
arch
Arch is an intelligent prompt gateway. Engineered with (fast) LLMs for the secure handling, robust observability, and seamless integration of prompts with APIs - all outside business logic. Built by the core contributors of Envoy proxy, on Envoy.
Stars: 90
Arch is an intelligent Layer 7 gateway designed to protect, observe, and personalize LLM applications with APIs. It handles tasks like detecting and rejecting jailbreak attempts, calling backend APIs, disaster recovery, and observability. Built on Envoy Proxy, it offers features like function calling, prompt guardrails, traffic management, and standards-based observability. Arch aims to improve the speed, security, and personalization of generative AI applications.
README:
![]()
Arch is an intelligent Layer 7 gateway designed to protect, observe, and personalize LLM applications (agents, assistants, co-pilots) with your APIs.
Engineered with purpose-built LLMs, Arch handles the critical but undifferentiated tasks related to the handling and processing of prompts, including detecting and rejecting jailbreak attempts, intelligently calling "backend" APIs to fulfill the user's request represented in a prompt, routing to and offering disaster recovery between upstream LLMs, and managing the observability of prompts and LLM interactions in a centralized way.
Arch is built on (and by the core contributors of) Envoy Proxy with the belief that:
Prompts are nuanced and opaque user requests, which require the same capabilities as traditional HTTP requests including secure handling, intelligent routing, robust observability, and integration with backend (API) systems for personalization – all outside business logic.*
Core Features:
- Built on Envoy: Arch runs alongside application servers, and builds on top of Envoy's proven HTTP management and scalability features to handle ingress and egress traffic related to prompts and LLMs.
- Function Calling for fast Agentic and RAG apps. Engineered with purpose-built LLMs to handle fast, cost-effective, and accurate prompt-based tasks like function/API calling, and parameter extraction from prompts.
- Prompt Guard: Arch centralizes prompt guardrails to prevent jailbreak attempts and ensure safe user interactions without writing a single line of code.
- Traffic Management: Arch manages LLM calls, offering smart retries, automatic cutover, and resilient upstream connections for continuous availability.
- Standards-based Observability: Arch uses the W3C Trace Context standard to enable complete request tracing across applications, ensuring compatibility with observability tools, and provides metrics to monitor latency, token usage, and error rates, helping optimize AI application performance.
Jump to our docs to learn how you can use Arch to improve the speed, security and personalization of your GenAI apps.
To get in touch with us, please join our discord server. We will be monitoring that actively and offering support there.
- Function Calling - Walk through of critical function calling capabilities
- Insurance Agent - Build a full insurance agent with arch
- Network Agent - Build a networking co-pilot/agent agent with arch
Follow this guide to learn how to quickly set up Arch and integrate it into your generative AI applications.
Before you begin, ensure you have the following:
-
Docker&Pythoninstalled on your system -
API Keysfor LLM providers (if using external LLMs)
Arch's CLI allows you to manage and interact with the Arch gateway efficiently. To install the CLI, simply run the following command: Tip: We recommend that developers create a new Python virtual environment to isolate dependencies before installing Arch. This ensures that archgw and its dependencies do not interfere with other packages on your system.
$ python -m venv venv
$ source venv/bin/activate # On Windows, use: venv\Scripts\activate
$ pip install archgwArch operates based on a configuration file where you can define LLM providers, prompt targets, guardrails, etc. Below is an example configuration to get you started:
version: v0.1
listen:
address: 0.0.0.0 # or 127.0.0.1
port: 10000
# Defines how Arch should parse the content from application/json or text/pain Content-type in the http request
message_format: huggingface
# Centralized way to manage LLMs, manage keys, retry logic, failover and limits in a central way
llm_providers:
- name: OpenAI
provider: openai
access_key: OPENAI_API_KEY
model: gpt-4o
default: true
stream: true
# default system prompt used by all prompt targets
system_prompt: You are a network assistant that just offers facts; not advice on manufacturers or purchasing decisions.
prompt_targets:
- name: reboot_devices
description: Reboot specific devices or device groups
path: /agent/device_reboot
parameters:
- name: device_ids
type: list
description: A list of device identifiers (IDs) to reboot.
