
beta9
Ultrafast serverless GPU inference, sandboxes, and background jobs
Stars: 1313
Beta9 is an open-source platform for running scalable serverless GPU workloads across cloud providers. It allows users to scale out workloads to thousands of GPU or CPU containers, achieve ultrafast cold-start for custom ML models, automatically scale to zero to pay for only what is used, utilize flexible distributed storage, distribute workloads across multiple cloud providers, and easily deploy task queues and functions using simple Python abstractions. The platform is designed for launching remote serverless containers quickly, featuring a custom, lazy loading image format backed by S3/FUSE, a fast redis-based container scheduling engine, content-addressed storage for caching images and files, and a custom runc container runtime.
README:


Beam is a fast, open-source runtime for serverless AI workloads. It gives you a Pythonic interface to deploy and scale AI applications with zero infrastructure overhead.

- Fast Image Builds: Launch containers in under a second using a custom container runtime
- Parallelization and Concurrency: Fan out workloads to 100s of containers
- First-Class Developer Experience: Hot-reloading, webhooks, and scheduled jobs
- Scale-to-Zero: Workloads are serverless by default
- Volume Storage: Mount distributed storage volumes
- GPU Support: Run on our cloud (4090s, H100s, and more) or bring your own GPUs
pip install beam-client- Create an account here
- Follow our Getting Started Guide
Spin up isolated containers to run LLM-generated code:
from beam import Image, Sandbox
sandbox = Sandbox(image=Image()).create()
response = sandbox.process.run_code("print('I am running remotely')")
print(response.result)Create an autoscaling endpoint for your custom model:
from beam import Image, endpoint
from beam import QueueDepthAutoscaler
@endpoint(
image=Image(python_version="python3.11"),
gpu="A10G",
cpu=2,
memory="16Gi",
autoscaler=QueueDepthAutoscaler(max_containers=5, tasks_per_container=30)
)
def handler():
return {"label": "cat", "confidence": 0.97}Schedule resilient background tasks (or replace your Celery queue) by adding a simple decorator:
from beam import Image, TaskPolicy, schema, task_queue
class Input(schema.Schema):
image_url = schema.String()
@task_queue(
name="image-processor",
image=Image(python_version="python3.11"),
cpu=1,
memory=1024,
inputs=Input,
task_policy=TaskPolicy(max_retries=3),
)
def my_background_task(input: Input, *, context):
image_url = input.image_url
print(f"Processing image: {image_url}")
return {"image_url": image_url}
if __name__ == "__main__":
# Invoke a background task from your app (without deploying it)
my_background_task.put(image_url="https://example.com/image.jpg")
# You can also deploy this behind a versioned endpoint with:
# beam deploy app.py:my_background_task --name image-processorBeta9 is the open-source engine powering Beam, our fully-managed cloud platform. You can self-host Beta9 for free or choose managed cloud hosting through Beam.
We welcome contributions big or small. These are the most helpful things for us:
- Submit a feature request or bug report
- Open a PR with a new feature or improvement
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for beta9
Similar Open Source Tools
beta9
Beta9 is an open-source platform for running scalable serverless GPU workloads across cloud providers. It allows users to scale out workloads to thousands of GPU or CPU containers, achieve ultrafast cold-start for custom ML models, automatically scale to zero to pay for only what is used, utilize flexible distributed storage, distribute workloads across multiple cloud providers, and easily deploy task queues and functions using simple Python abstractions. The platform is designed for launching remote serverless containers quickly, featuring a custom, lazy loading image format backed by S3/FUSE, a fast redis-based container scheduling engine, content-addressed storage for caching images and files, and a custom runc container runtime.

starwhale
Starwhale is an MLOps/LLMOps platform that brings efficiency and standardization to machine learning operations. It streamlines the model development lifecycle, enabling teams to optimize workflows around key areas like model building, evaluation, release, and fine-tuning. Starwhale abstracts Model, Runtime, and Dataset as first-class citizens, providing tailored capabilities for common workflow scenarios including Models Evaluation, Live Demo, and LLM Fine-tuning. It is an open-source platform designed for clarity and ease of use, empowering developers to build customized MLOps features tailored to their needs.
inferable
Inferable is an open source platform that helps users build reliable LLM-powered agentic automations at scale. It offers a managed agent runtime, durable tool calling, zero network configuration, multiple language support, and is fully open source under the MIT license. Users can define functions, register them with Inferable, and create runs that utilize these functions to automate tasks. The platform supports Node.js/TypeScript, Go, .NET, and React, and provides SDKs, core services, and bootstrap templates for various languages.

