
kernel-memory
RAG architecture: index and query any data using LLM and natural language, track sources, show citations, asynchronous memory patterns.
Stars: 1848

Kernel Memory (KM) is a multi-modal AI Service specialized in the efficient indexing of datasets through custom continuous data hybrid pipelines, with support for Retrieval Augmented Generation (RAG), synthetic memory, prompt engineering, and custom semantic memory processing. KM is available as a Web Service, as a Docker container, a Plugin for ChatGPT/Copilot/Semantic Kernel, and as a .NET library for embedded applications. Utilizing advanced embeddings and LLMs, the system enables Natural Language querying for obtaining answers from the indexed data, complete with citations and links to the original sources. Designed for seamless integration as a Plugin with Semantic Kernel, Microsoft Copilot and ChatGPT, Kernel Memory enhances data-driven features in applications built for most popular AI platforms.
README:





This repository presents best practices and a reference implementation for Memory in specific AI and LLMs application scenarios. Please note that the code provided serves as a demonstration and is not an officially supported Microsoft offering.
Kernel Memory (KM) is a multi-modal AI Service specialized in the efficient indexing of datasets through custom continuous data hybrid pipelines, with support for Retrieval Augmented Generation (RAG), synthetic memory, prompt engineering, and custom semantic memory processing.
KM is available as a Web Service, as a Docker container, a Plugin for ChatGPT/Copilot/Semantic Kernel, and as a .NET library for embedded applications.
Utilizing advanced embeddings and LLMs, the system enables Natural Language querying for obtaining answers from the indexed data, complete with citations and links to the original sources.
Kernel Memory is designed for seamless integration as a Plugin with Semantic Kernel, Microsoft Copilot and ChatGPT.

Kernel Memory can be deployed in various configurations, including as a Service in Azure. To learn more about deploying Kernel Memory in Azure, please refer to the Azure deployment guide. For detailed instructions on deploying to Azure, you can check the infrastructure documentation.
If you are already familiar with these resources, you can quickly deploy by clicking the following button.

