
WebAI-to-API
Gemini to API : ) (Don't need API KEY)
Stars: 304
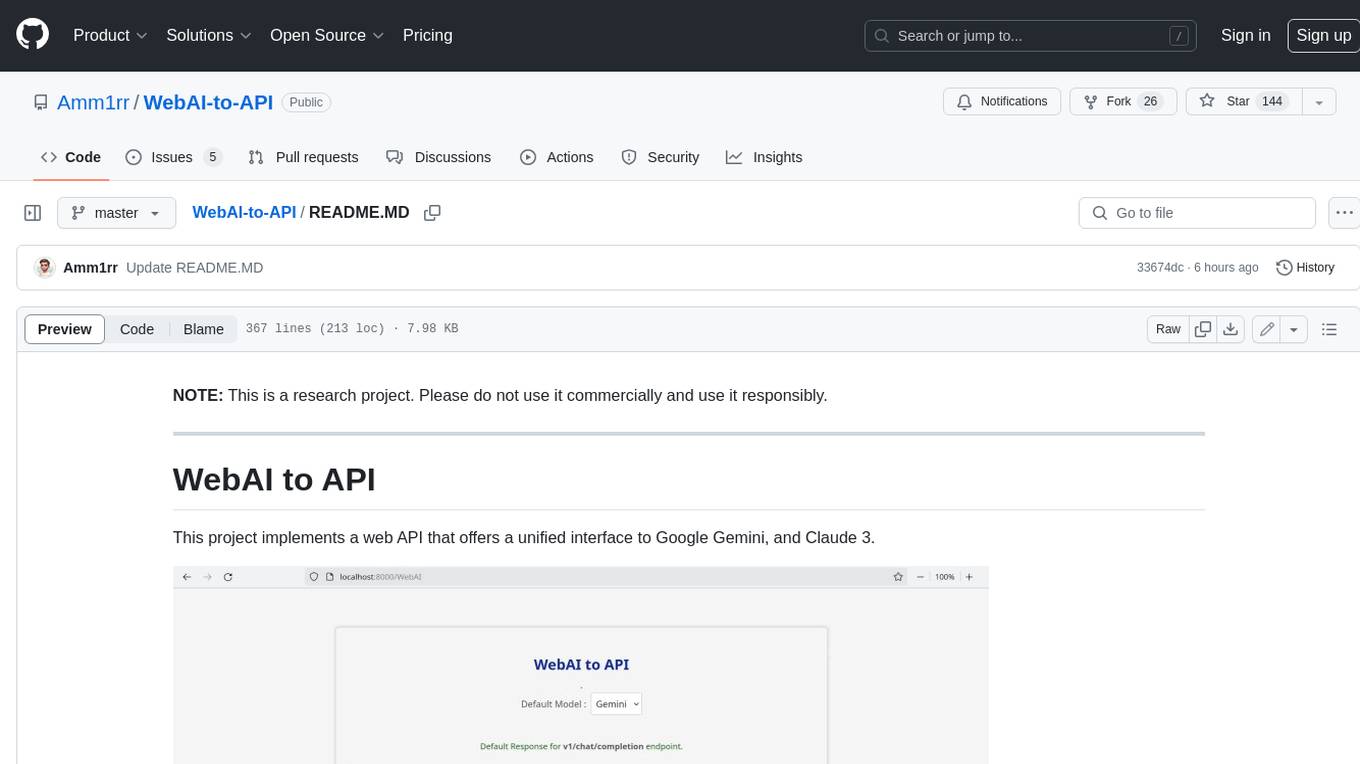
This project implements a web API that offers a unified interface to Google Gemini and Claude 3. It provides a self-hosted, lightweight, and scalable solution for accessing these AI models through a streaming API. The API supports both Claude and Gemini models, allowing users to interact with them in real-time. The project includes a user-friendly web UI for configuration and documentation, making it easy to get started and explore the capabilities of the API.
README:
This is a research project. Please do not use it commercially and use it responsibly.

