Best AI tools for< Quantization Specialist >
Infographic
1 - AI tool Sites

Private LLM
Private LLM is a secure, local, and private AI chatbot designed for iOS and macOS devices. It operates offline, ensuring that user data remains on the device, providing a safe and private experience. The application offers a range of features for text generation and language assistance, utilizing state-of-the-art quantization techniques to deliver high-quality on-device AI experiences without compromising privacy. Users can access a variety of open-source LLM models, integrate AI into Siri and Shortcuts, and benefit from AI language services across macOS apps. Private LLM stands out for its superior model performance and commitment to user privacy, making it a smart and secure tool for creative and productive tasks.
3 - Open Source Tools
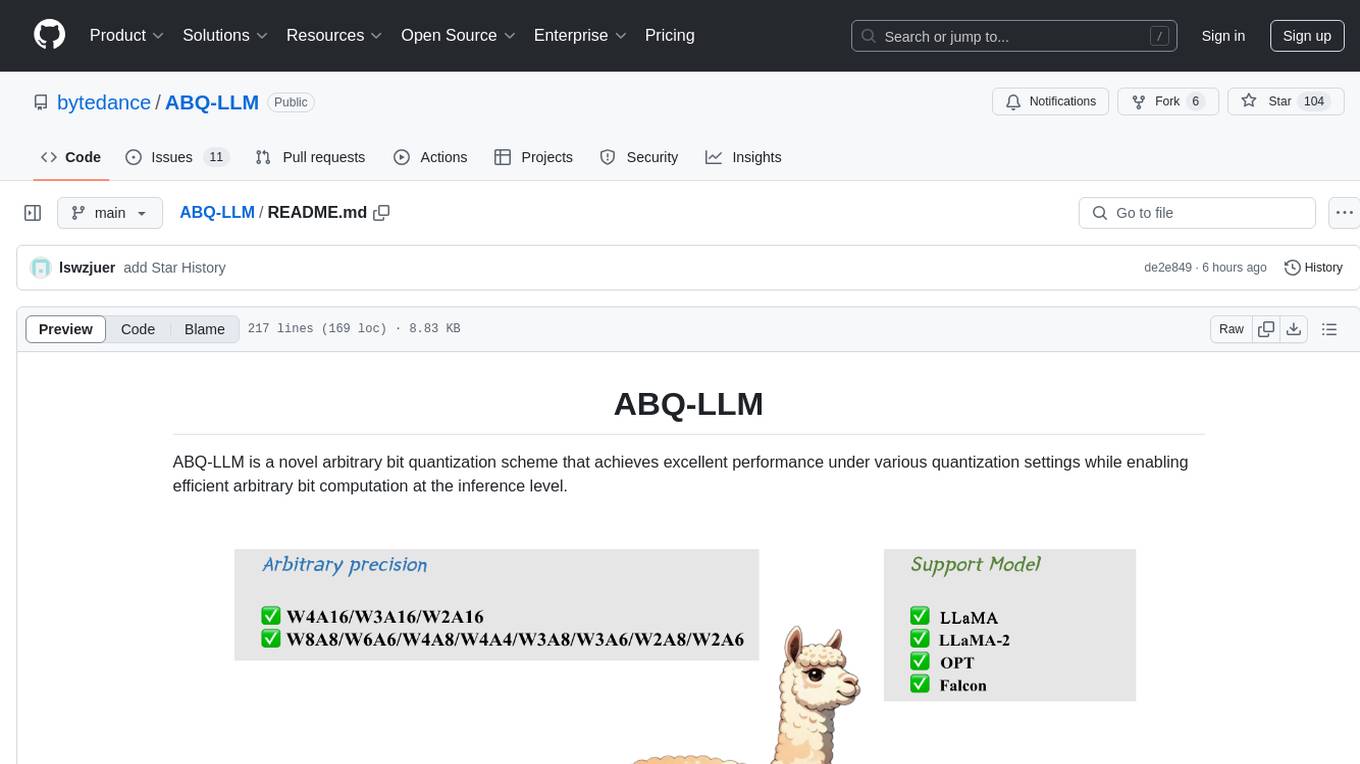
ABQ-LLM
ABQ-LLM is a novel arbitrary bit quantization scheme that achieves excellent performance under various quantization settings while enabling efficient arbitrary bit computation at the inference level. The algorithm supports precise weight-only quantization and weight-activation quantization. It provides pre-trained model weights and a set of out-of-the-box quantization operators for arbitrary bit model inference in modern architectures.
