
bert4torch
An elegent pytorch implement of transformers
Stars: 1284

**bert4torch** is a high-level framework for training and deploying transformer models in PyTorch. It provides a simple and efficient API for building, training, and evaluating transformer models, and supports a wide range of pre-trained models, including BERT, RoBERTa, ALBERT, XLNet, and GPT-2. bert4torch also includes a number of useful features, such as data loading, tokenization, and model evaluation. It is a powerful and versatile tool for natural language processing tasks.
README:








Documentation | Torch4keras | Examples | build_MiniLLM_from_scratch | bert4vector
安装稳定版
pip install bert4torch安装最新版
pip install git+https://github.com/Tongjilibo/bert4torch- 注意事项:pip包的发布慢于git上的开发版本,git clone注意引用路径,注意权重是否需要转换
-
测试用例:
git clone https://github.com/Tongjilibo/bert4torch,修改example中的预训练模型文件路径和数据路径即可启动脚本 - 自行训练:针对自己的数据,修改相应的数据处理代码块
-
开发环境:原使用
torch==1.10版本进行开发,现已切换到torch2.0开发,如其他版本遇到不适配,欢迎反馈
-
LLM模型: 加载chatglm、llama、 baichuan、ziya、bloom等开源大模型权重进行推理和微调,命令行一行部署大模型
-
核心功能:加载bert、roberta、albert、xlnet、nezha、bart、RoFormer、RoFormer_V2、ELECTRA、GPT、GPT2、T5、GAU-alpha、ERNIE等预训练权重继续进行finetune、并支持在bert基础上灵活定义自己模型
-
丰富示例:包含llm、pretrain、sentence_classfication、sentence_embedding、sequence_labeling、relation_extraction、seq2seq、serving等多种解决方案
-
实验验证:已在公开数据集实验验证,使用如下examples数据集和实验指标
-
易用trick:集成了常见的trick,即插即用
-
其他特性:加载transformers库模型一起使用;调用方式简洁高效;有训练进度条动态展示;配合torchinfo打印参数量;默认Logger和Tensorboard简便记录训练过程;自定义fit过程,满足高阶需求
-
训练过程:

| 功能 | bert4torch | transformers | 备注 |
|---|---|---|---|
| 训练进度条 | ✅ | ✅ | 进度条打印loss和定义的metrics |
| 分布式训练dp/ddp | ✅ | ✅ | torch自带dp/ddp |
| 各类callbacks | ✅ | ✅ | 日志/tensorboard/earlystop/wandb等 |
| 大模型推理,stream/batch输出 | ✅ | ✅ | 各个模型是通用的,无需单独维护脚本 |
| 大模型微调 | ✅ | ✅ | lora依赖peft库,pv2自带 |
| 丰富tricks | ✅ | ❌ | 对抗训练等tricks即插即用 |
| 代码简洁易懂,自定义空间大 | ✅ | ❌ | 代码复用度高, keras代码训练风格 |
| 仓库的维护能力/影响力/使用量/兼容性 | ❌ | ✅ | 目前仓库个人维护 |
| 一键部署大模型 |
- 本地 / 联网加载
# 联网下载全部文件 bert4torch-llm-server --checkpoint_path Qwen2-0.5B-Instruct # 加载本地大模型,联网下载bert4torch_config.json bert4torch-llm-server --checkpoint_path /data/pretrain_ckpt/Qwen/Qwen2-0.5B-Instruct --config_path Qwen/Qwen2-0.5B-Instruct # 加载本地大模型,且bert4torch_config.json已经下载并放于同名目录下 bert4torch-llm-server --checkpoint_path /data/pretrain_ckpt/Qwen/Qwen2-0.5B-Instruct
- 命令行 / gradio网页 / openai_api
# 命令行 bert4torch-llm-server --checkpoint_path /data/pretrain_ckpt/Qwen/Qwen2-0.5B-Instruct --mode cli # gradio网页 bert4torch-llm-server --checkpoint_path /data/pretrain_ckpt/Qwen/Qwen2-0.5B-Instruct --mode gradio # openai_api bert4torch-llm-server --checkpoint_path /data/pretrain_ckpt/Qwen/Qwen2-0.5B-Instruct --mode openai
- 命令行聊天示例

