
X-AnyLabeling
Effortless data labeling with AI support from Segment Anything and other awesome models.
Stars: 6609

X-AnyLabeling is a robust annotation tool that seamlessly incorporates an AI inference engine alongside an array of sophisticated features. Tailored for practical applications, it is committed to delivering comprehensive, industrial-grade solutions for image data engineers. This tool excels in swiftly and automatically executing annotations across diverse and intricate tasks.
README:



Auto-Labeling
Text/Visual Prompting and Prompt-free for Detection & Segmentation
Detect Anything
Segment Anything
Chatbot
VQA
Image Classifier
- Bump version to 3.2.4
- Add support for deleting group IDs from objects (#1141)
- Add support for Ultralytics image classification task training [Toturial]
- Add loop select labels functionality for sequential shape selection (#1138)
- Add checkboxes for description and labels visibility control in the labeling widget (#1139)
- Add support for radiobutton widgets in shape attributes for faster single-click selection [Toturial]
- Add automatic attributes panel display when finishing shape drawing
- Fix linestrip vertex drawing issues (#1134)
- Add support for drawing rectangle shapes outside canvas with auto-clipping (#1137)
- Add dedicated multi-class image classifier with streamlined workflow [Docs]
- Add select/deselect all shapes feature
- Add custom provider support and enhance model dropdown feature for Chatbot
- Add option to preserve existing annotations when uploading YOLO labels
- Add cross-component and annotation data reference tokens for VQA AI prompts
- Bump version to 3.2.3
- Add mask fineness control slider for SAM series models to adjust segmentation precision
- Add Re-recognition feature for PP-OCR models [Example]
- Add support for PP-OCRv5 model
- Add copy coordinates to clipboard feature
- Add Navigator feature for high-resolution image navigation and zoom control
- Bump version to 3.2.2
- Add AI Assistant and prompt template management for VQA
- Add support for batch editing multiple shapes simultaneously
- Add support for Show/Hide shape attributes on canvas
- Add support for automated training platform with Ultralytics tasks in X-AnyLabeling [Link]
- For more details, please refer to the CHANGELOG
X-AnyLabeling is a powerful annotation tool that integrates an AI engine for fast and automatic labeling. It's designed for multi-modal data engineers, offering industrial-grade solutions for complex tasks.
- Processes both
imagesandvideos. - Accelerates inference with
GPUsupport. - Allows custom models and secondary development.
- Supports one-click inference for all images in the current task.
- Enable import/export for formats like COCO, VOC, YOLO, DOTA, MOT, MASK, PPOCR, MMGD, VLM-R1.
- Handles tasks like
classification,detection,segmentation,caption,rotation,tracking,estimation,ocrand so on. - Supports diverse annotation styles:
polygons,rectangles,rotated boxes,circles,lines,points, and annotations fortext detection,recognition, andKIE.
| Task Category | Supported Models |
|---|---|
| 🖼️ Image Classification | YOLOv5-Cls, YOLOv8-Cls, YOLO11-Cls, InternImage, PULC |
| 🎯 Object Detection | YOLOv5/6/7/8/9/10, YOLO11/12, YOLOX, YOLO-NAS, D-FINE, DAMO-YOLO, Gold_YOLO, RT-DETR, RF-DETR |