🔗 See also: Kernel Memory via Docker and Serverless Kernel Memory with Azure services example.
Kernel Memory can be easily run and imported in other projects also via .NET Aspire. For example:
var builder = DistributedApplication.CreateBuilder();
builder.AddContainer("kernel-memory", "kernelmemory/service")
.WithEnvironment("KernelMemory__TextGeneratorType", "OpenAI")
.WithEnvironment("KernelMemory__DataIngestion__EmbeddingGeneratorTypes__0", "OpenAI")
.WithEnvironment("KernelMemory__Retrieval__EmbeddingGeneratorType", "OpenAI")
.WithEnvironment("KernelMemory__Services__OpenAI__APIKey", "...your OpenAI key...");
builder.Build().Run();
The example show the default documents ingestion pipeline:
- Extract text: automatically recognize the file format and extract the information
- Partition the text in small chunks, ready for search and RAG prompts
- Extract embeddings using any LLM embedding generator
- Save embeddings into a vector index such as Azure AI Search, Qdrant or other DBs.
The example shows how to safeguard private information specifying who owns each document, and how to organize data for search and faceted navigation, using Tags.
#r "nuget: Microsoft.KernelMemory.WebClient" var memory = new MemoryWebClient("http://127.0.0.1:9001"); // <== URL of KM web service // Import a file await memory.ImportDocumentAsync("meeting-transcript.docx"); // Import a file specifying Document ID and Tags await memory.ImportDocumentAsync("business-plan.docx", new Document("doc01") .AddTag("user", "[email protected]") .AddTag("collection", "business") .AddTag("collection", "plans") .AddTag("fiscalYear", "2025"));
import requests # Files to import files = { "file1": ("business-plan.docx", open("business-plan.docx", "rb")), } # Tags to apply, used by queries to filter memory data = { "documentId": "doc01", "tags": [ "user:[email protected]", "collection:business", "collection:plans", "fiscalYear:2025" ] } response = requests.post("http://127.0.0.1:9001/upload", files=files, data=data)
var memory = new KernelMemoryBuilder() .WithOpenAIDefaults(Environment.GetEnvironmentVariable("OPENAI_API_KEY")) .Build<MemoryServerless>(); // Import a file await memory.ImportDocumentAsync("meeting-transcript.docx"); // Import a file specifying Document ID and Tags await memory.ImportDocumentAsync("business-plan.docx", new Document("doc01") .AddTag("collection", "business") .AddTag("collection", "plans") .AddTag("fiscalYear", "2025"));
Asking questions, running RAG prompts, and filtering by user and other criteria is simple, with answers including citations and all the information needed to verify their accuracy, pointing to which documents ground the response.
Questions can be asked targeting the entire memory set, or a subset using filters, e.g. to implement security filters.
var answer1 = await memory.AskAsync("How many people attended the meeting?"); var answer2 = await memory.AskAsync("what's the project timeline?", filter: MemoryFilters.ByTag("user", "[email protected]"));
When generating answers with LLMs, the result includes a token usage report.
foreach (var report in tokenUsage) { Console.WriteLine($"{report.ServiceType}: {report.ModelName} ({report.ModelType})"); Console.WriteLine($"- Input : {report.ServiceTokensIn}"); Console.WriteLine($"- Output: {report.ServiceTokensOut}"); }Azure OpenAI: gpt-4o (TextGeneration)
- Input : 24356 tokens
- Output: 103 tokens
await memory.ImportFileAsync("NASA-news.pdf"); var answer = await memory.AskAsync("Any news from NASA about Orion?"); Console.WriteLine(answer.Result + "/n"); foreach (var x in answer.RelevantSources) { Console.WriteLine($" * {x.SourceName} -- {x.Partitions.First().LastUpdate:D}"); }Yes, there is news from NASA about the Orion spacecraft. NASA has invited the media to see a new test version [......] For more information about the Artemis program, you can visit the NASA website.
- NASA-news.pdf -- Tuesday, August 1, 2023
import requests import json data = { "question": "what's the project timeline?", "filters": [ {"user": ["[email protected]"]} ] } response = requests.post( "http://127.0.0.1:9001/ask", headers={"Content-Type": "application/json"}, data=json.dumps(data), ).json() print(response["text"])
curl http://127.0.0.1:9001/ask -d'{"query":"Any news from NASA about Orion?"}' -H 'Content-Type: application/json'{ "Query": "Any news from NASA about Orion?", "Text": "Yes, there is news from NASA about the Orion spacecraft. NASA has invited the media to see a new test version [......] For more information about the Artemis program, you can visit the NASA website.", "RelevantSources": [ { "Link": "...", "SourceContentType": "application/pdf", "SourceName": "file5-NASA-news.pdf", "Partitions": [ { "Text": "Skip to main content\nJul 28, 2023\nMEDIA ADVISORY M23-095\nNASA Invites Media to See Recovery Craft for\nArtemis Moon Mission\n(/sites/default/files/thumbnails/image/ksc-20230725-ph-fmx01_0003orig.jpg)\nAboard the [......] to Mars (/topics/moon-to-\nmars/),Orion Spacecraft (/exploration/systems/orion/index.html)\nNASA Invites Media to See Recovery Craft for Artemis Moon Miss... https://www.nasa.gov/press-release/nasa-invites-media-to-see-recov...\n2 of 3 7/28/23, 4:51 PM", "Relevance": 0.8430657, "SizeInTokens": 863, "LastUpdate": "2023-08-01T08:15:02-07:00" } ] } ] }
The OpenAPI schema ("swagger") is available at http://127.0.0.1:9001/swagger/index.html when running the service locally with OpenAPI enabled. Here's a copy.
🔗 See also:
If you want to give the service a quick test, use the following command to start the Kernel Memory Service using OpenAI:
docker run -e OPENAI_API_KEY="..." -it --rm -p 9001:9001 kernelmemory/serviceIf you prefer using custom settings and services such as Azure OpenAI, Azure
Document Intelligence, etc., you should create an appsettings.Development.json
file overriding the default values set in appsettings.json, or using the
configuration wizard included:
cd service/Service
dotnet run setup
Then run this command to start the Docker image with the configuration just created:
on Windows:
docker run --volume .\appsettings.Development.json:/app/appsettings.Production.json -it --rm -p 9001:9001 kernelmemory/service
on Linux / macOS:
docker run --volume ./appsettings.Development.json:/app/appsettings.Production.json -it --rm -p 9001:9001 kernelmemory/service
🔗 See also:
Depending on your scenarios, you might want to run all the code remotely through an asynchronous and scalable service, or locally inside your process.

