
VLMEvalKit
Open-source evaluation toolkit of large multi-modality models (LMMs), support 220+ LMMs, 80+ benchmarks
Stars: 3071

VLMEvalKit is an open-source evaluation toolkit of large vision-language models (LVLMs). It enables one-command evaluation of LVLMs on various benchmarks, without the heavy workload of data preparation under multiple repositories. In VLMEvalKit, we adopt generation-based evaluation for all LVLMs, and provide the evaluation results obtained with both exact matching and LLM-based answer extraction.
README:
A Toolkit for Evaluating Large Vision-Language Models.





🏆 OC Learderboard • 🏗️Quickstart • 📊Datasets & Models • 🛠️Development
🤗 HF Leaderboard • 🤗 Evaluation Records • 🤗 HF Video Leaderboard •
🔊 Discord • 📝 Report • 🎯Goal • 🖊️Citation
VLMEvalKit (the python package name is vlmeval) is an open-source evaluation toolkit of large vision-language models (LVLMs). It enables one-command evaluation of LVLMs on various benchmarks, without the heavy workload of data preparation under multiple repositories. In VLMEvalKit, we adopt generation-based evaluation for all LVLMs, and provide the evaluation results obtained with both exact matching and LLM-based answer extraction.
-
[2025-09-12] Major Update: Improved Handling for Models with Thinking Mode
A new feature in PR 1229 that improves support for models with thinking mode. VLMEvalKit now allows for the use of a custom
split_thinkingfunction. We strongly recommend this for models with thinking mode to ensure the accuracy of evaluation. To use this new functionality, please enable the following settings:SPLIT_THINK=True. By default, the function will parse content within<think>...</think>tags and store it in thethinkingkey of the output. For more advanced customization, you can also create asplit_thinkfunction for model. Please see the InternVL implementation for an example. -
[2025-09-12] Major Update: Improved Handling for Long Response(More than 16k/32k)
A new feature in PR 1229 that improves support for models with long response outputs. VLMEvalKit can now save prediction files in TSV format. Since individual cells in an
.xlsxfile are limited to 32,767 characters, we strongly recommend using this feature for models that generate long responses (e.g., exceeding 16k or 32k tokens) to prevent data truncation.. To use this new functionality, please enable the following settings:PRED_FORMAT=tsv. -
[2025-08-04] In PR 1175, we refine the
can_infer_optionandcan_infer_text, which increasingly route the evaluation to LLM choice extractors and empirically leads to slight performance improvement for MCQ benchmarks.
- [2025-07-07] Supported SeePhys, which is a full spectrum multimodal benchmark for evaluating physics reasoning across different knowledge levels. thanks to Quinn777 🔥🔥🔥
- [2025-07-02] Supported OvisU1, thanks to liyang-7 🔥🔥🔥
- [2025-06-16] Supported PhyX, a benchmark aiming to assess capacity for physics-grounded reasoning in visual scenarios. 🔥🔥🔥
-
[2025-05-24] To facilitate faster evaluations for large-scale or thinking models, VLMEvalKit supports multi-node distributed inference using LMDeploy (supports InternVL Series, QwenVL Series, LLaMa4) or VLLM(supports QwenVL Series, LLaMa4). You can activate this feature by adding the
use_lmdeployoruse_vllmflag to your custom model configuration in config.py . Leverage these tools to significantly speed up your evaluation workflows 🔥🔥🔥 - [2025-05-24] Supported Models: InternVL3 Series, Gemini-2.5-Pro, Kimi-VL, LLaMA4, NVILA, Qwen2.5-Omni, Phi4, SmolVLM2, Grok, SAIL-VL-1.5, WeThink-Qwen2.5VL-7B, Bailingmm, VLM-R1, Taichu-VLR. Supported Benchmarks: HLE-Bench, MMVP, MM-AlignBench, Creation-MMBench, MM-IFEval, OmniDocBench, OCR-Reasoning, EMMA, ChaXiv,MedXpertQA, Physics, MSEarthMCQ, MicroBench, MMSci, VGRP-Bench, wildDoc, TDBench, VisuLogic, CVBench, LEGO-Puzzles, Video-MMLU, QBench-Video, MME-CoT, VLM2Bench, VMCBench, MOAT, Spatial457 Benchmark. Please refer to VLMEvalKit Features for more details. Thanks to all contributors 🔥🔥🔥
