Best AI tools for< Text Classification >
Infographic
20 - AI tool Sites
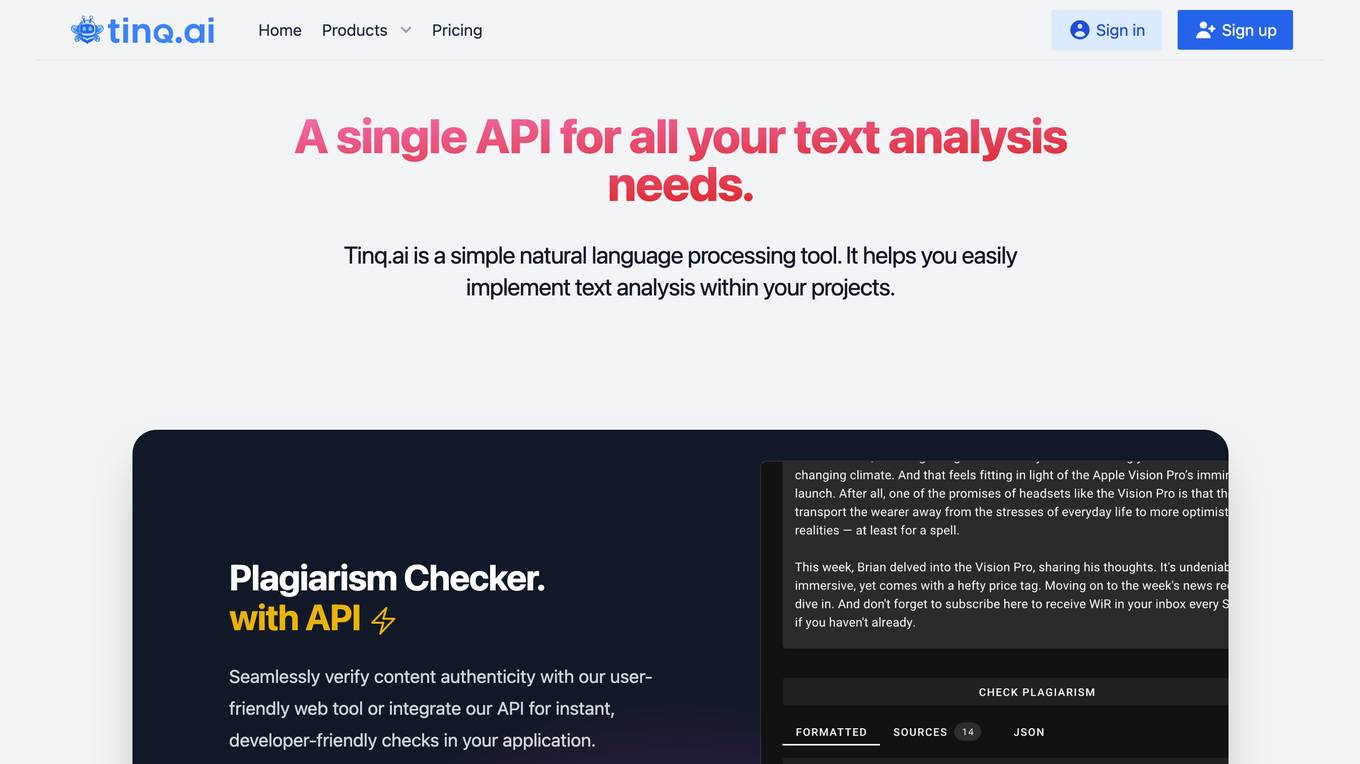
Tinq.ai
Tinq.ai is a natural language processing (NLP) tool that provides a range of text analysis capabilities through its API. It offers tools for tasks such as plagiarism checking, text summarization, sentiment analysis, named entity recognition, and article extraction. Tinq.ai's API can be integrated into applications to add NLP functionality, such as content moderation, sentiment analysis, and text rewriting.