If you're importing small files, and use only .NET and can block the application process while importing documents, then local-in-process execution can be fine, using the MemoryServerless described below.
However, if you are in one of these scenarios:
- My app is written in TypeScript, Java, Rust, or some other language
- I'd just like a web service to import data and send questions to answer
- I'm importing big documents that can require minutes to process, and I don't want to block the user interface
- I need memory import to run independently, supporting failures and retry logic
- I want to define custom pipelines mixing multiple languages like Python, TypeScript, etc
then you're likely looking for a Memory Service, and you can deploy Kernel Memory as a backend service, using the default ingestion logic, or your custom workflow including steps coded in Python/TypeScript/Java/etc., leveraging the asynchronous non-blocking memory encoding process, uploading documents and asking questions using the MemoryWebClient.

Here you can find a complete set of instruction about how to run the Kernel Memory service.
Kernel Memory works and scales at best when running as an asynchronous Web Service, allowing to ingest thousands of documents and information without blocking your app.
However, Kernel Memory can also run in serverless mode, embedding MemoryServerless class instance
in .NET backend/console/desktop apps in synchronous mode.
Each request is processed immediately, although calling clients are responsible for handling
transient errors.

Kernel Memory relies on external services to run stateful pipelines, store data, handle embeddings, and generate text responses. The project includes extensions that allow customization of file storage, queues, vector stores, and LLMs to fit specific requirements.
- AI: Azure OpenAI, OpenAI, ONNX, Ollama, Anthropic, Azure AI Document Intelligence, Azure AI Content Safety
- Vector Store: Azure AI Search, Postgres, SQL Server, Elasticsearch, Qdrant, Redis, MongoDB Atlas, In memory store
- File Storage: Azure Blob storage, AWS S3, MongoDB Atlas, Local disk, In memory storage
- Ingestion pipelines: Azure Queues, RabbitMQ, In memory queues
Document ingestion operates as a stateful pipeline, executing steps in a defined sequence. By default, Kernel Memory employs a pipeline to extract text, chunk content, vectorize, and store data.
If you need a custom data pipeline, you can modify the sequence, add new steps, or replace existing ones by providing custom “handlers” for each desired stage. This allows complete flexibility in defining how data is processed. For example:
// Memory setup, e.g. how to calculate and where to store embeddings
var memoryBuilder = new KernelMemoryBuilder()
.WithoutDefaultHandlers()
.WithOpenAIDefaults(Environment.GetEnvironmentVariable("OPENAI_API_KEY"));
var memory = memoryBuilder.Build();
// Plug in custom .NET handlers
memory.Orchestrator.AddHandler<MyHandler1>("step1");
memory.Orchestrator.AddHandler<MyHandler2>("step2");
memory.Orchestrator.AddHandler<MyHandler3>("step3");
// Use the custom handlers with the memory object
await memory.ImportDocumentAsync(
new Document("mytest001")
.AddFile("file1.docx")
.AddFile("file2.pdf"),
steps: new[] { "step1", "step2", "step3" });
Semantic Kernel is an SDK for C#, Python, and Java used to develop solutions with AI. SK includes libraries that wrap direct calls to databases, supporting vector search.
Semantic Kernel is maintained in three languages, while the list of supported storage engines (known as "connectors") varies across languages.
Kernel Memory (KM) is a SERVICE built on Semantic Kernel, with additional features developed for RAG, Security, and Cloud deployment. As a service, KM can be used from any language, tool, or platform, e.g. browser extensions and ChatGPT assistants.
