
rwkv-qualcomm
Inference RWKV v5, v6 and (WIP) v7 with Qualcomm AI Engine Direct SDK
Stars: 53
This repository provides support for inference RWKV models on Qualcomm HTP (Hexagon Tensor Processor) using QNN SDK. It supports RWKV v5, v6, and experimentally v7 models, inference using Qualcomm CPU, GPU, or HTP as the backend, whole-model float16 inference, activation INT16 and weights INT8 quantized inference, and activation INT16 and weights INT4/INT8 mixed quantized inference. Users can convert model weights to QNN model library files, generate HTP context cache, and run inference on Qualcomm Snapdragon SM8650 with HTP v75. The project requires QNN SDK, AIMET toolkit, and specific hardware for verification.
README:
- Support for RWKV v5, v6 and experimentally v7 models
- Inference RWKV using QNN SDK, with Qualcomm CPU, GPU or HTP (Hexagon Tensor Processor) as the backend.
- Support for whole-model float16 inference (since Qualcomm HTP cannot do float32 math).
- Support for activation INT16 and weights INT8 quantized inference (with some key operations running with float16).
- Support for activation INT16 and weights INT4/INT8 mixed quantized inference.
- Download and install the QNN SDK from the Qualcomm Developer Network.
- Setup the QNN SDK environment by following the instructions in Qualcomm's documents.
- Setup the $QNN_SDK_ROOT environment variable to point to the QNN SDK installation directory. It should by default be installed at /opt/qcom/aistack/qnn/{version}.
- (Optional) Install the AIMET toolkit for aimet quantization methods: https://quic.github.io/aimet-pages/releases/latest/install/index.html#quick-install
- This project has been verified with:
- QNN SDK 2.31.0
- python==3.10 (as is recommended by QNN SDK documentation)
- onnx==1.17.0
- protobuf==5.29.3
- torch==2.1.2
- aimet-torch==2.0.0
- Hardware: Qualcomm Snapdragon SM8650 with HTP v75 (Xiaomi Mi 14)
python compute_quant_encodings_experimental.py ../models/RWKV-x070-World-1.5B-v3-20250127-ctx4096.pth --output_folder v7_1b5_quant- The quantization encodings file will be in
v7_1b5_quant/RWKV-x070-World-1.5B-v3-20250127-ctx4096.encodingsandv7_1b5_quant/RWKV-x070-World-1.5B-v3-20250127-ctx4096_prefill.encodings - Convert the model file:
python convert_model.py --chunks 1 --qnn_float_width 16 --wkv_customop --quant_encodings v7_1b5_quant/RWKV-x070-World-1.5B-v3-20250127-ctx4096.encodings ../models/RWKV-x070-World-1.5B-v3-20250127-ctx4096.pth(Note: please remove--qnn_float_width 16for devices other than 8Gen3(SM8650)) - Convert the model file (prefill model with sequence length=128):
python convert_model.py --chunks 1 --qnn_float_width 16 --wkv_customop --prefill_model --quant_encodings v7_1b5_quant/RWKV-x070-World-1.5B-v3-20250127-ctx4096_prefill.encodings ../models/RWKV-x070-World-1.5B-v3-20250127-ctx4096.pth(Note: please remove--qnn_float_width 16for devices older than 8Gen3(SM8650)) - The act_bitwidth and weights_bitwidth default to 16 and 8 respectively.
TODO
-
make_context_cache_binary.py: usage: usage: make_context_cache_binary.py [-h] [--use_optrace] [--wkv_customop] [--output_name OUTPUT_NAME] [--prefill] model_lib output_path {SM8650,SM8550,SC8380,SM8475} - Example:
$ python make_context_cache_binary.py --prefill --wkv_customop lib/x86_64-linux-clang/libRWKV-x070-World-1.5B-v3-20250127-ctx4096.so output/ SM8650
- The script will automatically process each of the chunks together.
- The output would be in
output/RWKV-x070-World-1.5B-v3-20250127-ctx4096_combined.binwhich has weight sharing enabled for prefill and decoding graphs.
- Build the demo code:
make -C librwkv-qualcomm - Push the binary and the HTP context cache to the device:
adb push librwkv-qualcomm/obj/local/arm64-v8a/rwkv-qualcomm-demo /data/local/tmp/ && adb push output/RWKV-x070-World-1.5B-v3-20250127-ctx4096_combined.bin /data/local/tmp/ - Push the tokenizer model to the device:
adb push assets/b_rwkv_vocab_v20230424.txt /data/local/tmp/ - Push these QNN libs to the device
/data/local/tmp/(Please change the HTP V75 version to the one you have):
