
Mercury
Code Efficiency Benchmark
Stars: 89
Mercury is a code efficiency benchmark designed for code synthesis tasks. It includes 1,889 programming tasks of varying difficulty levels and provides test case generators for comprehensive evaluation. The benchmark aims to assess the efficiency of large language models in generating code solutions.
README:
- Welcome to Mercury!
- Mercury is the first code efficiency benchmark designed for code synthesis tasks.
- It consists of 1,889 programming tasks covering diverse difficulty levels, along with test case generators that produce unlimited cases for comprehensive evaluation.
[October 8, 2024] Mercury has been accepted to NeurIPS 2024 🌟
[September 20, 2024] We release a way bigger dataset Venus, which supports more languages. It also provides Memory measurement other than Time.
[July 10, 2024] We are building Code Arena now for more efficient Code LLMs evaluation!
[June 24, 2024] We are currently working on the Multilingual Mercury 🚧
[May 26, 2024] Mercury is now available on BigCode 🌟
We publish and maintain our datasets at Mercury@HF
# Option 1 (with BigCode):
# See https://github.com/bigcode-project/bigcode-evaluation-harness/tree/main/docs#mercury
accelerate launch --main_process_port 30003 main.py \
--model bigcode/starcoder2-7b \
--load_in_4bit \
--max_length_generation 2048 \
--tasks mercury \
--n_samples 5 \
--temperature 0.2 \
--batch_size 5 \
--allow_code_execution \
--save_generations \
--metric_output_path starcoder2-7b-mercury-result.json# Option 2 (this library):
import os
os.environ["OPENAI_API_KEY"] = 'YOUR_OPENAI_KEY'
# Instantiate evaluator with model_name
# Set do_generate to True if you are going to load the specific language model during evaluator initialization.
from src import evaluator as Evaluator
evaluator = Evaluator.DistributeWiseEvaluator(model_name_or_path='openai/gpt-3.5-turbo-1106', do_generate=True)
# Generate code samples
evaluator.generate(num_samples_per_task=1)
# Evaluate code samples using the Mercury benchmark
evaluator.evaluate(num_samples_per_task=1)@inproceedings{du2024mercury,
title={Mercury: A code efficiency benchmark for code large language models},
author={Du, Mingzhe and Luu, Anh Tuan and Ji, Bin and Liu, Qian and Ng, See-Kiong},
booktitle={The Thirty-eight Conference on Neural Information Processing Systems Datasets and Benchmarks Track},
year={2024}
}
Should you have any questions regarding this paper, please feel free to email us ([email protected]). Thank you for your attention!
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for Mercury
Similar Open Source Tools
Mercury
Mercury is a code efficiency benchmark designed for code synthesis tasks. It includes 1,889 programming tasks of varying difficulty levels and provides test case generators for comprehensive evaluation. The benchmark aims to assess the efficiency of large language models in generating code solutions.

rl
TorchRL is an open-source Reinforcement Learning (RL) library for PyTorch. It provides pytorch and **python-first** , low and high level abstractions for RL that are intended to be **efficient** , **modular** , **documented** and properly **tested**. The code is aimed at supporting research in RL. Most of it is written in python in a highly modular way, such that researchers can easily swap components, transform them or write new ones with little effort.