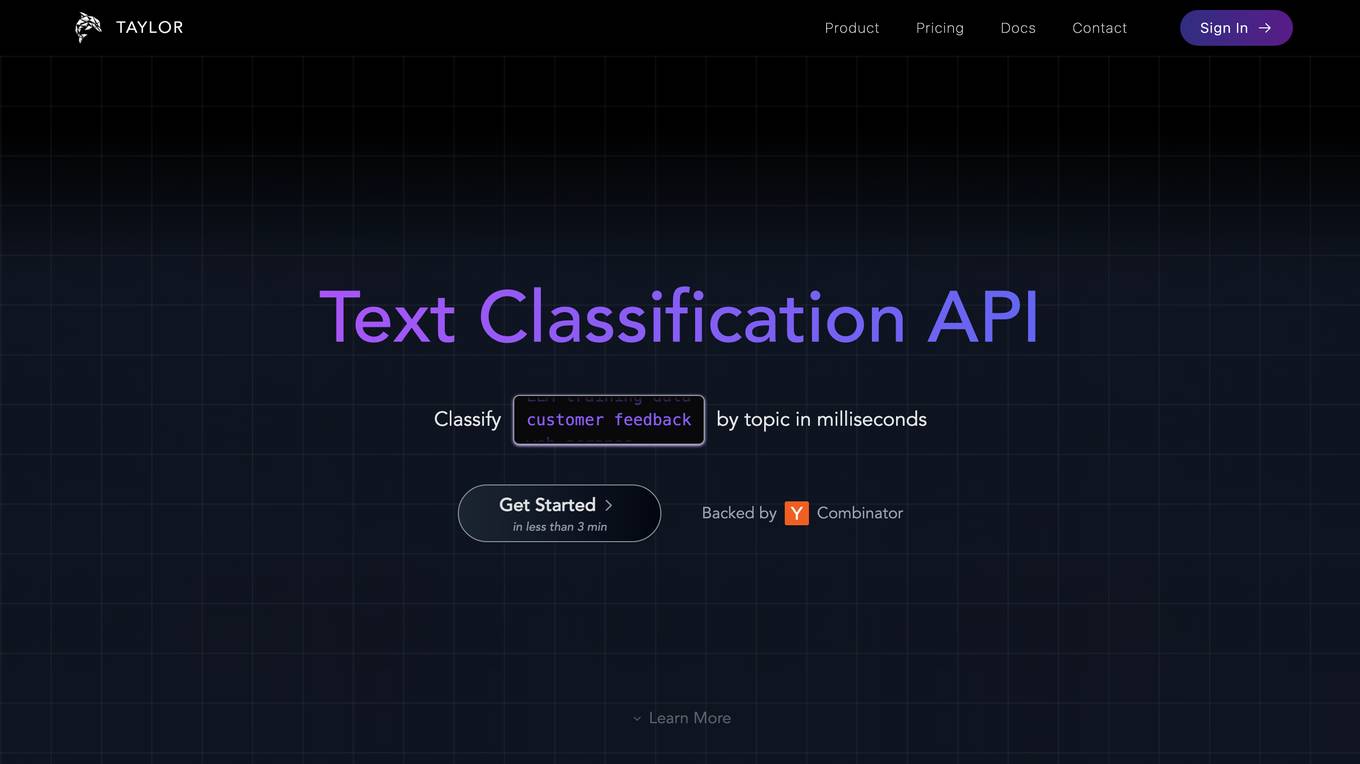
Taylor
Taylor is a deterministic AI tool that empowers Business & Engineering teams to enhance data at scale through bulk classification. It offers a Control Panel for Text Enrichment, enabling users to structure freeform text, enrich metadata, and customize enrichments according to their needs. Taylor's high impact, easy-to-use platform allows for total control over classification and extraction models, driving business impact from day one. With powerful integrations and the ability to integrate with various tools, Taylor simplifies the process of wrangling unstructured text data.
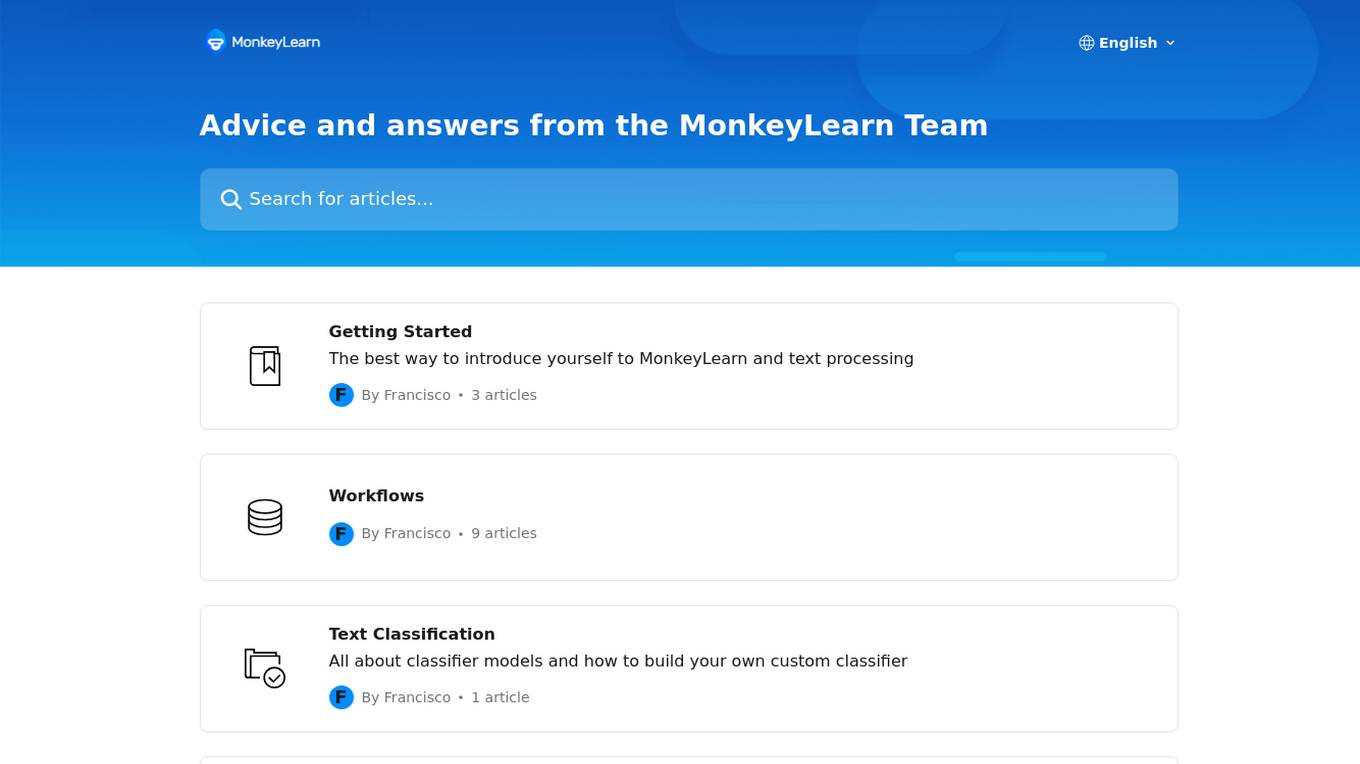
MonkeyLearn
