
FaceAISDK_Android
离线版设备端人脸识别 动作活体、静默活体、近红外双目活体检测 以及1:N M:N 人脸搜索算法SDK 封装;全程可开飞行模式不用联网 🧒 on_device Face Recognition 、 Liveness detection and 1:N & M:N Face Search SDK
Stars: 875
FaceAI SDK is an on-device offline face detection, recognition, liveness detection, anti-spoofing, and 1:N/M:N face search SDK. It enables quick integration to achieve on-device face recognition, face search, and other functions. The SDK performs all functions offline on the device without the need for internet connection, ensuring privacy and security. It supports various actions for liveness detection, custom camera management, and clear imaging even in challenging lighting conditions.
README:
FaceAI SDK is on_device Offline Face Detection 、Recognition 、Liveness Detection Anti Spoofing and 1:N/M:N Face Search SDK FaceAI SDK包括人脸识别、活体检测、人脸录入检测以及1:N以及M:N 人脸搜索,可快速集成实现端侧人脸识别,人脸搜索等功能。
Android SDK可支持Android[5,15] 所有功能都在设备终端离线执行,SDK本身不用联网,不保存不上传任何人脸信息敏感资料更具隐私安全 动作活体支持张嘴、微笑、眨眼、摇头、点头 随机两种组合验证(支持去除特定的动作),支持系统摄像头和UVC协议双目摄像头,宽动态值大于105Db成像清晰抗逆光。 开发人员也可以自定义摄像头管理,把帧数据送入到SDK。

其他平台
iOS SDK: https://github.com/FaceAISDK/FaceAISDK_iOS
Android: https://github.com/FaceAISDK/FaceAISDK_Android
其他实现
uni-App X: https://github.com/FaceAISDK/FaceAISDK_uniapp_UTS
React native https://github.com/zkteco-home/react-native-face-ai
- 添加光线明暗判断
- 更名MotionLivenessType 为 FaceLivenessType
- 添加相机等级判断和提示
- Demo中去除32位CPU配置减低APK 体积
- 人脸录入时优化人脸角度校验,并分4种等级
更多历史版本说明参考 历史版本SDK更新记录
【1:1】 移动考勤签到、App免密登录、刷脸授权、刷脸解锁、巡更打卡真人校验
【1:N】 小区门禁、公司门禁、智能门锁、智慧校园、机器人、智能家居、社区、酒店等
【M:N】 公安布控、人群追踪 监控等 (测试效果可使用images/MN_face_search_test.jpg 模拟)
先在「GitHub网站」下载最新接入SDK 接入代码导入到Android Studio。
Demo聚焦SDK的核心功能演示,细节并不完善,需要你根据你的业务需求自行完善。
- 去蒲公英下载APK Demo体验各种功能,查验是否满足业务需求;人脸搜索可以一键导入App内置人脸图也可录入你自己的
- 更新GitHub 最新的代码,花1天左右时间熟悉SDK API 和对应的注释备注,断点调试一下基本功能;熟悉后再接入到主工程
- 欲速则不达,一定要先跑成功SDK接入指引Demo。熟悉后再接入到主工程验证匹配业务功能;有问题可以GitHub 提issues
人脸识别已经验证过高中低配置设备,1万人脸搜索速度表现在几款设备统计如下,建议分库搜索以减少误差率:
| 设备型号 | 启动初始化速度 | 搜索速度(毫秒) |
|---|---|---|
| 小米 13 | 79 ms | 66 ms |
| RK3568-SM5 | 686 ms | 520 ms |
| 华为 P8 | 798 ms | 678 ms |
| 联想Pad2024 | 245 ms | 197 ms |
其中硬件配置要求参考:硬件配置要求
更多说明:https://mp.weixin.qq.com/s/G2dvFQraw-TAzDRFIgdobA
工程目录结构简要介绍
| 模块 | 描述 |
|---|---|
| Demo | Demo主工程,implementation project(':faceAILib') |
| faceAILib | 子Module,FaceAISDK 所有功能都在module 中演示 |
| /verify/* | 1:1 人脸检测识别,活体检测页面,静态人脸对比 |
| /search/* | 1:N 人脸搜索识别,人脸库增删改管理等财政 |
| /addFaceImage | 人脸识别和搜索共用的添加人脸照片录入模块 |
| /UVCCamera/* | UVC协议双目红外摄像头人脸识别,人脸搜索,一般是自自定义的硬件 |
| /SysCamera/* | 手机,平板自带的系统相机,一般系统摄像头打开就能看效果 |
-
1.调整JDK版本到java 17。AS设置Preferences -> Build -> Gradle -> JDK的版本为 17
-
2.最好翻墙科学上网同步AGP Gradle 插件7.4.2(或者更新AGP),然后同步其他依赖
-
3.Demo工程成功运行后,根据你的业务需求重点熟悉对应模块后再集成到你的主工程
-
4.集成到你的主工程,首先Gradle 中引入依赖 implementation 'io.github.FaceAISDK:Android:版本号' //及时升级到github最新版
-
5.解决项目工程中的第三方依赖库和主工程的冲突比如CameraX的版本等,Target SDK不同导致的冲突
目前SDK开发使用**java17. kotlin 1.9.22,AGP 7.x **打包,如果你的项目较老还在使用 kapt, kotlin-android-extensions导致集成冲突,建议尽快升级项目或者VIP联系定制
