
Vision-Agents
Open Vision Agents by Stream. Build Vision Agents quickly with any model or video provider. Uses Stream's edge network for ultra-low latency.
Stars: 5540
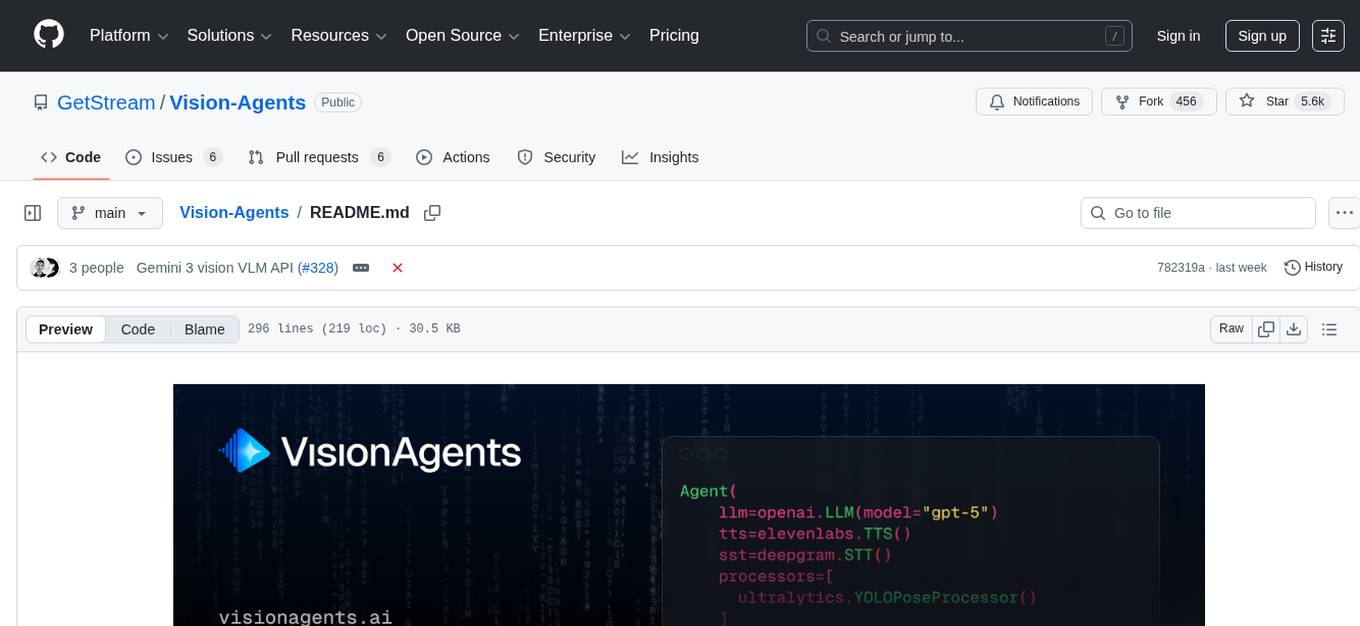
Vision Agents is an open-source project by Stream that provides building blocks for creating intelligent, low-latency video experiences powered by custom models and infrastructure. It offers multi-modal AI agents that watch, listen, and understand video in real-time. The project includes SDKs for various platforms and integrates with popular AI services like Gemini and OpenAI. Vision Agents can be used for tasks such as sports coaching, security camera systems with package theft detection, and building invisible assistants for various applications. The project aims to simplify the development of real-time vision AI applications by providing a range of processors, integrations, and out-of-the-box features.
README:

![]()



https://github.com/user-attachments/assets/d9778ab9-938d-4101-8605-ff879c29b0e4
Vision Agents give you the building blocks to create intelligent, low-latency video experiences powered by your models, your infrastructure, and your use cases.
- Video AI: Built for real-time video AI. Combine YOLO, Roboflow, and others with Gemini/OpenAI in real-time.
- Low Latency: Join quickly (500ms) and maintain audio/video latency under 30ms using Stream's edge network.
- Open: Built by Stream, but works with any video edge network.
