
factorio-learning-environment
A non-saturating, open-ended environment for evaluating LLMs in Factorio
Stars: 783

Factorio Learning Environment is an open source framework designed for developing and evaluating LLM agents in the game of Factorio. It provides two settings: Lab-play with structured tasks and Open-play for building large factories. Results show limitations in spatial reasoning and automation strategies. Agents interact with the environment through code synthesis, observation, action, and feedback. Tools are provided for game actions and state representation. Agents operate in episodes with observation, planning, and action execution. Tasks specify agent goals and are implemented in JSON files. The project structure includes directories for agents, environment, cluster, data, docs, eval, and more. A database is used for checkpointing agent steps. Benchmarks show performance metrics for different configurations.
README:
Leaderboard | Paper | Website| Discord
An open source framework for developing and evaluating LLM agents in the game of Factorio.


Claude 3.5 plays Factorio
We provide two settings:
- Lab-play: 24 structured tasks with fixed resources.
- Open-play An unbounded task of building the largest possible factory on a procedurally generated map.
Our results demonstrate that models still lack strong spatial reasoning. In lab-play, we find that while LLMs exhibit promising short-horizon skills, they are unable to operate effectively in constrained environments, reflecting limitations in error analysis. In open-play, while LLMs discover automation strategies that improve growth (e.g electric-powered drilling), they fail to achieve complex automation (e.g electronic-circuit manufacturing).
- [08/5/2025] Blog: Added support for multi-agent coordination and MCP allowing reasoning models to invoke tools within their reasoning chain
- [15/4/2025] Added a visual agent, that takes a rendering of the map as an additional input.
- Installation
- Environment
- Agents
- Tasks
- Multiagent Experiments
- Tools
- Project Structure
- Database
- Benchmarks
- Contributions
- Factorio (version 1.1.110)
- Docker
- Python 3.10+
You can install the factorio-learning-environment package using either uv or pip:
# Install from PyPI using uv
uv add factorio-learning-environment
# Install from PyPI using pip
pip install factorio-learning-environmentAfter installation, you can use the CLI:
# Start Docker image
fle cluster
# Run evaluation (auto-starts cluster if needed)
fle eval --config configs/gym_run_config.jsonWhen you run
flefor the first time, an.envfile and aconfigs/directory with example configurations are created automatically
Or import the package in your Python code:
import fleFLE can also be used as a gym environment for reinforcement learning experiments. See the Gym Environment Registry section for details.
-
Set up Factorio client:
- Purchase Factorio from the official website (recommended) or on Steam.
- Downgrade to version 1.1.110:
- Steam: Right-click Factorio → Properties → Betas → Select 1.1.110
- Important: Make sure to uncheck the Space Age DLC if you have it, as it forces the 2.x branch
-
Activate server:
- Open Factorio client
- Navigate to Multiplayer
- Connect to
localhost:34197(default) or your configured address in Docker.- Once connected, you can safely disconnect. This step confirms your Factorio license with the server.
- "No valid programs found for version X": This is normal during initialization. The system will start generating programs shortly.
- Database connection errors: Verify your database configuration in the .env file and ensure the database exists.
-
Docker issues: Ensure your user has permission to run Docker without sudo.
- For macOS and Windows:
- Open Docker Desktop application
- For Linux:
- Start Docker daemon with
sudo systemctl start docker - If you typically run Docker with sudo, add your user to the docker group:
sudo usermod -aG docker $USER newgrp docker
- Start Docker daemon with
- For macOS and Windows:
- Connection issues: Make sure the Factorio server is running and ports are properly configured.
FLE is an agent evaluation environment built on the game of Factorio, a popular resource management simulation game.
Agents interact with FLE by code synthesis through a REPL (Read-Eval-Print-Loop) pattern:
- Observation: The agent observes the world through the output streams (stderr/stdout) of their last program.
- Action: The agent generates a Python program to perform their desired action.
- Feedback: The environment executes the program, assigns variables, add classes/functions to the namespace, and provides an output stream.
Action
# 1. Get iron patch and place mining drill
drill = place_entity(
entity=Prototype.MiningDrill,
position=nearest(Resource.IronOre),
direction=Direction.NORTH
)
# 2. Add output storage
chest = place_entity_next_to(
entity=Prototype.IronChest,
reference_position=drill.drop_position,
direction=Direction.SOUTH
)
# 3. Verify automation chain and observe entities
sleep(10) # Sleep for 10 seconds
assert drill.status == EntityStatus.WORKING
print(get_entities())
|
Feedback
>>> [ BurnerMiningDrill(fuel=Inventory({'coal': 4}),
>>> name='burner-mining-drill',
>>> direction=Direction.DOWN,
>>> position=Position(x=-28.0, y=-61.0),
>>> energy=2666.6666666667,
>>> tile_dimensions=TileDimensions(tile_width=2.0, tile_height=2.0),
>>> status=EntityStatus.WORKING,
>>> neighbours=[Entity(name='iron-chest', direction=DOWN, position=Position(x=-27.5 y=-59.5)],
>>> drop_position=Position(x=-27.5, y=-59.5),
>>> resources=[Ingredient(name='iron-ore', count=30000, type=None)]),
>>> Chest(name='iron-chest',
>>> direction=Direction.UP,
>>> position=Position(x=-27.5, y=-59.5),
>>> energy=0.0,
>>> tile_dimensions=TileDimensions(tile_width=1.0, tile_height=1.0),
>>> status=EntityStatus.NORMAL,
>>> inventory=Inventory({'iron-ore': 75}))]
|
Agents are provided with the Python standard library, and an API comprising tools that they can use.
Tools are functions that perform a game action and return a typed object (e.g an Inventory), which can be stored as a named variable in the Python namespace for later use.
The namespace acts as an episodic symbolic memory system, and saved objects represent an observation of the environment at the moment of query.
This enables agents to maintain complex state representations and build hierarchical abstractions as the factories scale.
Agents observe stdout and stderr - the output streams of their program. Agents may intentionally choose to print relevant objects and computations to the output stream to construct observations.
Mistakes in the code or invalid operations raise typed exceptions with detailed context that is written to stderr.