更多历史版本查看这里: https://www.pgyer.com/faceVerify
都看到这了,顺手帮忙点个🌟Star吧
外包FaceAISDK之UTS插件(uni-app兼容模式组件)开发
🪐

For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for FaceAISDK_Android
Similar Open Source Tools
FaceAISDK_Android
FaceAI SDK is an on-device offline face detection, recognition, liveness detection, anti-spoofing, and 1:N/M:N face search SDK. It enables quick integration to achieve on-device face recognition, face search, and other functions. The SDK performs all functions offline on the device without the need for internet connection, ensuring privacy and security. It supports various actions for liveness detection, custom camera management, and clear imaging even in challenging lighting conditions.
AI0x0.com
AI 0x0 is a versatile AI query generation desktop floating assistant application that supports MacOS and Windows. It allows users to utilize AI capabilities in any desktop software to query and generate text, images, audio, and video data, helping them work more efficiently. The application features a dynamic desktop floating ball, floating dialogue bubbles, customizable presets, conversation bookmarking, preset packages, network acceleration, query mode, input mode, mouse navigation, deep customization of ChatGPT Next Web, support for full-format libraries, online search, voice broadcasting, voice recognition, voice assistant, application plugins, multi-model support, online text and image generation, image recognition, frosted glass interface, light and dark theme adaptation for each language model, and free access to all language models except Chat0x0 with a key.

Open-dLLM
Open-dLLM is the most open release of a diffusion-based large language model, providing pretraining, evaluation, inference, and checkpoints. It introduces Open-dCoder, the code-generation variant of Open-dLLM. The repo offers a complete stack for diffusion LLMs, enabling users to go from raw data to training, checkpoints, evaluation, and inference in one place. It includes pretraining pipeline with open datasets, inference scripts for easy sampling and generation, evaluation suite with various metrics, weights and checkpoints on Hugging Face, and transparent configs for full reproducibility.
HMusic
HMusic is an intelligent music player that supports Xiaomi AI speakers. It offers dual modes: xiaomusic server mode and Xiaomi IoT direct connection mode. Users can choose between these modes based on their preferences and needs. The direct connection mode is suitable for regular users who want a plug-and-play experience, while the xiaomusic mode is ideal for users with NAS/servers who require advanced features like a local music library, playlists, and progress control. The tool provides functionalities such as music search, playback, and volume control, catering to a wide range of music enthusiasts.