WebAI-to-API is a modular web server built with FastAPI, designed to manage requests across AI services like Gemini. It features a clean, extendable architecture that simplifies configuration, integration, and maintenance.
Note: Currently, Gemini is the primary supported AI service.
- 🌐 Endpoints Management:
/v1/chat/completions/gemini/gemini-chat/translate
- 🔄 Service Switching: Easily configure and switch between AI providers via
config.conf. - 🛠️ Modular Architecture: Organized into clearly defined modules for API routes, services, configurations, and utilities, making development and maintenance straightforward.

-
Clone the repository:
git clone https://github.com/Amm1rr/WebAI-to-API.git cd WebAI-to-API -
Install dependencies using Poetry:
poetry install
-
Create and update the configuration file:
cp config.conf.example config.conf
Then, edit
config.confto adjust service settings and other options. -
Run the server:
poetry run python src/run.py
Send a POST request to /v1/chat/completions (or any other available endpoint) with the required payload.
{
"model": "gemini-2.0-flash",
"messages": [{ "role": "user", "content": "Hello!" }]
}{
"id": "chatcmpl-12345",
"object": "chat.completion",
"created": 1693417200,
"model": "gemini-2.0-flash",
"choices": [
{
"message": {
"role": "assistant",
"content": "Hi there!"
},
"finish_reason": "stop",
"index": 0
}
],
"usage": {
"prompt_tokens": 0,
"completion_tokens": 0,
"total_tokens": 0
}
}- ✅ Gemini Support: Implemented
- 🟡
Claude, ChatGPT Development: Discontinued
| Section | Option | Description | Example Value |
|---|---|---|---|
| [AI] | default_ai | Default service for /v1/chat/completions
|
gemini |
| [EnabledAI] | gemini | Enable/disable Gemini service | true |
| [Browser] | name | Browser for cookie-based authentication | firefox |
The complete configuration template is available in WebAI-to-API/config.conf.example.
If the cookies are left empty, the application will automatically retrieve them using the default browser specified.
[AI]
# Default AI service.
default_ai = gemini
# Default model for Gemini.
default_model_gemini = gemini-2.0-flash
# Gemini cookies (leave empty to use browser_cookies3 for automatic authentication).
gemini_cookie_1psid =
gemini_cookie_1psidts =
[EnabledAI]
# Enable or disable AI services.
gemini = true
[Browser]
# Default browser options: firefox, brave, chrome, edge, safari.
name = firefoxThe project now follows a modular layout that separates configuration, business logic, API endpoints, and utilities:
src/
├── app/
│ ├── __init__.py
│ ├── main.py # FastAPI app creation, configuration, and lifespan management.
│ ├── config.py # Global configuration loader/updater.
│ ├── logger.py # Centralized logging configuration.
│ ├── endpoints/ # API endpoint routers.
│ │ ├── __init__.py
│ │ ├── gemini.py # Endpoints for Gemini (e.g., /gemini, /gemini-chat).
│ │ └── chat.py # Endpoints for translation and OpenAI-compatible requests.
│ ├── services/ # Business logic and service wrappers.
│ │ ├── __init__.py
│ │ ├── gemini_client.py # Gemini client initialization, content generation, and cleanup.
│ │ └── session_manager.py # Session management for chat and translation.
│ └── utils/ # Helper functions.
│ ├── __init__.py
│ └── browser.py # Browser-based cookie retrieval.
├── models/ # Models and wrappers (e.g., MyGeminiClient).
│ └── gemini.py
├── schemas/ # Pydantic schemas for request/response validation.
│ └── request.py
├── config.conf # Application configuration file.
└── run.py # Entry point to run the server.
The project is built on a modular architecture designed for scalability and ease of maintenance. Its primary components are:
- app/main.py: Initializes the FastAPI application, configures middleware, and manages application lifespan (startup and shutdown routines).
-
app/config.py: Handles the loading and updating of configuration settings from
config.conf. - app/logger.py: Sets up a centralized logging system.
-
app/endpoints/: Contains separate modules for handling API endpoints. Each module (e.g.,
gemini.pyandchat.py) manages routes specific to their functionality. -
app/services/: Encapsulates business logic, including the Gemini client wrapper (
gemini_client.py) and session management (session_manager.py). - app/utils/browser.py: Provides helper functions, such as retrieving cookies from the browser for authentication.
-
models/: Holds model definitions like
MyGeminiClientfor interfacing with the Gemini Web API. - schemas/: Defines Pydantic models for validating API requests.
-
Application Initialization:
On startup, the application loads configurations and initializes the Gemini client and session managers. This is managed via thelifespancontext inapp/main.py. -
Routing:
The API endpoints are organized into dedicated routers underapp/endpoints/, which are then included in the main FastAPI application. -
Service Layer:
Theapp/services/directory contains the logic for interacting with the Gemini API and managing user sessions, ensuring that the API routes remain clean and focused on request handling. -
Utilities and Configurations:
Helper functions and configuration logic are kept separate to maintain clarity and ease of updates.
This project is open source under the MIT License.
