
MiKaPo
Real-time MMD motion capture on Web
Stars: 75
MiKaPo is a web-based tool that allows users to pose MMD models in real-time using video input. It utilizes technologies such as Mediapipe for 3D key points detection, Babylon.js for 3D scene rendering, babylon-mmd for MMD model viewing, and Vite+React for the web framework. Users can upload videos and images, select different environments, and choose models for posing. MiKaPo also supports camera input and Ollama (electron version). The tool is open to feature requests and pull requests, with ongoing development to add VMD export functionality.
README:
![]()
MiKaPo is a Web-based tool that poses MMD models from video input in real-time. Welcome feature requests and PRs!



- 3D key points detection: Mediapipe
- 3D scene: Babylon.js
- MMD model viewer: babylon-mmd
- Web framework: Vite+React
- Models are from aplaybox.
- [x] Pose detection
- [x] Face detection
- [x] Hand detection
- [x] Environment selection
- [x] Video, image upload
- [x] Camera input
- [x] Model selection
- [x] Ollama support (electron version)
- [ ] VMD export
- [x] MMD editor: bone, material, mesh edit
- [ ] Custom model, vmd import
- [ ] Multi-user co-editing
npm installnpm run devnpm run buildLint with ESLint
npm run lintFor Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for MiKaPo
Similar Open Source Tools
MiKaPo
MiKaPo is a web-based tool that allows users to pose MMD models in real-time using video input. It utilizes technologies such as Mediapipe for 3D key points detection, Babylon.js for 3D scene rendering, babylon-mmd for MMD model viewing, and Vite+React for the web framework. Users can upload videos and images, select different environments, and choose models for posing. MiKaPo also supports camera input and Ollama (electron version). The tool is open to feature requests and pull requests, with ongoing development to add VMD export functionality.
ComfyUI-fal-API
ComfyUI-fal-API is a repository containing custom nodes for using Flux models with fal API in ComfyUI. It provides nodes for image generation, video generation, language models, and vision language models. Users can easily install and configure the repository to access various nodes for different tasks such as generating images, creating videos, processing text, and understanding images. The repository also includes troubleshooting steps and is licensed under the Apache License 2.0.
LLM-Hub
LLM Hub is an open-source Android app optimized for mobile usage, supporting multiple model formats for on-device LLM chat and image generation. It offers six AI tools including chat, writing aid, image generator, translator, transcriber, and scam detector. Privacy-first with on-device processing and zero data collection. Advanced capabilities include GPU/NPU acceleration, text-to-speech, RAG with global memory, and custom model import. Developed using Kotlin + Jetpack Compose, LLM Runtime, and various model runtimes.
BookWorm
BookWorm is a cloud-native application showcasing Aspire with AI integration. It features DDD and VSA, multi-agent orchestration, standardized AI tooling through MCP, A2A & AG-UI Protocol support, and various microservices patterns. The project includes API versioning, feature flags, AuthN/AuthZ with Keycloak, caching with HybridCache, CI/CD with GitHub Actions, comprehensive documentation, modern client applications with Next.js, testing strategies, and more.