- [2025-02-20] Supported Models: InternVL2.5 Series, Qwen2.5VL Series, QVQ-72B, Doubao-VL, Janus-Pro-7B, MiniCPM-o-2.6, InternVL2-MPO, LLaVA-CoT, Hunyuan-Standard-Vision, Ovis2, Valley, SAIL-VL, Ross, Long-VITA, EMU3, SmolVLM. Supported Benchmarks: MMMU-Pro, WeMath, 3DSRBench, LogicVista, VL-RewardBench, CC-OCR, CG-Bench, CMMMU, WorldSense. Thanks to all contributors 🔥🔥🔥
- [2024-12-11] Supported NaturalBench, a vision-centric VQA benchmark (NeurIPS'24) that challenges vision-language models with simple questions about natural imagery.
- [2024-12-02] Supported VisOnlyQA, a benchmark for evaluating the visual perception capabilities 🔥🔥🔥
- [2024-11-26] Supported Ovis1.6-Gemma2-27B, thanks to runninglsy 🔥🔥🔥
-
[2024-11-25] Create a new flag
VLMEVALKIT_USE_MODELSCOPE. By setting this environment variable, you can download the video benchmarks supported from modelscope 🔥🔥🔥
See [QuickStart | 快速开始] for a quick start guide.
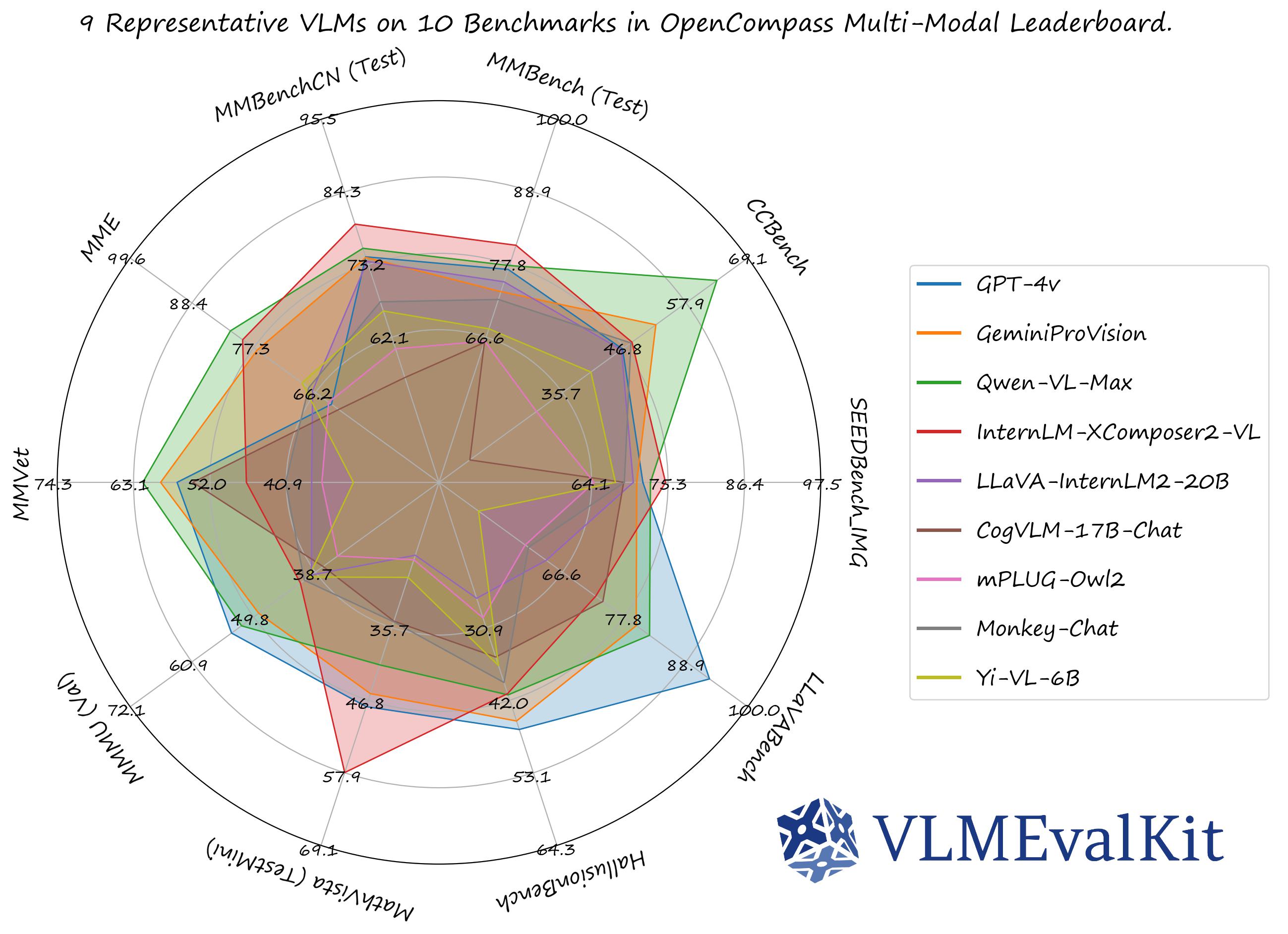
The performance numbers on our official multi-modal leaderboards can be downloaded from here!
OpenVLM Leaderboard: Download All DETAILED Results.
Check Supported Benchmarks Tab in VLMEvalKit Features to view all supported image & video benchmarks (70+).
Check Supported LMMs Tab in VLMEvalKit Features to view all supported LMMs, including commercial APIs, open-source models, and more (200+).
Transformers Version Recommendation:
Note that some VLMs may not be able to run under certain transformer versions, we recommend the following settings to evaluate each VLM:
-
Please use
transformers==4.33.0for:Qwen series,Monkey series,InternLM-XComposer Series,mPLUG-Owl2,OpenFlamingo v2,IDEFICS series,VisualGLM,MMAlaya,ShareCaptioner,MiniGPT-4 series,InstructBLIP series,PandaGPT,VXVERSE. -
Please use
transformers==4.36.2for:Moondream1. -
Please use
transformers==4.37.0for:LLaVA series,ShareGPT4V series,TransCore-M,LLaVA (XTuner),CogVLM Series,EMU2 Series,Yi-VL Series,MiniCPM-[V1/V2],OmniLMM-12B,DeepSeek-VL series,InternVL series,Cambrian Series,VILA Series,Llama-3-MixSenseV1_1,Parrot-7B,PLLaVA Series. -
Please use
transformers==4.40.0for:IDEFICS2,Bunny-Llama3,MiniCPM-Llama3-V2.5,360VL-70B,Phi-3-Vision,WeMM. -
Please use
transformers==4.42.0for:AKI. -
Please use
transformers==4.44.0for:Moondream2,H2OVL series. -
Please use
transformers==4.45.0for:Aria. -
Please use
transformers==latestfor:LLaVA-Next series,PaliGemma-3B,Chameleon series,Video-LLaVA-7B-HF,Ovis series,Mantis series,MiniCPM-V2.6,OmChat-v2.0-13B-sinlge-beta,Idefics-3,GLM-4v-9B,VideoChat2-HD,RBDash_72b,Llama-3.2 series,Kosmos series.
Torchvision Version Recommendation:
Note that some VLMs may not be able to run under certain torchvision versions, we recommend the following settings to evaluate each VLM:
-
Please use
torchvision>=0.16for:Moondream seriesandAria
Flash-attn Version Recommendation:
Note that some VLMs may not be able to run under certain flash-attention versions, we recommend the following settings to evaluate each VLM:
-
Please use
pip install flash-attn --no-build-isolationfor:Aria
# Demo
from vlmeval.config import supported_VLM
model = supported_VLM['idefics_9b_instruct']()
# Forward Single Image
ret = model.generate(['assets/apple.jpg', 'What is in this image?'])
print(ret) # The image features a red apple with a leaf on it.
# Forward Multiple Images
ret = model.generate(['assets/apple.jpg', 'assets/apple.jpg', 'How many apples are there in the provided images? '])
print(ret) # There are two apples in the provided images.To develop custom benchmarks, VLMs, or simply contribute other codes to VLMEvalKit, please refer to [Development_Guide | 开发指南].
