
AutoGPTQ
An easy-to-use LLMs quantization package with user-friendly apis, based on GPTQ algorithm.
Stars: 4360

AutoGPTQ is an easy-to-use LLM quantization package with user-friendly APIs, based on GPTQ algorithm (weight-only quantization). It provides a simple and efficient way to quantize large language models (LLMs) to reduce their size and computational cost while maintaining their performance. AutoGPTQ supports a wide range of LLM models, including GPT-2, GPT-J, OPT, and BLOOM. It also supports various evaluation tasks, such as language modeling, sequence classification, and text summarization. With AutoGPTQ, users can easily quantize their LLM models and deploy them on resource-constrained devices, such as mobile phones and embedded systems.
README:
An easy-to-use LLM quantization package with user-friendly APIs, based on GPTQ algorithm (weight-only quantization).


English | 中文
- 2024-02-15 - (News) - AutoGPTQ 0.7.0 is released, with Marlin int4*fp16 matrix multiplication kernel support, with the argument
use_marlin=Truewhen loading models. - 2023-08-23 - (News) - 🤗 Transformers, optimum and peft have integrated
auto-gptq, so now running and training GPTQ models can be more available to everyone! See this blog and it's resources for more details!
For more histories please turn to here
The result is generated using this script, batch size of input is 1, decode strategy is beam search and enforce the model to generate 512 tokens, speed metric is tokens/s (the larger, the better).
The quantized model is loaded using the setup that can gain the fastest inference speed.
| model | GPU | num_beams | fp16 | gptq-int4 |
|---|---|---|---|---|
| llama-7b | 1xA100-40G | 1 | 18.87 | 25.53 |
| llama-7b | 1xA100-40G | 4 | 68.79 | 91.30 |
| moss-moon 16b | 1xA100-40G | 1 | 12.48 | 15.25 |
| moss-moon 16b | 1xA100-40G | 4 | OOM | 42.67 |
| moss-moon 16b | 2xA100-40G | 1 | 06.83 | 06.78 |
| moss-moon 16b | 2xA100-40G | 4 | 13.10 | 10.80 |
| gpt-j 6b | 1xRTX3060-12G | 1 | OOM | 29.55 |
| gpt-j 6b | 1xRTX3060-12G | 4 | OOM | 47.36 |
For perplexity comparison, you can turn to here and here
AutoGPTQ is available on Linux and Windows only. You can install the latest stable release of AutoGPTQ from pip with pre-built wheels:
| Platform version | Installation | Built against PyTorch |
|---|---|---|
| CUDA 11.8 | pip install auto-gptq --no-build-isolation --extra-index-url https://huggingface.github.io/autogptq-index/whl/cu118/ |
2.2.1+cu118 |
| CUDA 12.1 | pip install auto-gptq --no-build-isolation |
2.2.1+cu121 |
| ROCm 5.7 | pip install auto-gptq --no-build-isolation --extra-index-url https://huggingface.github.io/autogptq-index/whl/rocm573/ |
2.2.1+rocm5.7 |
| Intel® Gaudi® 2 AI accelerator | BUILD_CUDA_EXT=0 pip install auto-gptq --no-build-isolation |
2.3.1+Intel Gaudi 1.17 |
AutoGPTQ can be installed with the Triton dependency with pip install auto-gptq[triton] --no-build-isolation in order to be able to use the Triton backend (currently only supports linux, no 3-bits quantization).
For older AutoGPTQ, please refer to the previous releases installation table.
On NVIDIA systems, AutoGPTQ does not support Maxwell or lower GPUs.
Clone the source code:
git clone https://github.com/PanQiWei/AutoGPTQ.git && cd AutoGPTQA few packages are required in order to build from source: pip install numpy gekko pandas.
Then, install locally from source:
pip install -vvv --no-build-isolation -e .You can set BUILD_CUDA_EXT=0 to disable pytorch extension building, but this is strongly discouraged as AutoGPTQ then falls back on a slow python implementation.
As a last resort, if the above command fails, you can try python setup.py install.
To install from source for AMD GPUs supporting ROCm, please specify the ROCM_VERSION environment variable. Example:
ROCM_VERSION=5.6 pip install -vvv --no-build-isolation -e .The compilation can be speeded up by specifying the PYTORCH_ROCM_ARCH variable (reference) in order to build for a single target device, for example gfx90a for MI200 series devices.
For ROCm systems, the packages rocsparse-dev, hipsparse-dev, rocthrust-dev, rocblas-dev and hipblas-dev are required to build.
To install from source for Intel Gaudi 2 HPUs, set the BUILD_CUDA_EXT=0 environment variable to disable building the CUDA PyTorch extension. Example:
BUILD_CUDA_EXT=0 pip install -vvv --no-build-isolation -e .Notice that Intel Gaudi 2 uses an optimized kernel upon inference, and requires
BUILD_CUDA_EXT=0on non-CUDA machines.
warning: this is just a showcase of the usage of basic apis in AutoGPTQ, which uses only one sample to quantize a much small model, quality of quantized model using such little samples may not good.
