
RPG-DiffusionMaster
[ICML 2024] Mastering Text-to-Image Diffusion: Recaptioning, Planning, and Generating with Multimodal LLMs (RPG)
Stars: 1667
This repository contains the official implementation of RPG, a powerful training-free paradigm for text-to-image generation and editing. RPG utilizes proprietary or open-source MLLMs as prompt recaptioner and region planner with complementary regional diffusion. It achieves state-of-the-art results and can generate high-resolution images. The codebase supports diffusers and various diffusion backbones, including SDXL and SD v1.4/1.5. Users can reproduce results with GPT-4, Gemini-Pro, or local MLLMs like miniGPT-4. The repository provides tools for quick start, regional diffusion with GPT-4, and regional diffusion with local LLMs.
README:
Mastering Text-to-Image Diffusion: Recaptioning, Planning, and Generating with Multimodal LLMs - ICML 2024
This repository contains the official implementation of our RPG, accepted by ICML 2024.
Mastering Text-to-Image Diffusion: Recaptioning, Planning, and Generating with Multimodal LLMs
Ling Yang, Zhaochen Yu, Chenlin Meng, Minkai Xu, Stefano Ermon, Bin Cui
Peking University, Stanford University, Pika Labs
 |
| Overview of our RPG |
Abstract: RPG is a powerful training-free paradigm that can utilize proprietary MLLMs (e.g., GPT-4, Gemini-Pro) or open-source local MLLMs (e.g., miniGPT-4) as the prompt recaptioner and region planner with our complementary regional diffusion to achieve SOTA text-to-image generation and editing. Our framework is very flexible and can generalize to arbitrary MLLM architectures and diffusion backbones. RPG is also capable of generating image with super high resolutions, here is an example:
 |
| Text prompt: A beautiful landscape with a river in the middle the left of the river is in the evening and in the winter with a big iceberg and a small village while some people are skating on the river and some people are skiing, the right of the river is in the summer with a volcano in the morning and a small village while some people are playing. |
[2024.1] Our main code along with the demo release, supporting different diffusion backbones (SDXL, SD v2.0/2.1 SD v1.4/1.5), and one can reproduce our good results utilizing GPT-4 and Gemini-Pro. Our RPG is also compatible with local MLLMs, and we will continue to improve the results in the future.
[2024.4] Our codebase has been updated based on diffusers, it now supports both ckpts and diffusers of diffusion models. As for diffusion backbones, one can use RegionalDiffusionPipeline for base models like SD v2.0/2.1 SD v1.4/1.5, and use RegionalDiffusionXLPipeline for SDXL.
[2024.10] We enhance RPG by incorporating a more powerful composition-aware backbone, IterComp, significantly improving performance on compositional generation without additional computational costs. Simply update the model path using the command below to obtain the results:
pipe = RegionalDiffusionXLPipeline.from_pretrained("comin/IterComp",torch_dtype=torch.float16, use_safetensors=True)
1024*1024 Examples
 |
 |
 |
 |
| A girl with white ponytail and black dress are chatting with a blonde curly hair girl in a white dress in a cafe. | A twin-tail girl wearing a brwon cowboy hat and white shirt printed with apples, and blue denim jeans with knee boots,full body shot. | A couple, the beautiful girl on the left, silver hair, braided ponytail, happy, dynamic, energetic, peaceful, the handsome young man on the right detailed gorgeous face, grin, blonde hair, enchanting | Two beautiful Chinese girls wearing cheongsams are drinking tea in the tea room, and a Chinese Landscape Painting is hanging on the wall, the girl on the left is black ponytail in red cheongsam, the girl on the right is white ponytail in orange cheongsam |
2048*1024 Example
 |
| From left to right, a blonde ponytail Europe girl in white shirt, a brown curly hair African girl in blue shirt printed with a bird, an Asian young man with black short hair in suit are walking in the campus happily. |
1024*1024 Examples
 |
 |
 |
 |
| From left to right, two red apples and an apple printed shirt and an ipad on the wooden floor | Seven white ceramic mugs with different geometric patterns on the marble table while a bunch of rose on the left | Five watermelons arranged in X shape on a wooden table, with the one in the middle being cut, realistic style, top down view. | From left to right ,bathed in soft morning light,a cozy nook features a steaming Starbucks latte on a rustic table beside an elegant vase of blooming roses,while a plush ragdoll cat purrs contentedly nearby,its eyes half-closed in blissful serenity. |
