
TempCompass
[ACL 2024 Findings] "TempCompass: Do Video LLMs Really Understand Videos?", Yuanxin Liu, Shicheng Li, Yi Liu, Yuxiang Wang, Shuhuai Ren, Lei Li, Sishuo Chen, Xu Sun, Lu Hou
Stars: 71

TempCompass is a benchmark designed to evaluate the temporal perception ability of Video LLMs. It encompasses a diverse set of temporal aspects and task formats to comprehensively assess the capability of Video LLMs in understanding videos. The benchmark includes conflicting videos to prevent models from relying on single-frame bias and language priors. Users can clone the repository, install required packages, prepare data, run inference using examples like Video-LLaVA and Gemini, and evaluate the performance of their models across different tasks such as Multi-Choice QA, Yes/No QA, Caption Matching, and Caption Generation.
README:
[2024-08-30] Results of Qwen2-VL, GPT-4o, MiniCPM-V-2.6, InternVL-2-8B, LLaVA-OneVision-Qwen-2-7B and InterLM-XComposer-2.5 are added to the leaderboard. GPT-4o establishes the new SoTA!
[2024-08-08] Results of LLaVA-Next-Video, VILA-1.5 and LongVA are added to the leaderboard.
[2024-07] 🎉🎉🎉 TempCompass is integrated into LMMs-Eval. See here for usage examples.
[2024-06-11] Result of Reka-core is added to the leaderboard.
[2024-05-25] TempCompass Leaderboard is available on HuggingFace Space 🤗.
[2024-05-16] 🎊🎊🎊 TempCompass is accepted at ACL 2024 Findings!
[2024-04-14] Evaluation result of Gemini-1.5-pro, the current SOTA Video LLM, is add.
[2024-03-23] The answer prompt is improved to better guide Video LLMs to follow the desired answer formats. The evaluation code now provides an option to disable the use of ChatGPT.
[2024-03-12] 🔥🔥🔥 The evaluation code is released now! Feel free to evaluate your own Video LLMs.

- TempCompass encompasses a diverse set of temporal aspects (left) and task formats (right) to comprehensively evaluate the temporal perception capability of Video LLMs.

-
We construct conflicting videos to prevent the models from taking advantage of single-frame bias and language priors.

-
🤔 Can your Video LLM correctly answer the following question for both two videos?