This enables agents to reactively debug their programs after execution, and proactively use runtime assertions during execution to self-verify their actions.
Agents are able to enhance their internal representation of the game state by defining:
- Utility functions for reuse throughout an episode, to encapsulate previously successful logic
- Classes in the namespace to better organize the data retrieved from the game.
The Factorio Learning Environment provides a straightforward agent architecture for developing and evaluating AI models that can play Factorio.
Agents operate in episodes, with each step involving observation, planning, and action execution through Python code synthesis. The agent maintains state through a conversation history that includes its actions (assistant) and the stdout/stderr from the environment (user). At each step, agents generate Python code policies that are executed in the environment.
Agents live in agents, and implement an abstract base class (AgentABC) that defines the core interface for interacting with the environment.
The abstract base class defines two methods that all agents must implement:
# Generates the next action based on conversation history and environment response (including score / achievements etc).
step(conversation: Conversation, response: Response) -> Policy:
# Handles cleanup when an episode terminates, i.e for reporting results etc.
end(conversation: Conversation, completion: CompletionState) -> None:
Each agent takes input a task (discussed in the next section) which specifies the goal of the agent.
Our default agent is BasicAgent, which incorporates some basic mechanisms for managing context over long (+1000 step) runs:
- Every 32 steps, the all older interactions are summarised into a report in the system message.
- Conversations are clipped to remain under 200k characters (~87k tokens).
- We strip out all historical observations of game entities, as this both fills up the context, and confuses the agent.
We include some basic utilities for calling different LLMs (agents/utils/llm_factory.py), for formatting the conversation history (agents/utils/formatters/conversation_formatter_abc.py), and for parsing responses into valid Python (agents/utils/parse_response.py)
# ./agents/minimal_agent.py
class MinimalAgent(AgentABC):
"""
This is a minimal Agent implementation, which takes the current conversation (including the most recent response)
and generates a simple Python code policy to execute the next step.
Note: This will blow up context length on longer runs, without some context pruning/management.
"""
def __init__(self, model, system_prompt, goal_description, *args, **kwargs):
system_prompt += f"\n\n### Goal\n{goal_description}\n\n"
super().__init__(model, system_prompt, *args, **kwargs)
self.llm_factory = LLMFactory(model)
@tenacity.retry(
retry=retry_if_exception_type(Exception),
wait=wait_exponential(multiplier=1, min=4, max=10)
)
async def step(self, conversation: Conversation, response: Response) -> Policy:
# Generate and return next policy
response = await self.llm_factory.acall(
messages=self.formatter.to_llm_messages(conversation),
n_samples=1, # We only need one program per iteration
temperature=self.generation_params.temperature,
max_tokens=self.generation_params.max_tokens,
model=self.generation_params.model,
)
# Parse LLM response into a Policy object
policy = parse_response(response)
if not policy:
raise Exception("Not a valid Python policy")
return policy
async def end(self, conversation: Conversation, completion: CompletionResult):
passEach agent is given a task, which specifies the goal the agent will carry out in FLE. A task consists of a task object defining the core interface of the task category and a json file specifying the parameters of the task.
Tasks live in eval/tasks, and implement an abstract base class in eval/tasks/task_abc.py that defines the core interface for defining the task, setting up the environment and verifying success
The abstract base class defines three methods that all tasks must implement:
verify(self, score: float, step: int, instance: FactorioInstance, step_statistics: Dict) -> bool:
""" Return true if the task is completed"""
setup_instance(self, instance):
"""Code to provision the initial game state for the task environment"""
enhance_response_with_task_output(self, response: str, task_response: TaskResponse) -> str:
"""Add task specific information to the environment response if needed"""
We provide two default tasks:
- OpenPlayTask - Task for the open-play setting, where the agent plays the game until a specified number of steps is finished. The verify function will always return False
- ThroughputTask - Task for requiring the agent to build a factory that achieves a specified throughput in the holdout period. The verify function will return True if the holdout period throughput is above the threshold
- UnboundedThroughputTask - Task for the agent to create a factory that maximises the throughput of a target entity in a specified number of timesteps. The verify function will always return False until the number of steps is reached
The task jsons specifies the "task_type" and the "config" parameters.
task_typespecifies the mapping from the json to the task type (the creation of task objects from the json is done ineval\tasks\task_factory.py).configspecifies all required attributes to substantiate the respective task object. Each config must at minimum define the "goal_description", "trajectory_length" and "task_key" parameters. Examples of task json
# Open play task json
{ "task_type": "default",
"config": {
"goal_description":"- Build the biggest possible factory\n- Maximise automation, efficiency and scale",
"trajectory_length": 5000,
"task_key": "open_play"
}
}
# One example of a throughput task json
{
"task_type": "throughput",
"config":
{"goal_description":"Create an automatic iron gear wheel factory that produces 16 iron gear wheel per 60 ingame seconds",
"throughput_entity":"iron-gear-wheel",
"quota":16,
"trajectory_length": 128,
"holdout_wait_period": 60,
"pre_holdout_wait_period": 60,
"task_key": "iron_gear_wheel_throughput_16"}
}
Example open play task object can be seen below. The throughput task object can be found here eval/tasks/throughput_task.py
class OpenPlayTask(TaskABC):
def __init__(self, trajectory_length, goal_description: str, task_key: str):
super().__init__(trajectory_length, starting_inventory = {}, goal_description=goal_description, task_key = task_key)
self.starting_game_state = None
def verify(self, score: float, instance: FactorioInstance, step_statistics: Dict) -> TaskResponse:
return TaskResponse(success = False,
meta = {})
def _to_dict(self) -> Dict[str, Any]:
return {
"goal_description": self.goal_description,
"trajectory_length": self.trajectory_length,
"starting_inventory": self.starting_inventory,
"initial_state": self.starting_game_state.to_raw() if self.starting_game_state else None,
}
def setup_instance(self, instance):
"""Code to provision the task environment"""
pass
The entrypoint to run tasks is env/src/gym_env/run_eval.py which reads in a run config json file, runs the tasks specified in parallel and saves each generated program with the environment output and task verification result into the database. The location of the run config json is sent in through the --run_config inline argument. If no argument is sent, the default run config eval/open/independent_runs/gym_run_config.json is used.