2048*1024 Example
 |
| A green twintail girl in orange dress is sitting on the sofa while a messy desk under a big window on the left, a lively aquarium is on the top right of the sofa, realistic style |
Open Pose Example
| Open Pose | |
 |
 |
Depth Map Example
| Depth Map | |
 |
 |
Canny Edge Example
| Canny Edge | |
 |
 |
1024*1024 Examples
 |
 |
| A colossal, ancient tree with leaves made of ice towers over a mystical castle. Green trees line both sides, while cascading waterfalls and an ethereal glow adorn the scene. The backdrop features towering mountains and a vibrant, colorful sky. | On the rooftop of a skyscraper in a bustling cyberpunk city, a figure in a trench coat and neon-lit visor stands amidst a garden of bio-luminescent plants, overlooking the maze of flying cars and towering holograms. Robotic birds flit among the foliage, digital billboards flash advertisements in the distance. |
Compared with RPG
| RPG | RPG with IterComp |
 |
 |
| Futuristic and prehistoric worlds collide: Dinosaurs roam near a medieval castle, flying cars and advanced skyscrapers dominate the skyline. A river winds through lush greenery, blending ancient and modern civilizations in a surreal landscape. | |
1. Set Environment
git clone https://github.com/YangLing0818/RPG-DiffusionMaster
cd RPG-DiffusionMaster
conda create -n RPG python==3.9
conda activate RPG
pip install -r requirements.txt
git clone https://github.com/huggingface/diffusers2. Download Diffusion Models and MLLMs
To attain SOTA generative capabilities, we mainly employ SDXL, SDXL-Turbo, and Playground v2 as our base diffusion. To generate images of high fidelity across various styles, such as photorealism, cartoons, and anime, we incorporate the models from CIVITA. For images aspiring to photorealism, we advocate the use of AlbedoBase XL , and DreamShaper XL. Moreover, we generalize our paradigm to SD v1.5 and SD v2.1. All checkpoints are accessible within our Hugging Face spaces, with detailed descriptions.
We recommend the utilization of GPT-4 or Gemini-Pro for users of Multilingual Large Language Models (MLLMs), as they not only exhibit superior performance but also reduce local memory. According to our experiments, the minimum requirements of VRAM is 10GB with GPT-4, if you want to use local LLM, it would need more VRAM. For those interested in using MLLMs locally, we suggest deploying miniGPT-4 or directly engaging with substantial Local LLMs such as Llama2-13b-chat and Llama2-70b-chat.
For individuals equipped with constrained computational resources, we here provide a simple notebook demonstration that partitions the image into two equal-sized subregions. By making minor alterations to select functions within the diffusers library, one may achieve commendable outcomes utilizing base diffusion models such as SD v1.4, v1.5, v2.0, and v2.1, as mentioned in our paper. Additionally, you can apply your customized configurations to experiment with a graphics card possessing 8GB of VRAM. For an in-depth exposition, kindly refer to our Example_Notebook.
Our method can automatically generates output without pre-storing MLLM responses, leveraging Chain-of-Thought reasoning and high-quality in-context examples to obtain satisfactory results. Users only need to specify some parameters. For example, to use GPT-4 as the region planner, we can refer to the code below, contained in the RPG.py ( Please note that we have two pipelines which support different model architectures, for SD v1.4/1.5/2.0/2.1 models, you should use RegionalDiffusionPipeline, for SDXL models, you should use RegionalDiffusionXLPipeline. ):
from RegionalDiffusion_base import RegionalDiffusionPipeline
from RegionalDiffusion_xl import RegionalDiffusionXLPipeline
from diffusers.schedulers import KarrasDiffusionSchedulers,DPMSolverMultistepScheduler
from mllm import local_llm,GPT4
import torch
# If you want to load ckpt, initialize with ".from_single_file".
pipe = RegionalDiffusionXLPipeline.from_single_file("path to your ckpt",torch_dtype=torch.float16, use_safetensors=True, variant="fp16")
# If you want to use diffusers, initialize with ".from_pretrained".
# pipe = RegionalDiffusionXLPipeline.from_pretrained("path to your diffusers",torch_dtype=torch.float16, use_safetensors=True, variant="fp16")
pipe.to("cuda")
pipe.scheduler = DPMSolverMultistepScheduler.from_config(pipe.scheduler.config,use_karras_sigmas=True)
pipe.enable_xformers_memory_efficient_attention()
## User input
prompt= ' A handsome young man with blonde curly hair and black suit with a black twintail girl in red cheongsam in the bar.'
para_dict = GPT4(prompt,key='...Put your api-key here...')
