
interaqt
Better application framework for LLM era.
Stars: 66
Interaqt is a project that aims to separate application business logic from its specific implementation by providing a structured data model and tools to automatically decide and implement software architecture. It liberates individuals and teams from implementation specifics, performance requirements, and cost demands, allowing them to focus on articulating business logic. The approach is considered optimal in the era of large language models (LLMs) as it eliminates uncertainty in generated systems and enables independence from engineering involvement unless specific capabilities are required.
README:
![]()
Better application framework for LLM era.
Interaqt is a project dedicated to separating application business logic from its specific implementation. It offers a revolutionary and rigorously structured data model for articulating business logic, alongside a suite of tools that automatically decide and implement software architecture based on this logic, directly providing usable APIs. Interaqt aims to liberate individuals and teams from the constraints of implementation specifics, performance requirements, and cost demands, allowing them to concentrate on the articulation of business logic and expedite application development. We also believe that this approach is optimal in the era of large language models (LLMs). Compared to generating code with LLMs, building intermediate data structures eliminates the uncertainty in generated systems, enabling true independence from engineering involvement unless specific capabilities are required.
Moving beyond MVC, Interaqt embraces entities, interactions, and activities for an intuitive business logic alignment. This simplifies database design, permissions, and data management, cutting down 80% of non-essential technicalities for developers.
Interaqt's principles reflect natural language, enabling immediate use of ChatGPT for business logic description without extra training. Quickly create a fully operational system with Interaqt's streamlined process. Checkout the video or tutorial to see how it works.

Interaqt transforms backend development with reactive programming, prioritizing data definition over manipulation. Its approach to reactive data ensures efficient incremental calculations and peak performance in all scenarios.

Performance and cost considerations are distinct from business logic in Interaqt's design. It specializes in automated architecture, dynamically adapting to user and data expansion.

Interaqt's abstraction transcends specific programming languages. The NodeJS iteration of Interaqt is now available for use. Anticipate the launch of its Go, Python, and Java versions in the summer of 2024!
| Component | Description | Status |
|---|---|---|
| Interaqt Runtime(NodeJS) | NodeJS runtime that automatically builds databases and generates usable APIs. |
 
|
| Interaqt IDE | Visual editor for processes, data, and more. | 🚧Release on August 2024 |
| Interaqt Runtime(Go) | Go runtime. | 🚧Release on August 2024 |
| Interaqt Runtime(Java) | Java runtime. | 🚧Release on August 2024 |
npx create-interaqt-app myappVisit our website for more details.
We invite you to subscribe to our release event or star our project on GitHub. Your valuable feedback will help us launch even faster!
All of Interaqt's code is open source, and we welcome contributions in any form. If you have any ideas or find any bugs at this stage, please let us know through an Issue.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for interaqt
Similar Open Source Tools
interaqt
Interaqt is a project that aims to separate application business logic from its specific implementation by providing a structured data model and tools to automatically decide and implement software architecture. It liberates individuals and teams from implementation specifics, performance requirements, and cost demands, allowing them to focus on articulating business logic. The approach is considered optimal in the era of large language models (LLMs) as it eliminates uncertainty in generated systems and enables independence from engineering involvement unless specific capabilities are required.
DevOpsGPT
DevOpsGPT is an AI-driven software development automation solution that combines Large Language Models (LLM) with DevOps tools to convert natural language requirements into working software. It improves development efficiency by eliminating the need for tedious requirement documentation, shortens development cycles, reduces communication costs, and ensures high-quality deliverables. The Enterprise Edition offers features like existing project analysis, professional model selection, and support for more DevOps platforms. The tool automates requirement development, generates interface documentation, provides pseudocode based on existing projects, facilitates code refinement, enables continuous integration, and supports software version release. Users can run DevOpsGPT with source code or Docker, and the tool comes with limitations in precise documentation generation and understanding existing project code. The product roadmap includes accurate requirement decomposition, rapid import of development requirements, and integration of more software engineering and professional tools for efficient software development tasks under AI planning and execution.