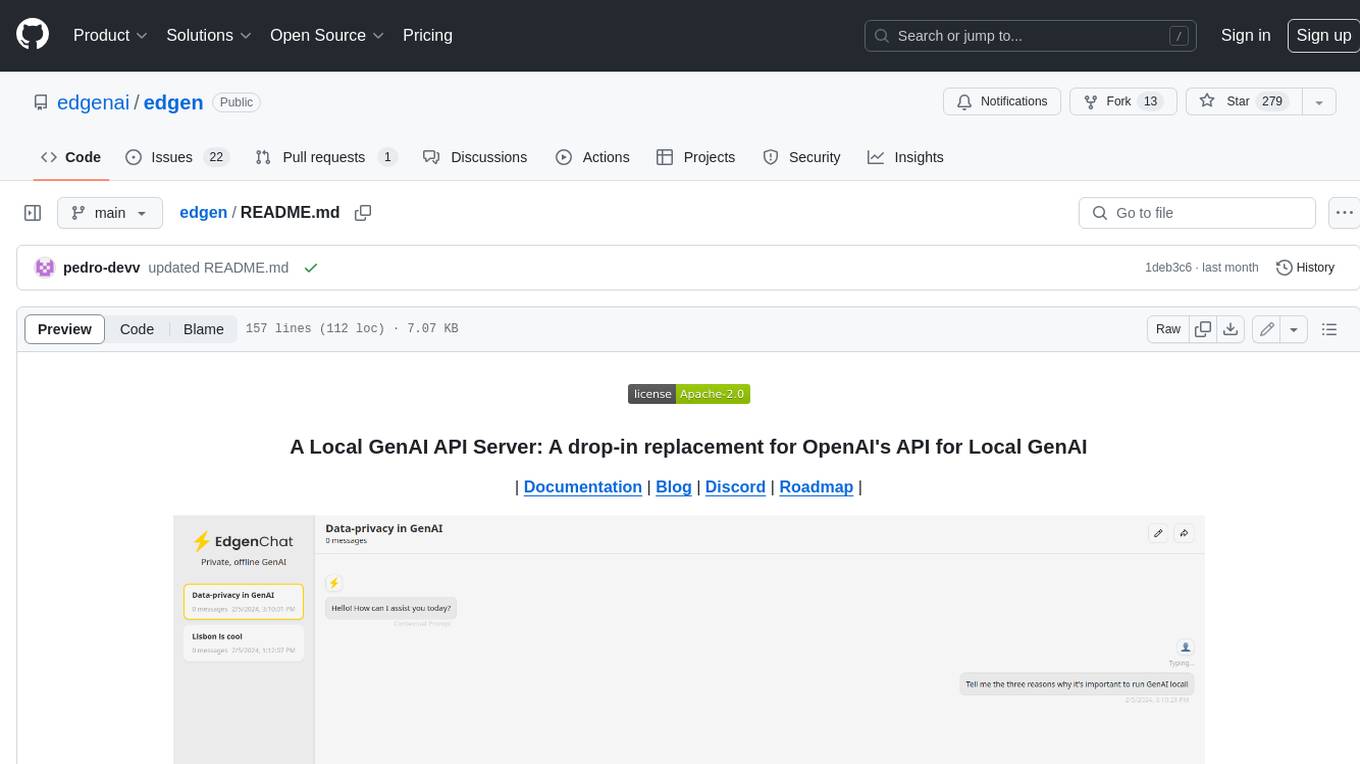
edgen
Edgen is a local GenAI API server that serves as a drop-in replacement for OpenAI's API. It provides multi-endpoint support for chat completions and speech-to-text, is model agnostic, offers optimized inference, and features model caching. Built in Rust, Edgen is natively compiled for Windows, MacOS, and Linux, eliminating the need for Docker. It allows users to utilize GenAI locally on their devices for free and with data privacy. With features like session caching, GPU support, and support for various endpoints, Edgen offers a scalable, reliable, and cost-effective solution for running GenAI applications locally.