## MLLM based split generation results
split_ratio = para_dict['Final split ratio']
regional_prompt = para_dict['Regional Prompt']
negative_prompt = "" # negative_prompt,
images = pipe(
prompt=regional_prompt,
split_ratio=split_ratio, # The ratio of the regional prompt, the number of prompts is the same as the number of regions
batch_size = 1, #batch size
base_ratio = 0.5, # The ratio of the base prompt
base_prompt= prompt,
num_inference_steps=20, # sampling step
height = 1024,
negative_prompt=negative_prompt, # negative prompt
width = 1024,
seed = None,# random seed
guidance_scale = 7.0
).images[0]
images.save("test.png")prompt is the original prompt that roughly summarize the content of the image
base_prompt sets base prompt for generation, which is the summary of the image, here we set the base_prompt as the original input prompt by default
base_ratio is the weight of the base prompt
There are also other common optional parameters:
guidance_scale is the classifier-free guidance scale
num_inference_steps is the steps to generate an image
seed controls the seed to make the generation reproducible
It should be noted that we introduce some important parameters: base_prompt & base_ratio
After adding your prompt and api-key, and setting your path to downloaded diffusion model, just run the following command and get the results:
python RPG.pyFAQ: How to set --base_prompt & --base_ratio properly ?
If you want to generate an image with multiple entities with the same class (e.g., two girls, three cats, a man and a girl), you should use base prompt and set base prompt that includes the number of each class of entities in the image using base_prompt. Another relevant parameter is base_ratio which is the weight of the base prompt. According to our experiments, when base_ratio is in [0.35,0.55], the final results are better. Here is the generated image for command above:
And you will get an image similar to ours results as long as we have the same random seed:
 |
| Text prompt: A handsome young man with blonde curly hair and black suit with a black twintail girl in red cheongsam in the bar. |
On the other hand, when it comes to an image including multiple entities with different classes, there is no need to use base prompt, here is an example:
from RegionalDiffusion_base import RegionalDiffusionPipeline
from RegionalDiffusion_xl import RegionalDiffusionXLPipeline
from diffusers.schedulers import KarrasDiffusionSchedulers,DPMSolverMultistepScheduler
from mllm import local_llm,GPT4
import torch
# If you want to load ckpt, initialize with ".from_single_file".
pipe = RegionalDiffusionXLPipeline.from_single_file("path to your ckpt",torch_dtype=torch.float16, use_safetensors=True, variant="fp16")
# #If you want to use diffusers, initialize with ".from_pretrained".
# pipe = RegionalDiffusionXLPipeline.from_pretrained("path to your diffusers",torch_dtype=torch.float16, use_safetensors=True, variant="fp16")
pipe.to("cuda")
pipe.scheduler = DPMSolverMultistepScheduler.from_config(pipe.scheduler.config,use_karras_sigmas=True)
pipe.enable_xformers_memory_efficient_attention()
prompt= 'From left to right, bathed in soft morning light,a cozy nook features a steaming Starbucks latte on a rustic table beside an elegant vase of blooming roses,while a plush ragdoll cat purrs contentedly nearby,its eyes half-closed in blissful serenity.'
para_dict = GPT4(prompt,key='your key')
split_ratio = para_dict['Final split ratio']
regional_prompt = para_dict['Regional Prompt']
negative_prompt = ""
images = pipe(
prompt=regional_prompt,
split_ratio=split_ratio, # The ratio of the regional prompt, the number of prompts is the same as the number of regions, and the number of prompts is the same as the number of regions
batch_size = 1, #batch size
base_ratio = 0.5, # The ratio of the base prompt
base_prompt= None, # If the base_prompt is None, the base_ratio will not work
num_inference_steps=20, # sampling step
height = 1024,
negative_prompt=negative_prompt, # negative prompt
width = 1024,
seed = None,# random seed
guidance_scale = 7.0
).images[0]
images.save("test.png")And you will get an image similar to our results:
 |
| Text prompt: From left to right, bathed in soft morning light,a cozy nook features a steaming Starbucks latte on a rustic table beside an elegant vase of blooming roses,while a plush ragdoll cat purrs contentedly nearby,its eyes half-closed in blissful serenity. |
It's important to know when should we use base_prompt, if these parameters are not set properly, we can not get satisfactory results. We have conducted ablation study about base prompt in our paper, you can check our paper for more information.
