Best AI tools for< Accelerate Inference >
20 - AI tool Sites
FluidStack
FluidStack is a leading GPU cloud platform designed for AI and LLM (Large Language Model) training. It offers unlimited scale for AI training and inference, allowing users to access thousands of fully-interconnected GPUs on demand. Trusted by top AI startups, FluidStack aggregates GPU capacity from data centers worldwide, providing access to over 50,000 GPUs for accelerating training and inference. With 1000+ data centers across 50+ countries, FluidStack ensures reliable and efficient GPU cloud services at competitive prices.
Anycores
Anycores is an AI tool designed to optimize the performance of deep neural networks and reduce the cost of running AI models in the cloud. It offers a platform that provides automated solutions for tuning and inference consultation, optimized networks zoo, and platform for reducing AI model cost. Anycores focuses on faster execution, reducing inference time over 10x times, and footprint reduction during model deployment. It is device agnostic, supporting Nvidia, AMD GPUs, Intel, ARM, AMD CPUs, servers, and edge devices. The tool aims to provide highly optimized, low footprint networks tailored to specific deployment scenarios.
FuriosaAI
FuriosaAI is an AI application that offers Hardware RNGD for LLM and Multimodality, as well as WARBOY for Computer Vision. It provides a comprehensive developer experience through the Furiosa SDK, Model Zoo, and Dev Support. The application focuses on efficient AI inference, high-performance LLM and multimodal deployment capabilities, and sustainable mass adoption of AI. FuriosaAI features the Tensor Contraction Processor architecture, software for streamlined LLM deployment, and a robust ecosystem support. It aims to deliver powerful and efficient deep learning acceleration while ensuring future-proof programmability and efficiency.
Denvr DataWorks AI Cloud
Denvr DataWorks AI Cloud is a cloud-based AI platform that provides end-to-end AI solutions for businesses. It offers a range of features including high-performance GPUs, scalable infrastructure, ultra-efficient workflows, and cost efficiency. Denvr DataWorks is an NVIDIA Elite Partner for Compute, and its platform is used by leading AI companies to develop and deploy innovative AI solutions.
ONNX Runtime
ONNX Runtime is a production-grade AI engine designed to accelerate machine learning training and inferencing in various technology stacks. It supports multiple languages and platforms, optimizing performance for CPU, GPU, and NPU hardware. ONNX Runtime powers AI in Microsoft products and is widely used in cloud, edge, web, and mobile applications. It also enables large model training and on-device training, offering state-of-the-art models for tasks like image synthesis and text generation.
Cerebras
Cerebras is an AI tool that offers products and services related to AI supercomputers, cloud system processors, and applications for various industries. It provides high-performance computing solutions, including large language models, and caters to sectors such as health, energy, government, scientific computing, and financial services. Cerebras specializes in AI model services, offering state-of-the-art models and training services for tasks like multi-lingual chatbots and DNA sequence prediction. The platform also features the Cerebras Model Zoo, an open-source repository of AI models for developers and researchers.
Graphcore
Graphcore is a cloud-based platform that accelerates machine learning processes by harnessing the power of IPU-powered generative AI. It offers cloud services, pre-trained models, optimized inference engines, and APIs to streamline operations and bring intelligence to enterprise applications. With Graphcore, users can build and deploy AI-native products and platforms using the latest AI technologies such as LLMs, NLP, and Computer Vision.
Cerebras
Cerebras is a leading AI tool and application provider that offers cutting-edge AI supercomputers, model services, and cloud solutions for various industries. The platform specializes in high-performance computing, large language models, and AI model training, catering to sectors such as health, energy, government, and financial services. Cerebras empowers developers and researchers with access to advanced AI models, open-source resources, and innovative hardware and software development kits.
Rebellions
Rebellions is an AI technology company specializing in AI chips and systems-on-chip for various applications. They focus on energy-efficient solutions and have secured significant investments to drive innovation in the field of Generative AI. Rebellions aims to reshape the future by providing versatile and efficient AI computing solutions.
