
Scrapegraph-ai
Python scraper based on AI
Stars: 22677

ScrapeGraphAI is a web scraping Python library that utilizes LLM and direct graph logic to create scraping pipelines for websites and local documents. It offers various standard scraping pipelines like SmartScraperGraph, SearchGraph, SpeechGraph, and ScriptCreatorGraph. Users can extract information by specifying prompts and input sources. The library supports different LLM APIs such as OpenAI, Groq, Azure, and Gemini, as well as local models using Ollama. ScrapeGraphAI is designed for data exploration and research purposes, providing a versatile tool for extracting information from web pages and generating outputs like Python scripts, audio summaries, and search results.
README:
🚀 Looking for an even faster and simpler way to scrape at scale (only 5 lines of code)? Check out our enhanced version at ScrapeGraphAI.com! 🚀
English | 中文 | 日本語 | 한국어 | Русский | Türkçe | Deutsch | Español | français | Português

ScrapeGraphAI is a web scraping python library that uses LLM and direct graph logic to create scraping pipelines for websites and local documents (XML, HTML, JSON, Markdown, etc.).
Just say which information you want to extract and the library will do it for you!
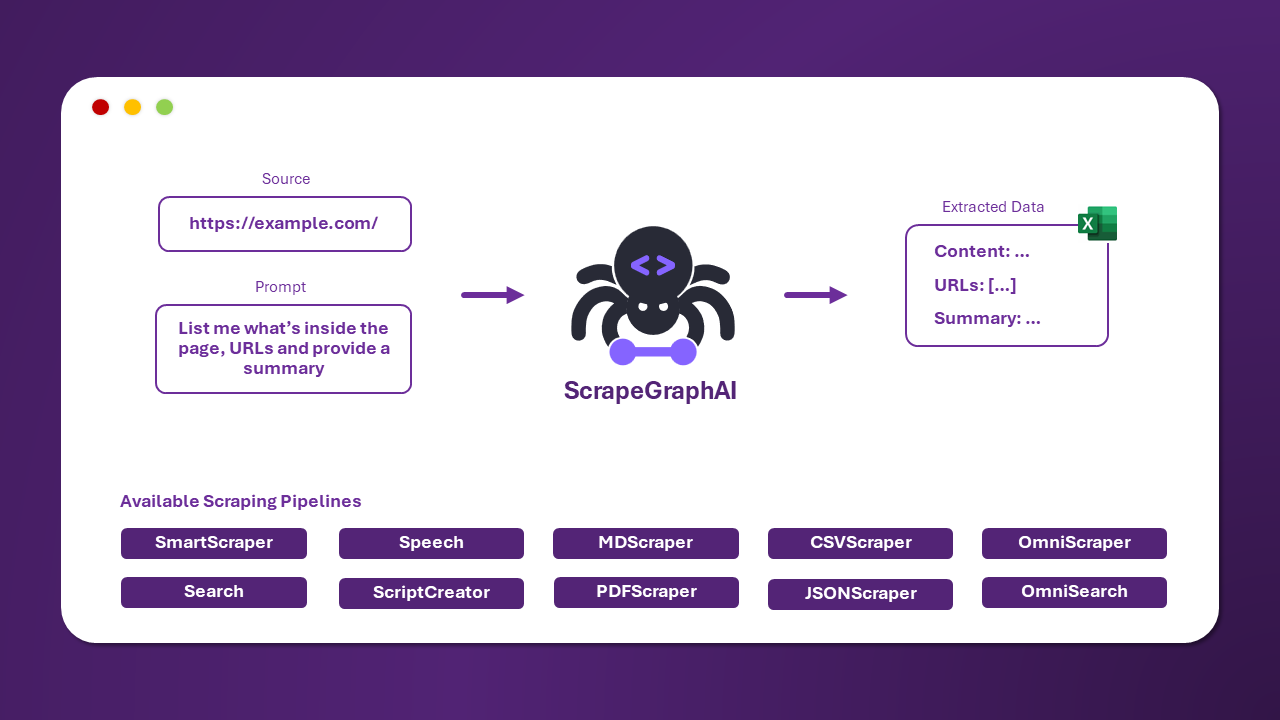
ScrapeGraphAI offers seamless integration with popular frameworks and tools to enhance your scraping capabilities. Whether you're building with Python or Node.js, using LLM frameworks, or working with no-code platforms, we've got you covered with our comprehensive integration options..
You can find more informations at the following link
Integrations:
- API: Documentation
- SDKs: Python, Node
- LLM Frameworks: Langchain, Llama Index, Crew.ai, Agno, CamelAI
- Low-code Frameworks: Pipedream, Bubble, Zapier, n8n, Dify, Toolhouse
- MCP server: Link
The reference page for Scrapegraph-ai is available on the official page of PyPI: pypi.
pip install scrapegraphai
# IMPORTANT (for fetching websites content)
playwright installNote: it is recommended to install the library in a virtual environment to avoid conflicts with other libraries 🐱
There are multiple standard scraping pipelines that can be used to extract information from a website (or local file).
The most common one is the SmartScraperGraph, which extracts information from a single page given a user prompt and a source URL.
from scrapegraphai.graphs import SmartScraperGraph
# Define the configuration for the scraping pipeline
graph_config = {
"llm": {
"model": "ollama/llama3.2",
"model_tokens": 8192,
"format": "json",
},
"verbose": True,
"headless": False,
}
# Create the SmartScraperGraph instance
smart_scraper_graph = SmartScraperGraph(
prompt="Extract useful information from the webpage, including a description of what the company does, founders and social media links",
source="https://scrapegraphai.com/",
config=graph_config
)
# Run the pipeline
result = smart_scraper_graph.run()
import json
print(json.dumps(result, indent=4))[!NOTE] For OpenAI and other models you just need to change the llm config!
graph_config = { "llm": { "api_key": "YOUR_OPENAI_API_KEY", "model": "openai/gpt-4o-mini", }, "verbose": True, "headless": False, }
The output will be a dictionary like the following:
{
"description": "ScrapeGraphAI transforms websites into clean, organized data for AI agents and data analytics. It offers an AI-powered API for effortless and cost-effective data extraction.",
"founders": [
{
"name": "",
"role": "Founder & Technical Lead",
"linkedin": "https://www.linkedin.com/in/perinim/"
},
{
"name": "Marco Vinciguerra",
"role": "Founder & Software Engineer",
"linkedin": "https://www.linkedin.com/in/marco-vinciguerra-7ba365242/"
},
{
"name": "Lorenzo Padoan",
"role": "Founder & Product Engineer",
"linkedin": "https://www.linkedin.com/in/lorenzo-padoan-4521a2154/"
}
],
"social_media_links": {
"linkedin": "https://www.linkedin.com/company/101881123",
"twitter": "https://x.com/scrapegraphai",
"github": "https://github.com/ScrapeGraphAI/Scrapegraph-ai"
}
}There are other pipelines that can be used to extract information from multiple pages, generate Python scripts, or even generate audio files.
| Pipeline Name | Description |
|---|---|
| SmartScraperGraph | Single-page scraper that only needs a user prompt and an input source. |
| SearchGraph | Multi-page scraper that extracts information from the top n search results of a search engine. |
| SpeechGraph | Single-page scraper that extracts information from a website and generates an audio file. |
| ScriptCreatorGraph | Single-page scraper that extracts information from a website and generates a Python script. |
| SmartScraperMultiGraph | Multi-page scraper that extracts information from multiple pages given a single prompt and a list of sources. |
| ScriptCreatorMultiGraph | Multi-page scraper that generates a Python script for extracting information from multiple pages and sources. |
For each of these graphs there is the multi version. It allows to make calls of the LLM in parallel.
It is possible to use different LLM through APIs, such as OpenAI, Groq, Azure and Gemini, or local models using Ollama.
Remember to have Ollama installed and download the models using the ollama pull command, if you want to use local models.
The documentation for ScrapeGraphAI can be found here. Check out also the Docusaurus here.
Feel free to contribute and join our Discord server to discuss with us improvements and give us suggestions!
Please see the contributing guidelines.
If you are looking for a quick solution to integrate ScrapeGraph in your system, check out our powerful API here!
We offer SDKs in both Python and Node.js, making it easy to integrate into your projects. Check them out below:
| SDK | Language | GitHub Link |
|---|---|---|
| Python SDK | Python | scrapegraph-py |
| Node.js SDK | Node.js | scrapegraph-js |
The Official API Documentation can be found here.
According to Firecrawl benchmark Firecrawl benchmark, ScrapeGraph is the best fetcher on the market!

