Speech Studio
The future of speech technology is here.

Speech Studio is a cloud-based speech-to-text and text-to-speech platform that enables developers to add speech capabilities to their applications. With Speech Studio, developers can easily transcribe audio and video files, generate synthetic speech, and build custom speech models. Speech Studio is a powerful tool that can be used to improve the accessibility, efficiency, and user experience of any application.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Features
Advantages
Disadvantages
Frequently Asked Questions
Alternative AI tools for Speech Studio
Similar sites
Speech Studio
Speech Studio is a cloud-based speech-to-text and text-to-speech platform that enables developers to add speech capabilities to their applications. With Speech Studio, developers can easily transcribe audio and video files, generate synthetic speech, and build custom speech models. Speech Studio is a powerful tool that can be used to improve the accessibility, efficiency, and user experience of any application.
Nemesys Labs
Nemesys Labs is a free AI-powered text-to-speech platform that utilizes artificial intelligence technology to convert written text into spoken words. Users can easily generate high-quality audio files from any text input, making it a valuable tool for content creators, educators, and individuals seeking accessible content. The platform offers a user-friendly interface and a range of customization options to tailor the voice, tone, and speed of the generated speech. Nemesys Labs aims to enhance communication and accessibility by providing a seamless text-to-speech solution for various applications.
Free Text to Speech Online Converter Tools
This website provides a free text-to-speech converter tool that utilizes Microsoft's AI speech library to synthesize realistic-sounding speech from text. It offers customizable voice options, fine-tuned speech controls, and multilingual support with over 330 neural network voices across 129 languages. The tool is accessible on various browsers, including Chrome, Firefox, and Edge, and can be used for a range of applications, such as text readers and voice-enabled assistants.
TEXTTOSPEECH.IM
TEXTTOSPEECH.IM is an advanced text to speech tool that utilizes artificial intelligence to convert text to lifelike audio. Users can easily generate and download high-quality speech in multiple languages and voice styles. The tool supports enhanced accessibility, cost-effective content creation, a wide range of voices, convenient offline use, high accuracy in speech synthesis, and cross-device compatibility for maximum flexibility.
Speech Intellect
Speech Intellect is an AI-powered speech-to-text and text-to-speech solution that provides real-time transcription and voice synthesis with emotional analysis. It utilizes a proprietary "Sense Theory" algorithm to capture the meaning and tone of speech, enabling businesses to automate tasks, improve customer interactions, and create personalized experiences.
Woord
Woord is an online text-to-speech (TTS) tool that allows users to convert text into natural-sounding speech. It offers a wide range of voices in over 34 languages, including regional variations. Woord also provides advanced features such as SSML editing, OCR support, and API access. With its user-friendly interface and affordable pricing, Woord is a great choice for individuals and businesses looking to add speech capabilities to their applications.
Speechelo
Speechelo is a text-to-speech software that allows users to instantly generate human-sounding voiceovers from text. It offers a wide range of features, including over 30 human-sounding voices, the ability to add breathing sounds and pauses, and the ability to generate voiceovers in over 23 languages. Speechelo is easy to use and can be integrated with any video creation software. It is a great tool for creating voiceovers for sales videos, training videos, educational videos, and more.
Text to Speech Online
Text to Speech Online is a free AI tool that offers unlimited text-to-speech conversion with over 409 realistic voices and 129 languages & dialects. Users can convert text to speech in seconds without the need to log in or sign up. The tool supports multiple languages and accents, including standard voices and AI voices, and offers flexible pricing models. Users can enjoy a full set of SSML features, create natural-sounding speech, download audio in MP3 or WAV formats, and share results on various platforms. Text to Speech Online is a versatile tool that can be used for various purposes, including providing audio cues for visually impaired users, assisting in education, creating audio versions of books, and developing virtual assistants.
Deepgram
Deepgram is a powerful API platform that provides developers with tools for building speech-to-text, text-to-speech, and intelligence applications. With Deepgram, developers can easily add speech recognition, text-to-speech, and other AI-powered features to their applications.
AudioBook Bot
AudioBook Bot is an AI-powered application that converts text into spoken audio, providing users with the convenience of listening to books and other text-based content. The tool utilizes advanced natural language processing and speech synthesis technologies to create high-quality audio renditions. Users can simply input text, and the bot will generate an audio version that can be played on various devices. With its user-friendly interface and efficient processing capabilities, AudioBook Bot offers a seamless experience for those who prefer listening over reading.
ChatTTS
ChatTTS is an open-source text-to-speech model designed for dialogue scenarios, supporting both English and Chinese speech generation. Trained on approximately 100,000 hours of Chinese and English data, it delivers speech quality comparable to human dialogue. The tool is particularly suitable for tasks involving large language model assistants and creating dialogue-based audio and video introductions. It provides developers with a powerful and easy-to-use tool based on open-source natural language processing and speech synthesis technologies.
SpeechText.AI
SpeechText.AI is a powerful artificial intelligence software for speech to text conversion and audio transcription. It offers accurate transcriptions of audio and video files using domain-specific speech recognition technology. The application provides various features to transcribe, edit, and export audio content in different formats. With state-of-the-art deep neural network models, SpeechText.AI achieves close to human accuracy in converting audio to text. The tool is widely used for transcription of interviews, medical data, conference calls, podcasts, and more, catering to various industries such as finance, healthcare, legal, and HR.
TTSMaker
TTSMaker is a free online text-to-speech tool that allows users to convert text into natural-sounding speech. It supports multiple languages and voices, and the resulting audio files can be downloaded for free and used for commercial purposes. TTSMaker is a valuable tool for creating audiobooks, dubbing videos, and other projects that require high-quality voiceovers.
