Best AI tools for< Model Quantization >
Infographic
20 - AI tool Sites

Private LLM
Private LLM is a secure, local, and private AI chatbot designed for iOS and macOS devices. It operates offline, ensuring that user data remains on the device, providing a safe and private experience. The application offers a range of features for text generation and language assistance, utilizing state-of-the-art quantization techniques to deliver high-quality on-device AI experiences without compromising privacy. Users can access a variety of open-source LLM models, integrate AI into Siri and Shortcuts, and benefit from AI language services across macOS apps. Private LLM stands out for its superior model performance and commitment to user privacy, making it a smart and secure tool for creative and productive tasks.

Enhans AI Model Generator
Enhans AI Model Generator is an advanced AI tool designed to help users generate AI models efficiently. It utilizes cutting-edge algorithms and machine learning techniques to streamline the model creation process. With Enhans AI Model Generator, users can easily input their data, select the desired parameters, and obtain a customized AI model tailored to their specific needs. The tool is user-friendly and does not require extensive programming knowledge, making it accessible to a wide range of users, from beginners to experts in the field of AI.
Frontier Model Forum
The Frontier Model Forum (FMF) is a collaborative effort among leading AI companies to advance AI safety and responsibility. The FMF brings together technical and operational expertise to identify best practices, conduct research, and support the development of AI applications that meet society's most pressing needs. The FMF's core objectives include advancing AI safety research, identifying best practices, collaborating across sectors, and helping AI meet society's greatest challenges.
Role Model AI
Role Model AI is a revolutionary multi-dimensional assistant that combines practicality and innovation. It offers four dynamic interfaces for seamless interaction: phone calls for on-the-go assistance, an interactive agent dashboard for detailed task management, lifelike 3D avatars for immersive communication, and an engaging Fortnite world integration for a gaming-inspired experience. Role Model AI adapts to your lifestyle, blending seamlessly into your personal and professional worlds, providing unparalleled convenience and a unique, versatile solution for managing tasks and interactions.

Flux LoRA Model Library
Flux LoRA Model Library is an AI tool that provides a platform for finding and using Flux LoRA models suitable for various projects. Users can browse a catalog of popular Flux LoRA models and learn about FLUX models and LoRA (Low-Rank Adaptation) technology. The platform offers resources for fine-tuning models and ensuring responsible use of generated images.
OpenAI Strawberry Model
OpenAI Strawberry Model is a cutting-edge AI initiative that represents a significant leap in AI capabilities, focusing on enhancing reasoning, problem-solving, and complex task execution. It aims to improve AI's ability to handle mathematical problems, programming tasks, and deep research, including long-term planning and action. The project showcases advancements in AI safety and aims to reduce errors in AI responses by generating high-quality synthetic data for training future models. Strawberry is designed to achieve human-like reasoning and is expected to play a crucial role in the development of OpenAI's next major model, codenamed 'Orion.'

Ray3 AI Video Model
Ray3 is a cutting-edge AI video model developed by Luma, designed to revolutionize HDR video creation for storytellers worldwide. With its native 16-bit HDR output, intelligent scene reasoning, and precise keyframe control, Ray3 empowers creators to generate professional-quality 4K HDR videos with unparalleled creative freedom. It goes beyond simple text-to-video generation, offering a complete creative partnership for modern storytellers, enabling them to bring their cinematic visions to life effortlessly.

HUAWEI Cloud Pangu Drug Molecule Model
HUAWEI Cloud Pangu is an AI tool designed for accelerating drug discovery by optimizing drug molecules. It offers features such as Molecule Search, Molecule Optimizer, and Pocket Molecule Design. Users can submit molecules for optimization and view historical optimization results. The tool is based on the MindSpore framework and has been visited over 300,000 times since August 23, 2021.