CodeFuse-muAgent
CodeFuse-muAgent is a Multi-Agent framework designed to streamline Standard Operating Procedure (SOP) orchestration for agents. It integrates toolkits, code libraries, knowledge bases, and sandbox environments for rapid construction of complex Multi-Agent interactive applications. The framework enables efficient execution and handling of multi-layered and multi-dimensional tasks.
craftgen
Craftgen.ai is an innovative AI platform designed for both technical and non-technical users. It's built on a foundation of graph architecture for scalability and the Actor Model for efficient concurrent operations, tailored to both technical and non-technical users. A key aspect of Craftgen.ai is its modular AI approach, allowing users to assemble and customize AI components like building blocks to fit their specific needs. The platform's robustness is enhanced by its event-driven architecture, ensuring reliable data processing and featuring browser web technologies for universal access. Craftgen.ai excels in dynamic tool and workflow generation, with strong offline capabilities for secure environments and plans for desktop application integration. A unique and valuable feature of Craftgen.ai is its marketplace, where users can access a variety of pre-built AI solutions. This marketplace accelerates the deployment of AI tools but also fosters a community of sharing and innovation. Users can contribute to and leverage this repository of solutions, enhancing the platform's versatility and practicality. Craftgen.ai uses JSON schema for industry-standard alignment, enabling seamless integration with any API following the OpenAPI spec. This allows for a broad range of applications, from automating data analysis to streamlining content management. The platform is designed to bridge the gap between advanced AI technology and practical usability. It's a flexible, secure, and intuitive platform that empowers users, from developers seeking to create custom AI solutions to businesses looking to automate routine tasks. Craftgen.ai's goal is to make AI technology an integral, seamless part of everyday problem-solving and innovation, providing a platform where modular AI and a thriving marketplace converge to meet the diverse needs of its users.

CSGHub
CSGHub is an open source, trustworthy large model asset management platform that can assist users in governing the assets involved in the lifecycle of LLM and LLM applications (datasets, model files, codes, etc). With CSGHub, users can perform operations on LLM assets, including uploading, downloading, storing, verifying, and distributing, through Web interface, Git command line, or natural language Chatbot. Meanwhile, the platform provides microservice submodules and standardized OpenAPIs, which could be easily integrated with users' own systems. CSGHub is committed to bringing users an asset management platform that is natively designed for large models and can be deployed On-Premise for fully offline operation. CSGHub offers functionalities similar to a privatized Huggingface(on-premise Huggingface), managing LLM assets in a manner akin to how OpenStack Glance manages virtual machine images, Harbor manages container images, and Sonatype Nexus manages artifacts.

agentUniverse
agentUniverse is a multi-agent framework based on large language models, providing flexible capabilities for building individual agents. It focuses on collaborative pattern components to solve problems in various fields and integrates domain experience. The framework supports LLM model integration and offers various pattern components like PEER and DOE. Users can easily configure models and set up agents for tasks. agentUniverse aims to assist developers and enterprises in constructing domain-expert-level intelligent agents for seamless collaboration.

awesome-generative-ai-guide
This repository serves as a comprehensive hub for updates on generative AI research, interview materials, notebooks, and more. It includes monthly best GenAI papers list, interview resources, free courses, and code repositories/notebooks for developing generative AI applications. The repository is regularly updated with the latest additions to keep users informed and engaged in the field of generative AI.
agentUniverse
agentUniverse is a multi-agent framework based on large language models, providing flexible capabilities for building individual agents. It focuses on multi-agent collaborative patterns, integrating domain experience to help agents solve problems in various fields. The framework includes pattern components like PEER and DOE for event interpretation, industry analysis, and financial report generation. It offers features for agent construction, multi-agent collaboration, and domain expertise integration, aiming to create intelligent applications with professional know-how.