We collect anonymous usage metrics to enhance our package's quality and user experience. The data helps us prioritize improvements and ensure compatibility. If you wish to opt-out, set the environment variable SCRAPEGRAPHAI_TELEMETRY_ENABLED=false. For more information, please refer to the documentation here.
If you have used our library for research purposes please quote us with the following reference:
@misc{scrapegraph-ai,
author = {Lorenzo Padoan, Marco Vinciguerra},
title = {Scrapegraph-ai},
year = {2024},
url = {https://github.com/VinciGit00/Scrapegraph-ai},
note = {A Python library for scraping leveraging large language models}
}
| Contact Info | |
|---|---|
| Marco Vinciguerra | |
| Lorenzo Padoan |
ScrapeGraphAI is licensed under the MIT License. See the LICENSE file for more information.
- We would like to thank all the contributors to the project and the open-source community for their support.
- ScrapeGraphAI is meant to be used for data exploration and research purposes only. We are not responsible for any misuse of the library.
Made with ❤️ by ScrapeGraph AI
{kind=link}
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for Scrapegraph-ai
Similar Open Source Tools
Scrapegraph-ai
ScrapeGraphAI is a web scraping Python library that utilizes LLM and direct graph logic to create scraping pipelines for websites and local documents. It offers various standard scraping pipelines like SmartScraperGraph, SearchGraph, SpeechGraph, and ScriptCreatorGraph. Users can extract information by specifying prompts and input sources. The library supports different LLM APIs such as OpenAI, Groq, Azure, and Gemini, as well as local models using Ollama. ScrapeGraphAI is designed for data exploration and research purposes, providing a versatile tool for extracting information from web pages and generating outputs like Python scripts, audio summaries, and search results.

ScaleLLM
ScaleLLM is a cutting-edge inference system engineered for large language models (LLMs), meticulously designed to meet the demands of production environments. It extends its support to a wide range of popular open-source models, including Llama3, Gemma, Bloom, GPT-NeoX, and more. ScaleLLM is currently undergoing active development. We are fully committed to consistently enhancing its efficiency while also incorporating additional features. Feel free to explore our **_Roadmap_** for more details. ## Key Features * High Efficiency: Excels in high-performance LLM inference, leveraging state-of-the-art techniques and technologies like Flash Attention, Paged Attention, Continuous batching, and more. * Tensor Parallelism: Utilizes tensor parallelism for efficient model execution. * OpenAI-compatible API: An efficient golang rest api server that compatible with OpenAI. * Huggingface models: Seamless integration with most popular HF models, supporting safetensors. * Customizable: Offers flexibility for customization to meet your specific needs, and provides an easy way to add new models. * Production Ready: Engineered with production environments in mind, ScaleLLM is equipped with robust system monitoring and management features to ensure a seamless deployment experience.

autogen
AutoGen is a framework that enables the development of LLM applications using multiple agents that can converse with each other to solve tasks. AutoGen agents are customizable, conversable, and seamlessly allow human participation. They can operate in various modes that employ combinations of LLMs, human inputs, and tools.
optscale
OptScale is an open-source FinOps and MLOps platform that provides cloud cost optimization for all types of organizations and MLOps capabilities like experiment tracking, model versioning, ML leaderboards.
intlayer
Intlayer is an open-source, flexible i18n toolkit with AI-powered translation and CMS capabilities. It is a modern i18n solution for web and mobile apps, framework-agnostic, and includes features like per-locale content files, TypeScript autocompletion, tree-shakable dictionaries, and CI/CD integration. With Intlayer, internationalization becomes faster, cleaner, and smarter, offering benefits such as cross-framework support, JavaScript-powered content management, simplified setup, enhanced routing, AI-powered translation, and more.