| 🖌️ Instance Segmentation | YOLOv5-Seg, YOLOv8-Seg, YOLO11-Seg, Hyper-YOLO-Seg |
| 🏃 Pose Estimation | YOLOv8-Pose, YOLO11-Pose, DWPose, RTMO |
| 👣 Tracking | Bot-SORT, ByteTrack |
| 🔄 Rotated Object Detection | YOLOv5-Obb, YOLOv8-Obb, YOLO11-Obb |
| 📏 Depth Estimation | Depth Anything |
| 🧩 Segment Anything | SAM, SAM-HQ, SAM-Med2D, EdgeSAM, EfficientViT-SAM, MobileSAM, |
| ✂️ Image Matting | RMBG 1.4/2.0 |
| 💡 Proposal | UPN |
| 🏷️ Tagging | RAM, RAM++ |
| 📄 OCR | PP-OCRv4, PP-OCRv5 |
| 🗣️ VLM | Florence2 |
| 🛣️ Land Detection | CLRNet |
| 📍 Grounding | CountGD, GeCO, Grunding DINO, YOLO-World, YOLOE |
| 📚 Other | 👉 model_zoo 👈 |
- Classification
- Detection
- Segmentation
- Description
- Estimation
- OCR
- MOT
- iVOS
- Matting
- Vision-Language
- Counting
- Training
We believe in open collaboration! X‑AnyLabeling continues to grow with the support of the community. Whether you're fixing bugs, improving documentation, or adding new features, your contributions make a real impact.
To get started, please read our Contributing Guide and make sure to agree to the Contributor License Agreement (CLA) before submitting a pull request.
If you find this project helpful, please consider giving it a ⭐️ star! Have questions or suggestions? Open an issue or email us at [email protected].
A huge thank you 🙏 to everyone helping to make X‑AnyLabeling better.
This project is licensed under the GPL-3.0 license and is only free to use for personal non-commercial purposes. For academic, research, or educational use, it is also free but requires registration via this form here. If you intend to use this project for commercial purposes or within a company, please contact [email protected] to obtain a commercial license.
I extend my heartfelt thanks to the developers and contributors of AnyLabeling, LabelMe, LabelImg, roLabelImg, PPOCRLabel and CVAT, whose work has been crucial to the success of this project.
If you use this software in your research, please cite it as below:
@misc{X-AnyLabeling,
year = {2023},
author = {Wei Wang},
publisher = {Github},
organization = {CVHub},
journal = {Github repository},
title = {Advanced Auto Labeling Solution with Added Features},
howpublished = {\url{https://github.com/CVHub520/X-AnyLabeling}}
}
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for X-AnyLabeling
Similar Open Source Tools
X-AnyLabeling
X-AnyLabeling is a robust annotation tool that seamlessly incorporates an AI inference engine alongside an array of sophisticated features. Tailored for practical applications, it is committed to delivering comprehensive, industrial-grade solutions for image data engineers. This tool excels in swiftly and automatically executing annotations across diverse and intricate tasks.
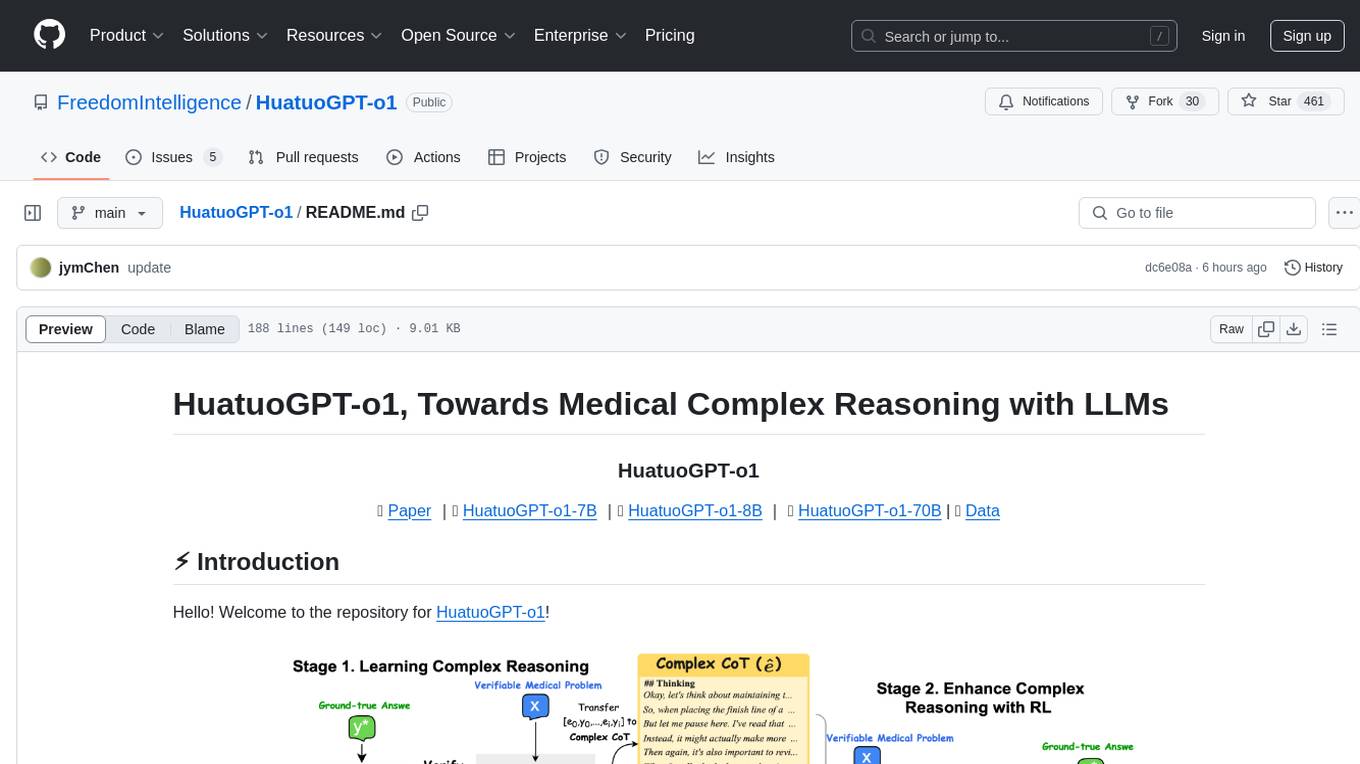
HuatuoGPT-o1
HuatuoGPT-o1 is a medical language model designed for advanced medical reasoning. It can identify mistakes, explore alternative strategies, and refine answers. The model leverages verifiable medical problems and a specialized medical verifier to guide complex reasoning trajectories and enhance reasoning through reinforcement learning. The repository provides access to models, data, and code for HuatuoGPT-o1, allowing users to deploy the model for medical reasoning tasks.