The run config json is a list of dictionaries specifying the gym environment ID, model and version (optional). One example to run 2s tasks in parallel:
[
{
"env_id": "Factorio-iron_ore_throughput_16-v0",
"model": "claude-3-5-sonnet-latest"
},
{
"env_id": "Factorio-open_play-v0",
"model": "claude-3-5-sonnet-latest"
}
]Each task is run until either verify returns True or the maximum number of steps (trajectory_length) is reached.
The Factorio Learning Environment uses a gym environment registry to automatically discover and register all available tasks. This allows you to use gym.make() to create environments and reference them by their environment IDs.
The registry system automatically discovers all task definitions in eval/tasks/task_definitions/ and registers them as gym environments. This means you can create any Factorio environment using the familiar gym.make() pattern.
-
Automatic Discovery: Automatically discovers all task definitions in
eval/tasks/task_definitions/ -
Gym Integration: All environments are registered with
gymand can be created usinggym.make() - Task Metadata: Provides access to task descriptions, configurations, and metadata
- Multi-agent Support: Supports both single-agent and multi-agent environments
- Command-line Tools: Built-in tools for exploring and testing environments
1. List Available Environments
from gym_env.registry import list_available_environments
# Get all available environment IDs
env_ids = list_available_environments()
print(f"Available environments: {env_ids}")Or use the command-line tool:
python env/src/gym_env/example_usage.py --list2. Create an Environment
import gym
# Create any available environment
env = gym.make("Factorio-iron_ore_throughput_16-v0")3. Use the Environment
# Reset the environment
obs = env.reset()
# Take an action
action = {
'agent_idx': 0, # Which agent takes the action
'code': 'print("Hello Factorio!")' # Python code to execute
}
# Execute the action
obs, reward, done, info = env.step(action)
# Clean up
env.close()The registry automatically discovers all JSON task definition files and creates corresponding gym environments. Environment IDs follow the pattern:
Factorio-{task_key}-v0
Example Environment IDs
-
Factorio-iron_ore_throughput_16-v0- Iron ore production task -
Factorio-iron_plate_throughput_16-v0- Iron plate production task -
Factorio-crude_oil_throughput_16-v0- Crude oil production task -
Factorio-open_play-v0- Open-ended factory building -
Factorio-automation_science_pack_throughput_16-v0- Science pack production
The example_usage.py script provides both interactive examples and command-line tools:
# Run interactive examples
python env/src/gym_env/example_usage.py
# List all environments
python env/src/gym_env/example_usage.py --list
# Show detailed information
python env/src/gym_env/example_usage.py --detail
# Search for specific environments
python env/src/gym_env/example_usage.py --search iron
# Output in gym.make() format
python env/src/gym_env/example_usage.py --gym-formatAll environments follow the standard gym interface:
Action Space
{
'agent_idx': Discrete(num_agents), # Which agent takes the action
'code': Text(max_length=10000) # Python code to execute
}Observation Space The observation space includes:
-
raw_text: Output from the last action -
entities: List of entities on the map -
inventory: Current inventory state -
research: Research progress and technologies -
game_info: Game state (tick, time, speed) -
score: Current score -
achievements: Achievement progress -
flows: Production statistics -
task_verification: Task completion status -
messages: Inter-agent messages -
serialized_functions: Available functions
Methods
reset(state: Optional[GameState] = None) -> Dict[str, Any]step(action: Dict[str, Any]) -> Tuple[Dict[str, Any], float, bool, Dict[str, Any]]close() -> None
Registry Functions
-
list_available_environments() -> List[str]- Returns a list of all registered environment IDs -
get_environment_info(env_id: str) -> Optional[Dict[str, Any]]- Returns detailed information about a specific environment -
register_all_environments() -> None- Manually trigger environment discovery and registration
Environment Creation
-
gym.make(env_id: str, **kwargs) -> FactorioGymEnv- Creates a Factorio gym environment
Here's a complete example that demonstrates the full workflow:
import gym
from gym_env.registry import list_available_environments, get_environment_info
# 1. List available environments
env_ids = list_available_environments()
print(f"Found {len(env_ids)} environments")
# 2. Get information about a specific environment
info = get_environment_info("Factorio-iron_ore_throughput_16-v0")
print(f"Description: {info['description']}")
# 3. Create the environment
env = gym.make("Factorio-iron_ore_throughput_16-v0")
# 4. Use the environment
obs = env.reset()
print(f"Initial observation keys: {list(obs.keys())}")
# 5. Take actions
for step in range(5):
action = {
'agent_idx': 0,
'code': f'print("Step {step}: Hello Factorio!")'
}
obs, reward, done, info = env.step(action)
print(f"Step {step}: Reward={reward}, Done={done}")
if done:
break
# 6. Clean up
env.close()To add a new task:
- Create a JSON file in
eval/tasks/task_definitions/ - Define the task configuration following the existing format
- The registry will automatically discover and register the new environment
Task Definition Format
{
"task_type": "throughput",
"config": {
"goal_description": "Create an automatic iron ore factory...",
"throughput_entity": "iron-ore",
"quota": 16,
"trajectory_length": 128,
"task_key": "iron_ore_throughput_16"
}
}Custom Environment Registration
You can also register custom environments programmatically:
from gym_env.registry import _registry
_registry.register_environment(
env_id="Factorio-CustomTask-v0",
task_key="custom_task",
task_config_path="/path/to/custom_task.json",
description="My custom task",
num_agents=2
)Multi-Agent Environments
The registry supports multi-agent environments. When creating a multi-agent environment, specify the number of agents:
# Create a multi-agent environment
env = gym.make("Factorio-MultiAgentTask-v0")
# Actions for different agents
action1 = {'agent_idx': 0, 'code': 'print("Agent 0 action")'}
action2 = {'agent_idx': 1, 'code': 'print("Agent 1 action")'}The registry includes error handling for:
- Missing task definition files
- Invalid JSON configurations
- Missing Factorio containers
- Environment creation failures
If an environment fails to load, a warning will be printed but the registry will continue to load other environments.