MemoryBear
MemoryBear is a next-generation AI memory system developed by RedBear AI, focusing on overcoming limitations in knowledge storage and multi-agent collaboration. It empowers AI with human-like memory capabilities, enabling deep knowledge understanding and cognitive collaboration. The system addresses challenges such as knowledge forgetting, memory gaps in multi-agent collaboration, and semantic ambiguity during reasoning. MemoryBear's core features include memory extraction engine, graph storage, hybrid search, memory forgetting engine, self-reflection engine, and FastAPI services. It offers a standardized service architecture for efficient integration and invocation across applications.
nocobase
NocoBase is an extensible AI-powered no-code platform that offers total control, infinite extensibility, and AI collaboration. It enables teams to adapt quickly and reduce costs without the need for years of development or wasted resources. With NocoBase, users can deploy the platform in minutes and have complete control over their projects. The platform is data model-driven, allowing for unlimited possibilities by decoupling UI and data structure. It integrates AI capabilities seamlessly into business systems, enabling roles such as translator, analyst, researcher, or assistant. NocoBase provides a simple and intuitive user experience with a 'what you see is what you get' approach. It is designed for extension through its plugin-based architecture, allowing users to customize and extend functionalities easily.

ianvs
Ianvs is a distributed synergy AI benchmarking project incubated in KubeEdge SIG AI. It aims to test the performance of distributed synergy AI solutions following recognized standards, providing end-to-end benchmark toolkits, test environment management tools, test case control tools, and benchmark presentation tools. It also collaborates with other organizations to establish comprehensive benchmarks and related applications. The architecture includes critical components like Test Environment Manager, Test Case Controller, Generation Assistant, Simulation Controller, and Story Manager. Ianvs documentation covers quick start, guides, dataset descriptions, algorithms, user interfaces, stories, and roadmap.

agentUniverse
agentUniverse is a framework for developing applications powered by multi-agent based on large language model. It provides essential components for building single agent and multi-agent collaboration mechanism for customizing collaboration patterns. Developers can easily construct multi-agent applications and share pattern practices from different fields. The framework includes pre-installed collaboration patterns like PEER and DOE for complex task breakdown and data-intensive tasks.
AI.Labs
AI.Labs is an open-source project that integrates advanced artificial intelligence technologies to create a powerful AI platform. It focuses on integrating AI services like large language models, speech recognition, and speech synthesis for functionalities such as dialogue, voice interaction, and meeting transcription. The project also includes features like a large language model dialogue system, speech recognition for meeting transcription, speech-to-text voice synthesis, integration of translation and chat, and uses technologies like C#, .Net, SQLite database, XAF, OpenAI API, TTS, and STT.

kaapana
Kaapana is an open-source toolkit for state-of-the-art platform provisioning in the field of medical data analysis. The applications comprise AI-based workflows and federated learning scenarios with a focus on radiological and radiotherapeutic imaging. Obtaining large amounts of medical data necessary for developing and training modern machine learning methods is an extremely challenging effort that often fails in a multi-center setting, e.g. due to technical, organizational and legal hurdles. A federated approach where the data remains under the authority of the individual institutions and is only processed on-site is, in contrast, a promising approach ideally suited to overcome these difficulties. Following this federated concept, the goal of Kaapana is to provide a framework and a set of tools for sharing data processing algorithms, for standardized workflow design and execution as well as for performing distributed method development. This will facilitate data analysis in a compliant way enabling researchers and clinicians to perform large-scale multi-center studies. By adhering to established standards and by adopting widely used open technologies for private cloud development and containerized data processing, Kaapana integrates seamlessly with the existing clinical IT infrastructure, such as the Picture Archiving and Communication System (PACS), and ensures modularity and easy extensibility.
btp-cap-genai-rag
This GitHub repository provides support for developers, partners, and customers to create advanced GenAI solutions on SAP Business Technology Platform (SAP BTP) following the Reference Architecture. It includes examples on integrating Foundation Models and Large Language Models via Generative AI Hub, using LangChain in CAP, and implementing advanced techniques like Retrieval Augmented Generation (RAG) through embeddings and SAP HANA Cloud's Vector Engine for enhanced value in customer support scenarios.

