
VideoLLaMA2
VideoLLaMA 2: Advancing Spatial-Temporal Modeling and Audio Understanding in Video-LLMs
Stars: 630

VideoLLaMA 2 is a project focused on advancing spatial-temporal modeling and audio understanding in video-LLMs. It provides tools for multi-choice video QA, open-ended video QA, and video captioning. The project offers model zoo with different configurations for visual encoder and language decoder. It includes training and evaluation guides, as well as inference capabilities for video and image processing. The project also features a demo setup for running a video-based Large Language Model web demonstration.
README:
![]()


💡 Some other multimodal-LLM projects from our team may interest you ✨.
Video-LLaMA: An Instruction-tuned Audio-Visual Language Model for Video Understanding
Hang Zhang, Xin Li, Lidong Bing




VCD: Mitigating Object Hallucinations in Large Vision-Language Models through Visual Contrastive Decoding
Sicong Leng, Hang Zhang, Guanzheng Chen, Xin Li, Shijian Lu, Chunyan Miao, Lidong Bing



- [2024.07.30] Release checkpoints of VideoLLaMA2-8x7B-Base and VideoLLaMA2-8x7B.
- [2024.06.25] 🔥🔥 As of Jun 25, our VideoLLaMA2-7B-16F is the Top-1 ~7B-sized VideoLLM on the MLVU Leaderboard.
- [2024.06.18] 🔥🔥 As of Jun 18, our VideoLLaMA2-7B-16F is the Top-1 ~7B-sized VideoLLM on the VideoMME Leaderboard.
- [2024.06.17] 👋👋 Update technical report with the latest results and the missing references. If you have works closely related to VideoLLaMA 2 but not mentioned in the paper, feel free to let us know.
- [2024.06.14] 🔥🔥 Online Demo is available.
- [2024.06.03] Release training, evaluation, and serving codes of VideoLLaMA 2.
Basic Dependencies:
- Python >= 3.8
- Pytorch >= 2.2.0
- CUDA Version >= 11.8
- transformers >= 4.41.2 (for mistral tokenizer)
- tokenizers >= 0.19.1 (for mistral tokenizer)
[Online Mode] Install required packages (better for development):
git clone https://github.com/DAMO-NLP-SG/VideoLLaMA2
cd VideoLLaMA2
pip install -r requirements.txt
pip install flash-attn==2.5.8 --no-build-isolation[Offline Mode] Install VideoLLaMA2 as a Python package (better for direct use):
git clone https://github.com/DAMO-NLP-SG/VideoLLaMA2
cd VideoLLaMA2
pip install --upgrade pip # enable PEP 660 support
pip install -e .
pip install flash-attn==2.5.8 --no-build-isolation| Model Name | Model Type | Visual Encoder | Language Decoder | # Training Frames |
|---|---|---|---|---|
| VideoLLaMA2-7B-Base | Base | clip-vit-large-patch14-336 | Mistral-7B-Instruct-v0.2 | 8 |
| VideoLLaMA2-7B | Chat | clip-vit-large-patch14-336 | Mistral-7B-Instruct-v0.2 | 8 |
| VideoLLaMA2-7B-16F-Base | Base | clip-vit-large-patch14-336 | Mistral-7B-Instruct-v0.2 | 16 |
| VideoLLaMA2-7B-16F | Chat | clip-vit-large-patch14-336 | Mistral-7B-Instruct-v0.2 | 16 |
| VideoLLaMA2-8x7B-Base | Base | clip-vit-large-patch14-336 | Mixtral-8x7B-Instruct-v0.1 | 8 |
| VideoLLaMA2-8x7B | Chat | clip-vit-large-patch14-336 | Mixtral-8x7B-Instruct-v0.1 | 8 |
| VideoLLaMA2-72B-Base | Base | clip-vit-large-patch14-336 | Qwen2-72B-Instruct | 8 |
| VideoLLaMA2-72B | Chat | clip-vit-large-patch14-336 | Qwen2-72B-Instruct | 8 |
It is highly recommended to try our online demo first.
To run a video-based LLM (Large Language Model) web demonstration on your device, you will first need to ensure that you have the necessary model checkpoints prepared, followed by adhering to the steps outlined to successfully launch the demo.
- Launch a gradio app directly (VideoLLaMA2-7B is adopted by default):
python videollama2/serve/gradio_web_server_adhoc.py- Launch a global controller
cd /path/to/VideoLLaMA2
python -m videollama2.serve.controller --host 0.0.0.0 --port 10000- Launch a gradio webserver
python -m videollama2.serve.gradio_web_server --controller http://localhost:10000 --model-list-mode reload- Launch one or multiple model workers
# export HF_ENDPOINT=https://hf-mirror.com # If you are unable to access Hugging Face, try to uncomment this line.
python -m videollama2.serve.model_worker --host 0.0.0.0 --controller http://localhost:10000 --port 40000 --worker http://localhost:40000 --model-path /PATH/TO/MODEL1
python -m videollama2.serve.model_worker --host 0.0.0.0 --controller http://localhost:10000 --port 40001 --worker http://localhost:40001 --model-path /PATH/TO/MODEL2
python -m videollama2.serve.model_worker --host 0.0.0.0 --controller http://localhost:10000 --port 40002 --worker http://localhost:40002 --model-path /PATH/TO/MODEL3
...To facilitate further development on top of our codebase, we provide a quick-start guide on how to train a customized VideoLLaMA2 with VideoLLaVA dataset and evaluate the trained model on the mainstream video-llm benchmarks.