aimeos
Aimeos is a full-featured e-commerce platform that is ultra-fast, cloud-native, and API-first. It offers a wide range of features including JSON REST API, GraphQL API, multi-vendor support, various product types, subscriptions, multiple payment gateways, admin backend, modular structure, SEO optimization, multi-language support, AI-based text translation, mobile optimization, and high-quality source code. It is highly configurable and extensible, making it suitable for e-commerce SaaS solutions, marketplaces, and various cloud environments. Aimeos is designed for scalability, security, and performance, catering to a diverse range of e-commerce needs.
TTS-WebUI
TTS WebUI is a comprehensive tool for text-to-speech synthesis, audio/music generation, and audio conversion. It offers a user-friendly interface for various AI projects related to voice and audio processing. The tool provides a range of models and extensions for different tasks, along with integrations like Silly Tavern and OpenWebUI. With support for Docker setup and compatibility with Linux and Windows, TTS WebUI aims to facilitate creative and responsible use of AI technologies in a user-friendly manner.

screenpipe
24/7 Screen & Audio Capture Library to build personalized AI powered by what you've seen, said, or heard. Works with Ollama. Alternative to Rewind.ai. Open. Secure. You own your data. Rust. We are shipping daily, make suggestions, post bugs, give feedback. Building a reliable stream of audio and screenshot data, simplifying life for developers by solving non-trivial problems. Multiple installation options available. Experimental tool with various integrations and features for screen and audio capture, OCR, STT, and more. Open source project focused on enabling tooling & infrastructure for a wide range of applications.
genius-ai
Genius is a modern Next.js 14 SaaS AI platform that provides a comprehensive folder structure for app development. It offers features like authentication, dashboard management, landing pages, API integration, and more. The platform is built using React JS, Next JS, TypeScript, Tailwind CSS, and integrates with services like Netlify, Prisma, MySQL, and Stripe. Genius enables users to create AI-powered applications with functionalities such as conversation generation, image processing, code generation, and more. It also includes features like Clerk authentication, OpenAI integration, Replicate API usage, Aiven database connectivity, and Stripe API/webhook setup. The platform is fully configurable and provides a seamless development experience for building AI-driven applications.

infinity
Infinity is a high-throughput, low-latency REST API for serving vector embeddings, supporting all sentence-transformer models and frameworks. It is developed under the MIT License and powers inference behind Gradient.ai. The API allows users to deploy models from SentenceTransformers, offers fast inference backends utilizing various accelerators, dynamic batching for efficient processing, correct and tested implementation, and easy-to-use API built on FastAPI with Swagger documentation. Users can embed text, rerank documents, and perform text classification tasks using the tool. Infinity supports various models from Huggingface and provides flexibility in deployment via CLI, Docker, Python API, and cloud services like dstack. The tool is suitable for tasks like embedding, reranking, and text classification.