Below is an example for the simplest use of auto_gptq to quantize a model and inference after quantization:
from transformers import AutoTokenizer, TextGenerationPipeline
from auto_gptq import AutoGPTQForCausalLM, BaseQuantizeConfig
import logging
logging.basicConfig(
format="%(asctime)s %(levelname)s [%(name)s] %(message)s", level=logging.INFO, datefmt="%Y-%m-%d %H:%M:%S"
)
pretrained_model_dir = "facebook/opt-125m"
quantized_model_dir = "opt-125m-4bit"
tokenizer = AutoTokenizer.from_pretrained(pretrained_model_dir, use_fast=True)
examples = [
tokenizer(
"auto-gptq is an easy-to-use model quantization library with user-friendly apis, based on GPTQ algorithm."
)
]
quantize_config = BaseQuantizeConfig(
bits=4, # quantize model to 4-bit
group_size=128, # it is recommended to set the value to 128
desc_act=False, # set to False can significantly speed up inference but the perplexity may slightly bad
)
# load un-quantized model, by default, the model will always be loaded into CPU memory
model = AutoGPTQForCausalLM.from_pretrained(pretrained_model_dir, quantize_config)
# quantize model, the examples should be list of dict whose keys can only be "input_ids" and "attention_mask"
model.quantize(examples)
# save quantized model
model.save_quantized(quantized_model_dir)
# save quantized model using safetensors
model.save_quantized(quantized_model_dir, use_safetensors=True)
# push quantized model to Hugging Face Hub.
# to use use_auth_token=True, Login first via huggingface-cli login.
# or pass explcit token with: use_auth_token="hf_xxxxxxx"
# (uncomment the following three lines to enable this feature)
# repo_id = f"YourUserName/{quantized_model_dir}"
# commit_message = f"AutoGPTQ model for {pretrained_model_dir}: {quantize_config.bits}bits, gr{quantize_config.group_size}, desc_act={quantize_config.desc_act}"
# model.push_to_hub(repo_id, commit_message=commit_message, use_auth_token=True)
# alternatively you can save and push at the same time
# (uncomment the following three lines to enable this feature)
# repo_id = f"YourUserName/{quantized_model_dir}"
# commit_message = f"AutoGPTQ model for {pretrained_model_dir}: {quantize_config.bits}bits, gr{quantize_config.group_size}, desc_act={quantize_config.desc_act}"
# model.push_to_hub(repo_id, save_dir=quantized_model_dir, use_safetensors=True, commit_message=commit_message, use_auth_token=True)
# load quantized model to the first GPU
model = AutoGPTQForCausalLM.from_quantized(quantized_model_dir, device="cuda:0")
# download quantized model from Hugging Face Hub and load to the first GPU
# model = AutoGPTQForCausalLM.from_quantized(repo_id, device="cuda:0", use_safetensors=True, use_triton=False)
# inference with model.generate
print(tokenizer.decode(model.generate(**tokenizer("auto_gptq is", return_tensors="pt").to(model.device))[0]))
# or you can also use pipeline
pipeline = TextGenerationPipeline(model=model, tokenizer=tokenizer)
print(pipeline("auto-gptq is")[0]["generated_text"])For more advanced features of model quantization, please reference to this script
Below is an example to extend `auto_gptq` to support `OPT` model, as you will see, it's very easy:
from auto_gptq.modeling import BaseGPTQForCausalLM
class OPTGPTQForCausalLM(BaseGPTQForCausalLM):
# chained attribute name of transformer layer block
layers_block_name = "model.decoder.layers"
# chained attribute names of other nn modules that in the same level as the transformer layer block
outside_layer_modules = [
"model.decoder.embed_tokens", "model.decoder.embed_positions", "model.decoder.project_out",
"model.decoder.project_in", "model.decoder.final_layer_norm"
]
# chained attribute names of linear layers in transformer layer module
# normally, there are four sub lists, for each one the modules in it can be seen as one operation,
# and the order should be the order when they are truly executed, in this case (and usually in most cases),
# they are: attention q_k_v projection, attention output projection, MLP project input, MLP project output
inside_layer_modules = [
["self_attn.k_proj", "self_attn.v_proj", "self_attn.q_proj"],
["self_attn.out_proj"],
["fc1"],
["fc2"]
]After this, you can use OPTGPTQForCausalLM.from_pretrained and other methods as shown in Basic.
You can use tasks defined in auto_gptq.eval_tasks to evaluate model's performance on specific down-stream task before and after quantization.
The predefined tasks support all causal-language-models implemented in 🤗 transformers and in this project.
Below is an example to evaluate `EleutherAI/gpt-j-6b` on sequence-classification task using `cardiffnlp/tweet_sentiment_multilingual` dataset:
from functools import partial
import datasets