Kernel Memory provides several features out of the scope of Semantic Kernel, that would usually be developed manually, such as storing files, extracting text from documents, providing a framework to secure users' data, content moderation etc.
Kernel Memory is also leveraged to explore new AI patterns, which sometimes are backported to Semantic Kernel and Microsoft libraries, for instance vector stores flexible schemas, advanced filtering, authentications.
Here's comparison table:
| Feature | Kernel Memory | Semantic Kernel |
|---|---|---|
| Runtime | Memory as a Service, Web service | SDK packages |
| Data formats | Web pages, PDF, Images, Word, PowerPoint, Excel, Markdown, Text, JSON | Text only |
| Language support | Any language | .NET, Python, Java |
| RAG | Yes | - |
| Cloud deployment | Yes | - |
- Collection of Jupyter notebooks with various scenarios
- Using Kernel Memory web service to upload documents and answer questions
- Importing files and asking question without running the service (serverless mode)
- Kernel Memory RAG with Azure services
- Kernel Memory with .NET Aspire
- Using KM Plugin for Semantic Kernel
- Customizations
- Processing files with custom logic (custom handlers) in serverless mode
- Processing files with custom logic (custom handlers) in asynchronous mode
- Customizing RAG and summarization prompts
- Custom partitioning/text chunking options
- Using a custom embedding/vector generator
- Using custom content decoders
- Using a custom web scraper to fetch web pages
- Writing and using a custom ingestion handler
- Using Context Parameters to customize RAG prompt during a request
- Local models and external connectors
- Upload files and ask questions from command line using curl
- Summarizing documents, using synthetic memories
- Hybrid Search with Azure AI Search
- Running a single asynchronous pipeline handler as a standalone service
- Integrating Memory with ASP.NET applications and controllers
- Sample code showing how to extract text from files
- .NET configuration and logging
- Expanding chunks retrieving adjacent partitions
- Creating a Memory instance without KernelMemoryBuilder
- Intent Detection
- Fetching data from Discord
- Test project using KM package from nuget.org
- .NET appsettings.json generator
- Curl script to upload files
- Curl script to ask questions
- Curl script to search documents
- Script to start Qdrant for development tasks
- Script to start Elasticsearch for development tasks
- Script to start MS SQL Server for development tasks
- Script to start Redis for development tasks
- Script to start RabbitMQ for development tasks
- Script to start MongoDB Atlas for development tasks
-
Microsoft.KernelMemory.WebClient: .NET web client to call a running instance of Kernel Memory web service.
-
Microsoft.KernelMemory: Kernel Memory library including all extensions and clients, it can be used to build custom pipelines and handlers. It contains also the serverless client to use memory in a synchronous way without the web service.
-
Microsoft.KernelMemory.Service.AspNetCore: an extension to load Kernel Memory into your ASP.NET apps.
-
Microsoft.KernelMemory.SemanticKernelPlugin: a Memory plugin for Semantic Kernel, replacing the original Semantic Memory available in SK.
-
Microsoft.KernelMemory.* packages: Kernel Memory Core and all KM extensions split into distinct packages.




Kernel Memory service offers a Web API out of the box, including the OpenAPI swagger documentation that you can leverage to test the API and create custom web clients. For instance, after starting the service locally, see http://127.0.0.1:9001/swagger/index.html.
A .NET Web Client and a Semantic Kernel plugin are available, see the nugets packages above.
For Python, TypeScript, Java and other languages we recommend leveraging the Web Service. We also welcome PR contributions to support more languages.









