
SageAttention
Quantized Attention achieves speedup of 2-5x and 3-11x compared to FlashAttention and xformers, without lossing end-to-end metrics across language, image, and video models.
Stars: 2407
SageAttention is an official implementation of an accurate 8-bit attention mechanism for plug-and-play inference acceleration. It is optimized for RTX4090 and RTX3090 GPUs, providing performance improvements for specific GPU architectures. The tool offers a technique called 'smooth_k' to ensure accuracy in processing FP16/BF16 data. Users can easily replace 'scaled_dot_product_attention' with SageAttention for faster video processing.
README:
This repository provides the official implementation of SageAttention, SageAttention2, and SageAttention2++, which achieve surprising speedup on most GPUs without lossing accuracy across all models in a plug-and-play way.
SageAttention: Accurate 8-Bit Attention for Plug-and-play Inference Acceleration
Paper: https://arxiv.org/abs/2410.02367
Jintao Zhang, Jia Wei, Haofeng Huang, Pengle Zhang, Jun Zhu, Jianfei Chen
SageAttention2: Efficient Attention with Thorough Outlier Smoothing and Per-thread INT4 Quantization
Paper: https://arxiv.org/abs/2411.10958
Jintao Zhang, Haofeng Huang, Pengle Zhang, Jia Wei, Jun Zhu, Jianfei Chen
SageAttention3: Microscaling FP4 Attention for Inference and An Exploration of 8-Bit Training
Paper: https://arxiv.org/abs/2505.11594
Jintao Zhang, Jia Wei, Pengle Zhang, Xiaoming Xu, Haofeng Huang, Haoxu Wang, Kai Jiang, Jun Zhu, Jianfei Chen
 Note: SageAttention2++ achieves higher speed while maintaining the same accuracy performance.
Note: SageAttention2++ achieves higher speed while maintaining the same accuracy performance.
- Optmized kernels for Ampere, Ada and Hopper GPUs.
- INT8 quantization and smoothing for $QK^\top$ with support for varying granularities.
- FP8 quantization for $PV$, and FP16 accumulator for FP8/FP16 $PV$.
- Two-level accumulation strategy for $PV$ to improve accuracy in FP8 MMA and WGMMA.
- Support
torch.compilewith non-cudagraphs mode and distributed inference.
- [2025-07-21]: The early access to SageAttention3 code is available at HuggingFace, where you'll need to fill out a form in detail and await approval.
- [2025-07-01]: The code of SageAttention2++ is released in this repository. We would still greatly appreciate it if you could take a moment to fill out the Form in Huggingface. Thank you very much!