NetMind
NetMind is an AI tool that offers a Model Library, Enterprise AI Solutions, and AI Consulting services. It provides cutting-edge inference capabilities, model APIs for various data types, and GPU clusters for accelerated performance. The platform allows rapid deployment of models with flexible scaling options. NetMind caters to a wide range of industries, offering solutions that enhance accuracy, cut costs, and accelerate decision-making processes.
TractoAI
TractoAI is an advanced AI platform that offers deep learning solutions for various industries. It provides Batch Inference with no rate limits, DeepSeek offline inference, and helps in training open source AI models. TractoAI simplifies training infrastructure setup, accelerates workflows with GPUs, and automates deployment and scaling for tasks like ML training and big data processing. The platform supports fine-tuning models, sandboxed code execution, and building custom AI models with distributed training launcher. It is developer-friendly, scalable, and efficient, offering a solution library and expert guidance for AI projects.

Cambricon
Cambricon is an AI technology company that specializes in developing intelligent acceleration cards and systems. They offer a range of products including cloud AI acceleration cards, edge AI chips, and intelligent processing units. Cambricon's advanced chiplet technology and MLUarch03 architecture provide high-performance AI solutions for training and inference tasks. The company is dedicated to advancing the AI industry through innovative hardware and software platforms.
Cirrascale Cloud Services
Cirrascale Cloud Services is an AI tool that offers cloud solutions for Artificial Intelligence applications. The platform provides a range of cloud services and products tailored for AI innovation, including NVIDIA GPU Cloud, AMD Instinct Series Cloud, Qualcomm Cloud, Graphcore, Cerebras, and SambaNova. Cirrascale's AI Innovation Cloud enables users to test and deploy on leading AI accelerators in one cloud, democratizing AI by delivering high-performance AI compute and scalable deep learning solutions. The platform also offers professional and managed services, tailored multi-GPU server options, and high-throughput storage and networking solutions to accelerate development, training, and inference workloads.

UpRizz
UpRizz is an AI-powered tool that helps users increase their Instagram followers and engagement by writing better comments. It uses advanced AI models to generate personalized comments that are tailored to each post, making it easy for users to connect with their audience and grow their influence on Instagram.
Crayon Data
Crayon Data offers B2B AI solutions for enterprises through their platform maya.ai. The platform provides flexible building blocks to help businesses launch and scale quickly. With a cloud-agnostic full-stack solution, maya.ai enables real-world applications for data, customer management, and more. Crayon Data focuses on AI-led solutions to enhance customer experiences, turn raw data into valuable insights, and drive engagement through AI marketplaces. The platform also offers tools for travel planning, payment optimization, offer management, data analytics, influencer management, and more. Industries served include consumer banking, digital payments, travel, and consumer products.
Rapid Muscle
Rapid Muscle is a science-powered hypertrophy workout generator that offers a cutting-edge platform to accelerate muscle growth. It provides tools like the Hypertrophy Split Generator and Workout Tracker to optimize exercise selection, sequencing, and volume for physique development. The upcoming AI Personal Trainer chatbot enhances user experience by providing expert advice on training-related queries. Rapid Muscle aims to revolutionize hypertrophy programming by offering evidence-based solutions and eliminating contradictory influencer advice.
Translate.Video
Translate.Video is an AI multi-speaker video translation tool that offers speaker diarization, voice cloning, text-to-speech, and instant voice cloning features. It allows users to translate videos to over 75 languages with just one click, making content creation and translation efficient and accessible. The tool also provides plugins for popular design software like Photoshop, Illustrator, and Figma, enabling users to accelerate creative translation. Translate.Video is designed to help creators, influencers, and enterprises reach a global audience by simplifying the captioning, subtitling, and dubbing process.
Adjust
Adjust is an AI-driven platform that helps mobile app developers accelerate their app's growth through a comprehensive suite of measurement, analytics, automation, and fraud prevention tools. The platform offers unlimited measurement capabilities across various platforms, powerful analytics and reporting features, AI-driven decision-making recommendations, streamlined operations through automation, and data protection against mobile ad fraud. Adjust also provides solutions for iOS and SKAdNetwork success, CTV and OTT performance enhancement, ROI measurement, fraud prevention, and incrementality analysis. With a focus on privacy and security, Adjust empowers app developers to optimize their marketing strategies and drive tangible growth.
