
Awesome-LLMs-for-Video-Understanding
🔥🔥🔥Latest Papers, Codes and Datasets on Vid-LLMs.
Stars: 1813

Awesome-LLMs-for-Video-Understanding is a repository dedicated to exploring Video Understanding with Large Language Models. It provides a comprehensive survey of the field, covering models, pretraining, instruction tuning, and hybrid methods. The repository also includes information on tasks, datasets, and benchmarks related to video understanding. Contributors are encouraged to add new papers, projects, and materials to enhance the repository.
README:
Yunlong Tang1,*, Jing Bi1,*, Siting Xu2,*, Luchuan Song1, Susan Liang1 , Teng Wang2,3 , Daoan Zhang1 , Jie An1 , Jingyang Lin1 , Rongyi Zhu1 , Ali Vosoughi1 , Chao Huang1 , Zeliang Zhang1 , Pinxin Liu1 , Mingqian Feng1 , Feng Zheng2 , Jianguo Zhang2 , Ping Luo3 , Jiebo Luo1, Chenliang Xu1,†. (*Core Contributors, †Corresponding Authors)
1University of Rochester, 2Southern University of Science and Technology, 3The University of Hong Kong

[07/23/2024]
📢 We've recently updated our survey: “Video Understanding with Large Language Models: A Survey”!
✨ This comprehensive survey covers video understanding techniques powered by large language models (Vid-LLMs), training strategies, relevant tasks, datasets, benchmarks, and evaluation methods, and discusses the applications of Vid-LLMs across various domains.
🚀 What's New in This Update:
✅ Updated to include around 100 additional Vid-LLMs and 15 new benchmarks as of June 2024.
✅ Introduced a novel taxonomy for Vid-LLMs based on video representation and LLM functionality.
✅ Added a Preliminary chapter, reclassifying video understanding tasks from the perspectives of granularity and language involvement, and enhanced the LLM Background section.
✅ Added a new Training Strategies chapter, removing adapters as a factor for model classification.
✅ All figures and tables have been redesigned.
Multiple minor updates will follow this major update. And the GitHub repository will be gradually updated soon. We welcome your reading and feedback ❤️
Table of Contents- Awesome-LLMs-for-Video-Understanding


If you find our survey useful for your research, please cite the following paper:
@article{vidllmsurvey,
title={Video Understanding with Large Language Models: A Survey},
author={Tang, Yunlong and Bi, Jing and Xu, Siting and Song, Luchuan and Liang, Susan and Wang, Teng and Zhang, Daoan and An, Jie and Lin, Jingyang and Zhu, Rongyi and Vosoughi, Ali and Huang, Chao and Zhang, Zeliang and Zheng, Feng and Zhang, Jianguo and Luo, Ping and Luo, Jiebo and Xu, Chenliang},
journal={arXiv preprint arXiv:2312.17432},
year={2023},
}

LLM as Hidden Layer
| Title | Model | Date | Code | Venue |
|---|---|---|---|---|
| VTG-LLM integrating timestamp knowledge into video LLMs for enhanced video temporal grounding | VTG-LLM | 05/2024 | code | arXiv |
| VITRON: A Unified Pixel-level Vision LLM for Understanding, Generating, Segmenting, Editing | VITRON | 04/2024 | project page | NeurIPS |
| VTG-GPT: Tuning-Free Zero-Shot Video Temporal Grounding with GPT | VTG-GPT | 03/2024 | code | arXiv |
| Momentor advancing video large language model with fine-grained temporal reasoning | Momentor | 02/2024 | code | ICML |
| Detours for navigating instructional videos | VidDetours | 01/2024 | code | CVPR |
| OneLLM: One Framework to Align All Modalities with Language | OneLLM | 12/2023 | code | arXiv |
| GPT4Video a unified multimodal large language model for lnstruction-followed understanding and safety-aware generation | GPT4Video | 11/2023 | code | ACMMM |
| Title | Model | Date | Code | Venue |
|---|---|---|---|---|
| MM-VID: Advancing Video Understanding with GPT-4V(ision) | MM-VID | 10/2023 | - | arXiv |
| Title | Model | Date | Code | Venue |
|---|---|---|---|---|
| Shot2Story20K a new benchmark for comprehensive understanding of multi-shot videos | SUM-shot | 12/2023 | code | arXiv |
| Title | Model | Date | Code | Venue |
|---|---|---|---|---|
| Vript: A Video Is Worth Thousands of Words | Vriptor | 06/2024 | code | NeurIPS |
| Merlin:Empowering Multimodal LLMs with Foresight Minds | Merlin | 12/2023 | project page | ECCV |
| VideoChat: Chat-Centric Video Understanding | VideoChat | 05/2023 | code | arXiv |
| Vid2Seq: Large-Scale Pretraining of a Visual Language Model for Dense Video Captioning | Vid2Seq | 02/2023 | code | CVPR |
| Title | Model | Date | Code | Venue |
|---|---|---|---|---|
| Contextual AD Narration with Interleaved Multimodal Sequence | Uni-AD | 03/2024 | code | arXiv |
| MM-Narrator: Narrating Long-form Videos with Multimodal In-Context Learning | MM-narrator | 11/2023 | project page | arXiv |
| Vamos: Versatile Action Models for Video Understanding | Vamos | 11/2023 | project page | ECCV |
| AutoAD II: The Sequel -- Who, When, and What in Movie Audio Description | Auto-AD II | 10/2023 | project page | ICCV |
LLM as Hidden Layer
| Title | Model | Date | Code | Venue |
|---|---|---|---|---|
PG-Video-LLaVA: Pixel Grounding Large Video-Language Models
|
PG-Video-LLaVA | 11/2023 | code | arXiv |