- [2025-06-19]: Sparse SageAttention1 API and Sparse SageAttention2 API can compute attention with any block sparse pattern very fast.
- [2025-05-02]: 🎉SageAttention2 and SpargeAttn are accepted by ICML 2025!
- [2025-02-25]: 🔥 We release SpargeAttn, a sparse attention based on SageAttention2, which could acclerate any model without training.
- [2025-02-15]: 🔥 The compilation code is updated to support RTX5090! On RTX5090, SageAttention reaches 560T, 2.7x faster than FlashAttention2!
- [2025-01-28]: 🔥⚡SageAttention is now available on Hopper GPUs (H100, H800, H20)! It matches the speed of FlashAttention3-FP8 but offers much better accuracy!
| FlashAttention2 | FlashAttention3 | FlashAttention3-FP8 | SageAttention |
|---|---|---|---|
 |
 |
 |
 |
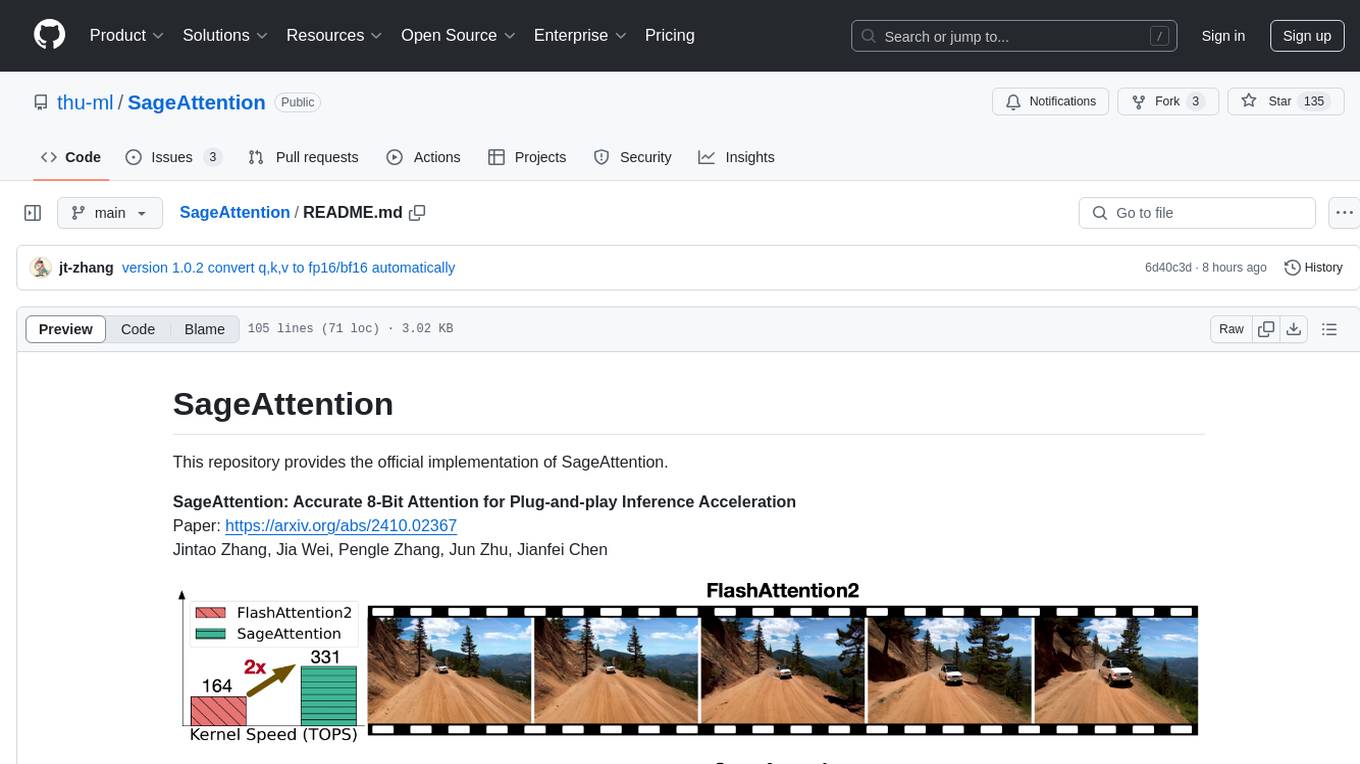
| 25'34'' | 17'32'' | 12'14'' | 12'07'' |
Results for CogVideoX1.5-5B on NVIDIA H20 GPU