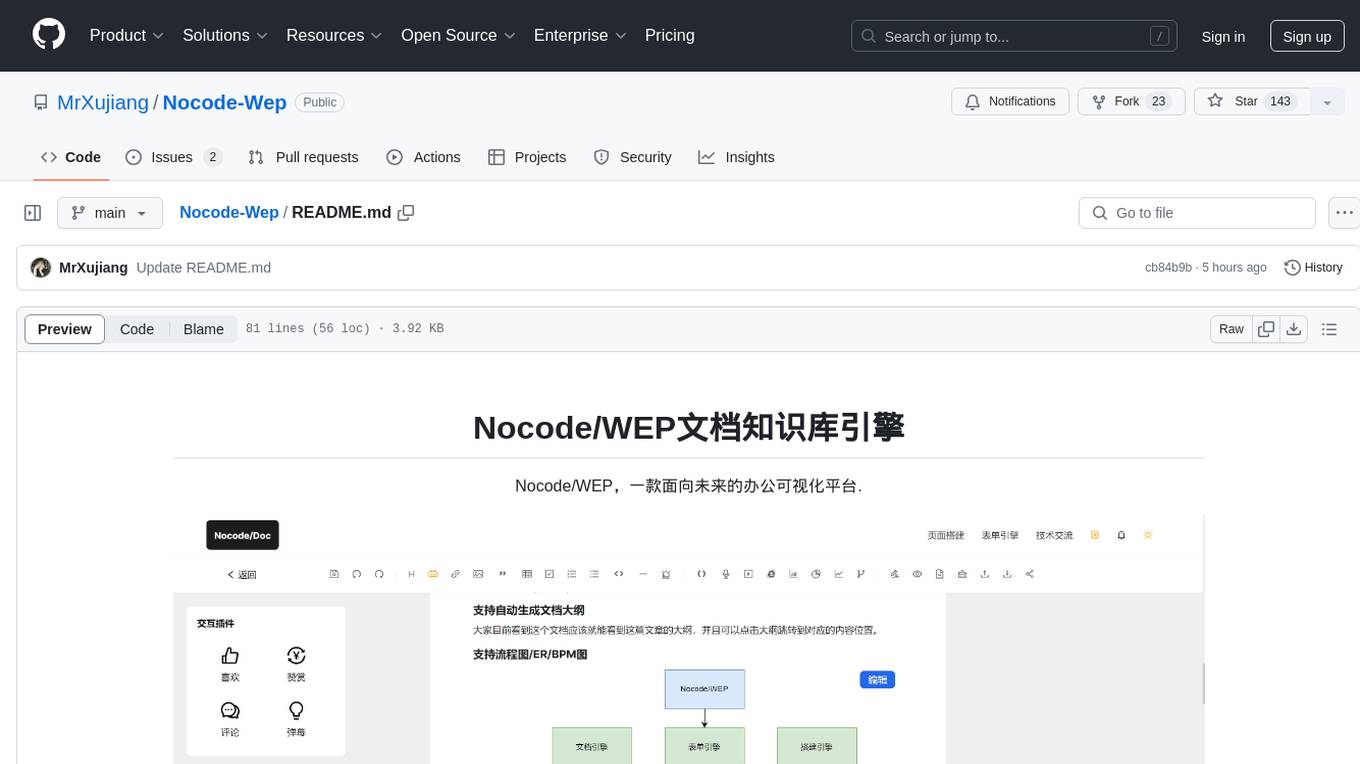
Nocode-Wep
Nocode/WEP is a forward-looking office visualization platform that includes modules for document building, web application creation, presentation design, and AI capabilities for office scenarios. It supports features such as configuring bullet comments, global article comments, multimedia content, custom drawing boards, flowchart editor, form designer, keyword annotations, article statistics, custom appreciation settings, JSON import/export, content block copying, and unlimited hierarchical directories. The platform is compatible with major browsers and aims to deliver content value, iterate products, share technology, and promote open-source collaboration.
END-TO-END-GENERATIVE-AI-PROJECTS
The 'END TO END GENERATIVE AI PROJECTS' repository is a collection of awesome industry projects utilizing Large Language Models (LLM) for various tasks such as chat applications with PDFs, image to speech generation, video transcribing and summarizing, resume tracking, text to SQL conversion, invoice extraction, medical chatbot, financial stock analysis, and more. The projects showcase the deployment of LLM models like Google Gemini Pro, HuggingFace Models, OpenAI GPT, and technologies such as Langchain, Streamlit, LLaMA2, LLaMAindex, and more. The repository aims to provide end-to-end solutions for different AI applications.
