
awesome-VLLMs
This repository collects papers on VLLM applications. We will update new papers irregularly.
Stars: 165
This repository contains a collection of pre-trained Very Large Language Models (VLLMs) that can be used for various natural language processing tasks. The models are fine-tuned on large text corpora and can be easily integrated into existing NLP pipelines for tasks such as text generation, sentiment analysis, and language translation. The repository also provides code examples and tutorials to help users get started with using these powerful language models in their projects.
README:

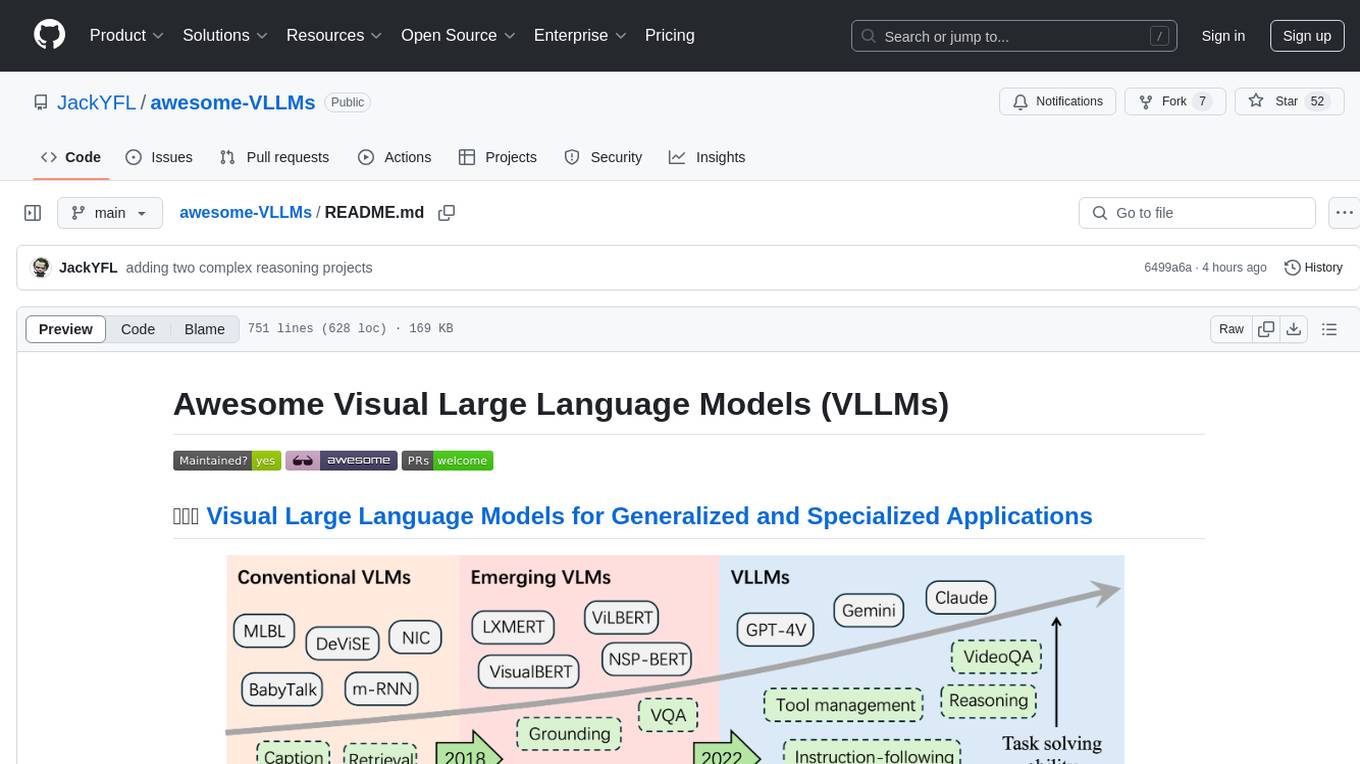
Vision language models (VLMs) have emerged as powerful tools for learning unified embedding spaces that integrate vision and language. Inspired by the success of large language models (LLMs), which have demonstrated remarkable reasoning and multi-task capabilities, visual large language models (VLLMs) are gaining significant attention for developing both general-purpose and specialized VLMs.
In this repository, we provide a comprehensive summary of the current literature from an application-oriented perspective. We hope this resource serves as a valuable reference for the VLLM research community.
If you are interested in this project, you can contribute to this repo by pulling requests 😊😊😊
If you think our paper is helpful for your research, you can cite through this bib tex entry!
@article{li2025visual,
title={Visual Large Language Models for Generalized and Specialized Applications},
author={Li, Yifan and Lai, Zhixin and Bao, Wentao and Tan, Zhen and Dao, Anh and Sui, Kewei and Shen, Jiayi and Liu, Dong and Liu, Huan and Kong, Yu},
journal={arXiv preprint arXiv:2501.02765},
year={2025}
}
🚀 What's New in This Update:
- [2025.7.28]: 🔥 Adding five papers on autonomous driving, vision generation and video understanding!
- [2025.4.25]: 🔥 Adding eleven papers on complex reasoning, face, video understanding and medical!
- [2025.4.18]: 🔥 Adding three papers on complex reasoning!
- [2025.4.12]: 🔥 Adding one paper on complex reasoning and one paper on efficiency!
- [2025.3.20]: 🔥 Adding eleven papers and 1 wonderful repo on complex reasoning!
- [2025.3.10]: 🔥 Adding three papers on complex reasoning, efficiency and face!
- [2025.3.6]: 🔥 Adding one paper on complex reasoning!
- [2025.3.2]: 🔥 Adding two projects on complex reasoning: R1-V and VLM-R1!
- [2025.2.23]: 🔥 Adding one video-to-action paper and one vision-to-text paper!
- [2025.2.1]: 🔥 Adding four video-to-text papers!
- [2025.1.22]: 🔥 Adding one video-to-text paper!
- [2025.1.17]: 🔥 Adding three video-to-text papers, thanks for the contributions from Enxin!
- [2025.1.14]: 🔥 Adding two complex reasoning papers and one video-to-text paper!
- [2025.1.13]: 🔥 Adding one VFM survey paper!
- [2025.1.12]: 🔥 Adding one efficient MLLM paper!
- [2025.1.9]: 🔥🔥🔥 Adding one efficient MLLM survey!
- [2025.1.7]: 🔥🔥🔥 Our survey paper is released! Please check this link for more information. We add more tool management papers in our paper list.
- [2025.1.6]: 🔥 We add one OS Agent survey paper in our paper list, and a new category: complex reasoning!
- [2025.1.4]: 🔥 We updated the general domain and egocentric video papers in our paper list, thanks for the contributions from Wentao!
- [2025.1.2]: 🔥 We add more interpretation papers to our paper list, thanks for the contributions from Ruoyu!
- [2024.12.15]: 🔥 We release our VLLM application paper list repo!
- Visual Large Language Models for Generalized and Specialized Applications
- Contributors
| Title | Venue | Date | Code | Project |
|---|---|---|---|---|
 A Survey on Bridging VLMs and Synthetic Data |
OpenReview | 2025-05-16 | Github | Project |
 Foundation Models Defining a New Era in Vision: A Survey and Outlook |
T-PAMI | 2025-1-9 | Github | Project |
 Vision-Language Models for Vision Tasks: A Survey |
T-PAMI | 2024-8-8 | Github | Project |
 Vision + Language Applications: A Survey |
CVPRW | 2023-5-24 | Github | Project |
|
Vision-and-Language Pretrained Models: A Survey |
IJCAI (survey track) | 2022-5-3 | Github | Project |














































































