Best AI tools for< Video Content Creator >
Infographic
11 - AI tool Sites
PlayAI
PlayAI is a leading AI voice generator and text-to-speech platform that offers a wide range of features to create high-quality audio content. With over 206 natural-sounding voices in 30+ languages, users can generate multi-speaker AI voices indistinguishable from humans. The platform allows users to enhance audio with speech styles, pronunciations, and SSML tags, making it ideal for audiobooks, YouTube videos, podcasts, and more. PlayAI's AI voice generator works by converting written text into natural-sounding speech through advanced text-to-speech technology, with real-time conversion and customizability options. The platform also supports voice cloning, API integration, and industry-leading AI voice products for various applications.
Puppetry
Puppetry is an AI tool that provides a comprehensive toolset for creating videos with talking faces. It enables video content creators, game artists, educators, and marketers to generate talking videos using AI puppets and craft compelling scripts with the power of ChatGPT. Users can create engaging and informative videos using AI technology, including features like AI puppet creation, realistic avatars, advanced technology, and intuitive user interface.
Pixop
Pixop is a cloud-based AI- and ML-powered video enhancer that is designed to help production companies, TV stations, rightsholders and independent creators monetize their digital archives by enhancing and upscaling footage to fit today's screens. Pixop's automated AI and ML filters make easy work of remastering your digital masters from SD all the way to UHD 8K. No expensive hardware or complicated setups involved.
SwiftSora
SwiftSora is an open-source project that enables users to generate videos from prompt text online. The project utilizes OpenAI's Sora model to streamline video creation and includes a straightforward one-click website deployment feature. With SwiftSora, users can effortlessly produce high-quality video assets, ranging from realistic scenes to imaginative visuals, by simply providing text instructions. The platform offers a user-friendly interface with customizable settings, making it accessible to both beginners and experienced video creators. SwiftSora empowers users to elevate their creativity and redefine the boundaries of possibility in video production.
SoraWebui
SoraWebui is an open-source web platform that simplifies video creation by allowing users to generate videos from text using OpenAI's Sora model. It provides an easy-to-use interface and one-click website deployment, making it accessible to both professionals and enthusiasts in video production and AI technology. SoraWebui also includes a simulated version of the Sora API called FakeSoraAPI, which allows developers to start developing and testing their projects in a mock environment.