- Training Data Structure:
VideoLLaMA2
├── datasets
│ ├── videollava_pt
| | ├── llava_image/ # Available at: https://pan.baidu.com/s/17GYcE69FcJjjUM0e4Gad2w?pwd=9ga3 or https://drive.google.com/drive/folders/1QmFj2FcMAoWNCUyiUtdcW0-IOhLbOBcf?usp=drive_link
| | ├── valley/ # Available at: https://pan.baidu.com/s/1jluOimE7mmihEBfnpwwCew?pwd=jyjz or https://drive.google.com/drive/folders/1QmFj2FcMAoWNCUyiUtdcW0-IOhLbOBcf?usp=drive_link
| | └── valley_llavaimage.json # Available at: https://drive.google.com/file/d/1zGRyVSUMoczGq6cjQFmT0prH67bu2wXD/view, including 703K video-text and 558K image-text pairs
│ ├── videollava_sft
| | ├── llava_image_tune/ # Available at: https://pan.baidu.com/s/1l-jT6t_DlN5DTklwArsqGw?pwd=o6ko
| | ├── videochatgpt_tune/ # Available at: https://pan.baidu.com/s/10hJ_U7wVmYTUo75YHc_n8g?pwd=g1hf
| | └── videochatgpt_llavaimage_tune.json # Available at: https://drive.google.com/file/d/1zGRyVSUMoczGq6cjQFmT0prH67bu2wXD/view, including 100K video-centric, 625K image-centric and 40K text-only conversations- Command:
# VideoLLaMA2-vllava pretraining
bash scripts/vllava/pretrain.sh
# VideoLLaMA2-vllava finetuning
bash scripts/vllava/finetune.sh- Evaluation Data Structure:
VideoLLaMA2
├── eval
│ ├── egoschema # Official website: https://github.com/egoschema/EgoSchema
| | ├── good_clips_git/ # Available at: https://drive.google.com/drive/folders/1SS0VVz8rML1e5gWq7D7VtP1oxE2UtmhQ
| | └── questions.json # Available at: https://github.com/egoschema/EgoSchema/blob/main/questions.json
│ ├── mvbench # Official website: https://huggingface.co/datasets/OpenGVLab/MVBench
| | ├── video/
| | | ├── clever/
| | | └── ...
| | └── json/
| | | ├── action_antonym.json
| | | └── ...
│ ├── perception_test_mcqa # Official website: https://huggingface.co/datasets/OpenGVLab/MVBench
| | ├── videos/ # Available at: https://storage.googleapis.com/dm-perception-test/zip_data/test_videos.zip
| | └── mc_question_test.json # Download from https://storage.googleapis.com/dm-perception-test/zip_data/mc_question_test_annotations.zip
│ ├── videomme # Official website: https://video-mme.github.io/home_page.html#leaderboard
| | ├── test-00000-of-00001.parquet
| | ├── videos/
| | └── subtitles/
│ ├── Activitynet_Zero_Shot_QA # Official website: https://github.com/MILVLG/activitynet-qa
| | ├── all_test/ # Available at: https://mbzuaiac-my.sharepoint.com/:u:/g/personal/hanoona_bangalath_mbzuai_ac_ae/EatOpE7j68tLm2XAd0u6b8ABGGdVAwLMN6rqlDGM_DwhVA?e=90WIuW
| | ├── test_q.json # Available at: https://github.com/MILVLG/activitynet-qa/tree/master/dataset
| | └── test_a.json # Available at: https://github.com/MILVLG/activitynet-qa/tree/master/dataset
│ ├── MSVD_Zero_Shot_QA # Official website: https://github.com/xudejing/video-question-answering
| | ├── videos/
| | ├── test_q.json
| | └── test_a.json
│ ├── videochatgpt_gen # Official website: https://github.com/mbzuai-oryx/Video-ChatGPT/tree/main/quantitative_evaluation
| | ├── Test_Videos/ # Available at: https://mbzuaiac-my.sharepoint.com/:u:/g/personal/hanoona_bangalath_mbzuai_ac_ae/EatOpE7j68tLm2XAd0u6b8ABGGdVAwLMN6rqlDGM_DwhVA?e=90WIuW
| | ├── Test_Human_Annotated_Captions/ # Available at: https://mbzuaiac-my.sharepoint.com/personal/hanoona_bangalath_mbzuai_ac_ae/_layouts/15/onedrive.aspx?id=%2Fpersonal%2Fhanoona%5Fbangalath%5Fmbzuai%5Fac%5Fae%2FDocuments%2FVideo%2DChatGPT%2FData%5FCode%5FModel%5FRelease%2FQuantitative%5FEvaluation%2Fbenchamarking%2FTest%5FHuman%5FAnnotated%5FCaptions%2Ezip&parent=%2Fpersonal%2Fhanoona%5Fbangalath%5Fmbzuai%5Fac%5Fae%2FDocuments%2FVideo%2DChatGPT%2FData%5FCode%5FModel%5FRelease%2FQuantitative%5FEvaluation%2Fbenchamarking&ga=1
| | ├── generic_qa.json # These three json files available at: https://mbzuaiac-my.sharepoint.com/personal/hanoona_bangalath_mbzuai_ac_ae/_layouts/15/onedrive.aspx?id=%2Fpersonal%2Fhanoona%5Fbangalath%5Fmbzuai%5Fac%5Fae%2FDocuments%2FVideo%2DChatGPT%2FData%5FCode%5FModel%5FRelease%2FQuantitative%5FEvaluation%2Fbenchamarking%2FBenchmarking%5FQA&ga=1
| | ├── temporal_qa.json
| | └── consistency_qa.json- Command:
# mvbench evaluation
CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 bash scripts/eval/eval_video_qa_mvbench.sh
# activitynet-qa evaluation (need to set azure openai key/endpoint/deployname)
CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 bash scripts/eval/eval_video_qa_mvbench.shIf you want to train a video-llm on your data, you need to follow the procedures below to prepare the video/image sft data:
- Suppose your data structure is like:
VideoLLaMA2