starwhale
Starwhale is an MLOps/LLMOps platform that brings efficiency and standardization to machine learning operations. It streamlines the model development lifecycle, enabling teams to optimize workflows around key areas like model building, evaluation, release, and fine-tuning. Starwhale abstracts Model, Runtime, and Dataset as first-class citizens, providing tailored capabilities for common workflow scenarios including Models Evaluation, Live Demo, and LLM Fine-tuning. It is an open-source platform designed for clarity and ease of use, empowering developers to build customized MLOps features tailored to their needs.
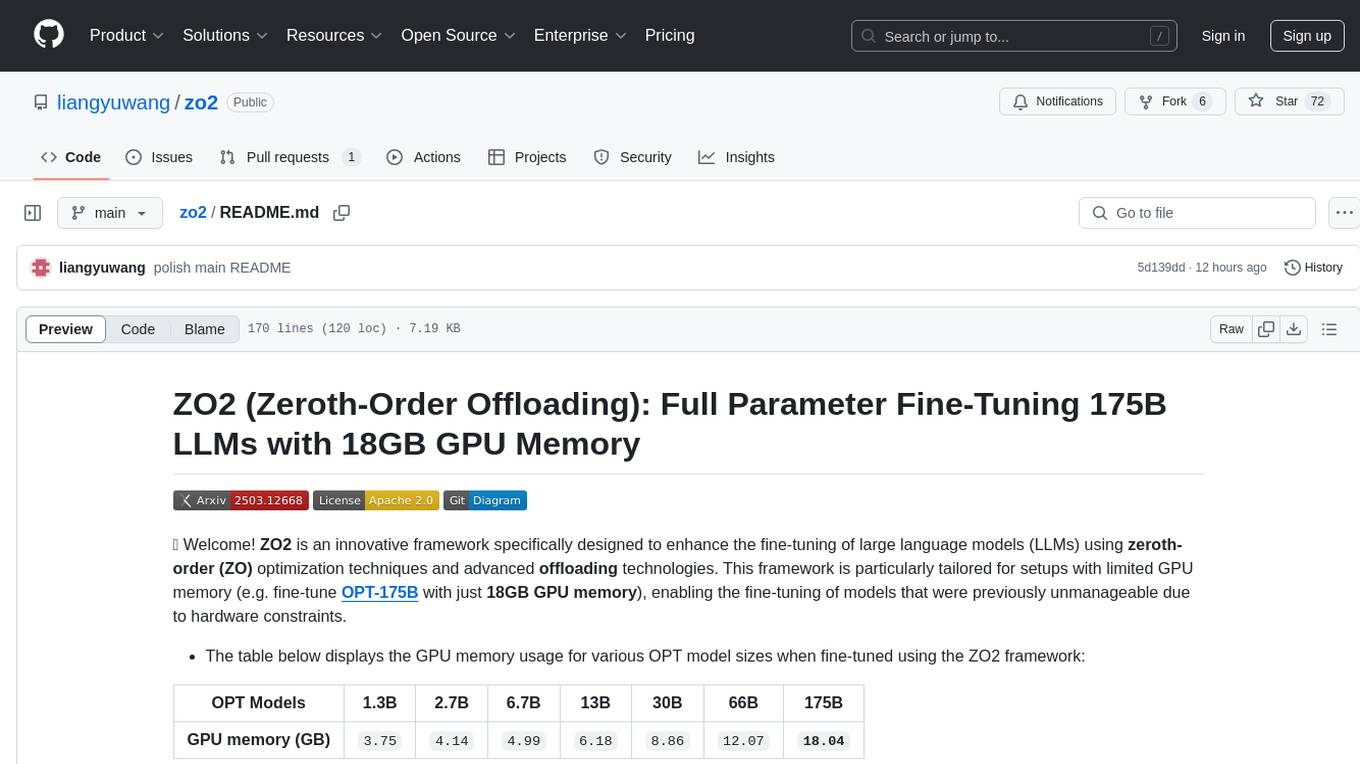
zo2
ZO2 (Zeroth-Order Offloading) is an innovative framework designed to enhance the fine-tuning of large language models (LLMs) using zeroth-order (ZO) optimization techniques and advanced offloading technologies. It is tailored for setups with limited GPU memory, enabling the fine-tuning of models with over 175 billion parameters on single GPUs with as little as 18GB of memory. ZO2 optimizes CPU offloading, incorporates dynamic scheduling, and has the capability to handle very large models efficiently without extra time costs or accuracy losses.

MathVerse
MathVerse is an all-around visual math benchmark designed to evaluate the capabilities of Multi-modal Large Language Models (MLLMs) in visual math problem-solving. It collects high-quality math problems with diagrams to assess how well MLLMs can understand visual diagrams for mathematical reasoning. The benchmark includes 2,612 problems transformed into six versions each, contributing to 15K test samples. It also introduces a Chain-of-Thought (CoT) Evaluation strategy for fine-grained assessment of output answers.

DeepResearch
Tongyi DeepResearch is an agentic large language model with 30.5 billion total parameters, designed for long-horizon, deep information-seeking tasks. It demonstrates state-of-the-art performance across various search benchmarks. The model features a fully automated synthetic data generation pipeline, large-scale continual pre-training on agentic data, end-to-end reinforcement learning, and compatibility with two inference paradigms. Users can download the model directly from HuggingFace or ModelScope. The repository also provides benchmark evaluation scripts and information on the Deep Research Agent Family.
llmxcpg
LLMxCPG is a framework for vulnerability detection using Code Property Graphs (CPG) and Large Language Models (LLM). It involves a two-phase process: Slice Construction where an LLM generates queries for a CPG to extract a code slice, and Vulnerability Detection where another LLM classifies the code slice as vulnerable or safe. The repository includes implementations of baseline models, information on datasets, scripts for running models, prompt templates, query generation examples, and configurations for fine-tuning models.

