
nntrainer
NNtrainer is Software Framework for Training Neural Network Models on Devices.
Stars: 135

NNtrainer is a software framework for training neural network models on devices with limited resources. It enables on-device fine-tuning of neural networks using user data for personalization. NNtrainer supports various machine learning algorithms and provides examples for tasks such as few-shot learning, ResNet, VGG, and product rating. It is optimized for embedded devices and utilizes CBLAS and CUBLAS for accelerated calculations. NNtrainer is open source and released under the Apache License version 2.0.
README:



NNtrainer is a Software Framework for training Neural Network models on devices.
NNtrainer is an Open Source Project. The aim of the NNtrainer is to develop a Software Framework to train neural network models on embedded devices which have relatively limited resources. Rather than training whole layers of a network from the scratch, NNtrainer finetunes the neural network model on device with user data for the personalization.
Even if NNtrainer runs on device, it provides full functionalities to train models and also utilizes limited device resources efficiently. NNTrainer is able to train various machine learning algorithms such as k-Nearest Neighbor (k-NN), Neural Networks, Logistic Regression, Reinforcement Learning algorithms, Recurrent network and more. We also provide examples for various tasks such as Few-shot learning, ResNet, VGG, Product Rating and more will be added. All of these were tested on Samsung Galaxy smart phone with Android and PC (Ubuntu 18.04/20.04).
A New Frontier of AI: On-Device AI Training and Personalization , ICSE-SEIP, 2024
NNTrainer: Light-Weight On-Device Training Framework , arXiv, 2022
Open Source On-Device AI SW Platform , Samsung Developer Conference 2023 (Korean)
NNTrainer: Personalize neural networks on devices! , Samsung Developer Conference 2021
NNTrainer: "On-device learning" , Samsung AI Forum 2021
| Tizen | Ubuntu | Android/NDK Build | |
|---|---|---|---|
| 6.0M2 and later | 18.04 | 9/P | |
| arm | Available | Ready | |
| arm64 | Available | ||
| x64 | Ready | ||
| x86 | N/A | N/A | |
| Publish | Tizen Repo | PPA | |
| API | C (Official) | C/C++ | C/C++ |
- Ready: CI system ensures build-ability and unit-testing. Users may easily build and execute. However, we do not have automated release & deployment system for this instance.
- Available: binary packages are released and deployed automatically and periodically along with CI tests.
- Daily Release
- SDK Support: Tizen Studio (6.0 M2+)
Instructions for installing NNTrainer.
Introductions for creating your own model.
Instructions for preparing NNTrainer for execution
NNTrainer examples for a variety of networks
This component defines layers which consist of a neural network model. Layers have their own properties to be set.
| Keyword | Layer Class Name | Description |
|---|---|---|
| conv1d | Conv1DLayer | Convolution 1-Dimentional Layer |
| conv2d | Conv2DLayer | Convolution 2-Dimentional Layer |
| pooling2d | Pooling2DLayer | Pooling 2-Dimentional Layer. Support average / max / global average / global max pooling |
| flatten | FlattenLayer | Flatten layer |
| fully_connected | FullyConnectedLayer | Fully connected layer |
| input | InputLayer | Input Layer. This is not always required. |
| batch_normalization | BatchNormalizationLayer | Batch normalization layer |
| layer_normalization | LayerNormalizationLayer | Layer normalization layer |
| activation | ActivationLayer | Set by layer property |
| addition | AdditionLayer | Add input input layers |
| attention | AttentionLayer | Attenstion layer |
| centroid_knn | CentroidKNN | Centroid K-nearest neighbor layer |
| concat | ConcatLayer | Concatenate input layers |
| multiout | MultiOutLayer | Multi-Output Layer |
| backbone_nnstreamer | NNStreamerLayer | Encapsulate NNStreamer layer |
| backbone_tflite | TfLiteLayer | Encapsulate tflite as a layer |
| permute | PermuteLayer | Permute layer for transpose |
| preprocess_flip | PreprocessFlipLayer | Preprocess random flip layer |