├── datasets
│ ├── custom_sft
│ | ├── images
│ | ├── videos
| | └── custom.json- Then you should re-organize the annotated video/image sft data according to the following format:
[
{
"id": 0,
"video": "images/xxx.jpg",
"conversations": [
{
"from": "human",
"value": "<image>\nWhat are the colors of the bus in the image?"
},
{
"from": "gpt",
"value": "The bus in the image is white and red."
},
...
],
}
{
"id": 1,
"video": "videos/xxx.mp4",
"conversations": [
{
"from": "human",
"value": "<video>\nWhat are the main activities that take place in the video?"
},
{
"from": "gpt",
"value": "The main activities that take place in the video are the preparation of camera equipment by a man, a group of men riding a helicopter, and a man sailing a boat through the water."
},
...
],
},
...
]- Modify the
scripts/custom/finetune.sh:
...
--data_path datasets/custom_sft/custom.json
--data_folder datasets/custom_sft/
--pretrain_mm_mlp_adapter CONNECTOR_DOWNLOAD_PATH (e.g., DAMO-NLP-SG/VideoLLaMA2-7B-Base)
...Video/Image Inference:
import sys
sys.path.append('./')
from videollama2 import model_init, mm_infer
from videollama2.utils import disable_torch_init
def inference():
disable_torch_init()
# Video Inference
modal = 'video'
modal_path = 'assets/cat_and_chicken.mp4'
instruct = 'What animals are in the video, what are they doing, and how does the video feel?'
# Reply:
# The video features a kitten and a baby chick playing together. The kitten is seen laying on the floor while the baby chick hops around. The two animals interact playfully with each other, and the video has a cute and heartwarming feel to it.
# Image Inference
modal = 'image'
modal_path = 'assets/sora.png'
instruct = 'What is the woman wearing, what is she doing, and how does the image feel?'
# Reply:
# The woman in the image is wearing a black coat and sunglasses, and she is walking down a rain-soaked city street. The image feels vibrant and lively, with the bright city lights reflecting off the wet pavement, creating a visually appealing atmosphere. The woman's presence adds a sense of style and confidence to the scene, as she navigates the bustling urban environment.
model_path = 'DAMO-NLP-SG/VideoLLaMA2-7B'
# Base model inference (only need to replace model_path)
# model_path = 'DAMO-NLP-SG/VideoLLaMA2-7B-Base'
model, processor, tokenizer = model_init(model_path)
output = mm_infer(processor[modal](modal_path), instruct, model=model, tokenizer=tokenizer, do_sample=False, modal=modal)
print(output)
if __name__ == "__main__":
inference()If you find VideoLLaMA useful for your research and applications, please cite using this BibTeX:
@article{damonlpsg2024videollama2,
title={VideoLLaMA 2: Advancing Spatial-Temporal Modeling and Audio Understanding in Video-LLMs},
author={Cheng, Zesen and Leng, Sicong and Zhang, Hang and Xin, Yifei and Li, Xin and Chen, Guanzheng and Zhu, Yongxin and Zhang, Wenqi and Luo, Ziyang and Zhao, Deli and Bing, Lidong},
journal={arXiv preprint arXiv:2406.07476},
year={2024},
url = {https://arxiv.org/abs/2406.07476}
}
@article{damonlpsg2023videollama,
title = {Video-LLaMA: An Instruction-tuned Audio-Visual Language Model for Video Understanding},
author = {Zhang, Hang and Li, Xin and Bing, Lidong},
journal = {arXiv preprint arXiv:2306.02858},
year = {2023},
url = {https://arxiv.org/abs/2306.02858}
}The codebase of VideoLLaMA 2 is adapted from LLaVA 1.5 and FastChat. We are also grateful for the following projects our VideoLLaMA 2 arise from:
- LLaMA 2, Mistral-7B, OpenAI CLIP, Honeybee.
- Video-ChatGPT, Video-LLaVA.
- WebVid, Panda-70M, LanguageBind, InternVid.
- VideoChat2, Valley, VTimeLLM, ShareGPT4V.
This project is released under the Apache 2.0 license as found in the LICENSE file. The service is a research preview intended for non-commercial use ONLY, subject to the model Licenses of LLaMA and Mistral, Terms of Use of the data generated by OpenAI, and Privacy Practices of ShareGPT. Please get in touch with us if you find any potential violations.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for VideoLLaMA2
Similar Open Source Tools
VideoLLaMA2
VideoLLaMA 2 is a project focused on advancing spatial-temporal modeling and audio understanding in video-LLMs. It provides tools for multi-choice video QA, open-ended video QA, and video captioning. The project offers model zoo with different configurations for visual encoder and language decoder. It includes training and evaluation guides, as well as inference capabilities for video and image processing. The project also features a demo setup for running a video-based Large Language Model web demonstration.