mlflow
MLflow is a platform to streamline machine learning development, including tracking experiments, packaging code into reproducible runs, and sharing and deploying models. MLflow offers a set of lightweight APIs that can be used with any existing machine learning application or library (TensorFlow, PyTorch, XGBoost, etc), wherever you currently run ML code (e.g. in notebooks, standalone applications or the cloud). MLflow's current components are:
* `MLflow Tracking

DB-GPT
DB-GPT is a personal database administrator that can solve database problems by reading documents, using various tools, and writing analysis reports. It is currently undergoing an upgrade. **Features:** * **Online Demo:** * Import documents into the knowledge base * Utilize the knowledge base for well-founded Q&A and diagnosis analysis of abnormal alarms * Send feedbacks to refine the intermediate diagnosis results * Edit the diagnosis result * Browse all historical diagnosis results, used metrics, and detailed diagnosis processes * **Language Support:** * English (default) * Chinese (add "language: zh" in config.yaml) * **New Frontend:** * Knowledgebase + Chat Q&A + Diagnosis + Report Replay * **Extreme Speed Version for localized llms:** * 4-bit quantized LLM (reducing inference time by 1/3) * vllm for fast inference (qwen) * Tiny LLM * **Multi-path extraction of document knowledge:** * Vector database (ChromaDB) * RESTful Search Engine (Elasticsearch) * **Expert prompt generation using document knowledge** * **Upgrade the LLM-based diagnosis mechanism:** * Task Dispatching -> Concurrent Diagnosis -> Cross Review -> Report Generation * Synchronous Concurrency Mechanism during LLM inference * **Support monitoring and optimization tools in multiple levels:** * Monitoring metrics (Prometheus) * Flame graph in code level * Diagnosis knowledge retrieval (dbmind) * Logical query transformations (Calcite) * Index optimization algorithms (for PostgreSQL) * Physical operator hints (for PostgreSQL) * Backup and Point-in-time Recovery (Pigsty) * **Continuously updated papers and experimental reports** This project is constantly evolving with new features. Don't forget to star ⭐ and watch 👀 to stay up to date.

CodeGeeX4
CodeGeeX4-ALL-9B is an open-source multilingual code generation model based on GLM-4-9B, offering enhanced code generation capabilities. It supports functions like code completion, code interpreter, web search, function call, and repository-level code Q&A. The model has competitive performance on benchmarks like BigCodeBench and NaturalCodeBench, outperforming larger models in terms of speed and performance.