Vocalx
Vocalx is an AI-powered online tool that converts text into natural-sounding speech. It utilizes advanced speech synthesis technology to generate lifelike voices for various applications. Users can easily create audio content from written text, making it ideal for content creators, educators, and businesses looking to enhance their multimedia offerings. With Vocalx, you can customize the voice, tone, and speed of the generated speech to suit your needs. The tool supports multiple languages and accents, providing a versatile solution for voiceover projects, audiobooks, podcasts, and more.
Vocaldo
Vocaldo is a revolutionary speech-to-text application that utilizes cutting-edge AI technology to transcribe speech into text in over 100 languages. It offers accurate, fast, and easy-to-use transcription services, allowing users to effortlessly convert audio or video files into text with high precision. Vocaldo supports multiple speakers, various accents, and background noise, making it a versatile tool for content creators, journalists, and businesses worldwide.
TTS Generator AI
TTS Generator AI is a free online text-to-speech tool that leverages cutting-edge AI technology to convert written text into high-quality, natural-sounding audio. This tool is invaluable for a variety of users, including students who need auditory learning materials, researchers who want to listen to long documents, and professionals seeking to make their written content more accessible. One of the standout features of TTS Tool is its ability to support a range of text formats, from simple text files to complex PDFs, making it incredibly versatile.
For similar tasks
Speech Studio
Speech Studio is a cloud-based speech-to-text and text-to-speech platform that enables developers to add speech capabilities to their applications. With Speech Studio, developers can easily transcribe audio and video files, generate synthetic speech, and build custom speech models. Speech Studio is a powerful tool that can be used to improve the accessibility, efficiency, and user experience of any application.
Eden AI
Eden AI is a platform offering a Unified AI API and Custom AI API solutions for users to access a wide range of AI models through a single endpoint or build tailored AI features optimized for specific business needs. The platform provides ready-to-use AI APIs, chatbot capabilities, image generation, speech-to-text, text-to-speech, OCR, and various other features to streamline AI integration. Eden AI empowers SaaS companies, internal tools, and customer-facing applications with high-quality AI functionalities, simplified integration, and centralized management of multiple third-party APIs. The platform focuses on simplicity, cost-effectiveness, and performance optimization to enhance AI development and deployment processes.
LMNT
LMNT is an ultrafast lifelike AI speech pricing API that offers low latency streaming for conversational apps, agents, and games. It provides lifelike voices through studio-quality voice clones and instant voice clones. Engineered by an ex-Google team, LMNT ensures reliable performance under pressure with consistent low latency and high availability. The platform enables real-time conversation, content creation at scale, and product marketing through captivating voiceovers. With a user-friendly interface and developer API, LMNT simplifies voice cloning and synthesis for both beginners and professionals.
AppTek
AppTek is a global leader in artificial intelligence (AI) and machine learning (ML) technologies for automatic speech recognition (ASR), neural machine translation (NMT), natural language processing/understanding (NLP/U) and text-to-speech (TTS) technologies. The AppTek platform delivers industry-leading solutions for organizations across a breadth of global markets such as media and entertainment, call centers, government, enterprise business, and more. Built by scientists and research engineers who are recognized among the best in the world, AppTek’s solutions cover a wide array of languages/ dialects, channels, domains and demographics.
Deepgram
Deepgram is a powerful API platform that provides developers with tools for building speech-to-text, text-to-speech, and intelligence applications. With Deepgram, developers can easily add speech recognition, text-to-speech, and other AI-powered features to their applications.
Replicate
Replicate is an AI tool that allows users to run and fine-tune open-source models, deploy custom models at scale, and generate images, text, videos, music, and speech with just one line of code. It provides a platform for the community to contribute and explore thousands of production-ready AI models, enabling users to push the boundaries of AI beyond academic papers and demos. With features like fine-tuning models, deploying custom models, and scaling on Replicate, users can easily create and deploy AI solutions for various tasks.
ChatTTS
ChatTTS is an open-source text-to-speech model designed for dialogue scenarios, supporting both English and Chinese speech generation. Trained on approximately 100,000 hours of Chinese and English data, it delivers speech quality comparable to human dialogue. The tool is particularly suitable for tasks involving large language model assistants and creating dialogue-based audio and video introductions. It provides developers with a powerful and easy-to-use tool based on open-source natural language processing and speech synthesis technologies.
ChatTTS
ChatTTS is a text-to-speech tool optimized for natural, conversational scenarios. It supports both Chinese and English languages, trained on approximately 100,000 hours of data. With features like multi-language support, large data training, dialog task compatibility, open-source plans, control, security, and ease of use, ChatTTS provides high-quality and natural-sounding voice synthesis. It is designed for conversational tasks, dialogue speech generation, video introductions, educational content synthesis, and more. Users can integrate ChatTTS into their applications using provided API and SDKs for a seamless text-to-speech experience.
ChatTTS
ChatTTS is a natural and expressive text-to-speech tool designed for dialogue applications. It supports mixed language input and offers multi-speaker capabilities with precise control over prosodic elements like laughter, pauses, and intonation. Users can explore the unique capabilities of ChatTTS, enjoy conversational TTS optimized for dialogue-based tasks, and benefit from fine-grained control over prosodic features. The tool is multilingual, supporting both English and Chinese languages, and is open-source and customizable with pretrained models available for further research and development.
