
edenai-apis
Eden AI: simplify the use and deployment of AI technologies by providing a unique API that connects to the best possible AI engines
Stars: 441

Eden AI aims to simplify the use and deployment of AI technologies by providing a unique API that connects to all the best AI engines. With the rise of **AI as a Service** , a lot of companies provide off-the-shelf trained models that you can access directly through an API. These companies are either the tech giants (Google, Microsoft , Amazon) or other smaller, more specialized companies, and there are hundreds of them. Some of the most known are : DeepL (translation), OpenAI (text and image analysis), AssemblyAI (speech analysis). There are **hundreds of companies** doing that. We're regrouping the best ones **in one place** !
README:
![]()
![]()
Table of Contents
Eden AI aims to simplify the use and deployment of AI technologies by providing a unique API that connects to all the best AI engines.
With the rise of AI as a Service , a lot of companies provide off-the-shelf trained models that you can access directly through an API. These companies are either the tech giants (Google, Microsoft , Amazon) or other smaller, more specialized companies, and there are hundreds of them. Some of the most known are : DeepL (translation), OpenAI (text and image analysis), AssemblyAI (speech analysis).
There are hundreds of companies doing that. We're regrouping the best ones in one place !
why aren't you regrouping Open Source models (instead of proprietary APIs) into one repo? : Because it doesn't make sens to deploy and maintain large pytorch (or other framework) AI models in every solution that wants AI capabilities (especially for document parsing, image and video moderation or speech recognition) . So using APIs makes way more sens. Deployed OpenSource models are being included using different APIs like HuggingFace and other equivalents.

You can install the package with pip :
pip install git+https://github.com/edenai/edenai-apis To make call to different AI providers, first add the api-keys/secrets for the provider you will use in edenai_apis.api_keys.<provider_name>_settings_templates.json, then rename the file to <provider_name>_settings.json
When it's done you can directly start using edenai_apis. Here is a quick example using Microsoft and IBM Keyword Extraction apis:
from edenai_apis import Text
keyword_extraction = Text.keyword_extraction("microsoft")
microsoft_res = keyword_extraction(language="en", text="as simple as that")
# Provider's response
print(microsoft_res.original_response)
# Standardized version of Provider's response
print(microsoft_res.standardized_response)
for item in microsoft_res.standardized_response.items:
print(f"keyword: {item.keyword}, importance: {item.importance}")
# What if we want to try an other provider?
ibm_kw = Text.keyword_extraction("ibm")
ibm_res = ibm_kw(language="en", text="same api & unified inputs for all providers")
# `original_response` will obviously be different and you will have to check
# the doc of each individual providers to know how to parse them
print(ibm_res.original_response)
# We can however easily parse `standardized_response`
# the same way as we did for microsoft:
for item in ibm_res.standardized_response.items:
print(f"keyword: {item.keyword}, importance: {item.importance}")If you need to use features like speech to text, object extraction from videos, etc. Then you will have to use asynchronous operations. This means that you will first make a call to launch an asynchronous job, it will then return a job ID allowing you to make other calls to get the job status or response if the job is finished
from edenai_apis import Audio
provider = "google" # it could also be assamblyai, deepgram, microsoft ...etc
stt_launch = Audio.speech_to_text_async__launch_job(provider)
stt_get_result = Audio.speech_to_text_async__get_job_result(provider)
res = stt_launch(
file=your_file.wav,
language="en",
speakers=2,
profanity_filter=False,
)
job_id = stt_launch.provider_job_id
res = stt_get_result(provider_job_id=job_id)
print(res.status) # "pending" | "succeeded" | "failed"We would love to have your contribution. Please follow our guidelines for adding a new AI provider's API or a new AI feature. You can check the package structure for more details on how it is organized. We use GitHub issues for tracking requests and bugs. For broader discussions you can join our discord.
You can create an account on Eden AI and have access to all the AI technologies and providers directly through our API.
![]()
Join our friendly community to improve your skills, focus on the integration of AI engines, get help to use Eden AI API and much more !
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for edenai-apis
Similar Open Source Tools
edenai-apis
Eden AI aims to simplify the use and deployment of AI technologies by providing a unique API that connects to all the best AI engines. With the rise of **AI as a Service** , a lot of companies provide off-the-shelf trained models that you can access directly through an API. These companies are either the tech giants (Google, Microsoft , Amazon) or other smaller, more specialized companies, and there are hundreds of them. Some of the most known are : DeepL (translation), OpenAI (text and image analysis), AssemblyAI (speech analysis). There are **hundreds of companies** doing that. We're regrouping the best ones **in one place** !