MonkeyLearn is an AI tool that specializes in text processing. It offers a range of features for text classification, extraction, data analysis, and more. Users can build custom models, process data manually or automatically, and integrate the tool into their workflows. MonkeyLearn provides advanced settings for custom models and ensures user data security and privacy compliance.
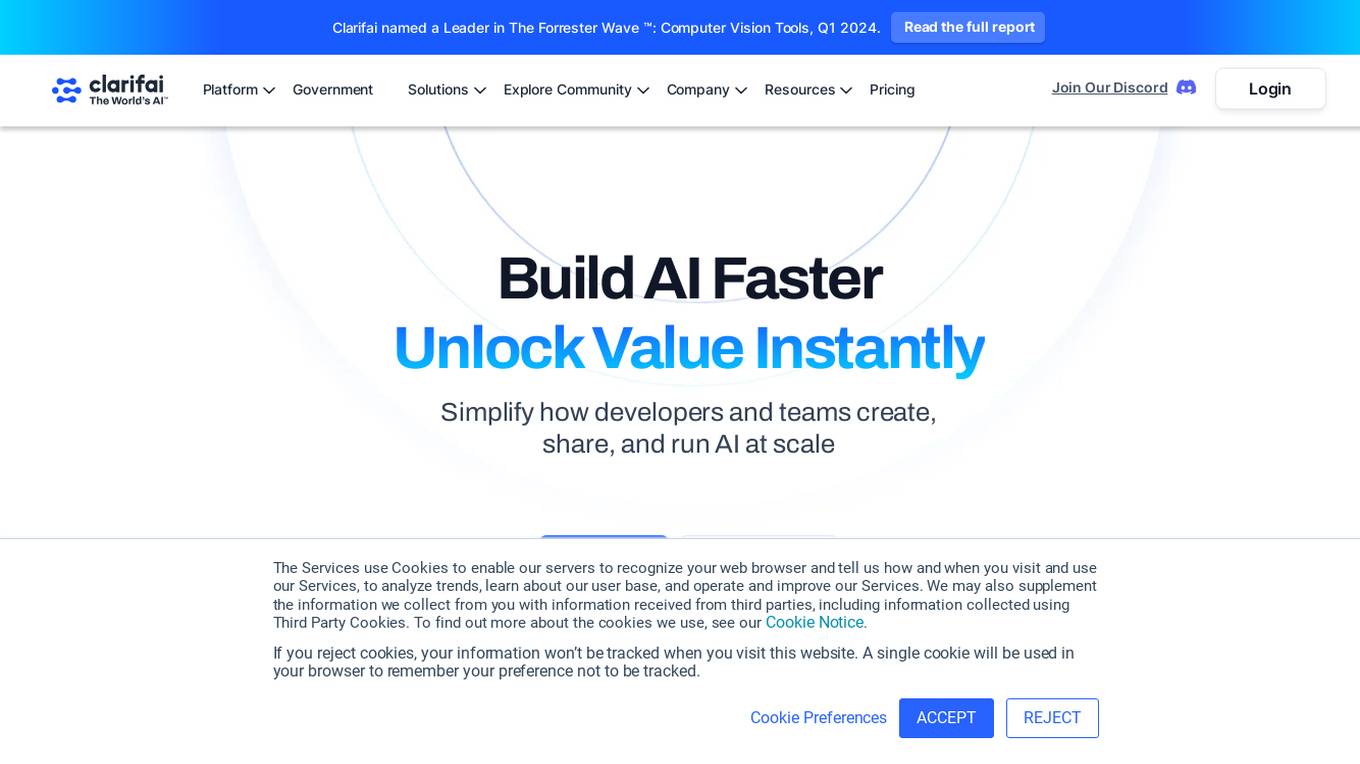
Clarifai
Clarifai is a full-stack AI developer platform that provides a range of tools and services for building and deploying AI applications. The platform includes a variety of computer vision, natural language processing, and generative AI models, as well as tools for data preparation, model training, and model deployment. Clarifai is used by a variety of businesses and organizations, including Fortune 500 companies, startups, and government agencies.