Neoform AI
Neoform AI is an innovative AI tool that focuses on developing AI models specifically for African dialects. The platform aims to bridge the gap in AI technology by providing solutions tailored to the linguistic diversity of Africa. With a commitment to inclusivity and cultural representation, Neoform AI is revolutionizing the field of artificial intelligence by addressing the unique challenges faced by African languages. Through cutting-edge research and development, Neoform AI is paving the way for greater accessibility and accuracy in AI applications across the continent.
TopTools.ai
The website toptools.ai is the #1 AI Tools Directory, providing a platform for users to discover and access various AI tools and applications. Users can filter tools based on pricing models and categories such as advertising, analysis, chatbots, design, education, marketing, and more. The site offers a wide range of AI-powered tools for different purposes, from content creation and SEO optimization to mental health support and influencer marketing. Users can find tools for free, on a free trial, freemium, or paid basis, catering to diverse needs and preferences in the AI space.
VoiceGen
VoiceGen is an AI audio platform that enables users to create realistic speech using the best technology from leading providers like OpenAI, Google, AWS, and Azure. It offers natural, high-quality voices with support for multiple languages and unrestricted commercial use. VoiceGen prioritizes simplicity, transparency, and innovation, providing an accessible and affordable solution for voice generation needs. The platform ensures security and privacy of user data, offering a pay-as-you-go pricing model with fair and transparent costs.
DubSmart
DubSmart is an AI-powered platform that offers advanced video dubbing and voice cloning services. It allows users to transform text into lifelike speech, dub videos with voice cloning technology, and generate subtitles for audio or video content. With a user-friendly interface, DubSmart enables users to create unique voices, edit projects, and download finished projects in various formats. The platform supports 33 languages for AI dubbing and 60+ languages for speech-to-text conversion. DubSmart caters to small creators, YouTubers, and companies looking to enhance their audiovisual content with personalized voices and multilingual capabilities.
AI Voice Studio
AI Voice Studio is an innovative online tool that allows users to convert text into lifelike speech using advanced AI technology. With AI Voice Studio, users can easily create high-quality voiceovers for various purposes such as videos, podcasts, and presentations. The tool offers a user-friendly interface and a wide range of customization options to tailor the voice output to specific needs. Whether you are a content creator, marketer, or educator, AI Voice Studio provides a convenient and efficient solution for generating natural-sounding voice content.
AssemblyAI
AssemblyAI is an AI tool that provides AI models for transcribing and understanding speech. Their products include Speech-to-Text Streaming, Speech Understanding, and more. AssemblyAI's research focuses on building new AI systems that can understand human speech with superhuman abilities. They offer industry-leading accuracy, low Word Error Rate (WER), and advanced capabilities like speaker identification and multilingual speech recognition. The platform is designed to be easy to use, scalable, and cost-effective for developers. AssemblyAI is trusted by top Voice AI companies for launching innovative products quickly and efficiently.
TalkFlow
TalkFlow is an AI assistant application designed for meetings, interviews, and more. It offers real-time advice during conversations, helps in solving coding problems, and provides personalized assistance for both personal and enterprise use. The application utilizes AI technology to enhance communication, improve efficiency, and streamline processes in various scenarios.
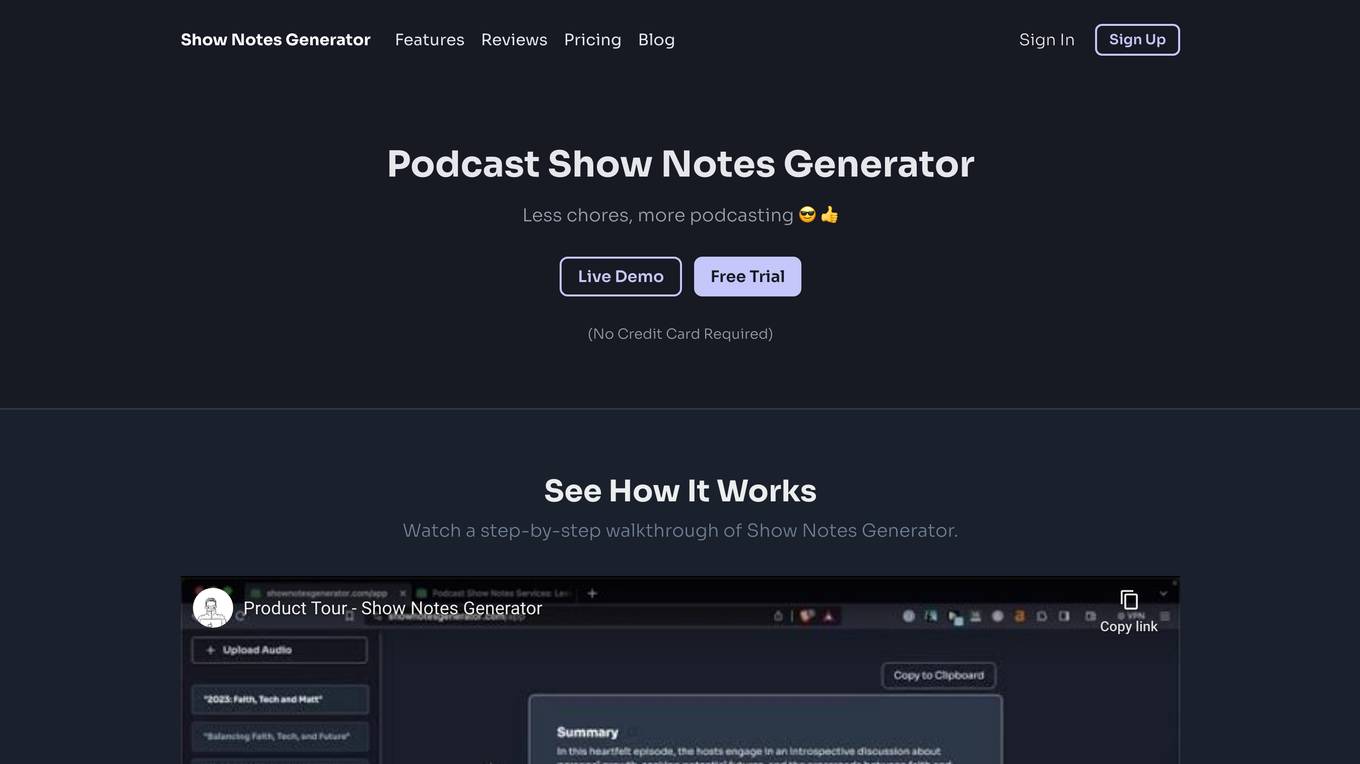
Podcast Show Notes Generator
The Podcast Show Notes Generator is an AI-powered tool designed to help podcasters create engaging show notes quickly and efficiently. It offers features such as converting audio into concise summaries, auto-identifying distinct sections in audio, and generating detailed text transcripts. The tool aims to enhance accessibility, SEO, and audience engagement for podcasters by providing a user-friendly platform to streamline the show notes creation process.