| preprocess_l2norm | PreprocessL2NormLayer | Preprocess simple l2norm layer to normalize |
| preprocess_translate | PreprocessTranslateLayer | Preprocess translate layer |
| reshape | ReshapeLayer | Reshape tensor dimension layer |
| split | SplitLayer | Split layer |
| dropout | DropOutLayer | Dropout Layer |
| embedding | EmbeddingLayer | Embedding Layer |
| positional_encoding | PositionalEncodingLayer | Positional Encoding Layer |
| rnn | RNNLayer | Recurrent Layer |
| rnncell | RNNCellLayer | Recurrent Cell Layer |
| gru | GRULayer | Gated Recurrent Unit Layer |
| grucell | GRUCellLayer | Gated Recurrent Unit Cell Layer |
| lstm | LSTMLayer | Long Short-Term Memory Layer |
| lstmcell | LSTMCellLayer | Long Short-Term Memory Cell Layer |
| zoneoutlstmcell | ZoneoutLSTMCellLayer | Zoneout Long Short-Term Memory Cell Layer |
| time_dist | TimeDistLayer | Time distributed Layer |
| multi_head_attention | MultiHeadAttentionLayer | Multi Head Attention Layer |
NNTrainer Provides
| Keyword | Optimizer Name | Description |
|---|---|---|
| sgd | Stochastic Gradient Decent | - |
| adam | Adaptive Moment Estimation | - |
| Keyword | Learning Rate | Description |
|---|---|---|
| exponential | exponential learning rate decay | - |
| constant | constant learning rate | - |
| step | step learning rate | - |
NNTrainer provides
| Keyword | Class Name | Description |
|---|---|---|
| cross_sigmoid | CrossEntropySigmoidLossLayer | Cross entropy sigmoid loss layer |
| cross_softmax | CrossEntropySoftmaxLossLayer | Cross entropy softmax loss layer |
| constant_derivative | ConstantDerivativeLossLayer | Constant derivative loss layer |
| mse | MSELossLayer | Mean square error loss layer |
| kld | KLDLossLayer | Kullback-Leibler Divergence loss layer |
NNTrainer provides
| Keyword | Loss Name | Description |
|---|---|---|
| tanh | tanh function | set as layer property |
| sigmoid | sigmoid function | set as layer property |
| softmax | softmax function | set as layer property |
| relu | relu function | set as layer property |
| leaky_relu | leaky_relu function | set as layer property |
| swish | swish function | set as layer property |
| gelu | gelu function | set as layer property |
| quick_gelu | quick gelu function | set as layer property |
| elu | elu function | set as layer property |
| selu | selu function | set as layer property |
| softplus | softplus function | set as layer property |
| mish | mish function | set as layer property |
Tensor is responsible for calculation of a layer. It executes several operations such as addition, division, multiplication, dot production, data averaging and so on. In order to accelerate calculation speed, CBLAS (C-Basic Linear Algebra: CPU) and CUBLAS (CUDA: Basic Linear Algebra) for PC (Especially NVIDIA GPU) are implemented for some of the operations. Later, these calculations will be optimized. Currently, we support lazy calculation mode to reduce complexity for copying tensors during calculations.
| Keyword | Description |
|---|---|
| 4D Tensor | B, C, H, W |
| Add/sub/mul/div | - |
| sum, average, argmax | - |
| Dot, Transpose | - |
| normalization, standardization | - |
| save, read | - |
NNTrainer provides
| Keyword | Loss Name | Description |
|---|---|---|
| weight_initializer | Weight Initialization | Xavier(Normal/Uniform), LeCun(Normal/Uniform), HE(Normal/Uniform) |
| weight_regularizer | weight decay ( L2Norm only ) | needs set weight_regularizer_param & type |
Currently, we provide C APIs for Tizen. C++ APIs are also provided for other platform. Java & C# APIs will be provided soon.
- Sangjung Woo
- Wook Song
- Jaeyun Jung
- Hyoungjoo Ahn
- Parichay Kapoor
- Dongju Chae
- Gichan Jang
- Yongjoo Ahn
- Jihoon Lee
- Hyeonseok Lee
- Mete Ozay
- Hyunil Park
- Jiho Chu
- Yelin Jeong
- Donghak Park
- Hyungjun Seo
- Seungbaek Hong
- Sungsik Kong
- Donghyeon Jeong
- Eunju Yang
The NNtrainer is an open source project released under the terms of the Apache License version 2.0.
Contributions are welcome! Please see our Contributing Guide for more details.








