
aphrodite-engine
Large-scale LLM inference engine
Stars: 1210

Aphrodite is the official backend engine for PygmalionAI, serving as the inference endpoint for the website. It allows serving Hugging Face-compatible models with fast speeds. Features include continuous batching, efficient K/V management, optimized CUDA kernels, quantization support, distributed inference, and 8-bit KV Cache. The engine requires Linux OS and Python 3.8 to 3.12, with CUDA >= 11 for build requirements. It supports various GPUs, CPUs, TPUs, and Inferentia. Users can limit GPU memory utilization and access full commands via CLI.
README:

Aphrodite is the official backend engine for PygmalionAI. It is designed to serve as the inference endpoint for the PygmalionAI website, and to allow serving Hugging Face-compatible models to a large number of users with blazing fast speeds (thanks to vLLM's Paged Attention).
Aphrodite builds upon and integrates the exceptional work from various projects, primarily vLLM.
Aphrodite is developed in collaboration with Ruliad.
(09/2024) v0.6.1 is here. You can now load FP16 models in FP2 to FP7 quant formats, to achieve extremely high throughput and save on memory.
(09/2024) v0.6.0 is released, with huge throughput improvements, many new quant formats (including fp8 and llm-compressor), asymmetric tensor parallel, pipeline parallel and more! Please check out the exhaustive documentation for the User and Developer guides.
- Continuous Batching
- Efficient K/V management with PagedAttention from vLLM
- Optimized CUDA kernels for improved inference
- Quantization support via AQLM, AWQ, Bitsandbytes, GGUF, GPTQ, QuIP#, Smoothquant+, SqueezeLLM, Marlin, FP2-FP12
- Distributed inference
- 8-bit KV Cache for higher context lengths and throughput, at both FP8 E5M3 and E4M3 formats.
Install the engine:
pip install -U aphrodite-engineThen launch a model:
aphrodite run meta-llama/Meta-Llama-3.1-8B-InstructThis will create a OpenAI-compatible API server that can be accessed at port 2242 of the localhost. You can plug in the API into a UI that supports OpenAI, such as SillyTavern.
Please refer to the documentation for the full list of arguments and flags you can pass to the engine.
You can play around with the engine in the demo here:
Additionally, we provide a Docker image for easy deployment. Here's a basic command to get you started:
docker run --runtime nvidia --gpus all \
-v ~/.cache/huggingface:/root/.cache/huggingface \
#--env "CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7" \
-p 2242:2242 \
--ipc=host \
alpindale/aphrodite-openai:latest \
--model NousResearch/Meta-Llama-3.1-8B-Instruct \
--tensor-parallel-size 8 \
--api-keys "sk-empty"This will pull the Aphrodite Engine image (~8GiB download), and launch the engine with the Llama-3.1-8B-Instruct model at port 2242.
- Operating System: Linux, Windows (Needs building from source)
- Python: 3.8 to 3.12
- CUDA >= 11
For supported devices, see here. Generally speaking, all semi-modern GPUs are supported - down to Pascal (GTX 10xx, P40, etc.) We also support AMD GPUs, Intel CPUs and GPUs, Google TPU, and AWS Inferentia.
-
By design, Aphrodite takes up 90% of your GPU's VRAM. If you're not serving an LLM at scale, you may want to limit the amount of memory it takes up. You can do this in the API example by launching the server with the
--gpu-memory-utilization 0.6(0.6 means 60%), or--single-user-modeto only allocate as much memory as needed for a single sequence. -
You can view the full list of commands by running
aphrodite run --help.
Aphrodite Engine would have not been possible without the phenomenal work of other open-source projects. Credits go to:
- vLLM (CacheFlow)
- TensorRT-LLM
- xFormers
- Flash Attention
- llama.cpp
- AutoAWQ
- AutoGPTQ
- SqueezeLLM
- Exllamav2
- TabbyAPI
- AQLM
- KoboldAI
- Text Generation WebUI
- Megatron-LM
- Ray
Everyone is welcome to contribute. You can support the project by opening Pull Requests for new features, fixes, or general UX improvements.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for aphrodite-engine
Similar Open Source Tools
aphrodite-engine
Aphrodite is the official backend engine for PygmalionAI, serving as the inference endpoint for the website. It allows serving Hugging Face-compatible models with fast speeds. Features include continuous batching, efficient K/V management, optimized CUDA kernels, quantization support, distributed inference, and 8-bit KV Cache. The engine requires Linux OS and Python 3.8 to 3.12, with CUDA >= 11 for build requirements. It supports various GPUs, CPUs, TPUs, and Inferentia. Users can limit GPU memory utilization and access full commands via CLI.

