
cocoindex
Data transformation framework for AI. Ultra performant, with incremental processing. 🌟 Star if you like it!
Stars: 6055
CocoIndex is the world's first open-source engine that supports both custom transformation logic and incremental updates specialized for data indexing. Users declare the transformation, CocoIndex creates & maintains an index, and keeps the derived index up to date based on source update, with minimal computation and changes. It provides a Python library for data indexing with features like text embedding, code embedding, PDF parsing, and more. The tool is designed to simplify the process of indexing data for semantic search and structured information extraction.
README:



![]()
![]()
![]()

Ultra performant data transformation framework for AI, with core engine written in Rust. Support incremental processing and data lineage out-of-box. Exceptional developer velocity. Production-ready at day 0.
⭐ Drop a star to help us grow!

CocoIndex makes it effortless to transform data with AI, and keep source data and target in sync. Whether you’re building a vector index, creating knowledge graphs for context engineering or performing any custom data transformations — goes beyond SQL.

Just declare transformation in dataflow with ~100 lines of python
# import
data['content'] = flow_builder.add_source(...)
# transform
data['out'] = data['content']
.transform(...)
.transform(...)
# collect data
collector.collect(...)
# export to db, vector db, graph db ...
collector.export(...)CocoIndex follows the idea of Dataflow programming model. Each transformation creates a new field solely based on input fields, without hidden states and value mutation. All data before/after each transformation is observable, with lineage out of the box.
Particularly, developers don't explicitly mutate data by creating, updating and deleting. They just need to define transformation/formula for a set of source data.
Native builtins for different source, targets and transformations. Standardize interface, make it 1-line code switch between different components - as easy as assembling building blocks.

CocoIndex keep source data and target in sync effortlessly.
It has out-of-box support for incremental indexing:
- minimal recomputation on source or logic change.
- (re-)processing necessary portions; reuse cache when possible
If you're new to CocoIndex, we recommend checking out
- Install CocoIndex Python library
pip install -U cocoindex-
Install Postgres if you don't have one. CocoIndex uses it for incremental processing.
-
(Optional) Install Claude Code skill for enhanced development experience. Run these commands in Claude Code:
/plugin marketplace add cocoindex-io/cocoindex-claude
/plugin install cocoindex-skills@cocoindex
Follow Quick Start Guide to define your first indexing flow. An example flow looks like:
@cocoindex.flow_def(name="TextEmbedding")
def text_embedding_flow(flow_builder: cocoindex.FlowBuilder, data_scope: cocoindex.DataScope):
# Add a data source to read files from a directory
data_scope["documents"] = flow_builder.add_source(cocoindex.sources.LocalFile(path="markdown_files"))
# Add a collector for data to be exported to the vector index
doc_embeddings = data_scope.add_collector()
# Transform data of each document
with data_scope["documents"].row() as doc:
# Split the document into chunks, put into `chunks` field
doc["chunks"] = doc["content"].transform(
cocoindex.functions.SplitRecursively(),
language="markdown", chunk_size=2000, chunk_overlap=500)
# Transform data of each chunk
with doc["chunks"].row() as chunk:
# Embed the chunk, put into `embedding` field
chunk["embedding"] = chunk["text"].transform(
cocoindex.functions.SentenceTransformerEmbed(
model="sentence-transformers/all-MiniLM-L6-v2"))
# Collect the chunk into the collector.
doc_embeddings.collect(filename=doc["filename"], location=chunk["location"],
text=chunk["text"], embedding=chunk["embedding"])
# Export collected data to a vector index.
doc_embeddings.export(
"doc_embeddings",
cocoindex.targets.Postgres(),
primary_key_fields=["filename", "location"],
vector_indexes=[
cocoindex.VectorIndexDef(
field_name="embedding",
metric=cocoindex.VectorSimilarityMetric.COSINE_SIMILARITY)])It defines an index flow like this:
| Example | Description |
|---|---|
| Text Embedding | Index text documents with embeddings for semantic search |
| Code Embedding | Index code embeddings for semantic search |
| PDF Embedding | Parse PDF and index text embeddings for semantic search |
| PDF Elements Embedding | Extract text and images from PDFs; embed text with SentenceTransformers and images with CLIP; store in Qdrant for multimodal search |
| Manuals LLM Extraction | Extract structured information from a manual using LLM |
| Amazon S3 Embedding | Index text documents from Amazon S3 |
| Azure Blob Storage Embedding | Index text documents from Azure Blob Storage |
| Google Drive Text Embedding | Index text documents from Google Drive |
| Meeting Notes to Knowledge Graph | Extract structured meeting info from Google Drive and build a knowledge graph |
| Docs to Knowledge Graph | Extract relationships from Markdown documents and build a knowledge graph |
| Embeddings to Qdrant | Index documents in a Qdrant collection for semantic search |
| Embeddings to LanceDB | Index documents in a LanceDB collection for semantic search |
| FastAPI Server with Docker | Run the semantic search server in a Dockerized FastAPI setup |
| Product Recommendation | Build real-time product recommendations with LLM and graph database |
| Image Search with Vision API | Generates detailed captions for images using a vision model, embeds them, enables live-updating semantic search via FastAPI and served on a React frontend |
| Face Recognition | Recognize faces in images and build embedding index |
| Paper Metadata | Index papers in PDF files, and build metadata tables for each paper |
| Multi Format Indexing | Build visual document index from PDFs and images with ColPali for semantic search |
| Custom Source HackerNews | Index HackerNews threads and comments, using CocoIndex Custom Source |
| Custom Output Files | Convert markdown files to HTML files and save them to a local directory, using CocoIndex Custom Targets |
| Patient intake form extraction | Use LLM to extract structured data from patient intake forms with different formats |
| HackerNews Trending Topics | Extract trending topics from HackerNews threads and comments, using CocoIndex Custom Source and LLM |
| Patient Intake Form Extraction with BAML | Extract structured data from patient intake forms using BAML |
| Patient Intake Form Extraction with DSPy | Extract structured data from patient intake forms using DSPy |
More coming and stay tuned 👀!
For detailed documentation, visit CocoIndex Documentation, including a Quickstart guide.
We love contributions from our community ❤️. For details on contributing or running the project for development, check out our contributing guide.
Welcome with a huge coconut hug 🥥⋆。˚🤗. We are super excited for community contributions of all kinds - whether it's code improvements, documentation updates, issue reports, feature requests, and discussions in our Discord.
Join our community here:
- 🌟 Star us on GitHub
- 👋 Join our Discord community
▶️ Subscribe to our YouTube channel- 📜 Read our blog posts
We are constantly improving, and more features and examples are coming soon. If you love this project, please drop us a star ⭐ at GitHub repo
CocoIndex is Apache 2.0 licensed.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for cocoindex
Similar Open Source Tools
cocoindex
CocoIndex is the world's first open-source engine that supports both custom transformation logic and incremental updates specialized for data indexing. Users declare the transformation, CocoIndex creates & maintains an index, and keeps the derived index up to date based on source update, with minimal computation and changes. It provides a Python library for data indexing with features like text embedding, code embedding, PDF parsing, and more. The tool is designed to simplify the process of indexing data for semantic search and structured information extraction.