Note: This is a research project. Please use it responsibly, and be aware that additional security measures and error handling are necessary for production deployments.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for WebAI-to-API
Similar Open Source Tools
WebAI-to-API
This project implements a web API that offers a unified interface to Google Gemini and Claude 3. It provides a self-hosted, lightweight, and scalable solution for accessing these AI models through a streaming API. The API supports both Claude and Gemini models, allowing users to interact with them in real-time. The project includes a user-friendly web UI for configuration and documentation, making it easy to get started and explore the capabilities of the API.
seline
Seline is a local-first AI desktop application that integrates conversational AI, visual generation tools, vector search, and multi-channel connectivity. It allows users to connect WhatsApp, Telegram, or Slack to create always-on bots with full context and background task delivery. The application supports multi-channel connectivity, deep research mode, local web browsing with Puppeteer, local knowledge and privacy features, visual and creative tools, automation and agents, developer experience enhancements, and more. Seline is actively developed with a focus on improving user experience and functionality.
kiss_ai
KISS AI is a lightweight and powerful multi-agent evolutionary framework that simplifies building AI agents. It uses native function calling for efficiency and accuracy, making building AI agents as straightforward as possible. The framework includes features like multi-agent orchestration, agent evolution and optimization, relentless coding agent for long-running tasks, output formatting, trajectory saving and visualization, GEPA for prompt optimization, KISSEvolve for algorithm discovery, self-evolving multi-agent, Docker integration, multiprocessing support, and support for various models from OpenAI, Anthropic, Gemini, Together AI, and OpenRouter.
typewhisper-mac
TypeWhisper for Mac is a speech-to-text and AI text processing tool designed for macOS. It allows users to transcribe audio using on-device AI models or cloud APIs like Groq and OpenAI, and process the results with custom LLM prompts. The tool offers features such as multiple transcription engines, on-device or cloud processing, streaming preview, file transcription, subtitle export, system-wide dictation with hotkeys, AI processing with custom prompts and translation, personalization through profiles, dictionary, snippets, and history, integration and extensibility via plugins, HTTP API, and CLI tool. The tool is designed for macOS 15.0 and later, supports Apple Silicon, and offers a multilingual UI with English and German languages.
conduit
Conduit is an open-source, cross-platform mobile application for Open-WebUI, providing a native mobile experience for interacting with your self-hosted AI infrastructure. It supports real-time chat, model selection, conversation management, markdown rendering, theme support, voice input, file uploads, multi-modal support, secure storage, folder management, and tools invocation. Conduit offers multiple authentication flows and follows a clean architecture pattern with Riverpod for state management, Dio for HTTP networking, WebSocket for real-time streaming, and Flutter Secure Storage for credential management.
astrsk
astrsk is a tool that pushes the boundaries of AI storytelling by offering advanced AI agents, customizable response formatting, and flexible prompt editing for immersive roleplaying experiences. It provides complete AI agent control, a visual flow editor for conversation flows, and ensures 100% local-first data storage. The tool is true cross-platform with support for various AI providers and modern technologies like React, TypeScript, and Tailwind CSS. Coming soon features include cross-device sync, enhanced session customization, and community features.
claudian
Claudian is an Obsidian plugin that embeds Claude Code as an AI collaborator in your vault. It provides full agentic capabilities, including file read/write, search, bash commands, and multi-step workflows. Users can leverage Claude Code's power to interact with their vault, analyze images, edit text inline, add custom instructions, create reusable prompt templates, extend capabilities with skills and agents, connect external tools via Model Context Protocol servers, control models and thinking budget, toggle plan mode, ensure security with permission modes and vault confinement, and interact with Chrome. The plugin requires Claude Code CLI, Obsidian v1.8.9+, Claude subscription/API or custom model provider, and desktop platforms (macOS, Linux, Windows).
OpenOutreach
OpenOutreach is a self-hosted, open-source LinkedIn automation tool designed for B2B lead generation. It automates the entire outreach process in a stealthy, human-like way by discovering and enriching target profiles, ranking profiles using ML for smart prioritization, sending personalized connection requests, following up with custom messages after acceptance, and tracking everything in a built-in CRM with web UI. It offers features like undetectable behavior, fully customizable Python-based campaigns, local execution with CRM, easy deployment with Docker, and AI-ready templating for hyper-personalized messages.