swift
SWIFT (Scalable lightWeight Infrastructure for Fine-Tuning) supports training, inference, evaluation and deployment of nearly **200 LLMs and MLLMs** (multimodal large models). Developers can directly apply our framework to their own research and production environments to realize the complete workflow from model training and evaluation to application. In addition to supporting the lightweight training solutions provided by [PEFT](https://github.com/huggingface/peft), we also provide a complete **Adapters library** to support the latest training techniques such as NEFTune, LoRA+, LLaMA-PRO, etc. This adapter library can be used directly in your own custom workflow without our training scripts. To facilitate use by users unfamiliar with deep learning, we provide a Gradio web-ui for controlling training and inference, as well as accompanying deep learning courses and best practices for beginners. Additionally, we are expanding capabilities for other modalities. Currently, we support full-parameter training and LoRA training for AnimateDiff.

InternLM
InternLM is a powerful language model series with features such as 200K context window for long-context tasks, outstanding comprehensive performance in reasoning, math, code, chat experience, instruction following, and creative writing, code interpreter & data analysis capabilities, and stronger tool utilization capabilities. It offers models in sizes of 7B and 20B, suitable for research and complex scenarios. The models are recommended for various applications and exhibit better performance than previous generations. InternLM models may match or surpass other open-source models like ChatGPT. The tool has been evaluated on various datasets and has shown superior performance in multiple tasks. It requires Python >= 3.8, PyTorch >= 1.12.0, and Transformers >= 4.34 for usage. InternLM can be used for tasks like chat, agent applications, fine-tuning, deployment, and long-context inference.