txtai
Txtai is an all-in-one embeddings database for semantic search, LLM orchestration, and language model workflows. It combines vector indexes, graph networks, and relational databases to enable vector search with SQL, topic modeling, retrieval augmented generation, and more. Txtai can stand alone or serve as a knowledge source for large language models (LLMs). Key features include vector search with SQL, object storage, topic modeling, graph analysis, multimodal indexing, embedding creation for various data types, pipelines powered by language models, workflows to connect pipelines, and support for Python, JavaScript, Java, Rust, and Go. Txtai is open-source under the Apache 2.0 license.

beeai-framework
BeeAI Framework is a versatile tool for building production-ready multi-agent systems. It offers flexibility in orchestrating agents, seamless integration with various models and tools, and production-grade controls for scaling. The framework supports Python and TypeScript libraries, enabling users to implement simple to complex multi-agent patterns, connect with AI services, and optimize token usage and resource management.
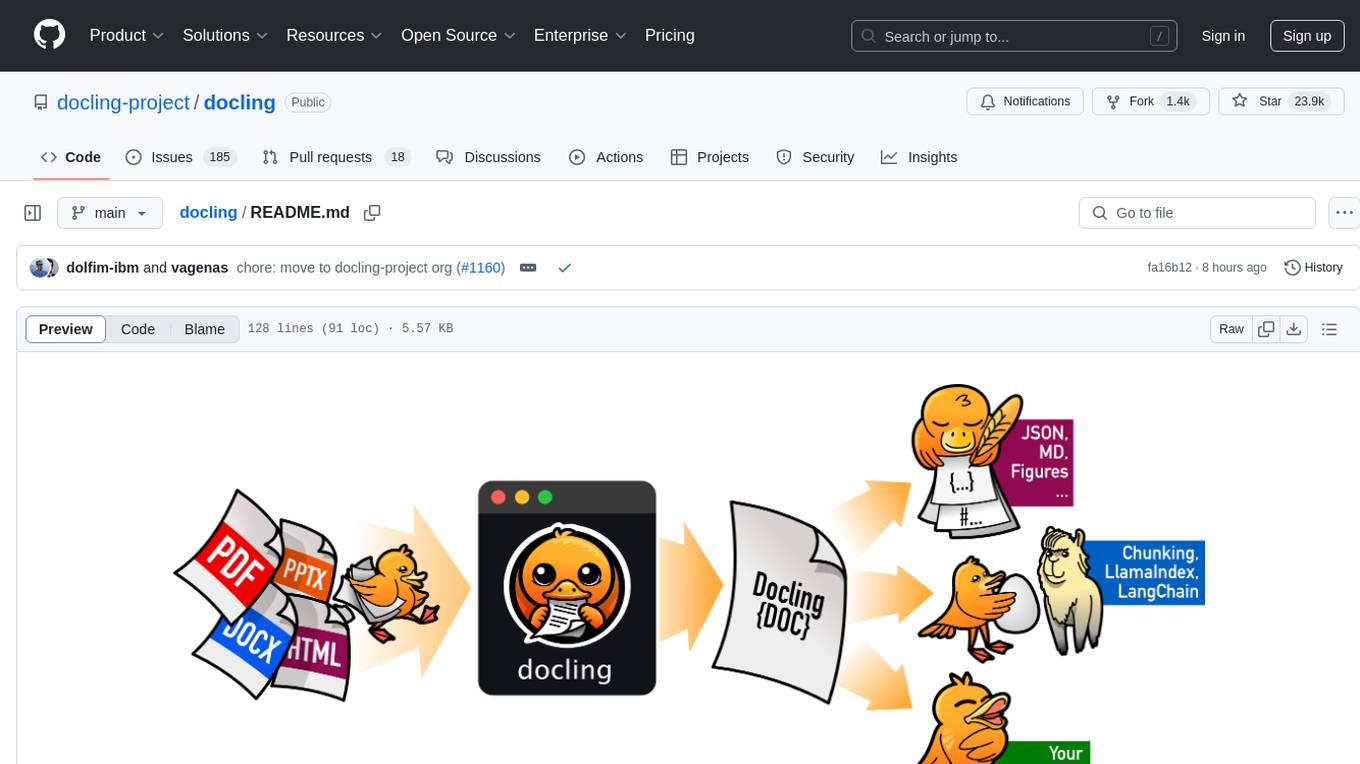
docling
Docling simplifies document processing, parsing diverse formats including advanced PDF understanding, and providing seamless integrations with the general AI ecosystem. It offers features such as parsing multiple document formats, advanced PDF understanding, unified DoclingDocument representation format, various export formats, local execution capabilities, plug-and-play integrations with agentic AI tools, extensive OCR support, and a simple CLI. Coming soon features include metadata extraction, visual language models, chart understanding, and complex chemistry understanding. Docling is installed via pip and works on macOS, Linux, and Windows environments. It provides detailed documentation, examples, integrations with popular frameworks, and support through the discussion section. The codebase is under the MIT license and has been developed by IBM.

superduperdb
SuperDuperDB is a Python framework for integrating AI models, APIs, and vector search engines directly with your existing databases, including hosting of your own models, streaming inference and scalable model training/fine-tuning. Build, deploy and manage any AI application without the need for complex pipelines, infrastructure as well as specialized vector databases, and moving our data there, by integrating