
Lidar_AI_Solution
A project demonstrating Lidar related AI solutions, including three GPU accelerated Lidar/camera DL networks (PointPillars, CenterPoint, BEVFusion) and the related libs (cuPCL, 3D SparseConvolution, YUV2RGB, cuOSD,).
Stars: 1181
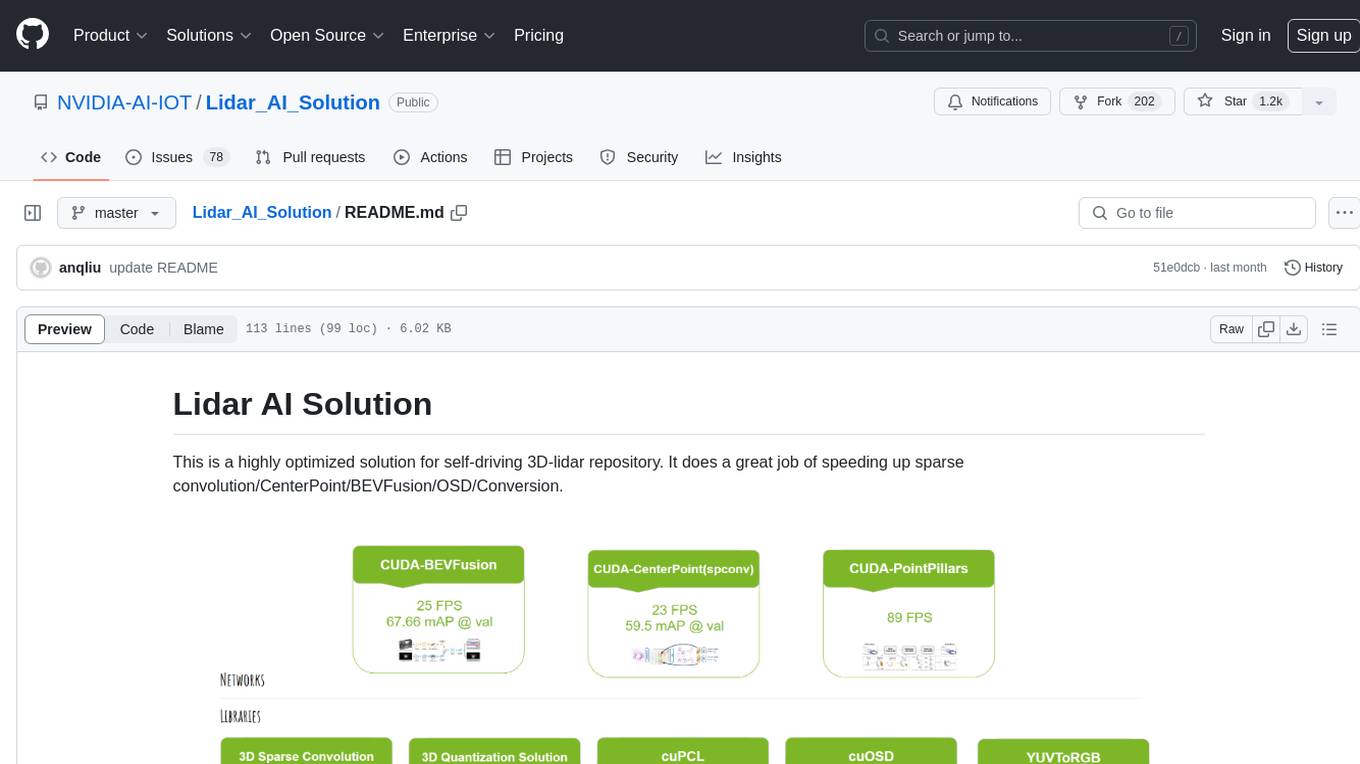
Lidar AI Solution is a highly optimized repository for self-driving 3D lidar, providing solutions for sparse convolution, BEVFusion, CenterPoint, OSD, and Conversion. It includes CUDA and TensorRT implementations for various tasks such as 3D sparse convolution, BEVFusion, CenterPoint, PointPillars, V2XFusion, cuOSD, cuPCL, and YUV to RGB conversion. The repository offers easy-to-use solutions, high accuracy, low memory usage, and quantization options for different tasks related to self-driving technology.
README:
This is a highly optimized solution for self-driving 3D-lidar repository. It does a great job of speeding up sparse convolution/CenterPoint/BEVFusion/OSD/Conversion.


