
ring-attention-pytorch
Implementation of 💍 Ring Attention, from Liu et al. at Berkeley AI, in Pytorch
Stars: 405
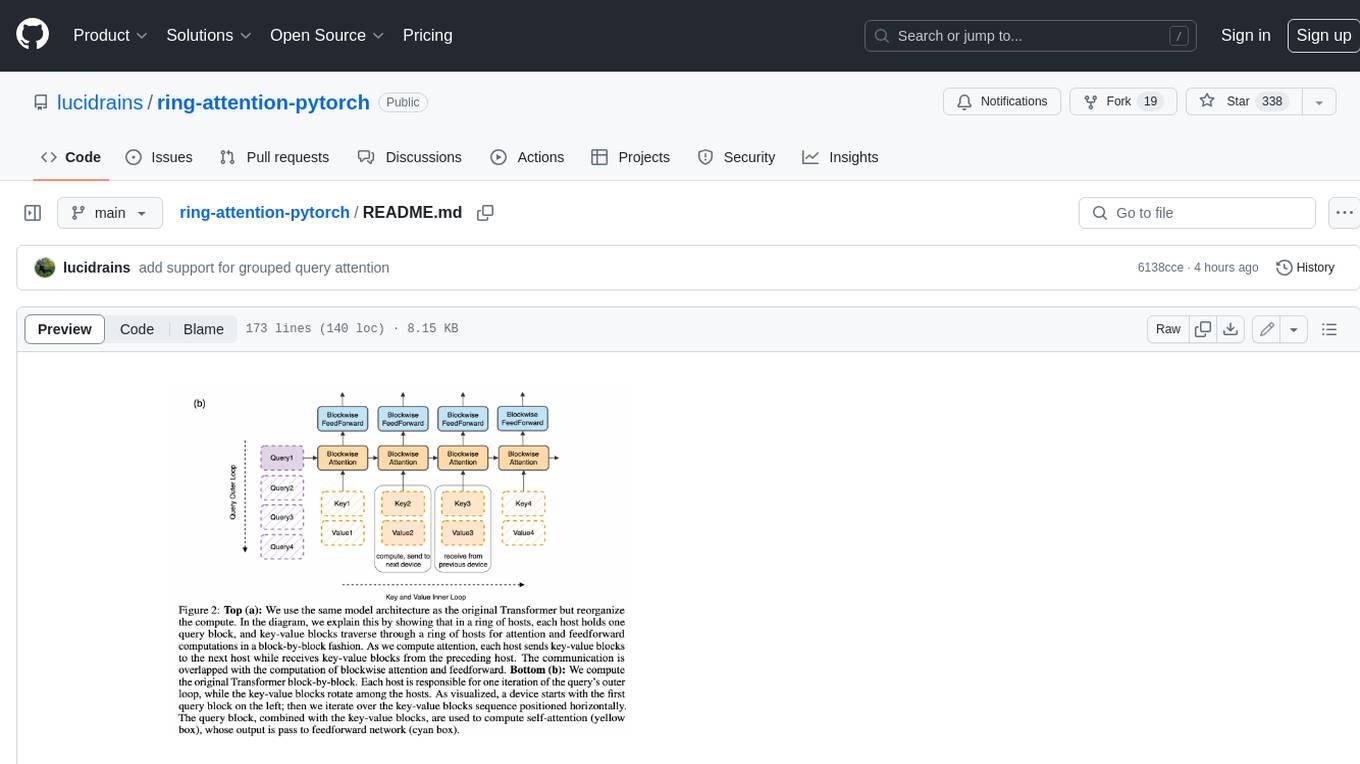
This repository contains an implementation of Ring Attention, a technique for processing large sequences in transformers. Ring Attention splits the data across the sequence dimension and applies ring reduce to the processing of the tiles of the attention matrix, similar to flash attention. It also includes support for Striped Attention, a follow-up paper that permutes the sequence for better workload balancing for autoregressive transformers, and grouped query attention, which saves on communication costs during the ring reduce. The repository includes a CUDA version of the flash attention kernel, which is used for the forward and backward passes of the ring attention. It also includes logic for splitting the sequence evenly among ranks, either within the attention function or in the external ring transformer wrapper, and basic test cases with two processes to check for equivalent output and gradients.
README:

Implementation of Ring Attention, from Liu et al. at Berkeley AI, in Pytorch.
It basically splits the data across the sequence dimension (instead of batch) and applies ring reduce to the processing of the tiles of the attention matrix, flash attention style.
I believe this is being used for the 1-10 million tokens for the latest Gemini. At least some form of it; the other possibility would be unpublished improvements on top of RMT.
In addition, the repository also contains the logic for Striped Attention, a follow up paper that permutes the sequence for better workload balancing for autoregressive transformers.
It also contains support for grouped query attention, popularized by Llama series of attention models. This will further save on communication costs during the ring reduce.
-
A16Z Open Source AI Grant Program for the generous sponsorship, as well as my other sponsors, for affording me the independence to open source current artificial intelligence research
-
Tri Dao for all his tremendous hard work maintaining Flash Attention over the last year or two, from which the CUDA version in this repository depends on
-
Phil Tillet for Triton, without which the forward ring flash attention CUDA kernel would have taken a magnitude of order more work.
$ pip install ring-attention-pytorchimport torch
from ring_attention_pytorch import RingAttention
attn = RingAttention(
dim = 512,
dim_head = 64,
heads = 8,
causal = True,
auto_shard_seq = True,
ring_attn = True,
ring_seq_size = 512
)
tokens = torch.randn(1, 1024, 512)
attended = attn(tokens)
assert attended.shape == tokens.shapeFirst install requirements
$ pip install -r requirements.txtThen say testing autoregressive striped ring attention on cuda would be
$ python assert.py --use-cuda --causal --striped-ring-attn-
[x] make it work with derived causal mask based on rank and chunk sizes
-
[x] modify flash attention to output intermediates and figure out backwards with recompute and ring passes
-
[x] functions for splitting the sequence evenly among ranks, either within attention function, or in the external ring transformer wrapper
-
[x] basic test case with two processes and check for equivalent output and gradients
-
[x] testing
- [x] make sure key padding mask works
- [x] make sure causal mask works
- [x] rotary embeddings, with proper key/value offset depending on ring rank
-
[x] striped attention
- [x] add the permutating logic before and after transformer
- [x] add causal masking logic - account for sub bucketing by flash attention
-
[x] fix issue with ring attention when flash buckets > 1
-
[x] move flash attention back to key / value column traversal on outer loop and save on ring communication
- [x] backwards
- [x] forwards
-
[x] fix rotary positions for striped ring attention when flash buckets > 1
-
[x] allow for variable ring passes per layer, for local -> global attention in ring transformer as one goes up the layers.
-
[x] when doing ring passes, alternate between designated send and receive buffers
-
[x] instead of max ring passes, able to specify lookback in terms of sequence length, and derive number of flash attention bucket + ring passes from that
-
[x] ability to have ring size < world size, sharding the batch and sequence, and doing ring reduce with the correct set of ranks
-
[x] add flash attention kernel version in the presence of cuda
- [x] for forwards, use modified Triton flash attention forwards that outputs row sums, maxes, and exponentiated weighted sum
- [x] for backwards, use Tri's flash attention kernels, accumulate dq, dk, dv across rings
- [x] refactor to have naive ring+flash attention work with
(batch, seq, head, dim) - [x] handle key padding mask for forwards by translating mask to bias
- [x] figure out how Tri handles key padding mask for backwards
- [x] scale output of flash attention forwards on the last ring pass reduce
- [x] verify backwards working in a100 runpod
- [x] dk, dv needs to be float32, while kv needs to be float16. see if both can be cast to int before stacked and ring passed all in one go, then reinterpret back to float32 and float16
- [x] prevent an unnecessary
tl.loadon the first ring pass - [x] cuda backwards pass must have same dq, dk, dv as naive
-
[x] fix naive flash attention backwards
-
[x] validate cuda causal and striped ring attention works
-
[x] make sure cuda striped attention works for multiple buckets, otherwise flash attention is ineffective
-
[x] for cuda striped attention, for backwards hack, pad the extra token once and index out when passing into Tri's cuda kernel
-
[x] find a machine with 8 GPUs and test with a quarter million tokens first
-
[x] see for cuda version whether softmax_D can be computed once and cached over the ring reduce. go for modified triton backwards if not
-
[ ] think about how to craft a special
Datasetthat shards across sequence length (take into account labels for cross entropy loss) for ring transformer training -
[ ] add ring attention to Tri's flash attention implementation. find some cuda ring reduce impl
-
[ ] figure out how to pytest distributed pytorch
-
[ ] use sdp context manager to validate when it is possible to use
ring_flash_attn_cuda, otherwise assert out -
[ ] improvise a variant where each machine keeps compressed summary tokens, and one only ring pass those summary token for some given distance
@article{Liu2023RingAW,
title = {Ring Attention with Blockwise Transformers for Near-Infinite Context},
author = {Hao Liu and Matei Zaharia and Pieter Abbeel},
journal = {ArXiv},
year = {2023},
volume = {abs/2310.01889},
url = {https://api.semanticscholar.org/CorpusID:263608461}
}@article{Brandon2023StripedAF,
title = {Striped Attention: Faster Ring Attention for Causal Transformers},
author = {William Brandon and Aniruddha Nrusimha and Kevin Qian and Zachary Ankner and Tian Jin and Zhiye Song and Jonathan Ragan-Kelley},
journal = {ArXiv},
year = {2023},
volume = {abs/2311.09431},
url = {https://api.semanticscholar.org/CorpusID:265220849}
}@article{Dao2022FlashAttentionFA,
title = {FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness},
author = {Tri Dao and Daniel Y. Fu and Stefano Ermon and Atri Rudra and Christopher R'e},
journal = {ArXiv},
year = {2022},
volume = {abs/2205.14135}
}@article{dao2023flashattention2,
title = {Flash{A}ttention-2: Faster Attention with Better Parallelism and Work Partitioning,
author = {Dao, Tri},
year = {2023}
}@article{Tillet2019TritonAI,
title = {Triton: an intermediate language and compiler for tiled neural network computations},
author = {Philippe Tillet and H. Kung and D. Cox},
journal = {Proceedings of the 3rd ACM SIGPLAN International Workshop on Machine Learning and Programming Languages},
year = {2019}
}@article{Ainslie2023GQATG,
title = {GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints},
author = {Joshua Ainslie and James Lee-Thorp and Michiel de Jong and Yury Zemlyanskiy and Federico Lebr'on and Sumit K. Sanghai},
journal = {ArXiv},
year = {2023},
volume = {abs/2305.13245},
url = {https://api.semanticscholar.org/CorpusID:258833177}
}The Bitter Lesson - Richard Sutton
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for ring-attention-pytorch
Similar Open Source Tools
ring-attention-pytorch
This repository contains an implementation of Ring Attention, a technique for processing large sequences in transformers. Ring Attention splits the data across the sequence dimension and applies ring reduce to the processing of the tiles of the attention matrix, similar to flash attention. It also includes support for Striped Attention, a follow-up paper that permutes the sequence for better workload balancing for autoregressive transformers, and grouped query attention, which saves on communication costs during the ring reduce. The repository includes a CUDA version of the flash attention kernel, which is used for the forward and backward passes of the ring attention. It also includes logic for splitting the sequence evenly among ranks, either within the attention function or in the external ring transformer wrapper, and basic test cases with two processes to check for equivalent output and gradients.
RPG-DiffusionMaster
This repository contains the official implementation of RPG, a powerful training-free paradigm for text-to-image generation and editing. RPG utilizes proprietary or open-source MLLMs as prompt recaptioner and region planner with complementary regional diffusion. It achieves state-of-the-art results and can generate high-resolution images. The codebase supports diffusers and various diffusion backbones, including SDXL and SD v1.4/1.5. Users can reproduce results with GPT-4, Gemini-Pro, or local MLLMs like miniGPT-4. The repository provides tools for quick start, regional diffusion with GPT-4, and regional diffusion with local LLMs.