-
Native APIs: Native SDK methods from OpenAI (
create response), Gemini (generate), and Claude (create message) — always access the latest LLM capabilities. - SDKs: SDKs for React, Android, iOS, Flutter, React Native, and Unity, powered by Stream's ultra-low-latency network.
https://github.com/user-attachments/assets/d66587ea-7af4-40c4-9966-5c04fbcf467c
https://github.com/user-attachments/assets/d1258ac2-ca98-4019-80e4-41ec5530117e
This example shows you how to build golf coaching AI with YOLO and Gemini Live. Combining a fast object detection model (like YOLO) with a full realtime AI is useful for many different video AI use cases. For example: Drone fire detection, sports/video game coaching, physical therapy, workout coaching, just dance style games etc.
# partial example, full example: examples/02_golf_coach_example/golf_coach_example.py
agent = Agent(
edge=getstream.Edge(),
agent_user=agent_user,
instructions="Read @golf_coach.md",
llm=gemini.Realtime(fps=10),
# llm=openai.Realtime(fps=1), # Careful with FPS can get expensive
processors=[ultralytics.YOLOPoseProcessor(model_path="yolo11n-pose.pt", device="cuda")],
)https://github.com/user-attachments/assets/92a2cdd8-909c-46d8-aab7-039a90efc186
This example shows a security camera system that detects faces, tracks packages and detects when a package is stolen. It automatically generates "WANTED" posters, posting them to X in real-time.
It combines face recognition, YOLOv11 object detection, Nano Banana and Gemini for a complete security workflow with voice interaction.
# partial example, full example: examples/04_security_camera_example/security_camera_example.py
security_processor = SecurityCameraProcessor(
fps=5,
model_path="weights_custom.pt", # YOLOv11 for package detection
package_conf_threshold=0.7,
)
agent = Agent(
edge=getstream.Edge(),
agent_user=User(name="Security AI", id="agent"),
instructions="Read @instructions.md",
processors=[security_processor],
llm=gemini.LLM("gemini-2.5-flash-lite"),
tts=elevenlabs.TTS(),
stt=deepgram.STT(),
)Apps like Cluely offer realtime coaching via an invisible overlay. This example shows you how you can build your own invisible assistant. It combines Gemini realtime (to watch your screen and audio), and doesn't broadcast audio (only text). This approach is quite versatile and can be used for: Sales coaching, job interview cheating, physical world/ on the job coaching with glasses
Demo video
agent = Agent(
edge=StreamEdge(), # low latency edge. clients for React, iOS, Android, RN, Flutter etc.
agent_user=agent_user, # the user object for the agent (name, image etc)
instructions="You are silently helping the user pass this interview. See @interview_coach.md",
# gemini realtime, no need to set tts, or sst (though that's also supported)
llm=gemini.Realtime()
)Step 1: Install via uv
uv add vision-agents
Step 2: (Optional) Install with extra integrations
uv add "vision-agents[getstream, openai, elevenlabs, deepgram]"
Step 3: Obtain your Stream API credentials
Get a free API key from Stream. Developers receive 333,000 participant minutes per month, plus extra credits via the Maker Program.
