
autogen
A programming framework for agentic AI 🤖 PyPi: autogen-agentchat Discord: https://aka.ms/autogen-discord Office Hour: https://aka.ms/autogen-officehour
Stars: 49736

AutoGen is a framework that enables the development of LLM applications using multiple agents that can converse with each other to solve tasks. AutoGen agents are customizable, conversable, and seamlessly allow human participation. They can operate in various modes that employ combinations of LLMs, human inputs, and tools.
README:


AutoGen is a framework for creating multi-agent AI applications that can act autonomously or work alongside humans.
AutoGen requires Python 3.10 or later.
# Install AgentChat and OpenAI client from Extensions
pip install -U "autogen-agentchat" "autogen-ext[openai]"The current stable version can be found in the releases. If you are upgrading from AutoGen v0.2, please refer to the Migration Guide for detailed instructions on how to update your code and configurations.
# Install AutoGen Studio for no-code GUI
pip install -U "autogenstudio"Create an assistant agent using OpenAI's GPT-4o model. See other supported models.
import asyncio
from autogen_agentchat.agents import AssistantAgent
from autogen_ext.models.openai import OpenAIChatCompletionClient
async def main() -> None:
model_client = OpenAIChatCompletionClient(model="gpt-4.1")
agent = AssistantAgent("assistant", model_client=model_client)
print(await agent.run(task="Say 'Hello World!'"))
await model_client.close()
asyncio.run(main())Create a web browsing assistant agent that uses the Playwright MCP server.
# First run `npm install -g @playwright/mcp@latest` to install the MCP server.
import asyncio
from autogen_agentchat.agents import AssistantAgent
from autogen_agentchat.ui import Console
from autogen_ext.models.openai import OpenAIChatCompletionClient
from autogen_ext.tools.mcp import McpWorkbench, StdioServerParams
async def main() -> None:
model_client = OpenAIChatCompletionClient(model="gpt-4.1")
server_params = StdioServerParams(
command="npx",
args=[
"@playwright/mcp@latest",
"--headless",
],
)
async with McpWorkbench(server_params) as mcp:
agent = AssistantAgent(
"web_browsing_assistant",
model_client=model_client,
workbench=mcp, # For multiple MCP servers, put them in a list.
model_client_stream=True,
max_tool_iterations=10,
)
await Console(agent.run_stream(task="Find out how many contributors for the microsoft/autogen repository"))
asyncio.run(main())Warning: Only connect to trusted MCP servers as they may execute commands in your local environment or expose sensitive information.
You can use AgentTool to create a basic multi-agent orchestration setup.
import asyncio
from autogen_agentchat.agents import AssistantAgent
from autogen_agentchat.tools import AgentTool
from autogen_agentchat.ui import Console
from autogen_ext.models.openai import OpenAIChatCompletionClient
async def main() -> None:
model_client = OpenAIChatCompletionClient(model="gpt-4.1")
math_agent = AssistantAgent(
"math_expert",
model_client=model_client,
system_message="You are a math expert.",
description="A math expert assistant.",
model_client_stream=True,
)
math_agent_tool = AgentTool(math_agent, return_value_as_last_message=True)
chemistry_agent = AssistantAgent(
"chemistry_expert",
model_client=model_client,
system_message="You are a chemistry expert.",
description="A chemistry expert assistant.",
model_client_stream=True,
)
chemistry_agent_tool = AgentTool(chemistry_agent, return_value_as_last_message=True)
agent = AssistantAgent(
"assistant",
system_message="You are a general assistant. Use expert tools when needed.",
model_client=model_client,
model_client_stream=True,
tools=[math_agent_tool, chemistry_agent_tool],
max_tool_iterations=10,
)
await Console(agent.run_stream(task="What is the integral of x^2?"))
await Console(agent.run_stream(task="What is the molecular weight of water?"))
asyncio.run(main())For more advanced multi-agent orchestrations and workflows, read AgentChat documentation.
Use AutoGen Studio to prototype and run multi-agent workflows without writing code.