| Name | Title | Venue | Date | Code | Project |
|---|---|---|---|---|---|
| EchoSight |
 EchoSight: Advancing Visual-Language Models with Wiki Knowledge |
EMNLP | 2024-07-17 | Github | Project |
| FROMAGe |
 Grounding Language Models to Images for Multimodal Inputs and Outputs |
ICML | 2024-01-31 | Github | Project |
| Wiki-LLaVA | Wiki-LLaVA: Hierarchical Retrieval-Augmented Generation for Multimodal LLMs | CVPR | 2023-04-23 | Github | Project |
| UniMuR | Unified Embeddings for Multimodal Retrieval via Frozen LLMs | ICML | 2019-05-08 | Github | Project |
























| Name | Title | Venue | Date | Code | Project |
|---|---|---|---|---|---|
| Graphist |
 Graphic Design with Large Multimodal Model |
ArXiv | 2024-04-22 | Github | Project |
| Ferret-UI |
Ferret-UI: Grounded Mobile UI Understanding with Multimodal LLMs |
ECCV | 2024-04-08 | Github | Project |
| CogAgent |
 CogAgent: A Visual Language Model for GUI Agents |
CVPR | 2023-12-21 | Github | Project |
| Name | Title | Venue | Date | Code | Project |
|---|---|---|---|---|---|
| FinTral |
FinTral: A Family of GPT-4 Level Multimodal Financial Large Language Models |
ACL | 2024-06-14 | Github | Project |
| FinVis-GPT |
 FinVis-GPT: A Multimodal Large Language Model for Financial Chart Analysis |
ArXiv | 2023-07-31 | Github | Project |


