AI at your data's source: - Generative AI, LLMs, RAG, vector search - Standard machine learning use-cases (classification, segmentation, regression, forecasting recommendation etc.) - Custom AI use-cases involving specialized models - Even the most complex applications/workflows in which different models work together SuperDuperDB is **not** a database. Think `db = superduper(db)`: SuperDuperDB transforms your databases into an intelligent platform that allows you to leverage the full AI and Python ecosystem. A single development and deployment environment for all your AI applications in one place, fully scalable and easy to manage.
docling
Docling is a tool that bundles PDF document conversion to JSON and Markdown in an easy, self-contained package. It can convert any PDF document to JSON or Markdown format, understand detailed page layout, reading order, recover table structures, extract metadata such as title, authors, references, and language, and optionally apply OCR for scanned PDFs. The tool is designed to be stable, lightning fast, and suitable for macOS and Linux environments.

langchain_dart
LangChain.dart is a Dart port of the popular LangChain Python framework created by Harrison Chase. LangChain provides a set of ready-to-use components for working with language models and a standard interface for chaining them together to formulate more advanced use cases (e.g. chatbots, Q&A with RAG, agents, summarization, extraction, etc.). The components can be grouped into a few core modules: * **Model I/O:** LangChain offers a unified API for interacting with various LLM providers (e.g. OpenAI, Google, Mistral, Ollama, etc.), allowing developers to switch between them with ease. Additionally, it provides tools for managing model inputs (prompt templates and example selectors) and parsing the resulting model outputs (output parsers). * **Retrieval:** assists in loading user data (via document loaders), transforming it (with text splitters), extracting its meaning (using embedding models), storing (in vector stores) and retrieving it (through retrievers) so that it can be used to ground the model's responses (i.e. Retrieval-Augmented Generation or RAG). * **Agents:** "bots" that leverage LLMs to make informed decisions about which available tools (such as web search, calculators, database lookup, etc.) to use to accomplish the designated task. The different components can be composed together using the LangChain Expression Language (LCEL).