![dependabot[bot]](https://avatars.githubusercontent.com/u/49699333?v=4&s=110)








































For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for kernel-memory
Similar Open Source Tools
kernel-memory
Kernel Memory (KM) is a multi-modal AI Service specialized in the efficient indexing of datasets through custom continuous data hybrid pipelines, with support for Retrieval Augmented Generation (RAG), synthetic memory, prompt engineering, and custom semantic memory processing. KM is available as a Web Service, as a Docker container, a Plugin for ChatGPT/Copilot/Semantic Kernel, and as a .NET library for embedded applications. Utilizing advanced embeddings and LLMs, the system enables Natural Language querying for obtaining answers from the indexed data, complete with citations and links to the original sources. Designed for seamless integration as a Plugin with Semantic Kernel, Microsoft Copilot and ChatGPT, Kernel Memory enhances data-driven features in applications built for most popular AI platforms.
agentica
Agentica is a specialized Agentic AI library focused on LLM Function Calling. Users can provide Swagger/OpenAPI documents or TypeScript class types to Agentica for seamless functionality. The library simplifies AI development by handling various tasks effortlessly.
CrackSQL
CrackSQL is a powerful SQL dialect translation tool that integrates rule-based strategies with large language models (LLMs) for high accuracy. It enables seamless conversion between dialects (e.g., PostgreSQL → MySQL) with flexible access through Python API, command line, and web interface. The tool supports extensive dialect compatibility, precision & advanced processing, and versatile access & integration. It offers three modes for dialect translation and demonstrates high translation accuracy over collected benchmarks. Users can deploy CrackSQL using PyPI package installation or source code installation methods. The tool can be extended to support additional syntax, new dialects, and improve translation efficiency. The project is actively maintained and welcomes contributions from the community.

Scrapegraph-ai
ScrapeGraphAI is a web scraping Python library that utilizes LLM and direct graph logic to create scraping pipelines for websites and local documents. It offers various standard scraping pipelines like SmartScraperGraph, SearchGraph, SpeechGraph, and ScriptCreatorGraph. Users can extract information by specifying prompts and input sources. The library supports different LLM APIs such as OpenAI, Groq, Azure, and Gemini, as well as local models using Ollama. ScrapeGraphAI is designed for data exploration and research purposes, providing a versatile tool for extracting information from web pages and generating outputs like Python scripts, audio summaries, and search results.
lance
Lance is a modern columnar data format optimized for ML workflows and datasets. It offers high-performance random access, vector search, zero-copy automatic versioning, and ecosystem integrations with Apache Arrow, Pandas, Polars, and DuckDB. Lance is designed to address the challenges of the ML development cycle, providing a unified data format for collection, exploration, analytics, feature engineering, training, evaluation, deployment, and monitoring. It aims to reduce data silos and streamline the ML development process.
inferable
Inferable is an open source platform that helps users build reliable LLM-powered agentic automations at scale. It offers a managed agent runtime, durable tool calling, zero network configuration, multiple language support, and is fully open source under the MIT license. Users can define functions, register them with Inferable, and create runs that utilize these functions to automate tasks. The platform supports Node.js/TypeScript, Go, .NET, and React, and provides SDKs, core services, and bootstrap templates for various languages.

glide
Glide is a cloud-native LLM gateway that provides a unified REST API for accessing various large language models (LLMs) from different providers. It handles LLMOps tasks such as model failover, caching, key management, and more, making it easy to integrate LLMs into applications. Glide supports popular LLM providers like OpenAI, Anthropic, Azure OpenAI, AWS Bedrock (Titan), Cohere, Google Gemini, OctoML, and Ollama. It offers high availability, performance, and observability, and provides SDKs for Python and NodeJS to simplify integration.
SynapseML
SynapseML (previously known as MMLSpark) is an open-source library that simplifies the creation of massively scalable machine learning (ML) pipelines. It provides simple, composable, and distributed APIs for various machine learning tasks such as text analytics, vision, anomaly detection, and more. Built on Apache Spark, SynapseML allows seamless integration of models into existing workflows. It supports training and evaluation on single-node, multi-node, and resizable clusters, enabling scalability without resource wastage. Compatible with Python, R, Scala, Java, and .NET, SynapseML abstracts over different data sources for easy experimentation. Requires Scala 2.12, Spark 3.4+, and Python 3.8+.
omnihuman
OmniHuman is an AI model designed to understand humanoids and text. It provides functionalities to process images and videos, generating text descriptions for human actions depicted in the visual content. The tool offers support for various tasks related to human pose recognition and action understanding. Users can easily integrate OmniHuman into their projects to enhance the capabilities of their applications in recognizing and interpreting human actions in images and videos.