sdk
Vikit.ai SDK is a software development kit that enables easy development of video generators using generative AI and other AI models. It serves as a langchain to orchestrate AI models and video editing tools. The SDK allows users to create videos from text prompts with background music and voice-over narration. It also supports generating composite videos from multiple text prompts. The tool requires Python 3.8+, specific dependencies, and tools like FFMPEG and ImageMagick for certain functionalities. Users can contribute to the project by following the contribution guidelines and standards provided.

EdgeChains
EdgeChains is an open-source chain-of-thought engineering framework tailored for Large Language Models (LLMs)- like OpenAI GPT, LLama2, Falcon, etc. - With a focus on enterprise-grade deployability and scalability. EdgeChains is specifically designed to **orchestrate** such applications. At EdgeChains, we take a unique approach to Generative AI - we think Generative AI is a deployment and configuration management challenge rather than a UI and library design pattern challenge. We build on top of a tech that has solved this problem in a different domain - Kubernetes Config Management - and bring that to Generative AI. Edgechains is built on top of jsonnet, originally built by Google based on their experience managing a vast amount of configuration code in the Borg infrastructure.
nobodywho
NobodyWho is a plugin for the Godot game engine that enables interaction with local LLMs for interactive storytelling. Users can install it from Godot editor or GitHub releases page, providing their own LLM in GGUF format. The plugin consists of `NobodyWhoModel` node for model file, `NobodyWhoChat` node for chat interaction, and `NobodyWhoEmbedding` node for generating embeddings. It offers a programming interface for sending text to LLM, receiving responses, and starting the LLM worker.

Sentient
Sentient is a personal, private, and interactive AI companion developed by Existence. The project aims to build a completely private AI companion that is deeply personalized and context-aware of the user. It utilizes automation and privacy to create a true companion for humans. The tool is designed to remember information about the user and use it to respond to queries and perform various actions. Sentient features a local and private environment, MBTI personality test, integrations with LinkedIn, Reddit, and more, self-managed graph memory, web search capabilities, multi-chat functionality, and auto-updates for the app. The project is built using technologies like ElectronJS, Next.js, TailwindCSS, FastAPI, Neo4j, and various APIs.

MARS5-TTS
MARS5 is a novel English speech model (TTS) developed by CAMB.AI, featuring a two-stage AR-NAR pipeline with a unique NAR component. The model can generate speech for various scenarios like sports commentary and anime with just 5 seconds of audio and a text snippet. It allows steering prosody using punctuation and capitalization in the transcript. Speaker identity is specified using an audio reference file, enabling 'deep clone' for improved quality. The model can be used via torch.hub or HuggingFace, supporting both shallow and deep cloning for inference. Checkpoints are provided for AR and NAR models, with hardware requirements of 750M+450M params on GPU. Contributions to improve model stability, performance, and reference audio selection are welcome.
OrionChat
Orion is a web-based chat interface that simplifies interactions with multiple AI model providers. It provides a unified platform for chatting and exploring various large language models (LLMs) such as Ollama, OpenAI (GPT model), Cohere (Command-r models), Google (Gemini models), Anthropic (Claude models), Groq Inc., Cerebras, and SambaNova. Users can easily navigate and assess different AI models through an intuitive, user-friendly interface. Orion offers features like browser-based access, code execution with Google Gemini, text-to-speech (TTS), speech-to-text (STT), seamless integration with multiple AI models, customizable system prompts, language translation tasks, document uploads for analysis, and more. API keys are stored locally, and requests are sent directly to official providers' APIs without external proxies.
SalesGPT
SalesGPT is an open-source AI agent designed for sales, utilizing context-awareness and LLMs to work across various communication channels like voice, email, and texting. It aims to enhance sales conversations by understanding the stage of the conversation and providing tools like product knowledge base to reduce errors. The agent can autonomously generate payment links, handle objections, and close sales. It also offers features like automated email communication, meeting scheduling, and integration with various LLMs for customization. SalesGPT is optimized for low latency in voice channels and ensures human supervision where necessary. The tool provides enterprise-grade security and supports LangSmith tracing for monitoring and evaluation of intelligent agents built on LLM frameworks.