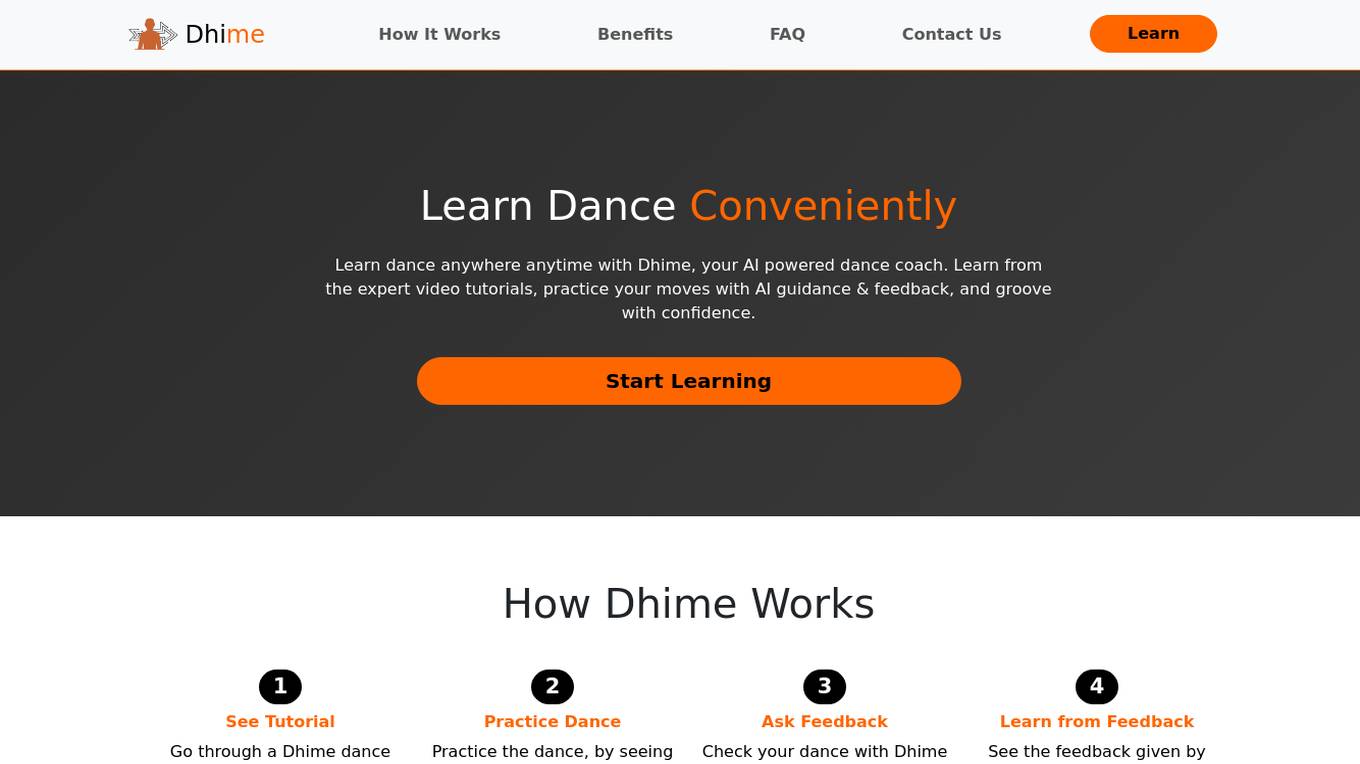
Dhime
Dhime is an AI-powered dance coaching application that allows users to learn dance conveniently from expert video tutorials, practice with AI guidance and feedback, and improve their dance skills with confidence. It offers unlimited practice, personalized lessons, and continuous progress tracking for effective learning. Dhime serves as a platform for both tutors and dance academies to reach worldwide students and enhance their teaching methods. The application ensures privacy by recording and analyzing dance videos internally without sharing them externally. With Dhime, users can learn dance anytime, anywhere, and at their own pace.
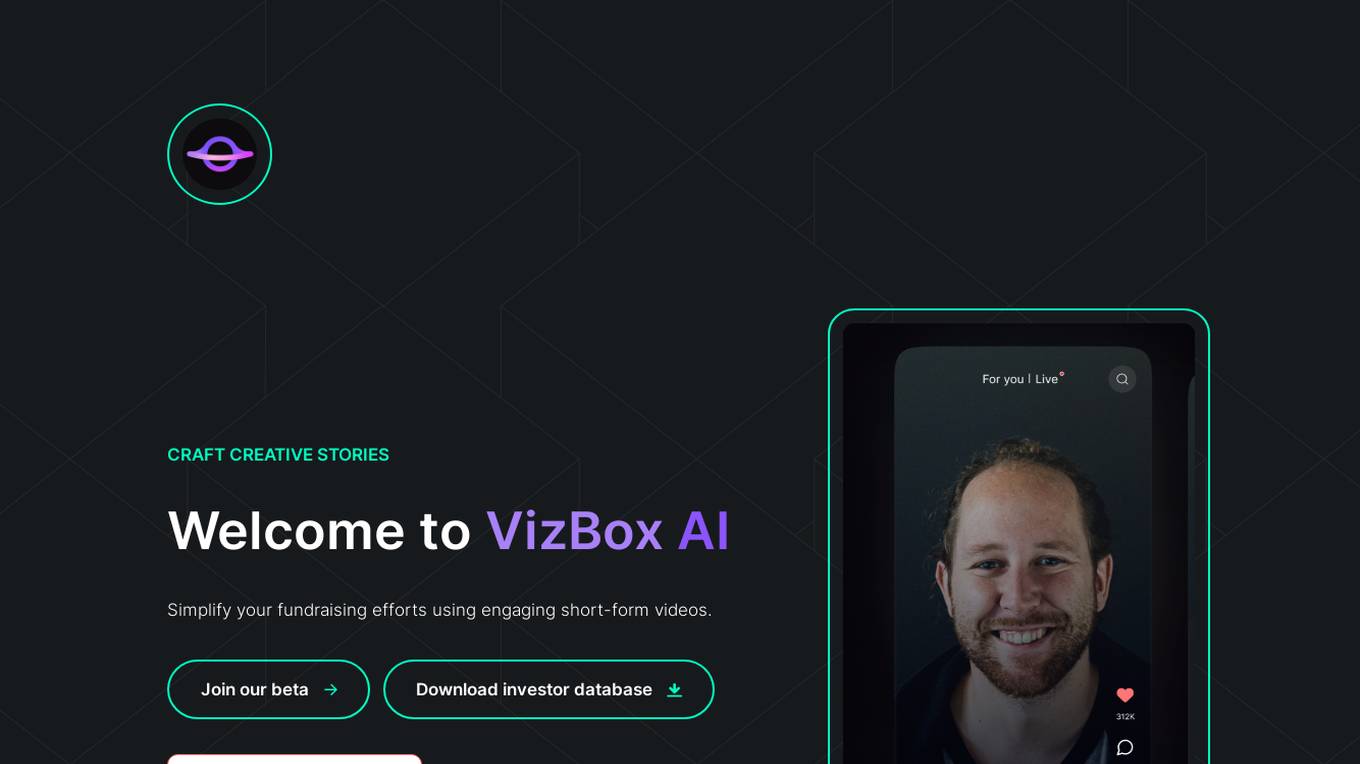
VizBox AI
VizBox AI is an AI-powered platform that simplifies fundraising efforts by creating engaging short-form videos. It offers built-in privacy features, advanced sentiment analysis, and community-driven innovation to enhance founder-investor engagement. The platform enables users to develop compelling stories, receive verified feedback, and streamline the pitch process through high-impact video content.
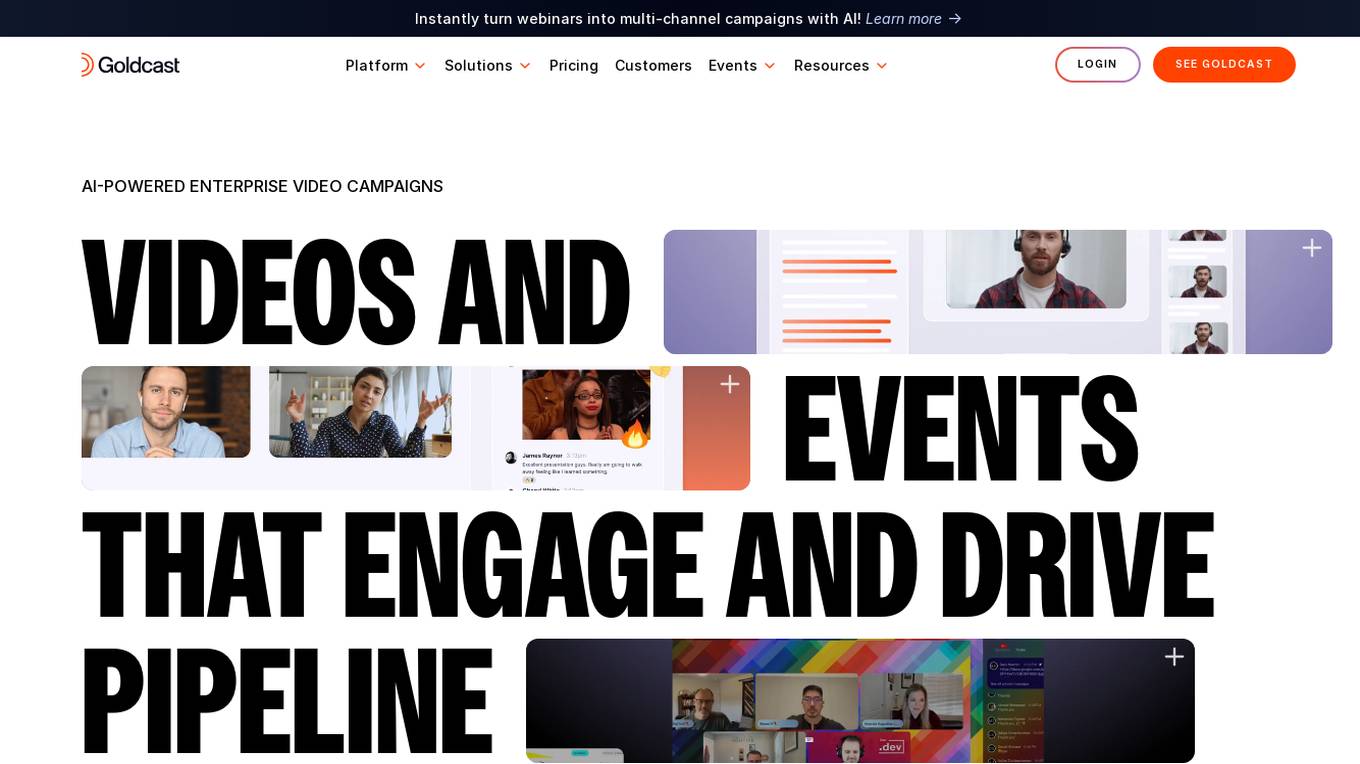
Goldcast