auto-news
Auto-News is an automatic news aggregator tool that utilizes Large Language Models (LLM) to pull information from various sources such as Tweets, RSS feeds, YouTube videos, web articles, Reddit, and journal notes. The tool aims to help users efficiently read and filter content based on personal interests, providing a unified reading experience and organizing information effectively. It features feed aggregation with summarization, transcript generation for videos and articles, noise reduction, task organization, and deep dive topic exploration. The tool supports multiple LLM backends, offers weekly top-k aggregations, and can be deployed on Linux/MacOS using docker-compose or Kubernetes.
vecs
vecs is a Python client for managing and querying vector stores in PostgreSQL with the pgvector extension. It allows users to create collections of vectors with associated metadata, index the collections for fast search performance, and query the collections based on specified filters. The tool simplifies the process of working with vector data in a PostgreSQL database, making it easier to store, retrieve, and analyze vector information.
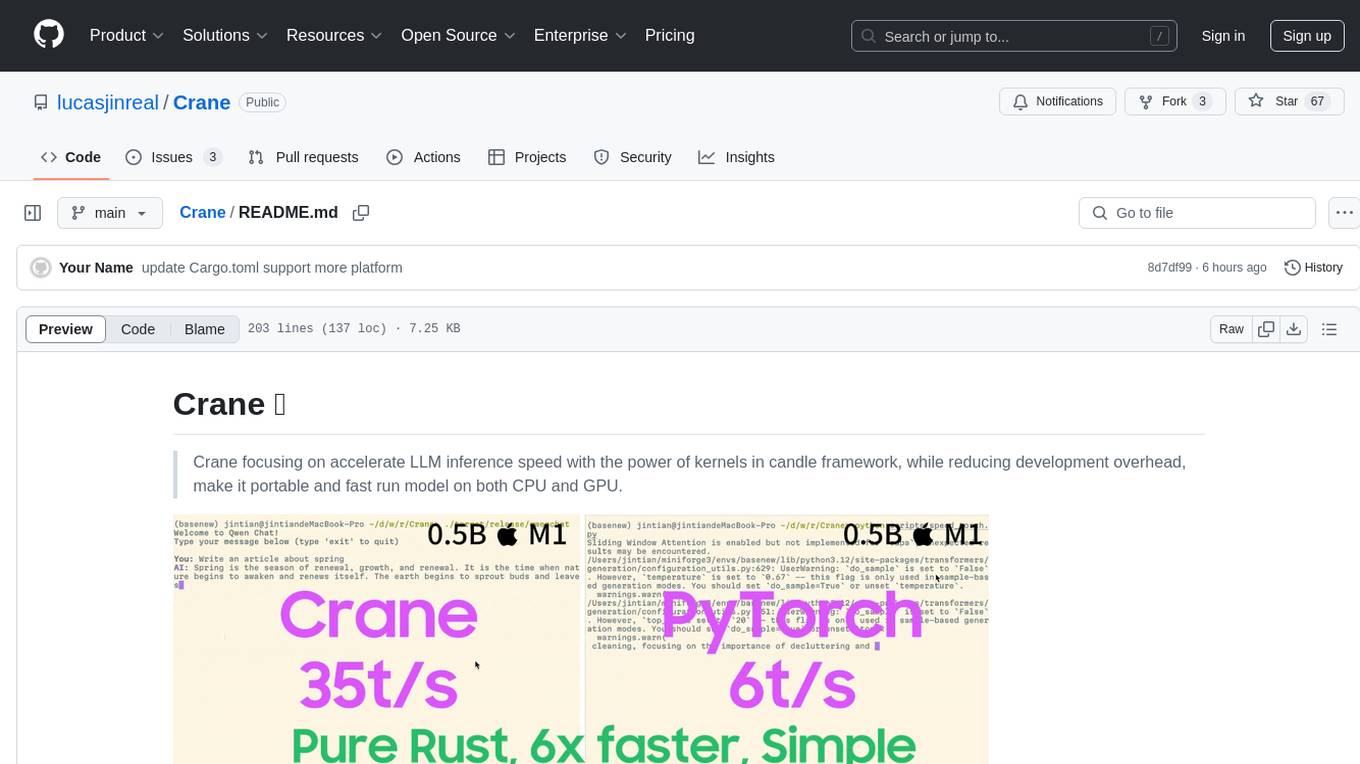
Crane
Crane is a high-performance inference framework leveraging Rust's Candle for maximum speed on CPU/GPU. It focuses on accelerating LLM inference speed with optimized kernels, reducing development overhead, and ensuring portability for running models on both CPU and GPU. Supported models include TTS systems like Spark-TTS and Orpheus-TTS, foundation models like Qwen2.5 series and basic LLMs, and multimodal models like Namo-R1 and Qwen2.5-VL. Key advantages of Crane include blazing-fast inference outperforming native PyTorch, Rust-powered to eliminate C++ complexity, Apple Silicon optimized for GPU acceleration via Metal, and hardware agnostic with a unified codebase for CPU/CUDA/Metal execution. Crane simplifies deployment with the ability to add new models with less than 100 lines of code in most cases.