Environment Creation Fails
If gym.make() fails with connection errors:
- Ensure Factorio containers are running
- Check that the cluster setup is working
- Verify network connectivity
No Environments Found
If no environments are listed:
- Check that the task definitions directory exists
- Verify JSON files are valid
- Check file permissions
Import Errors
If you get import errors:
- Ensure you're running from the correct directory
- Check that all dependencies are installed
- Verify the Python path includes the project root
Run the test suite to verify the registry is working correctly:
python env/tests/gym_env/test_registry.pyThis registry system provides a clean, standardized interface for working with Factorio gym environments, making it easy to experiment with different tasks and integrate with existing gym-based frameworks.
For backward compatibility, you can still use the legacy task-based configuration with eval/open/independent_runs/run.py:
[
{
"task": "iron_gear_wheel_throughput_16.json",
"model": "gpt-4o-mini-2024-07-18",
"version": 768
},
{
"task": "plastic_bar_throughput_16.json",
"model": "anthropic/claude-3.5-sonnet-open-router"
},
{ "task": "open_play.json", "model": "gpt-4o-mini-2024-07-18" }
]Note: The CLI (fle eval) is the recommended approach for new users.
The Factorio Learning Environment supports multiagent experiments where multiple AI agents can work together (or against each other) in the same game world through the Agent-to-Agent (A2A) protocol. Here's how to set up and run multiagent experiments:
Multiagent tasks are defined in JSON files under eval/tasks/task_definitions/multiagent/. Each task can specify:
- A shared goal description for all agents
- Agent-specific instructions for each agent
- Number of agents required
- Other task parameters (trajectory length, holdout period, etc.)
Example task configuration:
{
"task_type": "unbounded_throughput",
"config": {
"goal_description": "Create an automatic iron plate factory...",
"agent_instructions": [
"You are Agent 1. Your role is to mine coal.",
"You are Agent 2. Your role is to mine iron."
],
"throughput_entity": "iron-plate",
"trajectory_length": 16,
"holdout_wait_period": 60
}
}Create a run configuration file in eval/open/independent_runs/multiagent/ that specifies:
- The task file to use
- The model to use for each agent
- Number of agents
Example run configuration:
[
{
"task": "multiagent/iron_plate_throughput_free.json",
"model": "claude-3-5-sonnet-latest",
"num_agents": 2
}
]The Agent-to-Agent (A2A) protocol server enables communication between multiple AI agents in the Factorio environment. Here's how to set it up:
- Install Dependencies:
pip install fastapi uvicorn aiohttp- Start the A2A Server:
# Start the server on default host (localhost) and port (8000)
python env/src/protocols/a2a/server.py
# Or specify custom host and port
python env/src/protocols/a2a/server.py --host 127.0.0.1 --port 8000- Run the Experiment:
python eval/open/independent_runs/run.py --config eval/open/independent_runs/multiagent/your_config.jsonAgents can communicate with each other using the send_message() tool. Each agent's system prompt includes instructions about:
- Their role in the multiagent setup
- How to communicate with other agents
- When to send messages (start/end of programs)
The A2A server handles:
- Agent registrations
- Message routing between agents
- Agent discovery and capability negotiation
- Message queuing for offline agents
The codebase includes several example multiagent scenarios:
- Cooperative Factory Building: Agents work together to build an efficient factory
- Distrust Scenario: Agents are suspicious of each other's actions
- Impostor Scenario: One agent tries to sabotage while the other tries to maintain the factory
To run these examples, use the provided configuration files:
-
claude_lab_free.json: Cooperative scenario -
claude_lab_distrust.json: Distrust scenario -
claude_lab_impostor.json: Impostor scenario
If you encounter issues:
- Ensure the A2A server is running before starting agent instances
- Check that the server port (default 8000) is not blocked by a firewall
- Verify agent registration in the server logs
- Check agent message delivery status
Agents interact with the game using tools, which represent a narrow API into the game.
Tools live in env/src/tools, and are either admin tools (non-agent accessible) or agent tools (used by the agent).
A tool requires 3 files:
-
agent.md: The agent documentation for the tool, including usage patterns, best practices and failure modes. -
client.py: The client-side implementation, which is a Python class that can be invoked by the agent. -
server.lua: The server-side implementation, which handles most of the logic and heavy lifting.
---
config:
layout: fixed
flowchart:
defaultRenderer:
elk
---
flowchart LR
A("fa:fa-comment-dots Agent")
subgraph s1["Learning Environment"]
B("fa:fa-code Interpreter")
n1("client.py")
end
subgraph s2["Factorio Server"]
E1["fa:fa-shapes server.lua"]
F("fa:fa-cog Factorio Engine")
end
A -- Synthesises Python --> B
B -- Invokes --> n1
n1 -. Exceptions .-> B
n1 -. Objects .-> B
n1 --Remote TCP Call--> E1
E1 -- Execute --> F
F-. Result .-> E1
E1 -. TCP Response .-> n1
B -. Observation .-> A- Create a new directory in
env/src/tools/agent, e.genv/src/tools/agent/my_tool - Add a
client.pyfile, which should contain a class inheritingTooland implementing a__call__function to treat the class as a callable function. The method signature should contain type annotations. This function must callself.executeto invoke the server-side logic. - Add a
server.luafile, containing a function structured likeglobal.actions.my_tool = function(arg1, arg2, ...). This file should invoke the Factorio API to perform the desired action, and return a table that will be serialized and sent back to the client. - Add an
agent.mdfile, which should contain a markdown description of the tool. This file will be used by the agent to understand how to use the tool
Next time you run an eval, the tool will automatically be available to the agent and documented in the agent context.