sdialog
SDialog is an MIT-licensed open-source toolkit for building, simulating, and evaluating LLM-based conversational agents end-to-end. It aims to bridge agent construction, user simulation, dialog generation, and evaluation in a single reproducible workflow, enabling the generation of reliable, controllable dialog systems or data at scale. The toolkit standardizes a Dialog schema, offers persona-driven multi-agent simulation with LLMs, provides composable orchestration for precise control over behavior and flow, includes built-in evaluation metrics, and offers mechanistic interpretability. It allows for easy creation of user-defined components and interoperability across various AI platforms.
Eco2AI
Eco2AI is a python library for CO2 emission tracking that monitors energy consumption of CPU & GPU devices and estimates equivalent carbon emissions based on regional emission coefficients. Users can easily integrate Eco2AI into their Python scripts by adding a few lines of code. The library records emissions data and device information in a local file, providing detailed session logs with project names, experiment descriptions, start times, durations, power consumption, CO2 emissions, CPU and GPU names, operating systems, and countries.
Endia
Endia is a dynamic Array library for Scientific Computing, offering automatic differentiation of arbitrary order, complex number support, dual API with PyTorch-like imperative or JAX-like functional interface, and JIT Compilation for speeding up training and inference. It can handle complex valued functions, perform both forward and reverse-mode automatic differentiation, and has a builtin JIT compiler. Endia aims to advance AI & Scientific Computing by pushing boundaries with clear algorithms, providing high-performance open-source code that remains readable and pythonic, and prioritizing clarity and educational value over exhaustive features.
mobius
Mobius is an AI infra platform including realtime computing and training. It is built on Ray, a distributed computing framework, and provides a number of features that make it well-suited for online machine learning tasks. These features include: * **Cross Language**: Mobius can run in multiple languages (only Python and Java are supported currently) with high efficiency. You can implement your operator in different languages and run them in one job. * **Single Node Failover**: Mobius has a special failover mechanism that only needs to rollback the failed node itself, in most cases, to recover the job. This is a huge benefit if your job is sensitive about failure recovery time. * **AutoScaling**: Mobius can generate a new graph with different configurations in runtime without stopping the job. * **Fusion Training**: Mobius can combine TensorFlow/Pytorch and streaming, then building an e2e online machine learning pipeline. Mobius is still under development, but it has already been used to power a number of real-world applications, including: * A real-time recommendation system for a major e-commerce company * A fraud detection system for a large financial institution * A personalized news feed for a major news organization If you are interested in using Mobius for your own online machine learning projects, you can find more information in the documentation.
BIRD-CRITIC-1
BIRD-CRITIC 1.0 is a SQL benchmark designed to evaluate the capability of large language models (LLMs) in diagnosing and solving user issues within real-world database environments. It comprises 600 tasks for development and 200 held-out out-of-distribution tests across 4 prominent open-source SQL dialects. The benchmark expands beyond simple SELECT queries to cover a wider range of SQL operations, reflecting actual application scenarios. An optimized execution-based evaluation environment is included for rigorous and efficient validation.
LLM4Decompile
LLM4Decompile is an open-source large language model dedicated to decompilation of Linux x86_64 binaries, supporting GCC's O0 to O3 optimization levels. It focuses on assessing re-executability of decompiled code through HumanEval-Decompile benchmark. The tool includes models with sizes ranging from 1.3 billion to 33 billion parameters, available on Hugging Face. Users can preprocess C code into binary and assembly instructions, then decompile assembly instructions into C using LLM4Decompile. Ongoing efforts aim to expand capabilities to support more architectures and configurations, integrate with decompilation tools like Ghidra and Rizin, and enhance performance with larger training datasets.
For similar tasks

HuggingFists
HuggingFists is a low-code data flow tool that enables convenient use of LLM and HuggingFace models. It provides functionalities similar to Langchain, allowing users to design, debug, and manage data processing workflows, create and schedule workflow jobs, manage resources environment, and handle various data artifact resources. The tool also offers account management for users, allowing centralized management of data source accounts and API accounts. Users can access Hugging Face models through the Inference API or locally deployed models, as well as datasets on Hugging Face. HuggingFists supports breakpoint debugging, branch selection, function calls, workflow variables, and more to assist users in developing complex data processing workflows.
Mercury
Mercury is a code efficiency benchmark designed for code synthesis tasks. It includes 1,889 programming tasks of varying difficulty levels and provides test case generators for comprehensive evaluation. The benchmark aims to assess the efficiency of large language models in generating code solutions.

bigcodebench
BigCodeBench is an easy-to-use benchmark for code generation with practical and challenging programming tasks. It aims to evaluate the true programming capabilities of large language models (LLMs) in a more realistic setting. The benchmark is designed for HumanEval-like function-level code generation tasks, but with much more complex instructions and diverse function calls. BigCodeBench focuses on the evaluation of LLM4Code with diverse function calls and complex instructions, providing precise evaluation & ranking and pre-generated samples to accelerate code intelligence research. It inherits the design of the EvalPlus framework but differs in terms of execution environment and test evaluation.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

onnxruntime-genai
ONNX Runtime Generative AI is a library that provides the generative AI loop for ONNX models, including inference with ONNX Runtime, logits processing, search and sampling, and KV cache management. Users can call a high level `generate()` method, or run each iteration of the model in a loop. It supports greedy/beam search and TopP, TopK sampling to generate token sequences, has built in logits processing like repetition penalties, and allows for easy custom scoring.

mistral.rs
Mistral.rs is a fast LLM inference platform written in Rust. We support inference on a variety of devices, quantization, and easy-to-use application with an Open-AI API compatible HTTP server and Python bindings.
generative-ai-python
The Google AI Python SDK is the easiest way for Python developers to build with the Gemini API. The Gemini API gives you access to Gemini models created by Google DeepMind. Gemini models are built from the ground up to be multimodal, so you can reason seamlessly across text, images, and code.

jetson-generative-ai-playground
This repo hosts tutorial documentation for running generative AI models on NVIDIA Jetson devices. The documentation is auto-generated and hosted on GitHub Pages using their CI/CD feature to automatically generate/update the HTML documentation site upon new commits.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.