
DriveLM
[ECCV 2024 Oral] DriveLM: Driving with Graph Visual Question Answering
Stars: 917
DriveLM is a multimodal AI model that enables autonomous driving by combining computer vision and natural language processing. It is designed to understand and respond to complex driving scenarios using visual and textual information. DriveLM can perform various tasks related to driving, such as object detection, lane keeping, and decision-making. It is trained on a massive dataset of images and text, which allows it to learn the relationships between visual cues and driving actions. DriveLM is a powerful tool that can help to improve the safety and efficiency of autonomous vehicles.
README:

DriveLM: Driving with Graph Visual Question Answering
Autonomous Driving Challenge 2024 Driving-with-Language Leaderboard.
https://github.com/OpenDriveLab/DriveLM/assets/54334254/cddea8d6-9f6e-4e7e-b926-5afb59f8dce2
🔥 We instantiate datasets (DriveLM-Data) built upon nuScenes and CARLA, and propose a VLM-based baseline approach (DriveLM-Agent) for jointly performing Graph VQA and end-to-end driving.
🏁 DriveLM serves as a main track in the CVPR 2024 Autonomous Driving Challenge. Everything you need for the challenge is HERE, including baseline, test data and submission format and evaluation pipeline!

-
[2025/01/08]Drive-Bench release! In-depth analysis in what are DriveLM really benchmarking. Take a look at arxiv. -
[2024/07/16]DriveLM official leaderboard reopen! -
[2024/07/01]DriveLM got accepted to ECCV 2024! Congrats to the team! -
[2024/06/01]Challenge ended up! See the final leaderboard. -
[2024/03/25]Challenge test server is online and the test questions are released. Chekc it out! -
[2024/02/29]Challenge repo release. Baseline, data and submission format, evaluation pipeline. Have a look! -
[2023/08/25]DriveLM-nuScenes demo released. -
[2023/12/22]DriveLM-nuScenes fullv1.0and paper released.
- Highlights
- Getting Started
- Current Endeavors and Future Horizons
- TODO List
- DriveLM-Data
- License and Citation
- Other Resources
To get started with DriveLM:
- The advent of GPT-style multimodal models in real-world applications motivates the study of the role of language in driving.
- Date below reflects the arXiv submission date.
- If there is any missing work, please reach out to us!

DriveLM attempts to address some of the challenges faced by the community.
- Lack of data: DriveLM-Data serves as a comprehensive benchmark for driving with language.
- Embodiment: GVQA provides a potential direction for embodied applications of LLMs / VLMs.
- Closed-loop: DriveLM-CARLA attempts to explore closed-loop planning with language.
- [x] DriveLM-Data
- [x] DriveLM-nuScenes
- [x] DriveLM-CARLA
- [x] DriveLM-Metrics
- [x] GPT-score
- [ ] DriveLM-Agent
- [x] Inference code on DriveLM-nuScenes
- [ ] Inference code on DriveLM-CARLA
We facilitate the Perception, Prediction, Planning, Behavior, Motion tasks with human-written reasoning logic as a connection between them. We propose the task of GVQA on the DriveLM-Data.
DriveLM-Data is the first language-driving dataset facilitating the full stack of driving tasks with graph-structured logical dependencies.

Links to details about GVQA task, Dataset Features, and Annotation.
All assets and code in this repository are under the Apache 2.0 license unless specified otherwise. The language data is under CC BY-NC-SA 4.0. Other datasets (including nuScenes) inherit their own distribution licenses. Please consider citing our paper and project if they help your research.
@article{sima2023drivelm,
title={DriveLM: Driving with Graph Visual Question Answering},
author={Sima, Chonghao and Renz, Katrin and Chitta, Kashyap and Chen, Li and Zhang, Hanxue and Xie, Chengen and Luo, Ping and Geiger, Andreas and Li, Hongyang},
journal={arXiv preprint arXiv:2312.14150},
year={2023}
}@misc{contributors2023drivelmrepo,
title={DriveLM: Driving with Graph Visual Question Answering},
author={DriveLM contributors},
howpublished={\url{https://github.com/OpenDriveLab/DriveLM}},
year={2023}
}
OpenDriveLab

Autonomous Vision Group
- tuPlan garage | CARLA garage | Survey on E2EAD
- PlanT | KING | TransFuser | NEAT
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for DriveLM
Similar Open Source Tools
DriveLM
DriveLM is a multimodal AI model that enables autonomous driving by combining computer vision and natural language processing. It is designed to understand and respond to complex driving scenarios using visual and textual information. DriveLM can perform various tasks related to driving, such as object detection, lane keeping, and decision-making. It is trained on a massive dataset of images and text, which allows it to learn the relationships between visual cues and driving actions. DriveLM is a powerful tool that can help to improve the safety and efficiency of autonomous vehicles.