NeMo
NVIDIA NeMo Framework is a scalable and cloud-native generative AI framework built for researchers and PyTorch developers working on Large Language Models (LLMs), Multimodal Models (MMs), Automatic Speech Recognition (ASR), Text to Speech (TTS), and Computer Vision (CV) domains. It is designed to help you efficiently create, customize, and deploy new generative AI models by leveraging existing code and pre-trained model checkpoints.
For similar tasks
aiogram-django-template
Aiogram & Django API Template is a robust and secure Django template with advanced features like Docker integration, Celery for asynchronous tasks, Sentry for error tracking, Django Rest Framework for building APIs, and more. It provides scalability options, up-to-date dependencies, and integration with AWS S3 for storage. The template includes configuration guides for secrets, ports, performance tuning, application settings, CORS and CSRF settings, and database configuration. Security, scalability, and monitoring are emphasized for efficient Django API development.

modus
Modus is an open-source, serverless framework for building APIs powered by WebAssembly. It simplifies integrating AI models, data, and business logic with sandboxed execution. Modus extracts metadata, compiles code with optimizations, caches compiled modules, prepares invocation plans, generates API schema, and activates endpoints. Users query the endpoint, and Modus loads compiled code into a sandboxed environment, runs code securely, queries data and AI models, and responds via API. It provides a production-ready scalable endpoint for AI-enabled apps, optimized for sub-second response times. Modus supports programming languages like AssemblyScript and Go, and can be hosted on Hypermode or any platform. Developed by Hypermode as an open-source project, Modus welcomes external contributions.
interaqt
Interaqt is a project that aims to separate application business logic from its specific implementation by providing a structured data model and tools to automatically decide and implement software architecture. It liberates individuals and teams from implementation specifics, performance requirements, and cost demands, allowing them to focus on articulating business logic. The approach is considered optimal in the era of large language models (LLMs) as it eliminates uncertainty in generated systems and enables independence from engineering involvement unless specific capabilities are required.

minio
MinIO is a High Performance Object Storage released under GNU Affero General Public License v3.0. It is API compatible with Amazon S3 cloud storage service. Use MinIO to build high performance infrastructure for machine learning, analytics and application data workloads.

airbyte
Airbyte is an open-source data integration platform that makes it easy to move data from any source to any destination. With Airbyte, you can build and manage data pipelines without writing any code. Airbyte provides a library of pre-built connectors that make it easy to connect to popular data sources and destinations. You can also create your own connectors using Airbyte's no-code Connector Builder or low-code CDK. Airbyte is used by data engineers and analysts at companies of all sizes to build and manage their data pipelines.

labelbox-python
Labelbox is a data-centric AI platform for enterprises to develop, optimize, and use AI to solve problems and power new products and services. Enterprises use Labelbox to curate data, generate high-quality human feedback data for computer vision and LLMs, evaluate model performance, and automate tasks by combining AI and human-centric workflows. The academic & research community uses Labelbox for cutting-edge AI research.