# Run AutoGen Studio on http://localhost:8080
autogenstudio ui --port 8080 --appdir ./my-app
The AutoGen ecosystem provides everything you need to create AI agents, especially multi-agent workflows -- framework, developer tools, and applications.
The framework uses a layered and extensible design. Layers have clearly divided responsibilities and build on top of layers below. This design enables you to use the framework at different levels of abstraction, from high-level APIs to low-level components.
- Core API implements message passing, event-driven agents, and local and distributed runtime for flexibility and power. It also support cross-language support for .NET and Python.
- AgentChat API implements a simpler but opinionated API for rapid prototyping. This API is built on top of the Core API and is closest to what users of v0.2 are familiar with and supports common multi-agent patterns such as two-agent chat or group chats.
- Extensions API enables first- and third-party extensions continuously expanding framework capabilities. It support specific implementation of LLM clients (e.g., OpenAI, AzureOpenAI), and capabilities such as code execution.
The ecosystem also supports two essential developer tools:
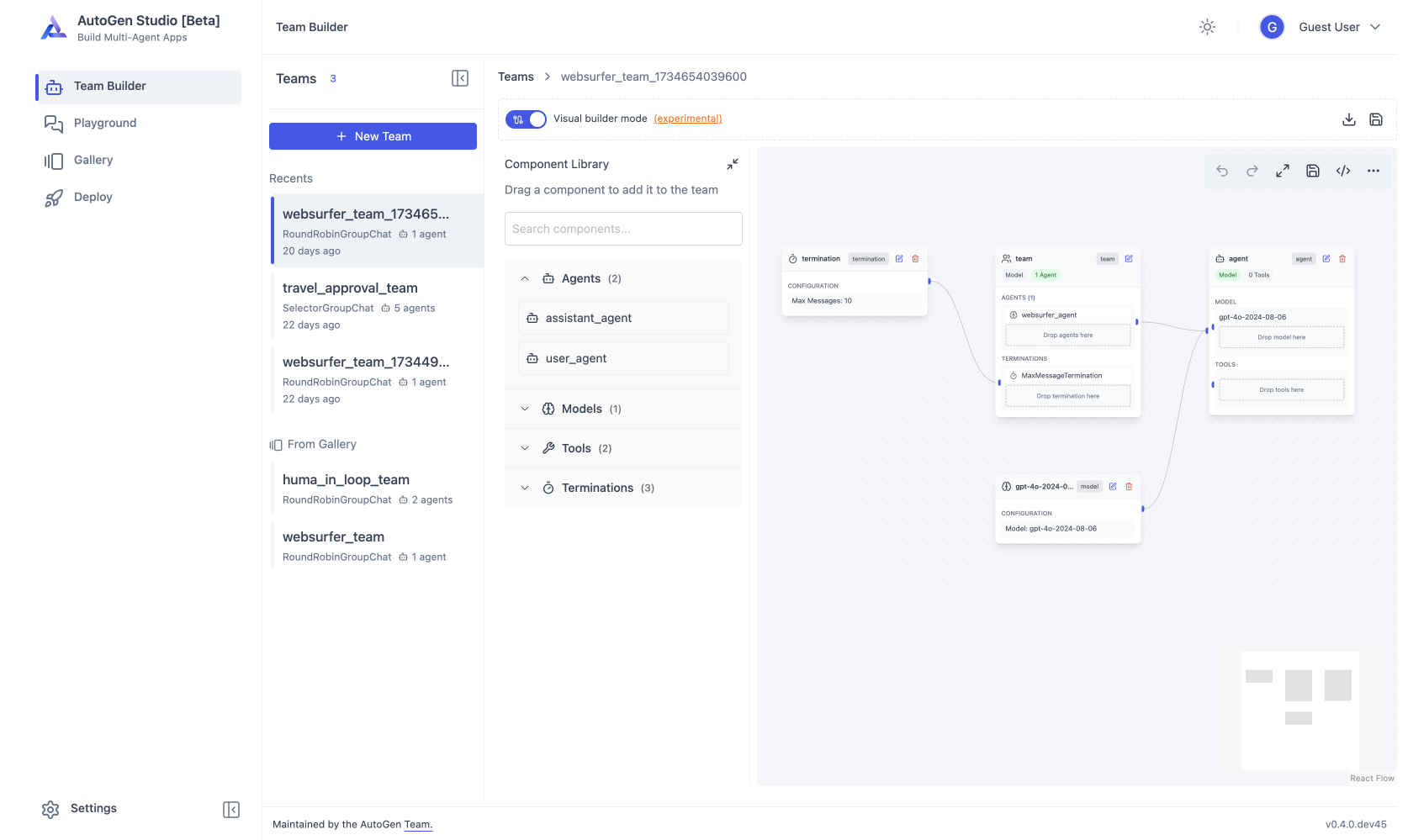
- AutoGen Studio provides a no-code GUI for building multi-agent applications.
- AutoGen Bench provides a benchmarking suite for evaluating agent performance.
You can use the AutoGen framework and developer tools to create applications for your domain. For example, Magentic-One is a state-of-the-art multi-agent team built using AgentChat API and Extensions API that can handle a variety of tasks that require web browsing, code execution, and file handling.
With AutoGen you get to join and contribute to a thriving ecosystem. We host weekly office hours and talks with maintainers and community. We also have a Discord server for real-time chat, GitHub Discussions for Q&A, and a blog for tutorials and updates.
| Installation | |||
| Quickstart | |||
| Tutorial | |||
| API Reference | |||
| Packages |
|
|
Interested in contributing? See CONTRIBUTING.md for guidelines on how to get started. We welcome contributions of all kinds, including bug fixes, new features, and documentation improvements. Join our community and help us make AutoGen better!
Have questions? Check out our Frequently Asked Questions (FAQ) for answers to common queries. If you don't find what you're looking for, feel free to ask in our GitHub Discussions or join our Discord server for real-time support. You can also read our blog for updates.
Microsoft and any contributors grant you a license to the Microsoft documentation and other content in this repository under the Creative Commons Attribution 4.0 International Public License, see the LICENSE file, and grant you a license to any code in the repository under the MIT License, see the LICENSE-CODE file.
Microsoft, Windows, Microsoft Azure, and/or other Microsoft products and services referenced in the documentation may be either trademarks or registered trademarks of Microsoft in the United States and/or other countries. The licenses for this project do not grant you rights to use any Microsoft names, logos, or trademarks. Microsoft's general trademark guidelines can be found at http://go.microsoft.com/fwlink/?LinkID=254653.
Privacy information can be found at https://go.microsoft.com/fwlink/?LinkId=521839
Microsoft and any contributors reserve all other rights, whether under their respective copyrights, patents, or trademarks, whether by implication, estoppel, or otherwise.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for autogen
Similar Open Source Tools
autogen
AutoGen is a framework that enables the development of LLM applications using multiple agents that can converse with each other to solve tasks. AutoGen agents are customizable, conversable, and seamlessly allow human participation. They can operate in various modes that employ combinations of LLMs, human inputs, and tools.