lingo.dev
Replexica AI automates software localization end-to-end, producing authentic translations instantly across 60+ languages. Teams can do localization 100x faster with state-of-the-art quality, reaching more paying customers worldwide. The tool offers a GitHub Action for CI/CD automation and supports various formats like JSON, YAML, CSV, and Markdown. With lightning-fast AI localization, auto-updates, native quality translations, developer-friendly CLI, and scalability for startups and enterprise teams, Replexica is a top choice for efficient and effective software localization.

vision-parse
Vision Parse is a tool that leverages Vision Language Models to parse PDF documents into beautifully formatted markdown content. It offers smart content extraction, content formatting, multi-LLM support, PDF document support, and local model hosting using Ollama. Users can easily convert PDFs to markdown with high precision and preserve document hierarchy and styling. The tool supports multiple Vision LLM providers like OpenAI, LLama, and Gemini for accuracy and speed, making document processing efficient and effortless.

HuixiangDou
HuixiangDou is a **group chat** assistant based on LLM (Large Language Model). Advantages: 1. Design a two-stage pipeline of rejection and response to cope with group chat scenario, answer user questions without message flooding, see arxiv2401.08772 2. Low cost, requiring only 1.5GB memory and no need for training 3. Offers a complete suite of Web, Android, and pipeline source code, which is industrial-grade and commercially viable Check out the scenes in which HuixiangDou are running and join WeChat Group to try AI assistant inside. If this helps you, please give it a star ⭐
sophia
Sophia is an open-source TypeScript platform designed for autonomous AI agents and LLM based workflows. It aims to automate processes, review code, assist with refactorings, and support various integrations. The platform offers features like advanced autonomous agents, reasoning/planning inspired by Google's Self-Discover paper, memory and function call history, adaptive iterative planning, and more. Sophia supports multiple LLMs/services, CLI and web interface, human-in-the-loop interactions, flexible deployment options, observability with OpenTelemetry tracing, and specific agents for code editing, software engineering, and code review. It provides a flexible platform for the TypeScript community to expand and support various use cases and integrations.
For similar tasks
kernel-memory
Kernel Memory (KM) is a multi-modal AI Service specialized in the efficient indexing of datasets through custom continuous data hybrid pipelines, with support for Retrieval Augmented Generation (RAG), synthetic memory, prompt engineering, and custom semantic memory processing. KM is available as a Web Service, as a Docker container, a Plugin for ChatGPT/Copilot/Semantic Kernel, and as a .NET library for embedded applications. Utilizing advanced embeddings and LLMs, the system enables Natural Language querying for obtaining answers from the indexed data, complete with citations and links to the original sources. Designed for seamless integration as a Plugin with Semantic Kernel, Microsoft Copilot and ChatGPT, Kernel Memory enhances data-driven features in applications built for most popular AI platforms.