from transformers import AutoTokenizer, AutoModelForCausalLM, GenerationConfig
from auto_gptq import AutoGPTQForCausalLM, BaseQuantizeConfig
from auto_gptq.eval_tasks import SequenceClassificationTask
MODEL = "EleutherAI/gpt-j-6b"
DATASET = "cardiffnlp/tweet_sentiment_multilingual"
TEMPLATE = "Question:What's the sentiment of the given text? Choices are {labels}.\nText: {text}\nAnswer:"
ID2LABEL = {
0: "negative",
1: "neutral",
2: "positive"
}
LABELS = list(ID2LABEL.values())
def ds_refactor_fn(samples):
text_data = samples["text"]
label_data = samples["label"]
new_samples = {"prompt": [], "label": []}
for text, label in zip(text_data, label_data):
prompt = TEMPLATE.format(labels=LABELS, text=text)
new_samples["prompt"].append(prompt)
new_samples["label"].append(ID2LABEL[label])
return new_samples
# model = AutoModelForCausalLM.from_pretrained(MODEL).eval().half().to("cuda:0")
model = AutoGPTQForCausalLM.from_pretrained(MODEL, BaseQuantizeConfig())
tokenizer = AutoTokenizer.from_pretrained(MODEL)
task = SequenceClassificationTask(
model=model,
tokenizer=tokenizer,
classes=LABELS,
data_name_or_path=DATASET,
prompt_col_name="prompt",
label_col_name="label",
**{
"num_samples": 1000, # how many samples will be sampled to evaluation
"sample_max_len": 1024, # max tokens for each sample
"block_max_len": 2048, # max tokens for each data block
# function to load dataset, one must only accept data_name_or_path as input
# and return datasets.Dataset
"load_fn": partial(datasets.load_dataset, name="english"),
# function to preprocess dataset, which is used for datasets.Dataset.map,
# must return Dict[str, list] with only two keys: [prompt_col_name, label_col_name]
"preprocess_fn": ds_refactor_fn,
# truncate label when sample's length exceed sample_max_len
"truncate_prompt": False
}
)
# note that max_new_tokens will be automatically specified internally based on given classes
print(task.run())
# self-consistency
print(
task.run(
generation_config=GenerationConfig(
num_beams=3,
num_return_sequences=3,
do_sample=True
)
)
)tutorials provide step-by-step guidance to integrate auto_gptq with your own project and some best practice principles.
examples provide plenty of example scripts to use auto_gptq in different ways.
you can use
model.config.model_typeto compare with the table below to check whether the model you use is supported byauto_gptq.for example, model_type of
WizardLM,vicunaandgpt4allare allllama, hence they are all supported byauto_gptq.
| model type | quantization | inference | peft-lora | peft-ada-lora | peft-adaption_prompt |
|---|---|---|---|---|---|
| bloom | ✅ | ✅ | ✅ | ✅ | |
| gpt2 | ✅ | ✅ | ✅ | ✅ | |
| gpt_neox | ✅ | ✅ | ✅ | ✅ | ✅requires this peft branch |
| gptj | ✅ | ✅ | ✅ | ✅ | ✅requires this peft branch |
| llama | ✅ | ✅ | ✅ | ✅ | ✅ |
| moss | ✅ | ✅ | ✅ | ✅ | ✅requires this peft branch |
| opt | ✅ | ✅ | ✅ | ✅ | |
| gpt_bigcode | ✅ | ✅ | ✅ | ✅ | |
| codegen | ✅ | ✅ | ✅ | ✅ | |
| falcon(RefinedWebModel/RefinedWeb) | ✅ | ✅ | ✅ | ✅ |
Currently, auto_gptq supports: LanguageModelingTask, SequenceClassificationTask and TextSummarizationTask; more Tasks will come soon!
Tests can be run with:
pytest tests/ -s
AutoGPTQ defaults to using exllamav2 int4*fp16 kernel for matrix multiplication.
Marlin is an optimized int4 * fp16 kernel was recently proposed at https://github.com/IST-DASLab/marlin. This is integrated in AutoGPTQ when loading a model with use_marlin=True. This kernel is available only on devices with compute capability 8.0 or 8.6 (Ampere GPUs).
- Special thanks Elias Frantar, Saleh Ashkboos, Torsten Hoefler and Dan Alistarh for proposing GPTQ algorithm and open source the code, and for releasing Marlin kernel for mixed precision computation.
- Special thanks qwopqwop200, for code in this project that relevant to quantization are mainly referenced from GPTQ-for-LLaMa.
- Special thanks to turboderp, for releasing Exllama and Exllama v2 libraries with efficient mixed precision kernels.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for AutoGPTQ
Similar Open Source Tools
AutoGPTQ
AutoGPTQ is an easy-to-use LLM quantization package with user-friendly APIs, based on GPTQ algorithm (weight-only quantization). It provides a simple and efficient way to quantize large language models (LLMs) to reduce their size and computational cost while maintaining their performance. AutoGPTQ supports a wide range of LLM models, including GPT-2, GPT-J, OPT, and BLOOM. It also supports various evaluation tasks, such as language modeling, sequence classification, and text summarization. With AutoGPTQ, users can easily quantize their LLM models and deploy them on resource-constrained devices, such as mobile phones and embedded systems.