If you find this NNTrainer project useful or relevant to your research, please consider citing our paper:
@inproceedings{10.1145/3639477.3639716,
author = {Moon, Jijoong and Lee, Hyeonseok and Chu, Jiho and Park, Donghak and Hong, Seungbaek and Seo, Hyungjun and Jeong, Donghyeon and Kong, Sungsik and Ham, Myungjoo},
title = {A New Frontier of AI: On-Device AI Training and Personalization},
year = {2024},
isbn = {9798400705014},
publisher = {Association for Computing Machinery},
url = {https://doi.org/10.1145/3639477.3639716},
doi = {10.1145/3639477.3639716},
booktitle = {Proceedings of the 46th International Conference on Software Engineering: Software Engineering in Practice},
pages = {323–333},
numpages = {11},
keywords = {on-device AI, neural network, personalization, training, software framework},
series = {ICSE-SEIP '24}
}
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for nntrainer
Similar Open Source Tools
nntrainer
NNtrainer is a software framework for training neural network models on devices with limited resources. It enables on-device fine-tuning of neural networks using user data for personalization. NNtrainer supports various machine learning algorithms and provides examples for tasks such as few-shot learning, ResNet, VGG, and product rating. It is optimized for embedded devices and utilizes CBLAS and CUBLAS for accelerated calculations. NNtrainer is open source and released under the Apache License version 2.0.
visionOS-examples
visionOS-examples is a repository containing accelerators for Spatial Computing. It includes examples such as Local Large Language Model, Chat Apple Vision Pro, WebSockets, Anchor To Head, Hand Tracking, Battery Life, Countdown, Plane Detection, Timer Vision, and PencilKit for visionOS. The repository showcases various functionalities and features for Apple Vision Pro, offering tools for developers to enhance their visionOS apps with capabilities like hand tracking, plane detection, and real-time cryptocurrency prices.

are-copilots-local-yet
Current trends and state of the art for using open & local LLM models as copilots to complete code, generate projects, act as shell assistants, automatically fix bugs, and more. This document is a curated list of local Copilots, shell assistants, and related projects, intended to be a resource for those interested in a survey of the existing tools and to help developers discover the state of the art for projects like these.
linghe
A library of high-performance kernels for LLM training, linghe is designed for MoE training with FP8 quantization. It provides fused quantization kernels, memory-efficiency kernels, and implementation-optimized kernels. The repo benchmarks on H800 with specific configurations and offers examples in tests. Users can refer to the API for more details.
Awesome-LLM-Tabular
This repository is a curated list of research papers that explore the integration of Large Language Model (LLM) technology with tabular data. It aims to provide a comprehensive resource for researchers and practitioners interested in this emerging field. The repository includes papers on a wide range of topics, including table-to-text generation, table question answering, and tabular data classification. It also includes a section on related datasets and resources.
llama-stack
Llama Stack defines and standardizes core building blocks for AI application development, providing a unified API layer, plugin architecture, prepackaged distributions, developer interfaces, and standalone applications. It offers flexibility in infrastructure choice, consistent experience with unified APIs, and a robust ecosystem with integrated distribution partners. The tool simplifies building, testing, and deploying AI applications with various APIs and environments, supporting local development, on-premises, cloud, and mobile deployments.

unstract
Unstract is a no-code platform that enables users to launch APIs and ETL pipelines to structure unstructured documents. With Unstract, users can go beyond co-pilots by enabling machine-to-machine automation. Unstract's Prompt Studio provides a simple, no-code approach to creating prompts for LLMs, vector databases, embedding models, and text extractors. Users can then configure Prompt Studio projects as API deployments or ETL pipelines to automate critical business processes that involve complex documents. Unstract supports a wide range of LLM providers, vector databases, embeddings, text extractors, ETL sources, and ETL destinations, providing users with the flexibility to choose the best tools for their needs.

