Best AI tools for< Speech Recognition >
Infographic
20 - AI tool Sites
Speech Intellect
Speech Intellect is an AI-powered speech-to-text and text-to-speech solution that provides real-time transcription and voice synthesis with emotional analysis. It utilizes a proprietary "Sense Theory" algorithm to capture the meaning and tone of speech, enabling businesses to automate tasks, improve customer interactions, and create personalized experiences.
Deepgram
Deepgram is a speech recognition and transcription service that uses artificial intelligence to convert audio into text. It is designed to be accurate, fast, and easy to use. Deepgram offers a variety of features, including: - Automatic speech recognition - Speaker diarization - Language identification - Custom acoustic models - Real-time transcription - Batch transcription - Webhooks - Integrations with popular platforms such as Zoom, Google Meet, and Microsoft Teams
ELSA Speech Analyzer
ELSA Speech Analyzer is an AI-powered conversational English fluency coach that provides instant, personalized feedback on your speech. It helps users improve their pronunciation, intonation, grammar, and vocabulary through real-time analysis. The tool is designed to assist individuals, professionals, students, and organizations in enhancing their English speaking skills and communication abilities.
Voicetapp
Voicetapp is a powerful cloud-based artificial intelligence software that helps you automatically convert audio to text with up to 100% accuracy. It supports over 170 languages and dialects, allowing you to quickly and accurately transcribe speech from audio and video files. Voicetapp also offers features such as speaker identification, live transcription, and multiple input formats, making it a versatile tool for various use cases.
Lingvanex
Lingvanex is a cloud-based machine translation and speech recognition platform that provides businesses with a variety of tools to translate text, documents, and speech in over 100 languages. The platform is powered by artificial intelligence (AI) and machine learning (ML) technologies, which enable it to deliver high-quality translations that are both accurate and fluent. Lingvanex also offers a variety of features that make it easy for businesses to integrate translation and speech recognition into their workflows, including APIs, SDKs, and plugins for popular programming languages and platforms.
VoxSigma
Vocapia Research develops leading-edge, multilingual speech processing technologies exploiting AI methods such as machine learning. These technologies enable large vocabulary continuous speech recognition, automatic audio segmentation, language identification, speaker diarization and audio-text synchronization. Vocapia's VoxSigma™ speech-to-text software suite delivers state-of-the-art performance in many languages for a variety of audio data types, including broadcast data, parliamentary hearings and conversational data.
SpeechFlow
SpeechFlow is a powerful speech-to-text API that transcribes audio and video files into text with high accuracy. It supports 14 languages and offers features such as punctuation, easy deployment, scalability, and fast processing. SpeechFlow is ideal for businesses and individuals who need accurate and timely transcription services.
BlabbyAI
BlabbyAI is an AI-powered speech-to-text Chrome extension that allows users to write with their voice on any website. It seamlessly integrates with various platforms, offering automatic punctuation, capitalization, and grammar. Users can personalize their transcription experience with custom modes and save time by boosting productivity. The tool has received positive reviews for its accuracy, ease of use, and cross-platform functionality.
Picovoice
Picovoice is an on-device Voice AI and local LLM platform designed for enterprises. It offers a range of voice AI and LLM solutions, including speech-to-text, noise suppression, speaker recognition, speech-to-index, wake word detection, and more. Picovoice empowers developers to build virtual assistants and AI-powered products with compliance, reliability, and scalability in mind. The platform allows enterprises to process data locally without relying on third-party remote servers, ensuring data privacy and security. With a focus on cutting-edge AI technology, Picovoice enables users to stay ahead of the curve and adapt quickly to changing customer needs.
SpeechText.AI
SpeechText.AI is a powerful artificial intelligence software for speech to text conversion and audio transcription. It offers accurate transcriptions of audio and video files using domain-specific speech recognition technology. The application provides various features to transcribe, edit, and export audio content in different formats. With state-of-the-art deep neural network models, SpeechText.AI achieves close to human accuracy in converting audio to text. The tool is widely used for transcription of interviews, medical data, conference calls, podcasts, and more, catering to various industries such as finance, healthcare, legal, and HR.