| Name | Title | Venue | Date | Code | Project |
|---|---|---|---|---|---|
| Video-LLaVA |
 Video-llava: Learning united visual representation by alignment before projection |
EMNLP | 2024-10-01 | Github | Project |
| BT-Adapter |
 BT-Adapter: Video Conversation is Feasible Without Video Instruction Tuning |
CVPR | 2024-06-27 | Github | Project |
| VideoGPT+ |
 VideoGPT+: Integrating Image and Video Encoders for Enhanced Video Understanding |
arXiv | 2024-06-13 | Github | Project |
| Video-ChatGPT |
 Video-ChatGPT: Towards Detailed Video Understanding via Large Vision and Language Models |
ACL | 2024-06-10 | Github | Project |
| MVBench |
 MVBench: A Comprehensive Multi-modal Video Understanding Benchmark |
CVPR | 2024-05-23 | Github | Project |
| LVChat |
 LVCHAT: Facilitating Long Video Comprehension |
ArXiv | 2024-02-19 | Github | Project |
| VideoChat |
VideoChat: Chat-Centric Video Understanding |
ArXiv | 2024-01-04 | Github | Project |
| Valley |
 Valley: Video Assistant with Large Language model Enhanced abilitY |
ArXiv | 2023-10-08 | Github | Project |
| Name | Title | Venue | Date | Code | Project |
|---|---|---|---|---|---|
| StreamChat |
 Streaming Video Understanding and Multi-round Interaction with Memory-enhanced Knowledge |
ICLR | 2025-01-23 | Github | Project |
| PALM |
 PALM: Predicting Actions through Language Models |
CVPR Workshop | 2024-07-18 | Github | Project |
| GPT4Ego | GPT4Ego: Unleashing the Potential of Pre-trained Models for Zero-Shot Egocentric Action Recognition | ArXiv | 2024-05-11 | Github | Project |
| AntGPT |
 AntGPT: Can Large Language Models Help Long-term Action Anticipation from Videos? |
ICLR | 2024-04-01 | Github | Project |
| LEAP | LEAP: LLM-Generation of Egocentric Action Programs | ArXiv | 2023-11-29 | Github | Project |
| LLM-Inner-Speech |
 Egocentric Video Comprehension via Large Language Model Inner Speech |
CVPR Workshop | 2023-06-18 | Github | Project |
| LLM-Brain | LLM as A Robotic Brain: Unifying Egocentric Memory and Control | ArXiv | 2023-04-25 | Github | Project |
| LaViLa |
 Learning Video Representations from Large Language Models |
CVPR | 2022-12-08 | Github | Project |
| Name | Title | Venue | Date | Code | Project |
|---|---|---|---|---|---|
| DriveBench |
 Are VLMs Ready for Autonomous Driving? An Empirical Study from the Reliability, Data, and Metric Perspectives |
ICCV | 2025-1-7 | Github | Project |
| DriveLM |
 DriveLM: Driving with Graph Visual Question Answering |
ECCV | 2024-7-17 | Github | Project |
| Talk2BEV |
 Talk2BEV: Language-enhanced Bird’s-eye View Maps for Autonomous Driving |
ICRA | 2024-5-13 | Github | Project |
| Nuscenes-QA |
 TNuScenes-QA: A Multi-Modal Visual Question Answering Benchmark for Autonomous Driving Scenario |
AAAI | 2024-3-24 | Github | Project |
| DriveMLM |
 DriveMLM: Aligning Multi-Modal Large Language Models with Behavioral Planning States for Autonomous Driving |
ArXiv | 2023-12-25 | Github | Project |
| LiDAR-LLM |
LiDAR-LLM: Exploring the Potential of Large Language Models for 3D LiDAR Understanding |
CoRR | 2023-12-21 | Github | Project |
| Dolphis |
 Dolphins: Multimodal Language Model for Driving |
ArXiv | 2023-12-1 | Github | Project |
| Name | Title | Venue | Date | Code | Project |
|---|---|---|---|---|---|
| DriveGPT4 |
DriveGPT4: Interpretable End-to-End Autonomous Driving Via Large Language Model |
RAL | 2024-8-7 | Github | Project |
| SurrealDriver |
 SurrealDriver: Designing LLM-powered Generative Driver Agent Framework based on Human Drivers’ Driving-thinking Data |
ArXiv | 2024-7-22 | Github | Project |
| DriveVLM |
DriveVLM: The Convergence of Autonomous Driving and Large Vision-Language Models |
CoRL | 2024-6-25 | Github | Project |
| DiLu |
 DiLu: A Knowledge-Driven Approach to Autonomous Driving with Large Language Models |
ICLR | 2024-2-22 | Github | Project |
| LMDrive |
 LMDrive: Closed-Loop End-to-End Driving with Large Language Models |
CVPR | 2023-12-21 | Github | Project |
| GPT-Driver |
 DGPT-Driver: Learning to Drive with GPT |
NeurlPS Workshop | 2023-12-5 | Github | Project |
| ADriver-I |
ADriver-I: A General World Model for Autonomous Driving |