Transcript.LOL
Transcript.LOL is a transcription tool designed to save time and enhance productivity for creators and small to medium-sized businesses. It offers a platform to transcribe audio, video, and meeting recordings, supporting over 1500 platforms. The tool provides summaries, categorizes key themes, and offers contextual Q&A based on the transcriptions. With speaker identification and readable transcripts, users can easily navigate and understand the content. Transcript.LOL aims to streamline the transcription process and provide valuable insights faster than ever before.
Paxo
Paxo is an AI-powered meeting notes app that provides clear, concise, and actionable meeting notes in minutes. It is purpose-built for in-person conversations and offers features such as voice identification, privacy-first architecture, and easy imports and exports. Paxo helps users stay organized and on top of their game by eliminating messy handwriting, misheard words, and forgotten action items. It is available as an app for iOS devices and syncs across all devices using iCloud.
WavoAI
WavoAI is an AI-powered transcription and summarization tool that helps users transcribe audio recordings quickly and accurately. It offers features such as speaker identification, annotations, and interactive AI insights, making it a valuable tool for a wide range of professionals, including academics, filmmakers, podcasters, and journalists.
pyannote AI Speaker Intelligence Platform
The pyannote AI Speaker Intelligence Platform is an advanced AI tool designed for developers to detect, segment, label, and separate speakers in any language. It offers state-of-the-art speaker diarization models that accurately identify speakers in audio recordings, providing valuable insights and improving productivity. With optimized AI models, the platform saves time, effort, and money by delivering top-tier performance. The tool is language agnostic and offers advanced features such as speaker partitioning, identification, overlapping speech detection, voice activity detection, speaker separation, and confidence scoring.
Descript
Descript is an AI-powered video and podcast editor that simplifies the editing process by offering features like video editing, podcasting, screen recording, automatic transcription, AI avatars, AI speech generation, and more. It allows users to create professional videos and podcasts with ease, using text-based editing and AI tools to enhance the content. Descript is designed to streamline the video and audio editing workflow, making it accessible for creators of all levels.
ScreenApp
ScreenApp is an AI-powered tool that serves as a notetaker, transcription tool, summarizer, and recorder for audio and video content. It offers features like instant capture and analysis of screen content, mobile recording and transcription with AI insights, and a variety of AI-powered tools for audio and video processing. ScreenApp aims to help users turn scattered conversations into structured knowledge, enhance productivity, and streamline information management across various platforms.
Supertranslate.ai
Supertranslate.ai is an AI-powered platform that offers speech-to-text transcription, subtitle generation, and translation services in over 125 languages. It caters to media professionals and organizations looking to reach global audiences by providing accurate and efficient tools for transforming audio and video content. The platform features advanced speech recognition technology, noise reduction capabilities, speaker identification, custom dictionaries, team collaboration options, and seamless integrations with popular services like Google Drive and Dropbox. Users can easily upload their media files, have them processed by AI algorithms, review and edit the transcripts, and export the subtitles in various formats. Supertranslate.ai offers different pricing plans to suit individual users, small teams, growing agencies, and enterprise-level media companies, ensuring scalability and customization based on specific needs.
For similar jobs
Beatsbrew
Beatsbrew is an AI-powered application that allows users to create unique audio samples, beats, and loops by entering text prompts. Users can generate a variety of sound assets, from instruments to beats, with the help of AI technology. The application provides a valuable resource for music producers and creators looking to enhance their projects with new and exciting sounds. Beatsbrew offers a user-friendly platform to easily create and explore sound samples, making music production and creative projects more efficient and innovative.
AnthemScore
AnthemScore is an automatic music transcription software that utilizes AI technology to convert audio files like MP3 and WAV into sheet music. It offers features such as automatic note detection, easy correction, time-saving tools, customization for different instruments, and advanced editing options. The software is available for Windows, Mac, and Linux, with a free trial option allowing users to transcribe songs and view sheet music. AnthemScore aims to simplify the process of music transcription for musicians and composers.
SplitSong
SplitSong.com is an AI tool that allows users to split songs into individual instrument tracks using Artificial Intelligence. Created by @markdoppler_, the website offers a user-friendly platform where users can upload their songs or extract them from YouTube. Users can then download separate tracks for drums, instrumental, bass, and vocals, enabling them to remix or study music in a more detailed manner.