aphrodite-engine
Aphrodite is an inference engine optimized for serving HuggingFace-compatible models at scale. It leverages vLLM's Paged Attention technology to deliver high-performance model inference for multiple concurrent users. The engine supports continuous batching, efficient key/value management, optimized CUDA kernels, quantization support, distributed inference, and modern samplers. It can be easily installed and launched, with Docker support for deployment. Aphrodite requires Linux or Windows OS, Python 3.8 to 3.12, and CUDA >= 11. It is designed to utilize 90% of GPU VRAM but offers options to limit memory usage. Contributors are welcome to enhance the engine.
AITemplate
AITemplate (AIT) is a Python framework that transforms deep neural networks into CUDA (NVIDIA GPU) / HIP (AMD GPU) C++ code for lightning-fast inference serving. It offers high performance close to roofline fp16 TensorCore (NVIDIA GPU) / MatrixCore (AMD GPU) performance on major models. AITemplate is unified, open, and flexible, supporting a comprehensive range of fusions for both GPU platforms. It provides excellent backward capability, horizontal fusion, vertical fusion, memory fusion, and works with or without PyTorch. FX2AIT is a tool that converts PyTorch models into AIT for fast inference serving, offering easy conversion and expanded support for models with unsupported operators.

NeMo
NVIDIA NeMo Framework is a scalable and cloud-native generative AI framework built for researchers and PyTorch developers working on Large Language Models (LLMs), Multimodal Models (MMs), Automatic Speech Recognition (ASR), Text to Speech (TTS), and Computer Vision (CV) domains. It is designed to help you efficiently create, customize, and deploy new generative AI models by leveraging existing code and pre-trained model checkpoints.

NeMo
NeMo Framework is a generative AI framework built for researchers and pytorch developers working on large language models (LLMs), multimodal models (MM), automatic speech recognition (ASR), and text-to-speech synthesis (TTS). The primary objective of NeMo is to provide a scalable framework for researchers and developers from industry and academia to more easily implement and design new generative AI models by being able to leverage existing code and pretrained models.

pathway
Pathway is a Python data processing framework for analytics and AI pipelines over data streams. It's the ideal solution for real-time processing use cases like streaming ETL or RAG pipelines for unstructured data. Pathway comes with an **easy-to-use Python API** , allowing you to seamlessly integrate your favorite Python ML libraries. Pathway code is versatile and robust: **you can use it in both development and production environments, handling both batch and streaming data effectively**. The same code can be used for local development, CI/CD tests, running batch jobs, handling stream replays, and processing data streams. Pathway is powered by a **scalable Rust engine** based on Differential Dataflow and performs incremental computation. Your Pathway code, despite being written in Python, is run by the Rust engine, enabling multithreading, multiprocessing, and distributed computations. All the pipeline is kept in memory and can be easily deployed with **Docker and Kubernetes**. You can install Pathway with pip: `pip install -U pathway` For any questions, you will find the community and team behind the project on Discord.
DistServe
DistServe improves the performance of large language models serving by disaggregating the prefill and decoding computation. It allows setting parallelism configs and scheduling strategies for the two phases independently, handling KV-Cache communication and memory management automatically. Utilizes a high-performance C++ Transformer inference library SwiftTransformer with features like model/pipeline parallelism, FlashAttention, Continuous Batching, and PagedAttention. Supports GPT-2, OPT, and LLaMA2 models.