| Feature | Description |
|---|---|
| True real-time via WebRTC | Stream directly to model providers that support it for instant visual understanding. |
| Interval/processor pipeline | For providers without WebRTC, process frames with pluggable video processors (e.g., YOLO, Roboflow, or custom PyTorch/ONNX) before/after model calls. |
| Turn detection & diarization | Keep conversations natural; know when the agent should speak or stay quiet and who's talking. |
| Voice activity detection (VAD) | Trigger actions intelligently and use resources efficiently. |
| Speech↔Text↔Speech | Enable low-latency loops for smooth, conversational voice UX. |
| Tool/function calling | Execute arbitrary code and APIs mid-conversation. Create Linear issues, query weather, trigger telephony, or hit internal services. |
| Built-in memory via Stream Chat | Agents recall context naturally across turns and sessions. |
| Text back-channel | Message the agent silently during a call. |
| Phone and RAG | Interact with the Agent via inbound or outbound phone calls using Twilio and Turbopuffer |
| Plugin Name | Description | Docs Link |
|---|---|---|
| AWS Bedrock | Realtime speech-to-speech plugin using Amazon Nova models with automatic reconnection | AWS |
| AWS Polly | TTS plugin using Amazon's cloud-based service with natural-sounding voices and neural engine support | AWS Polly |
| Cartesia | TTS plugin for realistic voice synthesis in real-time voice applications | Cartesia |
| Decart | Real-time AI video transformation service for applying artistic styles and effects to video streams | Decart |
| Deepgram | STT plugin for fast, accurate real-time transcription with speaker diarization | Deepgram |
| ElevenLabs | TTS plugin with highly realistic and expressive voices for conversational agents | ElevenLabs |
| Fast-Whisper | High-performance STT plugin using OpenAI's Whisper model with CTranslate2 for fast inference | Fast-Whisper |
| Fish Audio | STT and TTS plugin with automatic language detection and voice cloning capabilities | Fish Audio |
| Gemini | Realtime API for building conversational agents with support for both voice and video. Plugin supports LLMs, Gemini Live, and a VLM interface for Gemini 3 Flash. | Gemini |
| HeyGen | Realtime interactive avatars powered by HeyGen | HeyGen |
| Hugging Face | LLM plugin providing access to many open-source language models hosted on the Hugging Face Hub and powered by external providers (Cerebras, Together, Groq, etc.) | Hugging Face |
| Inworld | TTS plugin with high-quality streaming voices for real-time conversational AI agents | Inworld |
| Kokoro | Local TTS engine for offline voice synthesis with low latency | Kokoro |
| Mistral Voxtral | Mistral Voxtral is a real-time transcription tool with speaker diarization. | Mistral Voxtral |
| Moondream | Moondream provides realtime detection and VLM capabilities. Developers can choose from using the hosted API or running locally on their CUDA devices. Vision Agents supports Moondream's Detect, Caption and VQA skills out-of-the-box. | Moondream |
| NVIDIA Cosmos 2 | VLM plugin using NVIDIA's Cosmos 2 models for video understanding with automatic frame buffering and streaming responses | NVIDIA |
| OpenAI | Realtime API for building conversational agents with out of the box support for real-time video directly over WebRTC, LLMs and Open AI TTS | OpenAI |
| OpenRouter | LLM plugin providing access to multiple providers (Anthropic, Google, OpenAI) through a unified API | OpenRouter |
| Qwen | Realtime audio plugin using Alibaba's Qwen3 with native audio output and built-in speech recognition | Qwen |
| Roboflow | Object detection processor using Roboflow's hosted API or local RF-DETR models | Roboflow |
| Smart Turn | Advanced turn detection system combining Silero VAD, Whisper, and neural models for natural conversation flow | Smart Turn |
| TurboPuffer | RAG plugin using TurboPuffer for hybrid search (vector + BM25) with Gemini embeddings for retrieval augmented generation | TurboPuffer |
| Twilio | Voice call integration plugin enabling bidirectional audio streaming via Twilio Media Streams with call registry and audio conversion | Twilio |
| Ultralytics | Real-time pose detection processor using YOLO models with skeleton overlays | Ultralytics |
| Vogent | Neural turn detection system for intelligent turn-taking in voice conversations | Vogent |
| Wizper | STT plugin with real-time translation capabilities powered by Whisper v3 | Wizper |
| xAI | LLM plugin using xAI's Grok models with advanced reasoning and real-time knowledge | xAI |
Processors let your agent manage state and handle audio/video in real-time.
They take care of the hard stuff, like:
- Running smaller models
- Making API calls
- Transforming media
… so you can focus on your agent logic.
Check out our getting started guide at VisionAgents.ai.