superduperdb
SuperDuperDB is a Python framework for integrating AI models, APIs, and vector search engines directly with your existing databases, including hosting of your own models, streaming inference and scalable model training/fine-tuning. Build, deploy and manage any AI application without the need for complex pipelines, infrastructure as well as specialized vector databases, and moving our data there, by integrating AI at your data's source: - Generative AI, LLMs, RAG, vector search - Standard machine learning use-cases (classification, segmentation, regression, forecasting recommendation etc.) - Custom AI use-cases involving specialized models - Even the most complex applications/workflows in which different models work together SuperDuperDB is **not** a database. Think `db = superduper(db)`: SuperDuperDB transforms your databases into an intelligent platform that allows you to leverage the full AI and Python ecosystem. A single development and deployment environment for all your AI applications in one place, fully scalable and easy to manage.
SoM-LLaVA
SoM-LLaVA is a new data source and learning paradigm for Multimodal LLMs, empowering open-source Multimodal LLMs with Set-of-Mark prompting and improved visual reasoning ability. The repository provides a new dataset that is complementary to existing training sources, enhancing multimodal LLMs with Set-of-Mark prompting and improved general capacity. By adding 30k SoM data to the visual instruction tuning stage of LLaVA, the tool achieves 1% to 6% relative improvements on all benchmarks. Users can train SoM-LLaVA via command line and utilize the implementation to annotate COCO images with SoM. Additionally, the tool can be loaded in Huggingface for further usage.