Goldcast is an AI-first video campaign platform designed for B2B videos, webinars, and events. It enables users to instantly turn webinars into multi-channel campaigns using AI technology. The platform helps in efficiently connecting with the audience, boosting brand authority, and driving revenue through engaging videos and events. Goldcast offers solutions like Core for end-to-end event management and Content Lab for effortless video repurposing. Trusted by thousands of B2B marketers, Goldcast provides an engaging and interactive experience for both creators and viewers.
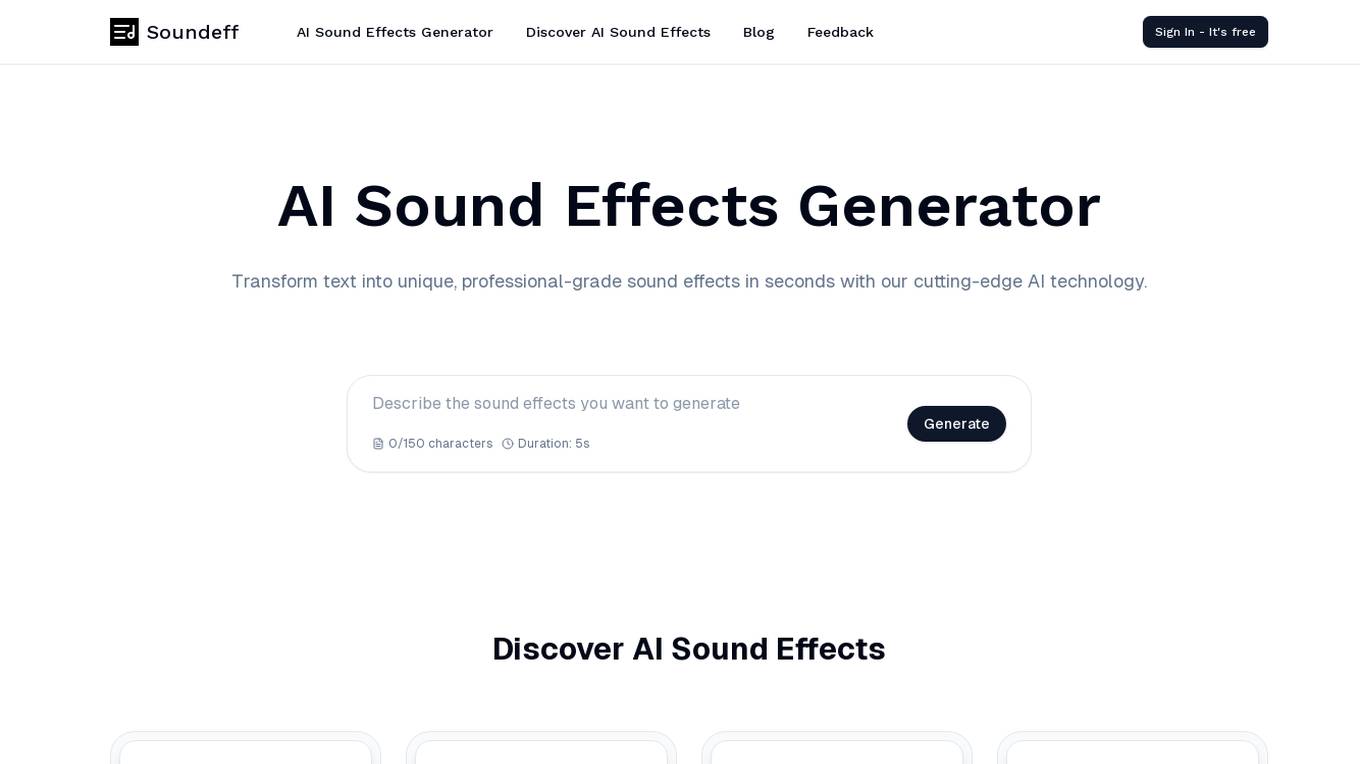
Soundeff
Soundeff is an AI Sound Effects Generator that allows users to create custom sound effects using cutting-edge AI technology. It offers a platform for professionals and enthusiasts in the audio-visual world to enhance their creative projects with unique, professional-grade sound effects in seconds. Users can generate a variety of sound effects for gaming, videos, podcasts, films, music, and user interfaces, improving user engagement and storytelling. Soundeff stands out with its AI-generated effects that cater to a wide range of creative needs, providing a seamless workflow and expanding sound libraries.
Videco
Videco is an AI-driven personalized and interactive video platform designed for sales and marketing teams to enhance customer engagement and boost conversions. It offers features such as AI voice cloning, interactive buttons, lead generation, in-video calendars, and dynamic video creation. With Videco, users can personalize videos, distribute them through various channels, analyze performance, and optimize results. The platform aims to help businesses 10x their pipeline with video content and improve sales outcomes through personalized interactions.
Tad AI
Tad AI is an AI music generator that allows users to create original songs with their choice of genres and moods using text prompts. It offers a simple and quick way to generate custom music in minutes, ensuring that the music created is royalty-free and safe from copyright issues. Tad AI is versatile and dynamic, allowing users to explore various genres and moods, and it can generate AI lyrics in one click. The platform is best suited for musicians, video content creators, businesses, hobbyists, and casual users looking to create music for personal or professional use.
17 - Open Source Tools

Awesome-LLMs-for-Video-Understanding
Awesome-LLMs-for-Video-Understanding is a repository dedicated to exploring Video Understanding with Large Language Models. It provides a comprehensive survey of the field, covering models, pretraining, instruction tuning, and hybrid methods. The repository also includes information on tasks, datasets, and benchmarks related to video understanding. Contributors are encouraged to add new papers, projects, and materials to enhance the repository.