- (Optional) Create a test suite in
env/tests/actionsfor your new tool.
| Tool | Description | Key Features |
|---|---|---|
inspect_inventory |
Checks contents of player or entity inventories | - Supports various inventory types (chests, furnaces, etc.) - Returns Inventory object with count methods - Can query specific items |
insert_item |
Places items from player inventory into entities | - Works with machines, chests, belts - Validates item compatibility - Returns updated entity |
extract_item |
Removes items from entity inventories | - Supports all inventory types - Auto-transfers to player inventory - Returns quantity extracted |
place_entity |
Places entities in the world | - Handles direction and positioning - Validates placement requirements - Returns placed Entity object |
place_entity_next_to |
Places entities relative to others | - Automatic spacing/alignment - Handles entity dimensions - Supports all entity types |
pickup_entity |
Removes entities from the world | - Returns items to inventory - Handles entity groups - Supports all placeable items |
rotate_entity |
Changes entity orientation | - Affects entity behavior (e.g., inserter direction) - Validates rotation rules - Returns updated entity |
get_entity |
Retrieves entity objects at positions | - Updates stale references - Returns typed Entity objects - Handles all entity types |
get_entities |
Finds multiple entities in an area | - Supports filtering by type - Returns List[Entity] - Groups connected entities |
nearest |
Locates closest resources/entities | - Finds ores, water, trees - Returns Position object - 500 tile search radius |
get_resource_patch |
Analyzes resource deposits | - Returns size and boundaries - Supports all resource types - Includes total resource amount |
harvest_resource |
Gathers resources from the world | - Supports ores, trees, rocks - Auto-collects to inventory - Returns amount harvested |
connect_entities |
Creates connections between entities | - Handles belts, pipes, power - Automatic pathfinding - Returns connection group |
get_connection_amount |
Calculates required connection items | - Pre-planning tool - Works with all connection types - Returns item count needed |
set_entity_recipe |
Configures machine crafting recipes | - Works with assemblers/chemical plants - Validates recipe requirements - Returns updated entity |
get_prototype_recipe |
Retrieves crafting requirements | - Shows ingredients/products - Includes crafting time - Returns Recipe object |
craft_item |
Creates items from components | - Handles recursive crafting - Validates technology requirements - Returns crafted amount |
set_research |
Initiates technology research | - Validates prerequisites - Returns required ingredients - Handles research queue |
get_research_progress |
Monitors research status | - Shows remaining requirements - Tracks progress percentage - Returns ingredient list |
move_to |
Moves player to position | - Pathfinds around obstacles - Can place items while moving - Returns final position |
nearest_buildable |
Finds valid building locations | - Respects entity dimensions - Handles resource requirements - Returns buildable position |
sleep |
Pauses execution | - Waits for actions to complete - Adapts to game speed - Maximum 15 second duration |
launch_rocket |
Controls rocket silo launches | - Validates launch requirements - Handles launch sequence - Returns updated silo state |
print |
Outputs debug information to stdout | - Supports various object types - Useful for monitoring state - Returns formatted string |
Below is an overview of how the project is structured. Some directories also contain more detailed readmes.
factorio-learning-environment/
├── .github/ # GitHub workflows and scripts
├── docs/ # Website and documentation
├── fle/ # Main Factorio Learning Environment codebase
│ ├── agents/ # Agent implementations
│ │ ├── formatters/ # Conversation formatting utilities
│ │ ├── llm/ # LLM integration utilities
│ │ ├── agent_abc.py # Abstract base class for agents
│ │ ├── basic_agent.py # Default agent implementation
│ │ ├── backtracking_agent.py # Backtracking agent
│ │ ├── visual_agent.py # Visual agent implementation
│ │ └── gym_agent.py # Gym-compatible agent
│ ├── cluster/ # Docker and deployment utilities
│ │ ├── remote/ # Remote deployment utilities
│ │ └── scenarios/ # Game scenario configurations
│ ├── commons/ # Shared utilities and constants
│ ├── data/ # Data files and resources
│ ├── env/ # Environment implementation
│ │ ├── gym_env/ # Gym environment interface
│ │ ├── tools/ # Agent tools and API
│ │ ├── protocols/ # Communication protocols (A2A, etc.)
│ │ ├── utils/ # Environment utilities
│ │ ├── lib/ # Core libraries
│ │ ├── exceptions/ # Custom exceptions
│ │ ├── instance.py # Factorio instance management
│ │ ├── namespace.py # Python namespace management
│ │ ├── entities.py # Entity definitions
│ │ └── game_types.py # Game type definitions
│ ├── eval/ # Evaluation framework
│ │ ├── algorithms/ # Evaluation algorithms
│ │ ├── tasks/ # Task definitions and implementations
│ │ ├── open/ # Open-play evaluation scripts
│ │ └── evaluator.py # Main evaluation logic
│ ├── run.py # Main CLI entry point
│ ├── server.py # Server implementation
│ └── __init__.py # Package initialization
├── tests/ # Test suite
├── .example.env # Example environment variables
├── .gitignore # Git ignore file
├── BUILD.md # Build instructions
├── CONTRIBUTING.md # Contribution guidelines
├── LICENSE # License file
├── README.md # Project readme
├── clean.sh # Clean script
├── pyproject.toml # Python project config
└── uv.lock # UV lock file
To run long trajectories in FLE, we support checkpointing at every agent step using a SQL database. The db_client implements the interface for saving and loading agent outputs, environment feedbacks, game states and histories of the current trajectory. We support out of the box SQLite (default) and Postgres databases. The easiest way to set up a FLE-compatible database is to use the default SQLite, the env variable FLE_DB_TYPE="sqlite" lets you select the DB.
We recommend changing and setting up the SQLITE_DB_FILE variable in the .env file. It defaults to .fle/data.db in your working directory.
Make sure all variables are set in the .env file with FLE_DB_TYPE="postgres".
To utilize postgres database you need to setup an instance of the db server yourself. The easiest way is to run it via Docker:
docker run --name fle-postgres -e POSTGRES_PASSWORD=fle123 -e POSTGRES_USER=fle_user -e POSTGRES_DB=fle_database -p 5432:5432 -d postgres:15
This launches a postgres:15 server with the defined settings, it can be used via the corresponding .env variables:
# Database Configuration - Set to postgres to use PostgreSQL
FLE_DB_TYPE="postgres"
# PostgreSQL Configuration
SKILLS_DB_HOST=localhost
SKILLS_DB_PORT=5432
SKILLS_DB_NAME=fle_database
SKILLS_DB_USER=fle_user
SKILLS_DB_PASSWORD=fle123
We measured FLE execution performance across different configurations to measure performance. All benchmarks were run on a Macbook Pro M4 128GB, with 100 iterations per operation on a subset of the existing tools.