| 更新日期 | bert4torch | torch4keras | 版本说明 |
|---|---|---|---|
| 20250401 | 0.5.6 | 0.2.9 | 命令行支持图片输入, 修复rope在batch推理和超长时候的bug |
| 20250215 | 0.5.5 | 0.2.8 | 增加deepseek-r1, internvl, internlm3, glm4v, modernbert, mllama, qwen2vl, qwenvl |
| 20240928 | 0.5.4 | 0.2.7 | 【新功能】增加deepseek系列、MiniCPM、MiniCPMV、llama3.2、Qwen2.5;支持device_map=auto;【修复】修复batch_generate和n>1的bug |
| 20240814 | 0.5.3 | 0.2.6 | 【新功能】增加llama3.1/Yi1.5;自动选择从hfmirror下载;支持命令行参数bert4torch-llm-server
|
-
预训练模型支持多种代码加载方式
from bert4torch.models import build_transformer_model # 1. 仅指定config_path: 从头初始化模型结构, 不加载预训练模型 model = build_transformer_model('./model/bert4torch_config.json') # 2. 仅指定checkpoint_path: ## 2.1 文件夹路径: 自动寻找路径下的*.bin/*.safetensors权重文件 + 需把bert4torch_config.json下载并放于该目录下 model = build_transformer_model(checkpoint_path='./model') ## 2.2 文件路径/列表: 文件路径即权重路径/列表, bert4torch_config.json会从同级目录下寻找 model = build_transformer_model(checkpoint_path='./pytorch_model.bin') ## 2.3 model_name: hf上预训练权重名称, 会自动下载hf权重以及bert4torch_config.json文件 model = build_transformer_model(checkpoint_path='bert-base-chinese') # 3. 同时指定config_path和checkpoint_path(本地路径名或model_name排列组合): # 本地路径从本地加载,pretrained_model_name会联网下载 config_path = './model/bert4torch_config.json' # 或'bert-base-chinese' checkpoint_path = './model/pytorch_model.bin' # 或'bert-base-chinese' model = build_transformer_model(config_path, checkpoint_path)
-
预训练权重链接和bert4torch_config.json
*注:
-
高亮格式(如bert-base-chinese)的表示可直接build_transformer_model()联网下载 - 国内镜像网站加速下载
HF_ENDPOINT=https://hf-mirror.com python your_script.py-
export HF_ENDPOINT=https://hf-mirror.com后再执行python代码 - 在python代码开头如下设置
import os os.environ['HF_ENDPOINT'] = "https://hf-mirror.com"
- 感谢苏神实现的bert4keras,本实现有不少地方参考了bert4keras的源码,在此衷心感谢大佬的无私奉献;
- 其次感谢项目bert4pytorch,也是在该项目的指引下给了我用pytorch来复现bert4keras的想法和思路。
@misc{bert4torch,
title={bert4torch},
author={Bo Li},
year={2022},
howpublished={\url{https://github.com/Tongjilibo/bert4torch}},
}
- Wechat & Star History Chart
- 微信群人数超过200个(有邀请限制),可添加个人微信拉群
 微信号 |
 微信群 |
Star History Chart |
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for bert4torch
Similar Open Source Tools
bert4torch
**bert4torch** is a high-level framework for training and deploying transformer models in PyTorch. It provides a simple and efficient API for building, training, and evaluating transformer models, and supports a wide range of pre-trained models, including BERT, RoBERTa, ALBERT, XLNet, and GPT-2. bert4torch also includes a number of useful features, such as data loading, tokenization, and model evaluation. It is a powerful and versatile tool for natural language processing tasks.

Qwen-TensorRT-LLM
Qwen-TensorRT-LLM is a project developed for the NVIDIA TensorRT Hackathon 2023, focusing on accelerating inference for the Qwen-7B-Chat model using TRT-LLM. The project offers various functionalities such as FP16/BF16 support, INT8 and INT4 quantization options, Tensor Parallel for multi-GPU parallelism, web demo setup with gradio, Triton API deployment for maximum throughput/concurrency, fastapi integration for openai requests, CLI interaction, and langchain support. It supports models like qwen2, qwen, and qwen-vl for both base and chat models. The project also provides tutorials on Bilibili and blogs for adapting Qwen models in NVIDIA TensorRT-LLM, along with hardware requirements and quick start guides for different model types and quantization methods.