We recommend to use base models with over 13 billion parameters for high-quality results, but it will increase load times and graphical memory use at the same time. We have conducted experiments with three different sized models. Here we take llama2-13b-chat as an example:
from RegionalDiffusion_base import RegionalDiffusionPipeline
from RegionalDiffusion_xl import RegionalDiffusionXLPipeline
from diffusers.schedulers import KarrasDiffusionSchedulers,DPMSolverMultistepScheduler
from mllm import local_llm,GPT4
import torch
# If you want to use single ckpt, use this pipeline
pipe = RegionalDiffusionXLPipeline.from_single_file("path to your ckpt",torch_dtype=torch.float16, use_safetensors=True, variant="fp16")
# If you want to use diffusers, use this pipeline
# pipe = RegionalDiffusionXLPipeline.from_pretrained("path to your diffusers",torch_dtype=torch.float16, use_safetensors=True, variant="fp16")
pipe.to("cuda")
pipe.scheduler = DPMSolverMultistepScheduler.from_config(pipe.scheduler.config,use_karras_sigmas=True)
pipe.enable_xformers_memory_efficient_attention()
prompt= 'Two girls are chatting in the cafe.'
para_dict = local_llm(prompt,model_path='path to your model')
split_ratio = para_dict['Final split ratio']
regional_prompt = para_dict['Regional Prompt']
negative_prompt = ""
images = pipe(
prompt=regional_prompt,
split_ratio=split_ratio, # The ratio of the regional prompt, the number of prompts is the same as the number of regions, and the number of prompts is the same as the number of regions
batch_size = 1, #batch size
base_ratio = 0.5, # The ratio of the base prompt
base_prompt= prompt,
num_inference_steps=20, # sampling step
height = 1024,
negative_prompt=negative_prompt, # negative prompt
width = 1024,
seed = 1234,# random seed
guidance_scale = 7.0
).images[0]
images.save("test.png")In local version, after adding your prompt and setting your path to diffusion model and your path to the local MLLM/LLM, just the command below to get the results:
python RPG.py
@inproceedings{yang2024mastering,
title={Mastering Text-to-Image Diffusion: Recaptioning, Planning, and Generating with Multimodal LLMs},
author={Yang, Ling and Yu, Zhaochen and Meng, Chenlin and Xu, Minkai and Ermon, Stefano and Cui, Bin},
booktitle={International Conference on Machine Learning},
year={2024}
}
Our RPG is a general MLLM-controlled text-to-image generation/editing framework, which is builded upon several solid works. Thanks to AUTOMATIC1111, regional-prompter, SAM, diffusers and IA for their wonderful work and codebase! We also thank Hugging Face for sharing our paper.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for RPG-DiffusionMaster
Similar Open Source Tools
RPG-DiffusionMaster
This repository contains the official implementation of RPG, a powerful training-free paradigm for text-to-image generation and editing. RPG utilizes proprietary or open-source MLLMs as prompt recaptioner and region planner with complementary regional diffusion. It achieves state-of-the-art results and can generate high-resolution images. The codebase supports diffusers and various diffusion backbones, including SDXL and SD v1.4/1.5. Users can reproduce results with GPT-4, Gemini-Pro, or local MLLMs like miniGPT-4. The repository provides tools for quick start, regional diffusion with GPT-4, and regional diffusion with local LLMs.

llm-reasoners
LLM Reasoners is a library that enables LLMs to conduct complex reasoning, with advanced reasoning algorithms. It approaches multi-step reasoning as planning and searches for the optimal reasoning chain, which achieves the best balance of exploration vs exploitation with the idea of "World Model" and "Reward". Given any reasoning problem, simply define the reward function and an optional world model (explained below), and let LLM reasoners take care of the rest, including Reasoning Algorithms, Visualization, LLM calling, and more!