/opt/qcom/aistack/qairt/2.31.0.250130/lib/aarch64-android/libQnnHtpNetRunExtensions.so
/opt/qcom/aistack/qairt/2.31.0.250130/lib/aarch64-android/libQnnHtpNetRunExtensions.so
/opt/qcom/aistack/qairt/2.31.0.250130/lib/aarch64-android/libQnnSystem.so
/opt/qcom/aistack/qairt/2.31.0.250130/lib/aarch64-android/libQnnHtpV75Stub.so
/opt/qcom/aistack/qairt/2.31.0.250130/lib/hexagon-v75/unsigned/libQnnHtpV75Skel.so
- Finally run the demo code:
adb shell
$ cd /data/local/tmp
$ export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/data/local/tmp
$ # Specify the path to the first model chunk. The second chunk will be loaded automatically.
$ ./rwkv-qualcomm-demo brwkv_vocab_v20230424.txt RWKV-x070-World-1.5B-v3-20250127-ctx4096_combined.bin
- TODO
RWKV v6 1B6 A16W4
130|houji:/data/local/tmp/rwkv $ ./rwkv-qualcomm-demo b_rwkv_vocab_v20230424.txt RWKV-x060-World-1B6-v2.1-20240328-ctx4096_chunk1of2.bin
Loading model context binary from RWKV-x060-World-1B6-v2.1-20240328-ctx4096_chunk1of2.bin
Reading chunk: RWKV-x060-World-1B6-v2.1-20240328-ctx4096_chunk1of2.bin
Buffer size: 719802320
Reading chunk: RWKV-x060-World-1B6-v2.1-20240328-ctx4096_chunk2of2.bin
Buffer size: 586727640
User: 请为我写一首诗。
Assistant: 当然,请告诉我你喜欢什么类型的诗歌。
User: 请写一首描写秋天景色的诗。
Assistant: 秋意渐浓,寒意渐深,
大地已是金黄如火,
落英纷飞,树影绰约,
人心也随之变得清静。
夜空中的繁星在闪闪,
思念似要被所有握住,
但又像是永不消散的孤注,
在这个秋天里如此特别。
请问这首诗符合您需求吗?
Average time per token: 0.0235644s
Average tokens per second: 42.4368
Running on the Qualcomm Snapdragon SM8650 with HTP v75 (Xiaomi Mi 14)
| Model | Precision | Generation Tokens per second | LAMBADA ppl, acc |
|---|---|---|---|
| RWKV v6 1.6B | att-a16w8 + ffn-a16w4 | 42.4368 | 5.09183,65.4182% |
| RWKV v6 1.6B | a16w8 | 31.6564 | 4.75009,66.3497% |
| RWKV v6 1.6B | fp16 | 15.0434 | 4.63598,67.2618% |
| RWKV v6 3B | att-a16w8 + ffn-a16w4 | 21.3172 | 4.46606,68.8725% |
| RWKV v6 3B | a16w8 | 16.2146 | 3.9039,71.3647% |
(Currently QNN's INT4 quantization is the naive linear per-channel quantization, together with the INT16 activation quantization, the perplexity gets a bit worse than the INT8 models. LAMBADA test accuracy seems lower but still acceptable.)
(Experimental) Running with custom WKV kernel
| Model | Precision | Generation Tokens per second | LAMBADA ppl, acc |
|---|---|---|---|
| RWKV v6 1.6B | att-a16w8 + ffn-a16w4 | 47.6698 | 5.09183,65.4182% |
| RWKV v6 7B | a16w4 | 12.9782 | TODO |
- [x] Add demo code for running inference on the device.
- [x] Add support for A16W8 quantized inference.
- [x] Add support for A16W4 quantized inference with AIMET quantization.
- [ ] Add document for running on Snapdragon X Elite laptops.
- [ ] Sequential prefilling on device.
- [ ] Package a library for easy use and integration.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for rwkv-qualcomm
Similar Open Source Tools
rwkv-qualcomm
This repository provides support for inference RWKV models on Qualcomm HTP (Hexagon Tensor Processor) using QNN SDK. It supports RWKV v5, v6, and experimentally v7 models, inference using Qualcomm CPU, GPU, or HTP as the backend, whole-model float16 inference, activation INT16 and weights INT8 quantized inference, and activation INT16 and weights INT4/INT8 mixed quantized inference. Users can convert model weights to QNN model library files, generate HTP context cache, and run inference on Qualcomm Snapdragon SM8650 with HTP v75. The project requires QNN SDK, AIMET toolkit, and specific hardware for verification.
GPULlama3.java
GPULlama3.java powered by TornadoVM is a Java-native implementation of Llama3 that automatically compiles and executes Java code on GPUs via TornadoVM. It supports Llama3, Mistral, Qwen2.5, Qwen3, and Phi3 models in the GGUF format. The repository aims to provide GPU acceleration for Java code, enabling faster execution and high-performance access to off-heap memory. It offers features like interactive and instruction modes, flexible backend switching between OpenCL and PTX, and cross-platform compatibility with NVIDIA, Intel, and Apple GPUs.