What is happening in the video?
A. A person drops down the pineapple
B. A person pushes forward the pineapple
C. A person rotates the pineapple
D. A person picks up the pineapple
To begin with, clone this repository and install some packages:
git clone https://github.com/llyx97/TempCompass.git
cd TempCompass
pip install -r requirements.txt1. Task Instructions
The task instructions can be found in questions/.
Task Instruction Generation Procedure
-
Generate Multi-Choice QA instructions (
question_gen.py). -
Manually validate quality and rectify.
-
Generate task instructions for Yes/No QA (
question_gen_yes_no.py), Caption Matching (question_gen_caption_match.py) and Caption Generation (question_gen_captioning.py), based on manually rectified Multi-Choice QA instructions. -
Manually validate quality and rectify.
2. Videos
All the processed videos can be downloaded from google drive or huggingface.
As an alternative, you can also download the raw videos and process them yourself
Run the following commands. The videos will be saved to videos/.
cd utils
python download_video.py # Download raw videos
python process_videos.py # Construct conflicting videosNote: If you encounter a MoviePy error when running the processing script, please refer to this issue.
We use Video-LLaVA and Gemini as examples to illustrate how to conduct MLLM inference on our benchmark.
1. Video-LLaVA
Enter run_video_llava and install the environment as instructed.
Then run the following commands. The prediction results will be saved to predictions/video-llava/<task_type>.
# select <task_type> from multi-choice, yes_no, caption_matching, captioning
python inference_dataset.py --task_type <task_type>2. Gemini
The inference script for gemini-1.5-pro is run_gemini.ipynb. It is recommended to run the script in Google Colab.
After obtaining the MLLM predictions, run the following commands to conduct automatic evaluation. Remember to set your own $OPENAI_API_KEY in utils/eval_utils.py.
-
Multi-Choice QA
python eval_multi_choice.py --video_llm video-llava -
Yes/No QA
python eval_yes_no.py --video_llm video-llava -
Caption Matching
python eval_caption_matching.py --video_llm video-llava -
Caption Generation
python eval_captioning.py --video_llm video-llava
Tip👉: Except for Caption Generation, you can set --disable_llm when running the scripts, which will disable chatgpt-based evaluation (i.e., entirely rely on rule-based evaluation). This is useful when you do not want to use ChatGPT API and your MLLM is good at following the instruction to generate answers of specific format.
The results of each data point will be saved to auto_eval_results/video-llava/<task_type>.json and the overall results on each temporal aspect will be printed out as follows:
{'action': 76.0, 'direction': 35.2, 'speed': 35.6, 'order': 37.7, 'attribute_change': 41.0, 'avg': 45.6}
{'fine-grained action': 58.8, 'coarse-grained action': 90.3, 'object motion': 36.2, 'camera motion': 32.6, 'absolute speed': 47.6, 'relative speed': 28.0, 'order': 37.7, 'color & light change': 43.6, 'size & shape change': 39.4, 'combined change': 41.7, 'other change': 38.9}
Match Success Rate=100.0
Here we provide an example of how to evaluate LLaVA-Next-Video on TempCompass, using lmms-eval.
1. Clone the repo from LLaVA-Next and setup environments
git clone https://github.com/LLaVA-VL/LLaVA-NeXT
cd LLaVA-NeXT
pip install -e .
2. Run inference and evaluation in a single command
accelerate launch --num_processes 8 --main_process_port 12345 -m lmms_eval \
--model llavavid \
--model_args pretrained=lmms-lab/LLaVA-NeXT-Video-32B-Qwen,conv_template=qwen_1_5,video_decode_backend=decord,max_frames_num=32,mm_spatial_pool_mode=average,mm_newline_position=grid,mm_resampler_location=after \
--tasks tempcompass \
--batch_size 1 \
--log_samples \
--log_samples_suffix llava_vid_32B \
--output_path ./logs/
You can also evaluate the performance on each task (e.g., multi-choice) seperately:
accelerate launch --num_processes 8 --main_process_port 12345 -m lmms_eval \
--model llavavid \
--model_args pretrained=lmms-lab/LLaVA-NeXT-Video-32B-Qwen,conv_template=qwen_1_5,video_decode_backend=decord,max_frames_num=32,mm_spatial_pool_mode=average,mm_newline_position=grid,mm_resampler_location=after \
--tasks tempcompass_multi_choice \
--batch_size 1 \
--log_samples \
--log_samples_suffix llava_vid_32B \
--output_path ./logs/
3. Submit results to TempCompass LeaderBoard
Place the lmms-eval outputs (tempcompass_multi_choice.json, tempcompass_yes_no.json, tempcompass_caption_matching.json and tempcompass_captioning.json) into the same folder and run this script:
python merge_eval_result.py
Then submit the output file merged_result.json to the leaderboard.
Note: Currently, the evaluation results calculated by lmms-eval on specific temporal aspects might be incorrect (the average accuracy on each task is correct). To obtain the correct results, you can use this script: acc_lmms_eval.py or submit the result to our leaderboard.

The following figures present results of five representative Video LLMs. Results of more Video LLMs and Image LLMs can be found in our paper and the leaderboard.




We update the answer prompt for Multi-Choice QA and Caption Matching, from "Best Option:" to "Please directly give the best option:", which can better encourage MLLMs to directly select an option. As such, we can reduce the reliance on ChatGPT API, if an MLLM is good at following the instruction.
The success rate of rule-based matching is as follows:
Multi-Choice QA
| V-LLaVA | SPHINX-v2 | LLaMA-VID | Qwen-VL-Chat | PandaGPT | Valley | |
|---|---|---|---|---|---|---|
| old prompt | 37.9 | 99.6 | 62.9 | 46.8 | 6.4 | 3.5 |
| new prompt | 100 | 100 | 97.0 | 98.5 | 3.9 | 0.4 |
Caption Matching
| V-LLaVA | SPHINX-v2 | LLaMA-VID | Qwen-VL-Chat | PandaGPT | Valley | |
|---|---|---|---|---|---|---|
| old prompt | 76.6 | 89.3 | 44.5 | 91.6 | 30.7 | 11.2 |
| new prompt | 99.5 | 99.5 | 68.3 | 96.0 | 22.5 | 3.7 |
- [x] Upload scripts to collect and process videos.
- [x] Upload the code for automatic evaluation.
- [x] Upload the code for task instruction generation.
@article{liu2024tempcompass,
title = {TempCompass: Do Video LLMs Really Understand Videos?},
author = {Yuanxin Liu and Shicheng Li and Yi Liu and Yuxiang Wang and Shuhuai Ren and Lei Li and Sishuo Chen and Xu Sun and Lu Hou},
year = {2024},
journal = {arXiv preprint arXiv: 2403.00476}
}For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for TempCompass
Similar Open Source Tools
TempCompass
TempCompass is a benchmark designed to evaluate the temporal perception ability of Video LLMs. It encompasses a diverse set of temporal aspects and task formats to comprehensively assess the capability of Video LLMs in understanding videos. The benchmark includes conflicting videos to prevent models from relying on single-frame bias and language priors. Users can clone the repository, install required packages, prepare data, run inference using examples like Video-LLaVA and Gemini, and evaluate the performance of their models across different tasks such as Multi-Choice QA, Yes/No QA, Caption Matching, and Caption Generation.