AQLM
AQLM is the official PyTorch implementation for Extreme Compression of Large Language Models via Additive Quantization. It includes prequantized AQLM models without PV-Tuning and PV-Tuned models for LLaMA, Mistral, and Mixtral families. The repository provides inference examples, model details, and quantization setups. Users can run prequantized models using Google Colab examples, work with different model families, and install the necessary inference library. The repository also offers detailed instructions for quantization, fine-tuning, and model evaluation. AQLM quantization involves calibrating models for compression, and users can improve model accuracy through finetuning. Additionally, the repository includes information on preparing models for inference and contributing guidelines.
rank_llm
RankLLM is a suite of prompt-decoders compatible with open source LLMs like Vicuna and Zephyr. It allows users to create custom ranking models for various NLP tasks, such as document reranking, question answering, and summarization. The tool offers a variety of features, including the ability to fine-tune models on custom datasets, use different retrieval methods, and control the context size and variable passages. RankLLM is easy to use and can be integrated into existing NLP pipelines.

floneum
Floneum is a graph editor that makes it easy to develop your own AI workflows. It uses large language models (LLMs) to run AI models locally, without any external dependencies or even a GPU. This makes it easy to use LLMs with your own data, without worrying about privacy. Floneum also has a plugin system that allows you to improve the performance of LLMs and make them work better for your specific use case. Plugins can be used in any language that supports web assembly, and they can control the output of LLMs with a process similar to JSONformer or guidance.