LiteLLM
LiteLLM is a platform that simplifies model access, spend tracking, and fallbacks across 100+ LLMs. It provides a gateway to manage model access and offers features like logging, budget tracking, pass-through endpoints, and self-serve key management. LiteLLM is open-source and compatible with the OpenAI format, allowing users to access various LLMs seamlessly.
Sapling
Sapling is a language model copilot and API for businesses. It provides real-time suggestions to help sales, support, and success teams more efficiently compose personalized responses. Sapling also offers a variety of features to help businesses improve their customer service, including: * Autocomplete Everywhere: Provides deep learning-powered autocomplete suggestions across all messaging platforms, allowing agents to compose replies more quickly. * Sapling Suggest: Retrieves relevant responses from a team response bank and allows agents to respond more quickly to customer inquiries by simply clicking on suggested responses in real time. * Snippet macros: Allow for quick insertion of common responses. * Grammar and language quality improvements: Sapling catches 60% more language quality issues than other spelling and grammar checkers using a machine learning system trained on millions of English sentences. * Enterprise teams can define custom settings for compliance and content governance. * Distribute knowledge: Ensure team knowledge is shared in a snippet library accessible on all your web applications. * Perform blazing fast search on your knowledge library for compliance, upselling, training, and onboarding.
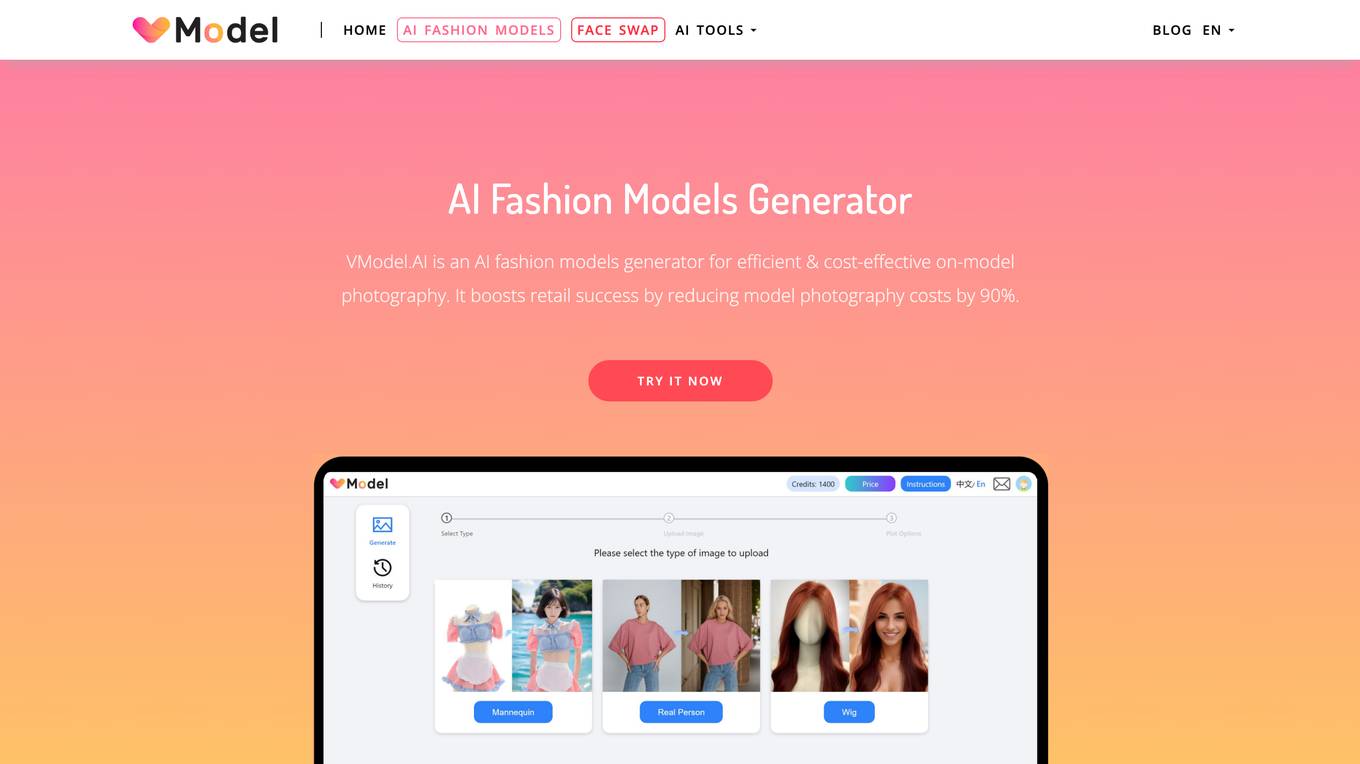
VModel.AI