Tidio
Tidio is an AI-powered customer service solution that helps businesses automate support, convert more leads, and increase revenue. With Lyro AI Chatbot, businesses can answer up to 70% of customer inquiries without human intervention, freeing up support agents to focus on high-value requests. Tidio also offers live chat, helpdesk, and automation features to help businesses provide excellent customer support and grow their business.
Tidio
Tidio is an AI-powered customer service solution that helps businesses automate their support and sales processes. With Lyro AI Chatbot, businesses can solve up to 70% of customer problems without human intervention. Tidio also offers live chat, helpdesk, and automation features to help businesses provide excellent customer service and grow their revenue.
15 - Open Source AI Tools

AutoGPTQ
AutoGPTQ is an easy-to-use LLM quantization package with user-friendly APIs, based on GPTQ algorithm (weight-only quantization). It provides a simple and efficient way to quantize large language models (LLMs) to reduce their size and computational cost while maintaining their performance. AutoGPTQ supports a wide range of LLM models, including GPT-2, GPT-J, OPT, and BLOOM. It also supports various evaluation tasks, such as language modeling, sequence classification, and text summarization. With AutoGPTQ, users can easily quantize their LLM models and deploy them on resource-constrained devices, such as mobile phones and embedded systems.

Qwen-TensorRT-LLM
Qwen-TensorRT-LLM is a project developed for the NVIDIA TensorRT Hackathon 2023, focusing on accelerating inference for the Qwen-7B-Chat model using TRT-LLM. The project offers various functionalities such as FP16/BF16 support, INT8 and INT4 quantization options, Tensor Parallel for multi-GPU parallelism, web demo setup with gradio, Triton API deployment for maximum throughput/concurrency, fastapi integration for openai requests, CLI interaction, and langchain support. It supports models like qwen2, qwen, and qwen-vl for both base and chat models. The project also provides tutorials on Bilibili and blogs for adapting Qwen models in NVIDIA TensorRT-LLM, along with hardware requirements and quick start guides for different model types and quantization methods.

stable-diffusion.cpp
The stable-diffusion.cpp repository provides an implementation for inferring stable diffusion in pure C/C++. It offers features such as support for different versions of stable diffusion, lightweight and dependency-free implementation, various quantization support, memory-efficient CPU inference, GPU acceleration, and more. Users can download the built executable program or build it manually. The repository also includes instructions for downloading weights, building from scratch, using different acceleration methods, running the tool, converting weights, and utilizing various features like Flash Attention, ESRGAN upscaling, PhotoMaker support, and more. Additionally, it mentions future TODOs and provides information on memory requirements, bindings, UIs, contributors, and references.

LMOps
LMOps is a research initiative focusing on fundamental research and technology for building AI products with foundation models, particularly enabling AI capabilities with Large Language Models (LLMs) and Generative AI models. The project explores various aspects such as prompt optimization, longer context handling, LLM alignment, acceleration of LLMs, LLM customization, and understanding in-context learning. It also includes tools like Promptist for automatic prompt optimization, Structured Prompting for efficient long-sequence prompts consumption, and X-Prompt for extensible prompts beyond natural language. Additionally, LLMA accelerators are developed to speed up LLM inference by referencing and copying text spans from documents. The project aims to advance technologies that facilitate prompting language models and enhance the performance of LLMs in various scenarios.

Awesome-Efficient-LLM
Awesome-Efficient-LLM is a curated list focusing on efficient large language models. It includes topics such as knowledge distillation, network pruning, quantization, inference acceleration, efficient MOE, efficient architecture of LLM, KV cache compression, text compression, low-rank decomposition, hardware/system, tuning, and survey. The repository provides a collection of papers and projects related to improving the efficiency of large language models through various techniques like sparsity, quantization, and compression.