$ git clone --recursive https://github.com/NVIDIA-AI-IOT/Lidar_AI_Solution
$ cd Lidar_AI_Solution
- For each specific task please refer to the readme in the sub-folder.
A tiny inference engine for 3d sparse convolutional networks using int8/fp16.
- Tiny Engine: Tiny Lidar-Backbone inference engine independent of TensorRT.
- Flexible: Build execution graph from ONNX.
- Easy To Use: Simple interface and onnx export solution.
- High Fidelity: Low accuracy drop on nuScenes validation.
- Low Memory: 422MB@SCN FP16, 426MB@SCN INT8.
- Compact: Based on the CUDA kernels and independent of cutlass.
CUDA & TensorRT solution for BEVFusion inference, including:
- Camera Encoder: ResNet50 and finetuned BEV pooling with TensorRT and onnx export solution.
- Lidar Encoder: Tiny Lidar-Backbone inference independent of TensorRT and onnx export solution.
- Feature Fusion: Camera & Lidar feature fuser with TensorRT and onnx export solution.
- Pre/Postprocess: Interval precomputing, lidar voxelization, feature decoder with CUDA kernels.
- Easy To Use: Preparation, inference, evaluation all in one to reproduce torch Impl accuracy.
- PTQ: Quantization solutions for mmdet3d/spconv, Easy to understand.
CUDA & TensorRT solution for CenterPoint inference, including:
- Preprocess: Voxelization with CUDA kernel
- Encoder: 3D backbone with NV spconv-scn and onnx export solution.
- Neck & Header: RPN & CenterHead with TensorRT and onnx export solution.
- Postprocess: Decode & NMS with CUDA kernel
- Easy To Use: Preparation, inference, evaluation all in one to reproduce torch Impl accuracy.
- QAT: Quantization solutions for traveller59/spconv, Easy to understand.
CUDA & TensorRT solution for pointpillars inference, including:
- Preprocess: Voxelization & Feature Extending with CUDA kernel
- Detector: 2.5D backbone with TensorRT and onnx export solution.
- Postprocess: Parse bounding box, class type and direction
- Easy To Use: Preparation, inference, evaluation all in one to reproduce torch Impl accuracy.
Training and inference solutions for V2XFusion.
- Easy To Use: Provides easily reproducible solutions for training, quantization, and ONNX export.
- Quantification friendly:PointPillars based backbone with pre-normalization which can reduce quantization error.
- Feature Fusion: Camera & Lidar feature fuser and onnx export solution.
- PTQ: Quantization solutions for V2XFusion, easy to understand.
- Sparsity: 4:2 structural sparsity support.
- Deepstream sample: Sample inference using CUDA, TensorRT/Triton in NVIDIA DeepStream SDK 7.0.
Draw all elements using a single CUDA kernel.
- Line: Plotting lines by interpolation(Nearest or Linear).
- RotateBox: Supports drawn with different border colors and fill colors.
- Circle: Supports drawn with different border colors and fill colors.
- Rectangle: Supports drawn with different border colors and fill colors.
- Text: Supports stb_truetype and pango-cairo backends, allowing fonts to be read via TTF or using font-family.
- Arrow: Combination of arrows by 3 lines.
- Point: Plotting points by interpolation(Nearest or Linear).
- Clock: Time plotting based on text support
Provide several GPU accelerated Point Cloud operations with high accuracy and high performance at the same time: cuICP, cuFilter, cuSegmentation, cuOctree, cuCluster, cuNDT, Voxelization(incoming).
- cuICP: CUDA accelerated iterative corresponding point vertex cloud(point-to-point) registration implementation.
- cuFilter: Support CUDA accelerated features: PassThrough and VoxelGrid.
- cuSegmentation: Support CUDA accelerated features: RandomSampleConsensus with a plane model.
- cuOctree: Support CUDA accelerated features: Approximate Nearest Search and Radius Search.
- cuCluster: Support CUDA accelerated features: Cluster based on the distance among points.
- cuNDT: CUDA accelerated 3D Normal Distribution Transform registration implementation for point cloud data.
YUV to RGB conversion. Combine Resize/Padding/Conversion/Normalization into a single kernel function.
-
Most of the time, it can be bit-aligned with OpenCV.
- It will give an exact result when the scaling factor is a rational number.
- Better performance is usually achieved when the stride can divide by 4.
- Supported Input Format:
- NV12BlockLinear
- NV12PitchLinear
- YUV422Packed_YUYV
- Supported Interpolation methods:
- Nearest
- Bilinear
- Supported Output Data Type:
- Uint8
- Float32
- Float16
- Supported Output Layout:
- CHW_RGB/BGR
- HWC_RGB/BGR
- CHW16/32/4/RGB/BGR for DLA input
- Supported Features:
- Resize
- Padding
- Conversion
- Normalization
This project makes use of a number of awesome open source libraries, including:
- stb_image for PNG and JPEG support
- pybind11 for seamless C++ / Python interop
- and others! See the dependencies folder.
Many thanks to the authors of these brilliant projects!
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for Lidar_AI_Solution
Similar Open Source Tools
Lidar_AI_Solution
Lidar AI Solution is a highly optimized repository for self-driving 3D lidar, providing solutions for sparse convolution, BEVFusion, CenterPoint, OSD, and Conversion. It includes CUDA and TensorRT implementations for various tasks such as 3D sparse convolution, BEVFusion, CenterPoint, PointPillars, V2XFusion, cuOSD, cuPCL, and YUV to RGB conversion. The repository offers easy-to-use solutions, high accuracy, low memory usage, and quantization options for different tasks related to self-driving technology.
VisioFirm
VisioFirm is an open-source, AI-powered image annotation tool designed to accelerate labeling for computer vision tasks like classification, object detection, oriented bounding boxes (OBB), segmentation and video annotation. Built for speed and simplicity, it leverages state-of-the-art models for semi-automated pre-annotations, allowing you to focus on refining rather than starting from scratch. Whether you're preparing datasets for YOLO, SAM, or custom models, VisioFirm streamlines your workflow with an intuitive web interface and powerful backend. Perfect for researchers, data scientists, and ML engineers handling large image datasets—get high-quality annotations in minutes, not hours!