VModel.AI is an AI fashion models generator that revolutionizes on-model photography for fashion retailers. It utilizes artificial intelligence to create high-quality on-model photography without the need for elaborate photoshoots, reducing model photography costs by 90%. The tool helps diversify stores, improve E-commerce engagement, reduce returns, promote diversity and inclusion in fashion, and enhance product offerings.
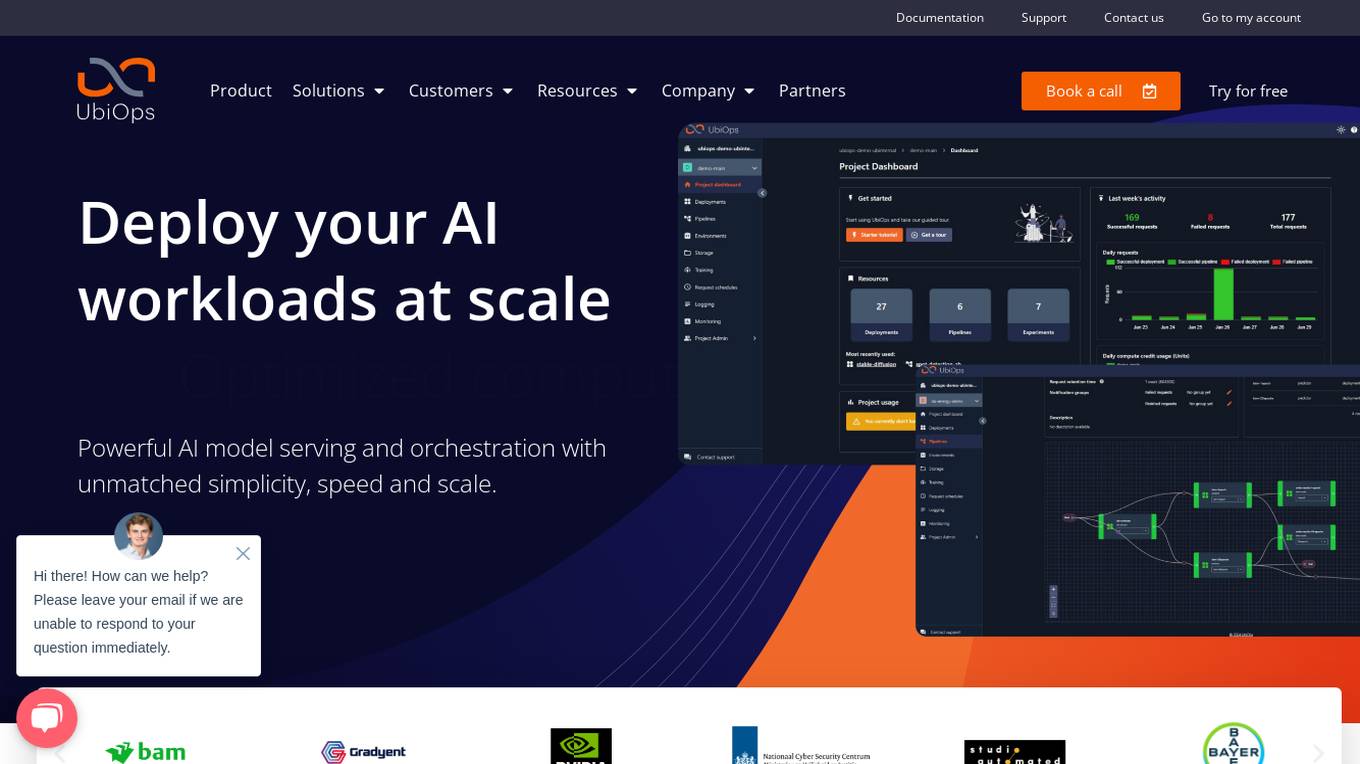
UbiOps
UbiOps is an AI infrastructure platform that helps teams quickly run their AI & ML workloads as reliable and secure microservices. It offers powerful AI model serving and orchestration with unmatched simplicity, speed, and scale. UbiOps allows users to deploy models and functions in minutes, manage AI workloads from a single control plane, integrate easily with tools like PyTorch and TensorFlow, and ensure security and compliance by design. The platform supports hybrid and multi-cloud workload orchestration, rapid adaptive scaling, and modular applications with unique workflow management system.
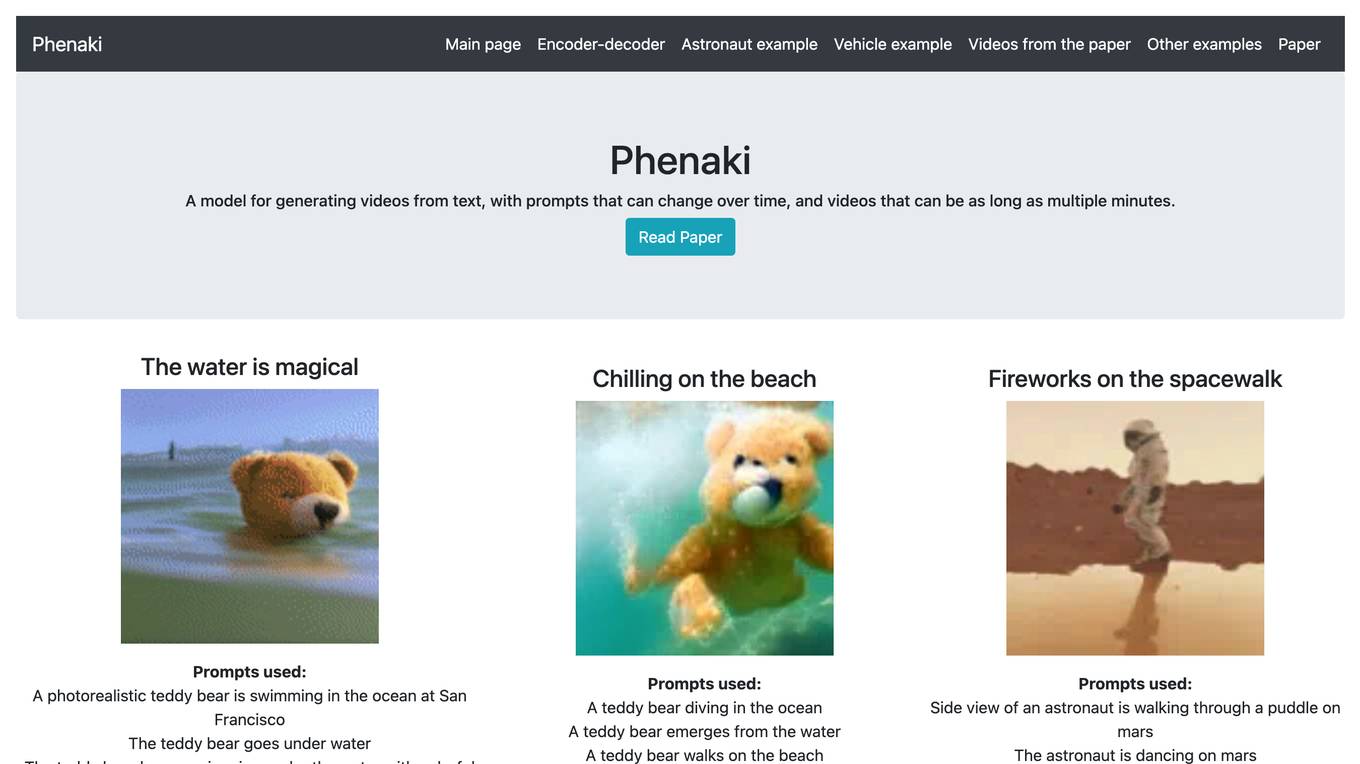
Phenaki
Phenaki is a model capable of generating realistic videos from a sequence of textual prompts. It is particularly challenging to generate videos from text due to the computational cost, limited quantities of high-quality text-video data, and variable length of videos. To address these issues, Phenaki introduces a new causal model for learning video representation, which compresses the video to a small representation of discrete tokens. This tokenizer uses causal attention in time, which allows it to work with variable-length videos. To generate video tokens from text, Phenaki uses a bidirectional masked transformer conditioned on pre-computed text tokens. The generated video tokens are subsequently de-tokenized to create the actual video. To address data issues, Phenaki demonstrates how joint training on a large corpus of image-text