TempCompass
TempCompass is a benchmark designed to evaluate the temporal perception ability of Video LLMs. It encompasses a diverse set of temporal aspects and task formats to comprehensively assess the capability of Video LLMs in understanding videos. The benchmark includes conflicting videos to prevent models from relying on single-frame bias and language priors. Users can clone the repository, install required packages, prepare data, run inference using examples like Video-LLaVA and Gemini, and evaluate the performance of their models across different tasks such as Multi-Choice QA, Yes/No QA, Caption Matching, and Caption Generation.

VideoLLaMA2
VideoLLaMA 2 is a project focused on advancing spatial-temporal modeling and audio understanding in video-LLMs. It provides tools for multi-choice video QA, open-ended video QA, and video captioning. The project offers model zoo with different configurations for visual encoder and language decoder. It includes training and evaluation guides, as well as inference capabilities for video and image processing. The project also features a demo setup for running a video-based Large Language Model web demonstration.

videodb-python
VideoDB Python SDK allows you to interact with the VideoDB serverless database. Manage videos as intelligent data, not files. It's scalable, cost-efficient & optimized for AI applications and LLM integration. The SDK provides functionalities for uploading videos, viewing videos, streaming specific sections of videos, searching inside a video, searching inside multiple videos in a collection, adding subtitles to a video, generating thumbnails, and more. It also offers features like indexing videos by spoken words, semantic indexing, and future indexing options for scenes, faces, and specific domains like sports. The SDK aims to simplify video management and enhance AI applications with video data.

CogVideo
CogVideo is an open-source repository that provides pretrained text-to-video models for generating videos based on input text. It includes models like CogVideoX-2B and CogVideo, offering powerful video generation capabilities. The repository offers tools for inference, fine-tuning, and model conversion, along with demos showcasing the model's capabilities through CLI, web UI, and online experiences. CogVideo aims to facilitate the creation of high-quality videos from textual descriptions, catering to a wide range of applications.
ST-LLM
ST-LLM is a temporal-sensitive video large language model that incorporates joint spatial-temporal modeling, dynamic masking strategy, and global-local input module for effective video understanding. It has achieved state-of-the-art results on various video benchmarks. The repository provides code and weights for the model, along with demo scripts for easy usage. Users can train, validate, and use the model for tasks like video description, action identification, and reasoning.
VideoTuna
VideoTuna is a codebase for text-to-video applications that integrates multiple AI video generation models for text-to-video, image-to-video, and text-to-image generation. It provides comprehensive pipelines in video generation, including pre-training, continuous training, post-training, and fine-tuning. The models in VideoTuna include U-Net and DiT architectures for visual generation tasks, with upcoming releases of a new 3D video VAE and a controllable facial video generation model.

TRACE
TRACE is a temporal grounding video model that utilizes causal event modeling to capture videos' inherent structure. It presents a task-interleaved video LLM model tailored for sequential encoding/decoding of timestamps, salient scores, and textual captions. The project includes various model checkpoints for different stages and fine-tuning on specific datasets. It provides evaluation codes for different tasks like VTG, MVBench, and VideoMME. The repository also offers annotation files and links to raw videos preparation projects. Users can train the model on different tasks and evaluate the performance based on metrics like CIDER, METEOR, SODA_c, F1, mAP, Hit@1, etc. TRACE has been enhanced with trace-retrieval and trace-uni models, showing improved performance on dense video captioning and general video understanding tasks.
ai-video-search-engine
AI Video Search Engine (AVSE) is a video search engine powered by the latest tools in AI. It allows users to search for specific answers within millions of videos by indexing video content. The tool extracts video transcription, elements like thumbnail and description, and generates vector embeddings using AI models. Users can search for relevant results based on questions, view timestamped transcripts, and get video summaries. AVSE requires a paid Supabase & Fly.io account for hosting and can handle millions of videos with the current setup.