auto-news
Auto-News is an automatic news aggregator tool that utilizes Large Language Models (LLM) to pull information from various sources such as Tweets, RSS feeds, YouTube videos, web articles, Reddit, and journal notes. The tool aims to help users efficiently read and filter content based on personal interests, providing a unified reading experience and organizing information effectively. It features feed aggregation with summarization, transcript generation for videos and articles, noise reduction, task organization, and deep dive topic exploration. The tool supports multiple LLM backends, offers weekly top-k aggregations, and can be deployed on Linux/MacOS using docker-compose or Kubernetes.
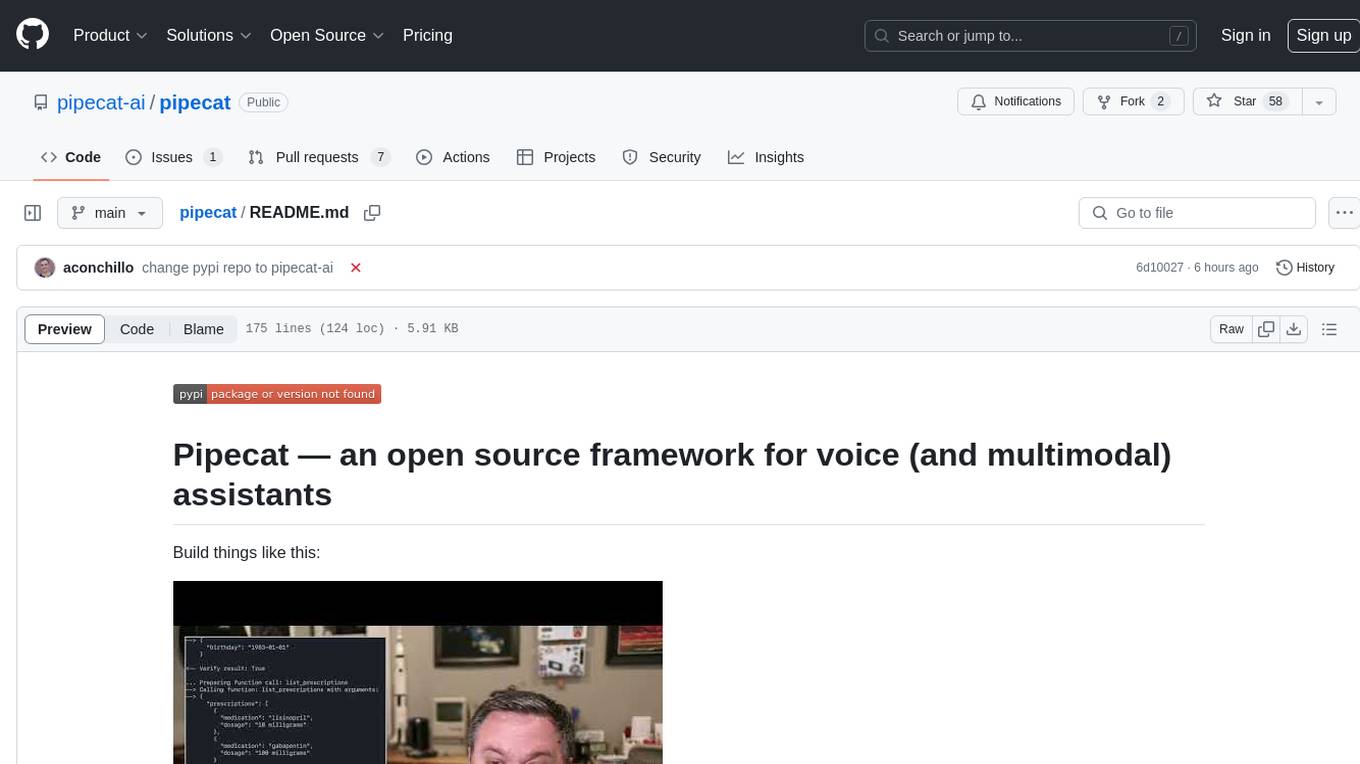
pipecat
Pipecat is an open-source framework designed for building generative AI voice bots and multimodal assistants. It provides code building blocks for interacting with AI services, creating low-latency data pipelines, and transporting audio, video, and events over the Internet. Pipecat supports various AI services like speech-to-text, text-to-speech, image generation, and vision models. Users can implement new services and contribute to the framework. Pipecat aims to simplify the development of applications like personal coaches, meeting assistants, customer support bots, and more by providing a complete framework for integrating AI services.
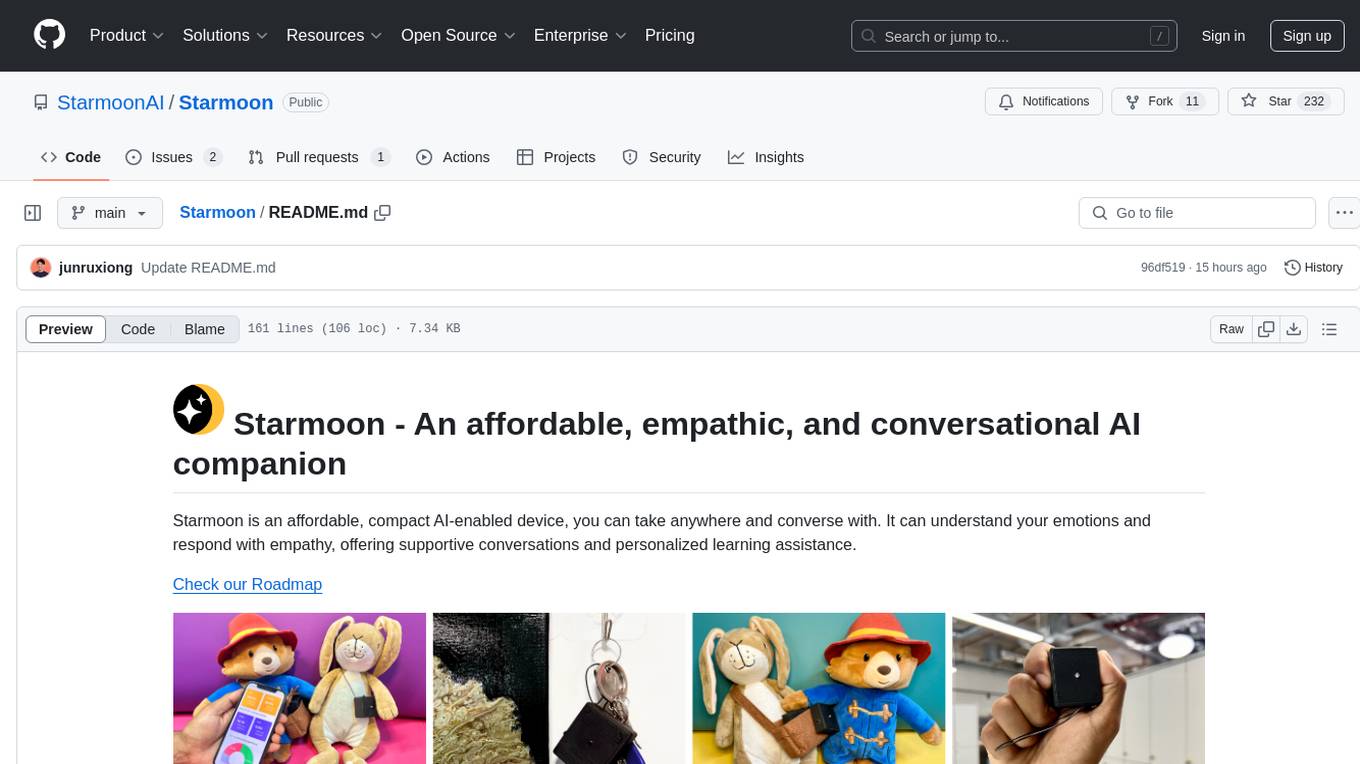
Starmoon
Starmoon is an affordable, compact AI-enabled device that can understand and respond to your emotions with empathy. It offers supportive conversations and personalized learning assistance. The device is cost-effective, voice-enabled, open-source, compact, and aims to reduce screen time. Users can assemble the device themselves using off-the-shelf components and deploy it locally for data privacy. Starmoon integrates various APIs for AI language models, speech-to-text, text-to-speech, and emotion intelligence. The hardware setup involves components like ESP32S3, microphone, amplifier, speaker, LED light, and button, along with software setup instructions for developers. The project also includes a web app, backend API, and background task dashboard for monitoring and management.

