
evalscope
A streamlined and customizable framework for efficient large model evaluation and performance benchmarking
Stars: 1690
Eval-Scope is a framework designed to support the evaluation of large language models (LLMs) by providing pre-configured benchmark datasets, common evaluation metrics, model integration, automatic evaluation for objective questions, complex task evaluation using expert models, reports generation, visualization tools, and model inference performance evaluation. It is lightweight, easy to customize, supports new dataset integration, model hosting on ModelScope, deployment of locally hosted models, and rich evaluation metrics. Eval-Scope also supports various evaluation modes like single mode, pairwise-baseline mode, and pairwise (all) mode, making it suitable for assessing and improving LLMs.
README:
![]()
中文   |   English  
📖 中文文档   |   📖 English Documents
⭐ If you like this project, please click the "Star" button at the top right to support us. Your support is our motivation to keep going!
- 📋 Contents
- 📝 Introduction
- ☎ User Groups
- 🎉 News
- 🛠️ Environment Setup
- 🚀 Quick Start
- 📈 Visualization of Evaluation Results
- 🌐 Evaluation of Model API
- ⚙️ Custom Parameter Evaluation
- 🧪 Other Evaluation Backends
- 📈 Model Serving Performance Evaluation
- 🖊️ Custom Dataset Evaluation
- ⚔️ Arena Mode
- 👷♂️ Contribution
- 📚 Citation
- 🔜 Roadmap
- ⭐ Star History
EvalScope is a comprehensive model evaluation and performance benchmarking framework meticulously crafted by the ModelScope Community, offering a one-stop solution for your model assessment needs. Regardless of the type of model you are developing, EvalScope is equipped to cater to your requirements:
- 🧠 Large Language Models
- 🎨 Multimodal Models
- 🔍 Embedding Models
- 🏆 Reranker Models
- 🖼️ CLIP Models
- 🎭 AIGC Models (Image-to-Text/Video)
- ...and more!
EvalScope is not merely an evaluation tool; it is a valuable ally in your model optimization journey:
- 🏅 Equipped with multiple industry-recognized benchmarks and evaluation metrics: MMLU, CMMLU, C-Eval, GSM8K, etc.
- 📊 Model inference performance stress testing: Ensuring your model excels in real-world applications.
- 🚀 Seamless integration with the ms-swift training framework, enabling one-click evaluations and providing full-chain support from training to assessment for your model development.
Below is the overall architecture diagram of EvalScope:
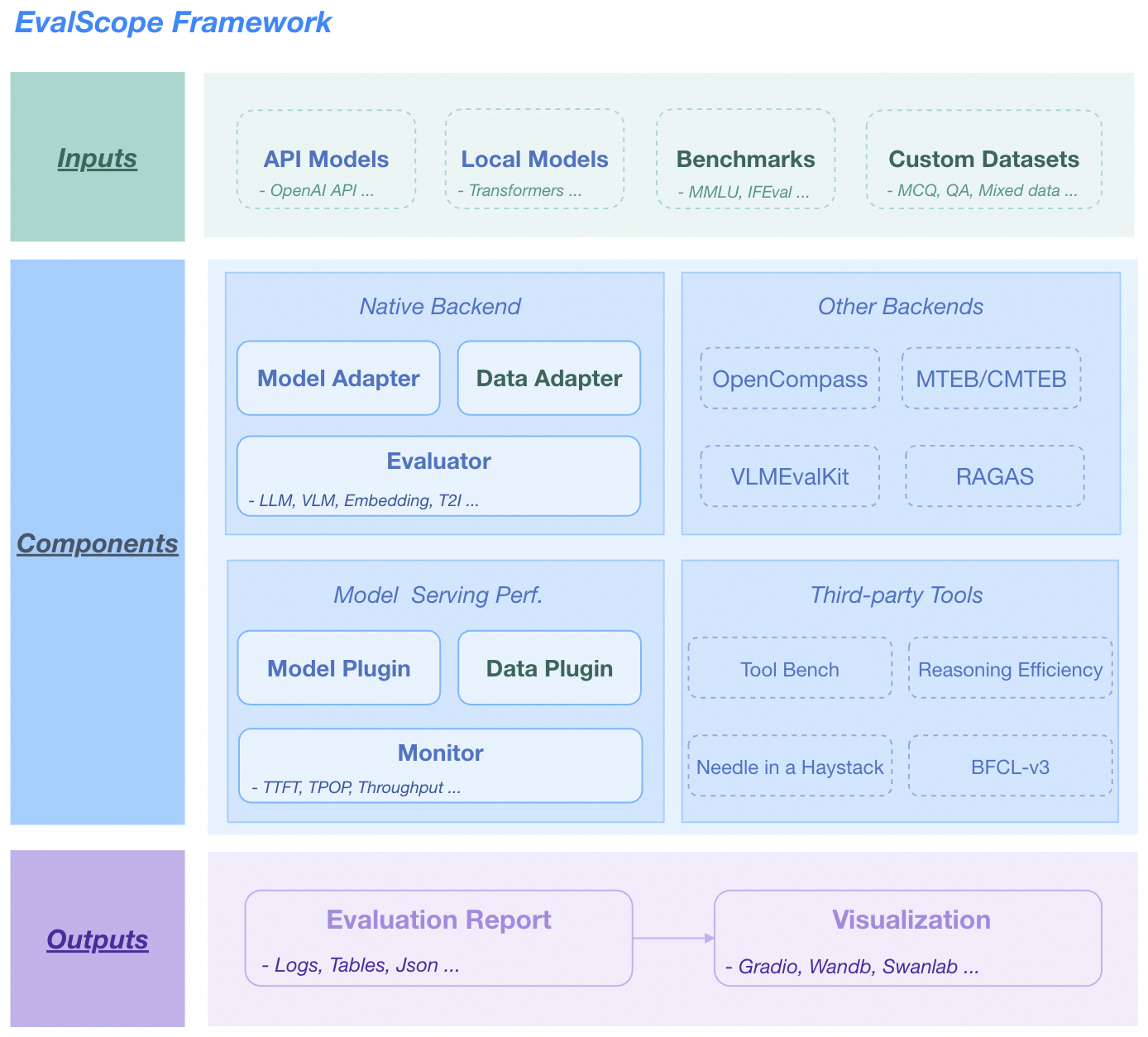
EvalScope Framework.
Framework Description
The architecture includes the following modules:
- Input Layer
- Model Sources: API models (OpenAI API), local models (ModelScope)
- Datasets: Standard evaluation benchmarks (MMLU/GSM8k, etc.), custom data (MCQ/QA)
- Core Functions
-
Multi-backend Evaluation
- Native backends: Unified evaluation for LLM/VLM/Embedding/T2I models
- Integrated frameworks: OpenCompass/MTEB/VLMEvalKit/RAGAS
-
Performance Monitoring
- Model plugins: Supports various model service APIs
- Data plugins: Supports multiple data formats
- Metric tracking: TTFT/TPOP/Stability and other metrics
-
Tool Extensions
- Integration: Tool-Bench/Needle-in-a-Haystack/BFCL-v3
- Output Layer
- Structured Reports: Supports JSON/Tables/Logs
- Visualization Platforms: Supports Gradio/Wandb/SwanLab
Please scan the QR code below to join our community groups:
| Discord Group | WeChat Group | DingTalk Group |
|---|---|---|
 |
 |
 |
[!IMPORTANT] Version 1.0 Refactoring
Version 1.0 introduces a major overhaul of the evaluation framework, establishing a new, more modular and extensible API layer under
evalscope/api. Key improvements include standardized data models for benchmarks, samples, and results; a registry-based design for components such as benchmarks and metrics; and a rewritten core evaluator that orchestrates the new architecture. Existing benchmark adapters have been migrated to this API, resulting in cleaner, more consistent, and easier-to-maintain implementations.
- 🔥 [2025.09.05] Added support for vision-language multimodal model evaluation tasks, such as MathVista and MMMU. For more supported datasets, please refer to the documentation.
- 🔥 [2025.09.04] Added support for image editing task evaluation, including the GEdit-Bench benchmark. For usage instructions, refer to the documentation.
- 🔥 [2025.08.22] Version 1.0 Refactoring. Break changes, please refer to.
