
TRACE
[Preprint] TRACE: Temporal Grounding Video LLM via Casual Event Modeling
Stars: 54

TRACE is a temporal grounding video model that utilizes causal event modeling to capture videos' inherent structure. It presents a task-interleaved video LLM model tailored for sequential encoding/decoding of timestamps, salient scores, and textual captions. The project includes various model checkpoints for different stages and fine-tuning on specific datasets. It provides evaluation codes for different tasks like VTG, MVBench, and VideoMME. The repository also offers annotation files and links to raw videos preparation projects. Users can train the model on different tasks and evaluate the performance based on metrics like CIDER, METEOR, SODA_c, F1, mAP, Hit@1, etc. TRACE has been enhanced with trace-retrieval and trace-uni models, showing improved performance on dense video captioning and general video understanding tasks.
README:
If our project helps you, please give us a star ⭐ and cite our paper!
- 01/11/2024, 🔥We are excited to announce the release of trace-uni, which has been enhanced by incorporating additional general video understanding data from a subset of LLaVA-Video-178k. Our results indicate that (1) the TRACE architecture is still capable of handling general video understanding tasks (53.8 on MVBench and 49.6 on VideoMME); (2) although not adding more VTG data, trace-uni outperforms trace in both VTG tasks and general video understanding tasks.
- 31/10/2024, 🔥 We evaluated the TRACE nodel on VideoMME benchmark and updated the evaluation code.
- 25/10/2024, 🔥 We evaluated the TRACE model on the MVBench benchmark and updated the evaluation code accordingly. Our findings indicate that, despite not being trained on extensive multi-task datasets, TRACE is still capable of effectively handling general QA tasks.
- 19/10/2024, 🔥 We release trace-retrieval by forcing the predicted timestamps to be align with the input frame timestamps. Results show trace-retrieval achieve better performance on dense video captioning tasks
- 10/10/2024, 🔥 Annotation files of training data are released!
- 10/10/2024, 🔥 Our model checkpoints and code are released!
TODO
- [x] Release the model checkpoints
- [x] Release the inference and evaluation code
- [x] Release the training and fine-tuning code
- [x] Release the training data
- [x] Release the TRACE-Retrieval, which outputs timestamps of input frames instead of predict unseen timestamps.
- [x] Train TRACE models on more tasks.
In this work
- We model the videos by a series of events, and propose causal event modeling framework to capture videos' inherent structure.
- We present a novel task-interleaved video LLM model, TRACE, tailored to implement the causal event modeling framework through the sequential encoding/decoding of timestamps, salient scores, and textual captions.

