
MathVerse
[ECCV 2024] Does Your Multi-modal LLM Truly See the Diagrams in Visual Math Problems?
Stars: 115

MathVerse is an all-around visual math benchmark designed to evaluate the capabilities of Multi-modal Large Language Models (MLLMs) in visual math problem-solving. It collects high-quality math problems with diagrams to assess how well MLLMs can understand visual diagrams for mathematical reasoning. The benchmark includes 2,612 problems transformed into six versions each, contributing to 15K test samples. It also introduces a Chain-of-Thought (CoT) Evaluation strategy for fine-grained assessment of output answers.
README:
Official repository for the paper "MathVerse: Does Your Multi-modal LLM Truly See the Diagrams in Visual Math Problems?".
🌟 For more details, please refer to the project page with dataset exploration and visualization tools: https://mathverse-cuhk.github.io/.
[🌐 Webpage] [📖 Paper] [🤗 Huggingface Dataset] [🏆 Leaderboard] [🔍 Visualization]
- [2024.07.01] 🎉 MathVerse is accepted by ECCV 2024 🎉
- [2024.03.31] 🔥 We release the testmini set of MathVerse at [🤗 Huggingface Dataset], alongside the evaluation code!
- [2024.03.22] 🎉 MathVerse has been selected as 🤗 Hugging Face Daily Papers!
- [2024.03.22] 🚀 We release the arXiv paper and some data samples in the visualizer.
- Coming soon: CoT Evaluation results & tools, and the full MathVerse dataset
The capabilities of Multi-modal Large Language Models (MLLMs) in visual math problem-solving remain insufficiently evaluated and understood. We investigate current benchmarks to incorporate excessive visual content within textual questions, which potentially assist MLLMs in deducing answers without truly interpreting the input diagrams.

To this end, we introduce MathVerse, an all-around visual math benchmark designed for an equitable and in-depth evaluation of MLLMs. We meticulously collect 2,612 high-quality, multi-subject math problems with diagrams from publicly available sources. Each problem is then transformed by human annotators into six distinct versions, each offering varying degrees of information content in multi-modality, contributing to 15K test samples in total. This approach allows MathVerse to comprehensively assess whether and how much MLLMs can truly understand the visual diagrams for mathematical reasoning.

Six different versions of each problem in MathVerse transformed by expert annotators.
In addition, we propose a Chain-of-Thought (CoT) Evaluation strategy for a fine-grained assessment of the output answers. Rather than naively judging True or False, we employ GPT-4(V) to adaptively extract crucial reasoning steps, and then score each step with detailed error analysis, which can reveal the intermediate CoT reasoning quality by MLLMs.