Awesome-LLM-Constrained-Decoding
Awesome-LLM-Constrained-Decoding is a curated list of papers, code, and resources related to constrained decoding of Large Language Models (LLMs). The repository aims to facilitate reliable, controllable, and efficient generation with LLMs by providing a comprehensive collection of materials in this domain.

awesome-mobile-llm
Awesome Mobile LLMs is a curated list of Large Language Models (LLMs) and related studies focused on mobile and embedded hardware. The repository includes information on various LLM models, deployment frameworks, benchmarking efforts, applications, multimodal LLMs, surveys on efficient LLMs, training LLMs on device, mobile-related use-cases, industry announcements, and related repositories. It aims to be a valuable resource for researchers, engineers, and practitioners interested in mobile LLMs.

goodai-ltm-benchmark
This repository contains code and data for replicating experiments on Long-Term Memory (LTM) abilities of conversational agents. It includes a benchmark for testing agents' memory performance over long conversations, evaluating tasks requiring dynamic memory upkeep and information integration. The repository supports various models, datasets, and configurations for benchmarking and reporting results.

YuLan-Mini
YuLan-Mini is a lightweight language model with 2.4 billion parameters that achieves performance comparable to industry-leading models despite being pre-trained on only 1.08T tokens. It excels in mathematics and code domains. The repository provides pre-training resources, including data pipeline, optimization methods, and annealing approaches. Users can pre-train their own language models, perform learning rate annealing, fine-tune the model, research training dynamics, and synthesize data. The team behind YuLan-Mini is AI Box at Renmin University of China. The code is released under the MIT License with future updates on model weights usage policies. Users are advised on potential safety concerns and ethical use of the model.
BizFinBench