transformerlab-app
Transformer Lab is an app that allows users to experiment with Large Language Models by providing features such as one-click download of popular models, finetuning across different hardware, RLHF and Preference Optimization, working with LLMs across different operating systems, chatting with models, using different inference engines, evaluating models, building datasets for training, calculating embeddings, providing a full REST API, running in the cloud, converting models across platforms, supporting plugins, embedded Monaco code editor, prompt editing, inference logs, all through a simple cross-platform GUI.
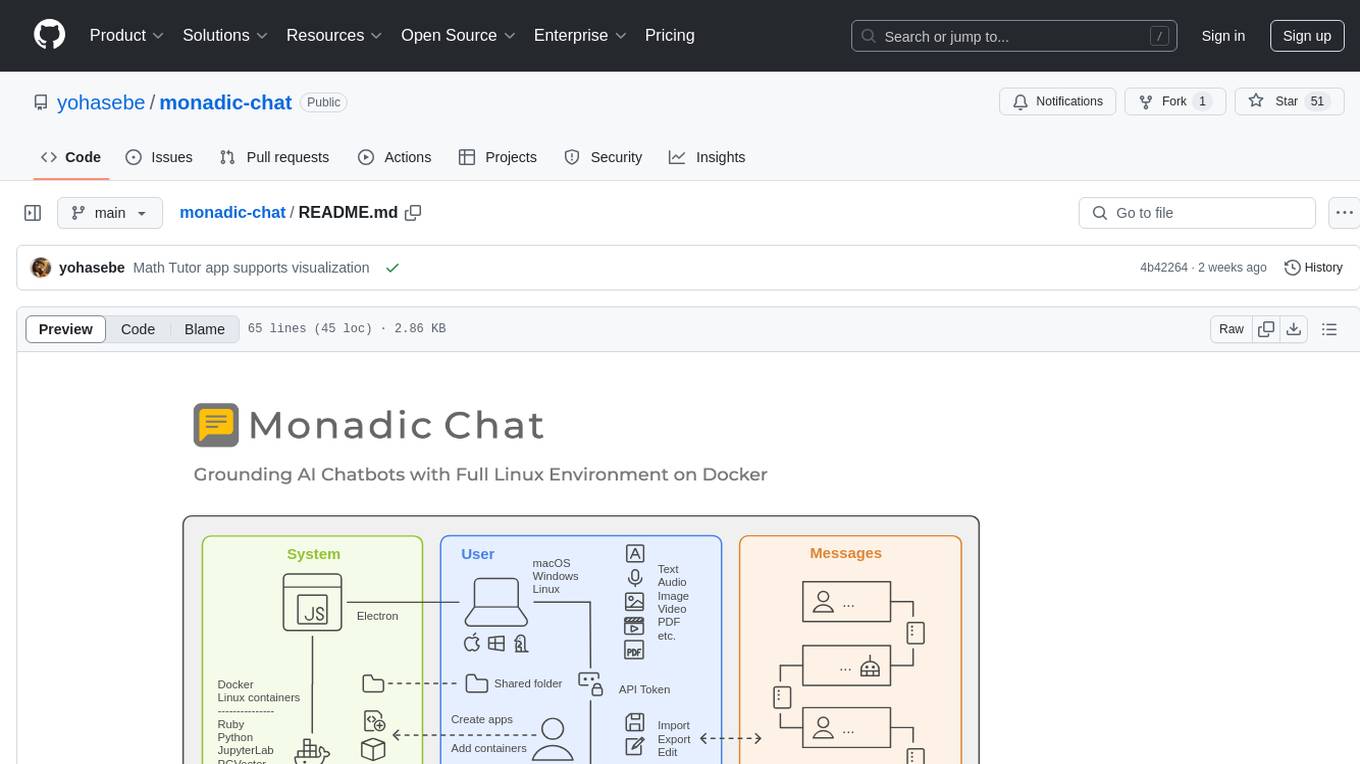
monadic-chat
Monadic Chat is a locally hosted web application designed to create and utilize intelligent chatbots. It provides a Linux environment on Docker to GPT and other LLMs, enabling the execution of advanced tasks that require external tools. The tool supports voice interaction, image and video recognition and generation, and AI-to-AI chat, making it useful for using AI and developing various applications. It is available for Mac, Windows, and Linux (Debian/Ubuntu) with easy-to-use installers.