Call for contributions
To promote the contribution from the community and share the corresponding credit (in the next report update):
- All Contributions will be acknowledged in the report.
- Contributors with 3 or more major contributions (implementing an MLLM, benchmark, or major feature) can join the author list of VLMEvalKit Technical Report on ArXiv. Eligible contributors can create an issue or dm kennyutc in VLMEvalKit Discord Channel.
Here is a contributor list we curated based on the records.
The codebase is designed to:
- Provide an easy-to-use, opensource evaluation toolkit to make it convenient for researchers & developers to evaluate existing LVLMs and make evaluation results easy to reproduce.
- Make it easy for VLM developers to evaluate their own models. To evaluate the VLM on multiple supported benchmarks, one just need to implement a single
generate_inner()function, all other workloads (data downloading, data preprocessing, prediction inference, metric calculation) are handled by the codebase.
The codebase is not designed to:
- Reproduce the exact accuracy number reported in the original papers of all 3rd party benchmarks. The reason can be two-fold:
- VLMEvalKit uses generation-based evaluation for all VLMs (and optionally with LLM-based answer extraction). Meanwhile, some benchmarks may use different approaches (SEEDBench uses PPL-based evaluation, eg.). For those benchmarks, we compare both scores in the corresponding result. We encourage developers to support other evaluation paradigms in the codebase.
- By default, we use the same prompt template for all VLMs to evaluate on a benchmark. Meanwhile, some VLMs may have their specific prompt templates (some may not covered by the codebase at this time). We encourage VLM developers to implement their own prompt template in VLMEvalKit, if that is not covered currently. That will help to improve the reproducibility.
If you find this work helpful, please consider to star🌟 this repo. Thanks for your support!
If you use VLMEvalKit in your research or wish to refer to published OpenSource evaluation results, please use the following BibTeX entry and the BibTex entry corresponding to the specific VLM / benchmark you used.
@inproceedings{duan2024vlmevalkit,
title={Vlmevalkit: An open-source toolkit for evaluating large multi-modality models},
author={Duan, Haodong and Yang, Junming and Qiao, Yuxuan and Fang, Xinyu and Chen, Lin and Liu, Yuan and Dong, Xiaoyi and Zang, Yuhang and Zhang, Pan and Wang, Jiaqi and others},
booktitle={Proceedings of the 32nd ACM International Conference on Multimedia},
pages={11198--11201},
year={2024}
}For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for VLMEvalKit
Similar Open Source Tools
VLMEvalKit
VLMEvalKit is an open-source evaluation toolkit of large vision-language models (LVLMs). It enables one-command evaluation of LVLMs on various benchmarks, without the heavy workload of data preparation under multiple repositories. In VLMEvalKit, we adopt generation-based evaluation for all LVLMs, and provide the evaluation results obtained with both exact matching and LLM-based answer extraction.
eval-assist
EvalAssist is an LLM-as-a-Judge framework built on top of the Unitxt open source evaluation library for large language models. It provides users with a convenient way of iteratively testing and refining LLM-as-a-judge criteria, supporting both direct (rubric-based) and pairwise assessment paradigms. EvalAssist is model-agnostic, supporting a rich set of off-the-shelf judge models that can be extended. Users can auto-generate a Notebook with Unitxt code to run bulk evaluations and save their own test cases. The tool is designed for evaluating text data using language models.