required: false
- name: device_group
type: str
description: The name of the device group to reboot
required: false
# Arch creates a round-robin load balancing between different endpoints, managed via the cluster subsystem.
endpoints:
app_server:
# value could be ip address or a hostname with port
# this could also be a list of endpoints for load balancing
# for example endpoint: [ ip1:port, ip2:port ]
endpoint: 127.0.0.1:80
# max time to wait for a connection to be established
connect_timeout: 0.005sMake outbound calls via Arch
import openai
# Set the OpenAI API base URL to the Arch gateway endpoint
openai.api_base = "http://127.0.0.1:51001/v1"
# No need to set openai.api_key since it's configured in Arch's gateway
# Use the OpenAI client as usual
response = openai.Completion.create(
model="text-davinci-003",
prompt="What is the capital of France?"
)
print("OpenAI Response:", response.choices[0].text.strip())Arch is designed to support best-in class observability by supporting open standards. Please read our docs on observability for more details on tracing, metrics, and logs
We would love feedback on our Roadmap and we welcome contributions to Arch! Whether you're fixing bugs, adding new features, improving documentation, or creating tutorials, your help is much appreciated. Please vist our Contribution Guide for more details
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for arch
Similar Open Source Tools
arch
Arch is an intelligent Layer 7 gateway designed to protect, observe, and personalize LLM applications with APIs. It handles tasks like detecting and rejecting jailbreak attempts, calling backend APIs, disaster recovery, and observability. Built on Envoy Proxy, it offers features like function calling, prompt guardrails, traffic management, and standards-based observability. Arch aims to improve the speed, security, and personalization of generative AI applications.
AgentUp
AgentUp is an active development tool that provides a developer-first agent framework for creating AI agents with enterprise-grade infrastructure. It allows developers to define agents with configuration, ensuring consistent behavior across environments. The tool offers secure design, configuration-driven architecture, extensible ecosystem for customizations, agent-to-agent discovery, asynchronous task architecture, deterministic routing, and MCP support. It supports multiple agent types like reactive agents and iterative agents, making it suitable for chatbots, interactive applications, research tasks, and more. AgentUp is built by experienced engineers from top tech companies and is designed to make AI agents production-ready, secure, and reliable.
ai2apps
AI2Apps is a visual IDE for building LLM-based AI agent applications, enabling developers to efficiently create AI agents through drag-and-drop, with features like design-to-development for rapid prototyping, direct packaging of agents into apps, powerful debugging capabilities, enhanced user interaction, efficient team collaboration, flexible deployment, multilingual support, simplified product maintenance, and extensibility through plugins.
AgentConnect
AgentConnect is an open-source implementation of the Agent Network Protocol (ANP) aiming to define how agents connect with each other and build an open, secure, and efficient collaboration network for billions of agents. It addresses challenges like interconnectivity, native interfaces, and efficient collaboration by providing authentication, end-to-end encryption, meta-protocol handling, and application layer protocol integration. The project focuses on performance and multi-platform support, with plans to rewrite core components in Rust and support Mac, Linux, Windows, mobile platforms, and browsers. AgentConnect aims to establish ANP as an industry standard through protocol development and forming a standardization committee.
uusec-waf
UUSEC WAF is an industrial grade free, high-performance, and highly scalable web application and API security protection product that supports AI and semantic engines. It provides intelligent 0-day defense, ultimate CDN acceleration, powerful proactive defense, advanced semantic engine, and advanced rule engine. With features like machine learning technology, cache cleaning, dual layer defense, semantic analysis, and Lua script rule writing, UUSEC WAF offers comprehensive website protection with three-layer defense functions at traffic, system, and runtime layers.
k8sgateway
K8sGateway is a feature-rich, fast, and flexible Kubernetes-native API gateway built on Envoy proxy and Kubernetes Gateway API. It excels in function-level routing, supports legacy apps, microservices, and serverless. It offers robust discovery capabilities, seamless integration with open-source projects, and supports hybrid applications with various technologies, architectures, protocols, and clouds.
AgentConnect
AgentConnect is an open-source implementation of the Agent Network Protocol (ANP) aiming to define how agents connect with each other and build an open, secure, and efficient collaboration network for billions of agents. It addresses challenges like interconnectivity, native interfaces, and efficient collaboration. The architecture includes authentication, end-to-end encryption modules, meta-protocol module, and application layer protocol integration framework. AgentConnect focuses on performance and multi-platform support, with plans to rewrite core components in Rust and support mobile platforms and browsers. The project aims to establish ANP as an industry standard and form an ANP Standardization Committee. Installation is done via 'pip install agent-connect' and demos can be run after cloning the repository. Features include decentralized authentication based on did:wba and HTTP, and meta-protocol negotiation examples.