GraphGen
GraphGen is a framework for synthetic data generation guided by knowledge graphs. It enhances supervised fine-tuning for large language models (LLMs) by generating synthetic data based on a fine-grained knowledge graph. The tool identifies knowledge gaps in LLMs, prioritizes generating QA pairs targeting high-value knowledge, incorporates multi-hop neighborhood sampling, and employs style-controlled generation to diversify QA data. Users can use LLaMA-Factory and xtuner for fine-tuning LLMs after data generation.
lemonade
Lemonade is a tool that helps users run local Large Language Models (LLMs) with high performance by configuring state-of-the-art inference engines for their Neural Processing Units (NPUs) and Graphics Processing Units (GPUs). It is used by startups, research teams, and large companies to run LLMs efficiently. Lemonade provides a high-level Python API for direct integration of LLMs into Python applications and a CLI for mixing and matching LLMs with various features like prompting templates, accuracy testing, performance benchmarking, and memory profiling. The tool supports both GGUF and ONNX models and allows importing custom models from Hugging Face using the Model Manager. Lemonade is designed to be easy to use and switch between different configurations at runtime, making it a versatile tool for running LLMs locally.

LocalAI
LocalAI is a free and open-source OpenAI alternative that acts as a drop-in replacement REST API compatible with OpenAI (Elevenlabs, Anthropic, etc.) API specifications for local AI inferencing. It allows users to run LLMs, generate images, audio, and more locally or on-premises with consumer-grade hardware, supporting multiple model families and not requiring a GPU. LocalAI offers features such as text generation with GPTs, text-to-audio, audio-to-text transcription, image generation with stable diffusion, OpenAI functions, embeddings generation for vector databases, constrained grammars, downloading models directly from Huggingface, and a Vision API. It provides a detailed step-by-step introduction in its Getting Started guide and supports community integrations such as custom containers, WebUIs, model galleries, and various bots for Discord, Slack, and Telegram. LocalAI also offers resources like an LLM fine-tuning guide, instructions for local building and Kubernetes installation, projects integrating LocalAI, and a how-tos section curated by the community. It encourages users to cite the repository when utilizing it in downstream projects and acknowledges the contributions of various software from the community.
new-api
New API is a next-generation large model gateway and AI asset management system that provides a wide range of features, including a new UI interface, multi-language support, online recharge function, key query for usage quota, compatibility with the original One API database, model charging by usage count, channel weighted randomization, data dashboard, token grouping and model restrictions, support for various authorization login methods, support for Rerank models, OpenAI Realtime API, Claude Messages format, reasoning effort setting, content reasoning, user-specific model rate limiting, request format conversion, cache billing support, and various model support such as gpts, Midjourney-Proxy, Suno API, custom channels, Rerank models, Claude Messages format, Dify, and more.
retinify
Retinify is an advanced AI-powered stereo vision library designed for robotics, enabling real-time, high-precision 3D perception by leveraging GPU and NPU acceleration. It is open source under Apache-2.0 license, offers high precision 3D mapping and object recognition, runs computations on GPU for fast performance, accepts stereo images from any rectified camera setup, is cost-efficient using minimal hardware, and has minimal dependencies on CUDA Toolkit, cuDNN, and TensorRT. The tool provides a pipeline for stereo matching and supports various image data types independently of OpenCV.