-
[2025-01-24]: 🎉SageAttention is accepted by ICLR 2025!
-
[2024-12-20]: 🔥Update the SageAttention2 Paper.
-
[2024-12-20]: 🔥Release SageAttention 2.0.1 Beta! In this version, we introduce a new feature: per-thread quantization, which offers finer granularity while maintaining hardware efficiency.
-
[2024-11-21]: 🔥SageAttention 2.0.0 beta is released! Now SageAttention has measured speedup on L20, L40, A100, A800, and A6000, RTX3090 and RTX4090.
-
[2024-11-12]: Support for
sageattn_varlenis available now. -
[2024-11-11]: Support for different sequence lengths between
qandk,v,(batch_size, head_num, seq_len, head_dim)or(batch_size, seq_len, head_num, head_dim)input shapes, andgroup-query attentionis available now.
-
python>=3.9,torch>=2.3.0,triton>=3.0.0
-
CUDA:-
>=12.8for Blackwell or SageAttention2++ -
>=12.4for fp8 support on Ada -
>=12.3for fp8 support on Hopper -
>=12.0for Ampere
-
-
flash-attnfor benchmarking
For SageAttention V1 in Triton (slower than SageAttention V2/V2++/V3), refer to SageAttention-1 and install using pip: pip install sageattention==1.0.6
To use SageAttention 2.2.0 (containing SageAttention2++), please compile from source:
git clone https://github.com/thu-ml/SageAttention.git
cd SageAttention
export EXT_PARALLEL=4 NVCC_APPEND_FLAGS="--threads 8" MAX_JOBS=32 # parallel compiling (Optional)
python setup.py install # or pip install -e .
To benchmark the speed against FlashAttention3, please compile FlashAttention3 from source:
git clone https://github.com/Dao-AILab/flash-attention.git --recursive
git checkout b7d29fb3b79f0b78b1c369a52aaa6628dabfb0d7 # 2.7.2 release
cd hopper
python setup.py install
from sageattention import sageattn
attn_output = sageattn(q, k, v, tensor_layout="HND", is_causal=False)-
q, k, vare FP16/BF16 dtype with the shape(batch_size, head_num, seq_len, head_dim)using defaulttensor_layout="HND". For shape(batch_size, seq_len, head_num, head_dim), settensor_layout="NHD". -
is_causaldetermines the use of a causal mask.
-
sageattn: Automatically selects the optimal kernel based on the GPU to achieve a good performance-accuracy trade-off. -
sageattn_qk_int8_pv_fp16_triton: INT8 quantization for $QK^\top$ and FP16 for $PV$ using Triton backend. -
sageattn_qk_int8_pv_fp16_cuda: INT8 quantization for $QK^\top$ and FP16 for $PV$ using CUDA backend. -
sageattn_qk_int8_pv_fp8_cuda: INT8 quantization for $QK^\top$ and FP8 for $PV$ using CUDA backend. (Note that settingpv_accum_dtype=fp32+fp16corresponds to SageAttention2++.) -
sageattn_qk_int8_pv_fp8_cuda_sm90: INT8 quantization for $QK^\top$ and FP8 for $PV$ using CUDA backend, specifically optimized for Hopper GPUs. -
sageattn_varlen: INT8 quantization for $QK^\top$ and FP16 for $PV$ using Triton backend. Support for varying sequence lengths within the same batch.
For optimal speed and accuracy performance on custom devices and models, we strongly recommend referring to the this file for detailed guidance.
Note: Support for different sequence lengths between
qandk,vandgroup-query attentionis available.
We can replace scaled_dot_product_attention easily.
We will take CogvideoX as an example:
Add the following codes and run
import torch.nn.functional as F
+ from sageattention import sageattn
+ F.scaled_dot_product_attention = sageattn
Specifically,
cd example
python cogvideox-2b.py --compile --attention_type sageYou can get a lossless video in ./example faster than by using python cogvideox-2b.py --compile. More examples and guidance can be found under the example/ directory.
Note: Not all models works with
F.scaled_dot_product_attention = sageattn. Technically, you should replace the original Attention by modifying theAttention Classof the target model. For image and video models, we suggest only replacing the attention in DiT (seeexample/mochi.pyfor detail).
We provide a benchmarking script to compare the speed of different kernels including SageAttention, FlashAttention2 and FlashAttention3. Please refer to the benchmark/ directory for more details.
8+8 means the kernel with INT8 quantization for $QK^\top$ and FP8 quantization for $PV$. 8+16 uses FP16 with FP16 accumulator for $PV$.




Note: The TOPS results refer only to the Attention Kernel, excluding the quantization and smoothing.