super-agent-party
A 3D AI desktop companion with endless possibilities! This repository provides a platform for enhancing the LLM API without code modification, supporting seamless integration of various functionalities such as knowledge bases, real-time networking, multimodal capabilities, automation, and deep thinking control. It offers one-click deployment to multiple terminals, ecological tool interconnection, standardized interface opening, and compatibility across all platforms. Users can deploy the tool on Windows, macOS, Linux, or Docker, and access features like intelligent agent deployment, VRM desktop pets, Tavern character cards, QQ bot deployment, and developer-friendly interfaces. The tool supports multi-service providers, extensive tool integration, and ComfyUI workflows. Hardware requirements are minimal, making it suitable for various deployment scenarios.
modular
The Modular Platform is a unified suite of AI libraries and tools designed for AI development and deployment. It abstracts hardware complexity to enable running popular open models with high GPU and CPU performance without code changes. The repository contains over 450,000 lines of code from 6000+ contributors, making it one of the largest open-source repositories for CPU and GPU kernels. Key components include the Mojo standard library, MAX GPU and CPU kernels, MAX inference server, MAX model pipelines, and code examples. The repository has main and stable branches for nightly builds and stable releases, respectively. Contributions are accepted for the Mojo standard library, MAX AI kernels, code examples, and Mojo docs.

Revornix
Revornix is an information management tool designed for the AI era. It allows users to conveniently integrate all visible information and generates comprehensive reports at specific times. The tool offers cross-platform availability, all-in-one content aggregation, document transformation & vectorized storage, native multi-tenancy, localization & open-source features, smart assistant & built-in MCP, seamless LLM integration, and multilingual & responsive experience for users.
uTensor
uTensor is an extremely light-weight machine learning inference framework built on Tensorflow and optimized for Arm targets. It consists of a runtime library and an offline tool that handles most of the model translation work. The core runtime is only ~2KB. The workflow involves constructing and training a model in Tensorflow, then using uTensor to produce C++ code for inferencing. The runtime ensures system safety, guarantees RAM usage, and focuses on clear, concise, and debuggable code. The high-level API simplifies tensor handling and operator execution for embedded systems.