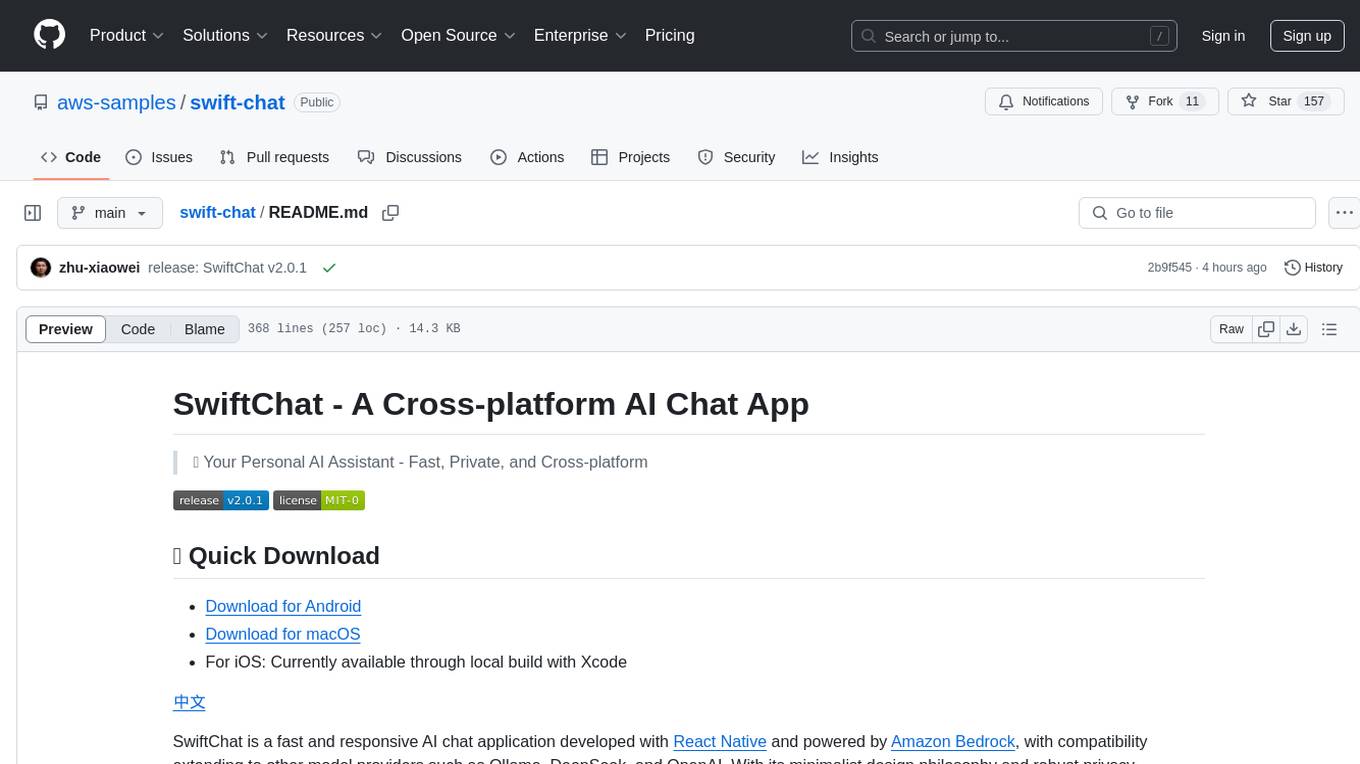
swift-chat
SwiftChat is a fast and responsive AI chat application developed with React Native and powered by Amazon Bedrock. It offers real-time streaming conversations, AI image generation, multimodal support, conversation history management, and cross-platform compatibility across Android, iOS, and macOS. The app supports multiple AI models like Amazon Bedrock, Ollama, DeepSeek, and OpenAI, and features a customizable system prompt assistant. With a minimalist design philosophy and robust privacy protection, SwiftChat delivers a seamless chat experience with various features like rich Markdown support, comprehensive multimodal analysis, creative image suite, and quick access tools. The app prioritizes speed in launch, request, render, and storage, ensuring a fast and efficient user experience. SwiftChat also emphasizes app privacy and security by encrypting API key storage, minimal permission requirements, local-only data storage, and a privacy-first approach.
next-ai-draw-io
Next AI Draw.io is a next.js web application that integrates AI capabilities with draw.io diagrams. It allows users to create, modify, and enhance diagrams through natural language commands and AI-assisted visualization. Features include LLM-Powered Diagram Creation, Image-Based Diagram Replication, Diagram History, Interactive Chat Interface, and Smart Editing. The application uses Next.js for frontend framework, @ai-sdk/react for chat interface and AI interactions, and react-drawio for diagram representation and manipulation. Diagrams are represented as XML that can be rendered in draw.io, with AI processing commands to generate or modify the XML accordingly.