ArXiv | 2023-11-22 | Github | Project |
| Name | Title | Venue | Date | Code | Project |
|---|---|---|---|---|---|
| Seena |
 Senna: Bridging Large Vision-Language Models and End-to-End Autonomous Driving |
ArXiv | 2024-10-29 | Github | Project |
| BEV-InMLLM |
 Holistic autonomous driving understanding by bird’s-eye-view injected multi-Modal large model |
CVPR | 2024-1-2 | Github | Project |
| Prompt4Driving |
 Language Prompt for Autonomous Driving |
ArXiv | 2023-9-8 | Github | Project |
| Name | Title | Venue | Date | Code | Project |
|---|---|---|---|---|---|
| Wonderful-Team |
 Wonderful Team: Zero-Shot Physical Task Planning with Visual LLMs |
ArXiv | 2024-12-4 | Github | Project |
| AffordanceLLM |
 AffordanceLLM: Grounding Affordance from Vision Language Models |
CVPR | 2024-4-17 | Github | Project |
| 3DVisProg |
 Visual Programming for Zero-shot Open-Vocabulary 3D Visual Grounding |
CVPR | 2024-3-23 | Github | Project |
| WREPLAN |
REPLAN: Robotic Replanning with Perception and Language Models |
ArXiv | 2024-2-20 | Github | Project |
| PaLM-E |
PaLM-E: An Embodied Multimodal Language Model |
ICML | 2023-3-6 | Github | Project |
| Name | Title | Venue | Date | Code | Project |
|---|---|---|---|---|---|
| OpenVLA |
 OpenVLA: An Open-Source Vision-Language-Action Model |
ArXiv | 2024-9-5 | Github | Project |
| LLARVA |
 LLARVA: Vision-Action Instruction Tuning Enhances Robot Learning |
CoRL | 2024-6-17 | Github | Project |
| RT-X |
 Open X-Embodiment: Robotic Learning Datasets and RT-X Models |
ArXiv | 2024-6-1 | Github | Project |
| RoboFlamingo |
Vision-Language Foundation Models as Effective Robot Imitators |
ICLR | 2024-2-5 | Github | Project |
| VoxPoser |
 VoxPoser: Composable 3D Value Maps for Robotic Manipulation with Language Models |
CoRL | 2023-11-2 | Github | Project |
| ManipLLM |
 ManipLLM: Embodied Multimodal Large Language Model for Object-Centric Robotic Manipulation |
CVPR | 2023-12-24 | Github | Project |
| RT-2 |
RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control |
ArXiv | 2023-7-28 | Github | Project |
| Instruct2Act |
 Instruct2Act: Mapping Multi-modality Instructions to Robotic Actions with Large Language Model |
ArXiv | 2023-5-24 | Github | Project |
| Name | Title | Venue | Date | Code | Project |
|---|---|---|---|---|---|
| Embodied-Reasoner |
 Embodied-Reasoner: Synergizing Visual Search, Reasoning, and Action for Embodied Interactive Tasks |
Arxiv | 2025-3-27 | Github | Project |
| LLaRP |
 Large Language Models as Generalizable Policies for Embodied Tasks |
ICLR | 2024-4-16 | Github | Project |
| MP5 |
 MP5: A Multi-modal Open-ended Embodied System in Minecraft via Active Perception |
CVPR | 2024-3-24 | Github | Project |
| LL3DA |
 LL3DA: Visual Interactive Instruction Tuning for Omni-3D Understanding, Reasoning, and Planning |
CVPR | 2023-11-30 | Github | Project |
| EmbodiedGPT |
 EmbodiedGPT: Vision-Language Pre-Training via Embodied Chain of Thought |
NeurlPS | 2023-11-2 | Github | Project |
| ELLM |
 Guiding Pretraining in Reinforcement Learning with Large Language Models |
ICML | 2023-9-15 | Github | Project |
| 3D-LLM |
 3D-LLM: Injecting the 3D World into Large Language Models |
NeurlPS | 2023-7-24 | Github | Project |
| NLMap |
 Open-vocabulary Queryable Scene Representations for Real World Planning |
ICRA | 2023-7-4 | Github | Project |
| Name | Title | Venue | Date | Code | Project |
|---|---|---|---|---|---|
| ConceptGraphs |
 ConceptGraphs: Open-Vocabulary 3D Scene Graphs for Perception and Planning |
ICRA | 2024-5-13 | Github | Project |
| RILA |
RILA: Reflective and Imaginative Language Agent for Zero-Shot Semantic Audio-Visual Navigation |
CVPR | 2024-4-27 | Github | Project |
| EMMA |
 Embodied Multi-Modal Agent trained by an LLM from a Parallel TextWorld |
CVPR | 2024-3-29 | Github | Project |
| VLN-VER |
 Volumetric Environment Representation for Vision-Language Navigation |
CVPR | 2024-3-24 | Github | Project |
| MultiPLY |
 MultiPLY: A Multisensory Object-Centric Embodied Large Language Model in 3D World |
CVPR | 2024-1-16 | Github | Project |





