PromptClip
PromptClip is a tool that allows developers to create video clips using LLM prompts. Users can upload videos from various sources, prompt the video in natural language, use different LLM models, instantly watch the generated clips, finetune the clips, and add music or image overlays. The tool provides a seamless way to extract specific moments from videos based on user queries, making video editing and content creation more efficient and intuitive.
deep-chat
Deep Chat is a fully customizable AI chat component that can be injected into your website with minimal to no effort. Whether you want to create a chatbot that leverages popular APIs such as ChatGPT or connect to your own custom service, this component can do it all! Explore deepchat.dev to view all of the available features, how to use them, examples and more!
ai-toolkit
The AI Toolkit by Ostris is a collection of tools for machine learning, specifically designed for image generation, LoRA (latent representations of attributes) extraction and manipulation, and model training. It provides a user-friendly interface and extensive documentation to make it accessible to both developers and non-developers. The toolkit is actively under development, with new features and improvements being added regularly. Some of the key features of the AI Toolkit include: - Batch Image Generation: Allows users to generate a batch of images based on prompts or text files, using a configuration file to specify the desired settings. - LoRA (lierla), LoCON (LyCORIS) Extractor: Facilitates the extraction of LoRA and LoCON representations from pre-trained models, enabling users to modify and manipulate these representations for various purposes. - LoRA Rescale: Provides a tool to rescale LoRA weights, allowing users to adjust the influence of specific attributes in the generated images. - LoRA Slider Trainer: Enables the training of LoRA sliders, which can be used to control and adjust specific attributes