rl
TorchRL is an open-source Reinforcement Learning (RL) library for PyTorch. It provides pytorch and **python-first** , low and high level abstractions for RL that are intended to be **efficient** , **modular** , **documented** and properly **tested**. The code is aimed at supporting research in RL. Most of it is written in python in a highly modular way, such that researchers can easily swap components, transform them or write new ones with little effort.

preswald
Preswald is a full-stack platform for building, deploying, and managing interactive data applications in Python. It simplifies the process by combining ingestion, storage, transformation, and visualization into one lightweight SDK. With Preswald, users can connect to various data sources, customize app themes, and easily deploy apps locally. The platform focuses on code-first simplicity, end-to-end coverage, and efficiency by design, making it suitable for prototyping internal tools or deploying production-grade apps with reduced complexity and cost.
BubbleLab
Bubble Lab is an open-source agentic workflow automation builder designed for developers seeking full control, transparency, and type safety. It compiles workflows into clean, production-ready TypeScript code that can be debugged and deployed anywhere. With features like natural language prompt to workflow generation, full observability, seamless migration from other platforms, and instant export as TypeScript/API, Bubble Lab offers a flexible and code-centric approach to workflow automation.
rag-chat
The `@upstash/rag-chat` package simplifies the development of retrieval-augmented generation (RAG) chat applications by providing Next.js compatibility with streaming support, built-in vector store, optional Redis compatibility for fast chat history management, rate limiting, and disableRag option. Users can easily set up the environment variables and initialize RAGChat to interact with AI models, manage knowledge base, chat history, and enable debugging features. Advanced configuration options allow customization of RAGChat instance with built-in rate limiting, observability via Helicone, and integration with Next.js route handlers and Vercel AI SDK. The package supports OpenAI models, Upstash-hosted models, and custom providers like TogetherAi and Replicate.
mem0
Mem0 is a tool that provides a smart, self-improving memory layer for Large Language Models, enabling personalized AI experiences across applications. It offers persistent memory for users, sessions, and agents, self-improving personalization, a simple API for easy integration, and cross-platform consistency. Users can store memories, retrieve memories, search for related memories, update memories, get the history of a memory, and delete memories using Mem0. It is designed to enhance AI experiences by enabling long-term memory storage and retrieval.
mobius
Mobius is an AI infra platform including realtime computing and training. It is built on Ray, a distributed computing framework, and provides a number of features that make it well-suited for online machine learning tasks. These features include: * **Cross Language**: Mobius can run in multiple languages (only Python and Java are supported currently) with high efficiency. You can implement your operator in different languages and run them in one job. * **Single Node Failover**: Mobius has a special failover mechanism that only needs to rollback the failed node itself, in most cases, to recover the job. This is a huge benefit if your job is sensitive about failure recovery time. * **AutoScaling**: Mobius can generate a new graph with different configurations in runtime without stopping the job. * **Fusion Training**: Mobius can combine TensorFlow/Pytorch and streaming, then building an e2e online machine learning pipeline. Mobius is still under development, but it has already been used to power a number of real-world applications, including: * A real-time recommendation system for a major e-commerce company * A fraud detection system for a large financial institution * A personalized news feed for a major news organization If you are interested in using Mobius for your own online machine learning projects, you can find more information in the documentation.
kubewall
kubewall is an open-source, single-binary Kubernetes dashboard with multi-cluster management and AI integration. It provides a simple and rich real-time interface to manage and investigate your clusters. With features like multi-cluster management, AI-powered troubleshooting, real-time monitoring, single-binary deployment, in-depth resource views, browser-based access, search and filter capabilities, privacy by default, port forwarding, live refresh, aggregated pod logs, and clean resource management, kubewall offers a comprehensive solution for Kubernetes cluster management.
Ivy-Framework
Ivy-Framework is a powerful tool for building internal applications with AI assistance using C# codebase. It provides a CLI for project initialization, authentication integrations, database support, LLM code generation, secrets management, container deployment, hot reload, dependency injection, state management, routing, and external widget framework. Users can easily create data tables for sorting, filtering, and pagination. The framework offers a seamless integration of front-end and back-end development, making it ideal for developing robust internal tools and dashboards.