BizFinBench is a benchmark tool designed for evaluating large language models (LLMs) in logic-heavy and precision-critical domains such as finance. It comprises over 100,000 bilingual financial questions rooted in real-world business scenarios. The tool covers five dimensions: numerical calculation, reasoning, information extraction, prediction recognition, and knowledge-based question answering, mapped to nine fine-grained categories. BizFinBench aims to assess the capacity of LLMs in real-world financial scenarios and provides insights into their strengths and limitations.
awesome-llm-webapps
This repository is a curated list of open-source, actively maintained web applications that leverage large language models (LLMs) for various use cases, including chatbots, natural language interfaces, assistants, and question answering systems. The projects are evaluated based on key criteria such as licensing, maintenance status, complexity, and features, to help users select the most suitable starting point for their LLM-based applications. The repository welcomes contributions and encourages users to submit projects that meet the criteria or suggest improvements to the existing list.
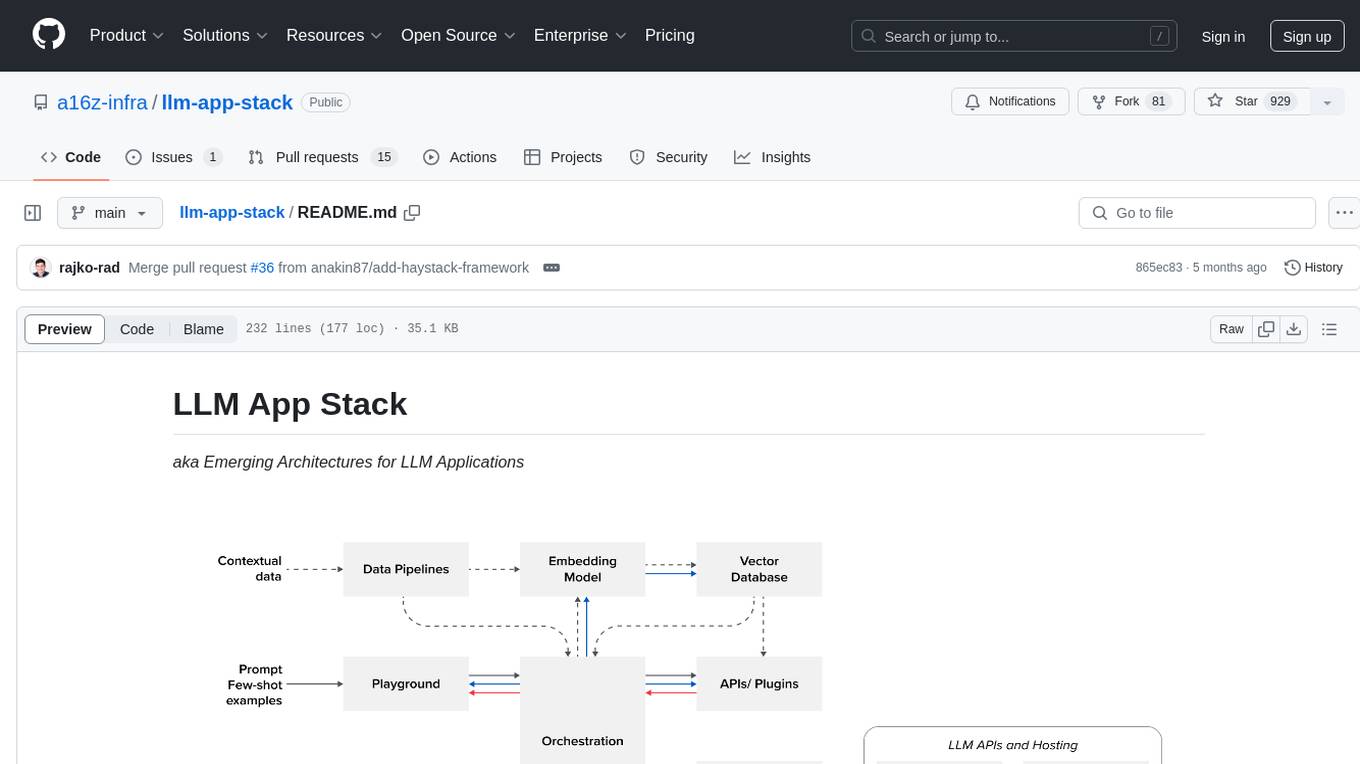
llm-app-stack
LLM App Stack, also known as Emerging Architectures for LLM Applications, is a comprehensive list of available tools, projects, and vendors at each layer of the LLM app stack. It covers various categories such as Data Pipelines, Embedding Models, Vector Databases, Playgrounds, Orchestrators, APIs/Plugins, LLM Caches, Logging/Monitoring/Eval, Validators, LLM APIs (proprietary and open source), App Hosting Platforms, Cloud Providers, and Opinionated Clouds. The repository aims to provide a detailed overview of tools and projects for building, deploying, and maintaining enterprise data solutions, AI models, and applications.

oumi
Oumi is an open-source platform for building state-of-the-art foundation models, offering tools for data preparation, training, evaluation, and deployment. It supports training and fine-tuning models with various parameters, working with text and multimodal models, synthesizing and curating training data, deploying models efficiently, evaluating models comprehensively, and running on different platforms. Oumi provides a consistent API, reliability, and flexibility for research purposes.