ScaleLLM
ScaleLLM is a cutting-edge inference system engineered for large language models (LLMs), meticulously designed to meet the demands of production environments. It extends its support to a wide range of popular open-source models, including Llama3, Gemma, Bloom, GPT-NeoX, and more. ScaleLLM is currently undergoing active development. We are fully committed to consistently enhancing its efficiency while also incorporating additional features. Feel free to explore our **_Roadmap_** for more details. ## Key Features * High Efficiency: Excels in high-performance LLM inference, leveraging state-of-the-art techniques and technologies like Flash Attention, Paged Attention, Continuous batching, and more. * Tensor Parallelism: Utilizes tensor parallelism for efficient model execution. * OpenAI-compatible API: An efficient golang rest api server that compatible with OpenAI. * Huggingface models: Seamless integration with most popular HF models, supporting safetensors. * Customizable: Offers flexibility for customization to meet your specific needs, and provides an easy way to add new models. * Production Ready: Engineered with production environments in mind, ScaleLLM is equipped with robust system monitoring and management features to ensure a seamless deployment experience.
cortex.cpp
Cortex is a C++ AI engine with a Docker-like command-line interface and client libraries. It supports running AI models using ONNX, TensorRT-LLM, and llama.cpp engines. Cortex can function as a standalone server or be integrated as a library. The tool provides support for various engines and models, allowing users to easily deploy and interact with AI models. It offers a range of CLI commands for managing models, embeddings, and engines, as well as a REST API for interacting with models. Cortex is designed to simplify the deployment and usage of AI models in C++ applications.
libllm
libLLM is an open-source project designed for efficient inference of large language models (LLM) on personal computers and mobile devices. It is optimized to run smoothly on common devices, written in C++14 without external dependencies, and supports CUDA for accelerated inference. Users can build the tool for CPU only or with CUDA support, and run libLLM from the command line. Additionally, there are API examples available for Python and the tool can export Huggingface models.
Liger-Kernel
Liger Kernel is a collection of Triton kernels designed for LLM training, increasing training throughput by 20% and reducing memory usage by 60%. It includes Hugging Face Compatible modules like RMSNorm, RoPE, SwiGLU, CrossEntropy, and FusedLinearCrossEntropy. The tool works with Flash Attention, PyTorch FSDP, and Microsoft DeepSpeed, aiming to enhance model efficiency and performance for researchers, ML practitioners, and curious novices.
Edit-Banana
Edit Banana is a universal content re-editor that allows users to transform fixed content into fully manipulatable assets. Powered by SAM 3 and multimodal large models, it enables high-fidelity reconstruction while preserving original diagram details and logical relationships. The platform offers advanced segmentation, fixed multi-round VLM scanning, high-quality OCR, user system with credits, multi-user concurrency, and a web interface. Users can upload images or PDFs to get editable DrawIO (XML) or PPTX files in seconds. The project structure includes components for segmentation, text extraction, frontend, models, and scripts, with detailed installation and setup instructions provided. The tool is open-source under the Apache License 2.0, allowing commercial use and secondary development.
star-vector
StarVector is a multimodal vision-language model for Scalable Vector Graphics (SVG) generation. It can be used to perform image2SVG and text2SVG generation. StarVector works directly in the SVG code space, leveraging visual understanding to apply accurate SVG primitives. It achieves state-of-the-art performance in producing compact and semantically rich SVGs. The tool provides Hugging Face model checkpoints for image2SVG vectorization, with models like StarVector-8B and StarVector-1B. It also offers datasets like SVG-Stack, SVG-Fonts, SVG-Icons, SVG-Emoji, and SVG-Diagrams for evaluation. StarVector can be trained using Deepspeed or FSDP for tasks like Image2SVG and Text2SVG generation. The tool provides a demo with options for HuggingFace generation or VLLM backend for faster generation speed.
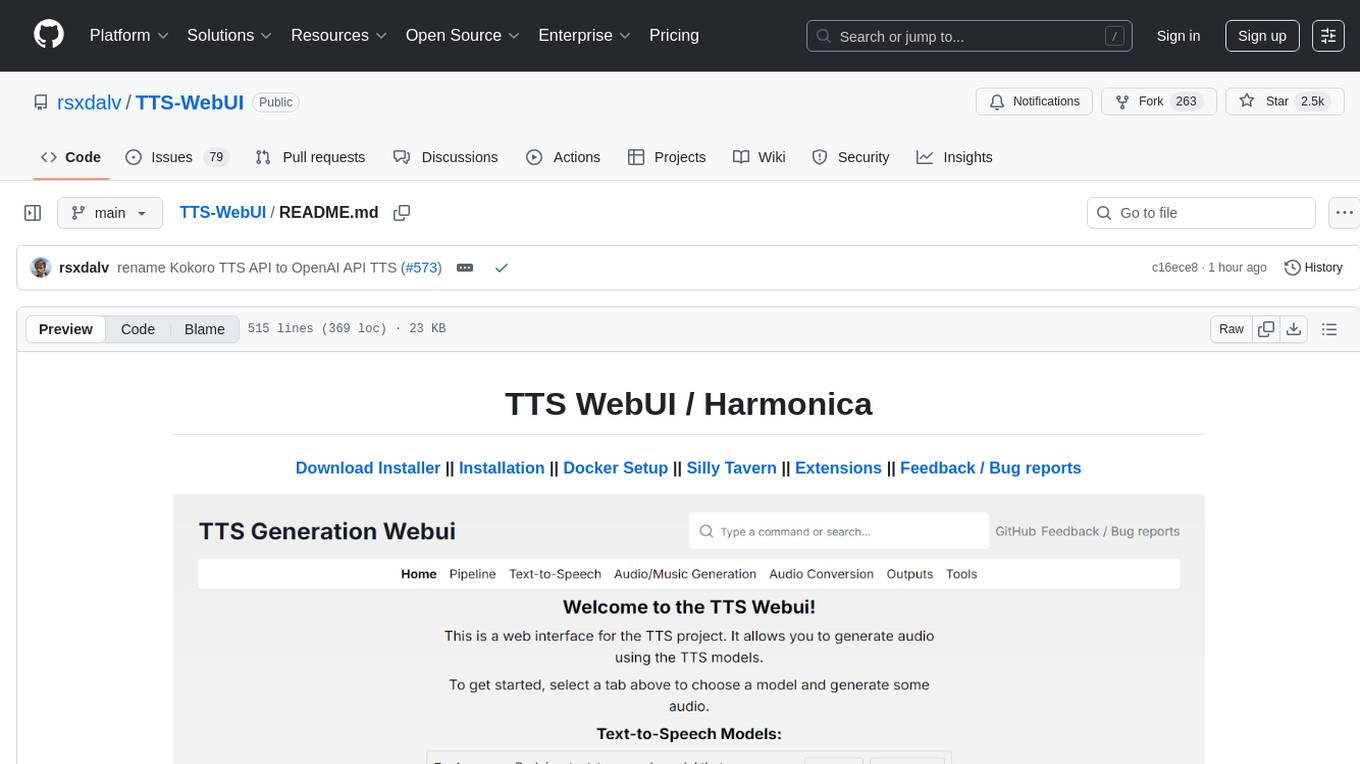
TTS-WebUI
TTS WebUI is a comprehensive tool for text-to-speech synthesis, audio/music generation, and audio conversion. It offers a user-friendly interface for various AI projects related to voice and audio processing. The tool provides a range of models and extensions for different tasks, along with integrations like Silly Tavern and OpenWebUI. With support for Docker setup and compatibility with Linux and Windows, TTS WebUI aims to facilitate creative and responsible use of AI technologies in a user-friendly manner.