MiniCheck
MiniCheck is an efficient fact-checking tool designed to verify claims against grounding documents using large language models. It provides a sentence-level fact-checking model that can be used to evaluate the consistency of claims with the provided documents. MiniCheck offers different models, including Bespoke-MiniCheck-7B, which is the state-of-the-art and commercially usable. The tool enables users to fact-check multi-sentence claims by breaking them down into individual sentences for optimal performance. It also supports automatic prefix caching for faster inference when repeatedly fact-checking the same document with different claims.
Gemini
Gemini is an open-source model designed to handle multiple modalities such as text, audio, images, and videos. It utilizes a transformer architecture with special decoders for text and image generation. The model processes input sequences by transforming them into tokens and then decoding them to generate image outputs. Gemini differs from other models by directly feeding image embeddings into the transformer instead of using a visual transformer encoder. The model also includes a component called Codi for conditional generation. Gemini aims to effectively integrate image, audio, and video embeddings to enhance its performance.
Numpy.NET
Numpy.NET is the most complete .NET binding for NumPy, empowering .NET developers with extensive functionality for scientific computing, machine learning, and AI. It provides multi-dimensional arrays, matrices, linear algebra, FFT, and more via a strong typed API. Numpy.NET does not require a local Python installation, as it uses Python.Included to package embedded Python 3.7. Multi-threading must be handled carefully to avoid deadlocks or access violation exceptions. Performance considerations include overhead when calling NumPy from C# and the efficiency of data transfer between C# and Python. Numpy.NET aims to match the completeness of the original NumPy library and is generated using CodeMinion by parsing the NumPy documentation. The project is MIT licensed and supported by JetBrains.