Executing tools against the Factorio server, while a Factorio game client is connected.
| Operation | Operations/Min | Operations/Sec |
|---|---|---|
| place_entity_next_to | 2,578.20 | 42.97 |
| place_entity | 12,057.63 | 200.96 |
| move_to | 8,649.89 | 144.16 |
| harvest_resource | 16,599.44 | 276.66 |
| craft_item | 16,875.14 | 281.25 |
| connect_entities | 1,664.70 | 27.74 |
| rotate_entity | 12,281.31 | 204.69 |
| insert_item | 13,044.42 | 217.41 |
| extract_item | 17,167.43 | 286.12 |
| inspect_inventory | 17,036.32 | 283.94 |
| get_resource_patch | 7,004.49 | 116.74 |
| Total | 7,513.29 | 125.22 |
Executing tools against the Factorio server without a game client.
| Operation | Operations/Min | Operations/Sec |
|---|---|---|
| place_entity_next_to | 4,856.51 | 80.94 |
| place_entity | 22,332.72 | 372.21 |
| move_to | 16,005.59 | 266.76 |
| harvest_resource | 32,727.01 | 545.45 |
| craft_item | 36,223.63 | 603.73 |
| connect_entities | 2,926.01 | 48.77 |
| rotate_entity | 23,467.46 | 391.12 |
| insert_item | 25,154.28 | 419.24 |
| extract_item | 32,997.26 | 549.95 |
| inspect_inventory | 28,401.56 | 473.36 |
| get_resource_patch | 8,736.30 | 145.61 |
| Total | 13,094.98 | 218.25 |
Executing tools as part of a Python policy string, while a Factorio game client is connected.
| Operation | Operations/Min | Operations/Sec |
|---|---|---|
| place_entity_next_to | 4,714.52 | 78.58 |
| place_entity | 4,774.13 | 79.57 |
| move_to | 4,005.77 | 66.76 |
| harvest_resource | 3,594.59 | 59.91 |
| craft_item | 4,985.02 | 83.08 |
| connect_entities | 1,497.11 | 24.95 |
| rotate_entity | 4,914.69 | 81.91 |
| insert_item | 5,046.99 | 84.12 |
| extract_item | 4,743.08 | 79.05 |
| inspect_inventory | 4,838.31 | 80.64 |
| get_resource_patch | 2,593.11 | 43.22 |
| Total | 3,639.10 | 60.65 |
Executing tools as part of a Python policy string, without a game client.
| Operation | Operations/Min | Operations/Sec |
|---|---|---|
| place_entity_next_to | 5,069.60 | 84.49 |
| place_entity | 5,238.61 | 87.31 |
| move_to | 4,979.59 | 82.99 |
| harvest_resource | 3,247.09 | 54.12 |
| craft_item | 5,854.27 | 97.57 |
| connect_entities | 2,150.21 | 35.84 |
| rotate_entity | 5,370.21 | 89.50 |
| insert_item | 5,065.89 | 84.43 |
| extract_item | 5,449.07 | 90.82 |
| inspect_inventory | 5,638.67 | 93.98 |
| get_resource_patch | 2,479.41 | 41.32 |
| Total | 4,103.53 | 68.39 |
-
Headless vs Client Performance: The headless server configuration consistently outperforms the client version, with direct API calls showing approximately 74% better throughput (218.25 vs 125.22 ops/sec).
-
Interpreter Overhead: Adding the interpreter layer introduces significant overhead:
- Headless: Drops from 218.25 to 68.39 ops/sec (~69% reduction)
- Client: Drops from 125.22 to 60.65 ops/sec (~52% reduction)
-
Operation Variability: Some operations show more significant performance variations:
-
connect_entitiesis consistently the slowest operation across all configurations (because it relies on pathfinding) -
craft_itemandextract_itemtend to be among the fastest operations
-
Join our team and contribute to one of the AI research community's most challenging problems - building open-ended / unsaturateable evals for post-AGI frontier models. If you want to contribute, please read CONTRIBUTING.md first.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for factorio-learning-environment
Similar Open Source Tools
factorio-learning-environment
Factorio Learning Environment is an open source framework designed for developing and evaluating LLM agents in the game of Factorio. It provides two settings: Lab-play with structured tasks and Open-play for building large factories. Results show limitations in spatial reasoning and automation strategies. Agents interact with the environment through code synthesis, observation, action, and feedback. Tools are provided for game actions and state representation. Agents operate in episodes with observation, planning, and action execution. Tasks specify agent goals and are implemented in JSON files. The project structure includes directories for agents, environment, cluster, data, docs, eval, and more. A database is used for checkpointing agent steps. Benchmarks show performance metrics for different configurations.
uLoopMCP
uLoopMCP is a Unity integration tool designed to let AI drive your Unity project forward with minimal human intervention. It provides a 'self-hosted development loop' where an AI can compile, run tests, inspect logs, and fix issues using tools like compile, run-tests, get-logs, and clear-console. It also allows AI to operate the Unity Editor itself—creating objects, calling menu items, inspecting scenes, and refining UI layouts from screenshots via tools like execute-dynamic-code, execute-menu-item, and capture-window. The tool enables AI-driven development loops to run autonomously inside existing Unity projects.
jido
Jido is a toolkit for building autonomous, distributed agent systems in Elixir. It provides the foundation for creating smart, composable workflows that can evolve and respond to their environment. Geared towards Agent builders, it contains core state primitives, composable actions, agent data structures, real-time sensors, signal system, skills, and testing tools. Jido is designed for multi-node Elixir clusters and offers rich helpers for unit and property-based testing.

pentagi
PentAGI is an innovative tool for automated security testing that leverages cutting-edge artificial intelligence technologies. It is designed for information security professionals, researchers, and enthusiasts who need a powerful and flexible solution for conducting penetration tests. The tool provides secure and isolated operations in a sandboxed Docker environment, fully autonomous AI-powered agent for penetration testing steps, a suite of 20+ professional security tools, smart memory system for storing research results, web intelligence for gathering information, integration with external search systems, team delegation system, comprehensive monitoring and reporting, modern interface, API integration, persistent storage, scalable architecture, self-hosted solution, flexible authentication, and quick deployment through Docker Compose.