Qwen
Qwen is a series of large language models developed by Alibaba DAMO Academy. It outperforms the baseline models of similar model sizes on a series of benchmark datasets, e.g., MMLU, C-Eval, GSM8K, MATH, HumanEval, MBPP, BBH, etc., which evaluate the models’ capabilities on natural language understanding, mathematic problem solving, coding, etc. Qwen models outperform the baseline models of similar model sizes on a series of benchmark datasets, e.g., MMLU, C-Eval, GSM8K, MATH, HumanEval, MBPP, BBH, etc., which evaluate the models’ capabilities on natural language understanding, mathematic problem solving, coding, etc. Qwen-72B achieves better performance than LLaMA2-70B on all tasks and outperforms GPT-3.5 on 7 out of 10 tasks.

EasySteer
EasySteer is a unified framework built on vLLM for high-performance LLM steering. It offers fast, flexible, and easy-to-use steering capabilities with features like high performance, modular design, fine-grained control, pre-computed steering vectors, and an interactive demo. Users can interactively configure models, adjust steering parameters, and test interventions without writing code. The tool supports OpenAI-compatible APIs and provides modules for hidden states extraction, analysis-based steering, learning-based steering, and a frontend web interface for interactive steering and ReFT interventions.

CodeGeeX4
CodeGeeX4-ALL-9B is an open-source multilingual code generation model based on GLM-4-9B, offering enhanced code generation capabilities. It supports functions like code completion, code interpreter, web search, function call, and repository-level code Q&A. The model has competitive performance on benchmarks like BigCodeBench and NaturalCodeBench, outperforming larger models in terms of speed and performance.

DB-GPT-Hub
DB-GPT-Hub is an experimental project leveraging Large Language Models (LLMs) for Text-to-SQL parsing. It includes stages like data collection, preprocessing, model selection, construction, and fine-tuning of model weights. The project aims to enhance Text-to-SQL capabilities, reduce model training costs, and enable developers to contribute to improving Text-to-SQL accuracy. The ultimate goal is to achieve automated question-answering based on databases, allowing users to execute complex database queries using natural language descriptions. The project has successfully integrated multiple large models and established a comprehensive workflow for data processing, SFT model training, prediction output, and evaluation.

LTEngine
LTEngine is a free and open-source local AI machine translation API written in Rust. It is self-hosted and compatible with LibreTranslate. LTEngine utilizes large language models (LLMs) via llama.cpp, offering high-quality translations that rival or surpass DeepL for certain languages. It supports various accelerators like CUDA, Metal, and Vulkan, with the largest model 'gemma3-27b' fitting on a single consumer RTX 3090. LTEngine is actively developed, with a roadmap outlining future enhancements and features.

Consistency_LLM
Consistency Large Language Models (CLLMs) is a family of efficient parallel decoders that reduce inference latency by efficiently decoding multiple tokens in parallel. The models are trained to perform efficient Jacobi decoding, mapping any randomly initialized token sequence to the same result as auto-regressive decoding in as few steps as possible. CLLMs have shown significant improvements in generation speed on various tasks, achieving up to 3.4 times faster generation. The tool provides a seamless integration with other techniques for efficient Large Language Model (LLM) inference, without the need for draft models or architectural modifications.

vision-parse
Vision Parse is a tool that leverages Vision Language Models to parse PDF documents into beautifully formatted markdown content. It offers smart content extraction, content formatting, multi-LLM support, PDF document support, and local model hosting using Ollama. Users can easily convert PDFs to markdown with high precision and preserve document hierarchy and styling. The tool supports multiple Vision LLM providers like OpenAI, LLama, and Gemini for accuracy and speed, making document processing efficient and effortless.