UMOE-Scaling-Unified-Multimodal-LLMs
Uni-MoE is a MoE-based unified multimodal model that can handle diverse modalities including audio, speech, image, text, and video. The project focuses on scaling Unified Multimodal LLMs with a Mixture of Experts framework. It offers enhanced functionality for training across multiple nodes and GPUs, as well as parallel processing at both the expert and modality levels. The model architecture involves three training stages: building connectors for multimodal understanding, developing modality-specific experts, and incorporating multiple trained experts into LLMs using the LoRA technique on mixed multimodal data. The tool provides instructions for installation, weights organization, inference, training, and evaluation on various datasets.

LLaMA-Factory
LLaMA Factory is a unified framework for fine-tuning 100+ large language models (LLMs) with various methods, including pre-training, supervised fine-tuning, reward modeling, PPO, DPO and ORPO. It features integrated algorithms like GaLore, BAdam, DoRA, LongLoRA, LLaMA Pro, LoRA+, LoftQ and Agent tuning, as well as practical tricks like FlashAttention-2, Unsloth, RoPE scaling, NEFTune and rsLoRA. LLaMA Factory provides experiment monitors like LlamaBoard, TensorBoard, Wandb, MLflow, etc., and supports faster inference with OpenAI-style API, Gradio UI and CLI with vLLM worker. Compared to ChatGLM's P-Tuning, LLaMA Factory's LoRA tuning offers up to 3.7 times faster training speed with a better Rouge score on the advertising text generation task. By leveraging 4-bit quantization technique, LLaMA Factory's QLoRA further improves the efficiency regarding the GPU memory.

LLaVA-pp
This repository, LLaVA++, extends the visual capabilities of the LLaVA 1.5 model by incorporating the latest LLMs, Phi-3 Mini Instruct 3.8B, and LLaMA-3 Instruct 8B. It provides various models for instruction-following LMMS and academic-task-oriented datasets, along with training scripts for Phi-3-V and LLaMA-3-V. The repository also includes installation instructions and acknowledgments to related open-source contributions.

llama.cpp
The main goal of llama.cpp is to enable LLM inference with minimal setup and state-of-the-art performance on a wide range of hardware - locally and in the cloud. It provides a Plain C/C++ implementation without any dependencies, optimized for Apple silicon via ARM NEON, Accelerate and Metal frameworks, and supports various architectures like AVX, AVX2, AVX512, and AMX. It offers integer quantization for faster inference, custom CUDA kernels for NVIDIA GPUs, Vulkan and SYCL backend support, and CPU+GPU hybrid inference. llama.cpp is the main playground for developing new features for the ggml library, supporting various models and providing tools and infrastructure for LLM deployment.

Hands-On-Large-Language-Models-CN
Hands-On Large Language Models CN(ZH) is a Chinese version of the book 'Hands-On Large Language Models' by Jay Alammar and Maarten Grootendorst. It provides detailed code annotations and additional insights, offers Notebook versions suitable for Chinese network environments, utilizes openbayes for free GPU access, allows convenient environment setup with vscode, and includes accompanying Chinese language videos on platforms like Bilibili and YouTube. The book covers various chapters on topics like Tokens and Embeddings, Transformer LLMs, Text Classification, Text Clustering, Prompt Engineering, Text Generation, Semantic Search, Multimodal LLMs, Text Embedding Models, Fine-tuning Models, and more.

llama.cpp
llama.cpp is a C++ implementation of LLaMA, a large language model from Meta. It provides a command-line interface for inference and can be used for a variety of tasks, including text generation, translation, and question answering. llama.cpp is highly optimized for performance and can be run on a variety of hardware, including CPUs, GPUs, and TPUs.
achatbot
achatbot is a factory tool that allows users to create chat bots with various functionalities such as llm (language models), asr (automatic speech recognition), tts (text-to-speech), vad (voice activity detection), ocr (optical character recognition), and object detection. The tool provides a structured project with features like chat bots for cmd, grpc, and http servers. It supports various chat bot processors, transport connectors, and AI modules for different tasks. Users can run chat bots locally or deploy them on cloud services like vercel, Cloudflare, AWS Lambda, or Docker. The tool also includes UI components for easy deployment and service architecture diagrams for reference.
PocketFlow
Pocket Flow is a 100-line minimalist LLM framework designed for (Multi-)Agents, Workflow, RAG, etc. It provides a core abstraction for LLM projects by focusing on computation and communication through a graph structure and shared store. The framework aims to support the development of LLM Agents, such as Cursor AI, by offering a minimal and low-level approach that is well-suited for understanding and usage. Users can install Pocket Flow via pip or by copying the source code, and detailed documentation is available on the project website.