tensorzero
TensorZero is an open-source platform that helps LLM applications graduate from API wrappers into defensible AI products. It enables a data & learning flywheel for LLMs by unifying inference, observability, optimization, and experimentation. The platform includes a high-performance model gateway, structured schema-based inference, observability, experimentation, and data warehouse for analytics. TensorZero Recipes optimize prompts and models, and the platform supports experimentation features and GitOps orchestration for deployment.
Open-WebUI-Functions
Open-WebUI-Functions is a collection of Python-based functions that extend Open WebUI with custom pipelines, filters, and integrations. Users can interact with AI models, process data efficiently, and customize the Open WebUI experience. It includes features like custom pipelines, data processing filters, Azure AI support, N8N workflow integration, flexible configuration, secure API key management, and support for both streaming and non-streaming processing. The functions require an active Open WebUI instance, may need external AI services like Azure AI, and admin access for installation. Security features include automatic encryption of sensitive information like API keys. Pipelines include Azure AI Foundry, N8N, Infomaniak, and Google Gemini. Filters like Time Token Tracker measure response time and token usage. Integrations with Azure AI, N8N, Infomaniak, and Google are supported. Contributions are welcome, and the project is licensed under Apache License 2.0.
Zettelgarden
Zettelgarden is a human-centric, open-source personal knowledge management system that helps users develop and maintain their understanding of the world. It focuses on creating and connecting atomic notes, thoughtful AI integration, and scalability from personal notes to company knowledge bases. The project is actively evolving, with features subject to change based on community feedback and development priorities.
kserve
KServe provides a Kubernetes Custom Resource Definition for serving predictive and generative machine learning (ML) models. It encapsulates the complexity of autoscaling, networking, health checking, and server configuration to bring cutting edge serving features like GPU Autoscaling, Scale to Zero, and Canary Rollouts to ML deployments. KServe enables a simple, pluggable, and complete story for Production ML Serving including prediction, pre-processing, post-processing, and explainability. It is a standard, cloud agnostic Model Inference Platform for serving predictive and generative AI models on Kubernetes, built for highly scalable use cases.
sparka
Sparka AI is a multi-provider AI chat tool that allows users to access various AI models like Claude, GPT-5, Gemini, and Grok through a single interface. It offers features such as document analysis, image generation, code execution, and research tools without the need for multiple subscriptions. The tool is open-source, production-ready, and provides capabilities for collaboration, secure authentication, attachment support, AI-powered image generation, syntax highlighting, resumable streams, chat branching, chat sharing, deep research, code execution, document creation, and web analytics. Built with modern technologies for scalability and performance, Sparka AI integrates with Vercel AI SDK, tRPC, Drizzle ORM, PostgreSQL, Redis, and AI SDK Gateway.
LLM-Scratch
LLM-Scratch is a minimal implementation of a GPT-style Large Language Model built from scratch using PyTorch. It utilizes BPE tokenization, multi head self-attention, feed-forward layers, and layer normalization. The model is designed for learning and experimentation purposes, focusing on autoregressive text generation. The codebase is clean, modular, and extensible, with a character-level tokenizer for easy understanding and no external dependencies like BPE or SentencePiece. The model architecture includes token embedding, positional embedding, transformer blocks with masked self-attention, feed-forward network, residual connections, layer normalization, and a language modeling head. Training objective involves next-token prediction using Cross-Entropy Loss and AdamW optimizer, with training data sampled in fixed-length blocks and gradients backpropagated through time. Configuration parameters are centralized for easy experimentation and reproducibility.