- 🔥 [2025.07.18] The model stress testing now supports randomly generating image-text data for multimodal model evaluation. For usage instructions, refer to the documentation.
- 🔥 [2025.07.16] Support for τ-bench has been added, enabling the evaluation of AI Agent performance and reliability in real-world scenarios involving dynamic user and tool interactions. For usage instructions, please refer to the documentation.
- 🔥 [2025.07.14] Support for "Humanity's Last Exam" (Humanity's-Last-Exam), a highly challenging evaluation benchmark. For usage instructions, refer to the documentation.
- 🔥 [2025.07.03] Refactored Arena Mode: now supports custom model battles, outputs a model leaderboard, and provides battle result visualization. See reference for details.
- 🔥 [2025.06.28] Optimized custom dataset evaluation: now supports evaluation without reference answers. Enhanced LLM judge usage, with built-in modes for "scoring directly without reference answers" and "checking answer consistency with reference answers". See reference for details.
- 🔥 [2025.06.19] Added support for the BFCL-v3 benchmark, designed to evaluate model function-calling capabilities across various scenarios. For more information, refer to the documentation.
- 🔥 [2025.06.02] Added support for the Needle-in-a-Haystack test. Simply specify
needle_haystackto conduct the test, and a corresponding heatmap will be generated in theoutputs/reportsfolder, providing a visual representation of the model's performance. Refer to the documentation for more details. - 🔥 [2025.05.29] Added support for two long document evaluation benchmarks: DocMath and FRAMES. For usage guidelines, please refer to the documentation.
- 🔥 [2025.05.16] Model service performance stress testing now supports setting various levels of concurrency and outputs a performance test report. Reference example.
- 🔥 [2025.05.13] Added support for the ToolBench-Static dataset to evaluate model's tool-calling capabilities. Refer to the documentation for usage instructions. Also added support for the DROP and Winogrande benchmarks to assess the reasoning capabilities of models.
More
- 🔥 [2025.04.29] Added Qwen3 Evaluation Best Practices, welcome to read 📖
- 🔥 [2025.04.27] Support for text-to-image evaluation: Supports 8 metrics including MPS, HPSv2.1Score, etc., and evaluation benchmarks such as EvalMuse, GenAI-Bench. Refer to the user documentation for more details.
- 🔥 [2025.04.10] Model service stress testing tool now supports the
/v1/completionsendpoint (the default endpoint for vLLM benchmarking) - 🔥 [2025.04.08] Support for evaluating embedding model services compatible with the OpenAI API has been added. For more details, check the user guide.
- 🔥 [2025.03.27] Added support for AlpacaEval and ArenaHard evaluation benchmarks. For usage notes, please refer to the documentation
- 🔥 [2025.03.20] The model inference service stress testing now supports generating prompts of specified length using random values. Refer to the user guide for more details.
- 🔥 [2025.03.13] Added support for the LiveCodeBench code evaluation benchmark, which can be used by specifying
live_code_bench. Supports evaluating QwQ-32B on LiveCodeBench, refer to the best practices. - 🔥 [2025.03.11] Added support for the SimpleQA and Chinese SimpleQA evaluation benchmarks. These are used to assess the factual accuracy of models, and you can specify
simple_qaandchinese_simpleqafor use. Support for specifying a judge model is also available. For more details, refer to the relevant parameter documentation. - 🔥 [2025.03.07] Added support for the QwQ-32B model, evaluate the model's reasoning ability and reasoning efficiency, refer to 📖 Best Practices for QwQ-32B Evaluation for more details.
- 🔥 [2025.03.04] Added support for the SuperGPQA dataset, which covers 13 categories, 72 first-level disciplines, and 285 second-level disciplines, totaling 26,529 questions. You can use it by specifying
super_gpqa. - 🔥 [2025.03.03] Added support for evaluating the IQ and EQ of models. Refer to 📖 Best Practices for IQ and EQ Evaluation to find out how smart your AI is!
- 🔥 [2025.02.27] Added support for evaluating the reasoning efficiency of models. Refer to 📖 Best Practices for Evaluating Thinking Efficiency. This implementation is inspired by the works Overthinking and Underthinking.