EvoAgentX
EvoAgentX is an open-source framework for building, evaluating, and evolving LLM-based agents or agentic workflows in an automated, modular, and goal-driven manner. It enables developers and researchers to move beyond static prompt chaining or manual workflow orchestration by introducing a self-evolving agent ecosystem. The framework includes features such as agent workflow autoconstruction, built-in evaluation, self-evolution engine, plug-and-play compatibility, comprehensive built-in tools, memory module support, and human-in-the-loop interactions.

WeKnora
WeKnora is a document understanding and semantic retrieval framework based on large language models (LLM), designed specifically for scenarios with complex structures and heterogeneous content. The framework adopts a modular architecture, integrating multimodal preprocessing, semantic vector indexing, intelligent recall, and large model generation reasoning to build an efficient and controllable document question-answering process. The core retrieval process is based on the RAG (Retrieval-Augmented Generation) mechanism, combining context-relevant segments with language models to achieve higher-quality semantic answers. It supports various document formats, intelligent inference, flexible extension, efficient retrieval, ease of use, and security and control. Suitable for enterprise knowledge management, scientific literature analysis, product technical support, legal compliance review, and medical knowledge assistance.
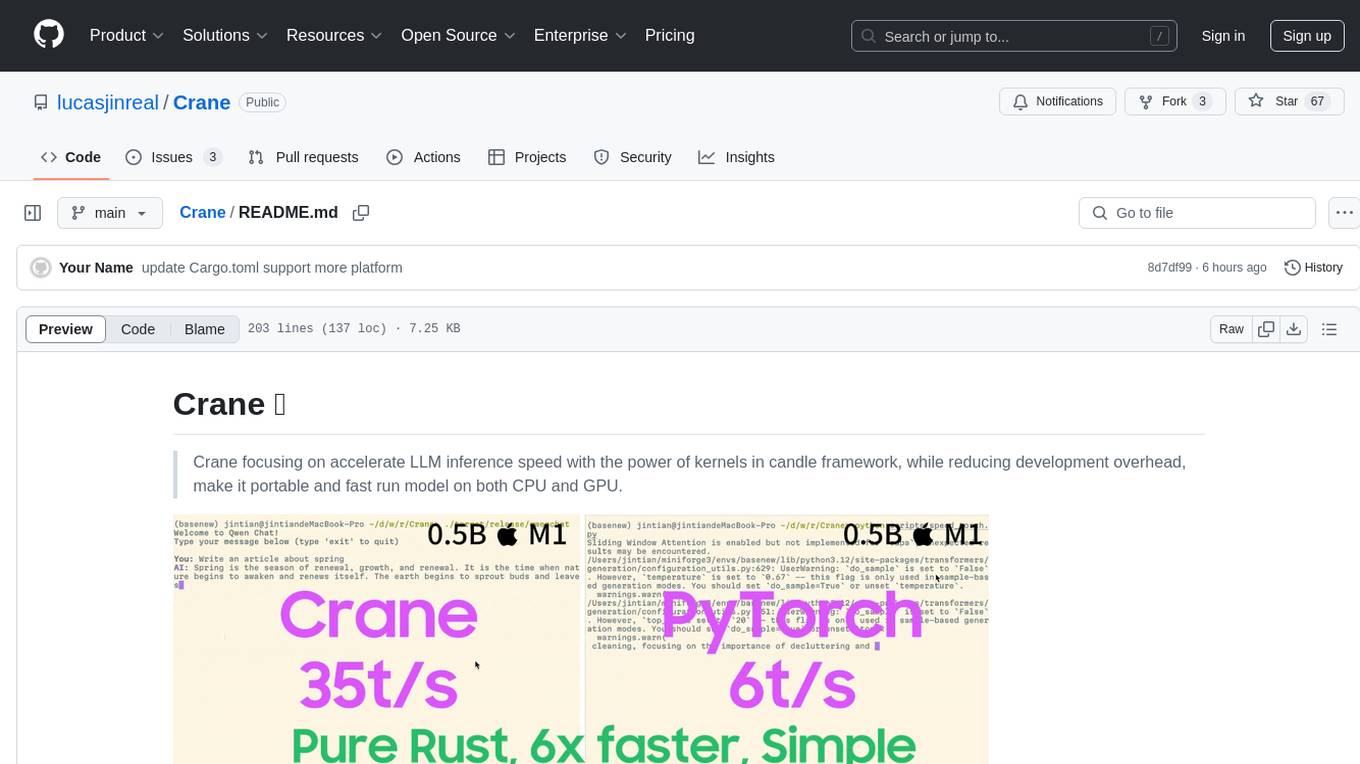
Crane
Crane is a high-performance inference framework leveraging Rust's Candle for maximum speed on CPU/GPU. It focuses on accelerating LLM inference speed with optimized kernels, reducing development overhead, and ensuring portability for running models on both CPU and GPU. Supported models include TTS systems like Spark-TTS and Orpheus-TTS, foundation models like Qwen2.5 series and basic LLMs, and multimodal models like Namo-R1 and Qwen2.5-VL. Key advantages of Crane include blazing-fast inference outperforming native PyTorch, Rust-powered to eliminate C++ complexity, Apple Silicon optimized for GPU acceleration via Metal, and hardware agnostic with a unified codebase for CPU/CUDA/Metal execution. Crane simplifies deployment with the ability to add new models with less than 100 lines of code in most cases.