in the generated images, offering a powerful tool for fine-tuning and customization. - Extensions: Supports the creation and sharing of custom extensions, allowing users to extend the functionality of the toolkit with their own tools and scripts. - VAE (Variational Auto Encoder) Trainer: Facilitates the training of VAEs for image generation, providing users with a tool to explore and improve the quality of generated images. The AI Toolkit is a valuable resource for anyone interested in exploring and utilizing machine learning for image generation and manipulation. Its user-friendly interface, extensive documentation, and active development make it an accessible and powerful tool for both beginners and experienced users.
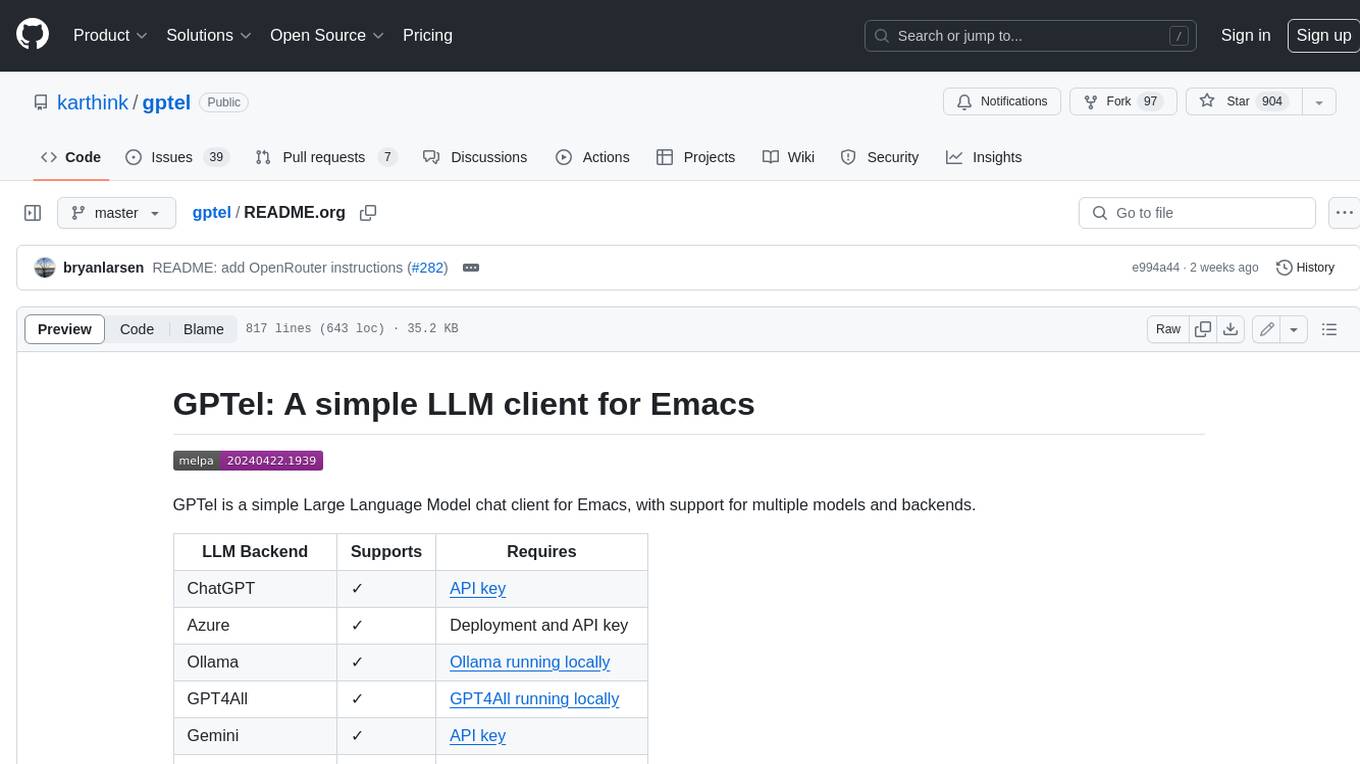
gptel
GPTel is a simple Large Language Model chat client for Emacs, with support for multiple models and backends. It's async and fast, streams responses, and interacts with LLMs from anywhere in Emacs. LLM responses are in Markdown or Org markup. Supports conversations and multiple independent sessions. Chats can be saved as regular Markdown/Org/Text files and resumed later. You can go back and edit your previous prompts or LLM responses when continuing a conversation. These will be fed back to the model. Don't like gptel's workflow? Use it to create your own for any supported model/backend with a simple API.
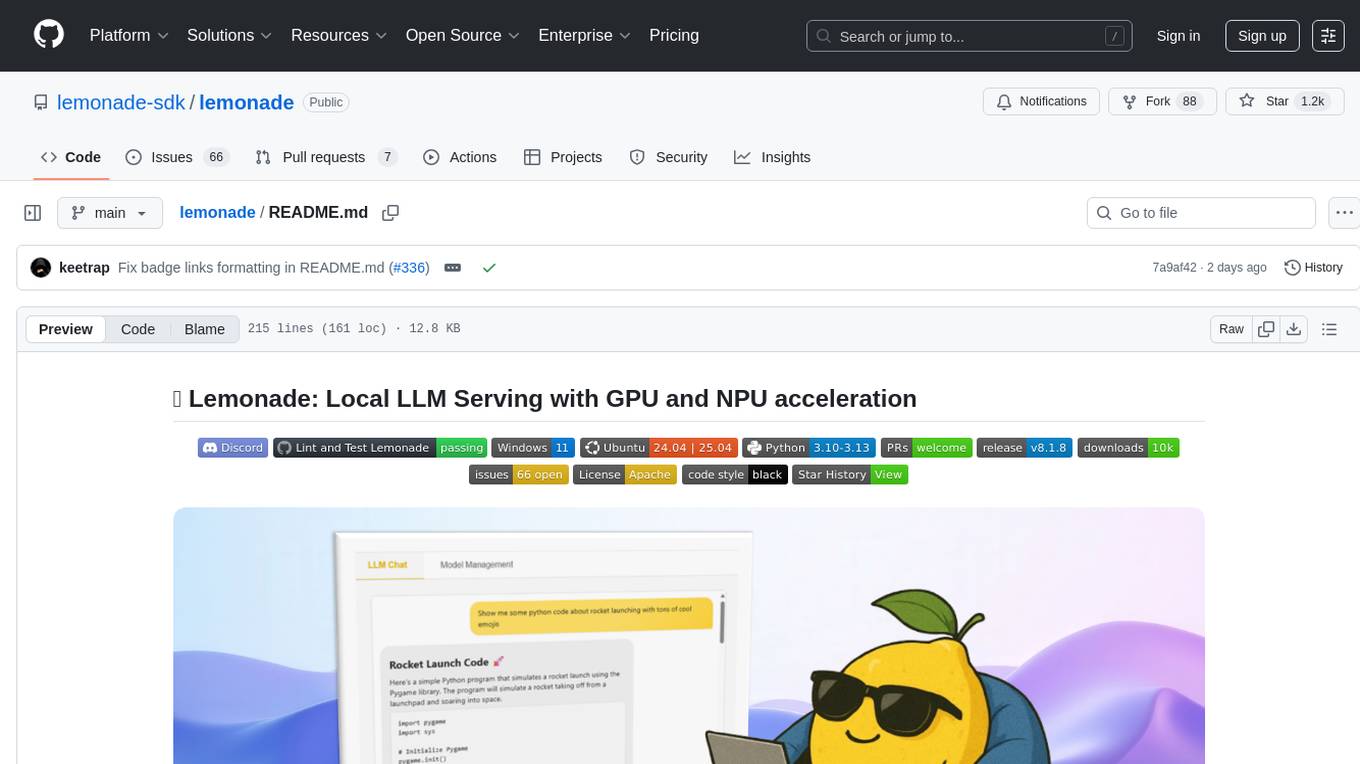
lemonade
Lemonade is a tool that helps users run local Large Language Models (LLMs) with high performance by configuring state-of-the-art inference engines for their Neural Processing Units (NPUs) and Graphics Processing Units (GPUs). It is used by startups, research teams, and large companies to run LLMs efficiently. Lemonade provides a high-level Python API for direct integration of LLMs into Python applications and a CLI for mixing and matching LLMs with various features like prompting templates, accuracy testing, performance