
rag-chat
Prototype SDK for RAG development.
Stars: 203
The `@upstash/rag-chat` package simplifies the development of retrieval-augmented generation (RAG) chat applications by providing Next.js compatibility with streaming support, built-in vector store, optional Redis compatibility for fast chat history management, rate limiting, and disableRag option. Users can easily set up the environment variables and initialize RAGChat to interact with AI models, manage knowledge base, chat history, and enable debugging features. Advanced configuration options allow customization of RAGChat instance with built-in rate limiting, observability via Helicone, and integration with Next.js route handlers and Vercel AI SDK. The package supports OpenAI models, Upstash-hosted models, and custom providers like TogetherAi and Replicate.
README:

[!NOTE]
Recommendation from the Upstash TeamThe RAG Chat SDK is designed to facilitate easier and faster prototype creation. For real projects, use Vercel AI SDK, Langchain, and LlamaIndex.
[!NOTE]
This project is a Community Project.The project is maintained and supported by the community. Upstash may contribute but does not officially support or assume responsibility for it.
The @upstash/rag-chat package makes it easy to develop retrieval-augmented generation (RAG) chat applications with minimal setup and configuration.
Features:
- Next.js compatibility with streaming support
- Ingest entire websites, PDFs, and more out of the box
- Built-in vector store for your knowledge base
- (Optional) built-in Redis compatibility for fast chat history management
- (Optional) built-in rate limiting
- (Optional) disableRag option to use it as LLM + chat history
- (Optional) Analytics via Helicone, Langsmith, and Cloudflare AI Gateway
Install the package using your preferred package manager:
pnpm add @upstash/rag-chat
bun add @upstash/rag-chat
npm i @upstash/rag-chat- Set up your environment variables:
UPSTASH_VECTOR_REST_URL="XXXXX"
UPSTASH_VECTOR_REST_TOKEN="XXXXX"
# if you use OpenAI compatible models
OPENAI_API_KEY="XXXXX"
# or if you use Upstash hosted models
QSTASH_TOKEN="XXXXX"
# Optional: For Redis-based chat history (default is in-memory)
UPSTASH_REDIS_REST_URL="XXXXX"
UPSTASH_REDIS_REST_TOKEN="XXXXX"- Initialize and use RAGChat:
import { RAGChat } from "@upstash/rag-chat";
const ragChat = new RAGChat();
const response = await ragChat.chat("Tell me about machine learning");
console.log(response);import { RAGChat, openai } from "@upstash/rag-chat";
export const ragChat = new RAGChat({
model: openai("gpt-4-turbo"),
});
await ragChat.context.add({
type: "text",
data: "The speed of light is approximately 299,792,458 meters per second.",
});
await ragChat.context.add({
type: "pdf",
fileSource: "./data/physics_basics.pdf",
});
const response = await ragChat.chat("What is the speed of light?");
console.log(response.output);For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for rag-chat
Similar Open Source Tools
rag-chat
The `@upstash/rag-chat` package simplifies the development of retrieval-augmented generation (RAG) chat applications by providing Next.js compatibility with streaming support, built-in vector store, optional Redis compatibility for fast chat history management, rate limiting, and disableRag option. Users can easily set up the environment variables and initialize RAGChat to interact with AI models, manage knowledge base, chat history, and enable debugging features. Advanced configuration options allow customization of RAGChat instance with built-in rate limiting, observability via Helicone, and integration with Next.js route handlers and Vercel AI SDK. The package supports OpenAI models, Upstash-hosted models, and custom providers like TogetherAi and Replicate.
LlamaBarn
LlamaBarn is a macOS menu bar app designed for running local LLMs. It allows users to install models from a built-in catalog, connect various applications such as chat UIs, editors, CLI tools, and scripts, and manage the loading and unloading of models based on usage. The app ensures all processing is done locally on the user's device, with a small app footprint and zero configuration required. It offers a smart model catalog, self-contained storage for models and configurations, and is built on llama.cpp from the GGML org.
BrowserAI
BrowserAI is a tool that allows users to run large language models (LLMs) directly in the browser, providing a simple, fast, and open-source solution. It prioritizes privacy by processing data locally, is cost-effective with no server costs, works offline after initial download, and offers WebGPU acceleration for high performance. It is developer-friendly with a simple API, supports multiple engines, and comes with pre-configured models for easy use. Ideal for web developers, companies needing privacy-conscious AI solutions, researchers experimenting with browser-based AI, and hobbyists exploring AI without infrastructure overhead.
sre
SmythOS is an operating system designed for building, deploying, and managing intelligent AI agents at scale. It provides a unified SDK and resource abstraction layer for various AI services, making it easy to scale and flexible. With an agent-first design, developer-friendly SDK, modular architecture, and enterprise security features, SmythOS offers a robust foundation for AI workloads. The system is built with a philosophy inspired by traditional operating system kernels, ensuring autonomy, control, and security for AI agents. SmythOS aims to make shipping production-ready AI agents accessible and open for everyone in the coming Internet of Agents era.