GPTSwarm
GPTSwarm is a graph-based framework for LLM-based agents that enables the creation of LLM-based agents from graphs and facilitates the customized and automatic self-organization of agent swarms with self-improvement capabilities. The library includes components for domain-specific operations, graph-related functions, LLM backend selection, memory management, and optimization algorithms to enhance agent performance and swarm efficiency. Users can quickly run predefined swarms or utilize tools like the file analyzer. GPTSwarm supports local LM inference via LM Studio, allowing users to run with a local LLM model. The framework has been accepted by ICML2024 and offers advanced features for experimentation and customization.

DeepResearch
Tongyi DeepResearch is an agentic large language model with 30.5 billion total parameters, designed for long-horizon, deep information-seeking tasks. It demonstrates state-of-the-art performance across various search benchmarks. The model features a fully automated synthetic data generation pipeline, large-scale continual pre-training on agentic data, end-to-end reinforcement learning, and compatibility with two inference paradigms. Users can download the model directly from HuggingFace or ModelScope. The repository also provides benchmark evaluation scripts and information on the Deep Research Agent Family.
rllm
rLLM (relationLLM) is a Pytorch library for Relational Table Learning (RTL) with LLMs. It breaks down state-of-the-art GNNs, LLMs, and TNNs as standardized modules and facilitates novel model building in a 'combine, align, and co-train' way using these modules. The library is LLM-friendly, processes various graphs as multiple tables linked by foreign keys, introduces new relational table datasets, and is supported by students and teachers from Shanghai Jiao Tong University and Tsinghua University.
WebMasterLog
WebMasterLog is a comprehensive repository showcasing various web development projects built with front-end and back-end technologies. It highlights interactive user interfaces, dynamic web applications, and a spectrum of web development solutions. The repository encourages contributions in areas such as adding new projects, improving existing projects, updating documentation, fixing bugs, implementing responsive design, enhancing code readability, and optimizing project functionalities. Contributors are guided to follow specific guidelines for project submissions, including directory naming conventions, README file inclusion, project screenshots, and commit practices. Pull requests are reviewed based on criteria such as proper PR template completion, originality of work, code comments for clarity, and sharing screenshots for frontend updates. The repository also participates in various open-source programs like JWOC, GSSoC, Hacktoberfest, KWOC, 24 Pull Requests, IWOC, SWOC, and DWOC, welcoming valuable contributors.
deepchecks
Deepchecks is a holistic open-source solution for AI & ML validation needs, enabling thorough testing of data and models from research to production. It includes components for testing, CI & testing management, and monitoring. Users can install and use Deepchecks for testing and monitoring their AI models, with customizable checks and suites for tabular, NLP, and computer vision data. The tool provides visual reports, pythonic/json output for processing, and a dynamic UI for collaboration and monitoring. Deepchecks is open source, with premium features available under a commercial license for monitoring components.
NExT-GPT
NExT-GPT is an end-to-end multimodal large language model that can process input and generate output in various combinations of text, image, video, and audio. It leverages existing pre-trained models and diffusion models with end-to-end instruction tuning. The repository contains code, data, and model weights for NExT-GPT, allowing users to work with different modalities and perform tasks like encoding, understanding, reasoning, and generating multimodal content.

nyxtext
Nyxtext is a text editor built using Python, featuring Custom Tkinter with the Catppuccin color scheme and glassmorphic design. It follows a modular approach with each element organized into separate files for clarity and maintainability. NyxText is not just a text editor but also an AI-powered desktop application for creatives, developers, and students.