BetaML.jl
The Beta Machine Learning Toolkit is a package containing various algorithms and utilities for implementing machine learning workflows in multiple languages, including Julia, Python, and R. It offers a range of supervised and unsupervised models, data transformers, and assessment tools. The models are implemented entirely in Julia and are not wrappers for third-party models. Users can easily contribute new models or request implementations. The focus is on user-friendliness rather than computational efficiency, making it suitable for educational and research purposes.
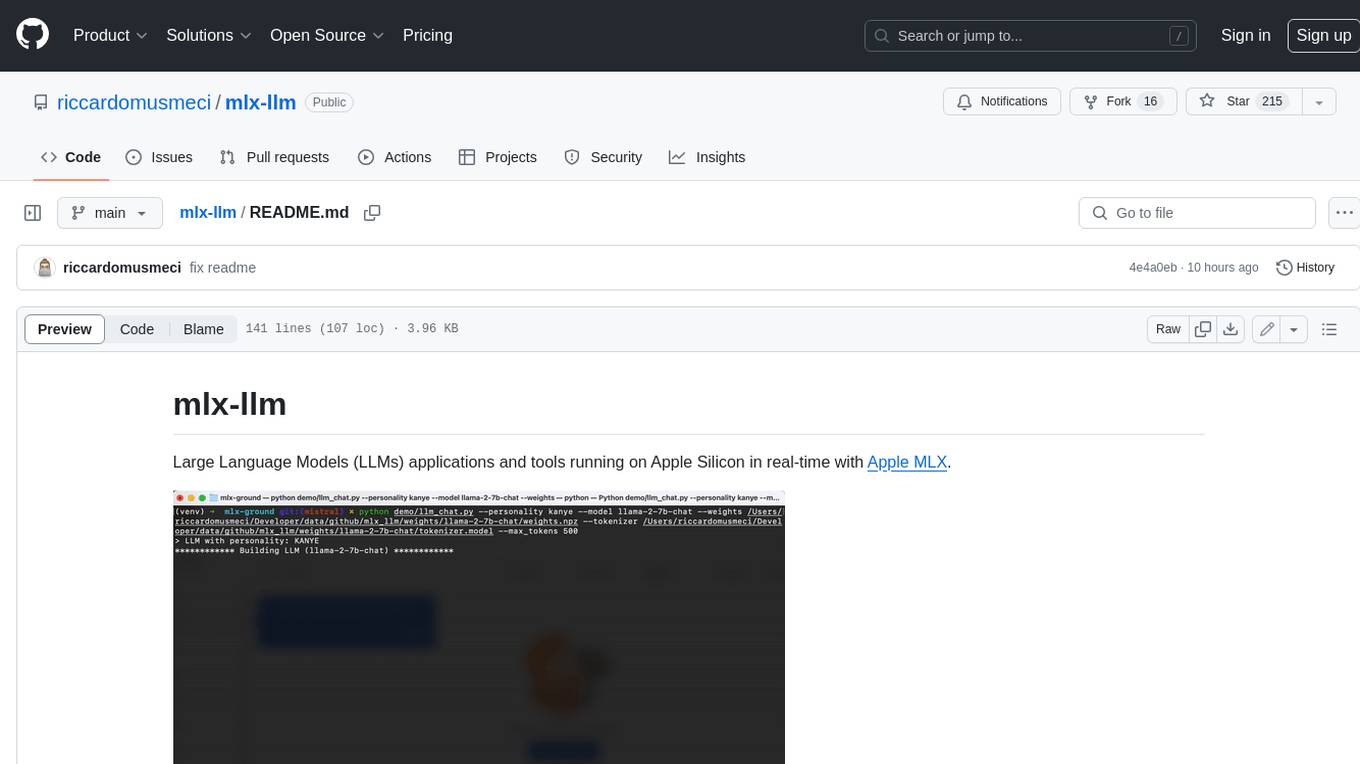
mlx-llm
mlx-llm is a library that allows you to run Large Language Models (LLMs) on Apple Silicon devices in real-time using Apple's MLX framework. It provides a simple and easy-to-use API for creating, loading, and using LLM models, as well as a variety of applications such as chatbots, fine-tuning, and retrieval-augmented generation.
evalica
Evalica is a powerful tool for evaluating code quality and performance in software projects. It provides detailed insights and metrics to help developers identify areas for improvement and optimize their code. With support for multiple programming languages and frameworks, Evalica offers a comprehensive solution for code analysis and optimization. Whether you are a beginner looking to learn best practices or an experienced developer aiming to enhance your code quality, Evalica is the perfect tool for you.