hi-ml
The Microsoft Health Intelligence Machine Learning Toolbox is a repository that provides low-level and high-level building blocks for Machine Learning / AI researchers and practitioners. It simplifies and streamlines work on deep learning models for healthcare and life sciences by offering tested components such as data loaders, pre-processing tools, deep learning models, and cloud integration utilities. The repository includes two Python packages, 'hi-ml-azure' for helper functions in AzureML, 'hi-ml' for ML components, and 'hi-ml-cpath' for models and workflows related to histopathology images.

lovelaice
Lovelaice is an AI-powered assistant for your terminal and editor. It can run bash commands, search the Internet, answer general and technical questions, complete text files, chat casually, execute code in various languages, and more. Lovelaice is configurable with API keys and LLM models, and can be used for a wide range of tasks requiring bash commands or coding assistance. It is designed to be versatile, interactive, and helpful for daily tasks and projects.

CodeProject.AI-Server
CodeProject.AI Server is a standalone, self-hosted, fast, free, and open-source Artificial Intelligence microserver designed for any platform and language. It can be installed locally without the need for off-device or out-of-network data transfer, providing an easy-to-use solution for developers interested in AI programming. The server includes a HTTP REST API server, backend analysis services, and the source code, enabling users to perform various AI tasks locally without relying on external services or cloud computing. Current capabilities include object detection, face detection, scene recognition, sentiment analysis, and more, with ongoing feature expansions planned. The project aims to promote AI development, simplify AI implementation, focus on core use-cases, and leverage the expertise of the developer community.
wingman-ai
Wingman AI allows you to use your voice to talk to various AI providers and LLMs, process your conversations, and ultimately trigger actions such as pressing buttons or reading answers. Our _Wingmen_ are like characters and your interface to this world, and you can easily control their behavior and characteristics, even if you're not a developer. AI is complex and it scares people. It's also **not just ChatGPT**. We want to make it as easy as possible for you to get started. That's what _Wingman AI_ is all about. It's a **framework** that allows you to build your own Wingmen and use them in your games and programs. The idea is simple, but the possibilities are endless. For example, you could: * **Role play** with an AI while playing for more immersion. Have air traffic control (ATC) in _Star Citizen_ or _Flight Simulator_. Talk to Shadowheart in Baldur's Gate 3 and have her respond in her own (cloned) voice. * Get live data such as trade information, build guides, or wiki content and have it read to you in-game by a _character_ and voice you control. * Execute keystrokes in games/applications and create complex macros. Trigger them in natural conversations with **no need for exact phrases.** The AI understands the context of your dialog and is quite _smart_ in recognizing your intent. Say _"It's raining! I can't see a thing!"_ and have it trigger a command you simply named _WipeVisors_. * Automate tasks on your computer * improve accessibility * ... and much more

pydantic-ai
PydanticAI is a Python agent framework designed to make it less painful to build production grade applications with Generative AI. It is built by the Pydantic Team and supports various AI models like OpenAI, Anthropic, Gemini, Ollama, Groq, and Mistral. PydanticAI seamlessly integrates with Pydantic Logfire for real-time debugging, performance monitoring, and behavior tracking of LLM-powered applications. It is type-safe, Python-centric, and offers structured responses, dependency injection system, and streamed responses. PydanticAI is in early beta, offering a Python-centric design to apply standard Python best practices in AI-driven projects.