chat
deco.chat is an open-source foundation for building AI-native software, providing developers, engineers, and AI enthusiasts with robust tools to rapidly prototype, develop, and deploy AI-powered applications. It empowers Vibecoders to prototype ideas and Agentic engineers to deploy scalable, secure, and sustainable production systems. The core capabilities include an open-source runtime for composing tools and workflows, MCP Mesh for secure integration of models and APIs, a unified TypeScript stack for backend logic and custom frontends, global modular infrastructure built on Cloudflare, and a visual workspace for building agents and orchestrating everything in code.
gpt-computer-assistant
GPT Computer Assistant (GCA) is an open-source framework designed to build vertical AI agents that can automate tasks on Windows, macOS, and Ubuntu systems. It leverages the Model Context Protocol (MCP) and its own modules to mimic human-like actions and achieve advanced capabilities. With GCA, users can empower themselves to accomplish more in less time by automating tasks like updating dependencies, analyzing databases, and configuring cloud security settings.

infinity
Infinity is an AI-native database designed for LLM applications, providing incredibly fast full-text and vector search capabilities. It supports a wide range of data types, including vectors, full-text, and structured data, and offers a fused search feature that combines multiple embeddings and full text. Infinity is easy to use, with an intuitive Python API and a single-binary architecture that simplifies deployment. It achieves high performance, with 0.1 milliseconds query latency on million-scale vector datasets and up to 15K QPS.
sre