TensorRT-Model-Optimizer
The NVIDIA TensorRT Model Optimizer is a library designed to quantize and compress deep learning models for optimized inference on GPUs. It offers state-of-the-art model optimization techniques including quantization and sparsity to reduce inference costs for generative AI models. Users can easily stack different optimization techniques to produce quantized checkpoints from torch or ONNX models. The quantized checkpoints are ready for deployment in inference frameworks like TensorRT-LLM or TensorRT, with planned integrations for NVIDIA NeMo and Megatron-LM. The tool also supports 8-bit quantization with Stable Diffusion for enterprise users on NVIDIA NIM. Model Optimizer is available for free on NVIDIA PyPI, and this repository serves as a platform for sharing examples, GPU-optimized recipes, and collecting community feedback.
lightning-bolts
Bolts package provides a variety of components to extend PyTorch Lightning, such as callbacks & datasets, for applied research and production. Users can accelerate Lightning training with the Torch ORT Callback to optimize ONNX graph for faster training & inference. Additionally, users can introduce sparsity with the SparseMLCallback to accelerate inference by leveraging the DeepSparse engine. Specific research implementations are encouraged, with contributions that help train SSL models and integrate with Lightning Flash for state-of-the-art models in applied research.

ms-swift
ms-swift is an official framework provided by the ModelScope community for fine-tuning and deploying large language models and multi-modal large models. It supports training, inference, evaluation, quantization, and deployment of over 400 large models and 100+ multi-modal large models. The framework includes various training technologies and accelerates inference, evaluation, and deployment modules. It offers a Gradio-based Web-UI interface and best practices for easy application of large models. ms-swift supports a wide range of model types, dataset types, hardware support, lightweight training methods, distributed training techniques, quantization training, RLHF training, multi-modal training, interface training, plugin and extension support, inference acceleration engines, model evaluation, and model quantization.
AITemplate
AITemplate (AIT) is a Python framework that transforms deep neural networks into CUDA (NVIDIA GPU) / HIP (AMD GPU) C++ code for lightning-fast inference serving. It offers high performance close to roofline fp16 TensorCore (NVIDIA GPU) / MatrixCore (AMD GPU) performance on major models. AITemplate is unified, open, and flexible, supporting a comprehensive range of fusions for both GPU platforms. It provides excellent backward capability, horizontal fusion, vertical fusion, memory fusion, and works with or without PyTorch. FX2AIT is a tool that converts PyTorch models into AIT for fast inference serving, offering easy conversion and expanded support for models with unsupported operators.
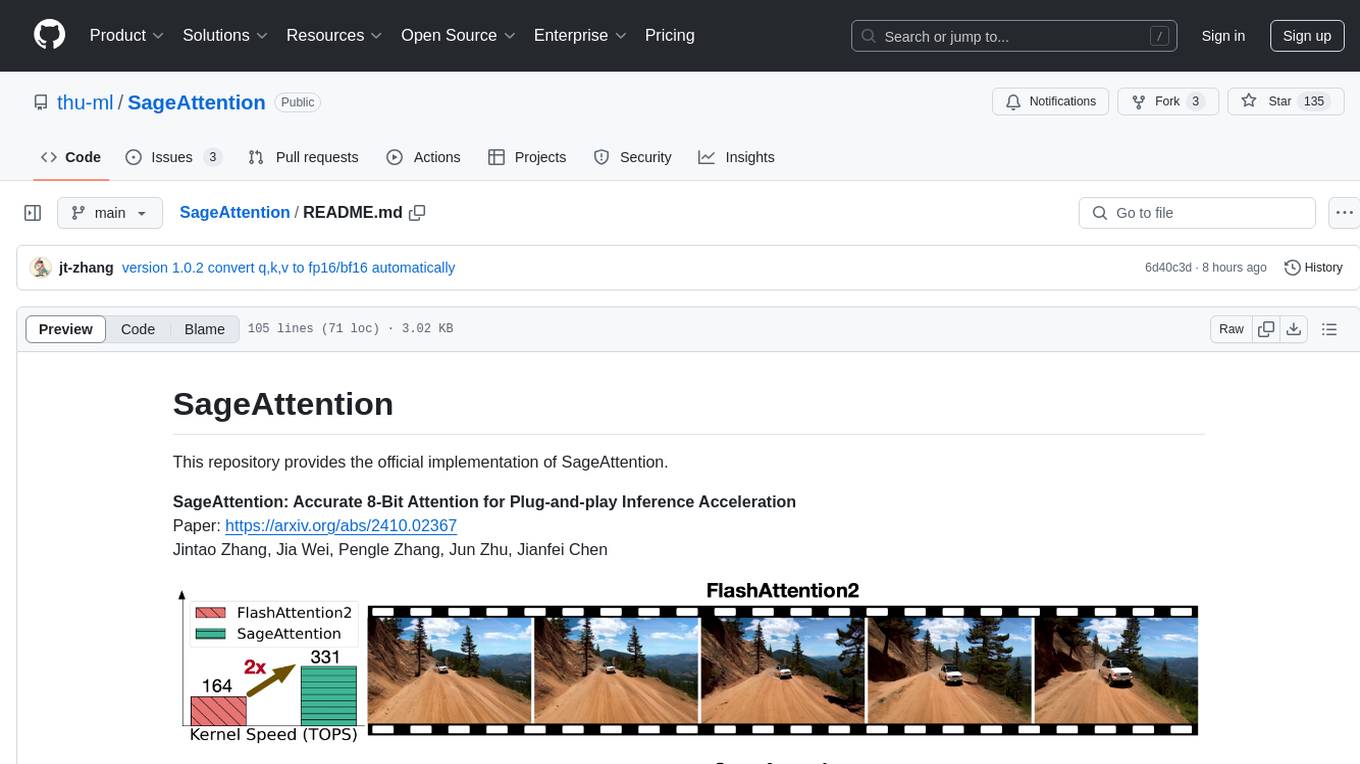