curated-transformers
Curated Transformers is a transformer library for PyTorch that provides state-of-the-art models composed of reusable components. It supports various transformer architectures, including encoders like ALBERT, BERT, and RoBERTa, and decoders like Falcon, Llama, and MPT. The library emphasizes consistent type annotations, minimal dependencies, and ease of use for education and research. It has been production-tested by Explosion and will be the default transformer implementation in spaCy 3.7.
video-search-and-summarization
The NVIDIA AI Blueprint for Video Search and Summarization is a repository showcasing video search and summarization agent with NVIDIA NIM microservices. It enables industries to make better decisions faster by providing insightful, accurate, and interactive video analytics AI agents. These agents can perform tasks like video summarization and visual question-answering, unlocking new application possibilities. The repository includes software components like NIM microservices, ingestion pipeline, and CA-RAG module, offering a comprehensive solution for analyzing and summarizing large volumes of video data. The target audience includes video analysts, IT engineers, and GenAI developers who can benefit from the blueprint's 1-click deployment steps, easy-to-manage configurations, and customization options. The repository structure overview includes directories for deployment, source code, and training notebooks, along with documentation for detailed instructions. Hardware requirements vary based on deployment topology and dependencies like VLM and LLM, with different deployment methods such as Launchable Deployment, Docker Compose Deployment, and Helm Chart Deployment provided for various use cases.
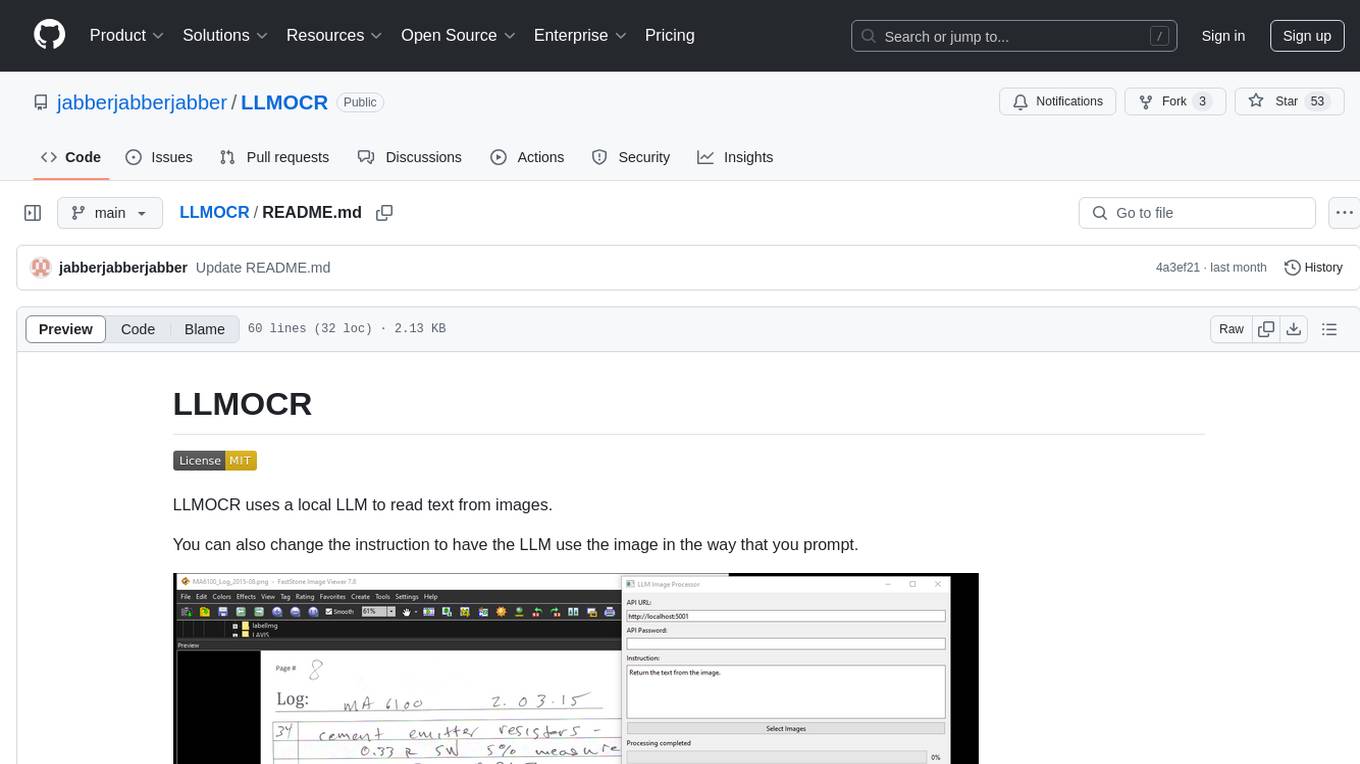
LLMOCR
LLMOCR is a tool that utilizes a local Large Language Model (LLM) to extract text from images. It offers a user-friendly GUI and supports GPU acceleration for faster inference. The tool is cross-platform, compatible with Windows, macOS ARM, and Linux. Users can prompt the LLM to process images in a customized way. The processing is done locally on the user's machine, ensuring data privacy and security. LLMOCR requires Python 3.8 or higher and KoboldCPP for installation and operation.
freegenius
FreeGenius AI is an ambitious project offering a comprehensive suite of AI solutions that mirror the capabilities of LetMeDoIt AI. It is designed to engage in intuitive conversations, execute codes, provide up-to-date information, and perform various tasks. The tool is free, customizable, and provides access to real-time data and device information. It aims to support offline and online backends, open-source large language models, and optional API keys. Users can use FreeGenius AI for tasks like generating tweets, analyzing audio, searching financial data, checking weather, and creating maps.