pairs as well as a smaller number of video-text examples can result in generalization beyond what is available in the video datasets. Compared to previous video generation methods, Phenaki can generate arbitrarily long videos conditioned on a sequence of prompts (i.e., time-variable text or a story) in an open domain. To the best of our knowledge, this is the first time a paper studies generating videos from time-variable prompts. In addition, the proposed video encoder-decoder outperforms all per-frame baselines currently used in the literature in terms of spatio-temporal quality and the number of tokens per video.
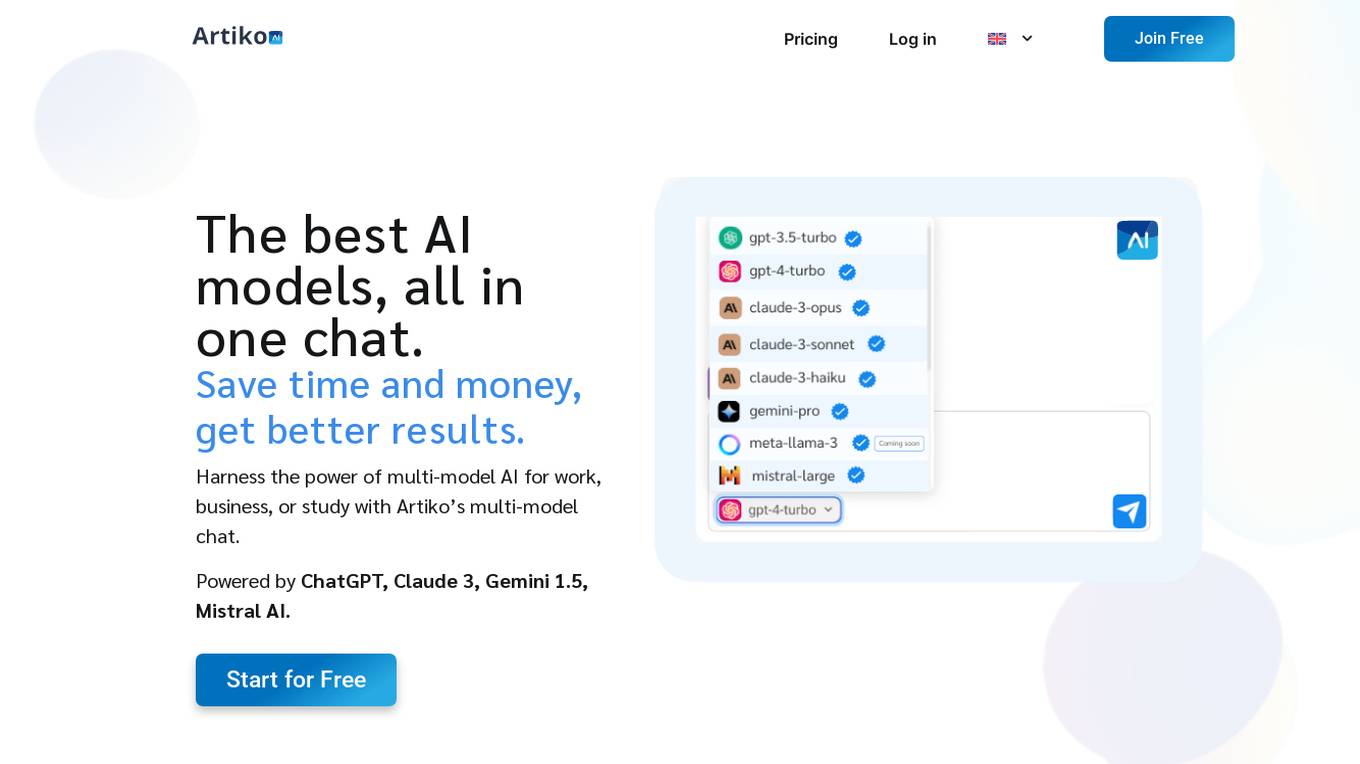
Artiko.ai
Artiko.ai is a multi-model AI chat platform that integrates advanced AI models such as ChatGPT, Claude 3, Gemini 1.5, and Mistral AI. It offers a convenient and cost-effective solution for work, business, or study by providing a single chat interface to harness the power of multi-model AI. Users can save time and money while achieving better results through features like text rewriting, data conversation, AI assistants, website chatbot, PDF and document chat, translation, brainstorming, and integration with various tools like Woocommerce, Amazon, Salesforce, and more.
LLMWise
LLMWise is a multi-model LLM API tool that allows users to compare, blend, and route AI models simultaneously. It offers 5 modes - Chat, Compare, Blend, Judge, and Failover - to help users make informed decisions based on model outputs. With 31+ available models, LLMWise provides a user-friendly platform for orchestrating AI models, ensuring reliability, and optimizing costs. The tool is designed to streamline the integration of various AI models through one API call, offering features like real-time responses, per-model metrics, and failover routing.