Scrapegraph-ai
ScrapeGraphAI is a web scraping Python library that utilizes LLM and direct graph logic to create scraping pipelines for websites and local documents. It offers various standard scraping pipelines like SmartScraperGraph, SearchGraph, SpeechGraph, and ScriptCreatorGraph. Users can extract information by specifying prompts and input sources. The library supports different LLM APIs such as OpenAI, Groq, Azure, and Gemini, as well as local models using Ollama. ScrapeGraphAI is designed for data exploration and research purposes, providing a versatile tool for extracting information from web pages and generating outputs like Python scripts, audio summaries, and search results.
TEN-Agent
TEN Agent is an open-source multimodal agent powered by the world’s first real-time multimodal framework, TEN Framework. It offers high-performance real-time multimodal interactions, multi-language and multi-platform support, edge-cloud integration, flexibility beyond model limitations, and real-time agent state management. Users can easily build complex AI applications through drag-and-drop programming, integrating audio-visual tools, databases, RAG, and more.
modelscope-agent
ModelScope-Agent is a customizable and scalable Agent framework. A single agent has abilities such as role-playing, LLM calling, tool usage, planning, and memory. It mainly has the following characteristics: - **Simple Agent Implementation Process**: Simply specify the role instruction, LLM name, and tool name list to implement an Agent application. The framework automatically arranges workflows for tool usage, planning, and memory. - **Rich models and tools**: The framework is equipped with rich LLM interfaces, such as Dashscope and Modelscope model interfaces, OpenAI model interfaces, etc. Built in rich tools, such as **code interpreter**, **weather query**, **text to image**, **web browsing**, etc., make it easy to customize exclusive agents. - **Unified interface and high scalability**: The framework has clear tools and LLM registration mechanism, making it convenient for users to expand more diverse Agent applications. - **Low coupling**: Developers can easily use built-in tools, LLM, memory, and other components without the need to bind higher-level agents.