benchmarking, and memory profiling. The tool supports both GGUF and ONNX models and allows importing custom models from Hugging Face using the Model Manager. Lemonade is designed to be easy to use and switch between different configurations at runtime, making it a versatile tool for running LLMs locally.
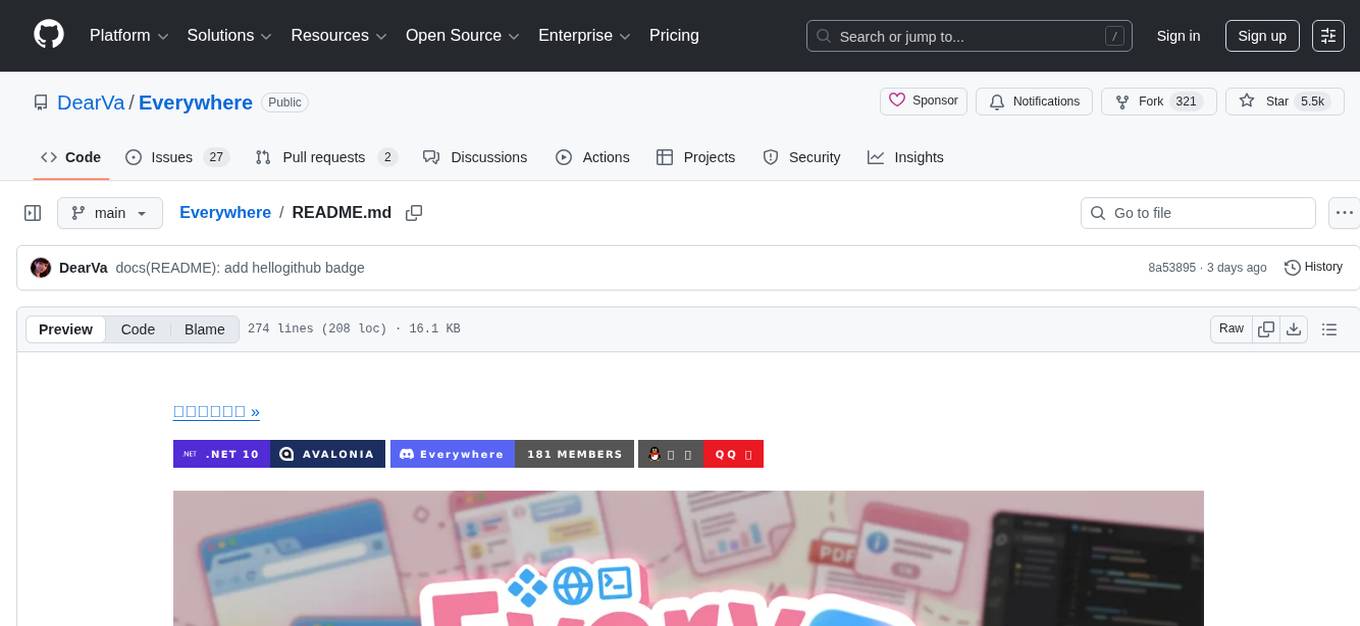
Everywhere
Everywhere is an interactive AI assistant with context-aware capabilities, featuring a sleek, modern UI and powerful integrated functionality. It instantly perceives and understands anything on your screen, providing seamless AI assistant support without the need for screenshots or app switching. The tool offers troubleshooting expertise, quick web summarization, instant translation, and email draft assistance. It supports LLM from various providers, integrates with web browsers, file systems, terminals, and more, and provides an interactive experience with a modern UI, context-aware invocation, keyboard shortcuts, and markdown rendering. Everywhere is available on Windows and macOS, with Linux support coming soon. Language support includes Simplified Chinese, English, German, Spanish, French, Italian, Japanese, Korean, Russian, Turkish, Traditional Chinese, and Traditional Chinese (Hong Kong).
For similar tasks
Scrapegraph-ai
ScrapeGraphAI is a web scraping Python library that utilizes LLM and direct graph logic to create scraping pipelines for websites and local documents. It offers various standard scraping pipelines like SmartScraperGraph, SearchGraph, SpeechGraph, and ScriptCreatorGraph. Users can extract information by specifying prompts and input sources. The library supports different LLM APIs such as OpenAI, Groq, Azure, and Gemini, as well as local models using Ollama. ScrapeGraphAI is designed for data exploration and research purposes, providing a versatile tool for extracting information from web pages and generating outputs like Python scripts, audio summaries, and search results.