VideoTree
VideoTree is an official implementation for a query-adaptive and hierarchical framework for understanding long videos with LLMs. It dynamically extracts query-related information from input videos and builds a tree-based video representation for LLM reasoning. The tool requires Python 3.8 or above and leverages models like LaViLa and EVA-CLIP-8B for feature extraction. It also provides scripts for tasks like Adaptive Breath Expansion, Relevance-based Depth Expansion, and LLM Reasoning. The codebase is being updated to incorporate scripts/captions for NeXT-QA and IntentQA in the future.

VILA
VILA is a family of open Vision Language Models optimized for efficient video understanding and multi-image understanding. It includes models like NVILA, LongVILA, VILA-M3, VILA-U, and VILA-1.5, each offering specific features and capabilities. The project focuses on efficiency, accuracy, and performance in various tasks related to video, image, and language understanding and generation. VILA models are designed to be deployable on diverse NVIDIA GPUs and support long-context video understanding, medical applications, and multi-modal design.
finetrainers
FineTrainers is a work-in-progress library designed to support the training of video models, with a focus on LoRA training for popular video models in Diffusers. It aims to eventually extend support to other methods like controlnets, control-loras, distillation, etc. The library provides tools for training custom models, handling big datasets, and supporting multi-backend distributed training. It also offers tooling for curating small and high-quality video datasets for fine-tuning.
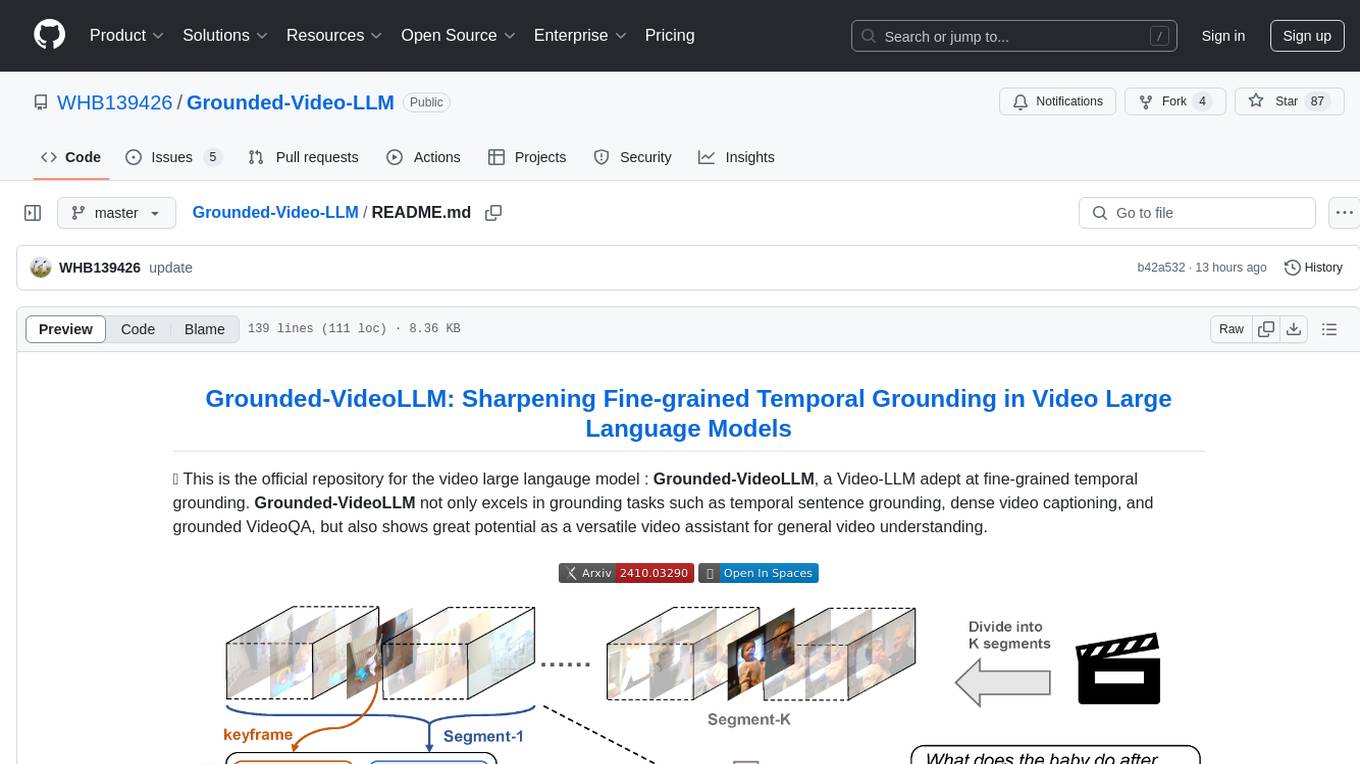
Grounded-Video-LLM
Grounded-VideoLLM is a Video Large Language Model specialized in fine-grained temporal grounding. It excels in tasks such as temporal sentence grounding, dense video captioning, and grounded VideoQA. The model incorporates an additional temporal stream, discrete temporal tokens with specific time knowledge, and a multi-stage training scheme. It shows potential as a versatile video assistant for general video understanding. The repository provides pretrained weights, inference scripts, and datasets for training. Users can run inference queries to get temporal information from videos and train the model from scratch.
Video-ChatGPT
Video-ChatGPT is a video conversation model that aims to generate meaningful conversations about videos by combining large language models with a pretrained visual encoder adapted for spatiotemporal video representation. It introduces high-quality video-instruction pairs, a quantitative evaluation framework for video conversation models, and a unique multimodal capability for video understanding and language generation. The tool is designed to excel in tasks related to video reasoning, creativity, spatial and temporal understanding, and action recognition.