| Title | Model | Date | Code | Venue |
|---|---|---|---|---|
Learning Video Representations from Large Language Models
|
LaViLa | 12/2022 | code | CVPR |
| Vid2Seq: Large-Scale Pretraining of a Visual Language Model for Dense Video Captioning | Vid2Seq | 02/2023 | code | CVPR |
VAST: A Vision-Audio-Subtitle-Text Omni-Modality Foundation Model and Dataset
|
VAST | 05/2023 | code | NeurIPS |
| Merlin:Empowering Multimodal LLMs with Foresight Minds | Merlin | 12/2023 | - | arXiv |













| Title | Model | Date | Code | Venue |
|---|---|---|---|---|
Otter: A Multi-Modal Model with In-Context Instruction Tuning
|
Otter | 06/2023 | code | arXiv |
VideoLLM: Modeling Video Sequence with Large Language Models
|
VideoLLM | 05/2023 | code | arXiv |
| Title | Model | Date | Code | Venue |
|---|---|---|---|---|
VTimeLLM: Empower LLM to Grasp Video Moments
|
VTimeLLM | 11/2023 | code | arXiv |
| GPT4Video: A Unified Multimodal Large Language Model for lnstruction-Followed Understanding and Safety-Aware Generation | GPT4Video | 11/2023 | - | arXiv |
| Title | Model | Date | Code | Venue |
|---|---|---|---|---|
VideoChat: Chat-Centric Video Understanding
|
VideoChat | 05/2023 | code demo | arXiv |
|
PG-Video-LLaVA: Pixel Grounding Large Video-Language Models
|
PG-Video-LLaVA | 11/2023 | code | arXiv |
TimeChat: A Time-sensitive Multimodal Large Language Model for Long Video Understanding
|
TimeChat | 12/2023 | code | CVPR |
Video-GroundingDINO: Towards Open-Vocabulary Spatio-Temporal Video Grounding
|
Video-GroundingDINO | 12/2023 | code | arXiv |
| A Video Is Worth 4096 Tokens: Verbalize Videos To Understand Them In Zero Shot | Video4096 | 05/2023 | EMNLP |
| Title | Model | Date | Code | Venue |
|---|---|---|---|---|
| SlowFast-LLaVA: A Strong Training-Free Baseline for Video Large Language Models | SlowFast-LLaVA | 07/2024 | - | arXiv |
| TS-LLaVA: Constructing Visual Tokens through Thumbnail-and-Sampling for Training-Free Video Large Language Models | TS-LLaVA | 11/2024 | code | arXiv |
| Name | Paper | Date | Link | Venue |
|---|---|---|---|---|
| Charades | Hollywood in homes: Crowdsourcing data collection for activity understanding | 2016 | Link | ECCV |
| YouTube8M | YouTube-8M: A Large-Scale Video Classification Benchmark | 2016 | Link | - |
| ActivityNet | ActivityNet: A Large-Scale Video Benchmark for Human Activity Understanding | 2015 | Link | CVPR |
| Kinetics-GEBC | GEB+: A Benchmark for Generic Event Boundary Captioning, Grounding and Retrieval | 2022 | Link | ECCV |
| Kinetics-400 | The Kinetics Human Action Video Dataset | 2017 | Link | - |
| VidChapters-7M | VidChapters-7M: Video Chapters at Scale | 2023 | Link | NeurIPS |