RLHF-Reward-Modeling
This repository contains code for training reward models for Deep Reinforcement Learning-based Reward-modulated Hierarchical Fine-tuning (DRL-based RLHF), Iterative Selection Fine-tuning (Rejection sampling fine-tuning), and iterative Decision Policy Optimization (DPO). The reward models are trained using a Bradley-Terry model based on the Gemma and Mistral language models. The resulting reward models achieve state-of-the-art performance on the RewardBench leaderboard for reward models with base models of up to 13B parameters.
x-lstm
This repository contains an unofficial implementation of the xLSTM model introduced in Beck et al. (2024). It serves as a didactic tool to explain the details of a modern Long-Short Term Memory model with competitive performance against Transformers or State-Space models. The repository also includes a Lightning-based implementation of a basic LLM for multi-GPU training. It provides modules for scalar-LSTM and matrix-LSTM, as well as an xLSTM LLM built using Pytorch Lightning for easy training on multi-GPUs.
x-crawl
x-crawl is a flexible Node.js AI-assisted crawler library that offers powerful AI assistance functions to make crawler work more efficient, intelligent, and convenient. It consists of a crawler API and various functions that can work normally even without relying on AI. The AI component is currently based on a large AI model provided by OpenAI, simplifying many tedious operations. The library supports crawling dynamic pages, static pages, interface data, and file data, with features like control page operations, device fingerprinting, asynchronous sync, interval crawling, failed retry handling, rotation proxy, priority queue, crawl information control, and TypeScript support.

allms
allms is a versatile and powerful library designed to streamline the process of querying Large Language Models (LLMs). Developed by Allegro engineers, it simplifies working with LLM applications by providing a user-friendly interface, asynchronous querying, automatic retrying mechanism, error handling, and output parsing. It supports various LLM families hosted on different platforms like OpenAI, Google, Azure, and GCP. The library offers features for configuring endpoint credentials, batch querying with symbolic variables, and forcing structured output format. It also provides documentation, quickstart guides, and instructions for local development, testing, updating documentation, and making new releases.
cappr
CAPPr is a tool for text classification that does not require training or post-processing. It allows users to have their language models pick from a list of choices or compute the probability of a completion given a prompt. The tool aims to help users get more out of open source language models by simplifying the text classification process. CAPPr can be used with GGUF models, Hugging Face models, models from the OpenAI API, and for tasks like caching instructions, extracting final answers from step-by-step completions, and running predictions in batches with different sets of completions.

llms
The 'llms' repository is a comprehensive guide on Large Language Models (LLMs), covering topics such as language modeling, applications of LLMs, statistical language modeling, neural language models, conditional language models, evaluation methods, transformer-based language models, practical LLMs like GPT and BERT, prompt engineering, fine-tuning LLMs, retrieval augmented generation, AI agents, and LLMs for computer vision. The repository provides detailed explanations, examples, and tools for working with LLMs.
forust
Forust is a lightweight package for building gradient boosted decision tree ensembles. The algorithm code is written in Rust with a Python wrapper. It implements the same algorithm as XGBoost and provides nearly identical results. The package was developed to better understand XGBoost, as a fun project in Rust, and to experiment with adding new features to the algorithm in a simpler codebase. Forust allows training gradient boosted decision tree ensembles with multiple objective functions, predicting on datasets, inspecting model structures, calculating feature importance, and saving/loading trained boosters.