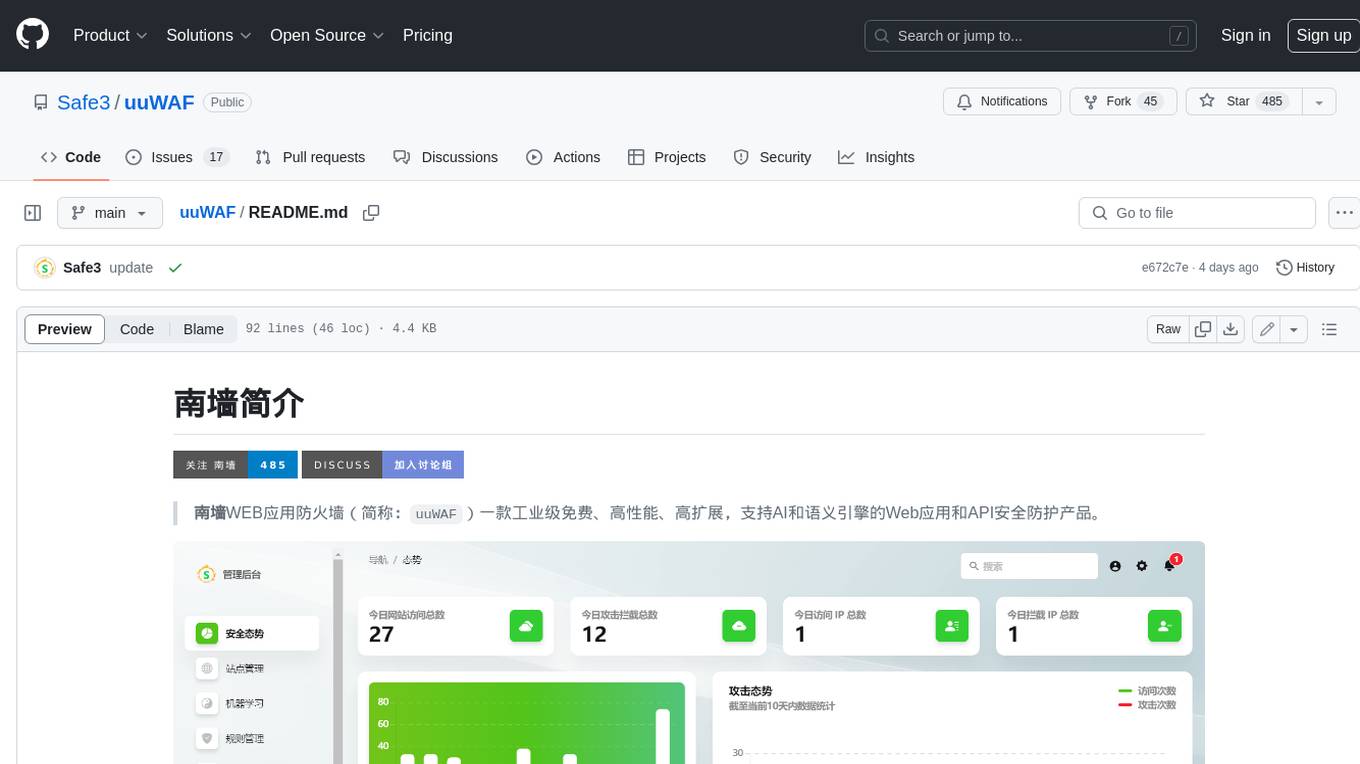
uuWAF
uuWAF is an industrial-grade, free, high-performance, highly extensible web application and API security protection product that supports AI and semantic engines.
trinityX
TrinityX is an open-source HPC, AI, and cloud platform designed to provide all services required in a modern system, with full customization options. It includes default services like Luna node provisioner, OpenLDAP, SLURM or OpenPBS, Prometheus, Grafana, OpenOndemand, and more. TrinityX also sets up NFS-shared directories, OpenHPC applications, environment modules, HA, and more. Users can install TrinityX on Enterprise Linux, configure network interfaces, set up passwordless authentication, and customize the installation using Ansible playbooks. The platform supports HA, OpenHPC integration, and provides detailed documentation for users to contribute to the project.