Woodpecker
Woodpecker is a tool designed to correct hallucinations in Multimodal Large Language Models (MLLMs) by introducing a training-free method that picks out and corrects inconsistencies between generated text and image content. It consists of five stages: key concept extraction, question formulation, visual knowledge validation, visual claim generation, and hallucination correction. Woodpecker can be easily integrated with different MLLMs and provides interpretable results by accessing intermediate outputs of the stages. The tool has shown significant improvements in accuracy over baseline models like MiniGPT-4 and mPLUG-Owl.

SheetCopilot
SheetCopilot is an assistant agent that manipulates spreadsheets by following user commands. It leverages Large Language Models (LLMs) to interact with spreadsheets like a human expert, enabling non-expert users to complete tasks on complex software such as Google Sheets and Excel via a language interface. The tool observes spreadsheet states, polishes generated solutions based on external action documents and error feedback, and aims to improve success rate and efficiency. SheetCopilot offers a dataset with diverse task categories and operations, supporting operations like entry & manipulation, management, formatting, charts, and pivot tables. Users can interact with SheetCopilot in Excel or Google Sheets, executing tasks like calculating revenue, creating pivot tables, and plotting charts. The tool's evaluation includes performance comparisons with leading LLMs and VBA-based methods on specific datasets, showcasing its capabilities in controlling various aspects of a spreadsheet.

RAG-FiT
RAG-FiT is a library designed to improve Language Models' ability to use external information by fine-tuning models on specially created RAG-augmented datasets. The library assists in creating training data, training models using parameter-efficient finetuning (PEFT), and evaluating performance using RAG-specific metrics. It is modular, customizable via configuration files, and facilitates fast prototyping and experimentation with various RAG settings and configurations.

RAGFoundry
RAG Foundry is a library designed to enhance Large Language Models (LLMs) by fine-tuning models on RAG-augmented datasets. It helps create training data, train models using parameter-efficient finetuning (PEFT), and measure performance using RAG-specific metrics. The library is modular, customizable using configuration files, and facilitates prototyping with various RAG settings and configurations for tasks like data processing, retrieval, training, inference, and evaluation.

llm-reasoners
LLM Reasoners is a library that enables LLMs to conduct complex reasoning, with advanced reasoning algorithms. It approaches multi-step reasoning as planning and searches for the optimal reasoning chain, which achieves the best balance of exploration vs exploitation with the idea of "World Model" and "Reward". Given any reasoning problem, simply define the reward function and an optional world model (explained below), and let LLM reasoners take care of the rest, including Reasoning Algorithms, Visualization, LLM calling, and more!