infinity
Infinity is a high-throughput, low-latency REST API for serving vector embeddings, supporting all sentence-transformer models and frameworks. It is developed under the MIT License and powers inference behind Gradient.ai. The API allows users to deploy models from SentenceTransformers, offers fast inference backends utilizing various accelerators, dynamic batching for efficient processing, correct and tested implementation, and easy-to-use API built on FastAPI with Swagger documentation. Users can embed text, rerank documents, and perform text classification tasks using the tool. Infinity supports various models from Huggingface and provides flexibility in deployment via CLI, Docker, Python API, and cloud services like dstack. The tool is suitable for tasks like embedding, reranking, and text classification.

agentscope
AgentScope is a multi-agent platform designed to empower developers to build multi-agent applications with large-scale models. It features three high-level capabilities: Easy-to-Use, High Robustness, and Actor-Based Distribution. AgentScope provides a list of `ModelWrapper` to support both local model services and third-party model APIs, including OpenAI API, DashScope API, Gemini API, and ollama. It also enables developers to rapidly deploy local model services using libraries such as ollama (CPU inference), Flask + Transformers, Flask + ModelScope, FastChat, and vllm. AgentScope supports various services, including Web Search, Data Query, Retrieval, Code Execution, File Operation, and Text Processing. Example applications include Conversation, Game, and Distribution. AgentScope is released under Apache License 2.0 and welcomes contributions.
For similar tasks
rwkv-qualcomm
This repository provides support for inference RWKV models on Qualcomm HTP (Hexagon Tensor Processor) using QNN SDK. It supports RWKV v5, v6, and experimentally v7 models, inference using Qualcomm CPU, GPU, or HTP as the backend, whole-model float16 inference, activation INT16 and weights INT8 quantized inference, and activation INT16 and weights INT4/INT8 mixed quantized inference. Users can convert model weights to QNN model library files, generate HTP context cache, and run inference on Qualcomm Snapdragon SM8650 with HTP v75. The project requires QNN SDK, AIMET toolkit, and specific hardware for verification.
For similar jobs