The two phases of the CoT evaluation strategy.
🚨 The Leaderboard for the testmini set is continuously being updated, welcoming the contribution of your excellent MLLMs! Currently, we regard the 'w/o' scores without the CoT evaluation as the primary metric in MathVerse, which is more cost-effective and saves time.
We release the testmini set of MathVerse for benchmarking on the leaderboard, which contains 788 visual math problems within two json files:
- testmini.json: 788*5 test samples for five main versions to calculate the overall score, i.e., Text Dominant/Lite and Vision Intensive/Dominant/Only.
- testmini_text_only.json: 788*1 test samples for Text Only to ablate the visual diagram understanding capacity.
You can download the dataset from the 🤗 Huggingface by the following command (make sure that you have installed related packages):
from datasets import load_dataset
dataset = load_dataset("AI4Math/MathVerse", "testmini")
dataset_text_only = load_dataset("AI4Math/MathVerse", "testmini_text_only")Here are some examples of how to access the downloaded dataset:
# print the first example on the testmini set
print(dataset["testmini"][0])
print(dataset["testmini"][0]['sample_index']) # print the test sample id
print(dataset["testmini"][0]['problem_index']) # print the unique problem id
print(dataset["testmini"][0]['problem_version']) # print the problem version
print(dataset["testmini"][0]['question']) # print the question text
print(dataset["testmini"][0]['query']) # print the question query
print(dataset["testmini"][0]['answer']) # print the answer
print(dataset["testmini"][0]['query_wo']) # the input query for w/o scores
print(dataset["testmini"][0]['query_cot']) # the input query for CoT evaluation scores
dataset["testmini"][0]['image'] # display the image
# print the first text-only example within the testmini set
print(dataset_text_only["testmini_text_only"][0])We also provide the images in the PNG format. You can download and unzip them using the following commands:
cd data
wget https://huggingface.co/datasets/AI4Math/MathVerse/resolve/main/images.zip
unzip images.zip && rm images.zipThis step might be optional if you prefer to use the Hugging Face format of the data.
First, please refer to the following two templates to prepare your result json files.
- output_testmini.json: the results of five problem versions in testmini.json
- output_testmini_text_only.json: the results of the Text-only version in testmini_text_only.json
If you expect to evaluate the 'w/o' scores in the leaderboard, please adopt query_wo as the input for MLLMs, which prompts the model to output a direct answer. For CoT evaluation, we can utilize query_cot that motivates MLLMs to provide a step-by-step reasoning process. You are also encouraged to tune the optimal prompt for your own model.
Then, we provide the code to derive the 'w/o' scores on the leaderboard, which requires advanced LLMs (e.g., ChatGPT/GPT-4, or Qwen-Max) to extract and match answers. The code 'CoT-E' scores will be released soon.
There are two steps for the evaluation of 'w/o' scores, where we prompt the ChatGPT/GPT-4 API as an example:
pip install openai
cd evaluation
python extract_answer_s1.py \
--model_output_file PATH_TO_OUTPUT_FILE \
--save_file PATH_TO_ENTRACTION_FILE \
--cache \
--trunk_response 30 \
--save_every 10 \
--api_key GPT_APINote that, step 1 is optional if your MLLM can directly output a clean answer for scoring.
python score_answer_s2.py \
--answer_extraction_file PATH_TO_ENTRACTION_FILE \
--save_file PATH_TO_SCORE_FILE \
--cache \
--trunk_response 30 \
--save_every 10 \
--api_key GPT_APINote that, we recommend using ChatGPT/GPT-4 API for step 2 by default. By adding --quick_match in the command above, we also support a direct string matching between extracted answers and ground truths, which is faster but not accurate enough.
🖱 Click to expand the examples for six problem versions within three subjects
🔍 Plane Geometry

🔍 Solid Geometry

🔍 Functions

Coming soon!
If you find MathVerse useful for your research and applications, please kindly cite using this BibTeX:
@article{zhang2024mathverse,
title={MathVerse: Does Your Multi-modal LLM Truly See the Diagrams in Visual Math Problems?},
author={Zhang, Renrui and Jiang, Dongzhi and Zhang, Yichi and Lin, Haokun and Guo, Ziyu and Qiu, Pengshuo and Zhou, Aojun and Lu, Pan and Chang, Kai-Wei and Gao, Peng and others},
journal={arXiv preprint arXiv:2403.14624},
year={2024}
}Explore our additional research on Vision-Language Large Models, focusing on multi-modal LLMs and mathematical reasoning:
- [MathVista] MathVista: Evaluating Mathematical Reasoning of Foundation Models in Visual Contexts
- [LLaMA-Adapter] LLaMA-Adapter: Efficient Fine-tuning of Language Models with Zero-init Attention
- [LLaMA-Adapter V2] LLaMA-Adapter V2: Parameter-Efficient Visual Instruction Model
- [ImageBind-LLM] Imagebind-LLM: Multi-modality Instruction Tuning
- [SPHINX] The Joint Mixing of Weights, Tasks, and Visual Embeddings for Multi-modal LLMs
- [SPHINX-X] Scaling Data and Parameters for a Family of Multi-modal Large Language Models
- [Point-Bind & Point-LLM] Multi-modality 3D Understanding, Generation, and Instruction Following
- [PerSAM] Personalize segment anything model with one shot
- [MathCoder] MathCoder: Seamless Code Integration in LLMs for Enhanced Mathematical Reasoning
- [MathVision] Measuring Multimodal Mathematical Reasoning with the MATH-Vision Dataset
- [CSV] Solving Challenging Math Word Problems Using GPT-4 Code Interpreter
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for MathVerse
Similar Open Source Tools
MathVerse
MathVerse is an all-around visual math benchmark designed to evaluate the capabilities of Multi-modal Large Language Models (MLLMs) in visual math problem-solving. It collects high-quality math problems with diagrams to assess how well MLLMs can understand visual diagrams for mathematical reasoning. The benchmark includes 2,612 problems transformed into six versions each, contributing to 15K test samples. It also introduces a Chain-of-Thought (CoT) Evaluation strategy for fine-grained assessment of output answers.