FranzAI LLM Playground
FranzAI LLM Playground is an AI-powered tool that helps you extract, classify, and analyze unstructured text data. It leverages transformer models to provide accurate and meaningful results, enabling you to build data applications faster and more efficiently. With FranzAI, you can accelerate product and content classification, enhance data interpretation, and advance data extraction processes, unlocking key insights from your textual data.

Nesa Playground
Nesa is a global blockchain network that brings AI on-chain, allowing applications and protocols to seamlessly integrate with AI. It offers secure execution for critical inference, a private AI network, and a global AI model repository. Nesa supports various AI models for tasks like text classification, content summarization, image generation, language translation, and more. The platform is backed by a team with extensive experience in AI and deep learning, with numerous awards and recognitions in the field.
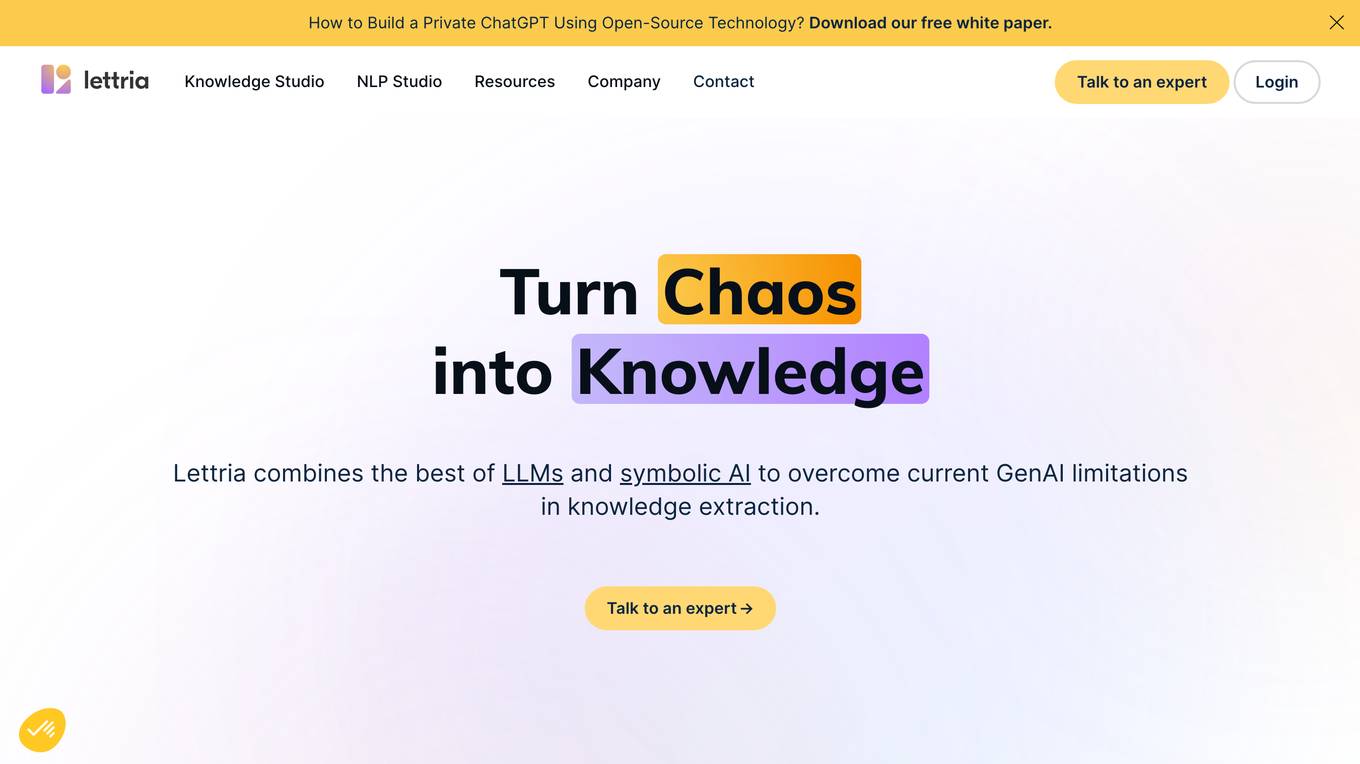
Lettria
Lettria is a no-code AI platform for text that helps users turn unstructured text data into structured knowledge. It combines the best of Large Language Models (LLMs) and symbolic AI to overcome current limitations in knowledge extraction. Lettria offers a suite of APIs for text cleaning, text mining, text classification, and prompt engineering. It also provides a Knowledge Studio for building knowledge graphs and private GPT models. Lettria is trusted by large organizations such as AP-HP and Leroy Merlin to improve their data analysis and decision-making processes.