FuzzyAI
The FuzzyAI Fuzzer is a powerful tool for automated LLM fuzzing, designed to help developers and security researchers identify jailbreaks and mitigate potential security vulnerabilities in their LLM APIs. It supports various fuzzing techniques, provides input generation capabilities, can be easily integrated into existing workflows, and offers an extensible architecture for customization and extension. The tool includes attacks like ArtPrompt, Taxonomy-based paraphrasing, Many-shot jailbreaking, Genetic algorithm, Hallucinations, DAN (Do Anything Now), WordGame, Crescendo, ActorAttack, Back To The Past, Please, Thought Experiment, and Default. It supports models from providers like Anthropic, OpenAI, Gemini, Azure, Bedrock, AI21, and Ollama, with the ability to add support for newer models. The tool also supports various cloud APIs and datasets for testing and experimentation.
spandrel
Spandrel is a library for loading and running pre-trained PyTorch models. It automatically detects the model architecture and hyperparameters from model files, and provides a unified interface for running models.
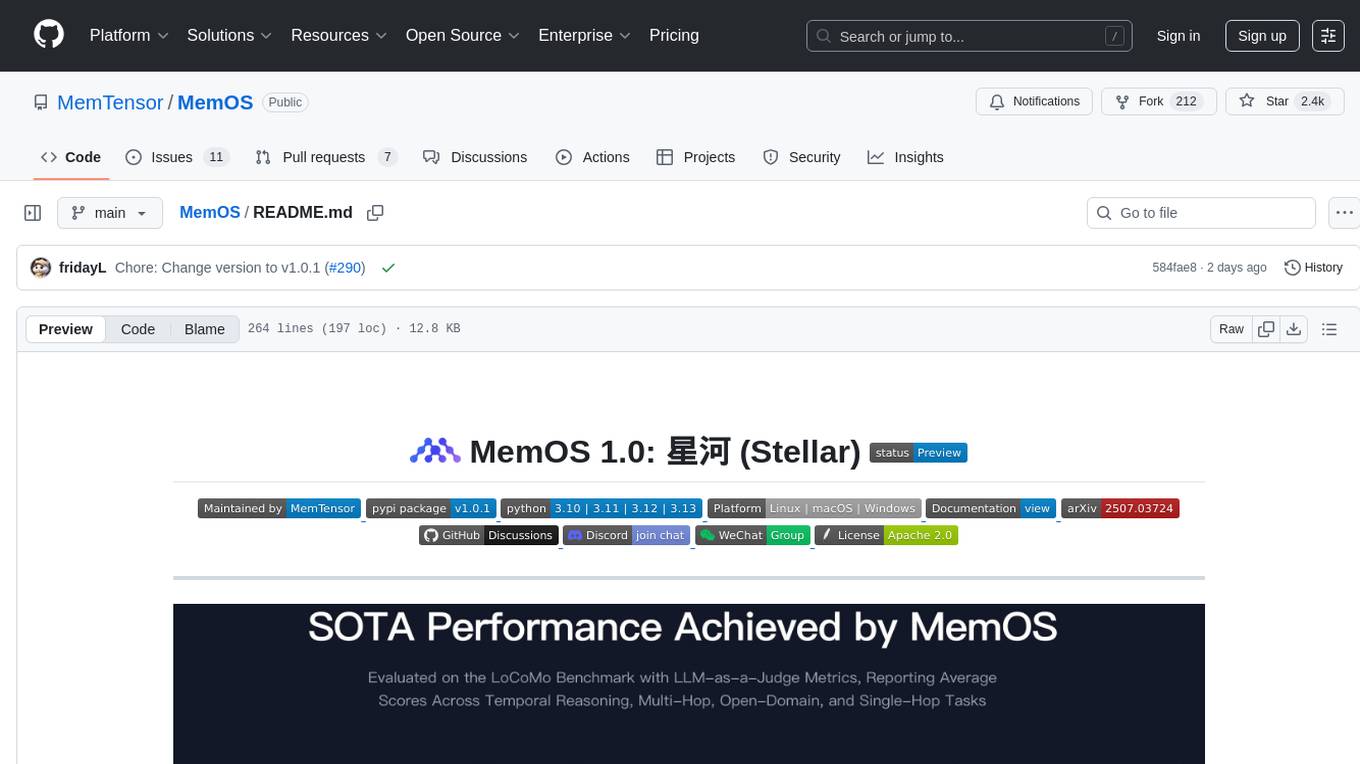
MemOS
MemOS is an operating system for Large Language Models (LLMs) that enhances them with long-term memory capabilities. It allows LLMs to store, retrieve, and manage information, enabling more context-aware, consistent, and personalized interactions. MemOS provides Memory-Augmented Generation (MAG) with a unified API for memory operations, a Modular Memory Architecture (MemCube) for easy integration and management of different memory types, and multiple memory types including Textual Memory, Activation Memory, and Parametric Memory. It is extensible, allowing users to customize memory modules, data sources, and LLM integrations. MemOS demonstrates significant improvements over baseline memory solutions in multiple reasoning tasks, with a notable improvement in temporal reasoning accuracy compared to the OpenAI baseline.