LALAL.AI
LALAL.AI is a next-generation vocal remover and music source separation service that offers fast, easy, and precise stem extraction. It allows users to remove vocals, instrumental tracks, drums, bass, guitar, and more without quality loss. The platform uses advanced AI technology to provide high-quality stem splitting based on transformer-based audio separation approach. Users can create custom voices, remove background noise, change voices, and separate lead and backing vocals with pinpoint accuracy. LALAL.AI offers various packages for individuals and businesses, with features like fast processing queue, batch upload, and stem download. The service supports a wide range of input/output formats for audio and video files.
Tape It
Tape It is an iOS app designed for songwriting and audio recording. It provides a platform for creative musicians to organize their song ideas, record audio, and collaborate with others. Users can set markers while recording, create mixtapes, add text and photo notes, search for instruments, and organize recordings in batches. The app allows users to record in stereo, connect audio interfaces, and export recordings as wav or mp3 files. Additionally, users can share their work privately or publicly, collaborate with friends, and create videos for social media. Tape It aims to streamline the songwriting process and enhance the recording experience for musicians.
Resemble AI
Resemble AI is an AI-powered platform that offers AI Voice Generator and Deepfake Detection services for enterprises. The platform provides features such as Generative AI Voice Cloning, Text to Speech, Speech to Speech conversion, Multilingual support, Audio Editing, and Open Source Voice Cloning AI Model. Resemble AI focuses on delivering state-of-the-art AI models for voice generation and deepfake detection, ensuring security and trust for its users.
Kits AI
Kits AI is a studio-quality AI music tool that offers a range of features to streamline music production workflows. It provides tools for voice cloning, singing like anyone, playing any instrument, isolating vocals, and more. With 100% Royalty Free content, Kits AI allows users to create their own AI singing clones and collaborate without the need for recording sessions. The application is designed to enhance creativity, save time, and offer new revenue streams for vocalists and producers.

Controlla Voice
Controlla Voice is an AI application that allows users to transform vocals into new voices or instruments, swap any song to their own voice in any language, and create unique blended voices. Users can train their own AI singing voice, generate AI cover songs, and create realistic choirs with customizable harmonies. The application provides a vocal toolkit for never-before-heard sounds and offers flexible pricing options to access high-quality AI singing voices. With Controlla Voice, users can enhance their voice, express themselves in their most natural way, and monetize their music with automatic royalties.
ACE Studio
ACE Studio is an AI Vocal Workstation that allows users to generate vocals from various professional AI vocalists by typing MIDI and lyrics. It simplifies the production of lead vocals, harmonies, backing vocals, and choirs. The platform features a next-generation AI Singing Synthesis Engine that aims to deliver natural and expressive vocal performances. Users can access over 41 AI pro-singers in English, Chinese, and Japanese for music production. ACE Studio offers tools for editing and controlling vocal emotions, converting dry vocals into MIDI clips, blending voices, and customizing AI voice models.
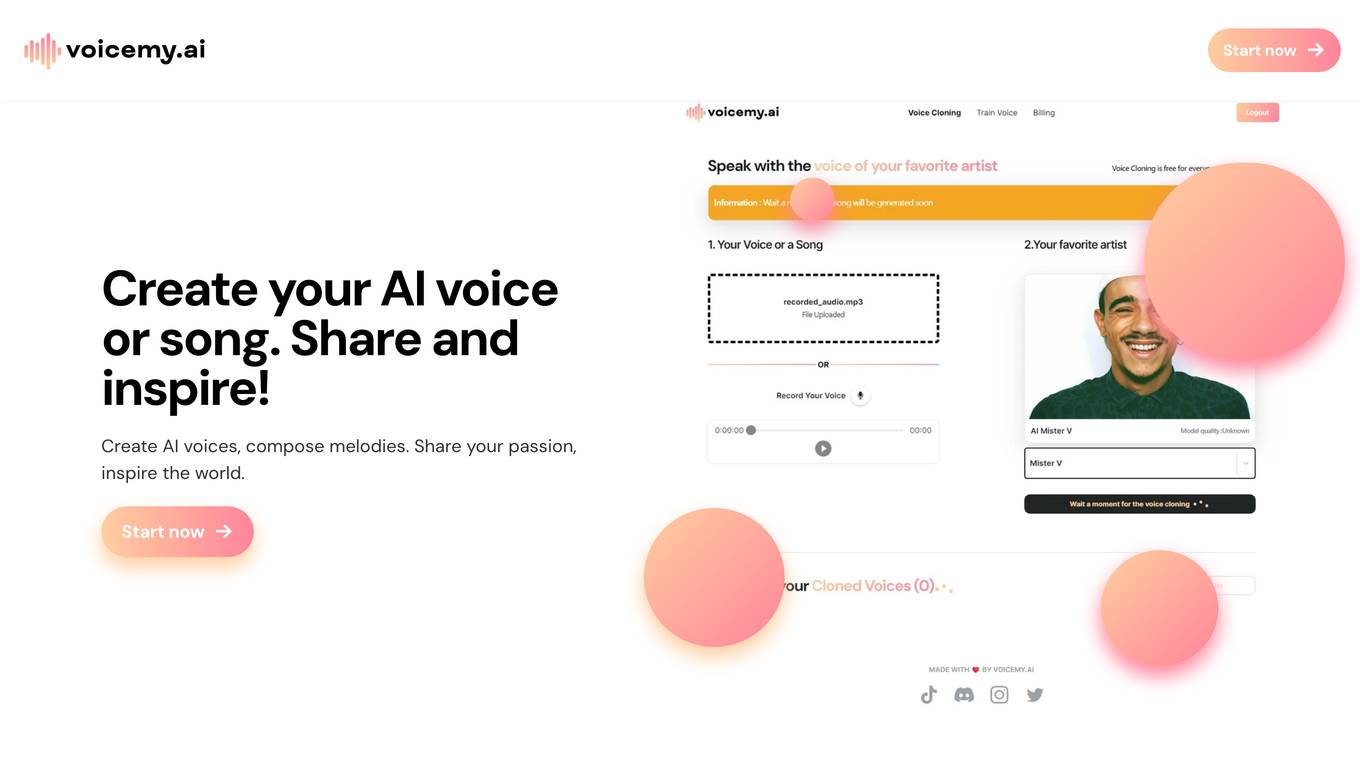
Voicemy.ai
Voicemy.ai is an AI application that allows users to create AI voices and songs. Users can clone voices of famous personalities, compose melodies, and convert text into spoken words using chosen voice models. The platform aims to inspire creativity and enable users to share their passion with the world.