MathCoder
MathCoder is a repository focused on enhancing mathematical reasoning by fine-tuning open-source language models to use code for modeling and deriving math equations. It introduces MathCodeInstruct dataset with solutions interleaving natural language, code, and execution results. The repository provides MathCoder models capable of generating code-based solutions for challenging math problems, achieving state-of-the-art scores on MATH and GSM8K datasets. It offers tools for model deployment, inference, and evaluation, along with a citation for referencing the work.

MInference
MInference is a tool designed to accelerate pre-filling for long-context Language Models (LLMs) by leveraging dynamic sparse attention. It achieves up to a 10x speedup for pre-filling on an A100 while maintaining accuracy. The tool supports various decoding LLMs, including LLaMA-style models and Phi models, and provides custom kernels for attention computation. MInference is useful for researchers and developers working with large-scale language models who aim to improve efficiency without compromising accuracy.
EasyInstruct
EasyInstruct is a Python package proposed as an easy-to-use instruction processing framework for Large Language Models (LLMs) like GPT-4, LLaMA, ChatGLM in your research experiments. EasyInstruct modularizes instruction generation, selection, and prompting, while also considering their combination and interaction.

RLAIF-V
RLAIF-V is a novel framework that aligns MLLMs in a fully open-source paradigm for super GPT-4V trustworthiness. It maximally exploits open-source feedback from high-quality feedback data and online feedback learning algorithm. Notable features include achieving super GPT-4V trustworthiness in both generative and discriminative tasks, using high-quality generalizable feedback data to reduce hallucination of different MLLMs, and exhibiting better learning efficiency and higher performance through iterative alignment.

qa-mdt
This repository provides an implementation of QA-MDT, integrating state-of-the-art models for music generation. It offers a Quality-Aware Masked Diffusion Transformer for enhanced music generation. The code is based on various repositories like AudioLDM, PixArt-alpha, MDT, AudioMAE, and Open-Sora. The implementation allows for training and fine-tuning the model with different strategies and datasets. The repository also includes instructions for preparing datasets in LMDB format and provides a script for creating a toy LMDB dataset. The model can be used for music generation tasks, with a focus on quality injection to enhance the musicality of generated music.

OpenMusic
OpenMusic is a repository providing an implementation of QA-MDT, a Quality-Aware Masked Diffusion Transformer for music generation. The code integrates state-of-the-art models and offers training strategies for music generation. The repository includes implementations of AudioLDM, PixArt-alpha, MDT, AudioMAE, and Open-Sora. Users can train or fine-tune the model using different strategies and datasets. The model is well-pretrained and can be used for music generation tasks. The repository also includes instructions for preparing datasets, training the model, and performing inference. Contact information is provided for any questions or suggestions regarding the project.