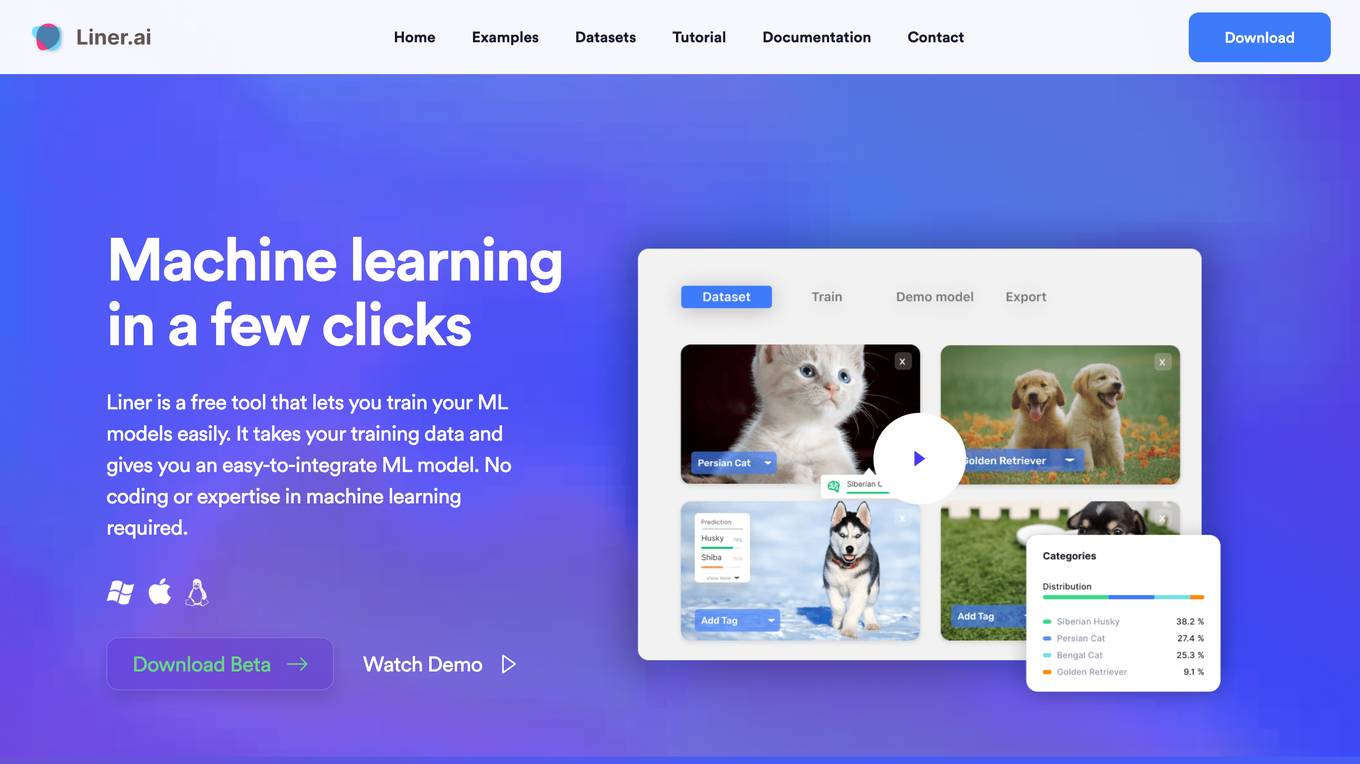
Liner.ai
Liner is a free and easy-to-use tool that allows users to train machine learning models without writing any code. It provides a user-friendly interface that guides users through the process of importing data, selecting a model, and training the model. Liner also offers a variety of pre-trained models that can be used for common tasks such as image classification, text classification, and object detection. With Liner, users can quickly and easily create and deploy machine learning applications without the need for specialized knowledge or expertise.
PyAI
PyAI is an advanced AI tool designed for developers and data scientists to streamline their workflow and enhance productivity. It offers a wide range of AI capabilities, including machine learning algorithms, natural language processing, computer vision, and more. With PyAI, users can easily build, train, and deploy AI models for various applications, such as predictive analytics, image recognition, and text classification. The tool provides a user-friendly interface and comprehensive documentation to support users at every stage of their AI projects.