aider-desk
AiderDesk is a desktop application that enhances coding workflow by leveraging AI capabilities. It offers an intuitive GUI, project management, IDE integration, MCP support, settings management, cost tracking, structured messages, visual file management, model switching, code diff viewer, one-click reverts, and easy sharing. Users can install it by downloading the latest release and running the executable. AiderDesk also supports Python version detection and auto update disabling. It includes features like multiple project management, context file management, model switching, chat mode selection, question answering, cost tracking, MCP server integration, and MCP support for external tools and context. Development setup involves cloning the repository, installing dependencies, running in development mode, and building executables for different platforms. Contributions from the community are welcome following specific guidelines.
ComfyUI-Ollama-Describer
ComfyUI-Ollama-Describer is an extension for ComfyUI that enables the use of LLM models provided by Ollama, such as Gemma, Llava (multimodal), Llama2, Llama3, or Mistral. It requires the Ollama library for interacting with large-scale language models, supporting GPUs using CUDA and AMD GPUs on Windows, Linux, and Mac. The extension allows users to run Ollama through Docker and utilize NVIDIA GPUs for faster processing. It provides nodes for image description, text description, image captioning, and text transformation, with various customizable parameters for model selection, API communication, response generation, and model memory management.
talkcody
TalkCody is a free, open-source AI coding agent designed for developers who value speed, cost, control, and privacy. It offers true freedom to use any AI model without vendor lock-in, maximum speed through unique four-level parallelism, and complete privacy as everything runs locally without leaving the user's machine. With professional-grade features like multimodal input support, MCP server compatibility, and a marketplace for agents and skills, TalkCody aims to enhance development productivity and flexibility.
kitchenai
KitchenAI is an open-source toolkit designed to simplify AI development by serving as an AI backend and LLMOps solution. It aims to empower developers to focus on delivering results without being bogged down by AI infrastructure complexities. With features like simplifying AI integration, providing an AI backend, and empowering developers, KitchenAI streamlines the process of turning AI experiments into production-ready APIs. It offers built-in LLMOps features, is framework-agnostic and extensible, and enables faster time-to-production. KitchenAI is suitable for application developers, AI developers & data scientists, and platform & infra engineers, allowing them to seamlessly integrate AI into apps, deploy custom AI techniques, and optimize AI services with a modular framework. The toolkit eliminates the need to build APIs and infrastructure from scratch, making it easier to deploy AI code as production-ready APIs in minutes. KitchenAI also provides observability, tracing, and evaluation tools, and offers a Docker-first deployment approach for scalability and confidence.
retrace
Retrace is a local-first screen recording and search application for macOS, inspired by Rewind AI. It captures screen activity, extracts text via OCR, and makes everything searchable locally on-device. The project is in very early development, offering features like continuous screen capture, OCR text extraction, full-text search, timeline viewer, dashboard analytics, Rewind AI import, settings panel, global hotkeys, HEVC video encoding, search highlighting, privacy controls, and more. Built with a modular architecture, Retrace uses Swift 5.9+, SwiftUI, Vision framework, SQLite with FTS5, HEVC video encoding, CryptoKit for encryption, and more. Future releases will include features like audio transcription and semantic search. Retrace requires macOS 13.0+ (Apple Silicon required) and Xcode 15.0+ for building from source, with permissions for screen recording and accessibility. Contributions are welcome, and the project is licensed under the MIT License.