| Name | Title | Venue | Date | Code | Project |
|---|---|---|---|---|---|
| 3DGPT |
 3D-GPT: Procedural 3D Modeling with Large Language Models |
ArXiv | 2024-5-29 | GitHub | Project |
| Holodeck |
 Holodeck: Language Guided Generation of 3D Embodied AI Environments |
CVPR | 2024-4-22 | GitHub | Project |
| LLMR |
 LLMR: Real-time Prompting of Interactive Worlds using Large Language Models |
ACM CHI | 2024-3-22 | GitHub | Project |
| GPT4Point |
 GPT4Point: A Unified Framework for Point-Language Understanding and Generation |
ArXiv | 2023-12-1 | GitHub | Project |
| ShapeGPT |
 ShapeGPT: 3D Shape Generation with A Unified Multi-modal Language Model |
ArXiv | 2023-12-1 | GitHub | Project |
| MeshGPT |
 MeshGPT: Generating Triangle Meshes with Decoder-Only Transformers |
ArXiv | 2023-11-27 | GitHub | Project |
| LI3D | Towards Language-guided Interactive 3D Generation: LLMs as Layout Interpreter with Generative Feedback | NeurlPS | 2023-5-26 | GitHub | Project |










| Name | Title | Venue | Date | Code | Project |
|---|---|---|---|---|---|
| HAWK |
 HAWK: Learning to Understand Open-World Video Anomalies |
NeurlPS | 2024-5-27 | Github | Project |
| CUVA |
 Uncovering What Why and How: A Comprehensive Benchmark for Causation Understanding of Video Anomaly |
CVPR | 2024-5-6 | Github | Project |
| LAVAD |
 Harnessing Large Language Models for Training-free Video Anomaly Detectiong |
CVPR | 2024-4-1 | Github | Project |






























| Name | Title | Venue | Date | Code | Project |
|---|---|---|---|---|---|
| SynthVLM |
 Synthvlm: High-efficiency and high-quality synthetic data for vision language models |
ArXiv | 2024-8-10 | Github | Project |
| WolfMLLM |
 The Wolf Within: Covert Injection of Malice into MLLM Societies via an MLLM Operative |
ArXiv | 2024-6-3 | Github | Project |
| AttackMLLM | Synthvlm: High-efficiency and high-quality synthetic data for vision language models | ICLRW | 2024-5-16 | Github | Project |
| OODCV |
 How Many Unicorns Are in This Image? A Safety Evaluation Benchmark for Vision LLMs |
ECCV | 2023-11-27 | Github | Project |
| InjectMLLM |
 (ab) using images and sounds for indirect instruction injection in multi-modal llms |
ArXiv | 2023-10-3 | Github | Project |
| AdvMLLM | On the Adversarial Robustness of Multi-Modal Foundation Models | ICCVW | 2023-8-21 | Github | Project |




















































Thanks to all the contributors! You are awesome!
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for awesome-VLLMs
Similar Open Source Tools
awesome-VLLMs
This repository contains a collection of pre-trained Very Large Language Models (VLLMs) that can be used for various natural language processing tasks. The models are fine-tuned on large text corpora and can be easily integrated into existing NLP pipelines for tasks such as text generation, sentiment analysis, and language translation. The repository also provides code examples and tutorials to help users get started with using these powerful language models in their projects.
intro-llm.github.io
Large Language Models (LLM) are language models built by deep neural networks containing hundreds of billions of weights, trained on a large amount of unlabeled text using self-supervised learning methods. Since 2018, companies and research institutions including Google, OpenAI, Meta, Baidu, and Huawei have released various models such as BERT, GPT, etc., which have performed well in almost all natural language processing tasks. Starting in 2021, large models have shown explosive growth, especially after the release of ChatGPT in November 2022, attracting worldwide attention. Users can interact with systems using natural language to achieve various tasks from understanding to generation, including question answering, classification, summarization, translation, and chat. Large language models demonstrate powerful knowledge of the world and understanding of language. This repository introduces the basic theory of large language models including language models, distributed model training, and reinforcement learning, and uses the Deepspeed-Chat framework as an example to introduce the implementation of large language models and ChatGPT-like systems.
FastFlowLM
FastFlowLM is a Python library for efficient and scalable language model inference. It provides a high-performance implementation of language model scoring using n-gram language models. The library is designed to handle large-scale text data and can be easily integrated into natural language processing pipelines for tasks such as text generation, speech recognition, and machine translation. FastFlowLM is optimized for speed and memory efficiency, making it suitable for both research and production environments.
LLM-Workshop
This repository contains a collection of resources for learning about and using Large Language Models (LLMs). The resources include tutorials, code examples, and links to additional resources. LLMs are a type of artificial intelligence that can understand and generate human-like text. They have a wide range of potential applications, including natural language processing, machine translation, and chatbot development.
LLM-Project
LLM-Project is a machine learning model for sentiment analysis. It is designed to analyze text data and classify it into positive, negative, or neutral sentiments. The model uses natural language processing techniques to extract features from the text and train a classifier to make predictions. LLM-Project is suitable for researchers, developers, and data scientists who are working on sentiment analysis tasks. It provides a pre-trained model that can be easily integrated into existing projects or used for experimentation and research purposes. The codebase is well-documented and easy to understand, making it accessible to users with varying levels of expertise in machine learning and natural language processing.