MassGen
MassGen is a cutting-edge multi-agent system that leverages the power of collaborative AI to solve complex tasks. It assigns a task to multiple AI agents who work in parallel, observe each other's progress, and refine their approaches to converge on the best solution to deliver a comprehensive and high-quality result. The system operates through an architecture designed for seamless multi-agent collaboration, with key features including cross-model/agent synergy, parallel processing, intelligence sharing, consensus building, and live visualization. Users can install the system, configure API settings, and run MassGen for various tasks such as question answering, creative writing, research, development & coding tasks, and web automation & browser tasks. The roadmap includes plans for advanced agent collaboration, expanded model, tool & agent integration, improved performance & scalability, enhanced developer experience, and a web interface.
alphora
Alphora is a full-stack framework for building production AI agents, providing agent orchestration, prompt engineering, tool execution, memory management, streaming, and deployment with an async-first, OpenAI-compatible design. It offers features like agent derivation, reasoning-action loop, async streaming, visual debugger, OpenAI compatibility, multimodal support, tool system with zero-config tools and type safety, prompt engine with dynamic prompts, memory and storage management, sandbox for secure execution, deployment as API, and more. Alphora allows users to build sophisticated AI agents easily and efficiently.
botserver
General Bots is a self-hosted AI automation platform and LLM conversational platform focused on convention over configuration and code-less approaches. It serves as the core API server handling LLM orchestration, business logic, database operations, and multi-channel communication. The platform offers features like multi-vendor LLM API, MCP + LLM Tools Generation, Semantic Caching, Web Automation Engine, Enterprise Data Connectors, and Git-like Version Control. It enforces a ZERO TOLERANCE POLICY for code quality and security, with strict guidelines for error handling, performance optimization, and code patterns. The project structure includes modules for core functionalities like Rhai BASIC interpreter, security, shared types, tasks, auto task system, file operations, learning system, and LLM assistance.
AI-Agent-Starter-Kit
AI Agent Starter Kit is a modern full-stack AI-enabled template using Next.js for frontend and Express.js for backend, with Telegram and OpenAI integrations. It offers AI-assisted development, smart environment variable setup assistance, intelligent error resolution, context-aware code completion, and built-in debugging helpers. The kit provides a structured environment for developers to interact with AI tools seamlessly, enhancing the development process and productivity.
claude-code-settings
A repository collecting best practices for Claude Code settings and customization. It provides configuration files for customizing Claude Code's behavior and building an efficient development environment. The repository includes custom agents and skills for specific domains, interactive development workflow features, efficient development rules, and team workflow with Codex MCP. Users can leverage the provided configuration files and tools to enhance their development process and improve code quality.
unity-mcp
MCP for Unity is a tool that acts as a bridge, enabling AI assistants to interact with the Unity Editor via a local MCP Client. Users can instruct their LLM to manage assets, scenes, scripts, and automate tasks within Unity. The tool offers natural language control, powerful tools for asset management, scene manipulation, and automation of workflows. It is extensible and designed to work with various MCP Clients, providing a range of functions for precise text edits, script management, GameObject operations, and more.
agent-memory-server
The agent-memory-server is a memory layer designed for AI agents, providing a dual interface with REST API and Model Context Protocol server. It offers two-tier memory management, configurable memory strategies, semantic search capabilities, and flexible backends. The tool supports multi-provider LLM integration and AI features like topic extraction, entity recognition, and conversation summarization. It includes a Python SDK for easy integration with AI applications, allowing users to store and search memories efficiently. The server is suitable for AI assistants, customer support, personal AI, research assistants, and chatbots, enabling persistent memory across conversations and context from previous interactions.