- 🔥 [2025.02.25] Added support for two model inference-related evaluation benchmarks: MuSR and ProcessBench. To use them, simply specify
musrandprocess_benchrespectively in the datasets parameter. - 🔥 [2025.02.18] Supports the AIME25 dataset, which contains 15 questions (Grok3 scored 93 on this dataset).
- 🔥 [2025.02.13] Added support for evaluating DeepSeek distilled models, including AIME24, MATH-500, and GPQA-Diamond datasets,refer to best practice; Added support for specifying the
eval_batch_sizeparameter to accelerate model evaluation. - 🔥 [2025.01.20] Support for visualizing evaluation results, including single model evaluation results and multi-model comparison, refer to the 📖 Visualizing Evaluation Results for more details; Added
iquizevaluation example, evaluating the IQ and EQ of the model. - 🔥 [2025.01.07] Native backend: Support for model API evaluation is now available. Refer to the 📖 Model API Evaluation Guide for more details. Additionally, support for the
ifevalevaluation benchmark has been added. - 🔥🔥 [2024.12.31] Support for adding benchmark evaluations, refer to the 📖 Benchmark Evaluation Addition Guide; support for custom mixed dataset evaluations, allowing for more comprehensive model evaluations with less data, refer to the 📖 Mixed Dataset Evaluation Guide.
- 🔥 [2024.12.13] Model evaluation optimization: no need to pass the
--template-typeparameter anymore; supports starting evaluation withevalscope eval --args. Refer to the 📖 User Guide for more details. - 🔥 [2024.11.26] The model inference service performance evaluator has been completely refactored: it now supports local inference service startup and Speed Benchmark; asynchronous call error handling has been optimized. For more details, refer to the 📖 User Guide.
- 🔥 [2024.10.31] The best practice for evaluating Multimodal-RAG has been updated, please check the 📖 Blog for more details.
- 🔥 [2024.10.23] Supports multimodal RAG evaluation, including the assessment of image-text retrieval using CLIP_Benchmark, and extends RAGAS to support end-to-end multimodal metrics evaluation.
- 🔥 [2024.10.8] Support for RAG evaluation, including independent evaluation of embedding models and rerankers using MTEB/CMTEB, as well as end-to-end evaluation using RAGAS.
- 🔥 [2024.09.18] Our documentation has been updated to include a blog module, featuring some technical research and discussions related to evaluations. We invite you to 📖 read it.
- 🔥 [2024.09.12] Support for LongWriter evaluation, which supports 10,000+ word generation. You can use the benchmark LongBench-Write to measure the long output quality as well as the output length.
- 🔥 [2024.08.30] Support for custom dataset evaluations, including text datasets and multimodal image-text datasets.
- 🔥 [2024.08.20] Updated the official documentation, including getting started guides, best practices, and FAQs. Feel free to 📖read it here!
- 🔥 [2024.08.09] Simplified the installation process, allowing for pypi installation of vlmeval dependencies; optimized the multimodal model evaluation experience, achieving up to 10x acceleration based on the OpenAI API evaluation chain.
- 🔥 [2024.07.31] Important change: The package name
llmuseshas been changed toevalscope. Please update your code accordingly. - 🔥 [2024.07.26] Support for VLMEvalKit as a third-party evaluation framework to initiate multimodal model evaluation tasks.
- 🔥 [2024.06.29] Support for OpenCompass as a third-party evaluation framework, which we have encapsulated at a higher level, supporting pip installation and simplifying evaluation task configuration.
- 🔥 [2024.06.13] EvalScope seamlessly integrates with the fine-tuning framework SWIFT, providing full-chain support from LLM training to evaluation.
- 🔥 [2024.06.13] Integrated the Agent evaluation dataset ToolBench.
We recommend using conda to manage your environment and pip to install dependencies. This allows you to use the latest evalscope PyPI package.
- Create a conda environment (optional)
# Python 3.10 is recommended
conda create -n evalscope python=3.10
# Activate the conda environment
conda activate evalscope- Install dependencies via pip
pip install evalscope- Install additional dependencies (optional)
- To use model service inference benchmarking features, install the perf dependency:
pip install 'evalscope[perf]' - To use visualization features, install the app dependency:
pip install 'evalscope[app]' - If you need to use other evaluation backends, you can install OpenCompass, VLMEvalKit, or RAGEval as needed:
pip install 'evalscope[opencompass]' pip install 'evalscope[vlmeval]' pip install 'evalscope[rag]'
- To install all dependencies:
pip install 'evalscope[all]'
[!NOTE] The project has been renamed to
evalscope. For versionv0.4.3or earlier, you can install it with:pip install llmuses<=0.4.3Then, import related dependencies using
llmuses:from llmuses import ...
Installing from source allows you to use the latest code and makes it easier for further development and debugging.
- Clone the source code
git clone https://github.com/modelscope/evalscope.git- Install dependencies
cd evalscope/
pip install -e .- Install additional dependencies
- To use model service inference benchmarking features, install the perf dependency:
pip install '.[perf]' - To use visualization features, install the app dependency:
pip install '.[app]' - If you need to use other evaluation backends, you can install OpenCompass, VLMEvalKit, or RAGEval as needed:
pip install '.[opencompass]' pip install '.[vlmeval]' pip install '.[rag]'
- To install all dependencies:
pip install '.[all]'
To evaluate a model on specified datasets using default configurations, this framework supports two ways to initiate evaluation tasks: using the command line or using Python code.
Execute the eval command in any directory:
evalscope eval \
--model Qwen/Qwen2.5-0.5B-Instruct \
--datasets gsm8k arc \
--limit 5When using Python code for evaluation, you need to submit the evaluation task using the run_task function, passing a TaskConfig as a parameter. It can also be a Python dictionary, yaml file path, or json file path, for example:
Using TaskConfig
from evalscope import run_task, TaskConfig
task_cfg = TaskConfig(
model='Qwen/Qwen2.5-0.5B-Instruct',
datasets=['gsm8k', 'arc'],
limit=5
)
run_task(task_cfg=task_cfg)More Startup Methods
Using Python Dictionary
from evalscope.run import run_task
task_cfg = {
'model': 'Qwen/Qwen2.5-0.5B-Instruct',
'datasets': ['gsm8k', 'arc'],
'limit': 5
}
run_task(task_cfg=task_cfg)Using yaml file
config.yaml:
model: Qwen/Qwen2.5-0.5B-Instruct
datasets:
- gsm8k
- arc
limit: 5from evalscope.run import run_task
run_task(task_cfg="config.yaml")Using json file
config.json:
{
"model": "Qwen/Qwen2.5-0.5B-Instruct",
"datasets": ["gsm8k", "arc"],
"limit": 5
}from evalscope.run import run_task
run_task(task_cfg="config.json")-
--model: Specifies themodel_idof the model in ModelScope, which can be automatically downloaded, e.g., Qwen/Qwen2.5-0.5B-Instruct; or use the local path of the model, e.g.,/path/to/model -
--datasets: Dataset names, supports inputting multiple datasets separated by spaces. Datasets will be automatically downloaded from modelscope. For supported datasets, refer to the Dataset List -
--limit: Maximum amount of evaluation data for each dataset. If not specified, it defaults to evaluating all data. Can be used for quick validation
+-----------------------+----------------+-----------------+-----------------+---------------+-------+---------+
| Model Name | Dataset Name | Metric Name | Category Name | Subset Name | Num | Score |
+=======================+================+=================+=================+===============+=======+=========+
| Qwen2.5-0.5B-Instruct | gsm8k | AverageAccuracy | default | main | 5 | 0.4 |
+-----------------------+----------------+-----------------+-----------------+---------------+-------+---------+
| Qwen2.5-0.5B-Instruct | ai2_arc | AverageAccuracy | default | ARC-Easy | 5 | 0.8 |
+-----------------------+----------------+-----------------+-----------------+---------------+-------+---------+
| Qwen2.5-0.5B-Instruct | ai2_arc | AverageAccuracy | default | ARC-Challenge | 5 | 0.4 |
+-----------------------+----------------+-----------------+-----------------+---------------+-------+---------+
- Install the dependencies required for visualization, including gradio, plotly, etc.
pip install 'evalscope[app]'- Start the Visualization Service
Run the following command to start the visualization service.
evalscope appYou can access the visualization service in the browser if the following output appears.
* Running on local URL: http://127.0.0.1:7861
To create a public link, set `share=True` in `launch()`.