SageAttention
SageAttention is an official implementation of an accurate 8-bit attention mechanism for plug-and-play inference acceleration. It is optimized for RTX4090 and RTX3090 GPUs, providing performance improvements for specific GPU architectures. The tool offers a technique called 'smooth_k' to ensure accuracy in processing FP16/BF16 data. Users can easily replace 'scaled_dot_product_attention' with SageAttention for faster video processing.
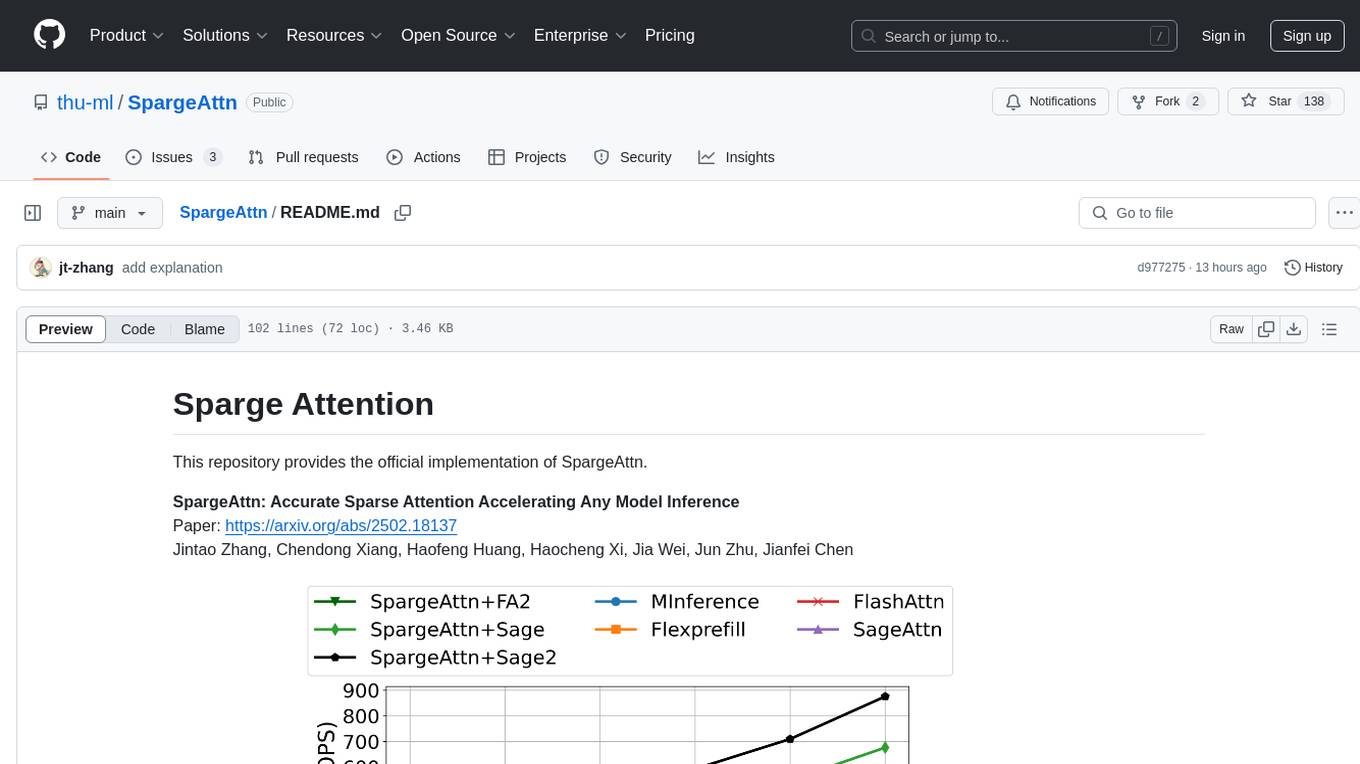
SpargeAttn
SpargeAttn is an official implementation designed for accelerating any model inference by providing accurate sparse attention. It offers a significant speedup in model performance while maintaining quality. The tool is based on SageAttention and SageAttention2, providing options for different levels of optimization. Users can easily install the package and utilize the available APIs for their specific needs. SpargeAttn is particularly useful for tasks requiring efficient attention mechanisms in deep learning models.
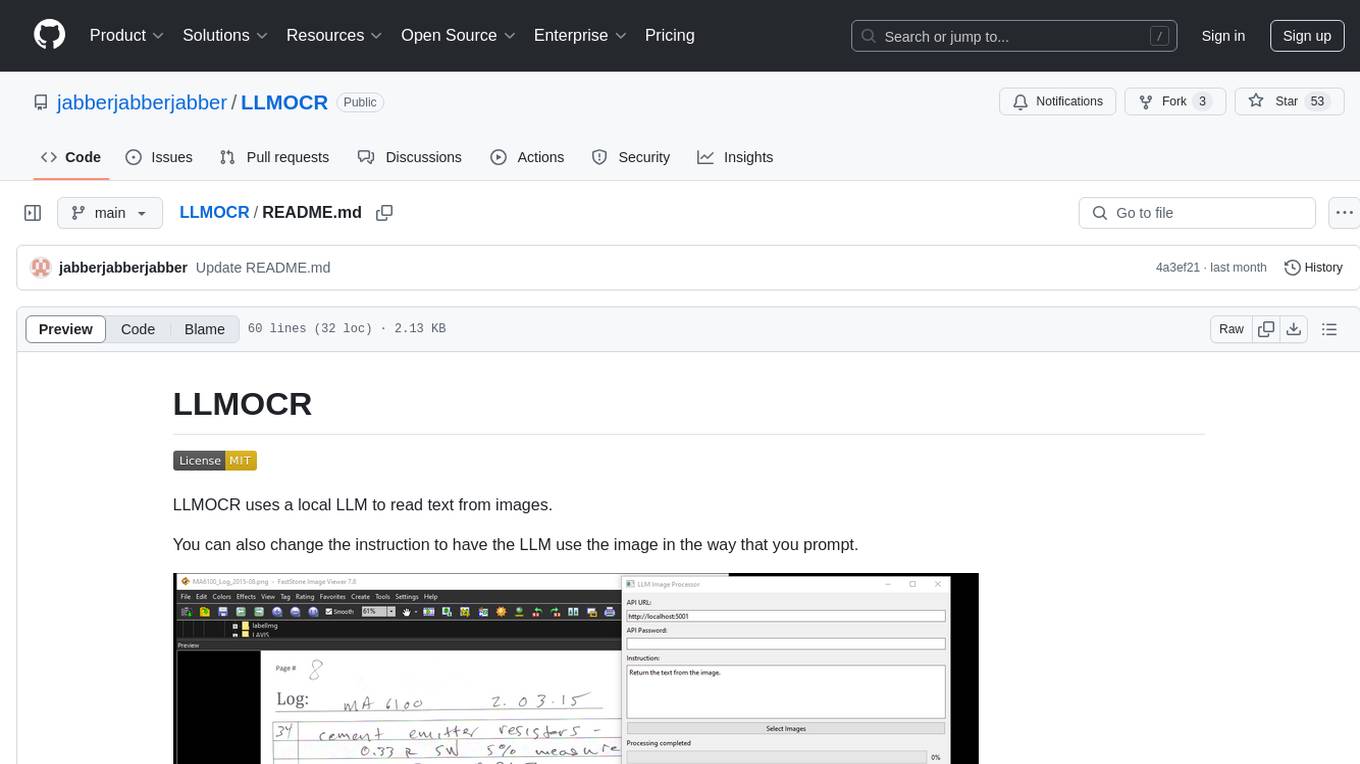
LLMOCR
LLMOCR is a tool that utilizes a local Large Language Model (LLM) to extract text from images. It offers a user-friendly GUI and supports GPU acceleration for faster inference. The tool is cross-platform, compatible with Windows, macOS ARM, and Linux. Users can prompt the LLM to process images in a customized way. The processing is done locally on the user's machine, ensuring data privacy and security. LLMOCR requires Python 3.8 or higher and KoboldCPP for installation and operation.