tidb
TiDB is an open-source distributed SQL database that supports Hybrid Transactional and Analytical Processing (HTAP) workloads. It is MySQL compatible and features horizontal scalability, strong consistency, and high availability.

screenpipe
24/7 Screen & Audio Capture Library to build personalized AI powered by what you've seen, said, or heard. Works with Ollama. Alternative to Rewind.ai. Open. Secure. You own your data. Rust. We are shipping daily, make suggestions, post bugs, give feedback. Building a reliable stream of audio and screenshot data, simplifying life for developers by solving non-trivial problems. Multiple installation options available. Experimental tool with various integrations and features for screen and audio capture, OCR, STT, and more. Open source project focused on enabling tooling & infrastructure for a wide range of applications.

FAV0
FAV0 Weekly is a repository that records weekly updates on front-end, AI, and computer-related content. It provides light and dark mode switching, bilingual interface, RSS subscription function, Giscus comment system, high-definition image preview, font settings customization, and SEO optimization. Users can stay updated with the latest weekly releases by starring/watching the repository. The repository is dual-licensed under the MIT License and CC-BY-4.0 License.

aimeos
Aimeos is a full-featured e-commerce platform that is ultra-fast, cloud-native, and API-first. It offers a wide range of features including JSON REST API, GraphQL API, multi-vendor support, various product types, subscriptions, multiple payment gateways, admin backend, modular structure, SEO optimization, multi-language support, AI-based text translation, mobile optimization, and high-quality source code. It is highly configurable and extensible, making it suitable for e-commerce SaaS solutions, marketplaces, and various cloud environments. Aimeos is designed for scalability, security, and performance, catering to a diverse range of e-commerce needs.
llama-assistant
Llama Assistant is an AI-powered assistant that helps with daily tasks, such as voice recognition, natural language processing, summarizing text, rephrasing sentences, answering questions, and more. It runs offline on your local machine, ensuring privacy by not sending data to external servers. The project is a work in progress with regular feature additions.

liboai
liboai is a simple C++17 library for the OpenAI API, providing developers with access to OpenAI endpoints through a collection of methods and classes. It serves as a spiritual port of OpenAI's Python library, 'openai', with similar structure and features. The library supports various functionalities such as ChatGPT, Audio, Azure, Functions, Image DALL·E, Models, Completions, Edit, Embeddings, Files, Fine-tunes, Moderation, and Asynchronous Support. Users can easily integrate the library into their C++ projects to interact with OpenAI services.
incubator-kie-optaplanner
A fast, easy-to-use, open source AI constraint solver for software developers. OptaPlanner is a powerful tool that helps developers solve complex optimization problems by providing a constraint satisfaction solver. It allows users to model and solve planning and scheduling problems efficiently, improving decision-making processes and resource allocation. With OptaPlanner, developers can easily integrate optimization capabilities into their applications, leading to better performance and cost-effectiveness.
omnihuman
OmniHuman is an AI model designed to understand humanoids and text. It provides functionalities to process images and videos, generating text descriptions for human actions depicted in the visual content. The tool offers support for various tasks related to human pose recognition and action understanding. Users can easily integrate OmniHuman into their projects to enhance the capabilities of their applications in recognizing and interpreting human actions in images and videos.