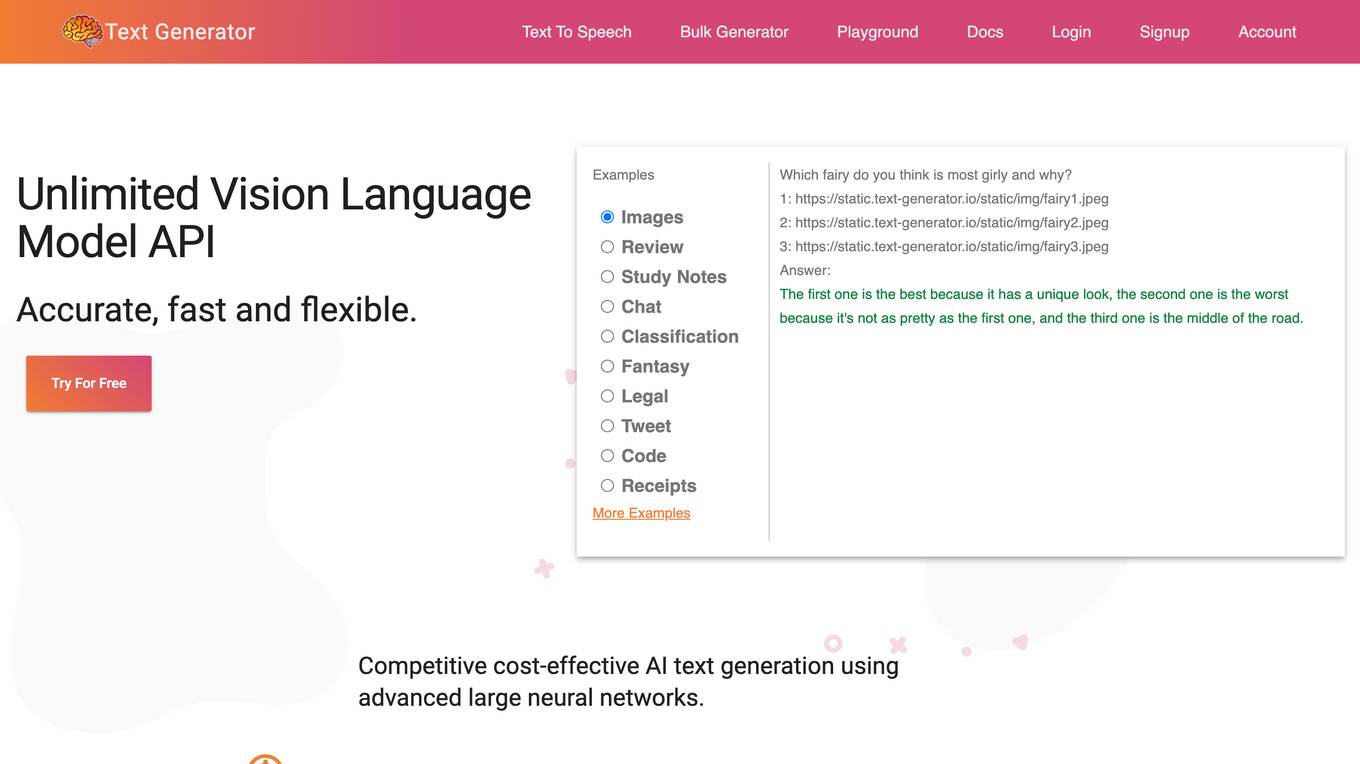
Text Generator
Text Generator is an AI-powered text generation tool that provides users with accurate, fast, and flexible text generation capabilities. With its advanced large neural networks, Text Generator offers a cost-effective solution for various text-related tasks. The tool's intuitive 'prompt engineering' feature allows users to guide text creation by providing keywords and natural questions, making it adaptable for tasks such as classification and sentiment analysis. Text Generator ensures industry-leading security by never storing personal information on its servers. The tool's continuous training ensures that its AI remains up-to-date with the latest events. Additionally, Text Generator offers a range of features including speech-to-text API, text-to-speech API, and code generation, supporting multiple spoken languages and programming languages. With its one-line migration from OpenAI's text generation hub and a shared embedding for multiple spoken languages, images, and code, Text Generator empowers users with powerful search, fingerprinting, tracking, and classification capabilities.
Lexalytics
Lexalytics is a leading provider of text analytics and natural language processing (NLP) solutions. Our platform and services help businesses transform complex text data into valuable insights and actionable intelligence. With Lexalytics, you can: * **Analyze customer feedback** to understand what your customers are saying about your products, services, and brand. * **Identify trends and patterns** in text data to make better decisions about your business. * **Automate tasks** such as document classification, entity extraction, and sentiment analysis. * **Develop custom NLP applications** to meet your specific needs.

Totoy
Totoy is a Document AI tool that redefines the way documents are processed. Its API allows users to explain, classify, and create knowledge bases from documents without the need for training. The tool supports 19 languages and works with plain text, images, and PDFs. Totoy is ideal for automating workflows, complying with accessibility laws, and creating custom AI assistants for employees or customers.