- Quickstart: Building a Voice AI app
- Quickstart: Building a Video AI app
- Tutorial: Building a real-time meeting assistant
- Tutorial: Building real-time sports coaching
| 🔮 Demo Applications | |
|---|---|
|
Using Cartesia's Sonic 3 model to visually look at what's in the frame and tell a story with emotion. • Real-time visual understanding • Emotional storytelling • Frame-by-frame analysis >Source Code and tutorial |
 |
|
Realtime stable diffusion using Vision Agents and Decart's Mirage 2 model to create interactive scenes and stories. • Real-time video restyling • Interactive scene generation • Stable diffusion integration >Source Code and tutorial |
 |
|
Using Gemini Live together with Vision Agents and Ultralytics YOLO, we're able to track the user's pose and provide realtime actionable feedback on their golf game. • Real-time pose tracking • Actionable coaching feedback • YOLO pose detection • Gemini Live integration >Source Code and tutorial |
 |
|
Together with OpenAI Realtime and Vision Agents, we can take GeoGuesser to the next level by asking it to identify places in our real world surroundings. • Real-world location identification • OpenAI Realtime integration • Visual scene understanding >Source Code and tutorial |
 |
|
Interact with your Agent over the phone using Twilio. This example demonstrates how to use TurboPuffer for Retrieval Augmented Generation (RAG) to give your agent specialized knowledge. • Inbound/Outbound telephony • Twilio Media Streams integration • Vector search with TurboPuffer • Retrieval Augmented Generation >Source Code and tutorial |
 |
|
A security camera with face recognition, package detection and automated theft response. Generates WANTED posters with Nano Banana and posts them to X when packages disappear. • Face detection & named recognition • YOLOv11 package detection • Automated WANTED poster generation • Real-time X posting >Source Code and tutorial |
 |
See DEVELOPMENT.md
Want to add your platform or provider? Reach out to [email protected].
Our favorite people & projects to follow for vision AI
|
@demishassabis CEO @ Google DeepMind Won a Nobel prize |
@OfficialLoganK Product Lead @ Gemini Posts about robotics vision |
@ultralytics Various fast vision AI models Pose, detect, segment, classify |
|
@skalskip92 Open Source Lead @ Roboflow Building tools for vision AI |
@moondreamai The tiny vision model that could Lightweight, fast, efficient |
@kwindla Pipecat / Daily Sharing AI and vision insights |
|
@juberti Head of Realtime AI @ OpenAI Realtime AI systems |
@romainhuet Head of DX @ OpenAI Developer tooling & APIs |
@thorwebdev Eleven Labs Voice and AI experiments |
 |
||
|---|---|---|
|
@mervenoyann Hugging Face Posts extensively about Video AI |
@stash_pomichter Spatial memory for robots Robotics & AI navigation |
@Mentraglass Open-source smart glasses Open-Source, hackable AR glasses with AI capabilities built in |
 |
|---|
|
@vikhyatk AI Engineer Open-source AI projects, Creator of Moondream AI |
- Livekit Agents: Great syntax, Livekit only
- Pipecat: Flexible, but more verbose.
- OpenAI Agents: Focused on openAI only
- Working TTS, Gemini & OpenAI
- Simplified the library & improved code quality
- Deepgram Nova 3, Elevenlabs Scribe 2, Fish, Moondream, QWen3, Smart turn, Vogent, Inworld, Heygen, AWS and more
- Improved openAI & Gemini realtime performance
- Audio & Video utilities
- Production-grade HTTP API for agent deployment (
uv run <agent.py> serve) - Metrics & Observability stack
- Phone/voice integration with RAG capabilities
- 10 new LLM plugins (AWS Nova 2, Qwen 3 Realtime, NVIDIA Cosmos 2, Pocket TTS, Deepgram TTS, OpenRouter, HuggingFace Inference, Roboflow, Twilio, Turbopuffer)
- Real-world examples (security camera, phone integration, football commentator, Docker deployment with GPU support, agent server)
- Stability: Fixes for participant sync, video frame handling, agent lifecycle, and screen sharing
- Excellence on documentation/polish
- Better Roboflow annotation docs
- Automated workflows for maintenance
- Local camera/audio support AND/OR WebRTC connection
- Embedded/robotics examples
Video AI is the frontier of AI. The state of the art is changing daily to help models understand live video. While building the integrations, here are the limitations we've noticed (Dec 2025)
- Video AI struggles with small text. If you want the AI to read the score in a game it will often get it wrong and hallucinate
- Longer videos can cause the AI to lose context. For instance if it's watching a soccer match it will get confused after 30 seconds
- Most applications require a combination of small specialized models like Yolo/Roboflow/Moondream, API calls to get more context and larger models like gemini/openAI
- Image size & FPS need to stay relatively low due to performance constraints
- Video doesn’t trigger responses in realtime models. You always need to send audio/text to trigger a response.