babs.ai
babs.ai is an AI-powered job matching platform that connects talent with opportunities. It leverages intelligent matching algorithms to streamline the recruitment process and ensure a seamless experience for both job seekers and employers. The platform caters to a wide range of job roles and industries, making it a versatile solution for all types of users.
WavoAI
WavoAI is an AI-powered transcription and summarization tool that helps users transcribe audio recordings quickly and accurately. It offers features such as speaker identification, annotations, and interactive AI insights, making it a valuable tool for a wide range of professionals, including academics, filmmakers, podcasters, and journalists.
Deepgram
Deepgram is a powerful API platform that provides developers with tools for building speech-to-text, text-to-speech, and intelligence applications. With Deepgram, developers can easily add speech recognition, text-to-speech, and other AI-powered features to their applications.
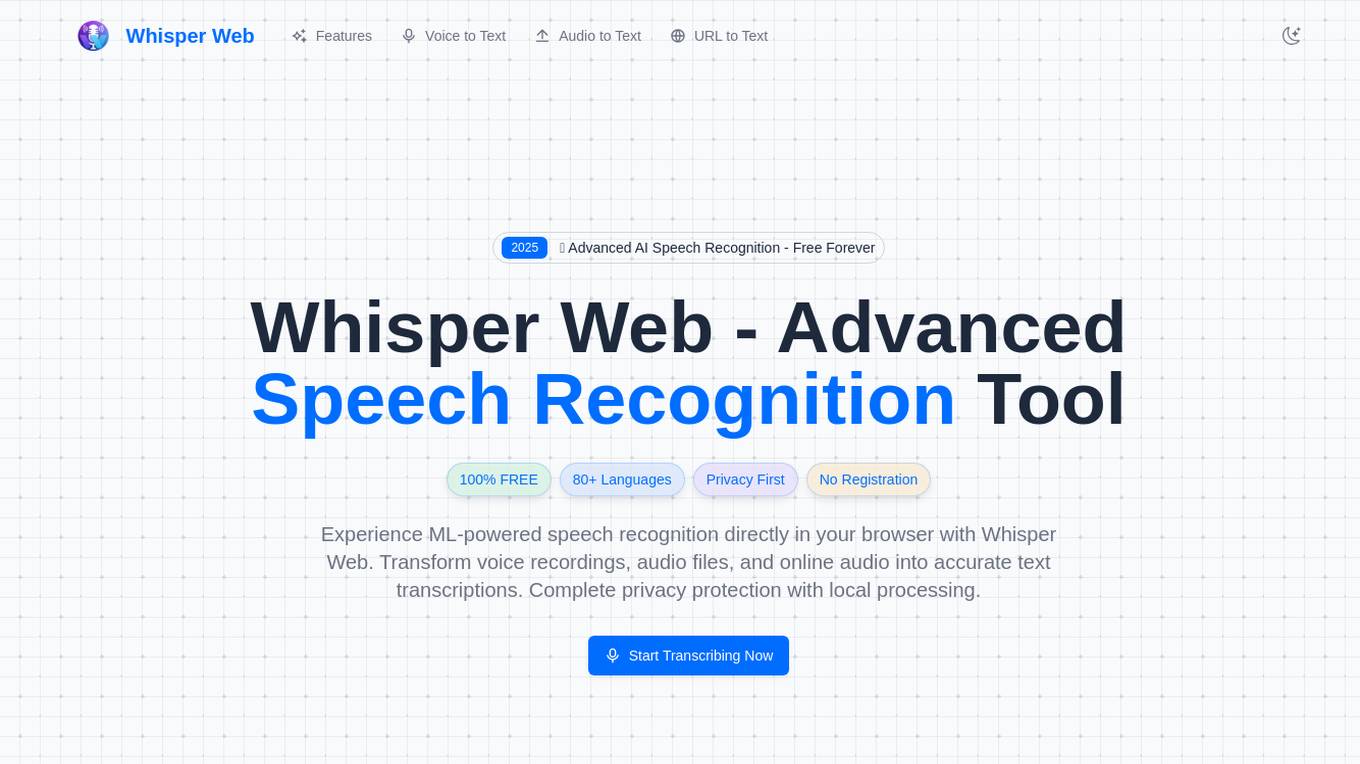
Whisper Web
Whisper Web is a free AI speech recognition tool that offers advanced speech recognition powered by machine learning algorithms. Users can transform voice recordings, audio files, and online audio into accurate text transcriptions with complete privacy protection through local processing in the browser. The tool supports multiple input methods, real-time processing, and export options in various formats, making it ideal for journalists, researchers, students, and professionals who require precise voice-to-text conversion.
ELSA
ELSA is an AI-powered English speaking coach that helps you improve your pronunciation, fluency, and confidence. With ELSA, you can practice speaking English in short, fun dialogues and get instant feedback from our proprietary artificial intelligence technology. ELSA also offers a variety of other features, such as personalized lesson plans, progress tracking, and games to help you stay motivated.
AppTek.ai
AppTek.ai is a global leader in artificial intelligence (AI) and machine learning (ML) technologies, providing advanced solutions in automatic speech recognition, neural machine translation, natural language processing/understanding, large language models, and text-to-speech technologies. The platform offers industry-leading language solutions for various sectors such as media and entertainment, call centers, government, and enterprise business. AppTek.ai combines cutting-edge AI research with real-world applications, delivering accurate and efficient tools for speech transcription, translation, understanding, and synthesis across multiple languages and dialects.
AppTek
AppTek is a global leader in artificial intelligence (AI) and machine learning (ML) technologies for automatic speech recognition (ASR), neural machine translation (NMT), natural language processing/understanding (NLP/U) and text-to-speech (TTS) technologies. The AppTek platform delivers industry-leading solutions for organizations across a breadth of global markets such as media and entertainment, call centers, government, enterprise business, and more. Built by scientists and research engineers who are recognized among the best in the world, AppTek’s solutions cover a wide array of languages/ dialects, channels, domains and demographics.