ScaleLLM
ScaleLLM is a cutting-edge inference system engineered for large language models (LLMs), meticulously designed to meet the demands of production environments. It extends its support to a wide range of popular open-source models, including Llama3, Gemma, Bloom, GPT-NeoX, and more. ScaleLLM is currently undergoing active development. We are fully committed to consistently enhancing its efficiency while also incorporating additional features. Feel free to explore our **_Roadmap_** for more details. ## Key Features * High Efficiency: Excels in high-performance LLM inference, leveraging state-of-the-art techniques and technologies like Flash Attention, Paged Attention, Continuous batching, and more. * Tensor Parallelism: Utilizes tensor parallelism for efficient model execution. * OpenAI-compatible API: An efficient golang rest api server that compatible with OpenAI. * Huggingface models: Seamless integration with most popular HF models, supporting safetensors. * Customizable: Offers flexibility for customization to meet your specific needs, and provides an easy way to add new models. * Production Ready: Engineered with production environments in mind, ScaleLLM is equipped with robust system monitoring and management features to ensure a seamless deployment experience.

agentscope
AgentScope is a multi-agent platform designed to empower developers to build multi-agent applications with large-scale models. It features three high-level capabilities: Easy-to-Use, High Robustness, and Actor-Based Distribution. AgentScope provides a list of `ModelWrapper` to support both local model services and third-party model APIs, including OpenAI API, DashScope API, Gemini API, and ollama. It also enables developers to rapidly deploy local model services using libraries such as ollama (CPU inference), Flask + Transformers, Flask + ModelScope, FastChat, and vllm. AgentScope supports various services, including Web Search, Data Query, Retrieval, Code Execution, File Operation, and Text Processing. Example applications include Conversation, Game, and Distribution. AgentScope is released under Apache License 2.0 and welcomes contributions.

candle-vllm
Candle-vllm is an efficient and easy-to-use platform designed for inference and serving local LLMs, featuring an OpenAI compatible API server. It offers a highly extensible trait-based system for rapid implementation of new module pipelines, streaming support in generation, efficient management of key-value cache with PagedAttention, and continuous batching. The tool supports chat serving for various models and provides a seamless experience for users to interact with LLMs through different interfaces.

openlrc
Open-Lyrics is a Python library that transcribes voice files using faster-whisper and translates/polishes the resulting text into `.lrc` files in the desired language using LLM, e.g. OpenAI-GPT, Anthropic-Claude. It offers well preprocessed audio to reduce hallucination and context-aware translation to improve translation quality. Users can install the library from PyPI or GitHub and follow the installation steps to set up the environment. The tool supports GUI usage and provides Python code examples for transcription and translation tasks. It also includes features like utilizing context and glossary for translation enhancement, pricing information for different models, and a list of todo tasks for future improvements.

GraphGen
GraphGen is a framework for synthetic data generation guided by knowledge graphs. It enhances supervised fine-tuning for large language models (LLMs) by generating synthetic data based on a fine-grained knowledge graph. The tool identifies knowledge gaps in LLMs, prioritizes generating QA pairs targeting high-value knowledge, incorporates multi-hop neighborhood sampling, and employs style-controlled generation to diversify QA data. Users can use LLaMA-Factory and xtuner for fine-tuning LLMs after data generation.