chat
deco.chat is an open-source foundation for building AI-native software, providing developers, engineers, and AI enthusiasts with robust tools to rapidly prototype, develop, and deploy AI-powered applications. It empowers Vibecoders to prototype ideas and Agentic engineers to deploy scalable, secure, and sustainable production systems. The core capabilities include an open-source runtime for composing tools and workflows, MCP Mesh for secure integration of models and APIs, a unified TypeScript stack for backend logic and custom frontends, global modular infrastructure built on Cloudflare, and a visual workspace for building agents and orchestrating everything in code.

starwhale
Starwhale is an MLOps/LLMOps platform that brings efficiency and standardization to machine learning operations. It streamlines the model development lifecycle, enabling teams to optimize workflows around key areas like model building, evaluation, release, and fine-tuning. Starwhale abstracts Model, Runtime, and Dataset as first-class citizens, providing tailored capabilities for common workflow scenarios including Models Evaluation, Live Demo, and LLM Fine-tuning. It is an open-source platform designed for clarity and ease of use, empowering developers to build customized MLOps features tailored to their needs.

exospherehost
Exosphere is an open source infrastructure designed to run AI agents at scale for large data and long running flows. It allows developers to define plug and playable nodes that can be run on a reliable backbone in the form of a workflow, with features like dynamic state creation at runtime, infinite parallel agents, persistent state management, and failure handling. This enables the deployment of production agents that can scale beautifully to build robust autonomous AI workflows.
effective_llm_alignment
This is a super customizable, concise, user-friendly, and efficient toolkit for training and aligning LLMs. It provides support for various methods such as SFT, Distillation, DPO, ORPO, CPO, SimPO, SMPO, Non-pair Reward Modeling, Special prompts basket format, Rejection Sampling, Scoring using RM, Effective FAISS Map-Reduce Deduplication, LLM scoring using RM, NER, CLIP, Classification, and STS. The toolkit offers key libraries like PyTorch, Transformers, TRL, Accelerate, FSDP, DeepSpeed, and tools for result logging with wandb or clearml. It allows mixing datasets, generation and logging in wandb/clearml, vLLM batched generation, and aligns models using the SMPO method.