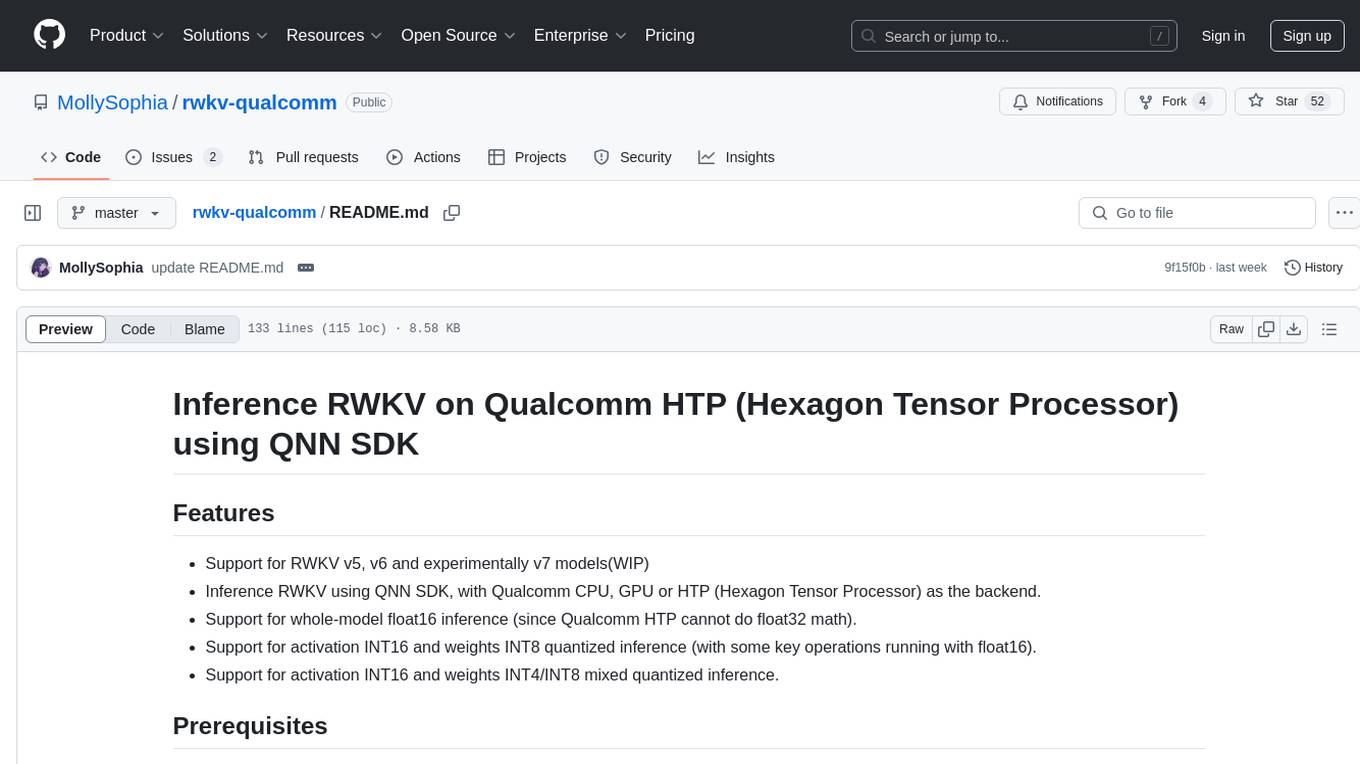
rwkv-qualcomm
This repository provides support for inference RWKV models on Qualcomm HTP (Hexagon Tensor Processor) using QNN SDK. It supports RWKV v5, v6, and experimentally v7 models, inference using Qualcomm CPU, GPU, or HTP as the backend, whole-model float16 inference, activation INT16 and weights INT8 quantized inference, and activation INT16 and weights INT4/INT8 mixed quantized inference. Users can convert model weights to QNN model library files, generate HTP context cache, and run inference on Qualcomm Snapdragon SM8650 with HTP v75. The project requires QNN SDK, AIMET toolkit, and specific hardware for verification.
ai-edge-quantizer
AI Edge Quantizer is a tool designed for advanced developers to quantize converted LiteRT models. It aims to optimize performance on resource-demanding models by providing quantization recipes for edge device deployment. The tool supports dynamic quantization, weight-only quantization, and static quantization methods, allowing users to customize the quantization process for different hardware deployments. Users can specify quantization recipes to apply to source models, resulting in quantized LiteRT models ready for deployment. The tool also includes advanced features such as selective quantization and mixed precision schemes for fine-tuning quantization recipes.