infinity
Infinity is a high-throughput, low-latency REST API for serving vector embeddings, supporting all sentence-transformer models and frameworks. It is developed under the MIT License and powers inference behind Gradient.ai. The API allows users to deploy models from SentenceTransformers, offers fast inference backends utilizing various accelerators, dynamic batching for efficient processing, correct and tested implementation, and easy-to-use API built on FastAPI with Swagger documentation. Users can embed text, rerank documents, and perform text classification tasks using the tool. Infinity supports various models from Huggingface and provides flexibility in deployment via CLI, Docker, Python API, and cloud services like dstack. The tool is suitable for tasks like embedding, reranking, and text classification.

auto-round
AutoRound is an advanced weight-only quantization algorithm for low-bits LLM inference. It competes impressively against recent methods without introducing any additional inference overhead. The method adopts sign gradient descent to fine-tune rounding values and minmax values of weights in just 200 steps, often significantly outperforming SignRound with the cost of more tuning time for quantization. AutoRound is tailored for a wide range of models and consistently delivers noticeable improvements.

OSA
OSA (Open-Source-Advisor) is a tool designed to improve the quality of scientific open source projects by automating the generation of README files, documentation, CI/CD scripts, and providing advice and recommendations for repositories. It supports various LLMs accessible via API, local servers, or osa_bot hosted on ITMO servers. OSA is currently under development with features like README file generation, documentation generation, automatic implementation of changes, LLM integration, and GitHub Action Workflow generation. It requires Python 3.10 or higher and tokens for GitHub/GitLab/Gitverse and LLM API key. Users can install OSA using PyPi or build from source, and run it using CLI commands or Docker containers.

KwaiAgents
KwaiAgents is a series of Agent-related works open-sourced by the [KwaiKEG](https://github.com/KwaiKEG) from [Kuaishou Technology](https://www.kuaishou.com/en). The open-sourced content includes: 1. **KAgentSys-Lite**: a lite version of the KAgentSys in the paper. While retaining some of the original system's functionality, KAgentSys-Lite has certain differences and limitations when compared to its full-featured counterpart, such as: (1) a more limited set of tools; (2) a lack of memory mechanisms; (3) slightly reduced performance capabilities; and (4) a different codebase, as it evolves from open-source projects like BabyAGI and Auto-GPT. Despite these modifications, KAgentSys-Lite still delivers comparable performance among numerous open-source Agent systems available. 2. **KAgentLMs**: a series of large language models with agent capabilities such as planning, reflection, and tool-use, acquired through the Meta-agent tuning proposed in the paper. 3. **KAgentInstruct**: over 200k Agent-related instructions finetuning data (partially human-edited) proposed in the paper. 4. **KAgentBench**: over 3,000 human-edited, automated evaluation data for testing Agent capabilities, with evaluation dimensions including planning, tool-use, reflection, concluding, and profiling.
unsloth
Unsloth is a tool that allows users to fine-tune large language models (LLMs) 2-5x faster with 80% less memory. It is a free and open-source tool that can be used to fine-tune LLMs such as Gemma, Mistral, Llama 2-5, TinyLlama, and CodeLlama 34b. Unsloth supports 4-bit and 16-bit QLoRA / LoRA fine-tuning via bitsandbytes. It also supports DPO (Direct Preference Optimization), PPO, and Reward Modelling. Unsloth is compatible with Hugging Face's TRL, Trainer, Seq2SeqTrainer, and Pytorch code. It is also compatible with NVIDIA GPUs since 2018+ (minimum CUDA Capability 7.0).

pytorch-lightning
PyTorch Lightning is a framework for training and deploying AI models. It provides a high-level API that abstracts away the low-level details of PyTorch, making it easier to write and maintain complex models. Lightning also includes a number of features that make it easy to train and deploy models on multiple GPUs or TPUs, and to track and visualize training progress. PyTorch Lightning is used by a wide range of organizations, including Google, Facebook, and Microsoft. It is also used by researchers at top universities around the world. Here are some of the benefits of using PyTorch Lightning: * **Increased productivity:** Lightning's high-level API makes it easy to write and maintain complex models. This can save you time and effort, and allow you to focus on the research or business problem you're trying to solve. * **Improved performance:** Lightning's optimized training loops and data loading pipelines can help you train models faster and with better performance. * **Easier deployment:** Lightning makes it easy to deploy models to a variety of platforms, including the cloud, on-premises servers, and mobile devices. * **Better reproducibility:** Lightning's logging and visualization tools make it easy to track and reproduce training results.
libllm
libLLM is an open-source project designed for efficient inference of large language models (LLM) on personal computers and mobile devices. It is optimized to run smoothly on common devices, written in C++14 without external dependencies, and supports CUDA for accelerated inference. Users can build the tool for CPU only or with CUDA support, and run libLLM from the command line. Additionally, there are API examples available for Python and the tool can export Huggingface models.