Join the team behind this project - we’re hiring a Staff Python Engineer to architect, build, and maintain a powerful toolkit for developers integrating voice and video AI into their products.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for Vision-Agents
Similar Open Source Tools
Vision-Agents
Vision Agents is an open-source project by Stream that provides building blocks for creating intelligent, low-latency video experiences powered by custom models and infrastructure. It offers multi-modal AI agents that watch, listen, and understand video in real-time. The project includes SDKs for various platforms and integrates with popular AI services like Gemini and OpenAI. Vision Agents can be used for tasks such as sports coaching, security camera systems with package theft detection, and building invisible assistants for various applications. The project aims to simplify the development of real-time vision AI applications by providing a range of processors, integrations, and out-of-the-box features.

mage-ai
Mage is an open-source data pipeline tool for transforming and integrating data. It offers an easy developer experience, engineering best practices built-in, and data as a first-class citizen. Mage makes it easy to build, preview, and launch data pipelines, and provides observability and scaling capabilities. It supports data integrations, streaming pipelines, and dbt integration.
rai
RAI is a framework designed to bring general multi-agent system capabilities to robots, enhancing human interactivity, flexibility in problem-solving, and out-of-the-box AI features. It supports multi-modalities, incorporates an advanced database for agent memory, provides ROS 2-oriented tooling, and offers a comprehensive task/mission orchestrator. The framework includes features such as voice interaction, customizable robot identity, camera sensor access, reasoning through ROS logs, and integration with LangChain for AI tools. RAI aims to support various AI vendors, improve human-robot interaction, provide an SDK for developers, and offer a user interface for configuration.

beeai-framework
BeeAI Framework is a versatile tool for building production-ready multi-agent systems. It offers flexibility in orchestrating agents, seamless integration with various models and tools, and production-grade controls for scaling. The framework supports Python and TypeScript libraries, enabling users to implement simple to complex multi-agent patterns, connect with AI services, and optimize token usage and resource management.

EvoAgentX
EvoAgentX is an open-source framework for building, evaluating, and evolving LLM-based agents or agentic workflows in an automated, modular, and goal-driven manner. It enables developers and researchers to move beyond static prompt chaining or manual workflow orchestration by introducing a self-evolving agent ecosystem. The framework includes features such as agent workflow autoconstruction, built-in evaluation, self-evolution engine, plug-and-play compatibility, comprehensive built-in tools, memory module support, and human-in-the-loop interactions.

camel
CAMEL is an open-source library designed for the study of autonomous and communicative agents. We believe that studying these agents on a large scale offers valuable insights into their behaviors, capabilities, and potential risks. To facilitate research in this field, we implement and support various types of agents, tasks, prompts, models, and simulated environments.
dinopal
DinoPal is an AI voice assistant residing in the Mac menu bar, offering real-time voice and video chat, screen sharing, online search, and multilingual support. It provides various AI assistants with unique strengths and characteristics to meet different conversational needs. Users can easily install DinoPal and access different communication modes, with a call time limit of 30 minutes. User feedback can be shared in the Discord community. DinoPal is powered by Google Gemini & Pipecat.