simili-bot
Simili Bot is an AI-powered tool designed for GitHub repositories to automatically detect duplicate issues, find similar issues using semantic search, and intelligently route issues across repositories. It offers features such as semantic duplicate detection, cross-repository search, intelligent routing, smart triage, modular pipeline customization, and multi-repo support. The tool follows a 'Lego with Blueprints' architecture, with Lego Blocks representing independent pipeline steps and Blueprints providing pre-defined workflows. Users can configure AI providers like Gemini and OpenAI, set default models for embeddings, and specify workflows in a 'simili.yaml' file. Simili Bot also offers CLI commands for bulk indexing, processing single issues, and batch operations, enabling local development, testing, and analysis of historical data.
For similar tasks

h2ogpt
h2oGPT is an Apache V2 open-source project that allows users to query and summarize documents or chat with local private GPT LLMs. It features a private offline database of any documents (PDFs, Excel, Word, Images, Video Frames, Youtube, Audio, Code, Text, MarkDown, etc.), a persistent database (Chroma, Weaviate, or in-memory FAISS) using accurate embeddings (instructor-large, all-MiniLM-L6-v2, etc.), and efficient use of context using instruct-tuned LLMs (no need for LangChain's few-shot approach). h2oGPT also offers parallel summarization and extraction, reaching an output of 80 tokens per second with the 13B LLaMa2 model, HYDE (Hypothetical Document Embeddings) for enhanced retrieval based upon LLM responses, a variety of models supported (LLaMa2, Mistral, Falcon, Vicuna, WizardLM. With AutoGPTQ, 4-bit/8-bit, LORA, etc.), GPU support from HF and LLaMa.cpp GGML models, and CPU support using HF, LLaMa.cpp, and GPT4ALL models. Additionally, h2oGPT provides Attention Sinks for arbitrarily long generation (LLaMa-2, Mistral, MPT, Pythia, Falcon, etc.), a UI or CLI with streaming of all models, the ability to upload and view documents through the UI (control multiple collaborative or personal collections), Vision Models LLaVa, Claude-3, Gemini-Pro-Vision, GPT-4-Vision, Image Generation Stable Diffusion (sdxl-turbo, sdxl) and PlaygroundAI (playv2), Voice STT using Whisper with streaming audio conversion, Voice TTS using MIT-Licensed Microsoft Speech T5 with multiple voices and Streaming audio conversion, Voice TTS using MPL2-Licensed TTS including Voice Cloning and Streaming audio conversion, AI Assistant Voice Control Mode for hands-free control of h2oGPT chat, Bake-off UI mode against many models at the same time, Easy Download of model artifacts and control over models like LLaMa.cpp through the UI, Authentication in the UI by user/password via Native or Google OAuth, State Preservation in the UI by user/password, Linux, Docker, macOS, and Windows support, Easy Windows Installer for Windows 10 64-bit (CPU/CUDA), Easy macOS Installer for macOS (CPU/M1/M2), Inference Servers support (oLLaMa, HF TGI server, vLLM, Gradio, ExLLaMa, Replicate, OpenAI, Azure OpenAI, Anthropic), OpenAI-compliant, Server Proxy API (h2oGPT acts as drop-in-replacement to OpenAI server), Python client API (to talk to Gradio server), JSON Mode with any model via code block extraction. Also supports MistralAI JSON mode, Claude-3 via function calling with strict Schema, OpenAI via JSON mode, and vLLM via guided_json with strict Schema, Web-Search integration with Chat and Document Q/A, Agents for Search, Document Q/A, Python Code, CSV frames (Experimental, best with OpenAI currently), Evaluate performance using reward models, and Quality maintained with over 1000 unit and integration tests taking over 4 GPU-hours.

serverless-chat-langchainjs
This sample shows how to build a serverless chat experience with Retrieval-Augmented Generation using LangChain.js and Azure. The application is hosted on Azure Static Web Apps and Azure Functions, with Azure Cosmos DB for MongoDB vCore as the vector database. You can use it as a starting point for building more complex AI applications.