Setting Interface |

Model Comparison |

Report Overview |

Report Details |
For more details, refer to: 📖 Visualization of Evaluation Results
Specify the model API service address (api_url) and API Key (api_key) to evaluate the deployed model API service. In this case, the eval-type parameter must be specified as service, for example:
For example, to launch a model service using vLLM:
export VLLM_USE_MODELSCOPE=True && python -m vllm.entrypoints.openai.api_server --model Qwen/Qwen2.5-0.5B-Instruct --served-model-name qwen2.5 --trust_remote_code --port 8801Then, you can use the following command to evaluate the model API service:
evalscope eval \
--model qwen2.5 \
--api-url http://127.0.0.1:8801/v1 \
--api-key EMPTY \
--eval-type service \
--datasets gsm8k \
--limit 10For more customized evaluations, such as customizing model parameters or dataset parameters, you can use the following command. The evaluation startup method is the same as simple evaluation. Below shows how to start the evaluation using the eval command:
evalscope eval \
--model Qwen/Qwen3-0.6B \
--model-args '{"revision": "master", "precision": "torch.float16", "device_map": "auto"}' \
--generation-config '{"do_sample":true,"temperature":0.6,"max_tokens":512,"chat_template_kwargs":{"enable_thinking": false}}' \
--dataset-args '{"gsm8k": {"few_shot_num": 0, "few_shot_random": false}}' \
--datasets gsm8k \
--limit 10-
--model-args: Model loading parameters, passed as a JSON string:-
revision: Model version -
precision: Model precision -
device_map: Device allocation for the model
-
-
--generation-config: Generation parameters, passed as a JSON string and parsed as a dictionary:-
do_sample: Whether to use sampling -
temperature: Generation temperature -
max_tokens: Maximum length of generated tokens -
chat_template_kwargs: Model inference template parameters
-
-
--dataset-args: Settings for the evaluation dataset, passed as a JSON string where the key is the dataset name and the value is the parameters. Note that these need to correspond one-to-one with the values in the--datasetsparameter:-
few_shot_num: Number of few-shot examples -
few_shot_random: Whether to randomly sample few-shot data; if not set, defaults totrue
-
Reference: Full Parameter Description
EvalScope supports using third-party evaluation frameworks to initiate evaluation tasks, which we call Evaluation Backend. Currently supported Evaluation Backend includes:
- Native: EvalScope's own default evaluation framework, supporting various evaluation modes including single model evaluation, arena mode, and baseline model comparison mode.
- OpenCompass: Initiate OpenCompass evaluation tasks through EvalScope. Lightweight, easy to customize, supports seamless integration with the LLM fine-tuning framework ms-swift. 📖 User Guide
- VLMEvalKit: Initiate VLMEvalKit multimodal evaluation tasks through EvalScope. Supports various multimodal models and datasets, and offers seamless integration with the LLM fine-tuning framework ms-swift. 📖 User Guide
- RAGEval: Initiate RAG evaluation tasks through EvalScope, supporting independent evaluation of embedding models and rerankers using MTEB/CMTEB, as well as end-to-end evaluation using RAGAS: 📖 User Guide
- ThirdParty: Third-party evaluation tasks, such as ToolBench and LongBench-Write.
A stress testing tool focused on large language models, which can be customized to support various dataset formats and different API protocol formats.
Reference: Performance Testing 📖 User Guide
Output example