nuitrack-sdk
Nuitrack™ is an ultimate 3D body tracking solution developed by 3DiVi Inc. It enables body motion analytics applications for virtually any widespread depth sensors and hardware platforms, supporting a wide range of applications from real-time gesture recognition on embedded platforms to large-scale multisensor analytical systems. Nuitrack provides highly-sophisticated 3D skeletal tracking, basic facial analysis, hand tracking, and gesture recognition APIs for UI control. It offers two skeletal tracking engines: classical for embedded hardware and AI for complex poses, providing a human-centric spatial understanding tool for natural and intelligent user engagement.
parallax
Parallax is a fully decentralized inference engine developed by Gradient. It allows users to build their own AI cluster for model inference across distributed nodes with varying configurations and physical locations. Core features include hosting local LLM on personal devices, cross-platform support, pipeline parallel model sharding, paged KV cache management, continuous batching for Mac, dynamic request scheduling, and routing for high performance. The backend architecture includes P2P communication powered by Lattica, GPU backend powered by SGLang and vLLM, and MAC backend powered by MLX LM.

MiniCPM-V-CookBook
MiniCPM-V & o Cookbook is a comprehensive repository for building multimodal AI applications effortlessly. It provides easy-to-use documentation, supports a wide range of users, and offers versatile deployment scenarios. The repository includes live demonstrations, inference recipes for vision and audio capabilities, fine-tuning recipes, serving recipes, quantization recipes, and a framework support matrix. Users can customize models, deploy them efficiently, and compress models to improve efficiency. The repository also showcases awesome works using MiniCPM-V & o and encourages community contributions.
agents-towards-production
Agents Towards Production is an open-source playbook for building production-ready GenAI agents that scale from prototype to enterprise. Tutorials cover stateful workflows, vector memory, real-time web search APIs, Docker deployment, FastAPI endpoints, security guardrails, GPU scaling, browser automation, fine-tuning, multi-agent coordination, observability, evaluation, and UI development.

MNN
MNN is a highly efficient and lightweight deep learning framework that supports inference and training of deep learning models. It has industry-leading performance for on-device inference and training. MNN has been integrated into various Alibaba Inc. apps and is used in scenarios like live broadcast, short video capture, search recommendation, and product searching by image. It is also utilized on embedded devices such as IoT. MNN-LLM and MNN-Diffusion are specific runtime solutions developed based on the MNN engine for deploying language models and diffusion models locally on different platforms. The framework is optimized for devices, supports various neural networks, and offers high performance with optimized assembly code and GPU support. MNN is versatile, easy to use, and supports hybrid computing on multiple devices.

NSMusicS
NSMusicS is a local music software that is expected to support multiple platforms with AI capabilities and multimodal features. The goal of NSMusicS is to integrate various functions (such as artificial intelligence, streaming, music library management, cross platform, etc.), which can be understood as similar to Navidrome but with more features than Navidrome. It wants to become a plugin integrated application that can almost have all music functions.
SimAI
SimAI is the industry's first full-stack, high-precision simulator for AI large-scale training. It provides detailed modeling and simulation of the entire LLM training process, encompassing framework, collective communication, network layers, and more. This comprehensive approach offers end-to-end performance data, enabling researchers to analyze training process details, evaluate time consumption of AI tasks under specific conditions, and assess performance gains from various algorithmic optimizations.

auto-news
Auto-News is an automatic news aggregator tool that utilizes Large Language Models (LLM) to pull information from various sources such as Tweets, RSS feeds, YouTube videos, web articles, Reddit, and journal notes. The tool aims to help users efficiently read and filter content based on personal interests, providing a unified reading experience and organizing information effectively. It features feed aggregation with summarization, transcript generation for videos and articles, noise reduction, task organization, and deep dive topic exploration. The tool supports multiple LLM backends, offers weekly top-k aggregations, and can be deployed on Linux/MacOS using docker-compose or Kubernetes.
generative-ai-with-javascript
The 'Generative AI with JavaScript' repository is a comprehensive resource hub for JavaScript developers interested in delving into the world of Generative AI. It provides code samples, tutorials, and resources from a video series, offering best practices and tips to enhance AI skills. The repository covers the basics of generative AI, guides on building AI applications using JavaScript, from local development to deployment on Azure, and scaling AI models. It is a living repository with continuous updates, making it a valuable resource for both beginners and experienced developers looking to explore AI with JavaScript.