CogVideo
CogVideo is a Python library for analyzing and processing video data. It provides functionalities for video segmentation, object detection, and tracking. With CogVideo, users can extract meaningful information from video streams, enabling applications in computer vision, surveillance, and video analytics. The library is designed to be user-friendly and efficient, making it suitable for both research and industrial projects.
ai
A TypeScript toolkit for building AI-driven video workflows on the server, powered by Mux! @mux/ai provides purpose-driven workflow functions and primitive functions that integrate with popular AI/LLM providers like OpenAI, Anthropic, and Google. It offers pre-built workflows for tasks like generating summaries and tags, content moderation, chapter generation, and more. The toolkit is cost-effective, supports multi-modal analysis, tone control, and configurable thresholds, and provides full TypeScript support. Users can easily configure credentials for Mux and AI providers, as well as cloud infrastructure like AWS S3 for certain workflows. @mux/ai is production-ready, offers composable building blocks, and supports universal language detection.
Vision-Agents
Vision Agents is an open-source project by Stream that provides building blocks for creating intelligent, low-latency video experiences powered by custom models and infrastructure. It offers multi-modal AI agents that watch, listen, and understand video in real-time. The project includes SDKs for various platforms and integrates with popular AI services like Gemini and OpenAI. Vision Agents can be used for tasks such as sports coaching, security camera systems with package theft detection, and building invisible assistants for various applications. The project aims to simplify the development of real-time vision AI applications by providing a range of processors, integrations, and out-of-the-box features.
20 - OpenAI Gpts
The Video Content Creator Coach
A content creator coach aiding in YouTube video content creation, analysis, script writing and storytelling. Designed by a successful YouTuber to help other YouTubers grow their channels.

DUMPTY NewsVidGenie
NewsVidGenie aims to assist content creators in quickly generating creative and relevant YouTube video concepts based on the latest news. It simplifies the process of converting current events into engaging video content

Video Generator
This GPTs engages with users through friendly and professional dialogue to create higher quality video covers. https://www.aisora.org By Mr Sora

CreceTube Experto
Asistente multilingüe para la creación de contenido de video, con apoyo y consejos creativos en múltiples idiomas.