Perplexica
Perplexica is an open-source AI-powered search engine that utilizes advanced machine learning algorithms to provide clear answers with sources cited. It offers various modes like Copilot Mode, Normal Mode, and Focus Modes for specific types of questions. Perplexica ensures up-to-date information by using SearxNG metasearch engine. It also features image and video search capabilities and upcoming features include finalizing Copilot Mode and adding Discover and History Saving features.

openai-cf-workers-ai
OpenAI for Workers AI is a simple, quick, and dirty implementation of OpenAI's API on Cloudflare's new Workers AI platform. It allows developers to use the OpenAI SDKs with the new LLMs without having to rewrite all of their code. The API currently supports completions, chat completions, audio transcription, embeddings, audio translation, and image generation. It is not production ready but will be semi-regularly updated with new features as they roll out to Workers AI.

TinyTroupe
TinyTroupe is an experimental Python library that leverages Large Language Models (LLMs) to simulate artificial agents called TinyPersons with specific personalities, interests, and goals in simulated environments. The focus is on understanding human behavior through convincing interactions and customizable personas for various applications like advertisement evaluation, software testing, data generation, project management, and brainstorming. The tool aims to enhance human imagination and provide insights for better decision-making in business and productivity scenarios.
For similar tasks

AiTreasureBox
AiTreasureBox is a versatile AI tool that provides a collection of pre-trained models and algorithms for various machine learning tasks. It simplifies the process of implementing AI solutions by offering ready-to-use components that can be easily integrated into projects. With AiTreasureBox, users can quickly prototype and deploy AI applications without the need for extensive knowledge in machine learning or deep learning. The tool covers a wide range of tasks such as image classification, text generation, sentiment analysis, object detection, and more. It is designed to be user-friendly and accessible to both beginners and experienced developers, making AI development more efficient and accessible to a wider audience.

InternVL
InternVL scales up the ViT to _**6B parameters**_ and aligns it with LLM. It is a vision-language foundation model that can perform various tasks, including: **Visual Perception** - Linear-Probe Image Classification - Semantic Segmentation - Zero-Shot Image Classification - Multilingual Zero-Shot Image Classification - Zero-Shot Video Classification **Cross-Modal Retrieval** - English Zero-Shot Image-Text Retrieval - Chinese Zero-Shot Image-Text Retrieval - Multilingual Zero-Shot Image-Text Retrieval on XTD **Multimodal Dialogue** - Zero-Shot Image Captioning - Multimodal Benchmarks with Frozen LLM - Multimodal Benchmarks with Trainable LLM - Tiny LVLM InternVL has been shown to achieve state-of-the-art results on a variety of benchmarks. For example, on the MMMU image classification benchmark, InternVL achieves a top-1 accuracy of 51.6%, which is higher than GPT-4V and Gemini Pro. On the DocVQA question answering benchmark, InternVL achieves a score of 82.2%, which is also higher than GPT-4V and Gemini Pro. InternVL is open-sourced and available on Hugging Face. It can be used for a variety of applications, including image classification, object detection, semantic segmentation, image captioning, and question answering.

clarifai-python
The Clarifai Python SDK offers a comprehensive set of tools to integrate Clarifai's AI platform to leverage computer vision capabilities like classification , detection ,segementation and natural language capabilities like classification , summarisation , generation , Q&A ,etc into your applications. With just a few lines of code, you can leverage cutting-edge artificial intelligence to unlock valuable insights from visual and textual content.

X-AnyLabeling
X-AnyLabeling is a robust annotation tool that seamlessly incorporates an AI inference engine alongside an array of sophisticated features. Tailored for practical applications, it is committed to delivering comprehensive, industrial-grade solutions for image data engineers. This tool excels in swiftly and automatically executing annotations across diverse and intricate tasks.