superlinked
Superlinked is a compute framework for information retrieval and feature engineering systems, focusing on converting complex data into vector embeddings for RAG, Search, RecSys, and Analytics stack integration. It enables custom model performance in machine learning with pre-trained model convenience. The tool allows users to build multimodal vectors, define weights at query time, and avoid postprocessing & rerank requirements. Users can explore the computational model through simple scripts and python notebooks, with a future release planned for production usage with built-in data infra and vector database integrations.
AI-Infra-Guard
A.I.G (AI-Infra-Guard) is an AI red teaming platform by Tencent Zhuque Lab that integrates capabilities such as AI infra vulnerability scan, MCP Server risk scan, and Jailbreak Evaluation. It aims to provide users with a comprehensive, intelligent, and user-friendly solution for AI security risk self-examination. The platform offers features like AI Infra Scan, AI Tool Protocol Scan, and Jailbreak Evaluation, along with a modern web interface, complete API, multi-language support, cross-platform deployment, and being free and open-source under the MIT license.

VITA
VITA is an open-source interactive omni multimodal Large Language Model (LLM) capable of processing video, image, text, and audio inputs simultaneously. It stands out with features like Omni Multimodal Understanding, Non-awakening Interaction, and Audio Interrupt Interaction. VITA can respond to user queries without a wake-up word, track and filter external queries in real-time, and handle various query inputs effectively. The model utilizes state tokens and a duplex scheme to enhance the multimodal interactive experience.

X-AnyLabeling
X-AnyLabeling is a robust annotation tool that seamlessly incorporates an AI inference engine alongside an array of sophisticated features. Tailored for practical applications, it is committed to delivering comprehensive, industrial-grade solutions for image data engineers. This tool excels in swiftly and automatically executing annotations across diverse and intricate tasks.
project-blog
Welcome to the Blog Script Project, a collaborative platform for developers and writers to create, manage, and share content. With features like Markdown support, submodule integration, customizable templates, project contribution workflow, global visibility, community discussions, SEO optimization, and role-based dashboard, Blog Script enhances collaboration and visibility for your work. You can contribute by adding new projects, improving existing projects, updating documentation, fixing bugs, optimizing, and ensuring code readability. Follow the contribution guidelines to star the repository, find tasks, fork the repository, make changes, add screenshots, submit a pull request, and contribute to the open-source community. Additionally, you can add your project as a submodule by following the provided guidelines. Join us, contribute, and grow together!
PPTAgent
PPTAgent is an innovative system that automatically generates presentations from documents. It employs a two-step process for quality assurance and introduces PPTEval for comprehensive evaluation. With dynamic content generation, smart reference learning, and quality assessment, PPTAgent aims to streamline presentation creation. The tool follows an analysis phase to learn from reference presentations and a generation phase to develop structured outlines and cohesive slides. PPTEval evaluates presentations based on content accuracy, visual appeal, and logical coherence.
SoM-LLaVA
SoM-LLaVA is a new data source and learning paradigm for Multimodal LLMs, empowering open-source Multimodal LLMs with Set-of-Mark prompting and improved visual reasoning ability. The repository provides a new dataset that is complementary to existing training sources, enhancing multimodal LLMs with Set-of-Mark prompting and improved general capacity. By adding 30k SoM data to the visual instruction tuning stage of LLaVA, the tool achieves 1% to 6% relative improvements on all benchmarks. Users can train SoM-LLaVA via command line and utilize the implementation to annotate COCO images with SoM. Additionally, the tool can be loaded in Huggingface for further usage.

rl
TorchRL is an open-source Reinforcement Learning (RL) library for PyTorch. It provides pytorch and **python-first** , low and high level abstractions for RL that are intended to be **efficient** , **modular** , **documented** and properly **tested**. The code is aimed at supporting research in RL. Most of it is written in python in a highly modular way, such that researchers can easily swap components, transform them or write new ones with little effort.
For similar tasks
DriveLM
DriveLM is a multimodal AI model that enables autonomous driving by combining computer vision and natural language processing. It is designed to understand and respond to complex driving scenarios using visual and textual information. DriveLM can perform various tasks related to driving, such as object detection, lane keeping, and decision-making. It is trained on a massive dataset of images and text, which allows it to learn the relationships between visual cues and driving actions. DriveLM is a powerful tool that can help to improve the safety and efficiency of autonomous vehicles.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