Supports wandb for recording results

Supports swanlab for recording results

Supports Speed Benchmark
It supports speed testing and provides speed benchmarks similar to those found in the official Qwen reports:
Speed Benchmark Results:
+---------------+-----------------+----------------+
| Prompt Tokens | Speed(tokens/s) | GPU Memory(GB) |
+---------------+-----------------+----------------+
| 1 | 50.69 | 0.97 |
| 6144 | 51.36 | 1.23 |
| 14336 | 49.93 | 1.59 |
| 30720 | 49.56 | 2.34 |
+---------------+-----------------+----------------+
EvalScope supports custom dataset evaluation. For detailed information, please refer to the Custom Dataset Evaluation 📖User Guide
Arena mode allows you to configure multiple candidate models and specify a baseline model. Evaluation is performed by pairwise battles between each candidate model and the baseline model, with the final output including each model's win rate and ranking. This method is suitable for comparative evaluation among multiple models, providing an intuitive reflection of each model's strengths and weaknesses. Refer to: Arena Mode 📖 User Guide
Model WinRate (%) CI (%)
------------ ------------- ---------------
qwen2.5-72b 69.3 (-13.3 / +12.2)
qwen2.5-7b 50 (+0.0 / +0.0)
qwen2.5-0.5b 4.7 (-2.5 / +4.4)
EvalScope, as the official evaluation tool of ModelScope, is continuously optimizing its benchmark evaluation features! We invite you to refer to the Contribution Guide to easily add your own evaluation benchmarks and share your contributions with the community. Let’s work together to support the growth of EvalScope and make our tools even better! Join us now!
|
|
|---|
@misc{evalscope_2024,
title={{EvalScope}: Evaluation Framework for Large Models},
author={ModelScope Team},
year={2024},
url={https://github.com/modelscope/evalscope}
}- [x] Support for better evaluation report visualization
- [x] Support for mixed evaluations across multiple datasets
- [x] RAG evaluation
- [x] VLM evaluation
- [x] Agents evaluation
- [x] vLLM
- [ ] Distributed evaluating
- [x] Multi-modal evaluation
- [ ] Benchmarks
- [x] BFCL-v3
- [x] GPQA
- [x] MBPP
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for evalscope
Similar Open Source Tools
evalscope
Eval-Scope is a framework designed to support the evaluation of large language models (LLMs) by providing pre-configured benchmark datasets, common evaluation metrics, model integration, automatic evaluation for objective questions, complex task evaluation using expert models, reports generation, visualization tools, and model inference performance evaluation. It is lightweight, easy to customize, supports new dataset integration, model hosting on ModelScope, deployment of locally hosted models, and rich evaluation metrics. Eval-Scope also supports various evaluation modes like single mode, pairwise-baseline mode, and pairwise (all) mode, making it suitable for assessing and improving LLMs.

DeepResearch
Tongyi DeepResearch is an agentic large language model with 30.5 billion total parameters, designed for long-horizon, deep information-seeking tasks. It demonstrates state-of-the-art performance across various search benchmarks. The model features a fully automated synthetic data generation pipeline, large-scale continual pre-training on agentic data, end-to-end reinforcement learning, and compatibility with two inference paradigms. Users can download the model directly from HuggingFace or ModelScope. The repository also provides benchmark evaluation scripts and information on the Deep Research Agent Family.
pixeltable
Pixeltable is a Python library designed for ML Engineers and Data Scientists to focus on exploration, modeling, and app development without the need to handle data plumbing. It provides a declarative interface for working with text, images, embeddings, and video, enabling users to store, transform, index, and iterate on data within a single table interface. Pixeltable is persistent, acting as a database unlike in-memory Python libraries such as Pandas. It offers features like data storage and versioning, combined data and model lineage, indexing, orchestration of multimodal workloads, incremental updates, and automatic production-ready code generation. The tool emphasizes transparency, reproducibility, cost-saving through incremental data changes, and seamless integration with existing Python code and libraries.

ScaleLLM
ScaleLLM is a cutting-edge inference system engineered for large language models (LLMs), meticulously designed to meet the demands of production environments. It extends its support to a wide range of popular open-source models, including Llama3, Gemma, Bloom, GPT-NeoX, and more. ScaleLLM is currently undergoing active development. We are fully committed to consistently enhancing its efficiency while also incorporating additional features. Feel free to explore our **_Roadmap_** for more details. ## Key Features * High Efficiency: Excels in high-performance LLM inference, leveraging state-of-the-art techniques and technologies like Flash Attention, Paged Attention, Continuous batching, and more. * Tensor Parallelism: Utilizes tensor parallelism for efficient model execution. * OpenAI-compatible API: An efficient golang rest api server that compatible with OpenAI. * Huggingface models: Seamless integration with most popular HF models, supporting safetensors. * Customizable: Offers flexibility for customization to meet your specific needs, and provides an easy way to add new models. * Production Ready: Engineered with production environments in mind, ScaleLLM is equipped with robust system monitoring and management features to ensure a seamless deployment experience.

infinity
Infinity is a high-throughput, low-latency REST API for serving vector embeddings, supporting all sentence-transformer models and frameworks. It is developed under the MIT License and powers inference behind Gradient.ai. The API allows users to deploy models from SentenceTransformers, offers fast inference backends utilizing various accelerators, dynamic batching for efficient processing, correct and tested implementation, and easy-to-use API built on FastAPI with Swagger documentation. Users can embed text, rerank documents, and perform text classification tasks using the tool. Infinity supports various models from Huggingface and provides flexibility in deployment via CLI, Docker, Python API, and cloud services like dstack. The tool is suitable for tasks like embedding, reranking, and text classification.