evalplus
EvalPlus is a rigorous evaluation framework for LLM4Code, providing HumanEval+ and MBPP+ tests to evaluate large language models on code generation tasks. It offers precise evaluation and ranking, coding rigorousness analysis, and pre-generated code samples. Users can use EvalPlus to generate code solutions, post-process code, and evaluate code quality. The tool includes tools for code generation and test input generation using various backends.
chatllm.cpp
ChatLLM.cpp is a pure C++ implementation tool for real-time chatting with RAG on your computer. It supports inference of various models ranging from less than 1B to more than 300B. The tool provides accelerated memory-efficient CPU inference with quantization, optimized KV cache, and parallel computing. It allows streaming generation with a typewriter effect and continuous chatting with virtually unlimited content length. ChatLLM.cpp also offers features like Retrieval Augmented Generation (RAG), LoRA, Python/JavaScript/C bindings, web demo, and more possibilities. Users can clone the repository, quantize models, build the project using make or CMake, and run quantized models for interactive chatting.

cellseg_models.pytorch
cellseg-models.pytorch is a Python library built upon PyTorch for 2D cell/nuclei instance segmentation models. It provides multi-task encoder-decoder architectures and post-processing methods for segmenting cell/nuclei instances. The library offers high-level API to define segmentation models, open-source datasets for training, flexibility to modify model components, sliding window inference, multi-GPU inference, benchmarking utilities, regularization techniques, and example notebooks for training and finetuning models with different backbones.
For similar tasks

llm-compression-intelligence
This repository presents the findings of the paper "Compression Represents Intelligence Linearly". The study reveals a strong linear correlation between the intelligence of LLMs, as measured by benchmark scores, and their ability to compress external text corpora. Compression efficiency, derived from raw text corpora, serves as a reliable evaluation metric that is linearly associated with model capabilities. The repository includes the compression corpora used in the paper, code for computing compression efficiency, and data collection and processing pipelines.

edsl
The Expected Parrot Domain-Specific Language (EDSL) package enables users to conduct computational social science and market research with AI. It facilitates designing surveys and experiments, simulating responses using large language models, and performing data labeling and other research tasks. EDSL includes built-in methods for analyzing, visualizing, and sharing research results. It is compatible with Python 3.9 - 3.11 and requires API keys for LLMs stored in a `.env` file.

fast-stable-diffusion
Fast-stable-diffusion is a project that offers notebooks for RunPod, Paperspace, and Colab Pro adaptations with AUTOMATIC1111 Webui and Dreambooth. It provides tools for running and implementing Dreambooth, a stable diffusion project. The project includes implementations by XavierXiao and is sponsored by Runpod, Paperspace, and Colab Pro.

RobustVLM
This repository contains code for the paper 'Robust CLIP: Unsupervised Adversarial Fine-Tuning of Vision Embeddings for Robust Large Vision-Language Models'. It focuses on fine-tuning CLIP in an unsupervised manner to enhance its robustness against visual adversarial attacks. By replacing the vision encoder of large vision-language models with the fine-tuned CLIP models, it achieves state-of-the-art adversarial robustness on various vision-language tasks. The repository provides adversarially fine-tuned ViT-L/14 CLIP models and offers insights into zero-shot classification settings and clean accuracy improvements.
TempCompass
TempCompass is a benchmark designed to evaluate the temporal perception ability of Video LLMs. It encompasses a diverse set of temporal aspects and task formats to comprehensively assess the capability of Video LLMs in understanding videos. The benchmark includes conflicting videos to prevent models from relying on single-frame bias and language priors. Users can clone the repository, install required packages, prepare data, run inference using examples like Video-LLaVA and Gemini, and evaluate the performance of their models across different tasks such as Multi-Choice QA, Yes/No QA, Caption Matching, and Caption Generation.