Overview of TRACE.
We use NPU environments for training and fine-tuning, and use V100 GPUs for evaluation. The environment we use can be found in npu-requirements and gpu-requirements.
| Checkpoints | Description | URL |
|---|---|---|
| Initialization | Weights initialized from VideoLLaMA2 | trace-init |
| Stage-1 | Model checkpoints trained after stage-1 | trace-stage1 |
| Stage-2 | Model checkpoints trained after stage-2 | trace |
| FT-Charades | Fine-tuned on Charades-STA dataset | trace-ft-charades |
| FT-Youcook2 | Fine-tuned on Youcook2 dataset | trace-ft-youcook2 |
| FT-QVHighlights | Fine-tuned on QVHighlights dataset | trace-ft-qvhighlights |
| TRACE-retrieval | Forcing the predicted timestamps to be align with input timestamps | trace-retrieval |
| TRACE-uni | Incorporating additional general video understanding data from a subset of LLaVA-Video-178k. | trace-uni |
Please make sure the model and video paths are correct before running the code.
- Inference codes are provided in inference.py.
- Evaluation codes are provided in trace/eval
- Evaluation of VTG tasks: Provided in eval/eval.sh.
- Evaluation of MVBench: Provided in eval/mvbench/eval.sh
- Evaluation of VideoMME: Provided in eval/videomme/eval.sh
We have provided the annotation files, and the raw videos can be prepared by the following projects
Stage 1 training
bash TRACE/scripts/train/pretrain-128.sh
Stage 2 training
bash TRACE/scripts/train/sft-128.sh
Fine-tune on downsteam task
bash TRACE/scripts/train/sft-youcook2.sh
Please config the data and model paths before running the scrips.
| Youcook2 (Zero-Shot) | CIDER | METEOR | SODA_c | F1 |
|---|---|---|---|---|
| TRACE | 8.1 | 2.8 | 2.2 | 22.4 |
| TRACE-retrieal | 8.3 | 2.9 | 2.3 | 24.1 |
| TRACE-uni | 8.6 | 2.9 | 2.3 | 22.4 |
| Charades-STA (Zero-Shot) | 0.3 | 0.5 | 0.7 | mIOU |
|---|---|---|---|---|
| TRACE | 58.6 | 40.3 | 19.4 | 38.7 |
| TRACE-retrieval | 57.9 | 37.4 | 17.3 | 37.4 |
| TRACE-uni | 63.7 | 43.7 | 21.0 | 41.5 |
| QVHighlights (Zero-Shot) | mAP | Hit@1 |
|---|---|---|
| TRACE | 26.8 | 42.7 |
| TRACE-retrieval | 27.9 | 44.3 |
| TRACE-uni | 27.5 | 43.9 |
| ActivityNet-DVC | CIDER | METEOR | SODA_c | F1 |
|---|---|---|---|---|
| TRACE | 25.9 | 6.0 | 6.4 | 39.3 |
| TRACE-retrieval | 25.7 | 5.9 | 6.5 | 40.1 |
| TRACE-uni | 29.2 | 6.9 | 6.4 | 40.4 |
| ActivityNet-MR | 0.3 | 0.5 | 0.7 | mIOU |
|---|---|---|---|---|
| TRACE | 54.0 | 37.7 | 24.0 | 39.0 |
| TRACE-retrieval | 54.4 | 39.8 | 24.9 | 40.2 |
| TRACE-uni | 53.2 | 38.2 | 24.7 | 39.4 |
| MVBench | Avg | AS | AP | AA | FA | UA | OE | OI | OS | MD | AL | ST | AC | MC | MA | SC | FP | CO | EN | ER | CI |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| TRACE | 48.1 | 61.2 | 56.5 | 72.5 | 46.5 | 61.0 | 48.0 | 69.5 | 40.0 | 22.0 | 31.0 | 86.5 | 37.5 | 37.0 | 51.0 | 45.0 | 40.5 | 39.0 | 31.0 | 43.5 | 44.5 |
| TRACE-uni | 53.8 | 68.1 | 58.5 | 72.5 | 41.5 | 73.5 | 55.1 | 71.5 | 40.5 | 25.0 | 53.0 | 88.5 | 63.5 | 38.5 | 51.0 | 52.5 | 49.0 | 59.5 | 33.5 | 49.5 | 32.5 |
| VideoMME (w/o subtitle) | Short | Midium | Long | Avg |
|---|---|---|---|---|
| TRACE | 49.5 | 42.5 | 39.3 | 43.8 |
| TRACE-uni | 58.2 | 48.1 | 42.3 | 49.6 |

Demo of TRACE.
We are grateful for the following awesome projects:
Contributors:
- Yongxin Guo
- Jingyu Liu
- Mingda Li
If you find this repository helpful for your project, please consider citing:
@misc{guo2024tracetemporalgroundingvideo,
title={TRACE: Temporal Grounding Video LLM via Causal Event Modeling},
author={Yongxin Guo and Jingyu Liu and Mingda Li and Xiaoying Tang and Qingbin Liu and Xi Chen},
year={2024},
eprint={2410.05643},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2410.05643},
}
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for TRACE
Similar Open Source Tools
TRACE
TRACE is a temporal grounding video model that utilizes causal event modeling to capture videos' inherent structure. It presents a task-interleaved video LLM model tailored for sequential encoding/decoding of timestamps, salient scores, and textual captions. The project includes various model checkpoints for different stages and fine-tuning on specific datasets. It provides evaluation codes for different tasks like VTG, MVBench, and VideoMME. The repository also offers annotation files and links to raw videos preparation projects. Users can train the model on different tasks and evaluate the performance based on metrics like CIDER, METEOR, SODA_c, F1, mAP, Hit@1, etc. TRACE has been enhanced with trace-retrieval and trace-uni models, showing improved performance on dense video captioning and general video understanding tasks.

LLamaTuner
LLamaTuner is a repository for the Efficient Finetuning of Quantized LLMs project, focusing on building and sharing instruction-following Chinese baichuan-7b/LLaMA/Pythia/GLM model tuning methods. The project enables training on a single Nvidia RTX-2080TI and RTX-3090 for multi-round chatbot training. It utilizes bitsandbytes for quantization and is integrated with Huggingface's PEFT and transformers libraries. The repository supports various models, training approaches, and datasets for supervised fine-tuning, LoRA, QLoRA, and more. It also provides tools for data preprocessing and offers models in the Hugging Face model hub for inference and finetuning. The project is licensed under Apache 2.0 and acknowledges contributions from various open-source contributors.