Qwen-TensorRT-LLM
Qwen-TensorRT-LLM is a project developed for the NVIDIA TensorRT Hackathon 2023, focusing on accelerating inference for the Qwen-7B-Chat model using TRT-LLM. The project offers various functionalities such as FP16/BF16 support, INT8 and INT4 quantization options, Tensor Parallel for multi-GPU parallelism, web demo setup with gradio, Triton API deployment for maximum throughput/concurrency, fastapi integration for openai requests, CLI interaction, and langchain support. It supports models like qwen2, qwen, and qwen-vl for both base and chat models. The project also provides tutorials on Bilibili and blogs for adapting Qwen models in NVIDIA TensorRT-LLM, along with hardware requirements and quick start guides for different model types and quantization methods.

dl_model_infer
This project is a c++ version of the AI reasoning library that supports the reasoning of tensorrt models. It provides accelerated deployment cases of deep learning CV popular models and supports dynamic-batch image processing, inference, decode, and NMS. The project has been updated with various models and provides tutorials for model exports. It also includes a producer-consumer inference model for specific tasks. The project directory includes implementations for model inference applications, backend reasoning classes, post-processing, pre-processing, and target detection and tracking. Speed tests have been conducted on various models, and onnx downloads are available for different models.

joliGEN
JoliGEN is an integrated framework for training custom generative AI image-to-image models. It implements GAN, Diffusion, and Consistency models for various image translation tasks, including domain and style adaptation with conservation of semantics. The tool is designed for real-world applications such as Controlled Image Generation, Augmented Reality, Dataset Smart Augmentation, and Synthetic to Real transforms. JoliGEN allows for fast and stable training with a REST API server for simplified deployment. It offers a wide range of options and parameters with detailed documentation available for models, dataset formats, and data augmentation.

ai-edge-torch
AI Edge Torch is a Python library that supports converting PyTorch models into a .tflite format for on-device applications on Android, iOS, and IoT devices. It offers broad CPU coverage with initial GPU and NPU support, closely integrating with PyTorch and providing good coverage of Core ATen operators. The library includes a PyTorch converter for model conversion and a Generative API for authoring mobile-optimized PyTorch Transformer models, enabling easy deployment of Large Language Models (LLMs) on mobile devices.

awesome-RK3588
RK3588 is a flagship 8K SoC chip by Rockchip, integrating Cortex-A76 and Cortex-A55 cores with NEON coprocessor for 8K video codec. This repository curates resources for developing with RK3588, including official resources, RKNN models, projects, development boards, documentation, tools, and sample code.

cl-waffe2
cl-waffe2 is an experimental deep learning framework in Common Lisp, providing fast, systematic, and customizable matrix operations, reverse mode tape-based Automatic Differentiation, and neural network model building and training features accelerated by a JIT Compiler. It offers abstraction layers, extensibility, inlining, graph-level optimization, visualization, debugging, systematic nodes, and symbolic differentiation. Users can easily write extensions and optimize their networks without overheads. The framework is designed to eliminate barriers between users and developers, allowing for easy customization and extension.

TensorRT-Model-Optimizer
The NVIDIA TensorRT Model Optimizer is a library designed to quantize and compress deep learning models for optimized inference on GPUs. It offers state-of-the-art model optimization techniques including quantization and sparsity to reduce inference costs for generative AI models. Users can easily stack different optimization techniques to produce quantized checkpoints from torch or ONNX models. The quantized checkpoints are ready for deployment in inference frameworks like TensorRT-LLM or TensorRT, with planned integrations for NVIDIA NeMo and Megatron-LM. The tool also supports 8-bit quantization with Stable Diffusion for enterprise users on NVIDIA NIM. Model Optimizer is available for free on NVIDIA PyPI, and this repository serves as a platform for sharing examples, GPU-optimized recipes, and collecting community feedback.

depthai
This repository contains a demo application for DepthAI, a tool that can load different networks, create pipelines, record video, and more. It provides documentation for installation and usage, including running programs through Docker. Users can explore DepthAI features via command line arguments or a clickable QT interface. Supported models include various AI models for tasks like face detection, human pose estimation, and object detection. The tool collects anonymous usage statistics by default, which can be disabled. Users can report issues to the development team for support and troubleshooting.