Steel-LLM
Steel-LLM is a project to pre-train a large Chinese language model from scratch using over 1T of data to achieve a parameter size of around 1B, similar to TinyLlama. The project aims to share the entire process including data collection, data processing, pre-training framework selection, model design, and open-source all the code. The goal is to enable reproducibility of the work even with limited resources. The name 'Steel' is inspired by a band '万能青年旅店' and signifies the desire to create a strong model despite limited conditions. The project involves continuous data collection of various cultural elements, trivia, lyrics, niche literature, and personal secrets to train the LLM. The ultimate aim is to fill the model with diverse data and leave room for individual input, fostering collaboration among users.
awesome-saas
The Alchemyst Platform Cookbook is a comprehensive guide for developers and builders to bring their AI ideas to life. It provides cutting-edge AI tools and templates to empower users in creating innovative projects. The platform offers API documentation, quick start guides, official and community templates for various projects. Users can contribute to the platform by forking the repository, adding the topic 'alchemyst-awesome-saas', making their repository public, and submitting a pull request. Troubleshooting guidelines are provided for contributors. The platform is actively maintained by the Alchemyst AI Team.

ASTRA.ai
Astra.ai is a multimodal agent powered by TEN, showcasing its capabilities in speech, vision, and reasoning through RAG from local documentation. It provides a platform for developing AI agents with features like RTC transportation, extension store, workflow builder, and local deployment. Users can build and test agents locally using Docker and Node.js, with prerequisites including Agora App ID, Azure's speech-to-text and text-to-speech API keys, and OpenAI API key. The platform offers advanced customization options through config files and API keys setup, enabling users to create and deploy their AI agents for various tasks.
new-api
New API is a next-generation large model gateway and AI asset management system that provides a wide range of features, including a new UI interface, multi-language support, online recharge function, key query for usage quota, compatibility with the original One API database, model charging by usage count, channel weighted randomization, data dashboard, token grouping and model restrictions, support for various authorization login methods, support for Rerank models, OpenAI Realtime API, Claude Messages format, reasoning effort setting, content reasoning, user-specific model rate limiting, request format conversion, cache billing support, and various model support such as gpts, Midjourney-Proxy, Suno API, custom channels, Rerank models, Claude Messages format, Dify, and more.
For similar tasks
VideoLLaMA2