fiftyone
FiftyOne is an open-source tool designed for building high-quality datasets and computer vision models. It supercharges machine learning workflows by enabling users to visualize datasets, interpret models faster, and improve efficiency. With FiftyOne, users can explore scenarios, identify failure modes, visualize complex labels, evaluate models, find annotation mistakes, and much more. The tool aims to streamline the process of improving machine learning models by providing a comprehensive set of features for data analysis and model interpretation.
lemonade
Lemonade is a tool that helps users run local Large Language Models (LLMs) with high performance by configuring state-of-the-art inference engines for their Neural Processing Units (NPUs) and Graphics Processing Units (GPUs). It is used by startups, research teams, and large companies to run LLMs efficiently. Lemonade provides a high-level Python API for direct integration of LLMs into Python applications and a CLI for mixing and matching LLMs with various features like prompting templates, accuracy testing, performance benchmarking, and memory profiling. The tool supports both GGUF and ONNX models and allows importing custom models from Hugging Face using the Model Manager. Lemonade is designed to be easy to use and switch between different configurations at runtime, making it a versatile tool for running LLMs locally.
llama-assistant
Llama Assistant is a local AI assistant that respects your privacy. It is an AI-powered assistant that can recognize your voice, process natural language, and perform various actions based on your commands. It can help with tasks like summarizing text, rephrasing sentences, answering questions, writing emails, and more. The assistant runs offline on your local machine, ensuring privacy by not sending data to external servers. It supports voice recognition, natural language processing, and customizable UI with adjustable transparency. The project is a work in progress with new features being added regularly.
RWKV-Runner
RWKV Runner is a project designed to simplify the usage of large language models by automating various processes. It provides a lightweight executable program and is compatible with the OpenAI API. Users can deploy the backend on a server and use the program as a client. The project offers features like model management, VRAM configurations, user-friendly chat interface, WebUI option, parameter configuration, model conversion tool, download management, LoRA Finetune, and multilingual localization. It can be used for various tasks such as chat, completion, composition, and model inspection.
For similar tasks
autogen
AutoGen is a framework that enables the development of LLM applications using multiple agents that can converse with each other to solve tasks. AutoGen agents are customizable, conversable, and seamlessly allow human participation. They can operate in various modes that employ combinations of LLMs, human inputs, and tools.

tracecat
Tracecat is an open-source automation platform for security teams. It's designed to be simple but powerful, with a focus on AI features and a practitioner-obsessed UI/UX. Tracecat can be used to automate a variety of tasks, including phishing email investigation, evidence collection, and remediation plan generation.

ciso-assistant-community
CISO Assistant is a tool that helps organizations manage their cybersecurity posture and compliance. It provides a centralized platform for managing security controls, threats, and risks. CISO Assistant also includes a library of pre-built frameworks and tools to help organizations quickly and easily implement best practices.