LLM-LieDetector
This repository contains code for reproducing experiments on lie detection in black-box LLMs by asking unrelated questions. It includes Q/A datasets, prompts, and fine-tuning datasets for generating lies with language models. The lie detectors rely on asking binary 'elicitation questions' to diagnose whether the model has lied. The code covers generating lies from language models, training and testing lie detectors, and generalization experiments. It requires access to GPUs and OpenAI API calls for running experiments with open-source models. Results are stored in the repository for reproducibility.

bigcodebench
BigCodeBench is an easy-to-use benchmark for code generation with practical and challenging programming tasks. It aims to evaluate the true programming capabilities of large language models (LLMs) in a more realistic setting. The benchmark is designed for HumanEval-like function-level code generation tasks, but with much more complex instructions and diverse function calls. BigCodeBench focuses on the evaluation of LLM4Code with diverse function calls and complex instructions, providing precise evaluation & ranking and pre-generated samples to accelerate code intelligence research. It inherits the design of the EvalPlus framework but differs in terms of execution environment and test evaluation.
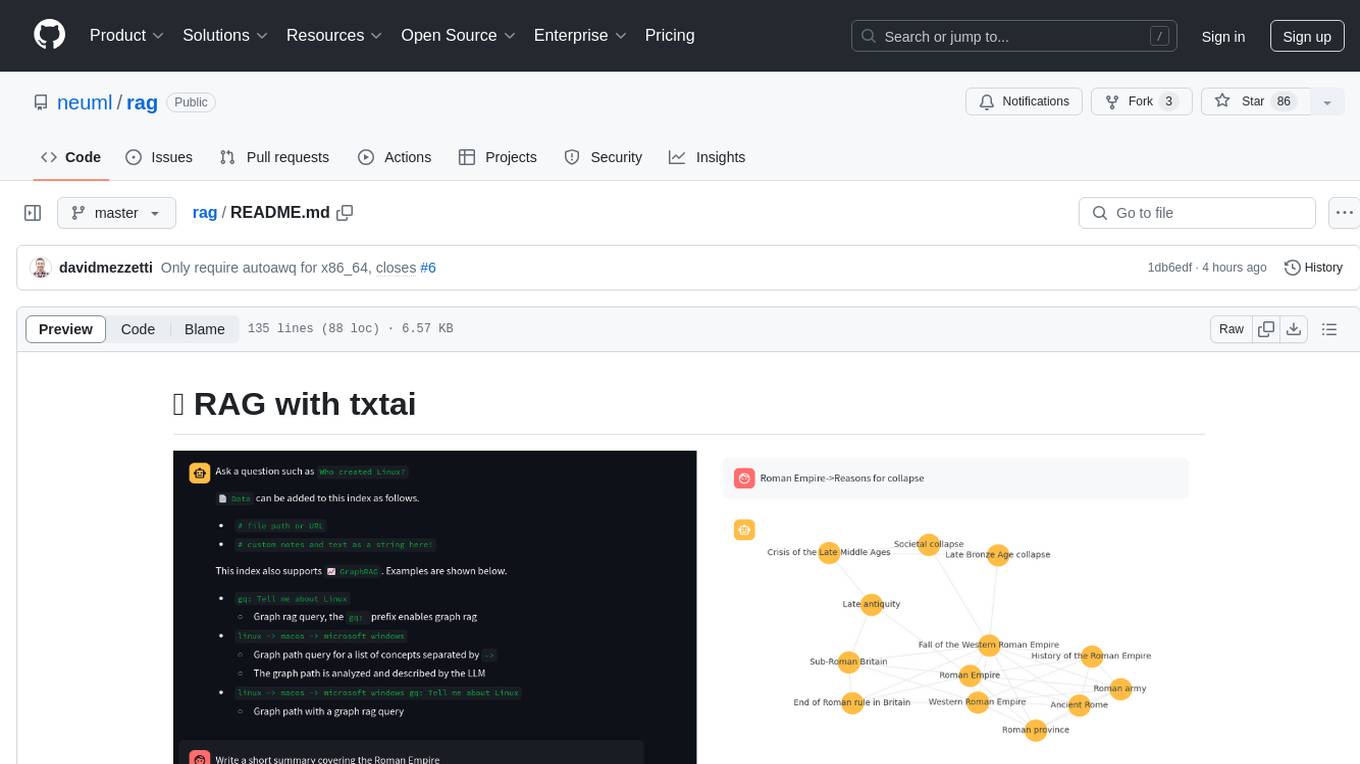
rag
RAG with txtai is a Retrieval Augmented Generation (RAG) Streamlit application that helps generate factually correct content by limiting the context in which a Large Language Model (LLM) can generate answers. It supports two categories of RAG: Vector RAG, where context is supplied via a vector search query, and Graph RAG, where context is supplied via a graph path traversal query. The application allows users to run queries, add data to the index, and configure various parameters to control its behavior.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.