| Name | Paper | Date | Link | Venue |
|---|---|---|---|---|
| Epic-Kitchens-100 | Rescaling Egocentric Vision | 2021 | Link | IJCV |
| VCR (Visual Commonsense Reasoning) | From Recognition to Cognition: Visual Commonsense Reasoning | 2019 | Link | CVPR |
| Ego4D-MQ and Ego4D-NLQ | Ego4D: Around the World in 3,000 Hours of Egocentric Video | 2021 | Link | CVPR |
| Vid-STG | Where Does It Exist: Spatio-Temporal Video Grounding for Multi-Form Sentences | 2020 | Link | CVPR |
| Charades-STA | TALL: Temporal Activity Localization via Language Query | 2017 | Link | ICCV |
| DiDeMo | Localizing Moments in Video with Natural Language | 2017 | Link | ICCV |
| Name | Paper | Date | Link | Venue |
|---|---|---|---|---|
| MSVD-QA | Video Question Answering via Gradually Refined Attention over Appearance and Motion | 2017 | Link | ACM Multimedia |
| MSRVTT-QA | Video Question Answering via Gradually Refined Attention over Appearance and Motion | 2017 | Link | ACM Multimedia |
| TGIF-QA | TGIF-QA: Toward Spatio-Temporal Reasoning in Visual Question Answering | 2017 | Link | CVPR |
| ActivityNet-QA | ActivityNet-QA: A Dataset for Understanding Complex Web Videos via Question Answering | 2019 | Link | AAAI |
| Pororo-QA | DeepStory: Video Story QA by Deep Embedded Memory Networks | 2017 | Link | IJCAI |
| TVQA | TVQA: Localized, Compositional Video Question Answering | 2018 | Link | EMNLP |
| MAD-QA | Encoding and Controlling Global Semantics for Long-form Video Question Answering | 2024 | Link | EMNLP |
| Ego-QA | Encoding and Controlling Global Semantics for Long-form Video Question Answering | 2024 | Link | EMNLP |
| Name | Paper | Date | Link | Venue |
|---|---|---|---|---|
| VidChapters-7M | VidChapters-7M: Video Chapters at Scale | 2023 | Link | NeurIPS |
| VALOR-1M | VALOR: Vision-Audio-Language Omni-Perception Pretraining Model and Dataset | 2023 | Link | arXiv |
| Youku-mPLUG | Youku-mPLUG: A 10 Million Large-scale Chinese Video-Language Dataset for Pre-training and Benchmarks | 2023 | Link | arXiv |
| InternVid | InternVid: A Large-scale Video-Text Dataset for Multimodal Understanding and Generation | 2023 | Link | arXiv |
| VAST-27M | VAST: A Vision-Audio-Subtitle-Text Omni-Modality Foundation Model and Dataset | 2023 | Link | NeurIPS |
| Name | Paper | Date | Link | Venue |
|---|---|---|---|---|
| MIMIC-IT | MIMIC-IT: Multi-Modal In-Context Instruction Tuning | 2023 | Link | arXiv |
| VideoInstruct100K | Video-ChatGPT: Towards Detailed Video Understanding via Large Vision and Language Models | 2023 | Link | arXiv |
| TimeIT | TimeChat: A Time-sensitive Multimodal Large Language Model for Long Video Understanding | 2023 | Link | CVPR |