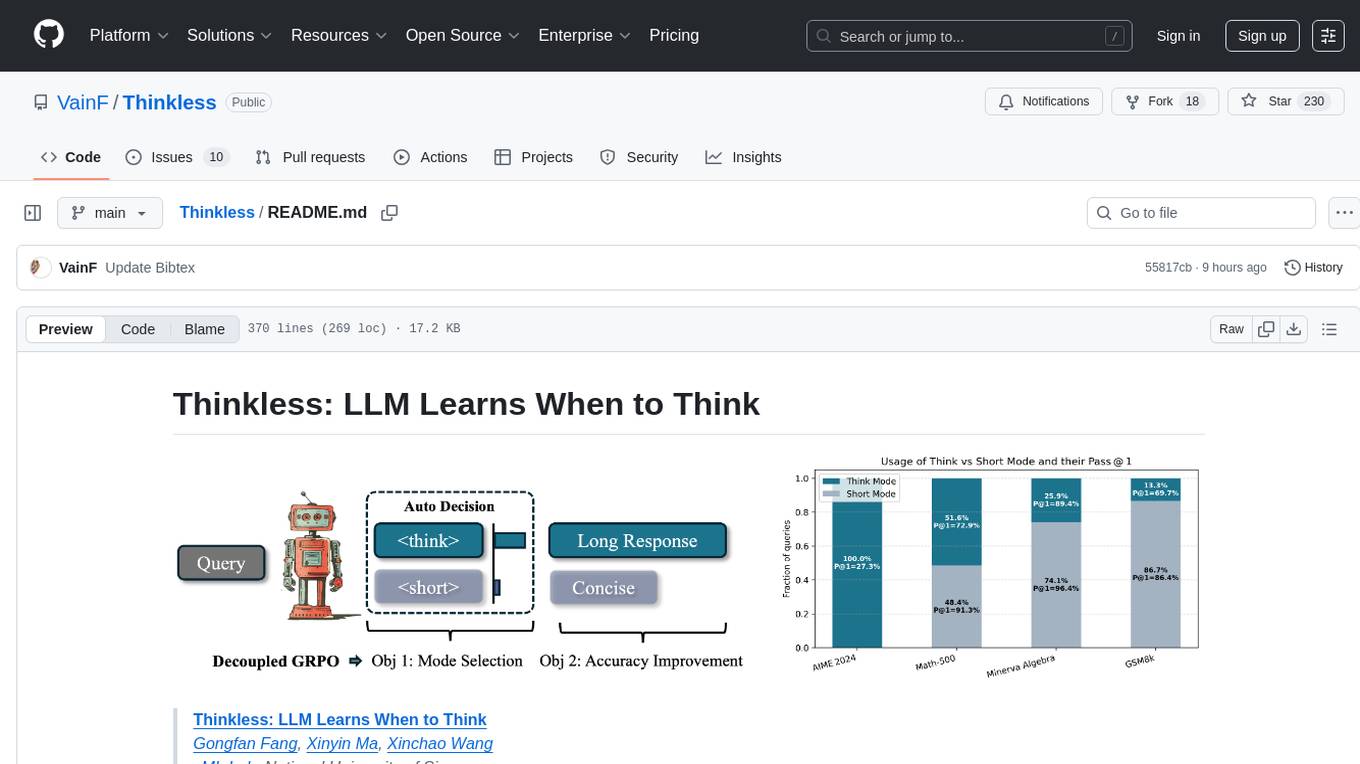
Thinkless
Thinkless is a learnable framework that empowers a Language and Reasoning Model (LLM) to adaptively select between short-form and long-form reasoning based on task complexity and model's ability. It is trained under a reinforcement learning paradigm and employs control tokens for concise responses and detailed reasoning. The core method uses a Decoupled Group Relative Policy Optimization (DeGRPO) algorithm to govern reasoning mode selection and improve answer accuracy, reducing long-chain thinking by 50% - 90% on benchmarks like Minerva Algebra and MATH-500. Thinkless enhances computational efficiency of Reasoning Language Models.
LLMLingua
LLMLingua is a tool that utilizes a compact, well-trained language model to identify and remove non-essential tokens in prompts. This approach enables efficient inference with large language models, achieving up to 20x compression with minimal performance loss. The tool includes LLMLingua, LongLLMLingua, and LLMLingua-2, each offering different levels of prompt compression and performance improvements for tasks involving large language models.

LLM-Pruner
LLM-Pruner is a tool for structural pruning of large language models, allowing task-agnostic compression while retaining multi-task solving ability. It supports automatic structural pruning of various LLMs with minimal human effort. The tool is efficient, requiring only 3 minutes for pruning and 3 hours for post-training. Supported LLMs include Llama-3.1, Llama-3, Llama-2, LLaMA, BLOOM, Vicuna, and Baichuan. Updates include support for new LLMs like GQA and BLOOM, as well as fine-tuning results achieving high accuracy. The tool provides step-by-step instructions for pruning, post-training, and evaluation, along with a Gradio interface for text generation. Limitations include issues with generating repetitive or nonsensical tokens in compressed models and manual operations for certain models.