biochatter
Generative AI models have shown tremendous usefulness in increasing accessibility and automation of a wide range of tasks. This repository contains the `biochatter` Python package, a generic backend library for the connection of biomedical applications to conversational AI. It aims to provide a common framework for deploying, testing, and evaluating diverse models and auxiliary technologies in the biomedical domain. BioChatter is part of the BioCypher ecosystem, connecting natively to BioCypher knowledge graphs.

mage-ai
Mage is an open-source data pipeline tool for transforming and integrating data. It offers an easy developer experience, engineering best practices built-in, and data as a first-class citizen. Mage makes it easy to build, preview, and launch data pipelines, and provides observability and scaling capabilities. It supports data integrations, streaming pipelines, and dbt integration.

FlagEmbedding
FlagEmbedding focuses on retrieval-augmented LLMs, consisting of the following projects currently: * **Long-Context LLM** : Activation Beacon * **Fine-tuning of LM** : LM-Cocktail * **Embedding Model** : Visualized-BGE, BGE-M3, LLM Embedder, BGE Embedding * **Reranker Model** : llm rerankers, BGE Reranker * **Benchmark** : C-MTEB
palico-ai
Palico AI is a tech stack designed for rapid iteration of LLM applications. It allows users to preview changes instantly, improve performance through experiments, debug issues with logs and tracing, deploy applications behind a REST API, and manage applications with a UI control panel. Users have complete flexibility in building their applications with Palico, integrating with various tools and libraries. The tool enables users to swap models, prompts, and logic easily using AppConfig. It also facilitates performance improvement through experiments and provides options for deploying applications to cloud providers or using managed hosting. Contributions to the project are welcomed, with easy ways to get involved by picking issues labeled as 'good first issue'.

autogen
AutoGen is a framework that enables the development of LLM applications using multiple agents that can converse with each other to solve tasks. AutoGen agents are customizable, conversable, and seamlessly allow human participation. They can operate in various modes that employ combinations of LLMs, human inputs, and tools.

PromptClip
PromptClip is a tool that allows developers to create video clips using LLM prompts. Users can upload videos from various sources, prompt the video in natural language, use different LLM models, instantly watch the generated clips, finetune the clips, and add music or image overlays. The tool provides a seamless way to extract specific moments from videos based on user queries, making video editing and content creation more efficient and intuitive.

auto-news
Auto-News is an automatic news aggregator tool that utilizes Large Language Models (LLM) to pull information from various sources such as Tweets, RSS feeds, YouTube videos, web articles, Reddit, and journal notes. The tool aims to help users efficiently read and filter content based on personal interests, providing a unified reading experience and organizing information effectively. It features feed aggregation with summarization, transcript generation for videos and articles, noise reduction, task organization, and deep dive topic exploration. The tool supports multiple LLM backends, offers weekly top-k aggregations, and can be deployed on Linux/MacOS using docker-compose or Kubernetes.

tidb
TiDB is an open-source distributed SQL database that supports Hybrid Transactional and Analytical Processing (HTAP) workloads. It is MySQL compatible and features horizontal scalability, strong consistency, and high availability.
anx-reader
Anx Reader is a meticulously designed e-book reader tailored for book enthusiasts. It boasts powerful AI functionalities and supports various e-book formats, enhancing the reading experience. With a modern interface, the tool aims to provide a seamless and enjoyable reading journey. It offers rich format support, seamless sync across devices, smart AI assistance, personalized reading experiences, professional reading analytics, a powerful note system, practical tools, and cross-platform support. The tool is continuously evolving with features like UI adaptation for tablets, page-turning animation, TTS voice reading, reading fonts, translation, and more in the pipeline.
For similar tasks

instructor-php
Instructor for PHP is a library designed for structured data extraction in PHP, powered by Large Language Models (LLMs). It simplifies the process of extracting structured, validated data from unstructured text or chat sequences. Instructor enhances workflow by providing a response model, validation capabilities, and max retries for requests. It supports classes as response models and provides features like partial results, string input, extracting scalar and enum values, and specifying data models using PHP type hints or DocBlock comments. The library allows customization of validation and provides detailed event notifications during request processing. Instructor is compatible with PHP 8.2+ and leverages PHP reflection, Symfony components, and SaloonPHP for communication with LLM API providers.
cocoindex
CocoIndex is the world's first open-source engine that supports both custom transformation logic and incremental updates specialized for data indexing. Users declare the transformation, CocoIndex creates & maintains an index, and keeps the derived index up to date based on source update, with minimal computation and changes. It provides a Python library for data indexing with features like text embedding, code embedding, PDF parsing, and more. The tool is designed to simplify the process of indexing data for semantic search and structured information extraction.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.