Chinese-Mixtral-8x7B
Chinese-Mixtral-8x7B is an open-source project based on Mistral's Mixtral-8x7B model for incremental pre-training of Chinese vocabulary, aiming to advance research on MoE models in the Chinese natural language processing community. The expanded vocabulary significantly improves the model's encoding and decoding efficiency for Chinese, and the model is pre-trained incrementally on a large-scale open-source corpus, enabling it with powerful Chinese generation and comprehension capabilities. The project includes a large model with expanded Chinese vocabulary and incremental pre-training code.
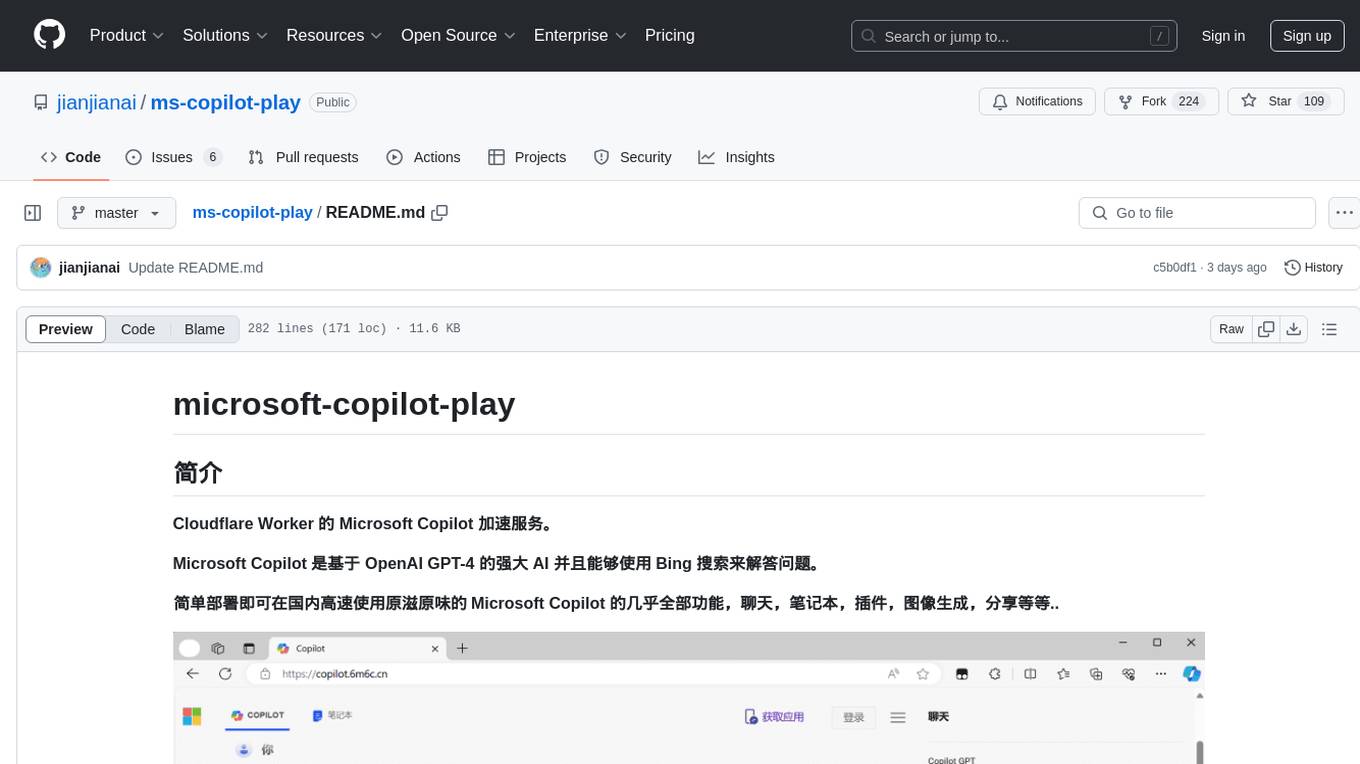
ms-copilot-play
Microsoft Copilot Play is a Cloudflare Worker service that accelerates Microsoft Copilot functionalities in China. It allows high-speed access to Microsoft Copilot features like chatting, notebook, plugins, image generation, and sharing. The service filters out meaningless requests used for statistics, saving up to 80% of Cloudflare Worker requests. Users can deploy the service easily with Cloudflare Worker, ensuring fast and unlimited access with no additional operations. The service leverages the power of Microsoft Copilot, based on OpenAI GPT-4, and utilizes Bing search to answer questions.
we-mp-rss
We-MP-RSS is a tool for subscribing to and managing WeChat official account content, providing RSS subscription functionality. It allows users to fetch and parse WeChat official account content, generate RSS feeds, manage subscriptions via a user-friendly web interface, automatically update content on a schedule, support multiple databases (default SQLite, optional MySQL), various fetching methods, multiple RSS clients, and expiration reminders for authorizations.
petercat