Claude
Claude is a large multi-modal model, trained by Google. It is similar to GPT-3, but it is trained on a larger dataset and with more advanced techniques. Claude is capable of generating human-like text, translating languages, answering questions, and writing different kinds of creative content.

SuperAnnotate
SuperAnnotate is an AI data platform that simplifies and accelerates model-building by unifying the AI pipeline. It enables users to create, curate, and evaluate datasets efficiently, leading to the development of better models faster. The platform offers features like connecting any data source, building customizable UIs, creating high-quality datasets, evaluating models, and deploying models seamlessly. SuperAnnotate ensures global security and privacy measures for data protection.
Infermatic.ai
Infermatic.ai is a platform that provides access to top Large Language Models (LLMs) with a user-friendly interface. It offers complete privacy, robust security, and scalability for projects, research, and integrations. Users can test, choose, and scale LLMs according to their content needs or business strategies. The platform eliminates the complexities of infrastructure management, latency issues, version control problems, integration complexities, scalability concerns, and cost management issues. Infermatic.ai is designed to be secure, intuitive, and efficient for users who want to leverage LLMs for various tasks.
GPT4All
GPT4All is a web-based platform that allows users to access the GPT-4 language model. GPT-4 is a large language model that can be used for a variety of tasks, including text generation, translation, question answering, and code generation. GPT4All makes it easy for users to get started with GPT-4, without having to worry about the technical details of setting up and running the model.
Together AI
Together AI is an AI tool that offers a variety of generative AI services, including serverless models, fine-tuning capabilities, dedicated endpoints, and GPU clusters. Users can run or fine-tune leading open source models with only a few lines of code. The platform provides a range of functionalities for tasks such as chat, vision, text-to-speech, code/language reranking, and more. Together AI aims to simplify the process of utilizing AI models for various applications.
2 - Open Source Tools