SmythOS is an operating system designed for building, deploying, and managing intelligent AI agents at scale. It provides a unified SDK and resource abstraction layer for various AI services, making it easy to scale and flexible. With an agent-first design, developer-friendly SDK, modular architecture, and enterprise security features, SmythOS offers a robust foundation for AI workloads. The system is built with a philosophy inspired by traditional operating system kernels, ensuring autonomy, control, and security for AI agents. SmythOS aims to make shipping production-ready AI agents accessible and open for everyone in the coming Internet of Agents era.
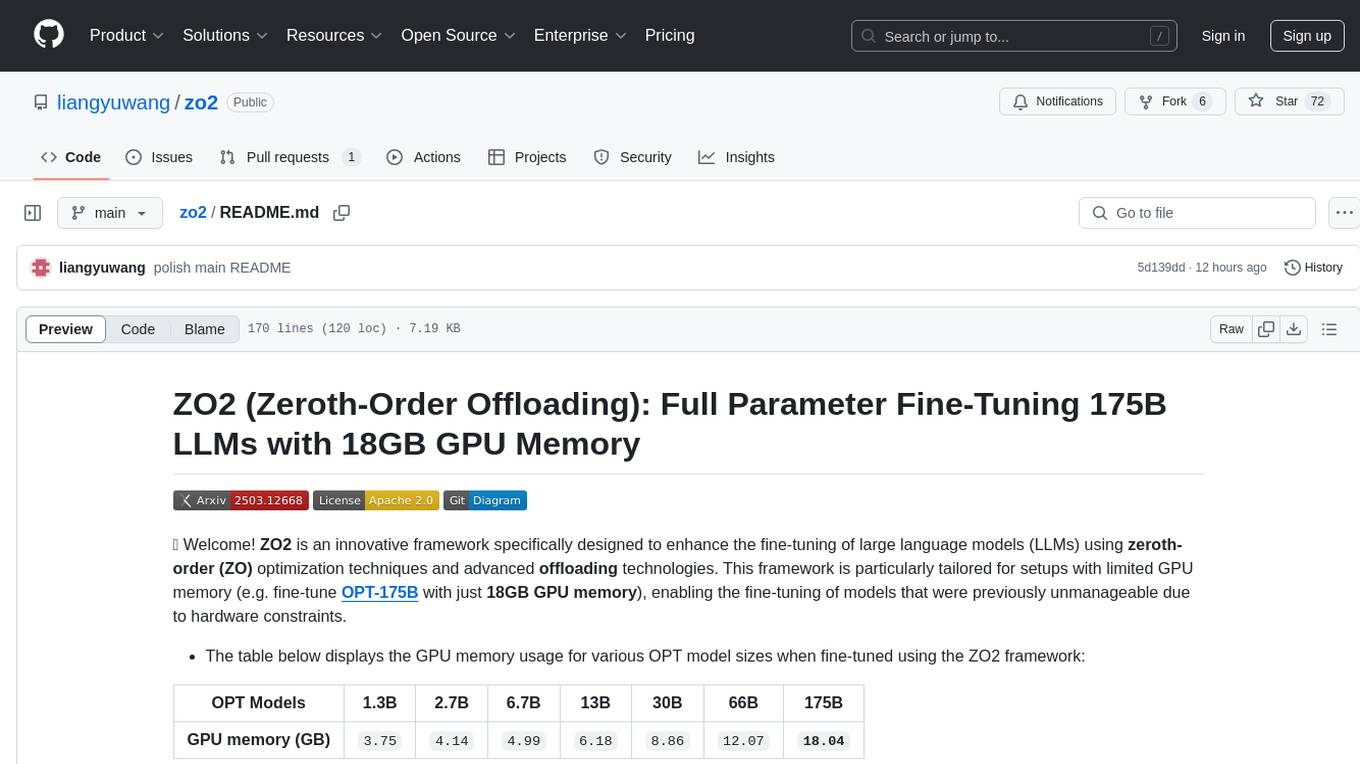
zo2
ZO2 (Zeroth-Order Offloading) is an innovative framework designed to enhance the fine-tuning of large language models (LLMs) using zeroth-order (ZO) optimization techniques and advanced offloading technologies. It is tailored for setups with limited GPU memory, enabling the fine-tuning of models with over 175 billion parameters on single GPUs with as little as 18GB of memory. ZO2 optimizes CPU offloading, incorporates dynamic scheduling, and has the capability to handle very large models efficiently without extra time costs or accuracy losses.
For similar tasks
beta9
Beta9 is an open-source platform for running scalable serverless GPU workloads across cloud providers. It allows users to scale out workloads to thousands of GPU or CPU containers, achieve ultrafast cold-start for custom ML models, automatically scale to zero to pay for only what is used, utilize flexible distributed storage, distribute workloads across multiple cloud providers, and easily deploy task queues and functions using simple Python abstractions. The platform is designed for launching remote serverless containers quickly, featuring a custom, lazy loading image format backed by S3/FUSE, a fast redis-based container scheduling engine, content-addressed storage for caching images and files, and a custom runc container runtime.