Peter Cat is an intelligent Q&A chatbot solution designed for community maintainers and developers. It provides a conversational Q&A agent configuration system, self-hosting deployment solutions, and a convenient integrated application SDK. Users can easily create intelligent Q&A chatbots for their GitHub repositories and quickly integrate them into various official websites or projects to provide more efficient technical support for the community.
Element-Plus-X
Element-Plus-X is an out-of-the-box enterprise-level AI component library based on Vue 3 + Element-Plus. It features built-in scenario components such as chatbots and voice interactions, seamless integration with zero configuration based on Element-Plus design system, and support for on-demand loading with Tree Shaking optimization.
Muice-Chatbot
Muice-Chatbot is an AI chatbot designed to proactively engage in conversations with users. It is based on the ChatGLM2-6B and Qwen-7B models, with a training dataset of 1.8K+ dialogues. The chatbot has a speaking style similar to a 2D girl, being somewhat tsundere but willing to share daily life details and greet users differently every day. It provides various functionalities, including initiating chats and offering 5 available commands. The project supports model loading through different methods and provides onebot service support for QQ users. Users can interact with the chatbot by running the main.py file in the project directory.
Langchain-Chatchat
LangChain-Chatchat is an open-source, offline-deployable retrieval-enhanced generation (RAG) large model knowledge base project based on large language models such as ChatGLM and application frameworks such as Langchain. It aims to establish a knowledge base Q&A solution that is friendly to Chinese scenarios, supports open-source models, and can run offline.
Llama-Chinese
Llama中文社区是一个专注于Llama模型在中文方面的优化和上层建设的高级技术社区。 **已经基于大规模中文数据,从预训练开始对Llama2模型进行中文能力的持续迭代升级【Done】**。**正在对Llama3模型进行中文能力的持续迭代升级【Doing】** 我们热忱欢迎对大模型LLM充满热情的开发者和研究者加入我们的行列。