telemetry-airflow
This repository codifies the Airflow cluster that is deployed at workflow.telemetry.mozilla.org (behind SSO) and commonly referred to as "WTMO" or simply "Airflow". Some links relevant to users and developers of WTMO: * The `dags` directory in this repository contains some custom DAG definitions * Many of the DAGs registered with WTMO don't live in this repository, but are instead generated from ETL task definitions in bigquery-etl * The Data SRE team maintains a WTMO Developer Guide (behind SSO)

fasttrackml
FastTrackML is an experiment tracking server focused on speed and scalability, fully compatible with MLFlow. It provides a user-friendly interface to track and visualize your machine learning experiments, making it easy to compare different models and identify the best performing ones. FastTrackML is open source and can be easily installed and run with pip or Docker. It is also compatible with the MLFlow Python package, making it easy to integrate with your existing MLFlow workflows.
For similar jobs

db2rest
DB2Rest is a modern low-code REST DATA API platform that simplifies the development of intelligent applications. It seamlessly integrates existing and new databases with language models (LMs/LLMs) and vector stores, enabling the rapid delivery of context-aware, reasoning applications without vendor lock-in.

kitops
KitOps is a packaging and versioning system for AI/ML projects that uses open standards so it works with the AI/ML, development, and DevOps tools you are already using. KitOps simplifies the handoffs between data scientists, application developers, and SREs working with LLMs and other AI/ML models. KitOps' ModelKits are a standards-based package for models, their dependencies, configurations, and codebases. ModelKits are portable, reproducible, and work with the tools you already use.
kweaver
KWeaver is an open-source cognitive intelligence development framework that provides data scientists, application developers, and domain experts with the ability for rapid development, comprehensive openness, and high-performance knowledge network generation and cognitive intelligence large model framework. It offers features such as automated and visual knowledge graph construction, visualization and analysis of knowledge graph data, knowledge graph integration, knowledge graph resource management, large model prompt engineering and debugging, and visual configuration for large model access.
honey
Bee is an ORM framework that provides easy and high-efficiency database operations, allowing developers to focus on business logic development. It supports various databases and features like automatic filtering, partial field queries, pagination, and JSON format results. Bee also offers advanced functionalities like sharding, transactions, complex queries, and MongoDB ORM. The tool is designed for rapid application development in Java, offering faster development for Java Web and Spring Cloud microservices. The Enterprise Edition provides additional features like financial computing support, automatic value insertion, desensitization, dictionary value conversion, multi-tenancy, and more.
moxin
Moxin is an AI LLM client written in Rust to demonstrate the functionality of the Robius framework for multi-platform application development. It is currently in early stages of development and not fully functional. The tool supports building and running on macOS and Linux systems, with packaging options available for distribution. Users can install the required WasmEdge WASM runtime and dependencies to build and run Moxin. Packaging for distribution includes generating `.deb` Debian packages, AppImage, and pacman installation packages for Linux, as well as `.app` bundles and `.dmg` disk images for macOS. The macOS app is not signed, leading to a warning on installation, which can be resolved by removing the quarantine attribute from the installed app.