react-native-vision-camera
VisionCamera is a powerful, high-performance Camera library for React Native. It features Photo and Video capture, QR/Barcode scanner, Customizable devices and multi-cameras ("fish-eye" zoom), Customizable resolutions and aspect-ratios (4k/8k images), Customizable FPS (30..240 FPS), Frame Processors (JS worklets to run facial recognition, AI object detection, realtime video chats, ...), Smooth zooming (Reanimated), Fast pause and resume, HDR & Night modes, Custom C++/GPU accelerated video pipeline (OpenGL).
GMTalker
GMTalker is an interactive digital human rendered by Unreal Engine, developed by the Media Intelligence Team at Bright Laboratory. The system integrates speech recognition, speech synthesis, natural language understanding, and lip-sync animation driving. It supports rapid deployment on Windows with only 2GB of VRAM required. The project showcases two 3D cartoon digital human avatars suitable for presentations, expansions, and commercial integration.
pyspur
PySpur is a graph-based editor designed for LLM (Large Language Models) workflows. It offers modular building blocks, node-level debugging, and performance evaluation. The tool is easy to hack, supports JSON configs for workflow graphs, and is lightweight with minimal dependencies. Users can quickly set up PySpur by cloning the repository, creating a .env file, starting docker services, and accessing the portal. PySpur can also work with local models served using Ollama, with steps provided for configuration. The roadmap includes features like canvas, async/batch execution, support for Ollama, new nodes, pipeline optimization, templates, code compilation, multimodal support, and more.
cherry-studio
Cherry Studio is a desktop client that supports multiple Large Language Model (LLM) providers, available on Windows, Mac, and Linux. It allows users to create multiple Assistants and topics, use multiple models to answer questions in the same conversation, and supports drag-and-drop sorting, code highlighting, and Mermaid chart. The tool is designed to enhance productivity and streamline the process of interacting with various language models.
pollinations
pollinations.ai is an open-source generative AI platform based in Berlin, empowering community projects with accessible text, image, video, and audio generation APIs. It offers a unified API endpoint for various AI generation needs, including text, images, audio, and video. The platform provides features like image generation using models such as Flux, GPT Image, Seedream, and Kontext, video generation with Seedance and Veo, and audio generation with text-to-speech and speech-to-text capabilities. Users can access the platform through a web interface or API, and authentication is managed through API keys. The platform is community-driven, transparent, and ethical, aiming to make AI technology open, accessible, and interconnected while fostering innovation and responsible development.

ollama
Ollama is a lightweight, extensible framework for building and running language models on the local machine. It provides a simple API for creating, running, and managing models, as well as a library of pre-built models that can be easily used in a variety of applications. Ollama is designed to be easy to use and accessible to developers of all levels. It is open source and available for free on GitHub.
mindpocket
MindPocket is a fully open-source, free, multi-platform, one-click deployable personal bookmark system with AI Agent integration. It organizes bookmarks with AI-powered RAG content summarization and automatic tag generation, making it easy to find and manage saved content. The project is built using VIBE CODING principles and offers features like zero cost deployment, one-click deploy setup, multi-platform support, AI enhancement for smart tagging and summarization, and full open-source accessibility for user data ownership. The tool is designed to provide a seamless bookmarking experience across web, mobile, and browser extension platforms.
superagentx
SuperAgentX is a lightweight open-source AI framework designed for multi-agent applications with Artificial General Intelligence (AGI) capabilities. It offers goal-oriented multi-agents with retry mechanisms, easy deployment through WebSocket, RESTful API, and IO console interfaces, streamlined architecture with no major dependencies, contextual memory using SQL + Vector databases, flexible LLM configuration supporting various Gen AI models, and extendable handlers for integration with diverse APIs and data sources. It aims to accelerate the development of AGI by providing a powerful platform for building autonomous AI agents capable of executing complex tasks with minimal human intervention.