openvino
OpenVINO™ is an open-source toolkit for optimizing and deploying AI inference. It provides a common API to deliver inference solutions on various platforms, including CPU, GPU, NPU, and heterogeneous devices. OpenVINO™ supports pre-trained models from Open Model Zoo and popular frameworks like TensorFlow, PyTorch, and ONNX. Key components of OpenVINO™ include the OpenVINO™ Runtime, plugins for different hardware devices, frontends for reading models from native framework formats, and the OpenVINO Model Converter (OVC) for adjusting models for optimal execution on target devices.
djl-demo
The Deep Java Library (DJL) is a framework-agnostic Java API for deep learning. It provides a unified interface to popular deep learning frameworks such as TensorFlow, PyTorch, and MXNet. DJL makes it easy to develop deep learning applications in Java, and it can be used for a variety of tasks, including image classification, object detection, natural language processing, and speech recognition.
nnstreamer
NNStreamer is a set of Gstreamer plugins that allow Gstreamer developers to adopt neural network models easily and efficiently and neural network developers to manage neural network pipelines and their filters easily and efficiently.
cortex
Nitro is a high-efficiency C++ inference engine for edge computing, powering Jan. It is lightweight and embeddable, ideal for product integration. The binary of nitro after zipped is only ~3mb in size with none to minimal dependencies (if you use a GPU need CUDA for example) make it desirable for any edge/server deployment.
PyTorch-Tutorial-2nd
The second edition of "PyTorch Practical Tutorial" was completed after 5 years, 4 years, and 2 years. On the basis of the essence of the first edition, rich and detailed deep learning application cases and reasoning deployment frameworks have been added, so that this book can more systematically cover the knowledge involved in deep learning engineers. As the development of artificial intelligence technology continues to emerge, the second edition of "PyTorch Practical Tutorial" is not the end, but the beginning, opening up new technologies, new fields, and new chapters. I hope to continue learning and making progress in artificial intelligence technology with you in the future.
CVPR2024-Papers-with-Code-Demo
This repository contains a collection of papers and code for the CVPR 2024 conference. The papers cover a wide range of topics in computer vision, including object detection, image segmentation, image generation, and video analysis. The code provides implementations of the algorithms described in the papers, making it easy for researchers and practitioners to reproduce the results and build upon the work of others. The repository is maintained by a team of researchers at the University of California, Berkeley.
For similar jobs
DriveLM
DriveLM is a multimodal AI model that enables autonomous driving by combining computer vision and natural language processing. It is designed to understand and respond to complex driving scenarios using visual and textual information. DriveLM can perform various tasks related to driving, such as object detection, lane keeping, and decision-making. It is trained on a massive dataset of images and text, which allows it to learn the relationships between visual cues and driving actions. DriveLM is a powerful tool that can help to improve the safety and efficiency of autonomous vehicles.
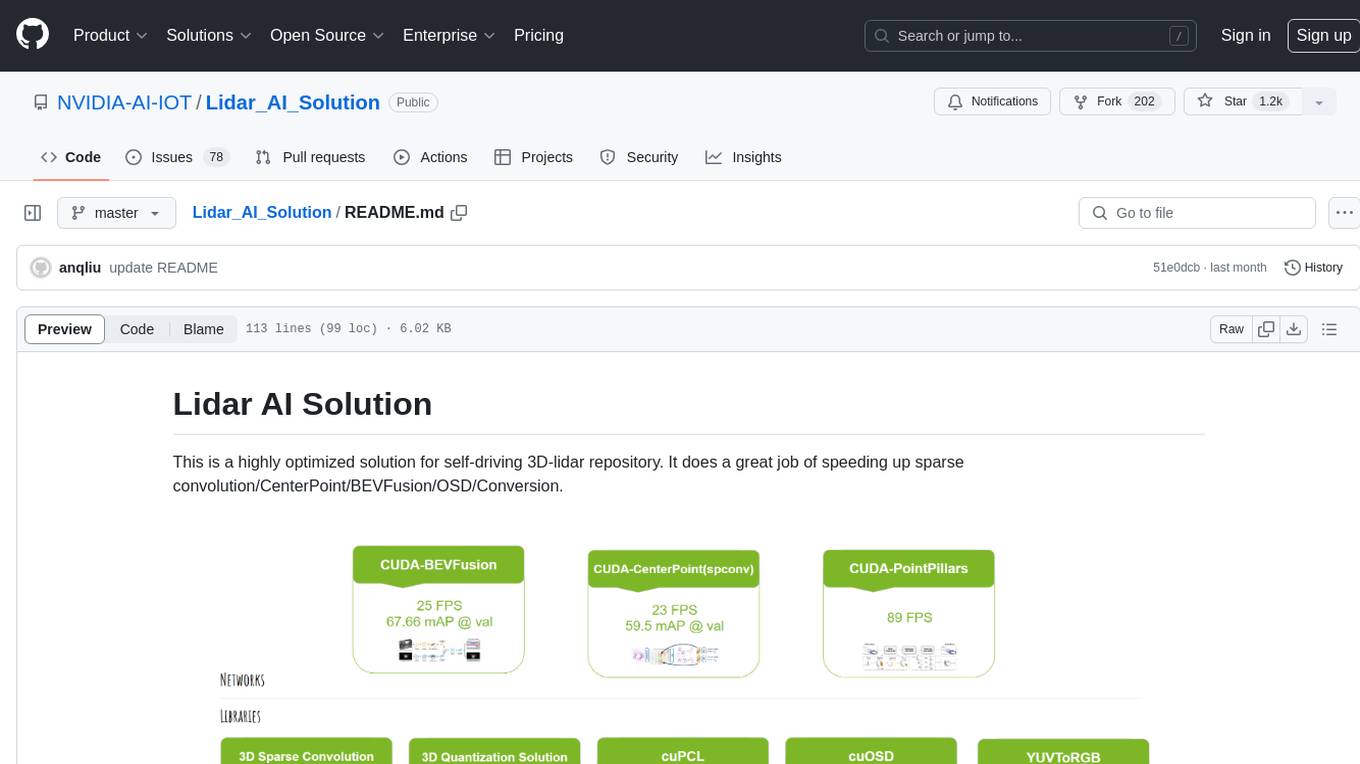
Lidar_AI_Solution
Lidar AI Solution is a highly optimized repository for self-driving 3D lidar, providing solutions for sparse convolution, BEVFusion, CenterPoint, OSD, and Conversion. It includes CUDA and TensorRT implementations for various tasks such as 3D sparse convolution, BEVFusion, CenterPoint, PointPillars, V2XFusion, cuOSD, cuPCL, and YUV to RGB conversion. The repository offers easy-to-use solutions, high accuracy, low memory usage, and quantization options for different tasks related to self-driving technology.
AirSLAM
AirSLAM is an efficient visual SLAM system designed to tackle short-term and long-term illumination challenges. It combines deep learning techniques with traditional optimization methods, featuring a unified CNN for keypoint and structural line extraction. The system includes a relocalization pipeline for map reuse, accelerated using C++ and NVIDIA TensorRT. Outperforming other SLAM systems in challenging environments, it runs at 73Hz on PC and 40Hz on embedded platforms.
sdk-examples
Spectacular AI SDK fuses data from cameras and IMU sensors to output an accurate 6-degree-of-freedom pose of a device, enabling Visual-Inertial SLAM for tracking robots and vehicles, as well as Augmented, Mixed, and Virtual Reality. The SDK includes a Mapping API for real-time and offline 3D reconstruction use cases.