Fast-dLLM
Fast-DLLM is a diffusion-based Large Language Model (LLM) inference acceleration framework that supports efficient inference for models like Dream and LLaDA. It offers fast inference support, multiple optimization strategies, code generation, evaluation capabilities, and an interactive chat interface. Key features include Key-Value Cache for Block-Wise Decoding, Confidence-Aware Parallel Decoding, and overall performance improvements. The project structure includes directories for Dream and LLaDA model-related code, with installation and usage instructions provided for using the LLaDA and Dream models.

PaddleNLP
PaddleNLP is an easy-to-use and high-performance NLP library. It aggregates high-quality pre-trained models in the industry and provides out-of-the-box development experience, covering a model library for multiple NLP scenarios with industry practice examples to meet developers' flexible customization needs.
Awesome-RAG
Awesome-RAG is a repository that lists recent developments in Retrieval-Augmented Generation (RAG) for large language models (LLM). It includes accepted papers, evaluation datasets, latest news, and papers from various conferences like NIPS, EMNLP, ACL, ICML, and ICLR. The repository is continuously updated and aims to build a general framework for RAG. Researchers are encouraged to submit pull requests to update information in their papers. The repository covers a wide range of topics related to RAG, including knowledge-enhanced generation, contrastive reasoning, self-alignment, mobile agents, and more.
FastGPT
FastGPT is a knowledge base Q&A system based on the LLM large language model, providing out-of-the-box data processing, model calling and other capabilities. At the same time, you can use Flow to visually arrange workflows to achieve complex Q&A scenarios!