llm-app
Pathway's LLM (Large Language Model) Apps provide a platform to quickly deploy AI applications using the latest knowledge from data sources. The Python application examples in this repository are Docker-ready, exposing an HTTP API to the frontend. These apps utilize the Pathway framework for data synchronization, API serving, and low-latency data processing without the need for additional infrastructure dependencies. They connect to document data sources like S3, Google Drive, and Sharepoint, offering features like real-time data syncing, easy alert setup, scalability, monitoring, security, and unification of application logic.
For similar tasks
aphrodite-engine
Aphrodite is the official backend engine for PygmalionAI, serving as the inference endpoint for the website. It allows serving Hugging Face-compatible models with fast speeds. Features include continuous batching, efficient K/V management, optimized CUDA kernels, quantization support, distributed inference, and 8-bit KV Cache. The engine requires Linux OS and Python 3.8 to 3.12, with CUDA >= 11 for build requirements. It supports various GPUs, CPUs, TPUs, and Inferentia. Users can limit GPU memory utilization and access full commands via CLI.

ai-on-gke
This repository contains assets related to AI/ML workloads on Google Kubernetes Engine (GKE). Run optimized AI/ML workloads with Google Kubernetes Engine (GKE) platform orchestration capabilities. A robust AI/ML platform considers the following layers: Infrastructure orchestration that support GPUs and TPUs for training and serving workloads at scale Flexible integration with distributed computing and data processing frameworks Support for multiple teams on the same infrastructure to maximize utilization of resources

ray
Ray is a unified framework for scaling AI and Python applications. It consists of a core distributed runtime and a set of AI libraries for simplifying ML compute, including Data, Train, Tune, RLlib, and Serve. Ray runs on any machine, cluster, cloud provider, and Kubernetes, and features a growing ecosystem of community integrations. With Ray, you can seamlessly scale the same code from a laptop to a cluster, making it easy to meet the compute-intensive demands of modern ML workloads.

labelbox-python
Labelbox is a data-centric AI platform for enterprises to develop, optimize, and use AI to solve problems and power new products and services. Enterprises use Labelbox to curate data, generate high-quality human feedback data for computer vision and LLMs, evaluate model performance, and automate tasks by combining AI and human-centric workflows. The academic & research community uses Labelbox for cutting-edge AI research.

djl
Deep Java Library (DJL) is an open-source, high-level, engine-agnostic Java framework for deep learning. It is designed to be easy to get started with and simple to use for Java developers. DJL provides a native Java development experience and allows users to integrate machine learning and deep learning models with their Java applications. The framework is deep learning engine agnostic, enabling users to switch engines at any point for optimal performance. DJL's ergonomic API interface guides users with best practices to accomplish deep learning tasks, such as running inference and training neural networks.

mlflow
MLflow is a platform to streamline machine learning development, including tracking experiments, packaging code into reproducible runs, and sharing and deploying models. MLflow offers a set of lightweight APIs that can be used with any existing machine learning application or library (TensorFlow, PyTorch, XGBoost, etc), wherever you currently run ML code (e.g. in notebooks, standalone applications or the cloud). MLflow's current components are:
* `MLflow Tracking

tt-metal
TT-NN is a python & C++ Neural Network OP library. It provides a low-level programming model, TT-Metalium, enabling kernel development for Tenstorrent hardware.

burn
Burn is a new comprehensive dynamic Deep Learning Framework built using Rust with extreme flexibility, compute efficiency and portability as its primary goals.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.