beeai-framework
BeeAI Framework is a versatile tool for building production-ready multi-agent systems. It offers flexibility in orchestrating agents, seamless integration with various models and tools, and production-grade controls for scaling. The framework supports Python and TypeScript libraries, enabling users to implement simple to complex multi-agent patterns, connect with AI services, and optimize token usage and resource management.

airunner
AI Runner is a multi-modal AI interface that allows users to run open-source large language models and AI image generators on their own hardware. The tool provides features such as voice-based chatbot conversations, text-to-speech, speech-to-text, vision-to-text, text generation with large language models, image generation capabilities, image manipulation tools, utility functions, and more. It aims to provide a stable and user-friendly experience with security updates, a new UI, and a streamlined installation process. The application is designed to run offline on users' hardware without relying on a web server, offering a smooth and responsive user experience.
fastRAG
fastRAG is a research framework designed to build and explore efficient retrieval-augmented generative models. It incorporates state-of-the-art Large Language Models (LLMs) and Information Retrieval to empower researchers and developers with a comprehensive tool-set for advancing retrieval augmented generation. The framework is optimized for Intel hardware, customizable, and includes key features such as optimized RAG pipelines, efficient components, and RAG-efficient components like ColBERT and Fusion-in-Decoder (FiD). fastRAG supports various unique components and backends for running LLMs, making it a versatile tool for research and development in the field of retrieval-augmented generation.
For similar tasks
X-AnyLabeling
X-AnyLabeling is a robust annotation tool that seamlessly incorporates an AI inference engine alongside an array of sophisticated features. Tailored for practical applications, it is committed to delivering comprehensive, industrial-grade solutions for image data engineers. This tool excels in swiftly and automatically executing annotations across diverse and intricate tasks.
file-organizer-2000
AI File Organizer 2000 is an Obsidian Plugin that uses AI to transcribe audio, annotate images, and automatically organize files by moving them to the most likely folders. It supports text, audio, and images, with upcoming local-first LLM support. Users can simply place unorganized files into the 'Inbox' folder for automatic organization. The tool renames and moves files quickly, providing a seamless file organization experience. Self-hosting is also possible by running the server and enabling the 'Self-hosted' option in the plugin settings. Join the community Discord server for more information and use the provided iOS shortcut for easy access on mobile devices.
LabelLLM
LabelLLM is an open-source data annotation platform designed to optimize the data annotation process for LLM development. It offers flexible configuration, multimodal data support, comprehensive task management, and AI-assisted annotation. Users can access a suite of annotation tools, enjoy a user-friendly experience, and enhance efficiency. The platform allows real-time monitoring of annotation progress and quality control, ensuring data integrity and timeliness.
awesome-open-data-annotation
At ZenML, we believe in the importance of annotation and labeling workflows in the machine learning lifecycle. This repository showcases a curated list of open-source data annotation and labeling tools that are actively maintained and fit for purpose. The tools cover various domains such as multi-modal, text, images, audio, video, time series, and other data types. Users can contribute to the list and discover tools for tasks like named entity recognition, data annotation for machine learning, image and video annotation, text classification, sequence labeling, object detection, and more. The repository aims to help users enhance their data-centric workflows by leveraging these tools.
anylabeling
AnyLabeling is a tool for effortless data labeling with AI support from YOLO and Segment Anything. It combines features from LabelImg and Labelme with an improved UI and auto-labeling capabilities. Users can annotate images with polygons, rectangles, circles, lines, and points, as well as perform auto-labeling using YOLOv5 and Segment Anything. The tool also supports text detection, recognition, and Key Information Extraction (KIE) labeling, with multiple language options available such as English, Vietnamese, and Chinese.
awesome-object-detection-datasets
This repository is a curated list of awesome public object detection and recognition datasets. It includes a wide range of datasets related to object detection and recognition tasks, such as general detection and recognition datasets, autonomous driving datasets, adverse weather datasets, person detection datasets, anti-UAV datasets, optical aerial imagery datasets, low-light image datasets, infrared image datasets, SAR image datasets, multispectral image datasets, 3D object detection datasets, vehicle-to-everything field datasets, super-resolution field datasets, and face detection and recognition datasets. The repository also provides information on tools for data annotation, data augmentation, and data management related to object detection tasks.