bisheng
Bisheng is a leading open-source **large model application development platform** that empowers and accelerates the development and deployment of large model applications, helping users enter the next generation of application development with the best possible experience.
llm_recipes
This repository showcases the author's experiments with Large Language Models (LLMs) for text generation tasks. It includes dataset preparation, preprocessing, model fine-tuning using libraries such as Axolotl and HuggingFace, and model evaluation.

lemonai
LemonAI is a versatile machine learning library designed to simplify the process of building and deploying AI models. It provides a wide range of tools and algorithms for data preprocessing, model training, and evaluation. With LemonAI, users can easily experiment with different machine learning techniques and optimize their models for various tasks. The library is well-documented and beginner-friendly, making it suitable for both novice and experienced data scientists. LemonAI aims to streamline the development of AI applications and empower users to create innovative solutions using state-of-the-art machine learning methods.

VisionLLM
VisionLLM is a series of large language models designed for vision-centric tasks. The latest version, VisionLLM v2, is a generalist multimodal model that supports hundreds of vision-language tasks, including visual understanding, perception, and generation.
LMForge-End-to-End-LLMOps-Platform-for-Multi-Model-Agents
LMForge is an end-to-end LLMOps platform designed for multi-model agents. It provides a comprehensive solution for managing and deploying large language models efficiently. The platform offers tools for training, fine-tuning, and deploying various types of language models, enabling users to streamline the development and deployment process. With LMForge, users can easily experiment with different model architectures, optimize hyperparameters, and scale their models to meet specific requirements. The platform also includes features for monitoring model performance, managing datasets, and collaborating with team members, making it a versatile tool for researchers and developers working with language models.

God-Level-AI
A drill of scientific methods, processes, algorithms, and systems to build stories & models. An in-depth learning resource for humans. This repository is designed for individuals aiming to excel in the field of Data and AI, providing video sessions and text content for learning. It caters to those in leadership positions, professionals, and students, emphasizing the need for dedicated effort to achieve excellence in the tech field. The content covers various topics with a focus on practical application.

pdr_ai_v2
pdr_ai_v2 is a Python library for implementing machine learning algorithms and models. It provides a wide range of tools and functionalities for data preprocessing, model training, evaluation, and deployment. The library is designed to be user-friendly and efficient, making it suitable for both beginners and experienced data scientists. With pdr_ai_v2, users can easily build and deploy machine learning models for various applications, such as classification, regression, clustering, and more.