PredictorLLM
PredictorLLM is an advanced trading agent framework that utilizes large language models to automate trading in financial markets. It includes a profiling module to establish agent characteristics, a layered memory module for retaining and prioritizing financial data, and a decision-making module to convert insights into trading strategies. The framework mimics professional traders' behavior, surpassing human limitations in data processing and continuously evolving to adapt to market conditions for superior investment outcomes.
For similar tasks

mindsdb
MindsDB is a platform for customizing AI from enterprise data. You can create, serve, and fine-tune models in real-time from your database, vector store, and application data. MindsDB "enhances" SQL syntax with AI capabilities to make it accessible for developers worldwide. With MindsDB’s nearly 200 integrations, any developer can create AI customized for their purpose, faster and more securely. Their AI systems will constantly improve themselves — using companies’ own data, in real-time.

training-operator
Kubeflow Training Operator is a Kubernetes-native project for fine-tuning and scalable distributed training of machine learning (ML) models created with various ML frameworks such as PyTorch, Tensorflow, XGBoost, MPI, Paddle and others. Training Operator allows you to use Kubernetes workloads to effectively train your large models via Kubernetes Custom Resources APIs or using Training Operator Python SDK. > Note: Before v1.2 release, Kubeflow Training Operator only supports TFJob on Kubernetes. * For a complete reference of the custom resource definitions, please refer to the API Definition. * TensorFlow API Definition * PyTorch API Definition * Apache MXNet API Definition * XGBoost API Definition * MPI API Definition * PaddlePaddle API Definition * For details of all-in-one operator design, please refer to the All-in-one Kubeflow Training Operator * For details on its observability, please refer to the monitoring design doc.

helix
HelixML is a private GenAI platform that allows users to deploy the best of open AI in their own data center or VPC while retaining complete data security and control. It includes support for fine-tuning models with drag-and-drop functionality. HelixML brings the best of open source AI to businesses in an ergonomic and scalable way, optimizing the tradeoff between GPU memory and latency.
nntrainer
NNtrainer is a software framework for training neural network models on devices with limited resources. It enables on-device fine-tuning of neural networks using user data for personalization. NNtrainer supports various machine learning algorithms and provides examples for tasks such as few-shot learning, ResNet, VGG, and product rating. It is optimized for embedded devices and utilizes CBLAS and CUBLAS for accelerated calculations. NNtrainer is open source and released under the Apache License version 2.0.

petals
Petals is a tool that allows users to run large language models at home in a BitTorrent-style manner. It enables fine-tuning and inference up to 10x faster than offloading. Users can generate text with distributed models like Llama 2, Falcon, and BLOOM, and fine-tune them for specific tasks directly from their desktop computer or Google Colab. Petals is a community-run system that relies on people sharing their GPUs to increase its capacity and offer a distributed network for hosting model layers.

LLaVA-pp
This repository, LLaVA++, extends the visual capabilities of the LLaVA 1.5 model by incorporating the latest LLMs, Phi-3 Mini Instruct 3.8B, and LLaMA-3 Instruct 8B. It provides various models for instruction-following LMMS and academic-task-oriented datasets, along with training scripts for Phi-3-V and LLaMA-3-V. The repository also includes installation instructions and acknowledgments to related open-source contributions.

KULLM
KULLM (구름) is a Korean Large Language Model developed by Korea University NLP & AI Lab and HIAI Research Institute. It is based on the upstage/SOLAR-10.7B-v1.0 model and has been fine-tuned for instruction. The model has been trained on 8×A100 GPUs and is capable of generating responses in Korean language. KULLM exhibits hallucination and repetition phenomena due to its decoding strategy. Users should be cautious as the model may produce inaccurate or harmful results. Performance may vary in benchmarks without a fixed system prompt.

Firefly
Firefly is an open-source large model training project that supports pre-training, fine-tuning, and DPO of mainstream large models. It includes models like Llama3, Gemma, Qwen1.5, MiniCPM, Llama, InternLM, Baichuan, ChatGLM, Yi, Deepseek, Qwen, Orion, Ziya, Xverse, Mistral, Mixtral-8x7B, Zephyr, Vicuna, Bloom, etc. The project supports full-parameter training, LoRA, QLoRA efficient training, and various tasks such as pre-training, SFT, and DPO. Suitable for users with limited training resources, QLoRA is recommended for fine-tuning instructions. The project has achieved good results on the Open LLM Leaderboard with QLoRA training process validation. The latest version has significant updates and adaptations for different chat model templates.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.