Scrapegraph-ai
ScrapeGraphAI is a Python library that uses Large Language Models (LLMs) and direct graph logic to create web scraping pipelines for websites, documents, and XML files. It allows users to extract specific information from web pages by providing a prompt describing the desired data. ScrapeGraphAI supports various LLMs, including Ollama, OpenAI, Gemini, and Docker, enabling users to choose the most suitable model for their needs. The library provides a user-friendly interface through its `SmartScraper` class, which simplifies the process of building and executing scraping pipelines. ScrapeGraphAI is open-source and available on GitHub, with extensive documentation and examples to guide users. It is particularly useful for researchers and data scientists who need to extract structured data from web pages for analysis and exploration.
For similar jobs

lollms-webui
LoLLMs WebUI (Lord of Large Language Multimodal Systems: One tool to rule them all) is a user-friendly interface to access and utilize various LLM (Large Language Models) and other AI models for a wide range of tasks. With over 500 AI expert conditionings across diverse domains and more than 2500 fine tuned models over multiple domains, LoLLMs WebUI provides an immediate resource for any problem, from car repair to coding assistance, legal matters, medical diagnosis, entertainment, and more. The easy-to-use UI with light and dark mode options, integration with GitHub repository, support for different personalities, and features like thumb up/down rating, copy, edit, and remove messages, local database storage, search, export, and delete multiple discussions, make LoLLMs WebUI a powerful and versatile tool.