Splitter.ai
Splitter.ai is an AI-driven audio processing platform developed by a Swedish research company. It offers advanced audio processing technologies, including stem separation/extraction, reverb removal, and direct YouTube splitting. The platform is designed to assist music producers, DJs, artists, forensics engineers, audio engineers, karaoke enthusiasts, police, scientists, and more in enhancing their audio processing tasks. Splitter.ai aims to provide high-quality services through AI-driven solutions to meet the diverse needs of its users.
Music AI
Music AI is an AI audio platform that offers state-of-the-art ethical AI solutions for audio and music applications. It provides a wide range of tools and modules for tasks such as stem separation, transcription, mixing, mastering, content generation, effects, utilities, classification, enhancement, style transfer, and more. The platform aims to streamline audio processing workflows, enhance creativity, improve accuracy, increase engagement, and save time for music professionals and businesses. Music AI prioritizes data security, privacy, and customization, allowing users to build custom workflows with over 50 AI modules.
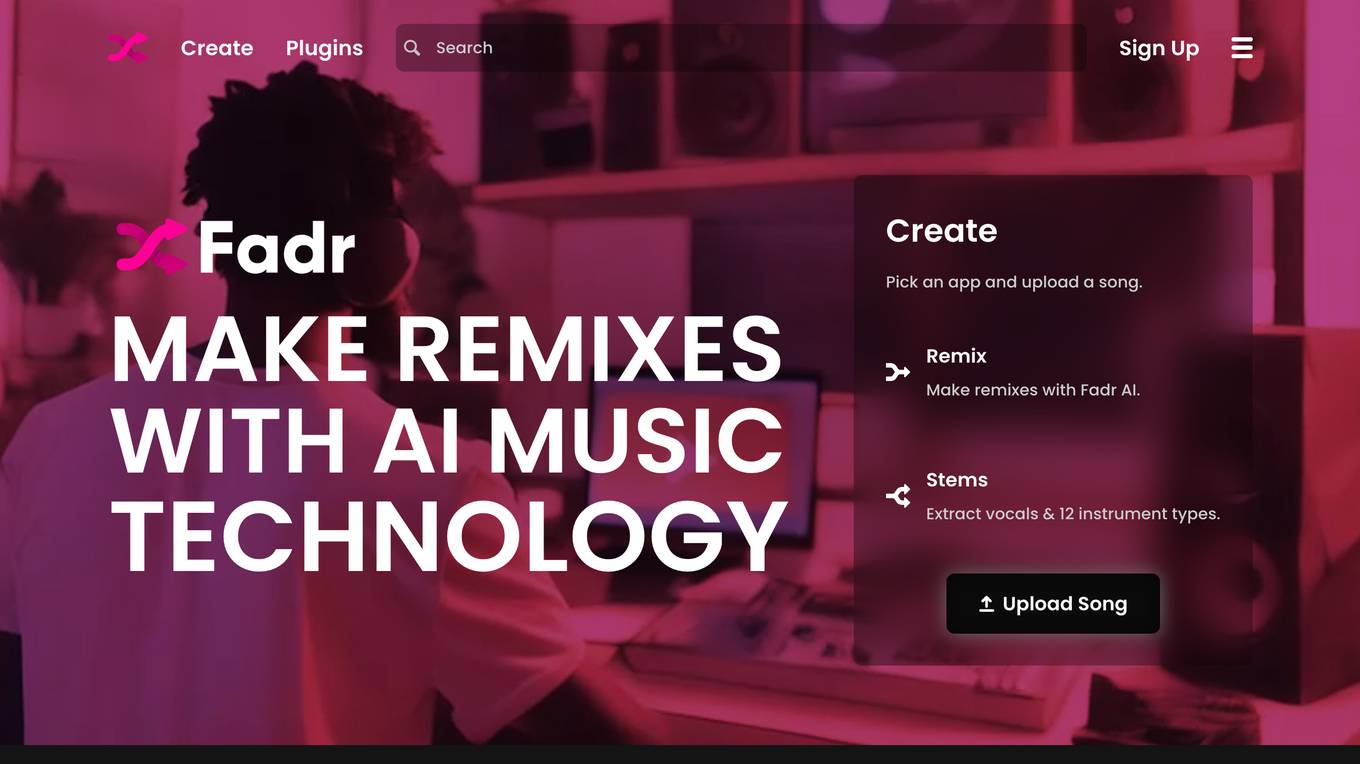
Fadr
Fadr is an AI music maker application that enhances creativity by providing tools for creating music using AI technology. Users can pick from a variety of tools like SynthGPT to create playable instruments with text, Remix to make remixes with Fadr AI, and Stems to extract vocals and instrument types. Fadr aims to amplify musical creativity by developing web apps and plugins that help users in making art and exploring new sounds.