RLHF-Reward-Modeling
This repository contains code for training reward models for Deep Reinforcement Learning-based Reward-modulated Hierarchical Fine-tuning (DRL-based RLHF), Iterative Selection Fine-tuning (Rejection sampling fine-tuning), and iterative Decision Policy Optimization (DPO). The reward models are trained using a Bradley-Terry model based on the Gemma and Mistral language models. The resulting reward models achieve state-of-the-art performance on the RewardBench leaderboard for reward models with base models of up to 13B parameters.

semlib
Semlib is a Python library for building data processing and data analysis pipelines that leverage the power of large language models (LLMs). It provides functional programming primitives like map, reduce, sort, and filter, programmed with natural language descriptions. Semlib handles complexities such as prompting, parsing, concurrency control, caching, and cost tracking. The library breaks down sophisticated data processing tasks into simpler steps to improve quality, feasibility, latency, cost, security, and flexibility of data processing tasks.

olmocr
olmOCR is a toolkit designed for training language models to work with PDF documents in real-world scenarios. It includes various components such as a prompting strategy for natural text parsing, an evaluation toolkit for comparing pipeline versions, filtering by language and SEO spam removal, finetuning code for specific models, processing PDFs through a finetuned model, and viewing documents created from PDFs. The toolkit requires a recent NVIDIA GPU with at least 20 GB of RAM and 30GB of free disk space. Users can install dependencies, set up a conda environment, and utilize olmOCR for tasks like converting single or multiple PDFs, viewing extracted text, and running batch inference pipelines.
DBCopilot
The development of Natural Language Interfaces to Databases (NLIDBs) has been greatly advanced by the advent of large language models (LLMs), which provide an intuitive way to translate natural language (NL) questions into Structured Query Language (SQL) queries. DBCopilot is a framework that addresses challenges in real-world scenarios of natural language querying over massive databases by employing a compact and flexible copilot model for routing. It decouples schema-agnostic NL2SQL into schema routing and SQL generation, utilizing a lightweight differentiable search index for semantic mappings and relation-aware joint retrieval. DBCopilot introduces a reverse schema-to-question generation paradigm for automatic learning and adaptation over massive databases, providing a scalable and effective solution for schema-agnostic NL2SQL.
uTensor
uTensor is an extremely light-weight machine learning inference framework built on Tensorflow and optimized for Arm targets. It consists of a runtime library and an offline tool that handles most of the model translation work. The core runtime is only ~2KB. The workflow involves constructing and training a model in Tensorflow, then using uTensor to produce C++ code for inferencing. The runtime ensures system safety, guarantees RAM usage, and focuses on clear, concise, and debuggable code. The high-level API simplifies tensor handling and operator execution for embedded systems.
LLMsKnow
LLMs Know More Than They Show is a repository containing code to reproduce the results in the paper. It includes scripts to generate model answers, extract exact answers, probe all layers and tokens, probe specific layers and tokens, conduct generalization experiments, perform resampling for error type probing and answer selection experiments, and run other baselines like logprob detection and p_true detection. The repository supports various datasets such as TriviaQA, Movies, HotpotQA, Winobias, Winogrande, NLI, IMDB, Math, and Natural questions. It also provides supported models like Mistral-7B-Instruct-v0.2, Mistral-7B-v0.3, Meta-Llama-3-8B, and Meta-Llama-3-8B-Instruct.
For similar tasks
ring-attention-pytorch
This repository contains an implementation of Ring Attention, a technique for processing large sequences in transformers. Ring Attention splits the data across the sequence dimension and applies ring reduce to the processing of the tiles of the attention matrix, similar to flash attention. It also includes support for Striped Attention, a follow-up paper that permutes the sequence for better workload balancing for autoregressive transformers, and grouped query attention, which saves on communication costs during the ring reduce. The repository includes a CUDA version of the flash attention kernel, which is used for the forward and backward passes of the ring attention. It also includes logic for splitting the sequence evenly among ranks, either within the attention function or in the external ring transformer wrapper, and basic test cases with two processes to check for equivalent output and gradients.
MoBA
MoBA (Mixture of Block Attention) is an innovative approach for long-context language models, enabling efficient processing of long sequences by dividing the full context into blocks and introducing a parameter-less gating mechanism. It allows seamless transitions between full and sparse attention modes, enhancing efficiency without compromising performance. MoBA has been deployed to support long-context requests and demonstrates significant advancements in efficient attention computation for large language models.
For similar jobs

llama_ros
This repository provides a set of ROS 2 packages to integrate llama.cpp into ROS 2. By using the llama_ros packages, you can easily incorporate the powerful optimization capabilities of llama.cpp into your ROS 2 projects by running GGUF-based LLMs and VLMs.