We welcome everyone to contribute to this repository and help improve it. You can submit pull requests to add new papers, projects, and helpful materials, or to correct any errors that you may find. Please make sure that your pull requests follow the "Title|Model|Date|Code|Venue" format. Thank you for your valuable contributions!
Our project wouldn't be possible without the contributions of these amazing people! Thank you all for making this project better.
Yunlong Tang @ University of Rochester
Jing Bi @ University of Rochester
Siting Xu @ Southern University of Science and Technology
Luchuan Song @ University of Rochester
Susan Liang @ University of Rochester
Teng Wang @ The University of Hong Kong
Daoan Zhang @ University of Rochester
Jie An @ University of Rochester
Jingyang Lin @ University of Rochester
Rongyi Zhu @ University of Rochester
Ali Vosoughi @ University of Rochester
Chao Huang @ University of Rochester
Zeliang Zhang @ University of Rochester
Pinxin Liu @ University of Rochester
Mingqian Feng @ University of Rochester
Feng Zheng @ Southern University of Science and Technology
Jianguo Zhang @ Southern University of Science and Technology
Ping Luo @ University of Hong Kong
Jiebo Luo @ University of Rochester
Chenliang Xu @ University of Rochester
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for Awesome-LLMs-for-Video-Understanding
Similar Open Source Tools
Awesome-LLMs-for-Video-Understanding
Awesome-LLMs-for-Video-Understanding is a repository dedicated to exploring Video Understanding with Large Language Models. It provides a comprehensive survey of the field, covering models, pretraining, instruction tuning, and hybrid methods. The repository also includes information on tasks, datasets, and benchmarks related to video understanding. Contributors are encouraged to add new papers, projects, and materials to enhance the repository.

Awesome-Knowledge-Distillation-of-LLMs
A collection of papers related to knowledge distillation of large language models (LLMs). The repository focuses on techniques to transfer advanced capabilities from proprietary LLMs to smaller models, compress open-source LLMs, and refine their performance. It covers various aspects of knowledge distillation, including algorithms, skill distillation, verticalization distillation in fields like law, medical & healthcare, finance, science, and miscellaneous domains. The repository provides a comprehensive overview of the research in the area of knowledge distillation of LLMs.
Awesome-Jailbreak-on-LLMs
Awesome-Jailbreak-on-LLMs is a collection of state-of-the-art, novel, and exciting jailbreak methods on Large Language Models (LLMs). The repository contains papers, codes, datasets, evaluations, and analyses related to jailbreak attacks on LLMs. It serves as a comprehensive resource for researchers and practitioners interested in exploring various jailbreak techniques and defenses in the context of LLMs. Contributions such as additional jailbreak-related content, pull requests, and issue reports are welcome, and contributors are acknowledged. For any inquiries or issues, contact [email protected]. If you find this repository useful for your research or work, consider starring it to show appreciation.

VoiceBench
VoiceBench is a repository containing code and data for benchmarking LLM-Based Voice Assistants. It includes a leaderboard with rankings of various voice assistant models based on different evaluation metrics. The repository provides setup instructions, datasets, evaluation procedures, and a curated list of awesome voice assistants. Users can submit new voice assistant results through the issue tracker for updates on the ranking list.

MOSS-TTS
MOSS-TTS Family is an open-source speech and sound generation model family designed for high-fidelity, high-expressiveness, and complex real-world scenarios. It includes five production-ready models: MOSS-TTS, MOSS-TTSD, MOSS-VoiceGenerator, MOSS-TTS-Realtime, and MOSS-SoundEffect, each serving specific purposes in speech generation, dialogue, voice design, real-time interactions, and sound effect generation. The models offer features like long-speech generation, fine-grained control over phonemes and duration, multilingual synthesis, voice cloning, and real-time voice agents.

llms-from-scratch-cn
This repository provides a detailed tutorial on how to build your own large language model (LLM) from scratch. It includes all the code necessary to create a GPT-like LLM, covering the encoding, pre-training, and fine-tuning processes. The tutorial is written in a clear and concise style, with plenty of examples and illustrations to help you understand the concepts involved. It is suitable for developers and researchers with some programming experience who are interested in learning more about LLMs and how to build them.

LLamaTuner
LLamaTuner is a repository for the Efficient Finetuning of Quantized LLMs project, focusing on building and sharing instruction-following Chinese baichuan-7b/LLaMA/Pythia/GLM model tuning methods. The project enables training on a single Nvidia RTX-2080TI and RTX-3090 for multi-round chatbot training. It utilizes bitsandbytes for quantization and is integrated with Huggingface's PEFT and transformers libraries. The repository supports various models, training approaches, and datasets for supervised fine-tuning, LoRA, QLoRA, and more. It also provides tools for data preprocessing and offers models in the Hugging Face model hub for inference and finetuning. The project is licensed under Apache 2.0 and acknowledges contributions from various open-source contributors.

Awesome-Interpretability-in-Large-Language-Models
This repository is a collection of resources focused on interpretability in large language models (LLMs). It aims to help beginners get started in the area and keep researchers updated on the latest progress. It includes libraries, blogs, tutorials, forums, tools, programs, papers, and more related to interpretability in LLMs.