sdialog
SDialog is an MIT-licensed open-source toolkit for building, simulating, and evaluating LLM-based conversational agents end-to-end. It aims to bridge agent construction, user simulation, dialog generation, and evaluation in a single reproducible workflow, enabling the generation of reliable, controllable dialog systems or data at scale. The toolkit standardizes a Dialog schema, offers persona-driven multi-agent simulation with LLMs, provides composable orchestration for precise control over behavior and flow, includes built-in evaluation metrics, and offers mechanistic interpretability. It allows for easy creation of user-defined components and interoperability across various AI platforms.
farfalle
Farfalle is an open-source AI-powered search engine that allows users to run their own local LLM or utilize the cloud. It provides a tech stack including Next.js for frontend, FastAPI for backend, Tavily for search API, Logfire for logging, and Redis for rate limiting. Users can get started by setting up prerequisites like Docker and Ollama, and obtaining API keys for Tavily, OpenAI, and Groq. The tool supports models like llama3, mistral, and gemma. Users can clone the repository, set environment variables, run containers using Docker Compose, and deploy the backend and frontend using services like Render and Vercel.
inference-gateway
The Inference Gateway is an open-source proxy server designed to simplify access to various language model APIs. It allows users to interact with different language models through a unified interface, stream tokens in real-time, process images alongside text, and use Docker or Kubernetes for deployment. The gateway supports Model Context Protocol integration, provides metrics and observability features, and is production-ready with minimal resource consumption. It offers middleware control and bypass mechanisms, enabling users to manage capabilities like MCP and vision support. The CLI tool provides status monitoring, interactive chat, configuration management, project initialization, and tool execution functionalities. The project aims to provide a flexible solution for AI Agents, supporting self-hosted LLMs and avoiding vendor lock-in.
inferable
Inferable is an open source platform that helps users build reliable LLM-powered agentic automations at scale. It offers a managed agent runtime, durable tool calling, zero network configuration, multiple language support, and is fully open source under the MIT license. Users can define functions, register them with Inferable, and create runs that utilize these functions to automate tasks. The platform supports Node.js/TypeScript, Go, .NET, and React, and provides SDKs, core services, and bootstrap templates for various languages.
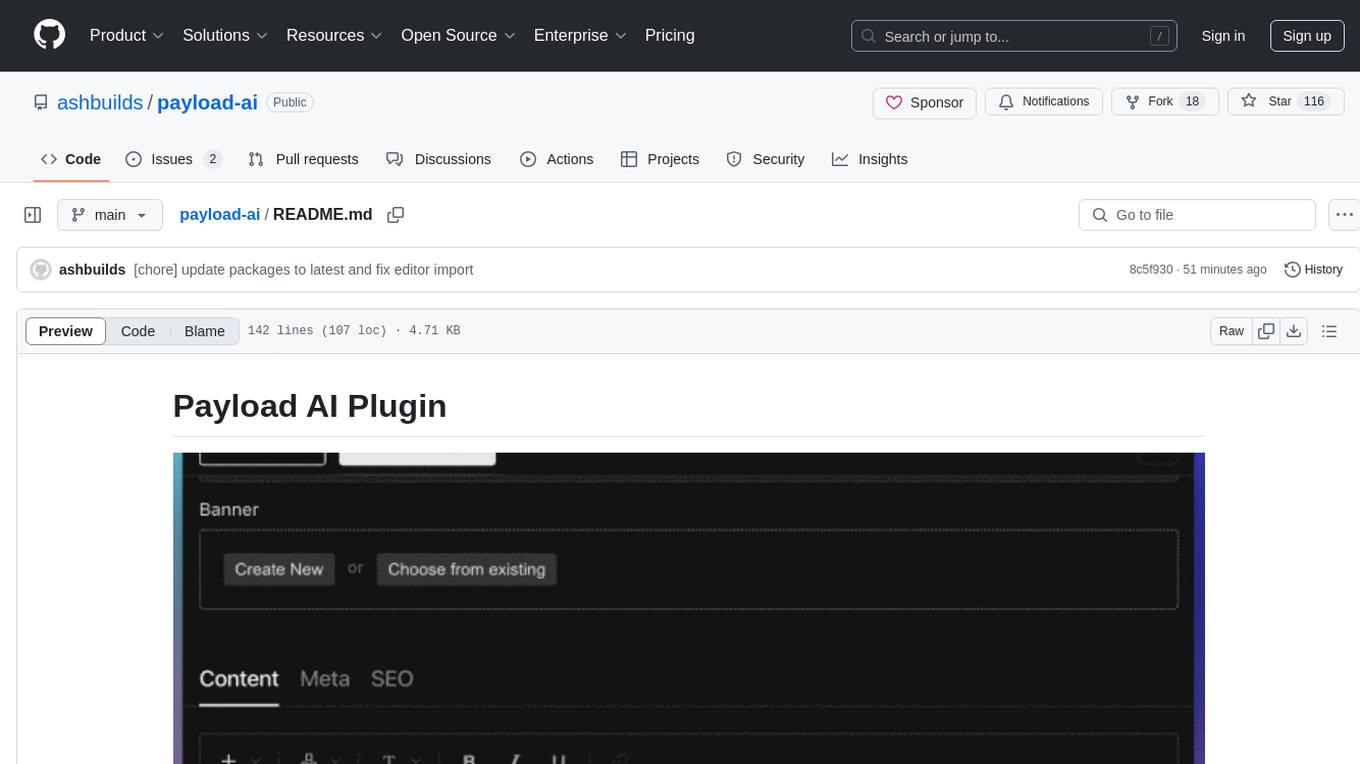
payload-ai
The Payload AI Plugin is an advanced extension that integrates modern AI capabilities into your Payload CMS, streamlining content creation and management. It offers features like text generation, voice and image generation, field-level prompt customization, prompt editor, document analyzer, fact checking, automated content workflows, internationalization support, editor AI suggestions, and AI chat support. Users can personalize and configure the plugin by setting environment variables. The plugin is actively developed and tested with Payload version v3.2.1, with regular updates expected.