pytorch-grad-cam
This repository provides advanced AI explainability for PyTorch, offering state-of-the-art methods for Explainable AI in computer vision. It includes a comprehensive collection of Pixel Attribution methods for various tasks like Classification, Object Detection, Semantic Segmentation, and more. The package supports high performance with full batch image support and includes metrics for evaluating and tuning explanations. Users can visualize and interpret model predictions, making it suitable for both production and model development scenarios.

LongLoRA
LongLoRA is a tool for efficient fine-tuning of long-context large language models. It includes LongAlpaca data with long QA data collected and short QA sampled, models from 7B to 70B with context length from 8k to 100k, and support for GPTNeoX models. The tool supports supervised fine-tuning, context extension, and improved LoRA fine-tuning. It provides pre-trained weights, fine-tuning instructions, evaluation methods, local and online demos, streaming inference, and data generation via Pdf2text. LongLoRA is licensed under Apache License 2.0, while data and weights are under CC-BY-NC 4.0 License for research use only.
For similar tasks
AutoGPTQ
AutoGPTQ is an easy-to-use LLM quantization package with user-friendly APIs, based on GPTQ algorithm (weight-only quantization). It provides a simple and efficient way to quantize large language models (LLMs) to reduce their size and computational cost while maintaining their performance. AutoGPTQ supports a wide range of LLM models, including GPT-2, GPT-J, OPT, and BLOOM. It also supports various evaluation tasks, such as language modeling, sequence classification, and text summarization. With AutoGPTQ, users can easily quantize their LLM models and deploy them on resource-constrained devices, such as mobile phones and embedded systems.

Qwen-TensorRT-LLM
Qwen-TensorRT-LLM is a project developed for the NVIDIA TensorRT Hackathon 2023, focusing on accelerating inference for the Qwen-7B-Chat model using TRT-LLM. The project offers various functionalities such as FP16/BF16 support, INT8 and INT4 quantization options, Tensor Parallel for multi-GPU parallelism, web demo setup with gradio, Triton API deployment for maximum throughput/concurrency, fastapi integration for openai requests, CLI interaction, and langchain support. It supports models like qwen2, qwen, and qwen-vl for both base and chat models. The project also provides tutorials on Bilibili and blogs for adapting Qwen models in NVIDIA TensorRT-LLM, along with hardware requirements and quick start guides for different model types and quantization methods.

stable-diffusion.cpp
The stable-diffusion.cpp repository provides an implementation for inferring stable diffusion in pure C/C++. It offers features such as support for different versions of stable diffusion, lightweight and dependency-free implementation, various quantization support, memory-efficient CPU inference, GPU acceleration, and more. Users can download the built executable program or build it manually. The repository also includes instructions for downloading weights, building from scratch, using different acceleration methods, running the tool, converting weights, and utilizing various features like Flash Attention, ESRGAN upscaling, PhotoMaker support, and more. Additionally, it mentions future TODOs and provides information on memory requirements, bindings, UIs, contributors, and references.