CSGHub
CSGHub is an open source, trustworthy large model asset management platform that can assist users in governing the assets involved in the lifecycle of LLM and LLM applications (datasets, model files, codes, etc). With CSGHub, users can perform operations on LLM assets, including uploading, downloading, storing, verifying, and distributing, through Web interface, Git command line, or natural language Chatbot. Meanwhile, the platform provides microservice submodules and standardized OpenAPIs, which could be easily integrated with users' own systems. CSGHub is committed to bringing users an asset management platform that is natively designed for large models and can be deployed On-Premise for fully offline operation. CSGHub offers functionalities similar to a privatized Huggingface(on-premise Huggingface), managing LLM assets in a manner akin to how OpenStack Glance manages virtual machine images, Harbor manages container images, and Sonatype Nexus manages artifacts.
hashbrown
Hashbrown is a lightweight and efficient hashing library for Python, designed to provide easy-to-use cryptographic hashing functions for secure data storage and transmission. It supports a variety of hashing algorithms, including MD5, SHA-1, SHA-256, and SHA-512, allowing users to generate hash values for strings, files, and other data types. With Hashbrown, developers can quickly implement data integrity checks, password hashing, digital signatures, and other security features in their Python applications.
cedana-cli
Cedana is a framework for the democritization and commodification of compute. It leverages checkpoint/restore to migrate work across machines, clouds, and beyond. The repo contains a CLI tool for developers to experiment with the system.
kgateway
Kgateway is a feature-rich, fast, and flexible Kubernetes-native API gateway built on top of Envoy proxy and the Kubernetes Gateway API. It excels in function-level routing, supports legacy apps, microservices, and serverless, offers robust discovery capabilities, integrates seamlessly with open-source projects, and is designed to support hybrid applications with various technologies, architectures, protocols, and clouds.

coze-studio
Coze Studio is an all-in-one AI agent development tool that offers the most convenient AI agent development environment, from development to deployment. It provides core technologies for AI agent development, complete app templates, and build frameworks. Coze Studio aims to simplify creating, debugging, and deploying AI agents through visual design and build tools, enabling powerful AI app development and customized business logic. The tool is developed using Golang for the backend, React + TypeScript for the frontend, and follows microservices architecture based on domain-driven design principles.
octelium
Octelium is a free and open source, self-hosted, unified zero trust secure access platform that operates as a modern zero-config remote access VPN, a comprehensive Zero Trust Network Access (ZTNA)/BeyondCorp platform, an ngrok/Cloudflare Tunnel alternative, an API gateway, an AI/LLM gateway, a PaaS-like platform, a Kubernetes gateway/ingress, and a homelab infrastructure. It provides scalable zero trust architecture for identity-based, application-layer aware secure access via private client-based access over WireGuard/QUIC tunnels and public clientless access, with context-aware access control. Octelium offers dynamic secretless access, fine-grained access control, identity-based routing, continuous strong authentication, OpenTelemetry-native auditing, passwordless SSH, effortless deployment of containerized applications, centralized management, and more. It is open source, designed for self-hosting, and provides a commercial license option for businesses.
langgraph
LangGraph is a low-level orchestration framework for building, managing, and deploying long-running, stateful agents. It provides durable execution, human-in-the-loop capabilities, comprehensive memory management, debugging tools, and production-ready deployment infrastructure. LangGraph can be used standalone or integrated with other LangChain products to streamline LLM application development.
For similar tasks
CrewAI-Studio
CrewAI Studio is an application with a user-friendly interface for interacting with CrewAI, offering support for multiple platforms and various backend providers. It allows users to run crews in the background, export single-page apps, and use custom tools for APIs and file writing. The roadmap includes features like better import/export, human input, chat functionality, automatic crew creation, and multiuser environment support.
arch
Arch is an intelligent Layer 7 gateway designed to protect, observe, and personalize LLM applications with APIs. It handles tasks like detecting and rejecting jailbreak attempts, calling backend APIs, disaster recovery, and observability. Built on Envoy Proxy, it offers features like function calling, prompt guardrails, traffic management, and standards-based observability. Arch aims to improve the speed, security, and personalization of generative AI applications.
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.