LLMs-playground
LLMs-playground is a repository containing code examples and tutorials for learning and experimenting with Large Language Models (LLMs). It provides a hands-on approach to understanding how LLMs work and how to fine-tune them for specific tasks. The repository covers various LLM architectures, pre-training techniques, and fine-tuning strategies, making it a valuable resource for researchers, students, and practitioners interested in natural language processing and machine learning. By exploring the code and following the tutorials, users can gain practical insights into working with LLMs and apply their knowledge to real-world projects.
llm_recipes
This repository showcases the author's experiments with Large Language Models (LLMs) for text generation tasks. It includes dataset preparation, preprocessing, model fine-tuning using libraries such as Axolotl and HuggingFace, and model evaluation.

turftopic
Turftopic is a Python library that provides tools for sentiment analysis and topic modeling of text data. It allows users to analyze large volumes of text data to extract insights on sentiment and topics. The library includes functions for preprocessing text data, performing sentiment analysis using machine learning models, and conducting topic modeling using algorithms such as Latent Dirichlet Allocation (LDA). Turftopic is designed to be user-friendly and efficient, making it suitable for both beginners and experienced data analysts.
ai-workshop-code
The ai-workshop-code repository contains code examples and tutorials for various artificial intelligence concepts and algorithms. It serves as a practical resource for individuals looking to learn and implement AI techniques in their projects. The repository covers a wide range of topics, including machine learning, deep learning, natural language processing, computer vision, and reinforcement learning. By exploring the code and following the tutorials, users can gain hands-on experience with AI technologies and enhance their understanding of how these algorithms work in practice.
llm_rl
llm_rl is a repository that combines llm (language model) and rl (reinforcement learning) techniques. It likely focuses on using language models in reinforcement learning tasks, such as natural language understanding and generation. The repository may contain implementations of algorithms that leverage both llm and rl to improve performance in various tasks. Developers interested in exploring the intersection of language models and reinforcement learning may find this repository useful for research and experimentation.
Awesome-RAG
Awesome-RAG is a repository that lists recent developments in Retrieval-Augmented Generation (RAG) for large language models (LLM). It includes accepted papers, evaluation datasets, latest news, and papers from various conferences like NIPS, EMNLP, ACL, ICML, and ICLR. The repository is continuously updated and aims to build a general framework for RAG. Researchers are encouraged to submit pull requests to update information in their papers. The repository covers a wide range of topics related to RAG, including knowledge-enhanced generation, contrastive reasoning, self-alignment, mobile agents, and more.

ai
This repository contains a collection of AI algorithms and models for various machine learning tasks. It provides implementations of popular algorithms such as neural networks, decision trees, and support vector machines. The code is well-documented and easy to understand, making it suitable for both beginners and experienced developers. The repository also includes example datasets and tutorials to help users get started with building and training AI models. Whether you are a student learning about AI or a professional working on machine learning projects, this repository can be a valuable resource for your development journey.
Complete-LLM-Finetuning
Complete-LLM-Finetuning is a tool designed for fine-tuning large language models for various natural language processing tasks. It provides a comprehensive guide and resources for users to effectively fine-tune language models for specific applications. The tool aims to simplify the process of adapting pre-trained language models to new tasks by offering step-by-step instructions and best practices. Users can leverage the tool to enhance the performance of language models on specific datasets and tasks, enabling them to achieve better results in natural language processing projects.
cs-self-learning
This repository serves as an archive for computer science learning notes, codes, and materials. It covers a wide range of topics including basic knowledge, AI, backend & big data, tools, and other related areas. The content is organized into sections and subsections for easy navigation and reference. Users can find learning resources, programming practices, and tutorials on various subjects such as languages, data structures & algorithms, AI, frameworks, databases, development tools, and more. The repository aims to support self-learning and skill development in the field of computer science.

RecAI
RecAI is a project that explores the integration of Large Language Models (LLMs) into recommender systems, addressing the challenges of interactivity, explainability, and controllability. It aims to bridge the gap between general-purpose LLMs and domain-specific recommender systems, providing a holistic perspective on the practical requirements of LLM4Rec. The project investigates various techniques, including Recommender AI agents, selective knowledge injection, fine-tuning language models, evaluation, and LLMs as model explainers, to create more sophisticated, interactive, and user-centric recommender systems.
build-your-own-x-machine-learning
This repository provides a step-by-step guide for building your own machine learning models from scratch. It covers various machine learning algorithms and techniques, including linear regression, logistic regression, decision trees, and neural networks. The code examples are written in Python and include detailed explanations to help beginners understand the concepts behind machine learning. By following the tutorials in this repository, you can gain a deeper understanding of how machine learning works and develop your own models for different applications.
For similar tasks

nlp-llms-resources
The 'nlp-llms-resources' repository is a comprehensive resource list for Natural Language Processing (NLP) and Large Language Models (LLMs). It covers a wide range of topics including traditional NLP datasets, data acquisition, libraries for NLP, neural networks, sentiment analysis, optical character recognition, information extraction, semantics, topic modeling, multilingual NLP, domain-specific LLMs, vector databases, ethics, costing, books, courses, surveys, aggregators, newsletters, papers, conferences, and societies. The repository provides valuable information and resources for individuals interested in NLP and LLMs.