For similar tasks
human
AI-powered 3D Face Detection & Rotation Tracking, Face Description & Recognition, Body Pose Tracking, 3D Hand & Finger Tracking, Iris Analysis, Age & Gender & Emotion Prediction, Gaze Tracking, Gesture Recognition, Body Segmentation

MiniAI-Face-Recognition-LivenessDetection-WindowsSDK
This repository contains a C++ application that demonstrates face recognition capabilities using computer vision techniques. The demo utilizes OpenCV and dlib libraries for efficient face detection and recognition with 3D passive face liveness detection (face anti-spoofing). Key Features: Face detection: The SDK utilizes advanced computer vision techniques to detect faces in images or video frames, enabling a wide range of applications. Face recognition: It can recognize known faces by comparing them with a pre-defined database of individuals. Age estimation: It can estimate the age of detected faces. Gender detection: It can determine the gender of detected faces. Liveness detection: It can detect whether a face is from a live person or a static image.
face-api
FaceAPI is an AI-powered tool for face detection, rotation tracking, face description, recognition, age, gender, and emotion prediction. It can be used in both browser and NodeJS environments using TensorFlow/JS. The tool provides live demos for processing images and webcam feeds, along with NodeJS examples for various tasks such as face similarity comparison and multiprocessing. FaceAPI offers different pre-built versions for client-side browser execution and server-side NodeJS execution, with or without TFJS pre-bundled. It is compatible with TFJS 2.0+ and TFJS 3.0+.
MiKaPo
MiKaPo is a web-based tool that allows users to pose MMD models in real-time using video input. It utilizes technologies such as Mediapipe for 3D key points detection, Babylon.js for 3D scene rendering, babylon-mmd for MMD model viewing, and Vite+React for the web framework. Users can upload videos and images, select different environments, and choose models for posing. MiKaPo also supports camera input and Ollama (electron version). The tool is open to feature requests and pull requests, with ongoing development to add VMD export functionality.
DeepSparkHub
DeepSparkHub is a repository that curates hundreds of application algorithms and models covering various fields in AI and general computing. It supports mainstream intelligent computing scenarios in markets such as smart cities, digital individuals, healthcare, education, communication, energy, and more. The repository provides a wide range of models for tasks such as computer vision, face detection, face recognition, instance segmentation, image generation, knowledge distillation, network pruning, object detection, 3D object detection, OCR, pose estimation, self-supervised learning, semantic segmentation, super resolution, tracking, traffic forecast, GNN, HPC, methodology, multimodal, NLP, recommendation, reinforcement learning, speech recognition, speech synthesis, and 3D reconstruction.
FaceAiSharp
FaceAiSharp is a .NET library designed for face-related computer vision tasks. It offers functionalities such as face detection, face recognition, facial landmarks detection, and eye state detection. The library utilizes pretrained ONNX models for accurate and efficient results, enabling users to integrate these capabilities into their .NET applications easily. With a focus on simplicity and performance, FaceAiSharp provides a local processing solution without relying on cloud services, supporting image-based face processing using ImageSharp. It is cross-platform compatible, supporting Windows, Linux, Android, and more.
Symposium2023
Symposium2023 is a project aimed at enabling Delphi users to incorporate AI technology into their applications. It provides generalized interfaces to different AI models, making them easily accessible. The project showcases AI's versatility in tasks like language translation, human-like conversations, image generation, data analysis, and more. Users can experiment with different AI models, change providers easily, and avoid vendor lock-in. The project supports various AI features like vision support and function calling, utilizing providers like Google, Microsoft Azure, Amazon, OpenAI, and more. It includes example programs demonstrating tasks such as text-to-speech, language translation, face detection, weather querying, audio transcription, voice recognition, image generation, invoice processing, and API testing. The project also hints at potential future research areas like using embeddings for data search and integrating Python AI libraries with Delphi.
FaceAISDK_Android
FaceAI SDK is an on-device offline face detection, recognition, liveness detection, anti-spoofing, and 1:N/M:N face search SDK. It enables quick integration to achieve on-device face recognition, face search, and other functions. The SDK performs all functions offline on the device without the need for internet connection, ensuring privacy and security. It supports various actions for liveness detection, custom camera management, and clear imaging even in challenging lighting conditions.
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.