react-native-vercel-ai
Run Vercel AI package on React Native, Expo, Web and Universal apps. Currently React Native fetch API does not support streaming which is used as a default on Vercel AI. This package enables you to use AI library on React Native but the best usage is when used on Expo universal native apps. On mobile you get back responses without streaming with the same API of `useChat` and `useCompletion` and on web it will fallback to `ai/react`

LLamaSharp
LLamaSharp is a cross-platform library to run 🦙LLaMA/LLaVA model (and others) on your local device. Based on llama.cpp, inference with LLamaSharp is efficient on both CPU and GPU. With the higher-level APIs and RAG support, it's convenient to deploy LLM (Large Language Model) in your application with LLamaSharp.

gpt4all
GPT4All is an ecosystem to run powerful and customized large language models that work locally on consumer grade CPUs and any GPU. Note that your CPU needs to support AVX or AVX2 instructions. Learn more in the documentation. A GPT4All model is a 3GB - 8GB file that you can download and plug into the GPT4All open-source ecosystem software. Nomic AI supports and maintains this software ecosystem to enforce quality and security alongside spearheading the effort to allow any person or enterprise to easily train and deploy their own on-edge large language models.

ChatGPT-Telegram-Bot
ChatGPT Telegram Bot is a Telegram bot that provides a smooth AI experience. It supports both Azure OpenAI and native OpenAI, and offers real-time (streaming) response to AI, with a faster and smoother experience. The bot also has 15 preset bot identities that can be quickly switched, and supports custom bot identities to meet personalized needs. Additionally, it supports clearing the contents of the chat with a single click, and restarting the conversation at any time. The bot also supports native Telegram bot button support, making it easy and intuitive to implement required functions. User level division is also supported, with different levels enjoying different single session token numbers, context numbers, and session frequencies. The bot supports English and Chinese on UI, and is containerized for easy deployment.

twinny
Twinny is a free and open-source AI code completion plugin for Visual Studio Code and compatible editors. It integrates with various tools and frameworks, including Ollama, llama.cpp, oobabooga/text-generation-webui, LM Studio, LiteLLM, and Open WebUI. Twinny offers features such as fill-in-the-middle code completion, chat with AI about your code, customizable API endpoints, and support for single or multiline fill-in-middle completions. It is easy to install via the Visual Studio Code extensions marketplace and provides a range of customization options. Twinny supports both online and offline operation and conforms to the OpenAI API standard.

agnai
Agnaistic is an AI roleplay chat tool that allows users to interact with personalized characters using their favorite AI services. It supports multiple AI services, persona schema formats, and features such as group conversations, user authentication, and memory/lore books. Agnaistic can be self-hosted or run using Docker, and it provides a range of customization options through its settings.json file. The tool is designed to be user-friendly and accessible, making it suitable for both casual users and developers.
For similar jobs
h2ogpt
h2oGPT is an Apache V2 open-source project that allows users to query and summarize documents or chat with local private GPT LLMs. It features a private offline database of any documents (PDFs, Excel, Word, Images, Video Frames, Youtube, Audio, Code, Text, MarkDown, etc.), a persistent database (Chroma, Weaviate, or in-memory FAISS) using accurate embeddings (instructor-large, all-MiniLM-L6-v2, etc.), and efficient use of context using instruct-tuned LLMs (no need for LangChain's few-shot approach). h2oGPT also offers parallel summarization and extraction, reaching an output of 80 tokens per second with the 13B LLaMa2 model, HYDE (Hypothetical Document Embeddings) for enhanced retrieval based upon LLM responses, a variety of models supported (LLaMa2, Mistral, Falcon, Vicuna, WizardLM. With AutoGPTQ, 4-bit/8-bit, LORA, etc.), GPU support from HF and LLaMa.cpp GGML models, and CPU support using HF, LLaMa.cpp, and GPT4ALL models. Additionally, h2oGPT provides Attention Sinks for arbitrarily long generation (LLaMa-2, Mistral, MPT, Pythia, Falcon, etc.), a UI or CLI with streaming of all models, the ability to upload and view documents through the UI (control multiple collaborative or personal collections), Vision Models LLaVa, Claude-3, Gemini-Pro-Vision, GPT-4-Vision, Image Generation Stable Diffusion (sdxl-turbo, sdxl) and PlaygroundAI (playv2), Voice STT using Whisper with streaming audio conversion, Voice TTS using MIT-Licensed Microsoft Speech T5 with multiple voices and Streaming audio conversion, Voice TTS using MPL2-Licensed TTS including Voice Cloning and Streaming audio conversion, AI Assistant Voice Control Mode for hands-free control of h2oGPT chat, Bake-off UI mode against many models at the same time, Easy Download of model artifacts and control over models like LLaMa.cpp through the UI, Authentication in the UI by user/password via Native or Google OAuth, State Preservation in the UI by user/password, Linux, Docker, macOS, and Windows support, Easy Windows Installer for Windows 10 64-bit (CPU/CUDA), Easy macOS Installer for macOS (CPU/M1/M2), Inference Servers support (oLLaMa, HF TGI server, vLLM, Gradio, ExLLaMa, Replicate, OpenAI, Azure OpenAI, Anthropic), OpenAI-compliant, Server Proxy API (h2oGPT acts as drop-in-replacement to OpenAI server), Python client API (to talk to Gradio server), JSON Mode with any model via code block extraction. Also supports MistralAI JSON mode, Claude-3 via function calling with strict Schema, OpenAI via JSON mode, and vLLM via guided_json with strict Schema, Web-Search integration with Chat and Document Q/A, Agents for Search, Document Q/A, Python Code, CSV frames (Experimental, best with OpenAI currently), Evaluate performance using reward models, and Quality maintained with over 1000 unit and integration tests taking over 4 GPU-hours.