InsForge
InsForge is a backend development platform designed for AI coding agents and AI code editors. It serves as a semantic layer that enables agents to interact with backend primitives such as databases, authentication, storage, and functions in a meaningful way. The platform allows agents to fetch backend context, configure primitives, and inspect backend state through structured schemas. InsForge facilitates backend context engineering for AI coding agents to understand, operate, and monitor backend systems effectively.
For similar tasks
ai-commits-intellij-plugin
AI Commits is a plugin for IntelliJ-based IDEs and Android Studio that generates commit messages using git diff and OpenAI. It offers features such as generating commit messages from diff using OpenAI API, computing diff only from selected files and lines in the commit dialog, creating custom prompts for commit message generation, using predefined variables and hints to customize prompts, choosing any of the models available in OpenAI API, setting OpenAI network proxy, and setting custom OpenAI compatible API endpoint.
MiKaPo
MiKaPo is a web-based tool that allows users to pose MMD models in real-time using video input. It utilizes technologies such as Mediapipe for 3D key points detection, Babylon.js for 3D scene rendering, babylon-mmd for MMD model viewing, and Vite+React for the web framework. Users can upload videos and images, select different environments, and choose models for posing. MiKaPo also supports camera input and Ollama (electron version). The tool is open to feature requests and pull requests, with ongoing development to add VMD export functionality.
human
AI-powered 3D Face Detection & Rotation Tracking, Face Description & Recognition, Body Pose Tracking, 3D Hand & Finger Tracking, Iris Analysis, Age & Gender & Emotion Prediction, Gaze Tracking, Gesture Recognition, Body Segmentation

MiniAI-Face-Recognition-LivenessDetection-WindowsSDK
This repository contains a C++ application that demonstrates face recognition capabilities using computer vision techniques. The demo utilizes OpenCV and dlib libraries for efficient face detection and recognition with 3D passive face liveness detection (face anti-spoofing). Key Features: Face detection: The SDK utilizes advanced computer vision techniques to detect faces in images or video frames, enabling a wide range of applications. Face recognition: It can recognize known faces by comparing them with a pre-defined database of individuals. Age estimation: It can estimate the age of detected faces. Gender detection: It can determine the gender of detected faces. Liveness detection: It can detect whether a face is from a live person or a static image.
face-api
FaceAPI is an AI-powered tool for face detection, rotation tracking, face description, recognition, age, gender, and emotion prediction. It can be used in both browser and NodeJS environments using TensorFlow/JS. The tool provides live demos for processing images and webcam feeds, along with NodeJS examples for various tasks such as face similarity comparison and multiprocessing. FaceAPI offers different pre-built versions for client-side browser execution and server-side NodeJS execution, with or without TFJS pre-bundled. It is compatible with TFJS 2.0+ and TFJS 3.0+.
DeepSparkHub
DeepSparkHub is a repository that curates hundreds of application algorithms and models covering various fields in AI and general computing. It supports mainstream intelligent computing scenarios in markets such as smart cities, digital individuals, healthcare, education, communication, energy, and more. The repository provides a wide range of models for tasks such as computer vision, face detection, face recognition, instance segmentation, image generation, knowledge distillation, network pruning, object detection, 3D object detection, OCR, pose estimation, self-supervised learning, semantic segmentation, super resolution, tracking, traffic forecast, GNN, HPC, methodology, multimodal, NLP, recommendation, reinforcement learning, speech recognition, speech synthesis, and 3D reconstruction.