R2R
R2R (RAG to Riches) is a fast and efficient framework for serving high-quality Retrieval-Augmented Generation (RAG) to end users. The framework is designed with customizable pipelines and a feature-rich FastAPI implementation, enabling developers to quickly deploy and scale RAG-based applications. R2R was conceived to bridge the gap between local LLM experimentation and scalable production solutions. **R2R is to LangChain/LlamaIndex what NextJS is to React**. A JavaScript client for R2R deployments can be found here. ### Key Features * **🚀 Deploy** : Instantly launch production-ready RAG pipelines with streaming capabilities. * **🧩 Customize** : Tailor your pipeline with intuitive configuration files. * **🔌 Extend** : Enhance your pipeline with custom code integrations. * **⚖️ Autoscale** : Scale your pipeline effortlessly in the cloud using SciPhi. * **🤖 OSS** : Benefit from a framework developed by the open-source community, designed to simplify RAG deployment.

preswald
Preswald is a full-stack platform for building, deploying, and managing interactive data applications in Python. It simplifies the process by combining ingestion, storage, transformation, and visualization into one lightweight SDK. With Preswald, users can connect to various data sources, customize app themes, and easily deploy apps locally. The platform focuses on code-first simplicity, end-to-end coverage, and efficiency by design, making it suitable for prototyping internal tools or deploying production-grade apps with reduced complexity and cost.
gpt-computer-assistant
GPT Computer Assistant (GCA) is an open-source framework designed to build vertical AI agents that can automate tasks on Windows, macOS, and Ubuntu systems. It leverages the Model Context Protocol (MCP) and its own modules to mimic human-like actions and achieve advanced capabilities. With GCA, users can empower themselves to accomplish more in less time by automating tasks like updating dependencies, analyzing databases, and configuring cloud security settings.
For similar tasks
rag-chat
The `@upstash/rag-chat` package simplifies the development of retrieval-augmented generation (RAG) chat applications by providing Next.js compatibility with streaming support, built-in vector store, optional Redis compatibility for fast chat history management, rate limiting, and disableRag option. Users can easily set up the environment variables and initialize RAGChat to interact with AI models, manage knowledge base, chat history, and enable debugging features. Advanced configuration options allow customization of RAGChat instance with built-in rate limiting, observability via Helicone, and integration with Next.js route handlers and Vercel AI SDK. The package supports OpenAI models, Upstash-hosted models, and custom providers like TogetherAi and Replicate.
ai-chat-protocol
The Microsoft AI Chat Protocol SDK is a library for easily building AI Chat interfaces from services that follow the AI Chat Protocol API Specification. By agreeing on a standard API contract, AI backend consumption and evaluation can be performed easily and consistently across different services. It allows developers to develop AI chat interfaces, consume and evaluate AI inference backends, and incorporate HTTP middleware for logging and authentication.