Datumbox
Datumbox is a machine learning platform that offers a powerful open-source Machine Learning Framework written in Java. It provides a large collection of algorithms, models, statistical tests, and tools to power up intelligent applications. The platform enables developers to build smart software and services quickly using its REST Machine Learning API. Datumbox API offers off-the-shelf Classifiers and Natural Language Processing services for applications like Sentiment Analysis, Topic Classification, Language Detection, and more. It simplifies the process of designing and training Machine Learning models, making it easy for developers to create innovative applications.
Noodle4
Noodle4 is an AI-powered platform designed for content review of User-Generated Content (UGC) and Influencer content. It offers advanced AI models that streamline manual content review processes with speed and accuracy. Noodle4 helps users to ensure that their content aligns with brand guidelines, briefs, ad compliance, and product classification. The platform allows for cross-referencing of audio, video, text, and images, making content review efficient and precise. Noodle4 also facilitates collaboration between clients and creators, providing a seamless review experience.
GooseAI
GooseAI is a fully managed NLP-as-a-Service delivered via API, at 30% the cost of other providers. It offers a variety of NLP models, including GPT-Neo 1.3B, Fairseq 1.3B, GPT-J 6B, Fairseq 6B, Fairseq 13B, and GPT-NeoX 20B. GooseAI is easy to use, with feature parity with industry standard APIs. It is also highly performant, with the industry's fastest generation speeds.
Airtrain
Airtrain is a no-code compute platform for Large Language Models (LLMs). It provides a user-friendly interface for fine-tuning, evaluating, and deploying custom AI models. Airtrain also offers a marketplace of pre-trained models that can be used for a variety of tasks, such as text generation, translation, and question answering.

NLTK
NLTK (Natural Language Toolkit) is a leading platform for building Python programs to work with human language data. It provides easy-to-use interfaces to over 50 corpora and lexical resources such as WordNet, along with a suite of text processing libraries for classification, tokenization, stemming, tagging, parsing, and semantic reasoning, wrappers for industrial-strength NLP libraries, and an active discussion forum. Thanks to a hands-on guide introducing programming fundamentals alongside topics in computational linguistics, plus comprehensive API documentation, NLTK is suitable for linguists, engineers, students, educators, researchers, and industry users alike.
Predibase
Predibase is a platform for fine-tuning and serving Large Language Models (LLMs). It provides a cost-effective and efficient way to train and deploy LLMs for a variety of tasks, including classification, information extraction, customer sentiment analysis, customer support, code generation, and named entity recognition. Predibase is built on proven open-source technology, including LoRAX, Ludwig, and Horovod.
Explosion
Explosion is a software company specializing in developer tools and tailored solutions for AI, Machine Learning, and Natural Language Processing (NLP). They are the makers of spaCy, one of the leading open-source libraries for advanced NLP. The company offers consulting services and builds developer tools for various AI-related tasks, such as coreference resolution, dependency parsing, image classification, named entity recognition, and more.
Floom.ai
Floom.ai is an AI Marketplace for apps that allows users to easily add AI functions to their applications in just 5 minutes, without requiring any prior AI knowledge. The platform offers a variety of AI functions developed by the community, such as text translation, classification, summarization, keyword extraction, social media post generation, code explanation, code conversion, code improvement, physical address extraction, and SQL query generation. Floom.ai aims to empower developers and businesses to enhance their applications with AI capabilities through a user-friendly and efficient marketplace.
3 - Open Source Tools

intel-extension-for-transformers
Intel® Extension for Transformers is an innovative toolkit designed to accelerate GenAI/LLM everywhere with the optimal performance of Transformer-based models on various Intel platforms, including Intel Gaudi2, Intel CPU, and Intel GPU. The toolkit provides the below key features and examples: * Seamless user experience of model compressions on Transformer-based models by extending [Hugging Face transformers](https://github.com/huggingface/transformers) APIs and leveraging [Intel® Neural Compressor](https://github.com/intel/neural-compressor) * Advanced software optimizations and unique compression-aware runtime (released with NeurIPS 2022's paper [Fast Distilbert on CPUs](https://arxiv.org/abs/2211.07715) and [QuaLA-MiniLM: a Quantized Length Adaptive MiniLM](https://arxiv.org/abs/2210.17114), and NeurIPS 2021's paper [Prune Once for All: Sparse Pre-Trained Language Models](https://arxiv.org/abs/2111.05754)) * Optimized Transformer-based model packages such as [Stable