swirl-search
Swirl is an open-source software that allows users to simultaneously search multiple content sources and receive AI-ranked results. It connects to various data sources, including databases, public data services, and enterprise sources, and utilizes AI and LLMs to generate insights and answers based on the user's data. Swirl is easy to use, requiring only the download of a YML file, starting in Docker, and searching with Swirl. Users can add credentials to preloaded SearchProviders to access more sources. Swirl also offers integration with ChatGPT as a configured AI model. It adapts and distributes user queries to anything with a search API, re-ranking the unified results using Large Language Models without extracting or indexing anything. Swirl includes five Google Programmable Search Engines (PSEs) to get users up and running quickly. Key features of Swirl include Microsoft 365 integration, SearchProvider configurations, query adaptation, synchronous or asynchronous search federation, optional subscribe feature, pipelining of Processor stages, results stored in SQLite3 or PostgreSQL, built-in Query Transformation support, matching on word stems and handling of stopwords, duplicate detection, re-ranking of unified results using Cosine Vector Similarity, result mixers, page through all results requested, sample data sets, optional spell correction, optional search/result expiration service, easily extensible Connector and Mixer objects, and a welcoming community for collaboration and support.

paper-qa
PaperQA is a minimal package for question and answering from PDFs or text files, providing very good answers with in-text citations. It uses OpenAI Embeddings to embed and search documents, and follows a process of embedding docs and queries, searching for top passages, creating summaries, scoring and selecting relevant summaries, putting summaries into prompt, and generating answers. Users can customize prompts and use various models for embeddings and LLMs. The tool can be used asynchronously and supports adding documents from paths, files, or URLs.
quick-start-connectors
Cohere's Build-Your-Own-Connector framework allows integration of Cohere's Command LLM via the Chat API endpoint to any datastore/software holding text information with a search endpoint. Enables user queries grounded in proprietary information. Use-cases include question/answering, knowledge working, comms summary, and research. Repository provides code for popular datastores and a template connector. Requires Python 3.11+ and Poetry. Connectors can be built and deployed using Docker. Environment variables set authorization values. Pre-commits for linting. Connectors tailored to integrate with Cohere's Chat API for creating chatbots. Connectors return documents as JSON objects for Cohere's API to generate answers with citations.

llm-rag-workshop
The LLM RAG Workshop repository provides a workshop on using Large Language Models (LLMs) and Retrieval-Augmented Generation (RAG) to generate and understand text in a human-like manner. It includes instructions on setting up the environment, indexing Zoomcamp FAQ documents, creating a Q&A system, and using OpenAI for generation based on retrieved information. The repository focuses on enhancing language model responses with retrieved information from external sources, such as document databases or search engines, to improve factual accuracy and relevance of generated text.
RAGMeUp
RAG Me Up is a generic framework that enables users to perform Retrieve and Generate (RAG) on their own dataset easily. It consists of a small server and UIs for communication. Best run on GPU with 16GB vRAM. Users can combine RAG with fine-tuning using LLaMa2Lang repository. The tool allows configuration for LLM, data, LLM parameters, prompt, and document splitting. Funding is sought to democratize AI and advance its applications.
local-genAI-search
Local-GenAI Search is a local generative search engine powered by the Llama3 model, allowing users to ask questions about their local files and receive concise answers with relevant document references. It utilizes MS MARCO embeddings for semantic search and can run locally on a 32GB laptop or computer. The tool can be used to index local documents, search for information, and provide generative search services through a user interface.
nanoPerplexityAI
nanoPerplexityAI is an open-source implementation of a large language model service that fetches information from Google. It involves a simple architecture where the user query is checked by the language model, reformulated for Google search, and an answer is generated and saved in a markdown file. The tool requires minimal setup and is designed for easy visualization of answers.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.