Bodo
Bodo is a high-performance Python compute engine designed for large-scale data processing and AI workloads. It utilizes an auto-parallelizing just-in-time compiler to optimize Python programs, making them 20x to 240x faster compared to alternatives. Bodo seamlessly integrates with native Python APIs like Pandas and NumPy, eliminates runtime overheads using MPI for distributed execution, and provides exceptional performance and scalability for data workloads. It is easy to use, interoperable with the Python ecosystem, and integrates with modern data platforms like Apache Iceberg and Snowflake. Bodo focuses on data-intensive and computationally heavy workloads in data engineering, data science, and AI/ML, offering automatic optimization and parallelization, linear scalability, advanced I/O support, and a high-performance SQL engine.
KAI-Scheduler
KAI Scheduler is a robust, efficient, and scalable Kubernetes scheduler optimized for GPU resource allocation in AI and machine learning workloads. It supports batch scheduling, bin packing, spread scheduling, workload priority, hierarchical queues, resource distribution, fairness policies, workload consolidation, elastic workloads, dynamic resource allocation, GPU sharing, and works in both cloud and on-premise environments.
For similar jobs
beta9
Beta9 is an open-source platform for running scalable serverless GPU workloads across cloud providers. It allows users to scale out workloads to thousands of GPU or CPU containers, achieve ultrafast cold-start for custom ML models, automatically scale to zero to pay for only what is used, utilize flexible distributed storage, distribute workloads across multiple cloud providers, and easily deploy task queues and functions using simple Python abstractions. The platform is designed for launching remote serverless containers quickly, featuring a custom, lazy loading image format backed by S3/FUSE, a fast redis-based container scheduling engine, content-addressed storage for caching images and files, and a custom runc container runtime.
3FS
The Fire-Flyer File System (3FS) is a high-performance distributed file system designed for AI training and inference workloads. It leverages modern SSDs and RDMA networks to provide a shared storage layer that simplifies development of distributed applications. Key features include performance, disaggregated architecture, strong consistency, file interfaces, data preparation, dataloaders, checkpointing, and KVCache for inference. The system is well-documented with design notes, setup guide, USRBIO API reference, and P specifications. Performance metrics include peak throughput, GraySort benchmark results, and KVCache optimization. The source code is available on GitHub for cloning and installation of dependencies. Users can build 3FS and run test clusters following the provided instructions. Issues can be reported on the GitHub repository.
genai-factory
GenAI Factory is a collection of end-to-end blueprints to deploy generative AI infrastructures in Google Cloud Platform (GCP), following security best practices. It embraces Infrastructure as Code (IaC) best practices, implements infrastructure in Terraform, and follows the least-privilege principle. The tool is compatible with Cloud Foundation Fabric FAST project-factory and application templates, allowing users to deploy various AI applications and systems on GCP.

AirGo
AirGo is a front and rear end separation, multi user, multi protocol proxy service management system, simple and easy to use. It supports vless, vmess, shadowsocks, and hysteria2.

mosec
Mosec is a high-performance and flexible model serving framework for building ML model-enabled backend and microservices. It bridges the gap between any machine learning models you just trained and the efficient online service API. * **Highly performant** : web layer and task coordination built with Rust 🦀, which offers blazing speed in addition to efficient CPU utilization powered by async I/O * **Ease of use** : user interface purely in Python 🐍, by which users can serve their models in an ML framework-agnostic manner using the same code as they do for offline testing * **Dynamic batching** : aggregate requests from different users for batched inference and distribute results back * **Pipelined stages** : spawn multiple processes for pipelined stages to handle CPU/GPU/IO mixed workloads * **Cloud friendly** : designed to run in the cloud, with the model warmup, graceful shutdown, and Prometheus monitoring metrics, easily managed by Kubernetes or any container orchestration systems * **Do one thing well** : focus on the online serving part, users can pay attention to the model optimization and business logic

llm-code-interpreter
The 'llm-code-interpreter' repository is a deprecated plugin that provides a code interpreter on steroids for ChatGPT by E2B. It gives ChatGPT access to a sandboxed cloud environment with capabilities like running any code, accessing Linux OS, installing programs, using filesystem, running processes, and accessing the internet. The plugin exposes commands to run shell commands, read files, and write files, enabling various possibilities such as running different languages, installing programs, starting servers, deploying websites, and more. It is powered by the E2B API and is designed for agents to freely experiment within a sandboxed environment.

pezzo
Pezzo is a fully cloud-native and open-source LLMOps platform that allows users to observe and monitor AI operations, troubleshoot issues, save costs and latency, collaborate, manage prompts, and deliver AI changes instantly. It supports various clients for prompt management, observability, and caching. Users can run the full Pezzo stack locally using Docker Compose, with prerequisites including Node.js 18+, Docker, and a GraphQL Language Feature Support VSCode Extension. Contributions are welcome, and the source code is available under the Apache 2.0 License.

learn-generative-ai
Learn Cloud Applied Generative AI Engineering (GenEng) is a course focusing on the application of generative AI technologies in various industries. The course covers topics such as the economic impact of generative AI, the role of developers in adopting and integrating generative AI technologies, and the future trends in generative AI. Students will learn about tools like OpenAI API, LangChain, and Pinecone, and how to build and deploy Large Language Models (LLMs) for different applications. The course also explores the convergence of generative AI with Web 3.0 and its potential implications for decentralized intelligence.