chipper
Chipper provides a web interface, CLI, and architecture for pipelines, document chunking, web scraping, and query workflows. It is built with Haystack, Ollama, Hugging Face, Docker, Tailwind, and ElasticSearch, running locally or as a Dockerized service. Originally created to assist in creative writing, it now offers features like local Ollama and Hugging Face API, ElasticSearch embeddings, document splitting, web scraping, audio transcription, user-friendly CLI, and Docker deployment. The project aims to be educational, beginner-friendly, and a playground for AI exploration and innovation.
For similar tasks
Lidar_AI_Solution
Lidar AI Solution is a highly optimized repository for self-driving 3D lidar, providing solutions for sparse convolution, BEVFusion, CenterPoint, OSD, and Conversion. It includes CUDA and TensorRT implementations for various tasks such as 3D sparse convolution, BEVFusion, CenterPoint, PointPillars, V2XFusion, cuOSD, cuPCL, and YUV to RGB conversion. The repository offers easy-to-use solutions, high accuracy, low memory usage, and quantization options for different tasks related to self-driving technology.

AiTreasureBox
AiTreasureBox is a versatile AI tool that provides a collection of pre-trained models and algorithms for various machine learning tasks. It simplifies the process of implementing AI solutions by offering ready-to-use components that can be easily integrated into projects. With AiTreasureBox, users can quickly prototype and deploy AI applications without the need for extensive knowledge in machine learning or deep learning. The tool covers a wide range of tasks such as image classification, text generation, sentiment analysis, object detection, and more. It is designed to be user-friendly and accessible to both beginners and experienced developers, making AI development more efficient and accessible to a wider audience.
react-native-vision-camera
VisionCamera is a powerful, high-performance Camera library for React Native. It features Photo and Video capture, QR/Barcode scanner, Customizable devices and multi-cameras ("fish-eye" zoom), Customizable resolutions and aspect-ratios (4k/8k images), Customizable FPS (30..240 FPS), Frame Processors (JS worklets to run facial recognition, AI object detection, realtime video chats, ...), Smooth zooming (Reanimated), Fast pause and resume, HDR & Night modes, Custom C++/GPU accelerated video pipeline (OpenGL).