CogVLM2
CogVLM2 is a new generation of open source models that offer significant improvements in benchmarks such as TextVQA and DocVQA. It supports 8K content length, image resolution up to 1344 * 1344, and both Chinese and English languages. The project provides basic calling methods, fine-tuning examples, and OpenAI API format calling examples to help developers quickly get started with the model.

Awesome-Tabular-LLMs
This repository is a collection of papers on Tabular Large Language Models (LLMs) specialized for processing tabular data. It includes surveys, models, and applications related to table understanding tasks such as Table Question Answering, Table-to-Text, Text-to-SQL, and more. The repository categorizes the papers based on key ideas and provides insights into the advancements in using LLMs for processing diverse tables and fulfilling various tabular tasks based on natural language instructions.
cool-ai-stuff
This repository contains an uncensored list of free to use APIs and sites for several AI models. > _This list is mainly managed by @zukixa, the queen of zukijourney, so any decisions may have bias!~_ > > **Scroll down for the sites, APIs come first!** * * * > [!WARNING] > We are not endorsing _any_ of the listed services! Some of them might be considered controversial. We are not responsible for any legal, technical or any other damage caused by using the listed services. Data is provided without warranty of any kind. **Use these at your own risk!** * * * # APIs Table of Contents #### Overview of Existing APIs #### Overview of Existing APIs -- Top LLM Models Available #### Overview of Existing APIs -- Top Image Models Available #### Overview of Existing APIs -- Top Other Features & Models Available #### Overview of Existing APIs -- Available Donator Perks * * * ## API List:* *: This list solely covers all providers I (@zukixa) was able to collect metrics in. Any mistakes are not my responsibility, as I am either banned, or not aware of x API. \ 1: Last Updated 4/14/24 ### Overview of APIs: | Service | # of Users1 | Link | Stablity | NSFW Ok? | Open Source? | Owner(s) | Other Notes | | ----------- | ---------- | ------------------------------------------ | ------------------------------------------ | --------------------------- | ------------------------------------------------------ | -------------------------- | ----------------------------------------------------------------------------------------------------------- | | zukijourney| 4441 | D | High | On /unf/, not /v1/ | ✅, Here | @zukixa | Largest & Oldest GPT-4 API still continuously around. Offers other popular AI-related Bots too. | | Hyzenberg| 1234 | D | High | Forbidden | ❌ | @thatlukinhasguy & @voidiii | Experimental sister API to Zukijourney. Successor to HentAI | | NagaAI | 2883 | D | High | Forbidden | ❌ | @zentixua | Honorary successor to ChimeraGPT, the largest API in history (15k users). | | WebRaftAI | 993 | D | High | Forbidden | ❌ | @ds_gamer | Largest API by model count. Provides a lot of service/hosting related stuff too. | | KrakenAI | 388 | D | High | Discouraged | ❌ | @paninico | It is an API of all time. | | ShuttleAI | 3585 | D | Medium | Generally Permitted | ❌ | @xtristan | Faked GPT-4 Before 1, 2 | | Mandrill | 931 | D | Medium | Enterprise-Tier-Only | ❌ | @fredipy | DALL-E-3 access pioneering API. Has some issues with speed & stability nowadays. | oxygen | 742 | D | Medium | Donator-Only | ❌ | @thesketchubuser | Bri'ish 🤮 & Fren'sh 🤮 | | Skailar | 399 | D | Medium | Forbidden | ❌ | @aquadraws | Service is the personification of the word 'feature creep'. Lots of things announced, not much operational. |
AI-Competition-Collections
AI-Competition-Collections is a repository that collects and curates various experiences and tips from AI competitions. It includes posts on competition experiences in computer vision, NLP, speech, and other AI-related fields. The repository aims to provide valuable insights and techniques for individuals participating in AI competitions, covering topics such as image classification, object detection, OCR, adversarial attacks, and more.
gpupixel
GPUPixel is a real-time, high-performance image and video filter library written in C++11 and based on OpenGL/ES. It incorporates a built-in beauty face filter that achieves commercial-grade beauty effects. The library is extremely easy to compile and integrate with a small size, supporting platforms including iOS, Android, Mac, Windows, and Linux. GPUPixel provides various filters like skin smoothing, whitening, face slimming, big eyes, lipstick, and blush. It supports input formats like YUV420P, RGBA, JPEG, PNG, and output formats like RGBA and YUV420P. The library's performance on devices like iPhone and Android is optimized, with low CPU usage and fast processing times. GPUPixel's lib size is compact, making it suitable for mobile and desktop applications.