FaceAiSharp
FaceAiSharp is a .NET library designed for face-related computer vision tasks. It offers functionalities such as face detection, face recognition, facial landmarks detection, and eye state detection. The library utilizes pretrained ONNX models for accurate and efficient results, enabling users to integrate these capabilities into their .NET applications easily. With a focus on simplicity and performance, FaceAiSharp provides a local processing solution without relying on cloud services, supporting image-based face processing using ImageSharp. It is cross-platform compatible, supporting Windows, Linux, Android, and more.
Symposium2023
Symposium2023 is a project aimed at enabling Delphi users to incorporate AI technology into their applications. It provides generalized interfaces to different AI models, making them easily accessible. The project showcases AI's versatility in tasks like language translation, human-like conversations, image generation, data analysis, and more. Users can experiment with different AI models, change providers easily, and avoid vendor lock-in. The project supports various AI features like vision support and function calling, utilizing providers like Google, Microsoft Azure, Amazon, OpenAI, and more. It includes example programs demonstrating tasks such as text-to-speech, language translation, face detection, weather querying, audio transcription, voice recognition, image generation, invoice processing, and API testing. The project also hints at potential future research areas like using embeddings for data search and integrating Python AI libraries with Delphi.
For similar jobs
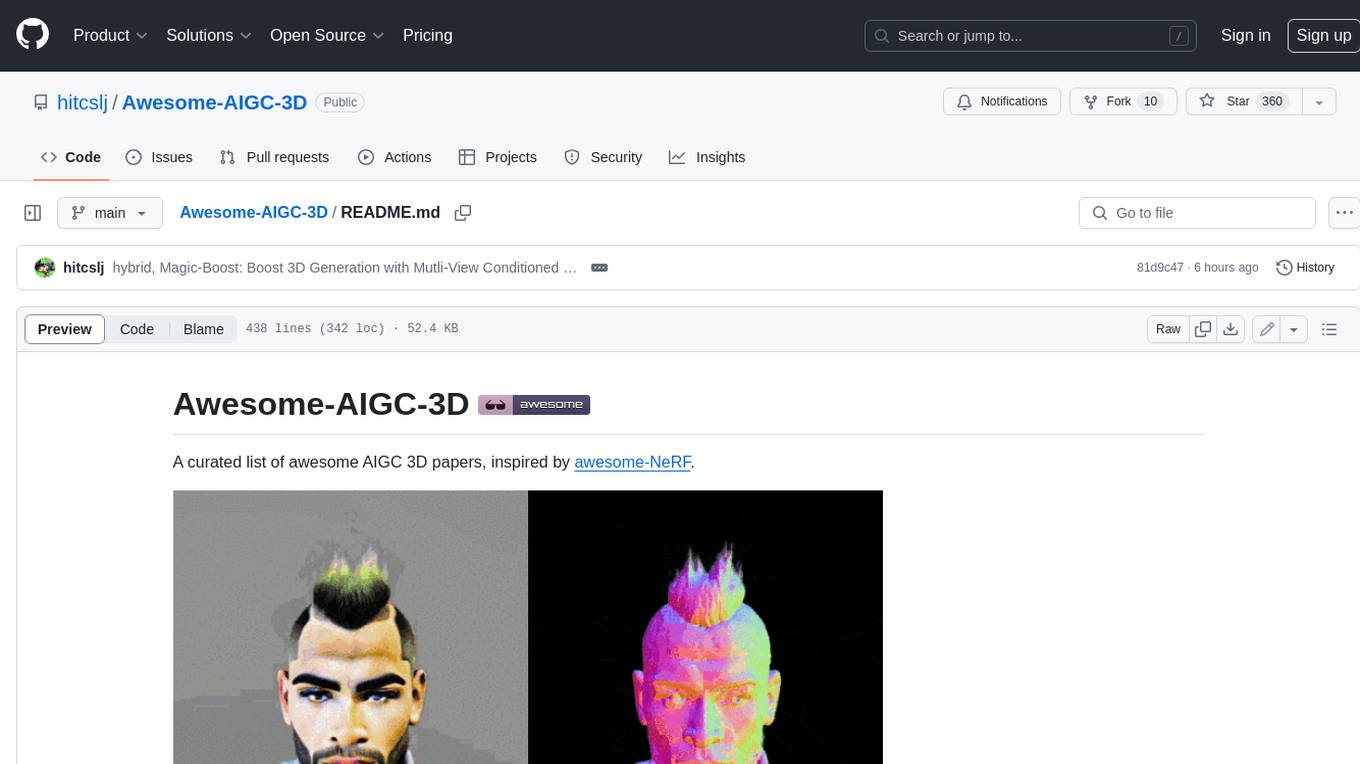
Awesome-AIGC-3D
Awesome-AIGC-3D is a curated list of awesome AIGC 3D papers, inspired by awesome-NeRF. It aims to provide a comprehensive overview of the state-of-the-art in AIGC 3D, including papers on text-to-3D generation, 3D scene generation, human avatar generation, and dynamic 3D generation. The repository also includes a list of benchmarks and datasets, talks, companies, and implementations related to AIGC 3D. The description is less than 400 words and provides a concise overview of the repository's content and purpose.