VLM-R1
VLM-R1 is a stable and generalizable R1-style Large Vision-Language Model proposed for Referring Expression Comprehension (REC) task. It compares R1 and SFT approaches, showing R1 model's steady improvement on out-of-domain test data. The project includes setup instructions, training steps for GRPO and SFT models, support for user data loading, and evaluation process. Acknowledgements to various open-source projects and resources are mentioned. The project aims to provide a reliable and versatile solution for vision-language tasks.

crawl4ai
Crawl4AI is a powerful and free web crawling service that extracts valuable data from websites and provides LLM-friendly output formats. It supports crawling multiple URLs simultaneously, replaces media tags with ALT, and is completely free to use and open-source. Users can integrate Crawl4AI into Python projects as a library or run it as a standalone local server. The tool allows users to crawl and extract data from specified URLs using different providers and models, with options to include raw HTML content, force fresh crawls, and extract meaningful text blocks. Configuration settings can be adjusted in the `crawler/config.py` file to customize providers, API keys, chunk processing, and word thresholds. Contributions to Crawl4AI are welcome from the open-source community to enhance its value for AI enthusiasts and developers.

superlinked
Superlinked is a compute framework for information retrieval and feature engineering systems, focusing on converting complex data into vector embeddings for RAG, Search, RecSys, and Analytics stack integration. It enables custom model performance in machine learning with pre-trained model convenience. The tool allows users to build multimodal vectors, define weights at query time, and avoid postprocessing & rerank requirements. Users can explore the computational model through simple scripts and python notebooks, with a future release planned for production usage with built-in data infra and vector database integrations.

TempCompass
TempCompass is a benchmark designed to evaluate the temporal perception ability of Video LLMs. It encompasses a diverse set of temporal aspects and task formats to comprehensively assess the capability of Video LLMs in understanding videos. The benchmark includes conflicting videos to prevent models from relying on single-frame bias and language priors. Users can clone the repository, install required packages, prepare data, run inference using examples like Video-LLaVA and Gemini, and evaluate the performance of their models across different tasks such as Multi-Choice QA, Yes/No QA, Caption Matching, and Caption Generation.

starcoder2-self-align
StarCoder2-Instruct is an open-source pipeline that introduces StarCoder2-15B-Instruct-v0.1, a self-aligned code Large Language Model (LLM) trained with a fully permissive and transparent pipeline. It generates instruction-response pairs to fine-tune StarCoder-15B without human annotations or data from proprietary LLMs. The tool is primarily finetuned for Python code generation tasks that can be verified through execution, with potential biases and limitations. Users can provide response prefixes or one-shot examples to guide the model's output. The model may have limitations with other programming languages and out-of-domain coding tasks.

MHA2MLA
This repository contains the code for the paper 'Towards Economical Inference: Enabling DeepSeek's Multi-Head Latent Attention in Any Transformer-based LLMs'. It provides tools for fine-tuning and evaluating Llama models, converting models between different frameworks, processing datasets, and performing specific model training tasks like Partial-RoPE Fine-Tuning and Multiple-Head Latent Attention Fine-Tuning. The repository also includes commands for model evaluation using Lighteval and LongBench, along with necessary environment setup instructions.

OSA
OSA (Open-Source-Advisor) is a tool designed to improve the quality of scientific open source projects by automating the generation of README files, documentation, CI/CD scripts, and providing advice and recommendations for repositories. It supports various LLMs accessible via API, local servers, or osa_bot hosted on ITMO servers. OSA is currently under development with features like README file generation, documentation generation, automatic implementation of changes, LLM integration, and GitHub Action Workflow generation. It requires Python 3.10 or higher and tokens for GitHub/GitLab/Gitverse and LLM API key. Users can install OSA using PyPi or build from source, and run it using CLI commands or Docker containers.

CodeTF
CodeTF is a Python transformer-based library for code large language models (Code LLMs) and code intelligence. It provides an interface for training and inferencing on tasks like code summarization, translation, and generation. The library offers utilities for code manipulation across various languages, including easy extraction of code attributes. Using tree-sitter as its core AST parser, CodeTF enables parsing of function names, comments, and variable names. It supports fast model serving, fine-tuning of LLMs, various code intelligence tasks, preprocessed datasets, model evaluation, pretrained and fine-tuned models, and utilities to manipulate source code. CodeTF aims to facilitate the integration of state-of-the-art Code LLMs into real-world applications, ensuring a user-friendly environment for code intelligence tasks.