choco-builder
ChocoBuilder (aka Chocolate Factory) is an open-source LLM application development framework designed to help you easily create powerful software development SDLC + LLM generation assistants. It provides modules for integration into JVM projects, usage with RAGScript, and local deployment examples. ChocoBuilder follows a Domain Driven Problem-Solving design philosophy with key concepts like ProblemClarifier, ProblemAnalyzer, SolutionDesigner, SolutionReviewer, and SolutionExecutor. It offers use cases for desktop/IDE, server, and Android applications, with examples for frontend design, semantic code search, testcase generation, and code interpretation.
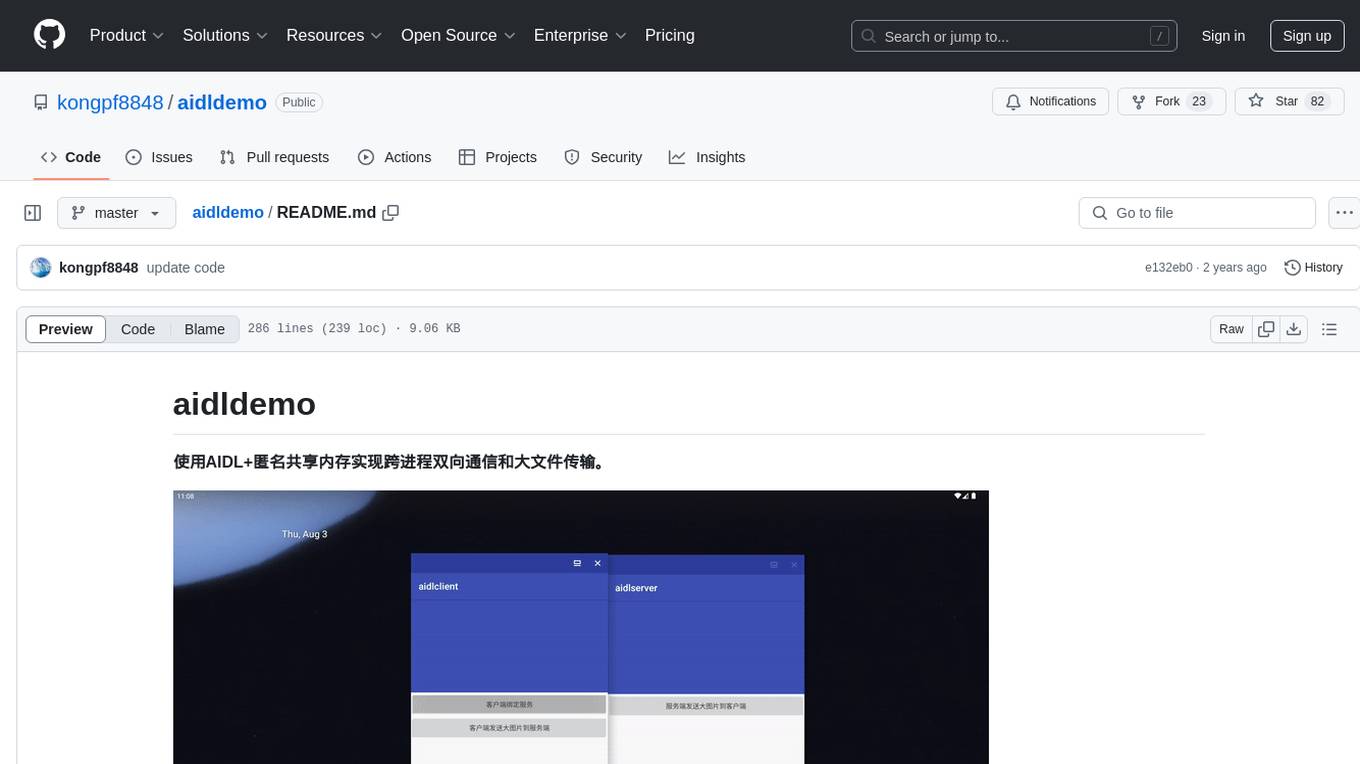
aidldemo
This repository demonstrates how to achieve cross-process bidirectional communication and large file transfer using AIDL and anonymous shared memory. AIDL is a way to implement Inter-Process Communication in Android, based on Binder. To overcome the data size limit of Binder, anonymous shared memory is used for large file transfer. Shared memory allows processes to share memory by mapping a common memory area into their respective process spaces. While efficient for transferring large data between processes, shared memory lacks synchronization mechanisms, requiring additional mechanisms like semaphores. Android's anonymous shared memory (Ashmem) is based on Linux shared memory and facilitates shared memory transfer using Binder and FileDescriptor. The repository provides practical examples of bidirectional communication and large file transfer between client and server using AIDL interfaces and MemoryFile in Android.

cube
Cube is a semantic layer for building data applications, helping data engineers and application developers access data from modern data stores, organize it into consistent definitions, and deliver it to every application. It works with SQL-enabled data sources, providing sub-second latency and high concurrency for API requests. Cube addresses SQL code organization, performance, and access control issues in data applications, enabling efficient data modeling, access control, and performance optimizations for various tools like embedded analytics, dashboarding, reporting, and data notebooks.