VideoLLaMA 2 is a project focused on advancing spatial-temporal modeling and audio understanding in video-LLMs. It provides tools for multi-choice video QA, open-ended video QA, and video captioning. The project offers model zoo with different configurations for visual encoder and language decoder. It includes training and evaluation guides, as well as inference capabilities for video and image processing. The project also features a demo setup for running a video-based Large Language Model web demonstration.
vigenair
ViGenAiR is a tool that harnesses the power of Generative AI models on Google Cloud Platform to automatically transform long-form Video Ads into shorter variants, targeting different audiences. It generates video, image, and text assets for Demand Gen and YouTube video campaigns. Users can steer the model towards generating desired videos, conduct A/B testing, and benefit from various creative features. The tool offers benefits like diverse inventory, compelling video ads, creative excellence, user control, and performance insights. ViGenAiR works by analyzing video content, splitting it into coherent segments, and generating variants following Google's best practices for effective ads.
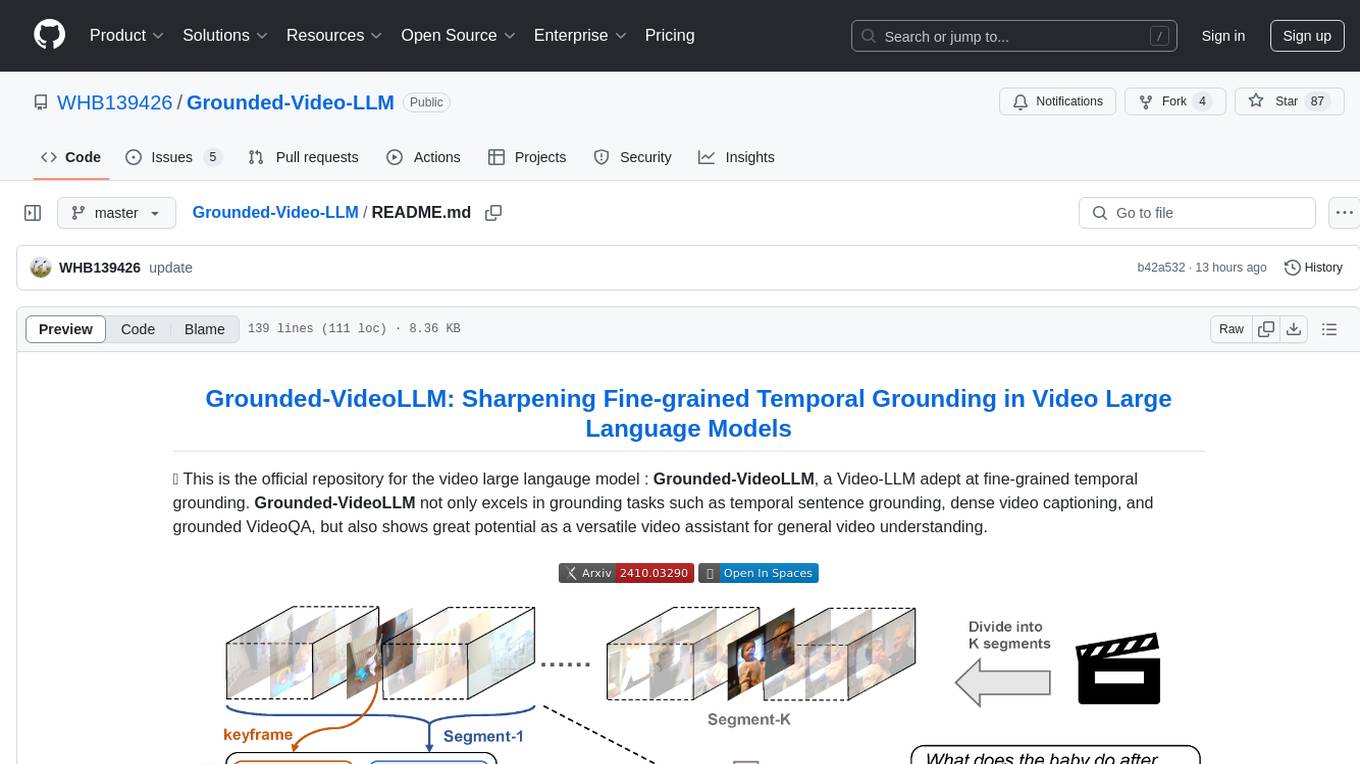
Grounded-Video-LLM
Grounded-VideoLLM is a Video Large Language Model specialized in fine-grained temporal grounding. It excels in tasks such as temporal sentence grounding, dense video captioning, and grounded VideoQA. The model incorporates an additional temporal stream, discrete temporal tokens with specific time knowledge, and a multi-stage training scheme. It shows potential as a versatile video assistant for general video understanding. The repository provides pretrained weights, inference scripts, and datasets for training. Users can run inference queries to get temporal information from videos and train the model from scratch.

Awesome-LLMs-for-Video-Understanding
Awesome-LLMs-for-Video-Understanding is a repository dedicated to exploring Video Understanding with Large Language Models. It provides a comprehensive survey of the field, covering models, pretraining, instruction tuning, and hybrid methods. The repository also includes information on tasks, datasets, and benchmarks related to video understanding. Contributors are encouraged to add new papers, projects, and materials to enhance the repository.
For similar jobs

promptflow
**Prompt flow** is a suite of development tools designed to streamline the end-to-end development cycle of LLM-based AI applications, from ideation, prototyping, testing, evaluation to production deployment and monitoring. It makes prompt engineering much easier and enables you to build LLM apps with production quality.

deepeval
DeepEval is a simple-to-use, open-source LLM evaluation framework specialized for unit testing LLM outputs. It incorporates various metrics such as G-Eval, hallucination, answer relevancy, RAGAS, etc., and runs locally on your machine for evaluation. It provides a wide range of ready-to-use evaluation metrics, allows for creating custom metrics, integrates with any CI/CD environment, and enables benchmarking LLMs on popular benchmarks. DeepEval is designed for evaluating RAG and fine-tuning applications, helping users optimize hyperparameters, prevent prompt drifting, and transition from OpenAI to hosting their own Llama2 with confidence.