Firefly
Firefly is an open-source large model training project that supports pre-training, fine-tuning, and DPO of mainstream large models. It includes models like Llama3, Gemma, Qwen1.5, MiniCPM, Llama, InternLM, Baichuan, ChatGLM, Yi, Deepseek, Qwen, Orion, Ziya, Xverse, Mistral, Mixtral-8x7B, Zephyr, Vicuna, Bloom, etc. The project supports full-parameter training, LoRA, QLoRA efficient training, and various tasks such as pre-training, SFT, and DPO. Suitable for users with limited training resources, QLoRA is recommended for fine-tuning instructions. The project has achieved good results on the Open LLM Leaderboard with QLoRA training process validation. The latest version has significant updates and adaptations for different chat model templates.

LLM-TPU
LLM-TPU project aims to deploy various open-source generative AI models on the BM1684X chip, with a focus on LLM. Models are converted to bmodel using TPU-MLIR compiler and deployed to PCIe or SoC environments using C++ code. The project has deployed various open-source models such as Baichuan2-7B, ChatGLM3-6B, CodeFuse-7B, DeepSeek-6.7B, Falcon-40B, Phi-3-mini-4k, Qwen-7B, Qwen-14B, Qwen-72B, Qwen1.5-0.5B, Qwen1.5-1.8B, Llama2-7B, Llama2-13B, LWM-Text-Chat, Mistral-7B-Instruct, Stable Diffusion, Stable Diffusion XL, WizardCoder-15B, Yi-6B-chat, Yi-34B-chat. Detailed model deployment information can be found in the 'models' subdirectory of the project. For demonstrations, users can follow the 'Quick Start' section. For inquiries about the chip, users can contact SOPHGO via the official website.
jimeng-free-api-all
Jimeng AI Free API is a reverse-engineered API server that encapsulates Jimeng AI's image and video generation capabilities into OpenAI-compatible API interfaces. It supports the latest jimeng-5.0-preview, jimeng-4.6 text-to-image models, Seedance 2.0 multi-image intelligent video generation, zero-configuration deployment, and multi-token support. The API is fully compatible with OpenAI API format, seamlessly integrating with existing clients and supporting multiple session IDs for polling usage.
AI-Guide-and-Demos-zh_CN
This is a Chinese AI/LLM introductory project that aims to help students overcome the initial difficulties of accessing foreign large models' APIs. The project uses the OpenAI SDK to provide a more compatible learning experience. It covers topics such as AI video summarization, LLM fine-tuning, and AI image generation. The project also offers a CodePlayground for easy setup and one-line script execution to experience the charm of AI. It includes guides on API usage, LLM configuration, building AI applications with Gradio, customizing prompts for better model performance, understanding LoRA, and more.
llmio
LLMIO is a Go-based LLM load balancing gateway that provides a unified REST API, weight scheduling, logging, and modern management interface for your LLM clients. It helps integrate different model capabilities from OpenAI, Anthropic, Gemini, and more in a single service. Features include unified API compatibility, weight scheduling with two strategies, visual management dashboard, rate and failure handling, and local persistence with SQLite. The tool supports multiple vendors' APIs and authentication methods, making it versatile for various AI model integrations.
daily_stock_analysis
The daily_stock_analysis repository is an intelligent stock analysis system based on AI large models for A-share/Hong Kong stock/US stock selection. It automatically analyzes and pushes a 'decision dashboard' to WeChat Work/Feishu/Telegram/email daily. The system features multi-dimensional analysis, global market support, market review, AI backtesting validation, multi-channel notifications, and scheduled execution using GitHub Actions. It utilizes AI models like Gemini, OpenAI, DeepSeek, and data sources like AkShare, Tushare, Pytdx, Baostock, YFinance for analysis. The system includes built-in trading disciplines like risk warning, trend trading, precise entry/exit points, and checklist marking for conditions.
For similar tasks

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

onnxruntime-genai
ONNX Runtime Generative AI is a library that provides the generative AI loop for ONNX models, including inference with ONNX Runtime, logits processing, search and sampling, and KV cache management. Users can call a high level `generate()` method, or run each iteration of the model in a loop. It supports greedy/beam search and TopP, TopK sampling to generate token sequences, has built in logits processing like repetition penalties, and allows for easy custom scoring.

jupyter-ai
Jupyter AI connects generative AI with Jupyter notebooks. It provides a user-friendly and powerful way to explore generative AI models in notebooks and improve your productivity in JupyterLab and the Jupyter Notebook. Specifically, Jupyter AI offers: * An `%%ai` magic that turns the Jupyter notebook into a reproducible generative AI playground. This works anywhere the IPython kernel runs (JupyterLab, Jupyter Notebook, Google Colab, Kaggle, VSCode, etc.). * A native chat UI in JupyterLab that enables you to work with generative AI as a conversational assistant. * Support for a wide range of generative model providers, including AI21, Anthropic, AWS, Cohere, Gemini, Hugging Face, NVIDIA, and OpenAI. * Local model support through GPT4All, enabling use of generative AI models on consumer grade machines with ease and privacy.

khoj
Khoj is an open-source, personal AI assistant that extends your capabilities by creating always-available AI agents. You can share your notes and documents to extend your digital brain, and your AI agents have access to the internet, allowing you to incorporate real-time information. Khoj is accessible on Desktop, Emacs, Obsidian, Web, and Whatsapp, and you can share PDF, markdown, org-mode, notion files, and GitHub repositories. You'll get fast, accurate semantic search on top of your docs, and your agents can create deeply personal images and understand your speech. Khoj is self-hostable and always will be.

langchain_dart
LangChain.dart is a Dart port of the popular LangChain Python framework created by Harrison Chase. LangChain provides a set of ready-to-use components for working with language models and a standard interface for chaining them together to formulate more advanced use cases (e.g. chatbots, Q&A with RAG, agents, summarization, extraction, etc.). The components can be grouped into a few core modules: * **Model I/O:** LangChain offers a unified API for interacting with various LLM providers (e.g. OpenAI, Google, Mistral, Ollama, etc.), allowing developers to switch between them with ease. Additionally, it provides tools for managing model inputs (prompt templates and example selectors) and parsing the resulting model outputs (output parsers). * **Retrieval:** assists in loading user data (via document loaders), transforming it (with text splitters), extracting its meaning (using embedding models), storing (in vector stores) and retrieving it (through retrievers) so that it can be used to ground the model's responses (i.e. Retrieval-Augmented Generation or RAG). * **Agents:** "bots" that leverage LLMs to make informed decisions about which available tools (such as web search, calculators, database lookup, etc.) to use to accomplish the designated task. The different components can be composed together using the LangChain Expression Language (LCEL).