sdialog
SDialog is an MIT-licensed open-source toolkit for building, simulating, and evaluating LLM-based conversational agents end-to-end. It aims to bridge agent construction, user simulation, dialog generation, and evaluation in a single reproducible workflow, enabling the generation of reliable, controllable dialog systems or data at scale. The toolkit standardizes a Dialog schema, offers persona-driven multi-agent simulation with LLMs, provides composable orchestration for precise control over behavior and flow, includes built-in evaluation metrics, and offers mechanistic interpretability. It allows for easy creation of user-defined components and interoperability across various AI platforms.
Endia
Endia is a dynamic Array library for Scientific Computing, offering automatic differentiation of arbitrary order, complex number support, dual API with PyTorch-like imperative or JAX-like functional interface, and JIT Compilation for speeding up training and inference. It can handle complex valued functions, perform both forward and reverse-mode automatic differentiation, and has a builtin JIT compiler. Endia aims to advance AI & Scientific Computing by pushing boundaries with clear algorithms, providing high-performance open-source code that remains readable and pythonic, and prioritizing clarity and educational value over exhaustive features.
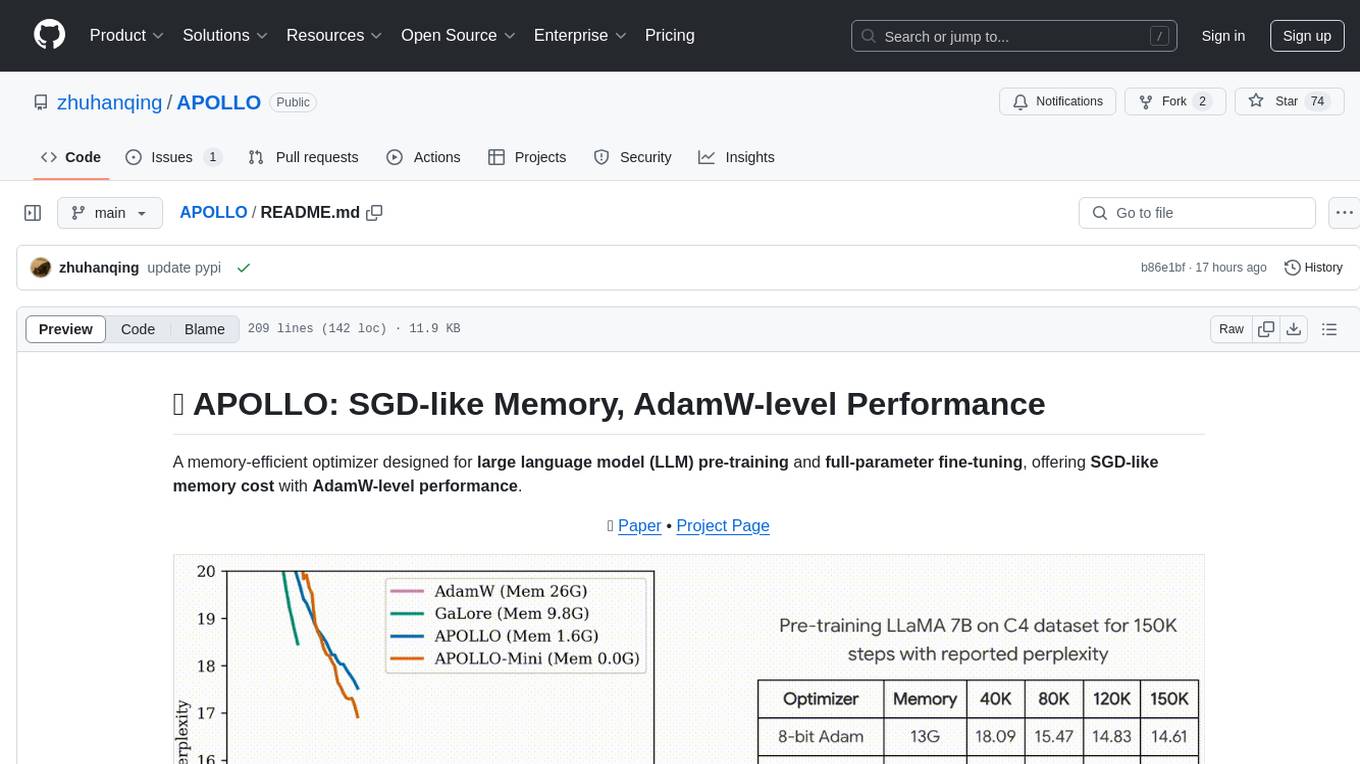
APOLLO
APOLLO is a memory-efficient optimizer designed for large language model (LLM) pre-training and full-parameter fine-tuning. It offers SGD-like memory cost with AdamW-level performance. The optimizer integrates low-rank approximation and optimizer state redundancy reduction to achieve significant memory savings while maintaining or surpassing the performance of Adam(W). Key contributions include structured learning rate updates for LLM training, approximated channel-wise gradient scaling in a low-rank auxiliary space, and minimal-rank tensor-wise gradient scaling. APOLLO aims to optimize memory efficiency during training large language models.