mistral.rs
Mistral.rs is a fast LLM inference platform written in Rust. We support inference on a variety of devices, quantization, and easy-to-use application with an Open-AI API compatible HTTP server and Python bindings.

ollama
Ollama is a lightweight, extensible framework for building and running language models on the local machine. It provides a simple API for creating, running, and managing models, as well as a library of pre-built models that can be easily used in a variety of applications. Ollama is designed to be easy to use and accessible to developers of all levels. It is open source and available for free on GitHub.

llama-cpp-agent
The llama-cpp-agent framework is a tool designed for easy interaction with Large Language Models (LLMs). Allowing users to chat with LLM models, execute structured function calls and get structured output (objects). It provides a simple yet robust interface and supports llama-cpp-python and OpenAI endpoints with GBNF grammar support (like the llama-cpp-python server) and the llama.cpp backend server. It works by generating a formal GGML-BNF grammar of the user defined structures and functions, which is then used by llama.cpp to generate text valid to that grammar. In contrast to most GBNF grammar generators it also supports nested objects, dictionaries, enums and lists of them.

llama_ros
This repository provides a set of ROS 2 packages to integrate llama.cpp into ROS 2. By using the llama_ros packages, you can easily incorporate the powerful optimization capabilities of llama.cpp into your ROS 2 projects by running GGUF-based LLMs and VLMs.

MITSUHA
OneReality is a virtual waifu/assistant that you can speak to through your mic and it'll speak back to you! It has many features such as: * You can speak to her with a mic * It can speak back to you * Has short-term memory and long-term memory * Can open apps * Smarter than you * Fluent in English, Japanese, Korean, and Chinese * Can control your smart home like Alexa if you set up Tuya (more info in Prerequisites) It is built with Python, Llama-cpp-python, Whisper, SpeechRecognition, PocketSphinx, VITS-fast-fine-tuning, VITS-simple-api, HyperDB, Sentence Transformers, and Tuya Cloud IoT.

wenxin-starter
WenXin-Starter is a spring-boot-starter for Baidu's "Wenxin Qianfan WENXINWORKSHOP" large model, which can help you quickly access Baidu's AI capabilities. It fully integrates the official API documentation of Wenxin Qianfan. Supports text-to-image generation, built-in dialogue memory, and supports streaming return of dialogue. Supports QPS control of a single model and supports queuing mechanism. Plugins will be added soon.

FlexFlow
FlexFlow Serve is an open-source compiler and distributed system for **low latency**, **high performance** LLM serving. FlexFlow Serve outperforms existing systems by 1.3-2.0x for single-node, multi-GPU inference and by 1.4-2.4x for multi-node, multi-GPU inference.