spring-ai
The Spring AI project provides a Spring-friendly API and abstractions for developing AI applications. It offers a portable client API for interacting with generative AI models, enabling developers to easily swap out implementations and access various models like OpenAI, Azure OpenAI, and HuggingFace. Spring AI also supports prompt engineering, providing classes and interfaces for creating and parsing prompts, as well as incorporating proprietary data into generative AI without retraining the model. This is achieved through Retrieval Augmented Generation (RAG), which involves extracting, transforming, and loading data into a vector database for use by AI models. Spring AI's VectorStore abstraction allows for seamless transitions between different vector database implementations.
ruby-nano-bots
Ruby Nano Bots is an implementation of the Nano Bots specification supporting various AI providers like Cohere Command, Google Gemini, Maritaca AI MariTalk, Mistral AI, Ollama, OpenAI ChatGPT, and others. It allows calling tools (functions) and provides a helpful assistant for interacting with AI language models. The tool can be used both from the command line and as a library in Ruby projects, offering features like REPL, debugging, and encryption for data privacy.
ryoma
Ryoma is an AI Powered Data Agent framework that offers a comprehensive solution for data analysis, engineering, and visualization. It leverages cutting-edge technologies like Langchain, Reflex, Apache Arrow, Jupyter Ai Magics, Amundsen, Ibis, and Feast to provide seamless integration of language models, build interactive web applications, handle in-memory data efficiently, work with AI models, and manage machine learning features in production. Ryoma also supports various data sources like Snowflake, Sqlite, BigQuery, Postgres, MySQL, and different engines like Apache Spark and Apache Flink. The tool enables users to connect to databases, run SQL queries, and interact with data and AI models through a user-friendly UI called Ryoma Lab.
shell-pilot
Shell-pilot is a simple, lightweight shell script designed to interact with various AI models such as OpenAI, Ollama, Mistral AI, LocalAI, ZhipuAI, Anthropic, Moonshot, and Novita AI from the terminal. It enhances intelligent system management without any dependencies, offering features like setting up a local LLM repository, using official models and APIs, viewing history and session persistence, passing input prompts with pipe/redirector, listing available models, setting request parameters, generating and running commands in the terminal, easy configuration setup, system package version checking, and managing system aliases.

awesome-llm-web-ui
Curating the best Large Language Model (LLM) Web User Interfaces that facilitate interaction with powerful AI models. Explore and catalogue intuitive, feature-rich, and innovative web interfaces for interacting with LLMs, ranging from simple chatbots to comprehensive platforms equipped with functionalities like PDF generation and web search.
java-sdk
The MCP Java SDK is a set of projects that provide Java SDK integration for the Model Context Protocol. It enables Java applications to interact with AI models and tools through a standardized interface, supporting both synchronous and asynchronous communication patterns.
For similar jobs

promptflow
**Prompt flow** is a suite of development tools designed to streamline the end-to-end development cycle of LLM-based AI applications, from ideation, prototyping, testing, evaluation to production deployment and monitoring. It makes prompt engineering much easier and enables you to build LLM apps with production quality.

deepeval
DeepEval is a simple-to-use, open-source LLM evaluation framework specialized for unit testing LLM outputs. It incorporates various metrics such as G-Eval, hallucination, answer relevancy, RAGAS, etc., and runs locally on your machine for evaluation. It provides a wide range of ready-to-use evaluation metrics, allows for creating custom metrics, integrates with any CI/CD environment, and enables benchmarking LLMs on popular benchmarks. DeepEval is designed for evaluating RAG and fine-tuning applications, helping users optimize hyperparameters, prevent prompt drifting, and transition from OpenAI to hosting their own Llama2 with confidence.