adata
AData is a free and open-source A-share database that focuses on transaction-related data. It provides comprehensive data on stocks, including basic information, market data, and sentiment analysis. AData is designed to be easy to use and integrate with other applications, making it a valuable tool for quantitative trading and AI training.

PIXIU
PIXIU is a project designed to support the development, fine-tuning, and evaluation of Large Language Models (LLMs) in the financial domain. It includes components like FinBen, a Financial Language Understanding and Prediction Evaluation Benchmark, FIT, a Financial Instruction Dataset, and FinMA, a Financial Large Language Model. The project provides open resources, multi-task and multi-modal financial data, and diverse financial tasks for training and evaluation. It aims to encourage open research and transparency in the financial NLP field.

hezar
Hezar is an all-in-one AI library designed specifically for the Persian community. It brings together various AI models and tools, making it easy to use AI with just a few lines of code. The library seamlessly integrates with Hugging Face Hub, offering a developer-friendly interface and task-based model interface. In addition to models, Hezar provides tools like word embeddings, tokenizers, feature extractors, and more. It also includes supplementary ML tools for deployment, benchmarking, and optimization.

text-embeddings-inference
Text Embeddings Inference (TEI) is a toolkit for deploying and serving open source text embeddings and sequence classification models. TEI enables high-performance extraction for popular models like FlagEmbedding, Ember, GTE, and E5. It implements features such as no model graph compilation step, Metal support for local execution on Macs, small docker images with fast boot times, token-based dynamic batching, optimized transformers code for inference using Flash Attention, Candle, and cuBLASLt, Safetensors weight loading, and production-ready features like distributed tracing with Open Telemetry and Prometheus metrics.

CodeProject.AI-Server
CodeProject.AI Server is a standalone, self-hosted, fast, free, and open-source Artificial Intelligence microserver designed for any platform and language. It can be installed locally without the need for off-device or out-of-network data transfer, providing an easy-to-use solution for developers interested in AI programming. The server includes a HTTP REST API server, backend analysis services, and the source code, enabling users to perform various AI tasks locally without relying on external services or cloud computing. Current capabilities include object detection, face detection, scene recognition, sentiment analysis, and more, with ongoing feature expansions planned. The project aims to promote AI development, simplify AI implementation, focus on core use-cases, and leverage the expertise of the developer community.

spark-nlp
Spark NLP is a state-of-the-art Natural Language Processing library built on top of Apache Spark. It provides simple, performant, and accurate NLP annotations for machine learning pipelines that scale easily in a distributed environment. Spark NLP comes with 36000+ pretrained pipelines and models in more than 200+ languages. It offers tasks such as Tokenization, Word Segmentation, Part-of-Speech Tagging, Named Entity Recognition, Dependency Parsing, Spell Checking, Text Classification, Sentiment Analysis, Token Classification, Machine Translation, Summarization, Question Answering, Table Question Answering, Text Generation, Image Classification, Image to Text (captioning), Automatic Speech Recognition, Zero-Shot Learning, and many more NLP tasks. Spark NLP is the only open-source NLP library in production that offers state-of-the-art transformers such as BERT, CamemBERT, ALBERT, ELECTRA, XLNet, DistilBERT, RoBERTa, DeBERTa, XLM-RoBERTa, Longformer, ELMO, Universal Sentence Encoder, Llama-2, M2M100, BART, Instructor, E5, Google T5, MarianMT, OpenAI GPT2, Vision Transformers (ViT), OpenAI Whisper, and many more not only to Python and R, but also to JVM ecosystem (Java, Scala, and Kotlin) at scale by extending Apache Spark natively.

scikit-llm
Scikit-LLM is a tool that seamlessly integrates powerful language models like ChatGPT into scikit-learn for enhanced text analysis tasks. It allows users to leverage large language models for various text analysis applications within the familiar scikit-learn framework. The tool simplifies the process of incorporating advanced language processing capabilities into machine learning pipelines, enabling users to benefit from the latest advancements in natural language processing.
For similar jobs

promptflow
**Prompt flow** is a suite of development tools designed to streamline the end-to-end development cycle of LLM-based AI applications, from ideation, prototyping, testing, evaluation to production deployment and monitoring. It makes prompt engineering much easier and enables you to build LLM apps with production quality.

deepeval
DeepEval is a simple-to-use, open-source LLM evaluation framework specialized for unit testing LLM outputs. It incorporates various metrics such as G-Eval, hallucination, answer relevancy, RAGAS, etc., and runs locally on your machine for evaluation. It provides a wide range of ready-to-use evaluation metrics, allows for creating custom metrics, integrates with any CI/CD environment, and enables benchmarking LLMs on popular benchmarks. DeepEval is designed for evaluating RAG and fine-tuning applications, helping users optimize hyperparameters, prevent prompt drifting, and transition from OpenAI to hosting their own Llama2 with confidence.