InternVL
InternVL scales up the ViT to _**6B parameters**_ and aligns it with LLM. It is a vision-language foundation model that can perform various tasks, including: **Visual Perception** - Linear-Probe Image Classification - Semantic Segmentation - Zero-Shot Image Classification - Multilingual Zero-Shot Image Classification - Zero-Shot Video Classification **Cross-Modal Retrieval** - English Zero-Shot Image-Text Retrieval - Chinese Zero-Shot Image-Text Retrieval - Multilingual Zero-Shot Image-Text Retrieval on XTD **Multimodal Dialogue** - Zero-Shot Image Captioning - Multimodal Benchmarks with Frozen LLM - Multimodal Benchmarks with Trainable LLM - Tiny LVLM InternVL has been shown to achieve state-of-the-art results on a variety of benchmarks. For example, on the MMMU image classification benchmark, InternVL achieves a top-1 accuracy of 51.6%, which is higher than GPT-4V and Gemini Pro. On the DocVQA question answering benchmark, InternVL achieves a score of 82.2%, which is also higher than GPT-4V and Gemini Pro. InternVL is open-sourced and available on Hugging Face. It can be used for a variety of applications, including image classification, object detection, semantic segmentation, image captioning, and question answering.

CogVLM2
CogVLM2 is a new generation of open source models that offer significant improvements in benchmarks such as TextVQA and DocVQA. It supports 8K content length, image resolution up to 1344 * 1344, and both Chinese and English languages. The project provides basic calling methods, fine-tuning examples, and OpenAI API format calling examples to help developers quickly get started with the model.

oumi
Oumi is an open-source platform for building state-of-the-art foundation models, offering tools for data preparation, training, evaluation, and deployment. It supports training and fine-tuning models with various parameters, working with text and multimodal models, synthesizing and curating training data, deploying models efficiently, evaluating models comprehensively, and running on different platforms. Oumi provides a consistent API, reliability, and flexibility for research purposes.
MMOS
MMOS (Mix of Minimal Optimal Sets) is a dataset designed for math reasoning tasks, offering higher performance and lower construction costs. It includes various models and data subsets for tasks like arithmetic reasoning and math word problem solving. The dataset is used to identify minimal optimal sets through reasoning paths and statistical analysis, with a focus on QA-pairs generated from open-source datasets. MMOS also provides an auto problem generator for testing model robustness and scripts for training and inference.

Awesome-Tabular-LLMs
This repository is a collection of papers on Tabular Large Language Models (LLMs) specialized for processing tabular data. It includes surveys, models, and applications related to table understanding tasks such as Table Question Answering, Table-to-Text, Text-to-SQL, and more. The repository categorizes the papers based on key ideas and provides insights into the advancements in using LLMs for processing diverse tables and fulfilling various tabular tasks based on natural language instructions.
llmq
llm.q is an implementation of (quantized) large language model training in CUDA, inspired by llm.c. It is particularly aimed at medium-sized training setups, i.e., a single node with multiple GPUs. The code is written in C++20 and requires CUDA 12 or later. It depends on nccl for communication, and cudnn for fast attention. Multi-GPU training can either be run in multi-process mode (requires OpenMPI) or in multi-thread mode. Additional header-only dependencies are automatically downloaded by cmake during the build process. The tool provides detailed instructions on data preparation, training runs, inspecting logs, evaluations, and a larger example for real training runs. It also offers detailed usage instructions covering model configuration, data configuration, optimization parameters, checkpointing, output, low-bit settings, activation checkpointing/recomputation, multi-GPU settings, offloading, algorithm selection, and Python bindings. The code organization includes directories for kernels, models, training, and utilities. Speed benchmarks for different GPU configurations are provided, along with testing details for recomputation, fixed reference, and Python reference tests.

MOSS-TTS
MOSS-TTS Family is an open-source speech and sound generation model family designed for high-fidelity, high-expressiveness, and complex real-world scenarios. It includes five production-ready models: MOSS-TTS, MOSS-TTSD, MOSS-VoiceGenerator, MOSS-TTS-Realtime, and MOSS-SoundEffect, each serving specific purposes in speech generation, dialogue, voice design, real-time interactions, and sound effect generation. The models offer features like long-speech generation, fine-grained control over phonemes and duration, multilingual synthesis, voice cloning, and real-time voice agents.

nntrainer
NNtrainer is a software framework for training neural network models on devices with limited resources. It enables on-device fine-tuning of neural networks using user data for personalization. NNtrainer supports various machine learning algorithms and provides examples for tasks such as few-shot learning, ResNet, VGG, and product rating. It is optimized for embedded devices and utilizes CBLAS and CUBLAS for accelerated calculations. NNtrainer is open source and released under the Apache License version 2.0.