HaE
HaE is a framework project in the field of network security (data security) that combines artificial intelligence (AI) large models to achieve highlighting and information extraction of HTTP messages (including WebSocket). It aims to reduce testing time, focus on valuable and meaningful messages, and improve vulnerability discovery efficiency. The project provides a clear and visual interface design, simple interface interaction, and centralized data panel for querying and extracting information. It also features built-in color upgrade algorithm, one-click export/import of data, and integration of AI large models API for optimized data processing.

Native-LLM-for-Android
This repository provides a demonstration of running a native Large Language Model (LLM) on Android devices. It supports various models such as Qwen2.5-Instruct, MiniCPM-DPO/SFT, Yuan2.0, Gemma2-it, StableLM2-Chat/Zephyr, and Phi3.5-mini-instruct. The demo models are optimized for extreme execution speed after being converted from HuggingFace or ModelScope. Users can download the demo models from the provided drive link, place them in the assets folder, and follow specific instructions for decompression and model export. The repository also includes information on quantization methods and performance benchmarks for different models on various devices.
CTFCrackTools
CTFCrackTools X is the next generation of CTFCrackTools, featuring extreme performance and experience, extensible node-based architecture, and future-oriented technology stack. It offers a visual node-based workflow for encoding and decoding processes, with 43+ built-in algorithms covering common CTF needs like encoding, classical ciphers, modern encryption, hashing, and text processing. The tool is lightweight (< 15MB), high-performance, and cross-platform, supporting Windows, macOS, and Linux without the need for a runtime environment. It aims to provide a beginner-friendly tool for CTF enthusiasts to easily work on challenges and improve their skills.

DataFlow
DataFlow is a data preparation and training system designed to parse, generate, process, and evaluate high-quality data from noisy sources, improving the performance of large language models in specific domains. It constructs diverse operators and pipelines, validated to enhance domain-oriented LLM's performance in fields like healthcare, finance, and law. DataFlow also features an intelligent DataFlow-agent capable of dynamically assembling new pipelines by recombining existing operators on demand.
runanywhere-sdks
RunAnywhere is an on-device AI tool for mobile apps that allows users to run LLMs, speech-to-text, text-to-speech, and voice assistant features locally, ensuring privacy, offline functionality, and fast performance. The tool provides a range of AI capabilities without relying on cloud services, reducing latency and ensuring that no data leaves the device. RunAnywhere offers SDKs for Swift (iOS/macOS), Kotlin (Android), React Native, and Flutter, making it easy for developers to integrate AI features into their mobile applications. The tool supports various models for LLM, speech-to-text, and text-to-speech, with detailed documentation and installation instructions available for each platform.
ReGraph
ReGraph is a decentralized AI compute marketplace that connects hardware providers with developers who need inference and training resources. It democratizes access to AI computing power by creating a global network of distributed compute nodes. It is cost-effective, decentralized, easy to integrate, supports multiple models, and offers pay-as-you-go pricing.

MOSS-TTS
MOSS-TTS Family is an open-source speech and sound generation model family designed for high-fidelity, high-expressiveness, and complex real-world scenarios. It includes five production-ready models: MOSS-TTS, MOSS-TTSD, MOSS-VoiceGenerator, MOSS-TTS-Realtime, and MOSS-SoundEffect, each serving specific purposes in speech generation, dialogue, voice design, real-time interactions, and sound effect generation. The models offer features like long-speech generation, fine-grained control over phonemes and duration, multilingual synthesis, voice cloning, and real-time voice agents.
nndeploy
nndeploy is a tool that allows you to quickly build your visual AI workflow without the need for frontend technology. It provides ready-to-use algorithm nodes for non-AI programmers, including large language models, Stable Diffusion, object detection, image segmentation, etc. The workflow can be exported as a JSON configuration file, supporting Python/C++ API for direct loading and running, deployment on cloud servers, desktops, mobile devices, edge devices, and more. The framework includes mainstream high-performance inference engines and deep optimization strategies to help you transform your workflow into enterprise-level production applications.