Main
This repository contains material related to the new book _Synthetic Data and Generative AI_ by the author, including code for NoGAN, DeepResampling, and NoGAN_Hellinger. NoGAN is a tabular data synthesizer that outperforms GenAI methods in terms of speed and results, utilizing state-of-the-art quality metrics. DeepResampling is a fast NoGAN based on resampling and Bayesian Models with hyperparameter auto-tuning. NoGAN_Hellinger combines NoGAN and DeepResampling with the Hellinger model evaluation metric.
minions
Minions is a communication protocol that enables small on-device models to collaborate with frontier models in the cloud. By only reading long contexts locally, it reduces cloud costs with minimal or no quality degradation. The repository provides a demonstration of the protocol.
ByteMLPerf
ByteMLPerf is an AI Accelerator Benchmark that focuses on evaluating AI Accelerators from a practical production perspective, including the ease of use and versatility of software and hardware. Byte MLPerf has the following characteristics: - Models and runtime environments are more closely aligned with practical business use cases. - For ASIC hardware evaluation, besides evaluate performance and accuracy, it also measure metrics like compiler usability and coverage. - Performance and accuracy results obtained from testing on the open Model Zoo serve as reference metrics for evaluating ASIC hardware integration.
For similar tasks
VLMEvalKit
VLMEvalKit is an open-source evaluation toolkit of large vision-language models (LVLMs). It enables one-command evaluation of LVLMs on various benchmarks, without the heavy workload of data preparation under multiple repositories. In VLMEvalKit, we adopt generation-based evaluation for all LVLMs, and provide the evaluation results obtained with both exact matching and LLM-based answer extraction.
For similar jobs

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

openvino
OpenVINO™ is an open-source toolkit for optimizing and deploying AI inference. It provides a common API to deliver inference solutions on various platforms, including CPU, GPU, NPU, and heterogeneous devices. OpenVINO™ supports pre-trained models from Open Model Zoo and popular frameworks like TensorFlow, PyTorch, and ONNX. Key components of OpenVINO™ include the OpenVINO™ Runtime, plugins for different hardware devices, frontends for reading models from native framework formats, and the OpenVINO Model Converter (OVC) for adjusting models for optimal execution on target devices.

peft
PEFT (Parameter-Efficient Fine-Tuning) is a collection of state-of-the-art methods that enable efficient adaptation of large pretrained models to various downstream applications. By only fine-tuning a small number of extra model parameters instead of all the model's parameters, PEFT significantly decreases the computational and storage costs while achieving performance comparable to fully fine-tuned models.

jetson-generative-ai-playground
This repo hosts tutorial documentation for running generative AI models on NVIDIA Jetson devices. The documentation is auto-generated and hosted on GitHub Pages using their CI/CD feature to automatically generate/update the HTML documentation site upon new commits.

emgucv
Emgu CV is a cross-platform .Net wrapper for the OpenCV image-processing library. It allows OpenCV functions to be called from .NET compatible languages. The wrapper can be compiled by Visual Studio, Unity, and "dotnet" command, and it can run on Windows, Mac OS, Linux, iOS, and Android.

MMStar
MMStar is an elite vision-indispensable multi-modal benchmark comprising 1,500 challenge samples meticulously selected by humans. It addresses two key issues in current LLM evaluation: the unnecessary use of visual content in many samples and the existence of unintentional data leakage in LLM and LVLM training. MMStar evaluates 6 core capabilities across 18 detailed axes, ensuring a balanced distribution of samples across all dimensions.
VLMEvalKit
VLMEvalKit is an open-source evaluation toolkit of large vision-language models (LVLMs). It enables one-command evaluation of LVLMs on various benchmarks, without the heavy workload of data preparation under multiple repositories. In VLMEvalKit, we adopt generation-based evaluation for all LVLMs, and provide the evaluation results obtained with both exact matching and LLM-based answer extraction.

llava-docker
This Docker image for LLaVA (Large Language and Vision Assistant) provides a convenient way to run LLaVA locally or on RunPod. LLaVA is a powerful AI tool that combines natural language processing and computer vision capabilities. With this Docker image, you can easily access LLaVA's functionalities for various tasks, including image captioning, visual question answering, text summarization, and more. The image comes pre-installed with LLaVA v1.2.0, Torch 2.1.2, xformers 0.0.23.post1, and other necessary dependencies. You can customize the model used by setting the MODEL environment variable. The image also includes a Jupyter Lab environment for interactive development and exploration. Overall, this Docker image offers a comprehensive and user-friendly platform for leveraging LLaVA's capabilities.