MegaDetector
MegaDetector is an AI model that identifies animals, people, and vehicles in camera trap images (which also makes it useful for eliminating blank images). This model is trained on several million images from a variety of ecosystems. MegaDetector is just one of many tools that aims to make conservation biologists more efficient with AI. If you want to learn about other ways to use AI to accelerate camera trap workflows, check out our of the field, affectionately titled "Everything I know about machine learning and camera traps".

leapfrogai
LeapfrogAI is a self-hosted AI platform designed to be deployed in air-gapped resource-constrained environments. It brings sophisticated AI solutions to these environments by hosting all the necessary components of an AI stack, including vector databases, model backends, API, and UI. LeapfrogAI's API closely matches that of OpenAI, allowing tools built for OpenAI/ChatGPT to function seamlessly with a LeapfrogAI backend. It provides several backends for various use cases, including llama-cpp-python, whisper, text-embeddings, and vllm. LeapfrogAI leverages Chainguard's apko to harden base python images, ensuring the latest supported Python versions are used by the other components of the stack. The LeapfrogAI SDK provides a standard set of protobuffs and python utilities for implementing backends and gRPC. LeapfrogAI offers UI options for common use-cases like chat, summarization, and transcription. It can be deployed and run locally via UDS and Kubernetes, built out using Zarf packages. LeapfrogAI is supported by a community of users and contributors, including Defense Unicorns, Beast Code, Chainguard, Exovera, Hypergiant, Pulze, SOSi, United States Navy, United States Air Force, and United States Space Force.

llava-docker
This Docker image for LLaVA (Large Language and Vision Assistant) provides a convenient way to run LLaVA locally or on RunPod. LLaVA is a powerful AI tool that combines natural language processing and computer vision capabilities. With this Docker image, you can easily access LLaVA's functionalities for various tasks, including image captioning, visual question answering, text summarization, and more. The image comes pre-installed with LLaVA v1.2.0, Torch 2.1.2, xformers 0.0.23.post1, and other necessary dependencies. You can customize the model used by setting the MODEL environment variable. The image also includes a Jupyter Lab environment for interactive development and exploration. Overall, this Docker image offers a comprehensive and user-friendly platform for leveraging LLaVA's capabilities.

carrot
The 'carrot' repository on GitHub provides a list of free and user-friendly ChatGPT mirror sites for easy access. The repository includes sponsored sites offering various GPT models and services. Users can find and share sites, report errors, and access stable and recommended sites for ChatGPT usage. The repository also includes a detailed list of ChatGPT sites, their features, and accessibility options, making it a valuable resource for ChatGPT users seeking free and unlimited GPT services.

TrustLLM
TrustLLM is a comprehensive study of trustworthiness in LLMs, including principles for different dimensions of trustworthiness, established benchmark, evaluation, and analysis of trustworthiness for mainstream LLMs, and discussion of open challenges and future directions. Specifically, we first propose a set of principles for trustworthy LLMs that span eight different dimensions. Based on these principles, we further establish a benchmark across six dimensions including truthfulness, safety, fairness, robustness, privacy, and machine ethics. We then present a study evaluating 16 mainstream LLMs in TrustLLM, consisting of over 30 datasets. The document explains how to use the trustllm python package to help you assess the performance of your LLM in trustworthiness more quickly. For more details about TrustLLM, please refer to project website.

AI-YinMei
AI-YinMei is an AI virtual anchor Vtuber development tool (N card version). It supports fastgpt knowledge base chat dialogue, a complete set of solutions for LLM large language models: [fastgpt] + [one-api] + [Xinference], supports docking bilibili live broadcast barrage reply and entering live broadcast welcome speech, supports Microsoft edge-tts speech synthesis, supports Bert-VITS2 speech synthesis, supports GPT-SoVITS speech synthesis, supports expression control Vtuber Studio, supports painting stable-diffusion-webui output OBS live broadcast room, supports painting picture pornography public-NSFW-y-distinguish, supports search and image search service duckduckgo (requires magic Internet access), supports image search service Baidu image search (no magic Internet access), supports AI reply chat box [html plug-in], supports AI singing Auto-Convert-Music, supports playlist [html plug-in], supports dancing function, supports expression video playback, supports head touching action, supports gift smashing action, supports singing automatic start dancing function, chat and singing automatic cycle swing action, supports multi scene switching, background music switching, day and night automatic switching scene, supports open singing and painting, let AI automatically judge the content.