ailia-models
The collection of pre-trained, state-of-the-art AI models. ailia SDK is a self-contained, cross-platform, high-speed inference SDK for AI. The ailia SDK provides a consistent C++ API across Windows, Mac, Linux, iOS, Android, Jetson, and Raspberry Pi platforms. It also supports Unity (C#), Python, Rust, Flutter(Dart) and JNI for efficient AI implementation. The ailia SDK makes extensive use of the GPU through Vulkan and Metal to enable accelerated computing. # Supported models 323 models as of April 8th, 2024
edenai-apis
Eden AI aims to simplify the use and deployment of AI technologies by providing a unique API that connects to all the best AI engines. With the rise of **AI as a Service** , a lot of companies provide off-the-shelf trained models that you can access directly through an API. These companies are either the tech giants (Google, Microsoft , Amazon) or other smaller, more specialized companies, and there are hundreds of them. Some of the most known are : DeepL (translation), OpenAI (text and image analysis), AssemblyAI (speech analysis). There are **hundreds of companies** doing that. We're regrouping the best ones **in one place** !

NanoLLM
NanoLLM is a tool designed for optimized local inference for Large Language Models (LLMs) using HuggingFace-like APIs. It supports quantization, vision/language models, multimodal agents, speech, vector DB, and RAG. The tool aims to provide efficient and effective processing for LLMs on local devices, enhancing performance and usability for various AI applications.

open-ai
Open AI is a powerful tool for artificial intelligence research and development. It provides a wide range of machine learning models and algorithms, making it easier for developers to create innovative AI applications. With Open AI, users can explore cutting-edge technologies such as natural language processing, computer vision, and reinforcement learning. The platform offers a user-friendly interface and comprehensive documentation to support users in building and deploying AI solutions. Whether you are a beginner or an experienced AI practitioner, Open AI offers the tools and resources you need to accelerate your AI projects and stay ahead in the rapidly evolving field of artificial intelligence.