OpenResearcher
OpenResearcher is a fully open agentic large language model designed for long-horizon deep research scenarios. It achieves an impressive 54.8% accuracy on BrowseComp-Plus, surpassing performance of GPT-4.1, Claude-Opus-4, Gemini-2.5-Pro, DeepSeek-R1, and Tongyi-DeepResearch. The tool is fully open-source, providing the training and evaluation recipe—including data, model, training methodology, and evaluation framework for everyone to progress deep research. It offers features like a fully open-source recipe, highly scalable and low-cost generation of deep research trajectories, and remarkable performance on deep research benchmarks.

VITA
VITA is an open-source interactive omni multimodal Large Language Model (LLM) capable of processing video, image, text, and audio inputs simultaneously. It stands out with features like Omni Multimodal Understanding, Non-awakening Interaction, and Audio Interrupt Interaction. VITA can respond to user queries without a wake-up word, track and filter external queries in real-time, and handle various query inputs effectively. The model utilizes state tokens and a duplex scheme to enhance the multimodal interactive experience.
llama-api-server
This project aims to create a RESTful API server compatible with the OpenAI API using open-source backends like llama/llama2. With this project, various GPT tools/frameworks can be compatible with your own model. Key features include: - **Compatibility with OpenAI API**: The API server follows the OpenAI API structure, allowing seamless integration with existing tools and frameworks. - **Support for Multiple Backends**: The server supports both llama.cpp and pyllama backends, providing flexibility in model selection. - **Customization Options**: Users can configure model parameters such as temperature, top_p, and top_k to fine-tune the model's behavior. - **Batch Processing**: The API supports batch processing for embeddings, enabling efficient handling of multiple inputs. - **Token Authentication**: The server utilizes token authentication to secure access to the API. This tool is particularly useful for developers and researchers who want to integrate large language models into their applications or explore custom models without relying on proprietary APIs.
For similar tasks

ai-on-gke
This repository contains assets related to AI/ML workloads on Google Kubernetes Engine (GKE). Run optimized AI/ML workloads with Google Kubernetes Engine (GKE) platform orchestration capabilities. A robust AI/ML platform considers the following layers: Infrastructure orchestration that support GPUs and TPUs for training and serving workloads at scale Flexible integration with distributed computing and data processing frameworks Support for multiple teams on the same infrastructure to maximize utilization of resources

ray
Ray is a unified framework for scaling AI and Python applications. It consists of a core distributed runtime and a set of AI libraries for simplifying ML compute, including Data, Train, Tune, RLlib, and Serve. Ray runs on any machine, cluster, cloud provider, and Kubernetes, and features a growing ecosystem of community integrations. With Ray, you can seamlessly scale the same code from a laptop to a cluster, making it easy to meet the compute-intensive demands of modern ML workloads.

labelbox-python
Labelbox is a data-centric AI platform for enterprises to develop, optimize, and use AI to solve problems and power new products and services. Enterprises use Labelbox to curate data, generate high-quality human feedback data for computer vision and LLMs, evaluate model performance, and automate tasks by combining AI and human-centric workflows. The academic & research community uses Labelbox for cutting-edge AI research.

djl
Deep Java Library (DJL) is an open-source, high-level, engine-agnostic Java framework for deep learning. It is designed to be easy to get started with and simple to use for Java developers. DJL provides a native Java development experience and allows users to integrate machine learning and deep learning models with their Java applications. The framework is deep learning engine agnostic, enabling users to switch engines at any point for optimal performance. DJL's ergonomic API interface guides users with best practices to accomplish deep learning tasks, such as running inference and training neural networks.

mlflow
MLflow is a platform to streamline machine learning development, including tracking experiments, packaging code into reproducible runs, and sharing and deploying models. MLflow offers a set of lightweight APIs that can be used with any existing machine learning application or library (TensorFlow, PyTorch, XGBoost, etc), wherever you currently run ML code (e.g. in notebooks, standalone applications or the cloud). MLflow's current components are:
* `MLflow Tracking

tt-metal
TT-NN is a python & C++ Neural Network OP library. It provides a low-level programming model, TT-Metalium, enabling kernel development for Tenstorrent hardware.

burn
Burn is a new comprehensive dynamic Deep Learning Framework built using Rust with extreme flexibility, compute efficiency and portability as its primary goals.

awsome-distributed-training
This repository contains reference architectures and test cases for distributed model training with Amazon SageMaker Hyperpod, AWS ParallelCluster, AWS Batch, and Amazon EKS. The test cases cover different types and sizes of models as well as different frameworks and parallel optimizations (Pytorch DDP/FSDP, MegatronLM, NemoMegatron...).
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.