIBUTING.md. The app is licensed under the MIT License.

crawl4ai
Crawl4AI is a powerful and free web crawling service that extracts valuable data from websites and provides LLM-friendly output formats. It supports crawling multiple URLs simultaneously, replaces media tags with ALT, and is completely free to use and open-source. Users can integrate Crawl4AI into Python projects as a library or run it as a standalone local server. The tool allows users to crawl and extract data from specified URLs using different providers and models, with options to include raw HTML content, force fresh crawls, and extract meaningful text blocks. Configuration settings can be adjusted in the `crawler/config.py` file to customize providers, API keys, chunk processing, and word thresholds. Contributions to Crawl4AI are welcome from the open-source community to enhance its value for AI enthusiasts and developers.
void
Void is an open-source Cursor alternative, providing a full source code for users to build and develop. It is a fork of the vscode repository, offering a waitlist for the official release. Users can contribute by checking the Project board and following the guidelines in CONTRIBUTING.md. Support is available through Discord or email.

aphrodite-engine
Aphrodite is an inference engine optimized for serving HuggingFace-compatible models at scale. It leverages vLLM's Paged Attention technology to deliver high-performance model inference for multiple concurrent users. The engine supports continuous batching, efficient key/value management, optimized CUDA kernels, quantization support, distributed inference, and modern samplers. It can be easily installed and launched, with Docker support for deployment. Aphrodite requires Linux or Windows OS, Python 3.8 to 3.12, and CUDA >= 11. It is designed to utilize 90% of GPU VRAM but offers options to limit memory usage. Contributors are welcome to enhance the engine.
cua
Cua is a tool for creating and running high-performance macOS and Linux virtual machines on Apple Silicon, with built-in support for AI agents. It provides libraries like Lume for running VMs with near-native performance, Computer for interacting with sandboxes, and Agent for running agentic workflows. Users can refer to the documentation for onboarding, explore demos showcasing AI-Gradio and GitHub issue fixing, and utilize accessory libraries like Core, PyLume, Computer Server, and SOM. Contributions are welcome, and the tool is open-sourced under the MIT License.
For similar jobs

AirGo
AirGo is a front and rear end separation, multi user, multi protocol proxy service management system, simple and easy to use. It supports vless, vmess, shadowsocks, and hysteria2.

mosec
Mosec is a high-performance and flexible model serving framework for building ML model-enabled backend and microservices. It bridges the gap between any machine learning models you just trained and the efficient online service API. * **Highly performant** : web layer and task coordination built with Rust 🦀, which offers blazing speed in addition to efficient CPU utilization powered by async I/O * **Ease of use** : user interface purely in Python 🐍, by which users can serve their models in an ML framework-agnostic manner using the same code as they do for offline testing * **Dynamic batching** : aggregate requests from different users for batched inference and distribute results back * **Pipelined stages** : spawn multiple processes for pipelined stages to handle CPU/GPU/IO mixed workloads * **Cloud friendly** : designed to run in the cloud, with the model warmup, graceful shutdown, and Prometheus monitoring metrics, easily managed by Kubernetes or any container orchestration systems * **Do one thing well** : focus on the online serving part, users can pay attention to the model optimization and business logic

llm-code-interpreter
The 'llm-code-interpreter' repository is a deprecated plugin that provides a code interpreter on steroids for ChatGPT by E2B. It gives ChatGPT access to a sandboxed cloud environment with capabilities like running any code, accessing Linux OS, installing programs, using filesystem, running processes, and accessing the internet. The plugin exposes commands to run shell commands, read files, and write files, enabling various possibilities such as running different languages, installing programs, starting servers, deploying websites, and more. It is powered by the E2B API and is designed for agents to freely experiment within a sandboxed environment.

pezzo
Pezzo is a fully cloud-native and open-source LLMOps platform that allows users to observe and monitor AI operations, troubleshoot issues, save costs and latency, collaborate, manage prompts, and deliver AI changes instantly. It supports various clients for prompt management, observability, and caching. Users can run the full Pezzo stack locally using Docker Compose, with prerequisites including Node.js 18+, Docker, and a GraphQL Language Feature Support VSCode Extension. Contributions are welcome, and the source code is available under the Apache 2.0 License.

learn-generative-ai
Learn Cloud Applied Generative AI Engineering (GenEng) is a course focusing on the application of generative AI technologies in various industries. The course covers topics such as the economic impact of generative AI, the role of developers in adopting and integrating generative AI technologies, and the future trends in generative AI. Students will learn about tools like OpenAI API, LangChain, and Pinecone, and how to build and deploy Large Language Models (LLMs) for different applications. The course also explores the convergence of generative AI with Web 3.0 and its potential implications for decentralized intelligence.

gcloud-aio
This repository contains shared codebase for two projects: gcloud-aio and gcloud-rest. gcloud-aio is built for Python 3's asyncio, while gcloud-rest is a threadsafe requests-based implementation. It provides clients for Google Cloud services like Auth, BigQuery, Datastore, KMS, PubSub, Storage, and Task Queue. Users can install the library using pip and refer to the documentation for usage details. Developers can contribute to the project by following the contribution guide.

fluid
Fluid is an open source Kubernetes-native Distributed Dataset Orchestrator and Accelerator for data-intensive applications, such as big data and AI applications. It implements dataset abstraction, scalable cache runtime, automated data operations, elasticity and scheduling, and is runtime platform agnostic. Key concepts include Dataset and Runtime. Prerequisites include Kubernetes version > 1.16, Golang 1.18+, and Helm 3. The tool offers features like accelerating remote file accessing, machine learning, accelerating PVC, preloading dataset, and on-the-fly dataset cache scaling. Contributions are welcomed, and the project is under the Apache 2.0 license with a vendor-neutral approach.

aiges
AIGES is a core component of the Athena Serving Framework, designed as a universal encapsulation tool for AI developers to deploy AI algorithm models and engines quickly. By integrating AIGES, you can deploy AI algorithm models and engines rapidly and host them on the Athena Serving Framework, utilizing supporting auxiliary systems for networking, distribution strategies, data processing, etc. The Athena Serving Framework aims to accelerate the cloud service of AI algorithm models and engines, providing multiple guarantees for cloud service stability through cloud-native architecture. You can efficiently and securely deploy, upgrade, scale, operate, and monitor models and engines without focusing on underlying infrastructure and service-related development, governance, and operations.