lmdeploy
LMDeploy is a toolkit for compressing, deploying, and serving LLM, developed by the MMRazor and MMDeploy teams. It has the following core features: * **Efficient Inference** : LMDeploy delivers up to 1.8x higher request throughput than vLLM, by introducing key features like persistent batch(a.k.a. continuous batching), blocked KV cache, dynamic split&fuse, tensor parallelism, high-performance CUDA kernels and so on. * **Effective Quantization** : LMDeploy supports weight-only and k/v quantization, and the 4-bit inference performance is 2.4x higher than FP16. The quantization quality has been confirmed via OpenCompass evaluation. * **Effortless Distribution Server** : Leveraging the request distribution service, LMDeploy facilitates an easy and efficient deployment of multi-model services across multiple machines and cards. * **Interactive Inference Mode** : By caching the k/v of attention during multi-round dialogue processes, the engine remembers dialogue history, thus avoiding repetitive processing of historical sessions.
ring-attention-pytorch
This repository contains an implementation of Ring Attention, a technique for processing large sequences in transformers. Ring Attention splits the data across the sequence dimension and applies ring reduce to the processing of the tiles of the attention matrix, similar to flash attention. It also includes support for Striped Attention, a follow-up paper that permutes the sequence for better workload balancing for autoregressive transformers, and grouped query attention, which saves on communication costs during the ring reduce. The repository includes a CUDA version of the flash attention kernel, which is used for the forward and backward passes of the ring attention. It also includes logic for splitting the sequence evenly among ranks, either within the attention function or in the external ring transformer wrapper, and basic test cases with two processes to check for equivalent output and gradients.

ailia-models
The collection of pre-trained, state-of-the-art AI models. ailia SDK is a self-contained, cross-platform, high-speed inference SDK for AI. The ailia SDK provides a consistent C++ API across Windows, Mac, Linux, iOS, Android, Jetson, and Raspberry Pi platforms. It also supports Unity (C#), Python, Rust, Flutter(Dart) and JNI for efficient AI implementation. The ailia SDK makes extensive use of the GPU through Vulkan and Metal to enable accelerated computing. # Supported models 323 models as of April 8th, 2024

curated-transformers
Curated Transformers is a transformer library for PyTorch that provides state-of-the-art models composed of reusable components. It supports various transformer architectures, including encoders like ALBERT, BERT, and RoBERTa, and decoders like Falcon, Llama, and MPT. The library emphasizes consistent type annotations, minimal dependencies, and ease of use for education and research. It has been production-tested by Explosion and will be the default transformer implementation in spaCy 3.7.

bert4torch
**bert4torch** is a high-level framework for training and deploying transformer models in PyTorch. It provides a simple and efficient API for building, training, and evaluating transformer models, and supports a wide range of pre-trained models, including BERT, RoBERTa, ALBERT, XLNet, and GPT-2. bert4torch also includes a number of useful features, such as data loading, tokenization, and model evaluation. It is a powerful and versatile tool for natural language processing tasks.

FlagEmbedding
FlagEmbedding focuses on retrieval-augmented LLMs, consisting of the following projects currently: * **Long-Context LLM** : Activation Beacon * **Fine-tuning of LM** : LM-Cocktail * **Embedding Model** : Visualized-BGE, BGE-M3, LLM Embedder, BGE Embedding * **Reranker Model** : llm rerankers, BGE Reranker * **Benchmark** : C-MTEB

edenai-apis
Eden AI aims to simplify the use and deployment of AI technologies by providing a unique API that connects to all the best AI engines. With the rise of **AI as a Service** , a lot of companies provide off-the-shelf trained models that you can access directly through an API. These companies are either the tech giants (Google, Microsoft , Amazon) or other smaller, more specialized companies, and there are hundreds of them. Some of the most known are : DeepL (translation), OpenAI (text and image analysis), AssemblyAI (speech analysis). There are **hundreds of companies** doing that. We're regrouping the best ones **in one place** !