MegaDetector
MegaDetector is an AI model that identifies animals, people, and vehicles in camera trap images (which also makes it useful for eliminating blank images). This model is trained on several million images from a variety of ecosystems. MegaDetector is just one of many tools that aims to make conservation biologists more efficient with AI. If you want to learn about other ways to use AI to accelerate camera trap workflows, check out our of the field, affectionately titled "Everything I know about machine learning and camera traps".

leapfrogai
LeapfrogAI is a self-hosted AI platform designed to be deployed in air-gapped resource-constrained environments. It brings sophisticated AI solutions to these environments by hosting all the necessary components of an AI stack, including vector databases, model backends, API, and UI. LeapfrogAI's API closely matches that of OpenAI, allowing tools built for OpenAI/ChatGPT to function seamlessly with a LeapfrogAI backend. It provides several backends for various use cases, including llama-cpp-python, whisper, text-embeddings, and vllm. LeapfrogAI leverages Chainguard's apko to harden base python images, ensuring the latest supported Python versions are used by the other components of the stack. The LeapfrogAI SDK provides a standard set of protobuffs and python utilities for implementing backends and gRPC. LeapfrogAI offers UI options for common use-cases like chat, summarization, and transcription. It can be deployed and run locally via UDS and Kubernetes, built out using Zarf packages. LeapfrogAI is supported by a community of users and contributors, including Defense Unicorns, Beast Code, Chainguard, Exovera, Hypergiant, Pulze, SOSi, United States Navy, United States Air Force, and United States Space Force.

llava-docker
This Docker image for LLaVA (Large Language and Vision Assistant) provides a convenient way to run LLaVA locally or on RunPod. LLaVA is a powerful AI tool that combines natural language processing and computer vision capabilities. With this Docker image, you can easily access LLaVA's functionalities for various tasks, including image captioning, visual question answering, text summarization, and more. The image comes pre-installed with LLaVA v1.2.0, Torch 2.1.2, xformers 0.0.23.post1, and other necessary dependencies. You can customize the model used by setting the MODEL environment variable. The image also includes a Jupyter Lab environment for interactive development and exploration. Overall, this Docker image offers a comprehensive and user-friendly platform for leveraging LLaVA's capabilities.

carrot
The 'carrot' repository on GitHub provides a list of free and user-friendly ChatGPT mirror sites for easy access. The repository includes sponsored sites offering various GPT models and services. Users can find and share sites, report errors, and access stable and recommended sites for ChatGPT usage. The repository also includes a detailed list of ChatGPT sites, their features, and accessibility options, making it a valuable resource for ChatGPT users seeking free and unlimited GPT services.

TrustLLM
TrustLLM is a comprehensive study of trustworthiness in LLMs, including principles for different dimensions of trustworthiness, established benchmark, evaluation, and analysis of trustworthiness for mainstream LLMs, and discussion of open challenges and future directions. Specifically, we first propose a set of principles for trustworthy LLMs that span eight different dimensions. Based on these principles, we further establish a benchmark across six dimensions including truthfulness, safety, fairness, robustness, privacy, and machine ethics. We then present a study evaluating 16 mainstream LLMs in TrustLLM, consisting of over 30 datasets. The document explains how to use the trustllm python package to help you assess the performance of your LLM in trustworthiness more quickly. For more details about TrustLLM, please refer to project website.

AI-YinMei
AI-YinMei is an AI virtual anchor Vtuber development tool (N card version). It supports fastgpt knowledge base chat dialogue, a complete set of solutions for LLM large language models: [fastgpt] + [one-api] + [Xinference], supports docking bilibili live broadcast barrage reply and entering live broadcast welcome speech, supports Microsoft edge-tts speech synthesis, supports Bert-VITS2 speech synthesis, supports GPT-SoVITS speech synthesis, supports expression control Vtuber Studio, supports painting stable-diffusion-webui output OBS live broadcast room, supports painting picture pornography public-NSFW-y-distinguish, supports search and image search service duckduckgo (requires magic Internet access), supports image search service Baidu image search (no magic Internet access), supports AI reply chat box [html plug-in], supports AI singing Auto-Convert-Music, supports playlist [html plug-in], supports dancing function, supports expression video playback, supports head touching action, supports gift smashing action, supports singing automatic start dancing function, chat and singing automatic cycle swing action, supports multi scene switching, background music switching, day and night automatic switching scene, supports open singing and painting, let AI automatically judge the content.