InternVL
InternVL scales up the ViT to _**6B parameters**_ and aligns it with LLM. It is a vision-language foundation model that can perform various tasks, including: **Visual Perception** - Linear-Probe Image Classification - Semantic Segmentation - Zero-Shot Image Classification - Multilingual Zero-Shot Image Classification - Zero-Shot Video Classification **Cross-Modal Retrieval** - English Zero-Shot Image-Text Retrieval - Chinese Zero-Shot Image-Text Retrieval - Multilingual Zero-Shot Image-Text Retrieval on XTD **Multimodal Dialogue** - Zero-Shot Image Captioning - Multimodal Benchmarks with Frozen LLM - Multimodal Benchmarks with Trainable LLM - Tiny LVLM InternVL has been shown to achieve state-of-the-art results on a variety of benchmarks. For example, on the MMMU image classification benchmark, InternVL achieves a top-1 accuracy of 51.6%, which is higher than GPT-4V and Gemini Pro. On the DocVQA question answering benchmark, InternVL achieves a score of 82.2%, which is also higher than GPT-4V and Gemini Pro. InternVL is open-sourced and available on Hugging Face. It can be used for a variety of applications, including image classification, object detection, semantic segmentation, image captioning, and question answering.

clarifai-python
The Clarifai Python SDK offers a comprehensive set of tools to integrate Clarifai's AI platform to leverage computer vision capabilities like classification , detection ,segementation and natural language capabilities like classification , summarisation , generation , Q&A ,etc into your applications. With just a few lines of code, you can leverage cutting-edge artificial intelligence to unlock valuable insights from visual and textual content.

ailia-models
The collection of pre-trained, state-of-the-art AI models. ailia SDK is a self-contained, cross-platform, high-speed inference SDK for AI. The ailia SDK provides a consistent C++ API across Windows, Mac, Linux, iOS, Android, Jetson, and Raspberry Pi platforms. It also supports Unity (C#), Python, Rust, Flutter(Dart) and JNI for efficient AI implementation. The ailia SDK makes extensive use of the GPU through Vulkan and Metal to enable accelerated computing. # Supported models 323 models as of April 8th, 2024

edenai-apis
Eden AI aims to simplify the use and deployment of AI technologies by providing a unique API that connects to all the best AI engines. With the rise of **AI as a Service** , a lot of companies provide off-the-shelf trained models that you can access directly through an API. These companies are either the tech giants (Google, Microsoft , Amazon) or other smaller, more specialized companies, and there are hundreds of them. Some of the most known are : DeepL (translation), OpenAI (text and image analysis), AssemblyAI (speech analysis). There are **hundreds of companies** doing that. We're regrouping the best ones **in one place** !
artificial-intelligence
This repository contains a collection of AI projects implemented in Python, primarily in Jupyter notebooks. The projects cover various aspects of artificial intelligence, including machine learning, deep learning, natural language processing, computer vision, and more. Each project is designed to showcase different AI techniques and algorithms, providing a hands-on learning experience for users interested in exploring the field of artificial intelligence.
For similar jobs