DataFlow
DataFlow is a data preparation and training system designed to parse, generate, process, and evaluate high-quality data from noisy sources, improving the performance of large language models in specific domains. It constructs diverse operators and pipelines, validated to enhance domain-oriented LLM's performance in fields like healthcare, finance, and law. DataFlow also features an intelligent DataFlow-agent capable of dynamically assembling new pipelines by recombining existing operators on demand.

VoiceBench
VoiceBench is a repository containing code and data for benchmarking LLM-Based Voice Assistants. It includes a leaderboard with rankings of various voice assistant models based on different evaluation metrics. The repository provides setup instructions, datasets, evaluation procedures, and a curated list of awesome voice assistants. Users can submit new voice assistant results through the issue tracker for updates on the ranking list.

goodai-ltm-benchmark
This repository contains code and data for replicating experiments on Long-Term Memory (LTM) abilities of conversational agents. It includes a benchmark for testing agents' memory performance over long conversations, evaluating tasks requiring dynamic memory upkeep and information integration. The repository supports various models, datasets, and configurations for benchmarking and reporting results.
SpinQuant
SpinQuant is a tool designed for LLM quantization with learned rotations. It focuses on optimizing rotation matrices to enhance the performance of quantized models, narrowing the accuracy gap to full precision models. The tool implements rotation optimization and PTQ evaluation with optimized rotation, providing arguments for model name, batch sizes, quantization bits, and rotation options. SpinQuant is based on the findings that rotation helps in removing outliers and improving quantization, with specific enhancements achieved through learning rotation with Cayley optimization.
go-cyber
Cyber is a superintelligence protocol that aims to create a decentralized and censorship-resistant internet. It uses a novel consensus mechanism called CometBFT and a knowledge graph to store and process information. Cyber is designed to be scalable, secure, and efficient, and it has the potential to revolutionize the way we interact with the internet.

denodo-ai-sdk
Denodo AI SDK is a tool that enables users to create AI chatbots and agents that provide accurate and context-aware answers using enterprise data. It connects to the Denodo Platform, supports popular LLMs and vector stores, and includes a sample chatbot and simple APIs for quick setup. The tool also offers benchmarks for evaluating LLM performance and provides guidance on configuring DeepQuery for different LLM providers.
For similar tasks

Awesome-LLMs-for-Video-Understanding
Awesome-LLMs-for-Video-Understanding is a repository dedicated to exploring Video Understanding with Large Language Models. It provides a comprehensive survey of the field, covering models, pretraining, instruction tuning, and hybrid methods. The repository also includes information on tasks, datasets, and benchmarks related to video understanding. Contributors are encouraged to add new papers, projects, and materials to enhance the repository.
Video-MME
Video-MME is the first-ever comprehensive evaluation benchmark of Multi-modal Large Language Models (MLLMs) in Video Analysis. It assesses the capabilities of MLLMs in processing video data, covering a wide range of visual domains, temporal durations, and data modalities. The dataset comprises 900 videos with 256 hours and 2,700 human-annotated question-answer pairs. It distinguishes itself through features like duration variety, diversity in video types, breadth in data modalities, and quality in annotations.

ControlLLM
ControlLLM is a framework that empowers large language models to leverage multi-modal tools for solving complex real-world tasks. It addresses challenges like ambiguous user prompts, inaccurate tool selection, and inefficient tool scheduling by utilizing a task decomposer, a Thoughts-on-Graph paradigm, and an execution engine with a rich toolbox. The framework excels in tasks involving image, audio, and video processing, showcasing superior accuracy, efficiency, and versatility compared to existing methods.

gen-cv
This repository is a rich resource offering examples of synthetic image generation, manipulation, and reasoning using Azure Machine Learning, Computer Vision, OpenAI, and open-source frameworks like Stable Diffusion. It provides practical insights into image processing applications, including content generation, video analysis, avatar creation, and image manipulation with various tools and APIs.