For similar jobs
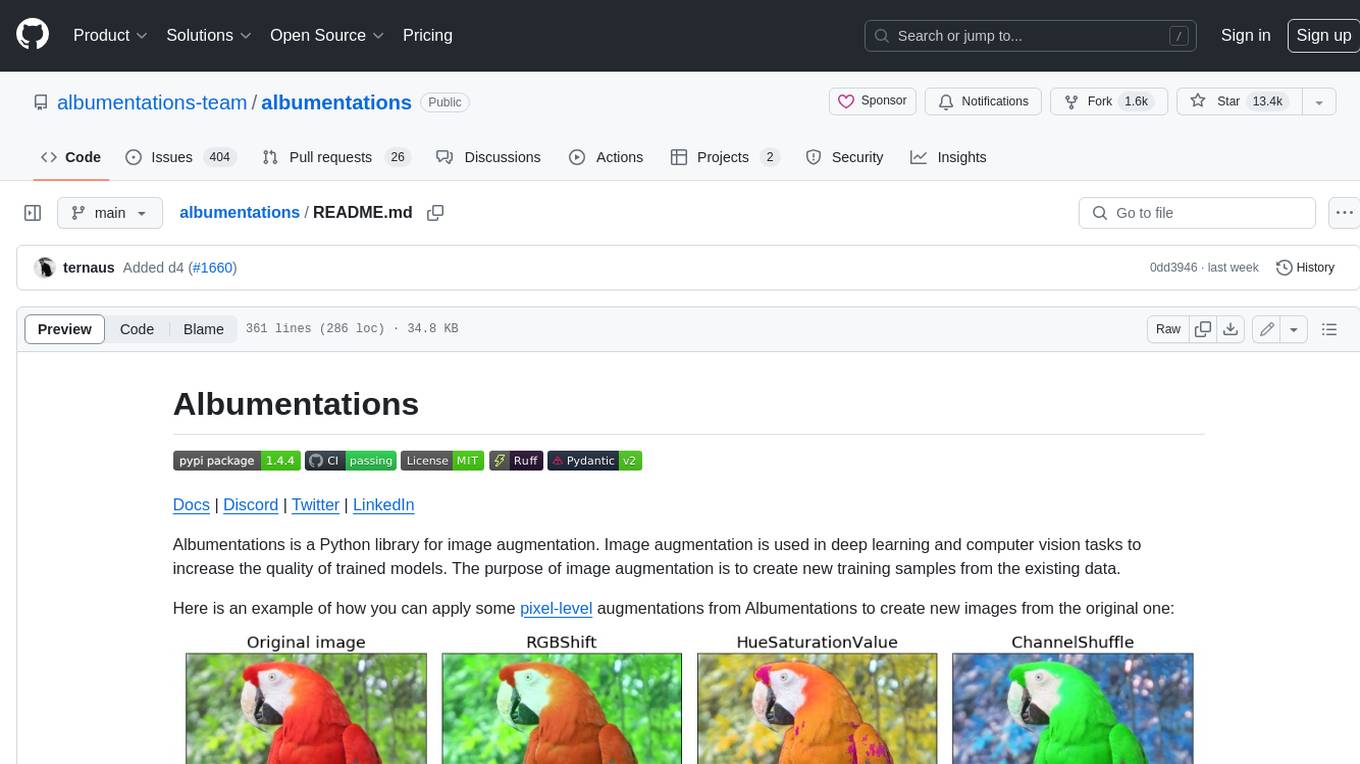
albumentations
Albumentations is a Python library for image augmentation. Image augmentation is used in deep learning and computer vision tasks to increase the quality of trained models. The purpose of image augmentation is to create new training samples from the existing data.
clarifai-python
The Clarifai Python SDK offers a comprehensive set of tools to integrate Clarifai's AI platform to leverage computer vision capabilities like classification , detection ,segementation and natural language capabilities like classification , summarisation , generation , Q&A ,etc into your applications. With just a few lines of code, you can leverage cutting-edge artificial intelligence to unlock valuable insights from visual and textual content.
ailia-models
The collection of pre-trained, state-of-the-art AI models. ailia SDK is a self-contained, cross-platform, high-speed inference SDK for AI. The ailia SDK provides a consistent C++ API across Windows, Mac, Linux, iOS, Android, Jetson, and Raspberry Pi platforms. It also supports Unity (C#), Python, Rust, Flutter(Dart) and JNI for efficient AI implementation. The ailia SDK makes extensive use of the GPU through Vulkan and Metal to enable accelerated computing. # Supported models 323 models as of April 8th, 2024
edenai-apis
Eden AI aims to simplify the use and deployment of AI technologies by providing a unique API that connects to all the best AI engines. With the rise of **AI as a Service** , a lot of companies provide off-the-shelf trained models that you can access directly through an API. These companies are either the tech giants (Google, Microsoft , Amazon) or other smaller, more specialized companies, and there are hundreds of them. Some of the most known are : DeepL (translation), OpenAI (text and image analysis), AssemblyAI (speech analysis). There are **hundreds of companies** doing that. We're regrouping the best ones **in one place** !