awesome-and-novel-works-in-slam
This repository contains a curated list of cutting-edge works in Simultaneous Localization and Mapping (SLAM). It includes research papers, projects, and tools related to various aspects of SLAM, such as 3D reconstruction, semantic mapping, novel algorithms, large-scale mapping, and more. The repository aims to showcase the latest advancements in SLAM technology and provide resources for researchers and practitioners in the field.
retinify
Retinify is an advanced AI-powered stereo vision library designed for robotics, enabling real-time, high-precision 3D perception by leveraging GPU and NPU acceleration. It is open source under Apache-2.0 license, offers high precision 3D mapping and object recognition, runs computations on GPU for fast performance, accepts stereo images from any rectified camera setup, is cost-efficient using minimal hardware, and has minimal dependencies on CUDA Toolkit, cuDNN, and TensorRT. The tool provides a pipeline for stereo matching and supports various image data types independently of OpenCV.
Autopilot-Notes
Autopilot Notes is an open-source knowledge base for systematically learning autonomous driving technology. It covers basic theory, hardware, algorithms, tools, and practical engineering practices across 10+ chapters. The repository provides daily updates on industry trends, in-depth analysis of mainstream solutions like Tesla, Baidu Apollo, and Openpilot, and hands-on content including simulation, deployment, and optimization. Contributors are welcome to submit pull requests to improve the documentation.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.