AutoGPTQ
AutoGPTQ is an easy-to-use LLM quantization package with user-friendly APIs, based on GPTQ algorithm (weight-only quantization). It provides a simple and efficient way to quantize large language models (LLMs) to reduce their size and computational cost while maintaining their performance. AutoGPTQ supports a wide range of LLM models, including GPT-2, GPT-J, OPT, and BLOOM. It also supports various evaluation tasks, such as language modeling, sequence classification, and text summarization. With AutoGPTQ, users can easily quantize their LLM models and deploy them on resource-constrained devices, such as mobile phones and embedded systems.

hqq
HQQ is a fast and accurate model quantizer that skips the need for calibration data. It's super simple to implement (just a few lines of code for the optimizer). It can crunch through quantizing the Llama2-70B model in only 4 minutes! 🚀
20 - OpenAI Gpts


Seabiscuit Business Model Master
Discover A More Robust Business: Craft tailored value proposition statements, develop a comprehensive business model canvas, conduct detailed PESTLE analysis, and gain strategic insights on enhancing business model elements like scalability, cost structure, and market competition strategies. (v1.18)

Create A Business Model Canvas For Your Business
Let's get started by telling me about your business: What do you offer? Who do you serve? ------------------------------------------------------- Need help Prompt Engineering? Reach out on LinkedIn: StephenHnilica

Business Model Canvas Strategist
Business Model Canvas Creator - Build and evaluate your business model
BITE Model Analyzer by Dr. Steven Hassan
Discover if your group, relationship or organization uses specific methods to recruit and maintain control over people
EIA model
Generates Environmental impact assessment templates based on specific global locations and parameters.
Business Model Canvas Wizard
Un aiuto a costruire il Business Model Canvas della tua iniziativa
Business Model Advisor
Business model expert, create detailed reports based on business ideas.



AI Model NFT Marketplace- Joy Marketplace
Expert on AI Model NFT Marketplace, offering insights on blockchain tech and NFTs.
SUPER PROMPTER Advanced GPT Model 10to100 Role
Super Prompter is an AI model designed to create high-quality prompts for chatbots. It thinks like a human in crafting prompts, leveraging various methods like the role method, knowledge level method, and emotion method. This AI model has the capability to generate prompts for any given scenario
Picture Creator🎨
Model Vibe Picture Creator: Unleash Your Imagination! 🎨📸 Generates detailed, cool prompts for stylized images, perfect for AI tools like DALL-E 3. 🔥👾