LabelQuick
LabelQuick_V2.0 is a fast image annotation tool designed and developed by the AI Horizon team. This version has been optimized and improved based on the previous version. It provides an intuitive interface and powerful annotation and segmentation functions to efficiently complete dataset annotation work. The tool supports video object tracking annotation, quick annotation by clicking, and various video operations. It introduces the SAM2 model for accurate and efficient object detection in video frames, reducing manual intervention and improving annotation quality. The tool is designed for Windows systems and requires a minimum of 6GB of memory.
VisioFirm
VisioFirm is an open-source, AI-powered image annotation tool designed to accelerate labeling for computer vision tasks like classification, object detection, oriented bounding boxes (OBB), segmentation and video annotation. Built for speed and simplicity, it leverages state-of-the-art models for semi-automated pre-annotations, allowing you to focus on refining rather than starting from scratch. Whether you're preparing datasets for YOLO, SAM, or custom models, VisioFirm streamlines your workflow with an intuitive web interface and powerful backend. Perfect for researchers, data scientists, and ML engineers handling large image datasets—get high-quality annotations in minutes, not hours!
For similar jobs

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

openvino
OpenVINO™ is an open-source toolkit for optimizing and deploying AI inference. It provides a common API to deliver inference solutions on various platforms, including CPU, GPU, NPU, and heterogeneous devices. OpenVINO™ supports pre-trained models from Open Model Zoo and popular frameworks like TensorFlow, PyTorch, and ONNX. Key components of OpenVINO™ include the OpenVINO™ Runtime, plugins for different hardware devices, frontends for reading models from native framework formats, and the OpenVINO Model Converter (OVC) for adjusting models for optimal execution on target devices.

peft
PEFT (Parameter-Efficient Fine-Tuning) is a collection of state-of-the-art methods that enable efficient adaptation of large pretrained models to various downstream applications. By only fine-tuning a small number of extra model parameters instead of all the model's parameters, PEFT significantly decreases the computational and storage costs while achieving performance comparable to fully fine-tuned models.

jetson-generative-ai-playground
This repo hosts tutorial documentation for running generative AI models on NVIDIA Jetson devices. The documentation is auto-generated and hosted on GitHub Pages using their CI/CD feature to automatically generate/update the HTML documentation site upon new commits.

emgucv
Emgu CV is a cross-platform .Net wrapper for the OpenCV image-processing library. It allows OpenCV functions to be called from .NET compatible languages. The wrapper can be compiled by Visual Studio, Unity, and "dotnet" command, and it can run on Windows, Mac OS, Linux, iOS, and Android.

MMStar
MMStar is an elite vision-indispensable multi-modal benchmark comprising 1,500 challenge samples meticulously selected by humans. It addresses two key issues in current LLM evaluation: the unnecessary use of visual content in many samples and the existence of unintentional data leakage in LLM and LVLM training. MMStar evaluates 6 core capabilities across 18 detailed axes, ensuring a balanced distribution of samples across all dimensions.

VLMEvalKit
VLMEvalKit is an open-source evaluation toolkit of large vision-language models (LVLMs). It enables one-command evaluation of LVLMs on various benchmarks, without the heavy workload of data preparation under multiple repositories. In VLMEvalKit, we adopt generation-based evaluation for all LVLMs, and provide the evaluation results obtained with both exact matching and LLM-based answer extraction.

llava-docker
This Docker image for LLaVA (Large Language and Vision Assistant) provides a convenient way to run LLaVA locally or on RunPod. LLaVA is a powerful AI tool that combines natural language processing and computer vision capabilities. With this Docker image, you can easily access LLaVA's functionalities for various tasks, including image captioning, visual question answering, text summarization, and more. The image comes pre-installed with LLaVA v1.2.0, Torch 2.1.2, xformers 0.0.23.post1, and other necessary dependencies. You can customize the model used by setting the MODEL environment variable. The image also includes a Jupyter Lab environment for interactive development and exploration. Overall, this Docker image offers a comprehensive and user-friendly platform for leveraging LLaVA's capabilities.