evalchemy
Evalchemy is a unified and easy-to-use toolkit for evaluating language models, focusing on post-trained models. It integrates multiple existing benchmarks such as RepoBench, AlpacaEval, and ZeroEval. Key features include unified installation, parallel evaluation, simplified usage, and results management. Users can run various benchmarks with a consistent command-line interface and track results locally or integrate with a database for systematic tracking and leaderboard submission.
iloom-cli
iloom is a tool designed to streamline AI-assisted development by focusing on maintaining alignment between human developers and AI agents. It treats context as a first-class concern, persisting AI reasoning in issue comments rather than temporary chats. The tool allows users to collaborate with AI agents in an isolated environment, switch between complex features without losing context, document AI decisions publicly, and capture key insights and lessons learned from AI sessions. iloom is not just a tool for managing git worktrees, but a control plane for maintaining alignment between users and their AI assistants.

metis
Metis is an open-source, AI-driven tool for deep security code review, created by Arm's Product Security Team. It helps engineers detect subtle vulnerabilities, improve secure coding practices, and reduce review fatigue. Metis uses LLMs for semantic understanding and reasoning, RAG for context-aware reviews, and supports multiple languages and vector store backends. It provides a plugin-friendly and extensible architecture, named after the Greek goddess of wisdom, Metis. The tool is designed for large, complex, or legacy codebases where traditional tooling falls short.
RepairAgent
RepairAgent is an autonomous LLM-based agent for automated program repair targeting the Defects4J benchmark. It uses an LLM-driven loop to localize, analyze, and fix Java bugs. The tool requires Docker, VS Code with Dev Containers extension, OpenAI API key, disk space of ~40 GB, and internet access. Users can get started with RepairAgent using either VS Code Dev Container or Docker Image. Running RepairAgent involves checking out the buggy project version, autonomous bug analysis, fix candidate generation, and testing against the project's test suite. Users can configure hyperparameters for budget control, repetition handling, commands limit, and external fix strategy. The tool provides output structure, experiment overview, individual analysis scripts, and data on fixed bugs from the Defects4J dataset.

quantalogic
QuantaLogic is a ReAct framework for building advanced AI agents that seamlessly integrates large language models with a robust tool system. It aims to bridge the gap between advanced AI models and practical implementation in business processes by enabling agents to understand, reason about, and execute complex tasks through natural language interaction. The framework includes features such as ReAct Framework, Universal LLM Support, Secure Tool System, Real-time Monitoring, Memory Management, and Enterprise Ready components.

xFasterTransformer
xFasterTransformer is an optimized solution for Large Language Models (LLMs) on the X86 platform, providing high performance and scalability for inference on mainstream LLM models. It offers C++ and Python APIs for easy integration, along with example codes and benchmark scripts. Users can prepare models in a different format, convert them, and use the APIs for tasks like encoding input prompts, generating token ids, and serving inference requests. The tool supports various data types and models, and can run in single or multi-rank modes using MPI. A web demo based on Gradio is available for popular LLM models like ChatGLM and Llama2. Benchmark scripts help evaluate model inference performance quickly, and MLServer enables serving with REST and gRPC interfaces.
open-responses
OpenResponses API provides enterprise-grade AI capabilities through a powerful API, simplifying development and deployment while ensuring complete data control. It offers automated tracing, integrated RAG for contextual information retrieval, pre-built tool integrations, self-hosted architecture, and an OpenAI-compatible interface. The toolkit addresses development challenges like feature gaps and integration complexity, as well as operational concerns such as data privacy and operational control. Engineering teams can benefit from improved productivity, production readiness, compliance confidence, and simplified architecture by choosing OpenResponses.
k8s-operator
OpenClaw Kubernetes Operator is a platform for self-hosting AI agents on Kubernetes with production-grade security, observability, and lifecycle management. It allows users to run OpenClaw AI agents on their own infrastructure, managing inboxes, calendars, smart homes, and more through various integrations. The operator encodes network isolation, secret management, persistent storage, health monitoring, optional browser automation, and config rollouts into a single custom resource 'OpenClawInstance'. It manages a stack of Kubernetes resources ensuring security, monitoring, and self-healing. Features include declarative configuration, security hardening, built-in metrics, provider-agnostic config, config modes, skill installation, auto-update, backup/restore, workspace seeding, gateway auth, Tailscale integration, self-configuration, extensibility, cloud-native features, and more.

skyvern
Skyvern automates browser-based workflows using LLMs and computer vision. It provides a simple API endpoint to fully automate manual workflows, replacing brittle or unreliable automation solutions. Traditional approaches to browser automations required writing custom scripts for websites, often relying on DOM parsing and XPath-based interactions which would break whenever the website layouts changed. Instead of only relying on code-defined XPath interactions, Skyvern adds computer vision and LLMs to the mix to parse items in the viewport in real-time, create a plan for interaction and interact with them. This approach gives us a few advantages: 1. Skyvern can operate on websites it’s never seen before, as it’s able to map visual elements to actions necessary to complete a workflow, without any customized code 2. Skyvern is resistant to website layout changes, as there are no pre-determined XPaths or other selectors our system is looking for while trying to navigate 3. Skyvern leverages LLMs to reason through interactions to ensure we can cover complex situations. Examples include: 1. If you wanted to get an auto insurance quote from Geico, the answer to a common question “Were you eligible to drive at 18?” could be inferred from the driver receiving their license at age 16 2. If you were doing competitor analysis, it’s understanding that an Arnold Palmer 22 oz can at 7/11 is almost definitely the same product as a 23 oz can at Gopuff (even though the sizes are slightly different, which could be a rounding error!) Want to see examples of Skyvern in action? Jump to #real-world-examples-of- skyvern

mLoRA
mLoRA (Multi-LoRA Fine-Tune) is an open-source framework for efficient fine-tuning of multiple Large Language Models (LLMs) using LoRA and its variants. It allows concurrent fine-tuning of multiple LoRA adapters with a shared base model, efficient pipeline parallelism algorithm, support for various LoRA variant algorithms, and reinforcement learning preference alignment algorithms. mLoRA helps save computational and memory resources when training multiple adapters simultaneously, achieving high performance on consumer hardware.
nanocoder
Nanocoder is a versatile code editor designed for beginners and experienced programmers alike. It provides a user-friendly interface with features such as syntax highlighting, code completion, and error checking. With Nanocoder, you can easily write and debug code in various programming languages, making it an ideal tool for learning, practicing, and developing software projects. Whether you are a student, hobbyist, or professional developer, Nanocoder offers a seamless coding experience to boost your productivity and creativity.