ChuanhuChatGPT
Chuanhu Chat is a user-friendly web graphical interface that provides various additional features for ChatGPT and other language models. It supports GPT-4, file-based question answering, local deployment of language models, online search, agent assistant, and fine-tuning. The tool offers a range of functionalities including auto-solving questions, online searching with network support, knowledge base for quick reading, local deployment of language models, GPT 3.5 fine-tuning, and custom model integration. It also features system prompts for effective role-playing, basic conversation capabilities with options to regenerate or delete dialogues, conversation history management with auto-saving and search functionalities, and a visually appealing user experience with themes, dark mode, LaTeX rendering, and PWA application support.
For similar tasks
human
AI-powered 3D Face Detection & Rotation Tracking, Face Description & Recognition, Body Pose Tracking, 3D Hand & Finger Tracking, Iris Analysis, Age & Gender & Emotion Prediction, Gaze Tracking, Gesture Recognition, Body Segmentation

MiniAI-Face-Recognition-LivenessDetection-WindowsSDK
This repository contains a C++ application that demonstrates face recognition capabilities using computer vision techniques. The demo utilizes OpenCV and dlib libraries for efficient face detection and recognition with 3D passive face liveness detection (face anti-spoofing). Key Features: Face detection: The SDK utilizes advanced computer vision techniques to detect faces in images or video frames, enabling a wide range of applications. Face recognition: It can recognize known faces by comparing them with a pre-defined database of individuals. Age estimation: It can estimate the age of detected faces. Gender detection: It can determine the gender of detected faces. Liveness detection: It can detect whether a face is from a live person or a static image.
face-api
FaceAPI is an AI-powered tool for face detection, rotation tracking, face description, recognition, age, gender, and emotion prediction. It can be used in both browser and NodeJS environments using TensorFlow/JS. The tool provides live demos for processing images and webcam feeds, along with NodeJS examples for various tasks such as face similarity comparison and multiprocessing. FaceAPI offers different pre-built versions for client-side browser execution and server-side NodeJS execution, with or without TFJS pre-bundled. It is compatible with TFJS 2.0+ and TFJS 3.0+.
MiKaPo
MiKaPo is a web-based tool that allows users to pose MMD models in real-time using video input. It utilizes technologies such as Mediapipe for 3D key points detection, Babylon.js for 3D scene rendering, babylon-mmd for MMD model viewing, and Vite+React for the web framework. Users can upload videos and images, select different environments, and choose models for posing. MiKaPo also supports camera input and Ollama (electron version). The tool is open to feature requests and pull requests, with ongoing development to add VMD export functionality.
DeepSparkHub
DeepSparkHub is a repository that curates hundreds of application algorithms and models covering various fields in AI and general computing. It supports mainstream intelligent computing scenarios in markets such as smart cities, digital individuals, healthcare, education, communication, energy, and more. The repository provides a wide range of models for tasks such as computer vision, face detection, face recognition, instance segmentation, image generation, knowledge distillation, network pruning, object detection, 3D object detection, OCR, pose estimation, self-supervised learning, semantic segmentation, super resolution, tracking, traffic forecast, GNN, HPC, methodology, multimodal, NLP, recommendation, reinforcement learning, speech recognition, speech synthesis, and 3D reconstruction.
FaceAiSharp
FaceAiSharp is a .NET library designed for face-related computer vision tasks. It offers functionalities such as face detection, face recognition, facial landmarks detection, and eye state detection. The library utilizes pretrained ONNX models for accurate and efficient results, enabling users to integrate these capabilities into their .NET applications easily. With a focus on simplicity and performance, FaceAiSharp provides a local processing solution without relying on cloud services, supporting image-based face processing using ImageSharp. It is cross-platform compatible, supporting Windows, Linux, Android, and more.
Symposium2023
Symposium2023 is a project aimed at enabling Delphi users to incorporate AI technology into their applications. It provides generalized interfaces to different AI models, making them easily accessible. The project showcases AI's versatility in tasks like language translation, human-like conversations, image generation, data analysis, and more. Users can experiment with different AI models, change providers easily, and avoid vendor lock-in. The project supports various AI features like vision support and function calling, utilizing providers like Google, Microsoft Azure, Amazon, OpenAI, and more. It includes example programs demonstrating tasks such as text-to-speech, language translation, face detection, weather querying, audio transcription, voice recognition, image generation, invoice processing, and API testing. The project also hints at potential future research areas like using embeddings for data search and integrating Python AI libraries with Delphi.