Adaptive-MT-LLM-Fine-tuning
The repository Adaptive-MT-LLM-Fine-tuning contains code and data for the paper 'Fine-tuning Large Language Models for Adaptive Machine Translation'. It focuses on enhancing Mistral 7B, a large language model, for real-time adaptive machine translation in the medical domain. The fine-tuning process involves using zero-shot and one-shot translation prompts to improve terminology and style adherence. The repository includes training and test data, data processing code, fuzzy match retrieval techniques, fine-tuning methods, conversion to CTranslate2 format, tokenizers, translation codes, and evaluation metrics.


WildBench
WildBench is a tool designed for benchmarking Large Language Models (LLMs) with challenging tasks sourced from real users in the wild. It provides a platform for evaluating the performance of various models on a range of tasks. Users can easily add new models to the benchmark by following the provided guidelines. The tool supports models from Hugging Face and other APIs, allowing for comprehensive evaluation and comparison. WildBench facilitates running inference and evaluation scripts, enabling users to contribute to the benchmark and collaborate on improving model performance.
unify
The Unify Python Package provides access to the Unify REST API, allowing users to query Large Language Models (LLMs) from any Python 3.7.1+ application. It includes Synchronous and Asynchronous clients with Streaming responses support. Users can easily use any endpoint with a single key, route to the best endpoint for optimal throughput, cost, or latency, and customize prompts to interact with the models. The package also supports dynamic routing to automatically direct requests to the top-performing provider. Additionally, users can enable streaming responses and interact with the models asynchronously for handling multiple user requests simultaneously.

py-llm-core
PyLLMCore is a light-weighted interface with Large Language Models with native support for llama.cpp, OpenAI API, and Azure deployments. It offers a Pythonic API that is simple to use, with structures provided by the standard library dataclasses module. The high-level API includes the assistants module for easy swapping between models. PyLLMCore supports various models including those compatible with llama.cpp, OpenAI, and Azure APIs. It covers use cases such as parsing, summarizing, question answering, hallucinations reduction, context size management, and tokenizing. The tool allows users to interact with language models for tasks like parsing text, summarizing content, answering questions, reducing hallucinations, managing context size, and tokenizing text.