Diffusion](examples/huggingface/pytorch/text-to-image/deployment/stable_diffusion), [GPT-J-6B](examples/huggingface/pytorch/text-generation/deployment), [GPT-NEOX](examples/huggingface/pytorch/language-modeling/quantization#2-validated-model-list), [BLOOM-176B](examples/huggingface/pytorch/language-modeling/inference#BLOOM-176B), [T5](examples/huggingface/pytorch/summarization/quantization#2-validated-model-list), [Flan-T5](examples/huggingface/pytorch/summarization/quantization#2-validated-model-list), and end-to-end workflows such as [SetFit-based text classification](docs/tutorials/pytorch/text-classification/SetFit_model_compression_AGNews.ipynb) and [document level sentiment analysis (DLSA)](workflows/dlsa) * [NeuralChat](intel_extension_for_transformers/neural_chat), a customizable chatbot framework to create your own chatbot within minutes by leveraging a rich set of [plugins](https://github.com/intel/intel-extension-for-transformers/blob/main/intel_extension_for_transformers/neural_chat/docs/advanced_features.md) such as [Knowledge Retrieval](./intel_extension_for_transformers/neural_chat/pipeline/plugins/retrieval/README.md), [Speech Interaction](./intel_extension_for_transformers/neural_chat/pipeline/plugins/audio/README.md), [Query Caching](./intel_extension_for_transformers/neural_chat/pipeline/plugins/caching/README.md), and [Security Guardrail](./intel_extension_for_transformers/neural_chat/pipeline/plugins/security/README.md). This framework supports Intel Gaudi2/CPU/GPU. * [Inference](https://github.com/intel/neural-speed/tree/main) of Large Language Model (LLM) in pure C/C++ with weight-only quantization kernels for Intel CPU and Intel GPU (TBD), supporting [GPT-NEOX](https://github.com/intel/neural-speed/tree/main/neural_speed/models/gptneox), [LLAMA](https://github.com/intel/neural-speed/tree/main/neural_speed/models/llama), [MPT](https://github.com/intel/neural-speed/tree/main/neural_speed/models/mpt), [FALCON](https://github.com/intel/neural-speed/tree/main/neural_speed/models/falcon), [BLOOM-7B](https://github.com/intel/neural-speed/tree/main/neural_speed/models/bloom), [OPT](https://github.com/intel/neural-speed/tree/main/neural_speed/models/opt), [ChatGLM2-6B](https://github.com/intel/neural-speed/tree/main/neural_speed/models/chatglm), [GPT-J-6B](https://github.com/intel/neural-speed/tree/main/neural_speed/models/gptj), and [Dolly-v2-3B](https://github.com/intel/neural-speed/tree/main/neural_speed/models/gptneox). Support AMX, VNNI, AVX512F and AVX2 instruction set. We've boosted the performance of Intel CPUs, with a particular focus on the 4th generation Intel Xeon Scalable processor, codenamed [Sapphire Rapids](https://www.intel.com/content/www/us/en/products/docs/processors/xeon-accelerated/4th-gen-xeon-scalable-processors.html).

bert4torch
**bert4torch** is a high-level framework for training and deploying transformer models in PyTorch. It provides a simple and efficient API for building, training, and evaluating transformer models, and supports a wide range of pre-trained models, including BERT, RoBERTa, ALBERT, XLNet, and GPT-2. bert4torch also includes a number of useful features, such as data loading, tokenization, and model evaluation. It is a powerful and versatile tool for natural language processing tasks.

FlagEmbedding
FlagEmbedding focuses on retrieval-augmented LLMs, consisting of the following projects currently: * **Long-Context LLM** : Activation Beacon * **Fine-tuning of LM** : LM-Cocktail * **Embedding Model** : Visualized-BGE, BGE-M3, LLM Embedder, BGE Embedding * **Reranker Model** : llm rerankers, BGE Reranker * **Benchmark** : C-MTEB
20 - OpenAI Gpts
BlogImage Wizard
I clarify and create positive blog images with a friendly tone, ensuring any text is in English.
Text Tune Up GPT
I edit articles, improving clarity and respectfulness, maintaining your style.
Text to DB Schema
Convert application descriptions to consumable DB schemas or create-table SQL statements
Zombie Apocalypse | Text-based survival game
I will take you for a ride in a custom text-based zombie game with survival, character development, and challenges.
Text My Pet
Text your favorite pet, after answering 10 questions about their everyday lives!
Chirico's Campaign: AI Text Adventure Simulator
Optional: Insert your character sheet and physical description. Or, use the suggested sheet below. // Note: You may have to remind this simulator to generate visuals by inserting "Please include a visual representation" at the end of your command/prompt."
Synthetic Detectives, a text adventure game
AI powered sleuths solve crimes with synthetic precision. Let me entertain you with this interactive true crime mystery game, lovingly illustrated in the style of synthetic, AI-powered humanoid robots.
Revelations: Detectives, a text adventure game
Justice hangs in the balance between good and evil. Let me entertain you with this interactive true crime mystery game, lovingly illustrated in the style of the angelic and demonic hosts of Renaissance paintings.
Cute Little Time Travellers, a text adventure game
Protect your cute little timeline. Let me entertain you with this interactive repair-the-timeline game, lovingly illustrated in the style of ultra-cute little 3D kawaii dioramas.
Murders After Dark, a text adventure game
Solve a murder mystery in gothic leather. Let me entertain you with this interactive murder mystery game, lovingly illustrated in the style of evocative leather fashion photo shoots.
📰 Simplify Text Hero (5.0⭐)
Transforms complex texts into simple, understandable language.