CushyStudio
CushyStudio is a generative AI platform designed for creatives of any level to effortlessly create stunning images, videos, and 3D models. It offers CushyApps, a collection of visual tools tailored for different artistic tasks, and CushyKit, an extensive toolkit for custom apps development and task automation. Users can dive into the AI revolution, unleash their creativity, share projects, and connect with a vibrant community. The platform aims to simplify the AI art creation process and provide a user-friendly environment for designing interfaces, adding custom logic, and accessing various tools.
dream-textures
Dream Textures is a tool integrated into Blender that allows users to create textures, concept art, background assets, and more using simple text prompts. It offers features like seamless texture creation, texture projection for entire scenes, restyling animations, and running models on the user's machine for faster iteration. The tool supports CUDA and Apple Silicon GPUs, with over 4GB of VRAM recommended. Users can troubleshoot issues by checking Blender's system console or seeking help from the community on Discord.
aircraft
Headwind Simulations A339X - A330-900neo is an open-source project aimed at creating a free Airbus A330-900neo for Microsoft Flight Simulator. The project is based on the FlyByWire System A32NX and offers a detailed simulation of the A330-941 model with various components like engines, FMS, ACAS, ATC, and more. Users can build the aircraft using Docker and node modules, and the package can be easily integrated into MSFS. The project is part of a collaborative effort with other open-source projects contributing to the aircraft's systems, cockpit, sound, and 3D parts. The repository is dual-licensed under GNU GPLv3 for textual-form source code and CC BY-NC 4.0 for artistic assets, ensuring proper usage and attribution of the content.
MiKaPo
MiKaPo is a web-based tool that allows users to pose MMD models in real-time using video input. It utilizes technologies such as Mediapipe for 3D key points detection, Babylon.js for 3D scene rendering, babylon-mmd for MMD model viewing, and Vite+React for the web framework. Users can upload videos and images, select different environments, and choose models for posing. MiKaPo also supports camera input and Ollama (electron version). The tool is open to feature requests and pull requests, with ongoing development to add VMD export functionality.
uDesktopMascot
uDesktopMascot is an open-source project for a desktop mascot application with a theme of 'freedom of creation'. It allows users to load and display VRM or GLB/FBX model files on the desktop, customize GUI colors and background images, and access various features through a menu screen. The application supports Windows 10/11 and macOS platforms.
DeepMesh
DeepMesh is an auto-regressive artist-mesh creation tool that utilizes reinforcement learning to generate high-quality meshes conditioned on a given point cloud. It offers pretrained weights and allows users to generate obj/ply files based on specific input parameters. The tool has been tested on Ubuntu 22 with CUDA 11.8 and supports A100, A800, and A6000 GPUs. Users can clone the repository, create a conda environment, install pretrained model weights, and use command line inference to generate meshes.