RTL-Coder
RTL-Coder is a tool designed to outperform GPT-3.5 in RTL code generation by providing a fully open-source dataset and a lightweight solution. It targets Verilog code generation and offers an automated flow to generate a large labeled dataset with over 27,000 diverse Verilog design problems and answers. The tool addresses the data availability challenge in IC design-related tasks and can be used for various applications beyond LLMs. The tool includes four RTL code generation models available on the HuggingFace platform, each with specific features and performance characteristics. Additionally, RTL-Coder introduces a new LLM training scheme based on code quality feedback to further enhance model performance and reduce GPU memory consumption.
For similar tasks
MathVerse
MathVerse is an all-around visual math benchmark designed to evaluate the capabilities of Multi-modal Large Language Models (MLLMs) in visual math problem-solving. It collects high-quality math problems with diagrams to assess how well MLLMs can understand visual diagrams for mathematical reasoning. The benchmark includes 2,612 problems transformed into six versions each, contributing to 15K test samples. It also introduces a Chain-of-Thought (CoT) Evaluation strategy for fine-grained assessment of output answers.
Video-MME
Video-MME is the first-ever comprehensive evaluation benchmark of Multi-modal Large Language Models (MLLMs) in Video Analysis. It assesses the capabilities of MLLMs in processing video data, covering a wide range of visual domains, temporal durations, and data modalities. The dataset comprises 900 videos with 256 hours and 2,700 human-annotated question-answer pairs. It distinguishes itself through features like duration variety, diversity in video types, breadth in data modalities, and quality in annotations.
MiniCPM
MiniCPM is a series of open-source large models on the client side jointly developed by Face Intelligence and Tsinghua University Natural Language Processing Laboratory. The main language model MiniCPM-2B has only 2.4 billion (2.4B) non-word embedding parameters, with a total of 2.7B parameters. - After SFT, MiniCPM-2B performs similarly to Mistral-7B on public comprehensive evaluation sets (better in Chinese, mathematics, and code capabilities), and outperforms models such as Llama2-13B, MPT-30B, and Falcon-40B overall. - After DPO, MiniCPM-2B also surpasses many representative open-source large models such as Llama2-70B-Chat, Vicuna-33B, Mistral-7B-Instruct-v0.1, and Zephyr-7B-alpha on the current evaluation set MTBench, which is closest to the user experience. - Based on MiniCPM-2B, a multi-modal large model MiniCPM-V 2.0 on the client side is constructed, which achieves the best performance of models below 7B in multiple test benchmarks, and surpasses larger parameter scale models such as Qwen-VL-Chat 9.6B, CogVLM-Chat 17.4B, and Yi-VL 34B on the OpenCompass leaderboard. MiniCPM-V 2.0 also demonstrates leading OCR capabilities, approaching Gemini Pro in scene text recognition capabilities. - After Int4 quantization, MiniCPM can be deployed and inferred on mobile phones, with a streaming output speed slightly higher than human speech speed. MiniCPM-V also directly runs through the deployment of multi-modal large models on mobile phones. - A single 1080/2080 can efficiently fine-tune parameters, and a single 3090/4090 can fully fine-tune parameters. A single machine can continuously train MiniCPM, and the secondary development cost is relatively low.
SemanticKernel.Assistants
This repository contains an assistant proposal for the Semantic Kernel, allowing the usage of assistants without relying on OpenAI Assistant APIs. It runs locally planners and plugins for the assistants, providing scenarios like Assistant with Semantic Kernel plugins, Multi-Assistant conversation, and AutoGen conversation. The Semantic Kernel is a lightweight SDK enabling integration of AI Large Language Models with conventional programming languages, offering functions like semantic functions, native functions, and embeddings-based memory. Users can bring their own model for the assistants and host them locally. The repository includes installation instructions, usage examples, and information on creating new conversation threads with the assistant.
AMchat
AMchat is a large language model that integrates advanced math concepts, exercises, and solutions. The model is based on the InternLM2-Math-7B model and is specifically designed to answer advanced math problems. It provides a comprehensive dataset that combines Math and advanced math exercises and solutions. Users can download the model from ModelScope or OpenXLab, deploy it locally or using Docker, and even retrain it using XTuner for fine-tuning. The tool also supports LMDeploy for quantization, OpenCompass for evaluation, and various other features for model deployment and evaluation. The project contributors have provided detailed documentation and guides for users to utilize the tool effectively.
Self-Iterative-Agent-System-for-Complex-Problem-Solving
The Self-Iterative Agent System for Complex Problem Solving is a solution developed for the Alibaba Mathematical Competition (AI Challenge). It involves multiple LLMs engaging in multi-round 'self-questioning' to iteratively refine the problem-solving process and select optimal solutions. The system consists of main and evaluation models, with a process that includes detailed problem-solving steps, feedback loops, and iterative improvements. The approach emphasizes communication and reasoning between sub-agents, knowledge extraction, and the importance of Agent-like architectures in complex tasks. While effective, there is room for improvement in model capabilities and error prevention mechanisms.
LLM4Opt
LLM4Opt is a collection of references and papers focusing on applying Large Language Models (LLMs) for diverse optimization tasks. The repository includes research papers, tutorials, workshops, competitions, and related collections related to LLMs in optimization. It covers a wide range of topics such as algorithm search, code generation, machine learning, science, industry, and more. The goal is to provide a comprehensive resource for researchers and practitioners interested in leveraging LLMs for optimization tasks.
Awesome-LLM-Strawberry
Awesome LLM Strawberry is a collection of research papers and blogs related to OpenAI Strawberry(o1) and Reasoning. The repository is continuously updated to track the frontier of LLM Reasoning.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.