 Note: SageAttention2++ achieves higher speed.
Note: SageAttention2++ achieves higher speed.
If you use this code or find our work valuable, please cite:
@inproceedings{zhang2025sageattention,
title={SageAttention: Accurate 8-Bit Attention for Plug-and-play Inference Acceleration},
author={Zhang, Jintao and Wei, Jia and Zhang, Pengle and Zhu, Jun and Chen, Jianfei},
booktitle={International Conference on Learning Representations (ICLR)},
year={2025}
}
@inproceedings{zhang2024sageattention2,
title={Sageattention2: Efficient attention with thorough outlier smoothing and per-thread int4 quantization},
author={Zhang, Jintao and Huang, Haofeng and Zhang, Pengle and Wei, Jia and Zhu, Jun and Chen, Jianfei},
booktitle={International Conference on Machine Learning (ICML)},
year={2025}
}
@article{zhang2025sageattention2++,
title={Sageattention2++: A more efficient implementation of sageattention2},
author={Zhang, Jintao and Xu, Xiaoming and Wei, Jia and Huang, Haofeng and Zhang, Pengle and Xiang, Chendong and Zhu, Jun and Chen, Jianfei},
journal={arXiv preprint arXiv:2505.21136},
year={2025}
}
@article{zhang2025sageattention3,
title={SageAttention3: Microscaling FP4 Attention for Inference and An Exploration of 8-Bit Training},
author={Zhang, Jintao and Wei, Jia and Zhang, Pengle and Xu, Xiaoming and Huang, Haofeng and Wang, Haoxu and Jiang, Kai and Zhu, Jun and Chen, Jianfei},
journal={arXiv preprint arXiv:2505.11594},
year={2025}
}
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for SageAttention
Similar Open Source Tools
SageAttention
SageAttention is an official implementation of an accurate 8-bit attention mechanism for plug-and-play inference acceleration. It is optimized for RTX4090 and RTX3090 GPUs, providing performance improvements for specific GPU architectures. The tool offers a technique called 'smooth_k' to ensure accuracy in processing FP16/BF16 data. Users can easily replace 'scaled_dot_product_attention' with SageAttention for faster video processing.
SpargeAttn
SpargeAttn is an official implementation designed for accelerating any model inference by providing accurate sparse attention. It offers a significant speedup in model performance while maintaining quality. The tool is based on SageAttention and SageAttention2, providing options for different levels of optimization. Users can easily install the package and utilize the available APIs for their specific needs. SpargeAttn is particularly useful for tasks requiring efficient attention mechanisms in deep learning models.
LLM-as-HH
LLM-as-HH is a codebase that accompanies the paper ReEvo: Large Language Models as Hyper-Heuristics with Reflective Evolution. It introduces Language Hyper-Heuristics (LHHs) that leverage LLMs for heuristic generation with minimal manual intervention and open-ended heuristic spaces. Reflective Evolution (ReEvo) is presented as a searching framework that emulates the reflective design approach of human experts while surpassing human capabilities with scalable LLM inference, Internet-scale domain knowledge, and powerful evolutionary search. The tool can improve various algorithms on problems like Traveling Salesman Problem, Capacitated Vehicle Routing Problem, Orienteering Problem, Multiple Knapsack Problems, Bin Packing Problem, and Decap Placement Problem in both black-box and white-box settings.

pgvecto.rs
pgvecto.rs is a Postgres extension written in Rust that provides vector similarity search functions. It offers ultra-low-latency, high-precision vector search capabilities, including sparse vector search and full-text search. With complete SQL support, async indexing, and easy data management, it simplifies data handling. The extension supports various data types like FP16/INT8, binary vectors, and Matryoshka embeddings. It ensures system performance with production-ready features, high availability, and resource efficiency. Security and permissions are managed through easy access control. The tool allows users to create tables with vector columns, insert vector data, and calculate distances between vectors using different operators. It also supports half-precision floating-point numbers for better performance and memory usage optimization.
zo2
ZO2 (Zeroth-Order Offloading) is an innovative framework designed to enhance the fine-tuning of large language models (LLMs) using zeroth-order (ZO) optimization techniques and advanced offloading technologies. It is tailored for setups with limited GPU memory, enabling the fine-tuning of models with over 175 billion parameters on single GPUs with as little as 18GB of memory. ZO2 optimizes CPU offloading, incorporates dynamic scheduling, and has the capability to handle very large models efficiently without extra time costs or accuracy losses.
wanda
Official PyTorch implementation of Wanda (Pruning by Weights and Activations), a simple and effective pruning approach for large language models. The pruning approach removes weights on a per-output basis, by the product of weight magnitudes and input activation norms. The repository provides support for various features such as LLaMA-2, ablation study on OBS weight update, zero-shot evaluation, and speedup evaluation. Users can replicate main results from the paper using provided bash commands. The tool aims to enhance the efficiency and performance of language models through structured and unstructured sparsity techniques.

curator
Bespoke Curator is an open-source tool for data curation and structured data extraction. It provides a Python library for generating synthetic data at scale, with features like programmability, performance optimization, caching, and integration with HuggingFace Datasets. The tool includes a Curator Viewer for dataset visualization and offers a rich set of functionalities for creating and refining data generation strategies.