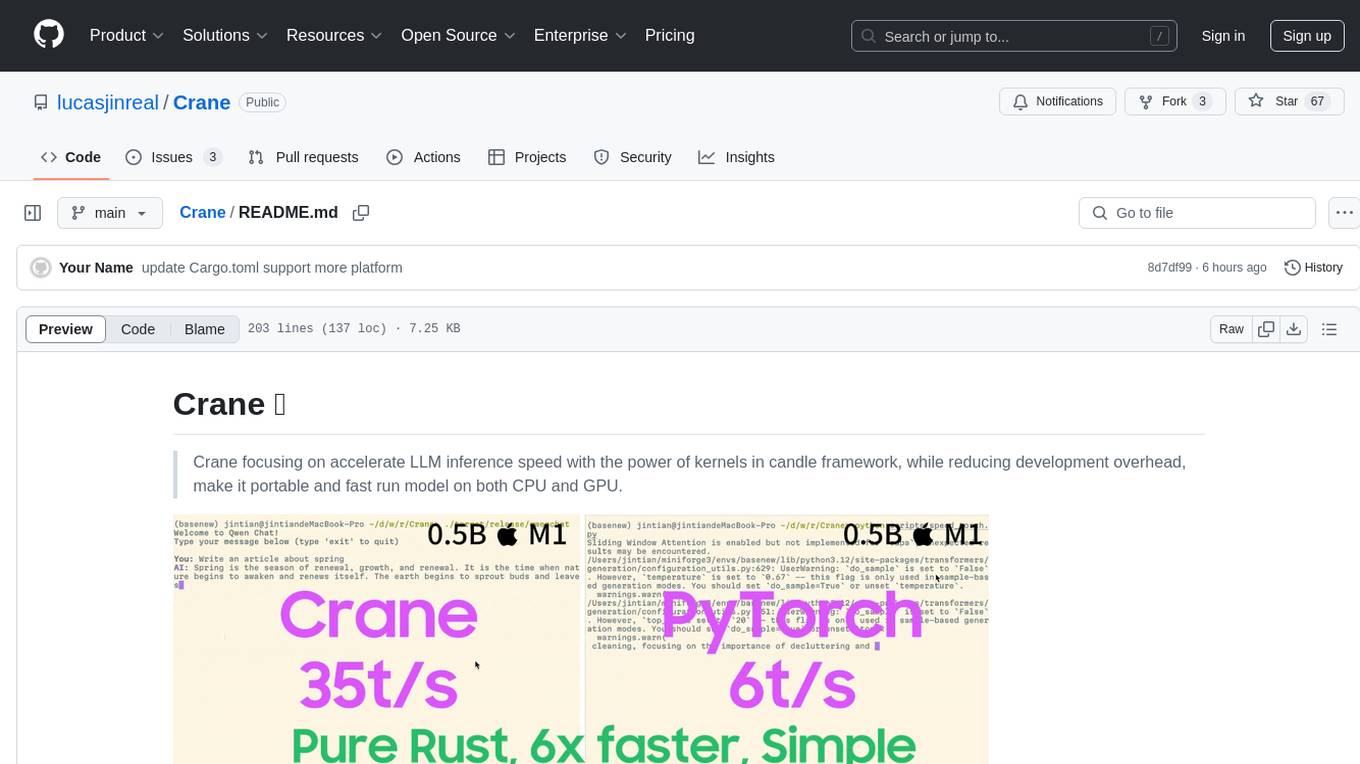
Crane
Crane is a high-performance inference framework leveraging Rust's Candle for maximum speed on CPU/GPU. It focuses on accelerating LLM inference speed with optimized kernels, reducing development overhead, and ensuring portability for running models on both CPU and GPU. Supported models include TTS systems like Spark-TTS and Orpheus-TTS, foundation models like Qwen2.5 series and basic LLMs, and multimodal models like Namo-R1 and Qwen2.5-VL. Key advantages of Crane include blazing-fast inference outperforming native PyTorch, Rust-powered to eliminate C++ complexity, Apple Silicon optimized for GPU acceleration via Metal, and hardware agnostic with a unified codebase for CPU/CUDA/Metal execution. Crane simplifies deployment with the ability to add new models with less than 100 lines of code in most cases.
FastDeploy
FastDeploy is an inference and deployment toolkit for large language models and visual language models based on PaddlePaddle. It provides production-ready deployment solutions with core acceleration technologies such as load-balanced PD disaggregation, unified KV cache transmission, OpenAI API server compatibility, comprehensive quantization format support, advanced acceleration techniques, and multi-hardware support. The toolkit supports various hardware platforms like NVIDIA GPUs, Kunlunxin XPUs, Iluvatar GPUs, Enflame GCUs, and Hygon DCUs, with plans for expanding support to Ascend NPU and MetaX GPU. FastDeploy aims to optimize resource utilization, throughput, and performance for inference and deployment tasks.

dLLM-RL
dLLM-RL is a revolutionary reinforcement learning framework designed for Diffusion Large Language Models. It supports various models with diverse structures, offers inference acceleration, RL training capabilities, and SFT functionalities. The tool introduces TraceRL for trajectory-aware RL and diffusion-based value models for optimization stability. Users can download and try models like TraDo-4B-Instruct and TraDo-8B-Instruct. The tool also provides support for multi-node setups and easy building of reinforcement learning methods. Additionally, it offers supervised fine-tuning strategies for different models and tasks.
7 - OpenAI Gpts
Material Tailwind GPT
Accelerate web app development with Material Tailwind GPT's components - 10x faster.
Tourist Language Accelerator
Accelerates the learning of key phrases and cultural norms for travelers in various languages.


Digital Entrepreneurship Accelerator Coach
The Go-To Coach for Aspiring Digital Entrepreneurs, Innovators, & Startups. Learn More at UnderdogInnovationInc.com.
24 Hour Startup Accelerator
Niche-focused startup guide, humorous, strategic, simplifying ideas.
Backloger.ai - Product MVP Accelerator
Drop in any requirements or any text ; I'll help you create an MVP with insights.
Digital Boost Lab
A guide for developing university-focused digital startup accelerator programs.