Azure-Analytics-and-AI-Engagement
The Azure-Analytics-and-AI-Engagement repository provides packaged Industry Scenario DREAM Demos with ARM templates (Containing a demo web application, Power BI reports, Synapse resources, AML Notebooks etc.) that can be deployed in a customer’s subscription using the CAPE tool within a matter of few hours. Partners can also deploy DREAM Demos in their own subscriptions using DPoC.

minio
MinIO is a High Performance Object Storage released under GNU Affero General Public License v3.0. It is API compatible with Amazon S3 cloud storage service. Use MinIO to build high performance infrastructure for machine learning, analytics and application data workloads.

mage-ai
Mage is an open-source data pipeline tool for transforming and integrating data. It offers an easy developer experience, engineering best practices built-in, and data as a first-class citizen. Mage makes it easy to build, preview, and launch data pipelines, and provides observability and scaling capabilities. It supports data integrations, streaming pipelines, and dbt integration.

AiTreasureBox
AiTreasureBox is a versatile AI tool that provides a collection of pre-trained models and algorithms for various machine learning tasks. It simplifies the process of implementing AI solutions by offering ready-to-use components that can be easily integrated into projects. With AiTreasureBox, users can quickly prototype and deploy AI applications without the need for extensive knowledge in machine learning or deep learning. The tool covers a wide range of tasks such as image classification, text generation, sentiment analysis, object detection, and more. It is designed to be user-friendly and accessible to both beginners and experienced developers, making AI development more efficient and accessible to a wider audience.

tidb
TiDB is an open-source distributed SQL database that supports Hybrid Transactional and Analytical Processing (HTAP) workloads. It is MySQL compatible and features horizontal scalability, strong consistency, and high availability.

airbyte
Airbyte is an open-source data integration platform that makes it easy to move data from any source to any destination. With Airbyte, you can build and manage data pipelines without writing any code. Airbyte provides a library of pre-built connectors that make it easy to connect to popular data sources and destinations. You can also create your own connectors using Airbyte's no-code Connector Builder or low-code CDK. Airbyte is used by data engineers and analysts at companies of all sizes to build and manage their data pipelines.

labelbox-python
Labelbox is a data-centric AI platform for enterprises to develop, optimize, and use AI to solve problems and power new products and services. Enterprises use Labelbox to curate data, generate high-quality human feedback data for computer vision and LLMs, evaluate model performance, and automate tasks by combining AI and human-centric workflows. The academic & research community uses Labelbox for cutting-edge AI research.