DataFlow
DataFlow is a data preparation and training system designed to parse, generate, process, and evaluate high-quality data from noisy sources, improving the performance of large language models in specific domains. It constructs diverse operators and pipelines, validated to enhance domain-oriented LLM's performance in fields like healthcare, finance, and law. DataFlow also features an intelligent DataFlow-agent capable of dynamically assembling new pipelines by recombining existing operators on demand.
go-cyber
Cyber is a superintelligence protocol that aims to create a decentralized and censorship-resistant internet. It uses a novel consensus mechanism called CometBFT and a knowledge graph to store and process information. Cyber is designed to be scalable, secure, and efficient, and it has the potential to revolutionize the way we interact with the internet.

TRACE
TRACE is a temporal grounding video model that utilizes causal event modeling to capture videos' inherent structure. It presents a task-interleaved video LLM model tailored for sequential encoding/decoding of timestamps, salient scores, and textual captions. The project includes various model checkpoints for different stages and fine-tuning on specific datasets. It provides evaluation codes for different tasks like VTG, MVBench, and VideoMME. The repository also offers annotation files and links to raw videos preparation projects. Users can train the model on different tasks and evaluate the performance based on metrics like CIDER, METEOR, SODA_c, F1, mAP, Hit@1, etc. TRACE has been enhanced with trace-retrieval and trace-uni models, showing improved performance on dense video captioning and general video understanding tasks.
For similar tasks
Awesome-LLMs-for-Video-Understanding
Awesome-LLMs-for-Video-Understanding is a repository dedicated to exploring Video Understanding with Large Language Models. It provides a comprehensive survey of the field, covering models, pretraining, instruction tuning, and hybrid methods. The repository also includes information on tasks, datasets, and benchmarks related to video understanding. Contributors are encouraged to add new papers, projects, and materials to enhance the repository.
Video-MME
Video-MME is the first-ever comprehensive evaluation benchmark of Multi-modal Large Language Models (MLLMs) in Video Analysis. It assesses the capabilities of MLLMs in processing video data, covering a wide range of visual domains, temporal durations, and data modalities. The dataset comprises 900 videos with 256 hours and 2,700 human-annotated question-answer pairs. It distinguishes itself through features like duration variety, diversity in video types, breadth in data modalities, and quality in annotations.

ControlLLM
ControlLLM is a framework that empowers large language models to leverage multi-modal tools for solving complex real-world tasks. It addresses challenges like ambiguous user prompts, inaccurate tool selection, and inefficient tool scheduling by utilizing a task decomposer, a Thoughts-on-Graph paradigm, and an execution engine with a rich toolbox. The framework excels in tasks involving image, audio, and video processing, showcasing superior accuracy, efficiency, and versatility compared to existing methods.

gen-cv
This repository is a rich resource offering examples of synthetic image generation, manipulation, and reasoning using Azure Machine Learning, Computer Vision, OpenAI, and open-source frameworks like Stable Diffusion. It provides practical insights into image processing applications, including content generation, video analysis, avatar creation, and image manipulation with various tools and APIs.