LMOps
LMOps is a research initiative focusing on fundamental research and technology for building AI products with foundation models, particularly enabling AI capabilities with Large Language Models (LLMs) and Generative AI models. The project explores various aspects such as prompt optimization, longer context handling, LLM alignment, acceleration of LLMs, LLM customization, and understanding in-context learning. It also includes tools like Promptist for automatic prompt optimization, Structured Prompting for efficient long-sequence prompts consumption, and X-Prompt for extensible prompts beyond natural language. Additionally, LLMA accelerators are developed to speed up LLM inference by referencing and copying text spans from documents. The project aims to advance technologies that facilitate prompting language models and enhance the performance of LLMs in various scenarios.

Awesome-Efficient-LLM
Awesome-Efficient-LLM is a curated list focusing on efficient large language models. It includes topics such as knowledge distillation, network pruning, quantization, inference acceleration, efficient MOE, efficient architecture of LLM, KV cache compression, text compression, low-rank decomposition, hardware/system, tuning, and survey. The repository provides a collection of papers and projects related to improving the efficiency of large language models through various techniques like sparsity, quantization, and compression.

TensorRT-Model-Optimizer
The NVIDIA TensorRT Model Optimizer is a library designed to quantize and compress deep learning models for optimized inference on GPUs. It offers state-of-the-art model optimization techniques including quantization and sparsity to reduce inference costs for generative AI models. Users can easily stack different optimization techniques to produce quantized checkpoints from torch or ONNX models. The quantized checkpoints are ready for deployment in inference frameworks like TensorRT-LLM or TensorRT, with planned integrations for NVIDIA NeMo and Megatron-LM. The tool also supports 8-bit quantization with Stable Diffusion for enterprise users on NVIDIA NIM. Model Optimizer is available for free on NVIDIA PyPI, and this repository serves as a platform for sharing examples, GPU-optimized recipes, and collecting community feedback.
lightning-bolts
Bolts package provides a variety of components to extend PyTorch Lightning, such as callbacks & datasets, for applied research and production. Users can accelerate Lightning training with the Torch ORT Callback to optimize ONNX graph for faster training & inference. Additionally, users can introduce sparsity with the SparseMLCallback to accelerate inference by leveraging the DeepSparse engine. Specific research implementations are encouraged, with contributions that help train SSL models and integrate with Lightning Flash for state-of-the-art models in applied research.

ms-swift
ms-swift is an official framework provided by the ModelScope community for fine-tuning and deploying large language models and multi-modal large models. It supports training, inference, evaluation, quantization, and deployment of over 400 large models and 100+ multi-modal large models. The framework includes various training technologies and accelerates inference, evaluation, and deployment modules. It offers a Gradio-based Web-UI interface and best practices for easy application of large models. ms-swift supports a wide range of model types, dataset types, hardware support, lightweight training methods, distributed training techniques, quantization training, RLHF training, multi-modal training, interface training, plugin and extension support, inference acceleration engines, model evaluation, and model quantization.
For similar jobs
AutoGPTQ
AutoGPTQ is an easy-to-use LLM quantization package with user-friendly APIs, based on GPTQ algorithm (weight-only quantization). It provides a simple and efficient way to quantize large language models (LLMs) to reduce their size and computational cost while maintaining their performance. AutoGPTQ supports a wide range of LLM models, including GPT-2, GPT-J, OPT, and BLOOM. It also supports various evaluation tasks, such as language modeling, sequence classification, and text summarization. With AutoGPTQ, users can easily quantize their LLM models and deploy them on resource-constrained devices, such as mobile phones and embedded systems.

hqq
HQQ is a fast and accurate model quantizer that skips the need for calibration data. It's super simple to implement (just a few lines of code for the optimizer). It can crunch through quantizing the Llama2-70B model in only 4 minutes! 🚀