VITA
VITA is an open-source interactive omni multimodal Large Language Model (LLM) capable of processing video, image, text, and audio inputs simultaneously. It stands out with features like Omni Multimodal Understanding, Non-awakening Interaction, and Audio Interrupt Interaction. VITA can respond to user queries without a wake-up word, track and filter external queries in real-time, and handle various query inputs effectively. The model utilizes state tokens and a duplex scheme to enhance the multimodal interactive experience.
open-unlearning
OpenUnlearning is an easily extensible framework that unifies LLM unlearning evaluation benchmarks. It provides efficient implementations of TOFU and MUSE unlearning benchmarks, supporting 5 unlearning methods, 3+ datasets, 6+ evaluation metrics, and 7+ LLMs. Users can easily extend the framework to incorporate more variants, collaborate by adding new benchmarks, unlearning methods, datasets, and evaluation metrics, and drive progress in the field.

chat
deco.chat is an open-source foundation for building AI-native software, providing developers, engineers, and AI enthusiasts with robust tools to rapidly prototype, develop, and deploy AI-powered applications. It empowers Vibecoders to prototype ideas and Agentic engineers to deploy scalable, secure, and sustainable production systems. The core capabilities include an open-source runtime for composing tools and workflows, MCP Mesh for secure integration of models and APIs, a unified TypeScript stack for backend logic and custom frontends, global modular infrastructure built on Cloudflare, and a visual workspace for building agents and orchestrating everything in code.
speech-to-speech
This repository implements a speech-to-speech cascaded pipeline with consecutive parts including Voice Activity Detection (VAD), Speech to Text (STT), Language Model (LM), and Text to Speech (TTS). It aims to provide a fully open and modular approach by leveraging models available on the Transformers library via the Hugging Face hub. The code is designed for easy modification, with each component implemented as a class. Users can run the pipeline either on a server/client approach or locally, with detailed setup and usage instructions provided in the readme.

WordLlama
WordLlama is a fast, lightweight NLP toolkit optimized for CPU hardware. It recycles components from large language models to create efficient word representations. It offers features like Matryoshka Representations, low resource requirements, binarization, and numpy-only inference. The tool is suitable for tasks like semantic matching, fuzzy deduplication, ranking, and clustering, making it a good option for NLP-lite tasks and exploratory analysis.

VLM-R1
VLM-R1 is a stable and generalizable R1-style Large Vision-Language Model proposed for Referring Expression Comprehension (REC) task. It compares R1 and SFT approaches, showing R1 model's steady improvement on out-of-domain test data. The project includes setup instructions, training steps for GRPO and SFT models, support for user data loading, and evaluation process. Acknowledgements to various open-source projects and resources are mentioned. The project aims to provide a reliable and versatile solution for vision-language tasks.

graphiti
Graphiti is a framework for building and querying temporally-aware knowledge graphs, tailored for AI agents in dynamic environments. It continuously integrates user interactions, structured and unstructured data, and external information into a coherent, queryable graph. The framework supports incremental data updates, efficient retrieval, and precise historical queries without complete graph recomputation, making it suitable for developing interactive, context-aware AI applications.
next-money
Next Money Stripe Starter is a SaaS Starter project that empowers your next project with a stack of Next.js, Prisma, Supabase, Clerk Auth, Resend, React Email, Shadcn/ui, and Stripe. It seamlessly integrates these technologies to accelerate your development and SaaS journey. The project includes frameworks, platforms, UI components, hooks and utilities, code quality tools, and miscellaneous features to enhance the development experience. Created by @koyaguo in 2023 and released under the MIT license.

HuixiangDou
HuixiangDou is a **group chat** assistant based on LLM (Large Language Model). Advantages: 1. Design a two-stage pipeline of rejection and response to cope with group chat scenario, answer user questions without message flooding, see arxiv2401.08772 2. Low cost, requiring only 1.5GB memory and no need for training 3. Offers a complete suite of Web, Android, and pipeline source code, which is industrial-grade and commercially viable Check out the scenes in which HuixiangDou are running and join WeChat Group to try AI assistant inside. If this helps you, please give it a star ⭐
For similar tasks

AutoGPTQ
AutoGPTQ is an easy-to-use LLM quantization package with user-friendly APIs, based on GPTQ algorithm (weight-only quantization). It provides a simple and efficient way to quantize large language models (LLMs) to reduce their size and computational cost while maintaining their performance. AutoGPTQ supports a wide range of LLM models, including GPT-2, GPT-J, OPT, and BLOOM. It also supports various evaluation tasks, such as language modeling, sequence classification, and text summarization. With AutoGPTQ, users can easily quantize their LLM models and deploy them on resource-constrained devices, such as mobile phones and embedded systems.