ck
Collective Mind (CM) is a collection of portable, extensible, technology-agnostic and ready-to-use automation recipes with a human-friendly interface (aka CM scripts) to unify and automate all the manual steps required to compose, run, benchmark and optimize complex ML/AI applications on any platform with any software and hardware: see online catalog and source code. CM scripts require Python 3.7+ with minimal dependencies and are continuously extended by the community and MLCommons members to run natively on Ubuntu, MacOS, Windows, RHEL, Debian, Amazon Linux and any other operating system, in a cloud or inside automatically generated containers while keeping backward compatibility - please don't hesitate to report encountered issues here and contact us via public Discord Server to help this collaborative engineering effort! CM scripts were originally developed based on the following requirements from the MLCommons members to help them automatically compose and optimize complex MLPerf benchmarks, applications and systems across diverse and continuously changing models, data sets, software and hardware from Nvidia, Intel, AMD, Google, Qualcomm, Amazon and other vendors: * must work out of the box with the default options and without the need to edit some paths, environment variables and configuration files; * must be non-intrusive, easy to debug and must reuse existing user scripts and automation tools (such as cmake, make, ML workflows, python poetry and containers) rather than substituting them; * must have a very simple and human-friendly command line with a Python API and minimal dependencies; * must require minimal or zero learning curve by using plain Python, native scripts, environment variables and simple JSON/YAML descriptions instead of inventing new workflow languages; * must have the same interface to run all automations natively, in a cloud or inside containers. CM scripts were successfully validated by MLCommons to modularize MLPerf inference benchmarks and help the community automate more than 95% of all performance and power submissions in the v3.1 round across more than 120 system configurations (models, frameworks, hardware) while reducing development and maintenance costs.

zenml
ZenML is an extensible, open-source MLOps framework for creating portable, production-ready machine learning pipelines. By decoupling infrastructure from code, ZenML enables developers across your organization to collaborate more effectively as they develop to production.

clearml
ClearML is a suite of tools designed to streamline the machine learning workflow. It includes an experiment manager, MLOps/LLMOps, data management, and model serving capabilities. ClearML is open-source and offers a free tier hosting option. It supports various ML/DL frameworks and integrates with Jupyter Notebook and PyCharm. ClearML provides extensive logging capabilities, including source control info, execution environment, hyper-parameters, and experiment outputs. It also offers automation features, such as remote job execution and pipeline creation. ClearML is designed to be easy to integrate, requiring only two lines of code to add to existing scripts. It aims to improve collaboration, visibility, and data transparency within ML teams.
devchat
DevChat is an open-source workflow engine that enables developers to create intelligent, automated workflows for engaging with users through a chat panel within their IDEs. It combines script writing flexibility, latest AI models, and an intuitive chat GUI to enhance user experience and productivity. DevChat simplifies the integration of AI in software development, unlocking new possibilities for developers.

LLM-Finetuning-Toolkit
LLM Finetuning toolkit is a config-based CLI tool for launching a series of LLM fine-tuning experiments on your data and gathering their results. It allows users to control all elements of a typical experimentation pipeline - prompts, open-source LLMs, optimization strategy, and LLM testing - through a single YAML configuration file. The toolkit supports basic, intermediate, and advanced usage scenarios, enabling users to run custom experiments, conduct ablation studies, and automate fine-tuning workflows. It provides features for data ingestion, model definition, training, inference, quality assurance, and artifact outputs, making it a comprehensive tool for fine-tuning large language models.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

agentcloud
AgentCloud is an open-source platform that enables companies to build and deploy private LLM chat apps, empowering teams to securely interact with their data. It comprises three main components: Agent Backend, Webapp, and Vector Proxy. To run this project locally, clone the repository, install Docker, and start the services. The project is licensed under the GNU Affero General Public License, version 3 only. Contributions and feedback are welcome from the community.

oss-fuzz-gen
This framework generates fuzz targets for real-world `C`/`C++` projects with various Large Language Models (LLM) and benchmarks them via the `OSS-Fuzz` platform. It manages to successfully leverage LLMs to generate valid fuzz targets (which generate non-zero coverage increase) for 160 C/C++ projects. The maximum line coverage increase is 29% from the existing human-written targets.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

Azure-Analytics-and-AI-Engagement
The Azure-Analytics-and-AI-Engagement repository provides packaged Industry Scenario DREAM Demos with ARM templates (Containing a demo web application, Power BI reports, Synapse resources, AML Notebooks etc.) that can be deployed in a customer’s subscription using the CAPE tool within a matter of few hours. Partners can also deploy DREAM Demos in their own subscriptions using DPoC.