outspeed
Outspeed is a PyTorch-inspired SDK for building real-time AI applications on voice and video input. It offers low-latency processing of streaming audio and video, an intuitive API familiar to PyTorch users, flexible integration of custom AI models, and tools for data preprocessing and model deployment. Ideal for developing voice assistants, video analytics, and other real-time AI applications processing audio-visual data.
starter-applets
This repository contains the source code for Google AI Studio's starter apps — a collection of small apps that demonstrate how Gemini can be used to create interactive experiences. These apps are built to run inside AI Studio, but the versions included here can run standalone using the Gemini API. The apps cover spatial understanding, video analysis, and map exploration, showcasing Gemini's capabilities in these areas. Developers can use these starter applets to kickstart their projects and learn how to leverage Gemini for spatial reasoning and interactive experiences.
TRACE
TRACE is a temporal grounding video model that utilizes causal event modeling to capture videos' inherent structure. It presents a task-interleaved video LLM model tailored for sequential encoding/decoding of timestamps, salient scores, and textual captions. The project includes various model checkpoints for different stages and fine-tuning on specific datasets. It provides evaluation codes for different tasks like VTG, MVBench, and VideoMME. The repository also offers annotation files and links to raw videos preparation projects. Users can train the model on different tasks and evaluate the performance based on metrics like CIDER, METEOR, SODA_c, F1, mAP, Hit@1, etc. TRACE has been enhanced with trace-retrieval and trace-uni models, showing improved performance on dense video captioning and general video understanding tasks.
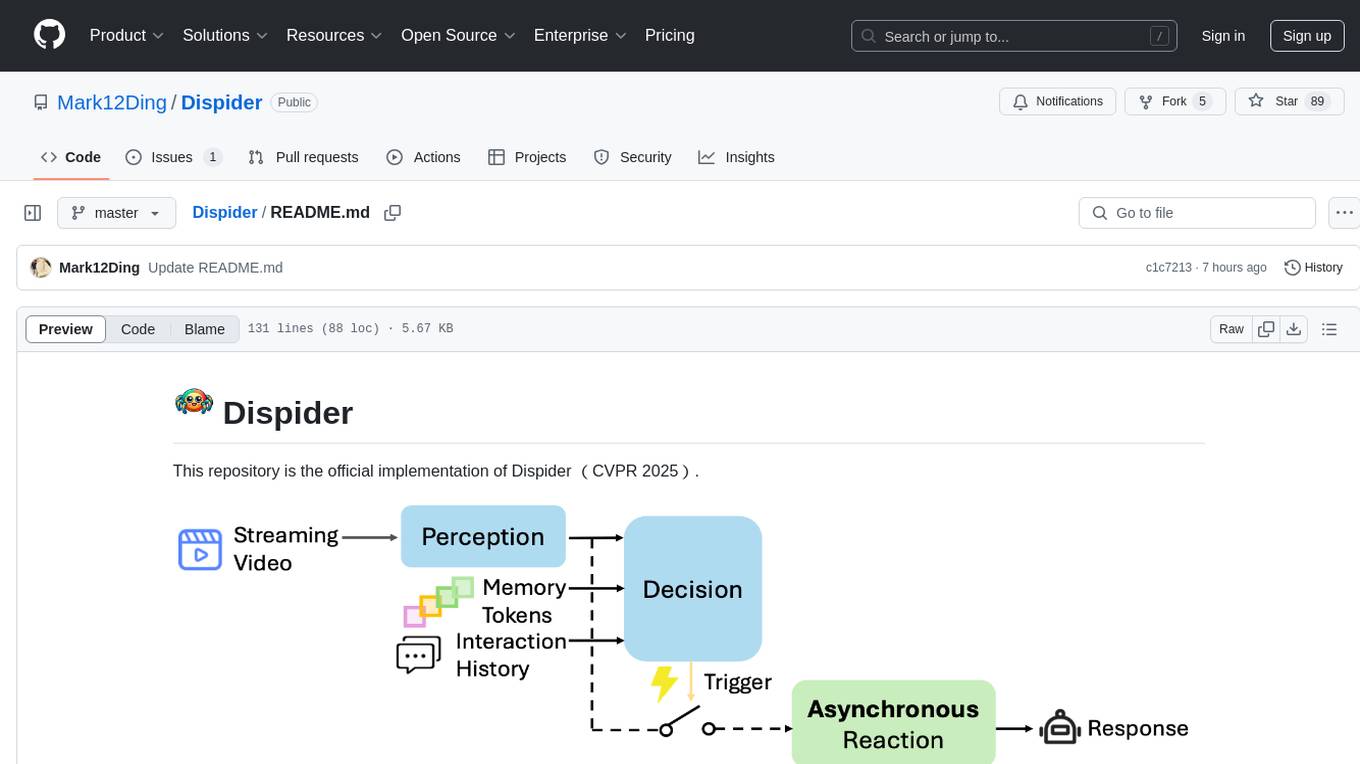
Dispider
Dispider is an implementation enabling real-time interactions with streaming videos, providing continuous feedback in live scenarios. It separates perception, decision-making, and reaction into asynchronous modules, ensuring timely interactions. Dispider outperforms VideoLLM-online on benchmarks like StreamingBench and excels in temporal reasoning. The tool requires CUDA 11.8 and specific library versions for optimal performance.
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.