MegaDetector
MegaDetector is an AI model that identifies animals, people, and vehicles in camera trap images (which also makes it useful for eliminating blank images). This model is trained on several million images from a variety of ecosystems. MegaDetector is just one of many tools that aims to make conservation biologists more efficient with AI. If you want to learn about other ways to use AI to accelerate camera trap workflows, check out our of the field, affectionately titled "Everything I know about machine learning and camera traps".

leapfrogai
LeapfrogAI is a self-hosted AI platform designed to be deployed in air-gapped resource-constrained environments. It brings sophisticated AI solutions to these environments by hosting all the necessary components of an AI stack, including vector databases, model backends, API, and UI. LeapfrogAI's API closely matches that of OpenAI, allowing tools built for OpenAI/ChatGPT to function seamlessly with a LeapfrogAI backend. It provides several backends for various use cases, including llama-cpp-python, whisper, text-embeddings, and vllm. LeapfrogAI leverages Chainguard's apko to harden base python images, ensuring the latest supported Python versions are used by the other components of the stack. The LeapfrogAI SDK provides a standard set of protobuffs and python utilities for implementing backends and gRPC. LeapfrogAI offers UI options for common use-cases like chat, summarization, and transcription. It can be deployed and run locally via UDS and Kubernetes, built out using Zarf packages. LeapfrogAI is supported by a community of users and contributors, including Defense Unicorns, Beast Code, Chainguard, Exovera, Hypergiant, Pulze, SOSi, United States Navy, United States Air Force, and United States Space Force.

llava-docker
This Docker image for LLaVA (Large Language and Vision Assistant) provides a convenient way to run LLaVA locally or on RunPod. LLaVA is a powerful AI tool that combines natural language processing and computer vision capabilities. With this Docker image, you can easily access LLaVA's functionalities for various tasks, including image captioning, visual question answering, text summarization, and more. The image comes pre-installed with LLaVA v1.2.0, Torch 2.1.2, xformers 0.0.23.post1, and other necessary dependencies. You can customize the model used by setting the MODEL environment variable. The image also includes a Jupyter Lab environment for interactive development and exploration. Overall, this Docker image offers a comprehensive and user-friendly platform for leveraging LLaVA's capabilities.

carrot
The 'carrot' repository on GitHub provides a list of free and user-friendly ChatGPT mirror sites for easy access. The repository includes sponsored sites offering various GPT models and services. Users can find and share sites, report errors, and access stable and recommended sites for ChatGPT usage. The repository also includes a detailed list of ChatGPT sites, their features, and accessibility options, making it a valuable resource for ChatGPT users seeking free and unlimited GPT services.

TrustLLM
TrustLLM is a comprehensive study of trustworthiness in LLMs, including principles for different dimensions of trustworthiness, established benchmark, evaluation, and analysis of trustworthiness for mainstream LLMs, and discussion of open challenges and future directions. Specifically, we first propose a set of principles for trustworthy LLMs that span eight different dimensions. Based on these principles, we further establish a benchmark across six dimensions including truthfulness, safety, fairness, robustness, privacy, and machine ethics. We then present a study evaluating 16 mainstream LLMs in TrustLLM, consisting of over 30 datasets. The document explains how to use the trustllm python package to help you assess the performance of your LLM in trustworthiness more quickly. For more details about TrustLLM, please refer to project website.

AI-YinMei
AI-YinMei is an AI virtual anchor Vtuber development tool (N card version). It supports fastgpt knowledge base chat dialogue, a complete set of solutions for LLM large language models: [fastgpt] + [one-api] + [Xinference], supports docking bilibili live broadcast barrage reply and entering live broadcast welcome speech, supports Microsoft edge-tts speech synthesis, supports Bert-VITS2 speech synthesis, supports GPT-SoVITS speech synthesis, supports expression control Vtuber Studio, supports painting stable-diffusion-webui output OBS live broadcast room, supports painting picture pornography public-NSFW-y-distinguish, supports search and image search service duckduckgo (requires magic Internet access), supports image search service Baidu image search (no magic Internet access), supports AI reply chat box [html plug-in], supports AI singing Auto-Convert-Music, supports playlist [html plug-in], supports dancing function, supports expression video playback, supports head touching action, supports gift smashing action, supports singing automatic start dancing function, chat and singing automatic cycle swing action, supports multi scene switching, background music switching, day and night automatic switching scene, supports open singing and painting, let AI automatically judge the content.