Qwen-TensorRT-LLM
Qwen-TensorRT-LLM is a project developed for the NVIDIA TensorRT Hackathon 2023, focusing on accelerating inference for the Qwen-7B-Chat model using TRT-LLM. The project offers various functionalities such as FP16/BF16 support, INT8 and INT4 quantization options, Tensor Parallel for multi-GPU parallelism, web demo setup with gradio, Triton API deployment for maximum throughput/concurrency, fastapi integration for openai requests, CLI interaction, and langchain support. It supports models like qwen2, qwen, and qwen-vl for both base and chat models. The project also provides tutorials on Bilibili and blogs for adapting Qwen models in NVIDIA TensorRT-LLM, along with hardware requirements and quick start guides for different model types and quantization methods.

stable-diffusion.cpp
The stable-diffusion.cpp repository provides an implementation for inferring stable diffusion in pure C/C++. It offers features such as support for different versions of stable diffusion, lightweight and dependency-free implementation, various quantization support, memory-efficient CPU inference, GPU acceleration, and more. Users can download the built executable program or build it manually. The repository also includes instructions for downloading weights, building from scratch, using different acceleration methods, running the tool, converting weights, and utilizing various features like Flash Attention, ESRGAN upscaling, PhotoMaker support, and more. Additionally, it mentions future TODOs and provides information on memory requirements, bindings, UIs, contributors, and references.

LMOps
LMOps is a research initiative focusing on fundamental research and technology for building AI products with foundation models, particularly enabling AI capabilities with Large Language Models (LLMs) and Generative AI models. The project explores various aspects such as prompt optimization, longer context handling, LLM alignment, acceleration of LLMs, LLM customization, and understanding in-context learning. It also includes tools like Promptist for automatic prompt optimization, Structured Prompting for efficient long-sequence prompts consumption, and X-Prompt for extensible prompts beyond natural language. Additionally, LLMA accelerators are developed to speed up LLM inference by referencing and copying text spans from documents. The project aims to advance technologies that facilitate prompting language models and enhance the performance of LLMs in various scenarios.

Awesome-Efficient-LLM
Awesome-Efficient-LLM is a curated list focusing on efficient large language models. It includes topics such as knowledge distillation, network pruning, quantization, inference acceleration, efficient MOE, efficient architecture of LLM, KV cache compression, text compression, low-rank decomposition, hardware/system, tuning, and survey. The repository provides a collection of papers and projects related to improving the efficiency of large language models through various techniques like sparsity, quantization, and compression.

TensorRT-Model-Optimizer
The NVIDIA TensorRT Model Optimizer is a library designed to quantize and compress deep learning models for optimized inference on GPUs. It offers state-of-the-art model optimization techniques including quantization and sparsity to reduce inference costs for generative AI models. Users can easily stack different optimization techniques to produce quantized checkpoints from torch or ONNX models. The quantized checkpoints are ready for deployment in inference frameworks like TensorRT-LLM or TensorRT, with planned integrations for NVIDIA NeMo and Megatron-LM. The tool also supports 8-bit quantization with Stable Diffusion for enterprise users on NVIDIA NIM. Model Optimizer is available for free on NVIDIA PyPI, and this repository serves as a platform for sharing examples, GPU-optimized recipes, and collecting community feedback.
lightning-bolts
Bolts package provides a variety of components to extend PyTorch Lightning, such as callbacks & datasets, for applied research and production. Users can accelerate Lightning training with the Torch ORT Callback to optimize ONNX graph for faster training & inference. Additionally, users can introduce sparsity with the SparseMLCallback to accelerate inference by leveraging the DeepSparse engine. Specific research implementations are encouraged, with contributions that help train SSL models and integrate with Lightning Flash for state-of-the-art models in applied research.

ms-swift
ms-swift is an official framework provided by the ModelScope community for fine-tuning and deploying large language models and multi-modal large models. It supports training, inference, evaluation, quantization, and deployment of over 400 large models and 100+ multi-modal large models. The framework includes various training technologies and accelerates inference, evaluation, and deployment modules. It offers a Gradio-based Web-UI interface and best practices for easy application of large models. ms-swift supports a wide range of model types, dataset types, hardware support, lightweight training methods, distributed training techniques, quantization training, RLHF training, multi-modal training, interface training, plugin and extension support, inference acceleration engines, model evaluation, and model quantization.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.