LitServe
LitServe is a high-throughput serving engine designed for deploying AI models at scale. It generates an API endpoint for models, handles batching, streaming, and autoscaling across CPU/GPUs. LitServe is built for enterprise scale with a focus on minimal, hackable code-base without bloat. It supports various model types like LLMs, vision, time-series, and works with frameworks like PyTorch, JAX, Tensorflow, and more. The tool allows users to focus on model performance rather than serving boilerplate, providing full control and flexibility.
Lidar_AI_Solution
Lidar AI Solution is a highly optimized repository for self-driving 3D lidar, providing solutions for sparse convolution, BEVFusion, CenterPoint, OSD, and Conversion. It includes CUDA and TensorRT implementations for various tasks such as 3D sparse convolution, BEVFusion, CenterPoint, PointPillars, V2XFusion, cuOSD, cuPCL, and YUV to RGB conversion. The repository offers easy-to-use solutions, high accuracy, low memory usage, and quantization options for different tasks related to self-driving technology.

generative-ai-sagemaker-cdk-demo
This repository showcases how to deploy generative AI models from Amazon SageMaker JumpStart using the AWS CDK. Generative AI is a type of AI that can create new content and ideas, such as conversations, stories, images, videos, and music. The repository provides a detailed guide on deploying image and text generative AI models, utilizing pre-trained models from SageMaker JumpStart. The web application is built on Streamlit and hosted on Amazon ECS with Fargate. It interacts with the SageMaker model endpoints through Lambda functions and Amazon API Gateway. The repository also includes instructions on setting up the AWS CDK application, deploying the stacks, using the models, and viewing the deployed resources on the AWS Management Console.

cake
cake is a pure Rust implementation of the llama3 LLM distributed inference based on Candle. The project aims to enable running large models on consumer hardware clusters of iOS, macOS, Linux, and Windows devices by sharding transformer blocks. It allows running inferences on models that wouldn't fit in a single device's GPU memory by batching contiguous transformer blocks on the same worker to minimize latency. The tool provides a way to optimize memory and disk space by splitting the model into smaller bundles for workers, ensuring they only have the necessary data. cake supports various OS, architectures, and accelerations, with different statuses for each configuration.

Awesome-Robotics-3D
Awesome-Robotics-3D is a curated list of 3D Vision papers related to Robotics domain, focusing on large models like LLMs/VLMs. It includes papers on Policy Learning, Pretraining, VLM and LLM, Representations, and Simulations, Datasets, and Benchmarks. The repository is maintained by Zubair Irshad and welcomes contributions and suggestions for adding papers. It serves as a valuable resource for researchers and practitioners in the field of Robotics and Computer Vision.
tensorzero
TensorZero is an open-source platform that helps LLM applications graduate from API wrappers into defensible AI products. It enables a data & learning flywheel for LLMs by unifying inference, observability, optimization, and experimentation. The platform includes a high-performance model gateway, structured schema-based inference, observability, experimentation, and data warehouse for analytics. TensorZero Recipes optimize prompts and models, and the platform supports experimentation features and GitOps orchestration for deployment.

vector-inference
This repository provides an easy-to-use solution for running inference servers on Slurm-managed computing clusters using vLLM. All scripts in this repository run natively on the Vector Institute cluster environment. Users can deploy models as Slurm jobs, check server status and performance metrics, and shut down models. The repository also supports launching custom models with specific configurations. Additionally, users can send inference requests and set up an SSH tunnel to run inference from a local device.

rhesis
Rhesis is a comprehensive test management platform designed for Gen AI teams, offering tools to create, manage, and execute test cases for generative AI applications. It ensures the robustness, reliability, and compliance of AI systems through features like test set management, automated test generation, edge case discovery, compliance validation, integration capabilities, and performance tracking. The platform is open source, emphasizing community-driven development, transparency, extensible architecture, and democratizing AI safety. It includes components such as backend services, frontend applications, SDK for developers, worker services, chatbot applications, and Polyphemus for uncensored LLM service. Rhesis enables users to address challenges unique to testing generative AI applications, such as non-deterministic outputs, hallucinations, edge cases, ethical concerns, and compliance requirements.