Speech Studio
Speech Studio is a cloud-based speech-to-text and text-to-speech platform that enables developers to add speech capabilities to their applications. With Speech Studio, developers can easily transcribe audio and video files, generate synthetic speech, and build custom speech models. Speech Studio is a powerful tool that can be used to improve the accessibility, efficiency, and user experience of any application.
DeepScribe
DeepScribe is an AI medical scribe application that leverages advanced speech recognition technology to capture clinical conversations with extreme accuracy. It empowers clinicians and health systems with real-time AI insights, offers customization options to match provider workflows, and ensures trust and safety through features that promote AI transparency. DeepScribe is designed to save time, improve accuracy, drive adoption, and maximize revenue for doctors, hospitals, and health systems. The application is built for enterprise use, allowing users to unlock the power of AI and modernize their patient data strategy.
S10.AI
S10.AI is an AI-powered medical scribe application designed to streamline medical documentation processes for healthcare professionals. It offers seamless integration with any EMR system, providing accurate and efficient transcription of patient conversations. The application saves time, ensures confidentiality, and adapts to various medical templates and workflows. S10.AI is praised for its precision, efficiency, and support, making it a valuable asset for practitioners looking to enhance administrative tasks without compromising patient care.
3 - Open Source Tools
Friend
Friend is an open-source AI wearable device that records everything you say, gives you proactive feedback and advice. It has real-time AI audio processing capabilities, low-powered Bluetooth, open-source software, and a wearable design. The device is designed to be affordable and easy to use, with a total cost of less than $20. To get started, you can clone the repo, choose the version of the app you want to install, and follow the instructions for installing the firmware and assembling the device. Friend is still a prototype project and is provided "as is", without warranty of any kind. Use of the device should comply with all local laws and regulations concerning privacy and data protection.

edenai-apis
Eden AI aims to simplify the use and deployment of AI technologies by providing a unique API that connects to all the best AI engines. With the rise of **AI as a Service** , a lot of companies provide off-the-shelf trained models that you can access directly through an API. These companies are either the tech giants (Google, Microsoft , Amazon) or other smaller, more specialized companies, and there are hundreds of them. Some of the most known are : DeepL (translation), OpenAI (text and image analysis), AssemblyAI (speech analysis). There are **hundreds of companies** doing that. We're regrouping the best ones **in one place** !

ruby-openai
Use the OpenAI API with Ruby! 🤖🩵 Stream text with GPT-4, transcribe and translate audio with Whisper, or create images with DALL·E... Hire me | 🎮 Ruby AI Builders Discord | 🐦 Twitter | 🧠 Anthropic Gem | 🚂 Midjourney Gem ## Table of Contents * Ruby OpenAI * Table of Contents * Installation * Bundler * Gem install * Usage * Quickstart * With Config * Custom timeout or base URI * Extra Headers per Client * Logging * Errors * Faraday middleware * Azure * Ollama * Counting Tokens * Models * Examples * Chat * Streaming Chat * Vision * JSON Mode * Functions * Edits * Embeddings * Batches * Files * Finetunes * Assistants * Threads and Messages * Runs * Runs involving function tools * Image Generation * DALL·E 2 * DALL·E 3 * Image Edit * Image Variations * Moderations * Whisper * Translate * Transcribe * Speech * Errors * Development * Release * Contributing * License * Code of Conduct
20 - OpenAI Gpts
Ultimate Translator
Speak, snap, and understand the world. Your pocket-sized translator deciphers docs, images, and speech in a heartbeat with pronunciation guides and motivational boosts!
Deep Learning Master
Guiding you through the depths of deep learning with accuracy and respect.

English Pronunciation Helper
I assist with English pronunciation using the Turkish alphabet.

Tourist Language Accelerator
Accelerates the learning of key phrases and cultural norms for travelers in various languages.

Language Coach
Practice speaking another language like a local without being a local (use ChatGPT Voice via mobile app!)
AI Speech Guide
A helpful coach for speech writing, offering constructive advice and support
Dedicated Speech-Language Pathologist
Expert Speech-Language Pathologist offering tailored medical consultations.
Speech Parody
Create speech transcript parodies. Copyright (C) 2023, Sourceduty - All Rights Reserved.

Detailed Speech Drafting Wizard
Crafts speeches from PowerPoint slides and reference materials, adding depth and context.
AI.EX Wedding Speech Consultant
Your partner in crafting perfect wedding speeches. Let me be your guide to writing impactful, memorable speeches for unforgettable moments.

AI Phonetics and Reading Coach with Speech
Phonetics and reading coach with interactive voice capabilities, tailored for adult beginners.