AI
AI is an open-source Swift framework for interfacing with generative AI. It provides functionalities for text completions, image-to-text vision, function calling, DALLE-3 image generation, audio transcription and generation, and text embeddings. The framework supports multiple AI models from providers like OpenAI, Anthropic, Mistral, Groq, and ElevenLabs. Users can easily integrate AI capabilities into their Swift projects using AI framework.
SUPIR
SUPIR is an AI-based image processing and upscaling tool that leverages cutting-edge technology to enhance image quality and resolution. The tool provides users with the ability to upscale images with high generalization and quality, as well as specific settings for light degradation scenarios. It offers a range of models and checkpoints for different use cases, along with detailed instructions for installation and usage. SUPIR also includes features for color fixing, linear CFG adjustments, and various prompts for image enhancement. The tool is designed for non-commercial use only and comes with a contact email for inquiries and permission requests for commercial use.

k2
K2 (GeoLLaMA) is a large language model for geoscience, trained on geoscience literature and fine-tuned with knowledge-intensive instruction data. It outperforms baseline models on objective and subjective tasks. The repository provides K2 weights, core data of GeoSignal, GeoBench benchmark, and code for further pretraining and instruction tuning. The model is available on Hugging Face for use. The project aims to create larger and more powerful geoscience language models in the future.
For similar tasks

InvokeAI
InvokeAI is a leading creative engine built to empower professionals and enthusiasts alike. Generate and create stunning visual media using the latest AI-driven technologies. InvokeAI offers an industry leading Web Interface, interactive Command Line Interface, and also serves as the foundation for multiple commercial products.

StableSwarmUI
StableSwarmUI is a modular Stable Diffusion web user interface that emphasizes making power tools easily accessible, high performance, and extensible. It is designed to be a one-stop-shop for all things Stable Diffusion, providing a wide range of features and capabilities to enhance the user experience.

civitai
Civitai is a platform where people can share their stable diffusion models (textual inversions, hypernetworks, aesthetic gradients, VAEs, and any other crazy stuff people do to customize their AI generations), collaborate with others to improve them, and learn from each other's work. The platform allows users to create an account, upload their models, and browse models that have been shared by others. Users can also leave comments and feedback on each other's models to facilitate collaboration and knowledge sharing.

ap-plugin
AP-PLUGIN is an AI drawing plugin for the Yunzai series robot framework, allowing you to have a convenient AI drawing experience in the input box. It uses the open source Stable Diffusion web UI as the backend, deploys it for free, and generates a variety of images with richer functions.

ComfyUI-IF_AI_tools
ComfyUI-IF_AI_tools is a set of custom nodes for ComfyUI that allows you to generate prompts using a local Large Language Model (LLM) via Ollama. This tool enables you to enhance your image generation workflow by leveraging the power of language models.
midjourney-proxy
Midjourney-proxy is a proxy for the Discord channel of MidJourney, enabling API-based calls for AI drawing. It supports Imagine instructions, adding image base64 as a placeholder, Blend and Describe commands, real-time progress tracking, Chinese prompt translation, prompt sensitive word pre-detection, user-token connection to WSS, multi-account configuration, and more. For more advanced features, consider using midjourney-proxy-plus, which includes Shorten, focus shifting, image zooming, local redrawing, nearly all associated button actions, Remix mode, seed value retrieval, account pool persistence, dynamic maintenance, /info and /settings retrieval, account settings configuration, Niji bot robot, InsightFace face replacement robot, and an embedded management dashboard.
krita-ai-diffusion
Krita-AI-Diffusion is a plugin for Krita that allows users to generate images from within the program. It offers a variety of features, including inpainting, outpainting, generating images from scratch, refining existing content, live painting, and control over image creation. The plugin is designed to fit into an interactive workflow where AI generation is used as just another tool while painting. It is meant to synergize with traditional tools and the layer stack.
cog-comfyui
Cog-comfyui allows users to run ComfyUI workflows on Replicate. ComfyUI is a visual programming tool for creating and sharing generative art workflows. With cog-comfyui, users can access a variety of pre-trained models and custom nodes to create their own unique artworks. The tool is easy to use and does not require any coding experience. Users simply need to upload their API JSON file and any necessary input files, and then click the "Run" button. Cog-comfyui will then generate the output image or video file.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.