danswer
Danswer is an open-source Gen-AI Chat and Unified Search tool that connects to your company's docs, apps, and people. It provides a Chat interface and plugs into any LLM of your choice. Danswer can be deployed anywhere and for any scale - on a laptop, on-premise, or to cloud. Since you own the deployment, your user data and chats are fully in your own control. Danswer is MIT licensed and designed to be modular and easily extensible. The system also comes fully ready for production usage with user authentication, role management (admin/basic users), chat persistence, and a UI for configuring Personas (AI Assistants) and their Prompts. Danswer also serves as a Unified Search across all common workplace tools such as Slack, Google Drive, Confluence, etc. By combining LLMs and team specific knowledge, Danswer becomes a subject matter expert for the team. Imagine ChatGPT if it had access to your team's unique knowledge! It enables questions such as "A customer wants feature X, is this already supported?" or "Where's the pull request for feature Y?"

infinity
Infinity is an AI-native database designed for LLM applications, providing incredibly fast full-text and vector search capabilities. It supports a wide range of data types, including vectors, full-text, and structured data, and offers a fused search feature that combines multiple embeddings and full text. Infinity is easy to use, with an intuitive Python API and a single-binary architecture that simplifies deployment. It achieves high performance, with 0.1 milliseconds query latency on million-scale vector datasets and up to 15K QPS.
For similar jobs

curated-transformers
Curated Transformers is a transformer library for PyTorch that provides state-of-the-art models composed of reusable components. It supports various transformer architectures, including encoders like ALBERT, BERT, and RoBERTa, and decoders like Falcon, Llama, and MPT. The library emphasizes consistent type annotations, minimal dependencies, and ease of use for education and research. It has been production-tested by Explosion and will be the default transformer implementation in spaCy 3.7.
bert4torch
**bert4torch** is a high-level framework for training and deploying transformer models in PyTorch. It provides a simple and efficient API for building, training, and evaluating transformer models, and supports a wide range of pre-trained models, including BERT, RoBERTa, ALBERT, XLNet, and GPT-2. bert4torch also includes a number of useful features, such as data loading, tokenization, and model evaluation. It is a powerful and versatile tool for natural language processing tasks.
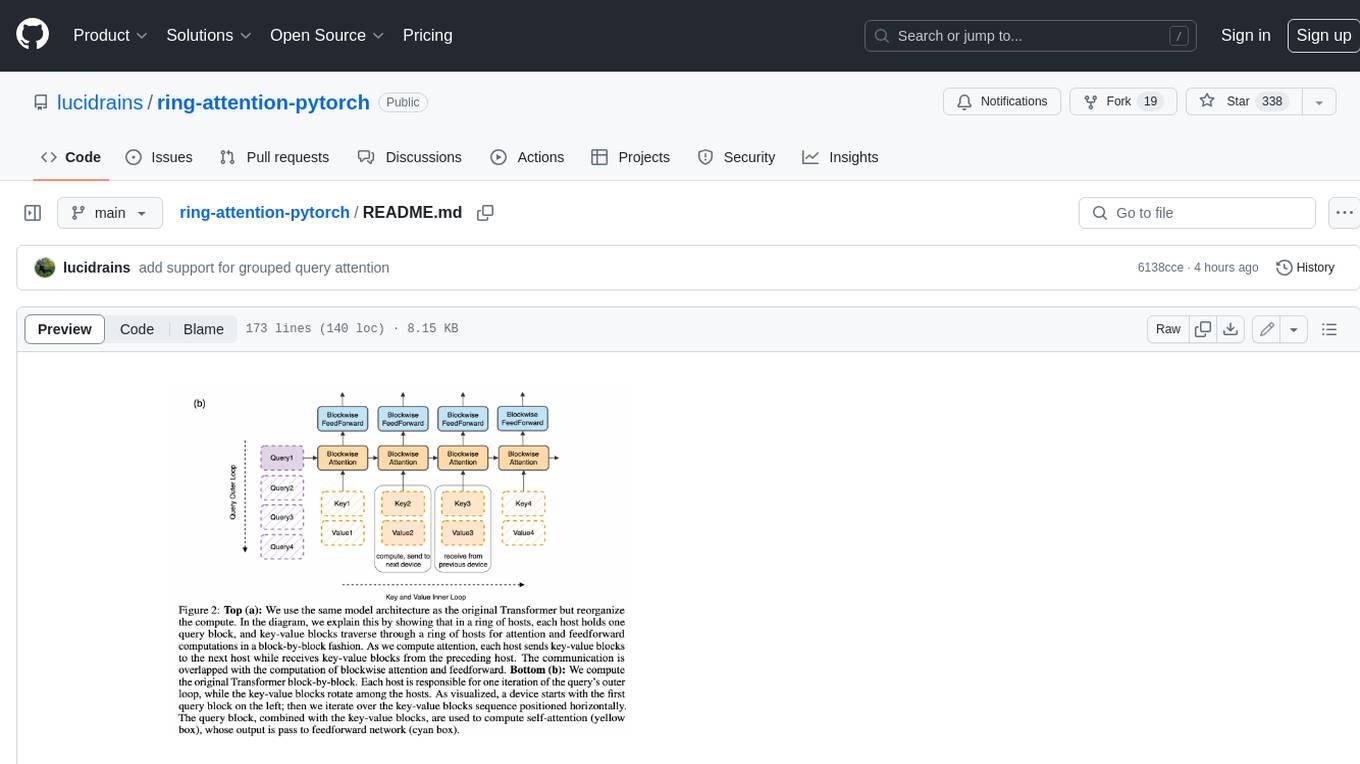
ring-attention-pytorch
This repository contains an implementation of Ring Attention, a technique for processing large sequences in transformers. Ring Attention splits the data across the sequence dimension and applies ring reduce to the processing of the tiles of the attention matrix, similar to flash attention. It also includes support for Striped Attention, a follow-up paper that permutes the sequence for better workload balancing for autoregressive transformers, and grouped query attention, which saves on communication costs during the ring reduce. The repository includes a CUDA version of the flash attention kernel, which is used for the forward and backward passes of the ring attention. It also includes logic for splitting the sequence evenly among ranks, either within the attention function or in the external ring transformer wrapper, and basic test cases with two processes to check for equivalent output and gradients.