Output
Output is the ultimate creative software for music makers, offering a range of tools and plugins to supercharge music production. With Output Arcade as the flagship product, musicians can access a powerful sampler and instrument plugin, along with FX plugins and Kontakt Instruments to transform their sound. The platform also introduces AI capabilities through features like Pack Generator, providing cutting-edge software for musicians to enhance their creativity and production workflow. Output aims to simplify the music-making process and empower artists to focus on their craft.
Stability AI
Stability AI is an AI application that offers a suite of models for various modalities such as image, video, audio, 3D, and language. It provides cutting-edge generative AI technology with a focus on stability and quality. Users can access advanced AI models for tasks like text-to-image generation, video modeling, audio generation, and more. The application also offers licensing options for commercial use and self-hosting benefits.
Tracksy
Tracksy is a generative AI assistant that empowers creators to effortlessly craft unique music, regardless of their musical background. With Tracksy, users can unleash their creativity by generating music using text, genre, or mood as their inspiration. The platform offers a user-friendly interface, making it accessible to both experienced musicians and those new to music creation. Tracksy's mission is to empower creators by providing them with the tools they need to bring their musical ideas to life.
VOCALOID
VOCALOID is a singing synthesizer software that allows users to create and edit vocal melodies and lyrics. It is used by musicians, producers, and songwriters to create a wide range of musical genres, from pop and rock to electronic and experimental music. VOCALOID is known for its realistic and expressive vocal synthesis, which is achieved through a combination of advanced sampling and modeling techniques.
TuneFlow
TuneFlow is an intelligent music-making platform powered by AI. It provides users with a wide range of tools and features to create, edit, and share their music. TuneFlow is designed to be easy to use, even for beginners, and it offers a variety of features that make it a powerful tool for professional musicians as well.
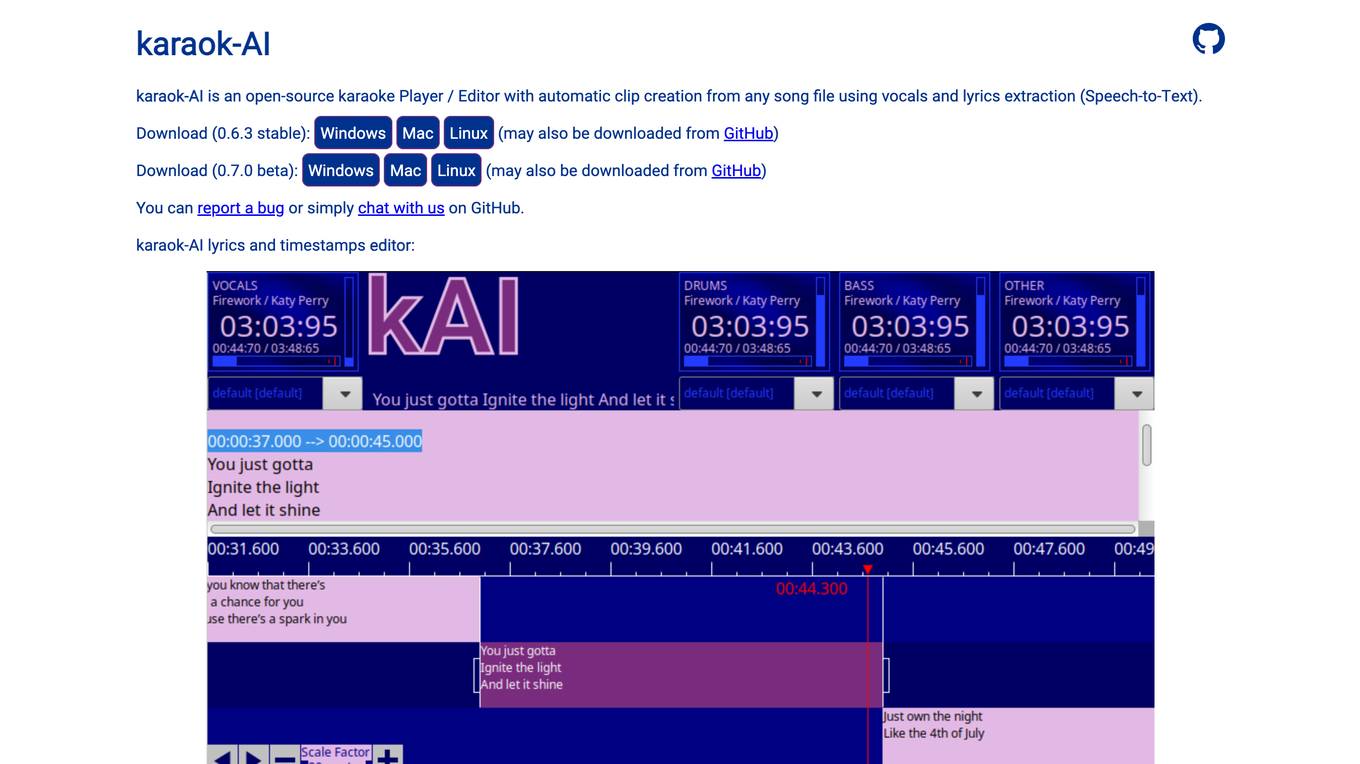
karaok-AI
karaok-AI is an open-source karaoke Player / Editor with automatic clip creation from any song file using vocals and lyrics extraction (Speech-to-Text). It uses WhisperHallu and WhisperTimeSync to extract vocals and lyrics. karaok-AI also includes kaiDJ, a minimalist and easy-to-use DJ Party Player with multi-sound cards support, two players with auto-mix between songs, and a pre-listen player. It can index thousands of songs in a single efficient database and allows for direct search and selection over all songs. Additionally, it offers playlist management with nested groups and the ability to open and save m3u and m3u8 playlists while keeping group definitions.