FaceAISDK_Android
FaceAI SDK is an on-device offline face detection, recognition, liveness detection, anti-spoofing, and 1:N/M:N face search SDK. It enables quick integration to achieve on-device face recognition, face search, and other functions. The SDK performs all functions offline on the device without the need for internet connection, ensuring privacy and security. It supports various actions for liveness detection, custom camera management, and clear imaging even in challenging lighting conditions.
For similar jobs
FaceAISDK_Android
FaceAI SDK is an on-device offline face detection, recognition, liveness detection, anti-spoofing, and 1:N/M:N face search SDK. It enables quick integration to achieve on-device face recognition, face search, and other functions. The SDK performs all functions offline on the device without the need for internet connection, ensuring privacy and security. It supports various actions for liveness detection, custom camera management, and clear imaging even in challenging lighting conditions.

Protofy
Protofy is a full-stack, batteries-included low-code enabled web/app and IoT system with an API system and real-time messaging. It is based on Protofy (protoflow + visualui + protolib + protodevices) + Expo + Next.js + Tamagui + Solito + Express + Aedes + Redbird + Many other amazing packages. Protofy can be used to fast prototype Apps, webs, IoT systems, automations, or APIs. It is a ultra-extensible CMS with supercharged capabilities, mobile support, and IoT support (esp32 thanks to esphome).
generative-ai-dart
The Google Generative AI SDK for Dart enables developers to utilize cutting-edge Large Language Models (LLMs) for creating language applications. It provides access to the Gemini API for generating content using state-of-the-art models. Developers can integrate the SDK into their Dart or Flutter applications to leverage powerful AI capabilities. It is recommended to use the SDK for server-side API calls to ensure the security of API keys and protect against potential key exposure in mobile or web apps.
visionOS-examples
visionOS-examples is a repository containing accelerators for Spatial Computing. It includes examples such as Local Large Language Model, Chat Apple Vision Pro, WebSockets, Anchor To Head, Hand Tracking, Battery Life, Countdown, Plane Detection, Timer Vision, and PencilKit for visionOS. The repository showcases various functionalities and features for Apple Vision Pro, offering tools for developers to enhance their visionOS apps with capabilities like hand tracking, plane detection, and real-time cryptocurrency prices.
gemini-pro-vision-playground
Gemini Pro Vision Playground is a simple project aimed at assisting developers in utilizing the Gemini Pro Vision and Gemini Pro AI models for building applications. It provides a playground environment for experimenting with these models and integrating them into apps. The project includes instructions for setting up the Google AI API key and running the development server to visualize the results. Developers can learn more about the Gemini API documentation and Next.js framework through the provided resources. The project encourages contributions and feedback from the community.
Tiktok_Automation_Bot
TikTok Automation Bot is an Appium-based tool for automating TikTok account creation and video posting on real devices. It offers functionalities such as automated account creation and video posting, along with integrations like Crane tweak, SMSActivate service, and IPQualityScore service. The tool also provides device and automation management system, anti-bot system for human behavior modeling, and IP rotation system for different IP addresses. It is designed to simplify the process of managing TikTok accounts and posting videos efficiently.
general
General is a DART & Flutter library created by AZKADEV to speed up development on various platforms and CLI easily. It allows access to features such as camera, fingerprint, SMS, and MMS. The library is designed for Dart language and provides functionalities for app background, text to speech, speech to text, and more.
shards
Shards is a high-performance, multi-platform, type-safe programming language designed for visual development. It is a dataflow visual programming language that enables building full-fledged apps and games without traditional coding. Shards features automatic type checking, optimized shard implementations for high performance, and an intuitive visual workflow for beginners. The language allows seamless round-trip engineering between code and visual models, empowering users to create multi-platform apps easily. Shards also powers an upcoming AI-powered game creation system, enabling real-time collaboration and game development in a low to no-code environment.