curated-transformers
Curated Transformers is a transformer library for PyTorch that provides state-of-the-art models composed of reusable components. It supports various transformer architectures, including encoders like ALBERT, BERT, and RoBERTa, and decoders like Falcon, Llama, and MPT. The library emphasizes consistent type annotations, minimal dependencies, and ease of use for education and research. It has been production-tested by Explosion and will be the default transformer implementation in spaCy 3.7.

bert4torch
**bert4torch** is a high-level framework for training and deploying transformer models in PyTorch. It provides a simple and efficient API for building, training, and evaluating transformer models, and supports a wide range of pre-trained models, including BERT, RoBERTa, ALBERT, XLNet, and GPT-2. bert4torch also includes a number of useful features, such as data loading, tokenization, and model evaluation. It is a powerful and versatile tool for natural language processing tasks.
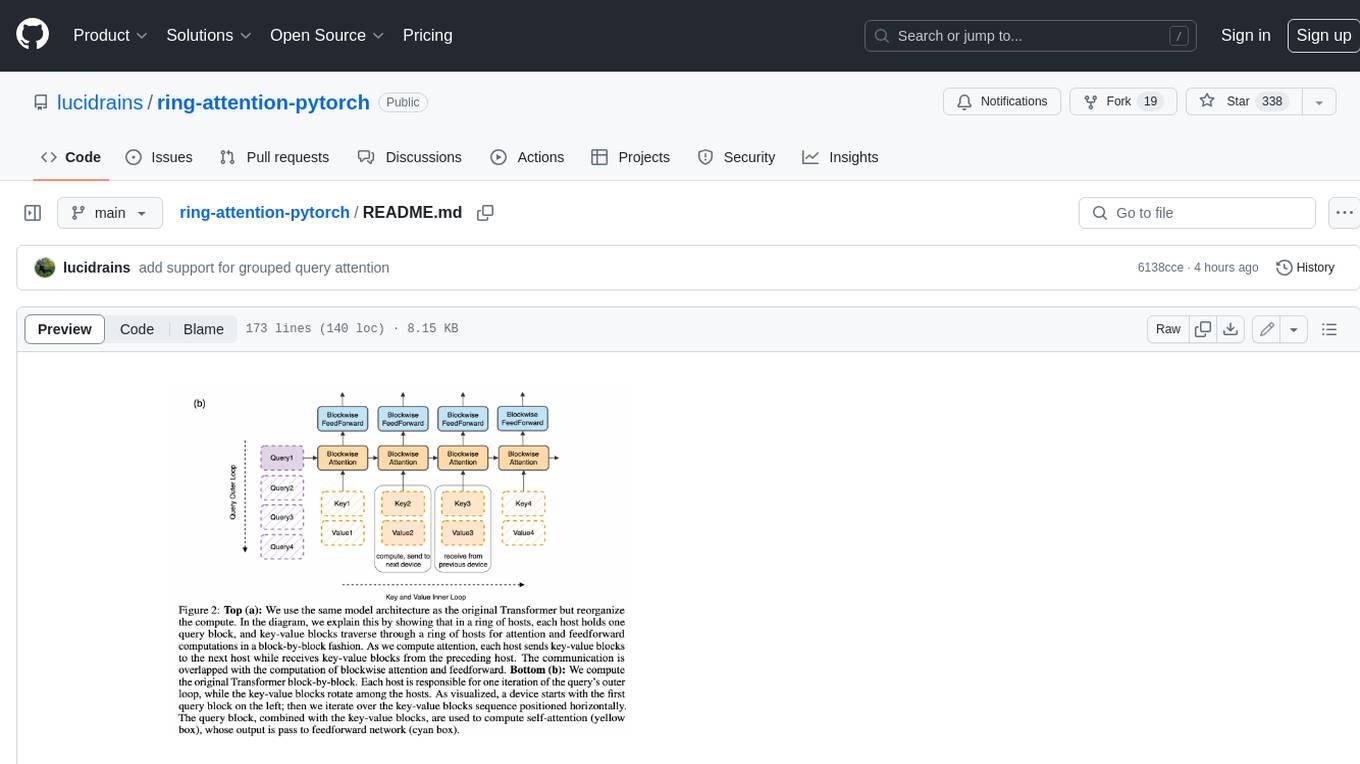
ring-attention-pytorch
This repository contains an implementation of Ring Attention, a technique for processing large sequences in transformers. Ring Attention splits the data across the sequence dimension and applies ring reduce to the processing of the tiles of the attention matrix, similar to flash attention. It also includes support for Striped Attention, a follow-up paper that permutes the sequence for better workload balancing for autoregressive transformers, and grouped query attention, which saves on communication costs during the ring reduce. The repository includes a CUDA version of the flash attention kernel, which is used for the forward and backward passes of the ring attention. It also includes logic for splitting the sequence evenly among ranks, either within the attention function or in the external ring transformer wrapper, and basic test cases with two processes to check for equivalent output and gradients.

FlagEmbedding
FlagEmbedding focuses on retrieval-augmented LLMs, consisting of the following projects currently: * **Long-Context LLM** : Activation Beacon * **Fine-tuning of LM** : LM-Cocktail * **Embedding Model** : Visualized-BGE, BGE-M3, LLM Embedder, BGE Embedding * **Reranker Model** : llm rerankers, BGE Reranker * **Benchmark** : C-MTEB