FlagEmbedding
FlagEmbedding focuses on retrieval-augmented LLMs, consisting of the following projects currently: * **Long-Context LLM** : Activation Beacon * **Fine-tuning of LM** : LM-Cocktail * **Embedding Model** : Visualized-BGE, BGE-M3, LLM Embedder, BGE Embedding * **Reranker Model** : llm rerankers, BGE Reranker * **Benchmark** : C-MTEB

edenai-apis
Eden AI aims to simplify the use and deployment of AI technologies by providing a unique API that connects to all the best AI engines. With the rise of **AI as a Service** , a lot of companies provide off-the-shelf trained models that you can access directly through an API. These companies are either the tech giants (Google, Microsoft , Amazon) or other smaller, more specialized companies, and there are hundreds of them. Some of the most known are : DeepL (translation), OpenAI (text and image analysis), AssemblyAI (speech analysis). There are **hundreds of companies** doing that. We're regrouping the best ones **in one place** !

mistral.rs
Mistral.rs is a fast LLM inference platform written in Rust. We support inference on a variety of devices, quantization, and easy-to-use application with an Open-AI API compatible HTTP server and Python bindings.
home-llm
Home LLM is a project that provides the necessary components to control your Home Assistant installation with a completely local Large Language Model acting as a personal assistant. The goal is to provide a drop-in solution to be used as a "conversation agent" component by Home Assistant. The 2 main pieces of this solution are Home LLM and Llama Conversation. Home LLM is a fine-tuning of the Phi model series from Microsoft and the StableLM model series from StabilityAI. The model is able to control devices in the user's house as well as perform basic question and answering. The fine-tuning dataset is a custom synthetic dataset designed to teach the model function calling based on the device information in the context. Llama Conversation is a custom component that exposes the locally running LLM as a "conversation agent" in Home Assistant. This component can be interacted with in a few ways: using a chat interface, integrating with Speech-to-Text and Text-to-Speech addons, or running the oobabooga/text-generation-webui project to provide access to the LLM via an API interface.

llama_ros
This repository provides a set of ROS 2 packages to integrate llama.cpp into ROS 2. By using the llama_ros packages, you can easily incorporate the powerful optimization capabilities of llama.cpp into your ROS 2 projects by running GGUF-based LLMs and VLMs.