HippoRAG
HippoRAG is a novel retrieval augmented generation (RAG) framework inspired by the neurobiology of human long-term memory that enables Large Language Models (LLMs) to continuously integrate knowledge across external documents. It provides RAG systems with capabilities that usually require a costly and high-latency iterative LLM pipeline for only a fraction of the computational cost. The tool facilitates setting up retrieval corpus, indexing, and retrieval processes for LLMs, offering flexibility in choosing different online LLM APIs or offline LLM deployments through LangChain integration. Users can run retrieval on pre-defined queries or integrate directly with the HippoRAG API. The tool also supports reproducibility of experiments and provides data, baselines, and hyperparameter tuning scripts for research purposes.
For similar tasks
factorio-learning-environment
Factorio Learning Environment is an open source framework designed for developing and evaluating LLM agents in the game of Factorio. It provides two settings: Lab-play with structured tasks and Open-play for building large factories. Results show limitations in spatial reasoning and automation strategies. Agents interact with the environment through code synthesis, observation, action, and feedback. Tools are provided for game actions and state representation. Agents operate in episodes with observation, planning, and action execution. Tasks specify agent goals and are implemented in JSON files. The project structure includes directories for agents, environment, cluster, data, docs, eval, and more. A database is used for checkpointing agent steps. Benchmarks show performance metrics for different configurations.
Odyssey
Odyssey is a framework designed to empower agents with open-world skills in Minecraft. It provides an interactive agent with a skill library, a fine-tuned LLaMA-3 model, and an open-world benchmark for evaluating agent capabilities. The framework enables agents to explore diverse gameplay opportunities in the vast Minecraft world by offering primitive and compositional skills, extensive training data, and various long-term planning tasks. Odyssey aims to advance research on autonomous agent solutions by providing datasets, model weights, and code for public use.
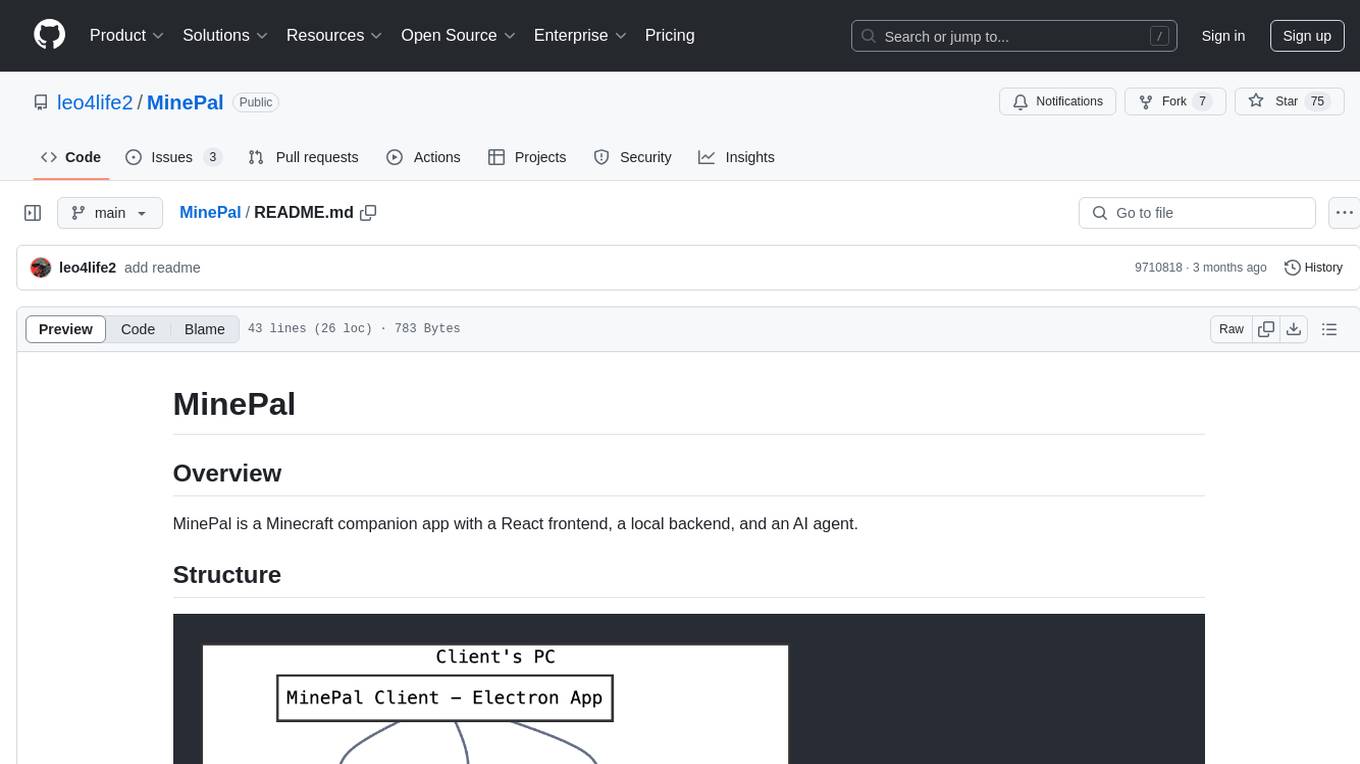
MinePal
MinePal is a Minecraft companion app with a React frontend, a local backend, and an AI agent. The frontend is built with React and Vite, the local backend APIs are in server.js, and the Minecraft agent logic is in src/agent/. Users can set up the frontend by installing dependencies and building it, refer to the backend repository for backend setup, and navigate to src/agent/ to access actions that the bot can take.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.