Virtuozy Pro
Virtuozy Pro is an AI-powered music assistant that helps musicians of all levels create, produce, and master their music. With its intuitive interface and powerful features, Virtuozy Pro makes it easy to generate chords, lyrics, and complete songs in a variety of genres. Whether you're a beginner looking to learn the basics of music theory or a professional musician looking to streamline your workflow, Virtuozy Pro has something to offer everyone.
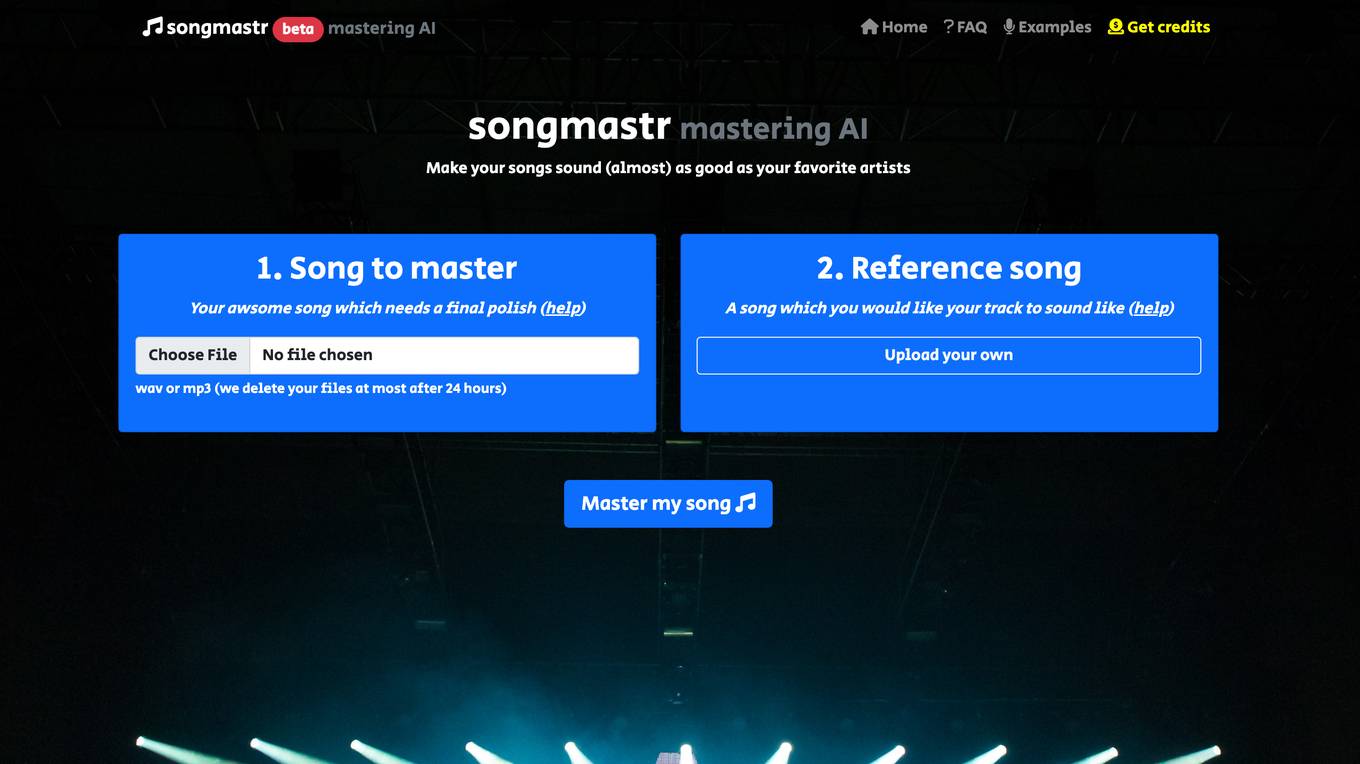
Songmastr
Songmastr is an automatic song mastering tool that uses artificial intelligence to master your songs to sound like a reference track. It's free to use for up to 7 songs per week, and you can master songs up to 10 minutes in length and 80MB in size. Songmastr is based on the open source library Matchering, and it uses the same RMS, FR, peak amplitude, and stereo width as the reference song you choose.

WarpSound
WarpSound is an AI music platform that uses cutting-edge generative AI technologies to create new forms of limitless music play and creativity. Its industry-leading music platform was developed in collaboration with Grammy-winning artists and uses a proprietary training dataset to produce original music in real time. It powers interactive music experiences and content for streaming, gaming, and more.

RipX DAW
RipX DAW is an AI-powered digital audio workstation (DAW) that allows users to edit notes in the mix, replace sounds, and separate stems. It is designed to assist musicians and producers in creating and editing music using AI-generated samples and loops. RipX DAW is known for its advanced features such as 6+ stem separation, sound replacement menu, and the ability to edit notes in the mix.
Respeecher
Respeecher is a voice cloning software that allows users to create synthetic voices that are indistinguishable from the original speaker. The software is used by content creators in a variety of industries, including film, television, gaming, advertising, and audiobooks. Respeecher's technology is based on artificial intelligence and machine learning, and it can replicate the voice of any person with just a few minutes of audio recording. The software is easy to use and can be accessed through a web interface. Respeecher offers a variety of features, including the ability to change the pitch, speed, and volume of the synthetic voice, as well as the ability to add effects such as reverb and delay. The software also includes a library of pre-recorded voices that can be used for a variety of purposes.