outspeed
Outspeed is a PyTorch-inspired SDK for building real-time AI applications on voice and video input. It offers low-latency processing of streaming audio and video, an intuitive API familiar to PyTorch users, flexible integration of custom AI models, and tools for data preprocessing and model deployment. Ideal for developing voice assistants, video analytics, and other real-time AI applications processing audio-visual data.
starter-applets
This repository contains the source code for Google AI Studio's starter apps — a collection of small apps that demonstrate how Gemini can be used to create interactive experiences. These apps are built to run inside AI Studio, but the versions included here can run standalone using the Gemini API. The apps cover spatial understanding, video analysis, and map exploration, showcasing Gemini's capabilities in these areas. Developers can use these starter applets to kickstart their projects and learn how to leverage Gemini for spatial reasoning and interactive experiences.
TRACE
TRACE is a temporal grounding video model that utilizes causal event modeling to capture videos' inherent structure. It presents a task-interleaved video LLM model tailored for sequential encoding/decoding of timestamps, salient scores, and textual captions. The project includes various model checkpoints for different stages and fine-tuning on specific datasets. It provides evaluation codes for different tasks like VTG, MVBench, and VideoMME. The repository also offers annotation files and links to raw videos preparation projects. Users can train the model on different tasks and evaluate the performance based on metrics like CIDER, METEOR, SODA_c, F1, mAP, Hit@1, etc. TRACE has been enhanced with trace-retrieval and trace-uni models, showing improved performance on dense video captioning and general video understanding tasks.
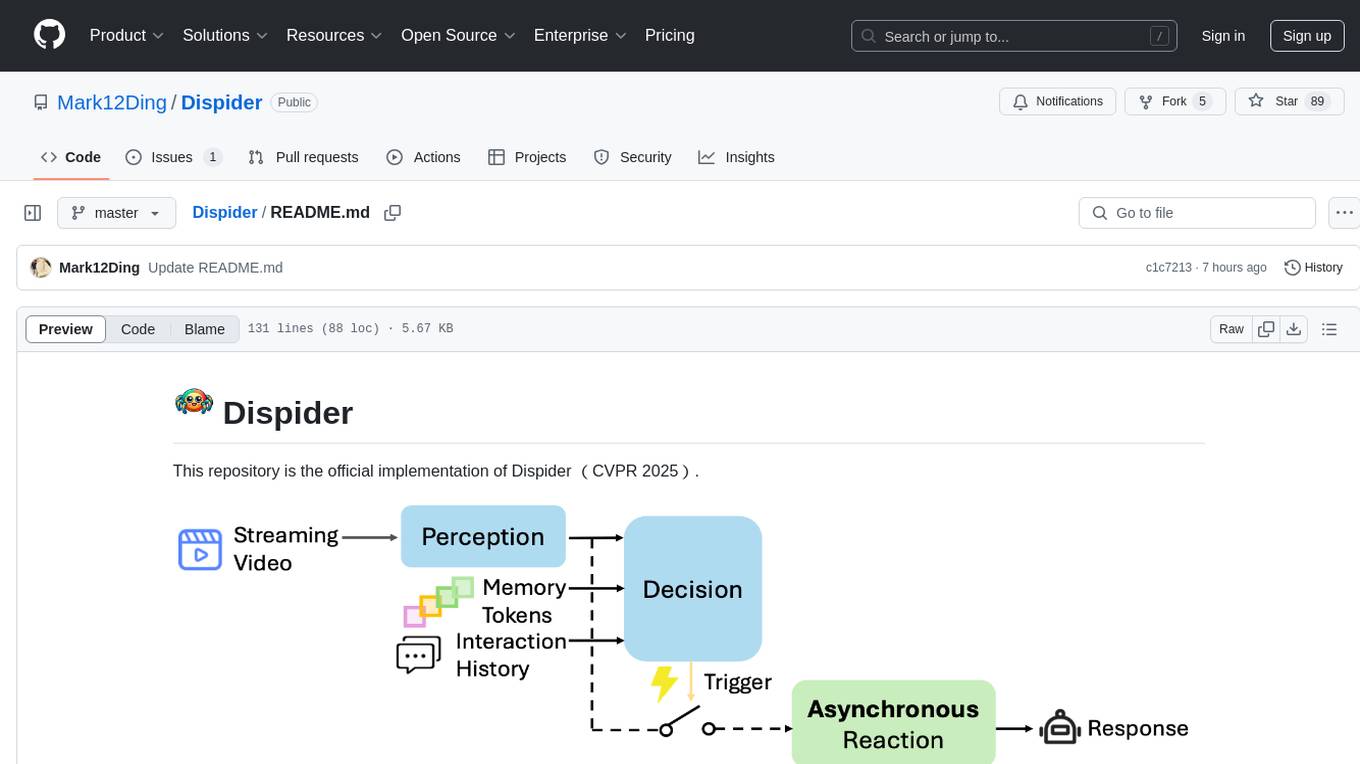
Dispider
Dispider is an implementation enabling real-time interactions with streaming videos, providing continuous feedback in live scenarios. It separates perception, decision-making, and reaction into asynchronous modules, ensuring timely interactions. Dispider outperforms VideoLLM-online on benchmarks like StreamingBench and excels in temporal reasoning. The tool requires CUDA 11.8 and specific library versions for optimal performance.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.