
pytorch-grad-cam
Advanced AI Explainability for computer vision. Support for CNNs, Vision Transformers, Classification, Object detection, Segmentation, Image similarity and more.
Stars: 10989

This repository provides advanced AI explainability for PyTorch, offering state-of-the-art methods for Explainable AI in computer vision. It includes a comprehensive collection of Pixel Attribution methods for various tasks like Classification, Object Detection, Semantic Segmentation, and more. The package supports high performance with full batch image support and includes metrics for evaluating and tuning explanations. Users can visualize and interpret model predictions, making it suitable for both production and model development scenarios.
README:
![]()
pip install grad-cam
Documentation with advanced tutorials: https://jacobgil.github.io/pytorch-gradcam-book
This is a package with state of the art methods for Explainable AI for computer vision. This can be used for diagnosing model predictions, either in production or while developing models. The aim is also to serve as a benchmark of algorithms and metrics for research of new explainability methods.
⭐ Comprehensive collection of Pixel Attribution methods for Computer Vision.
⭐ Tested on many Common CNN Networks and Vision Transformers.
⭐ Advanced use cases: Works with Classification, Object Detection, Semantic Segmentation, Embedding-similarity and more.
⭐ Includes smoothing methods to make the CAMs look nice.
⭐ High performance: full support for batches of images in all methods.
⭐ Includes metrics for checking if you can trust the explanations, and tuning them for best performance.

| Method | What it does |
|---|---|
| GradCAM | Weight the 2D activations by the average gradient |
| HiResCAM | Like GradCAM but element-wise multiply the activations with the gradients; provably guaranteed faithfulness for certain models |
| GradCAMElementWise | Like GradCAM but element-wise multiply the activations with the gradients then apply a ReLU operation before summing |
| GradCAM++ | Like GradCAM but uses second order gradients |
| XGradCAM | Like GradCAM but scale the gradients by the normalized activations |
| AblationCAM | Zero out activations and measure how the output drops (this repository includes a fast batched implementation) |
| ScoreCAM | Perbutate the image by the scaled activations and measure how the output drops |
| EigenCAM | Takes the first principle component of the 2D Activations (no class discrimination, but seems to give great results) |
| EigenGradCAM | Like EigenCAM but with class discrimination: First principle component of Activations*Grad. Looks like GradCAM, but cleaner |
| LayerCAM | Spatially weight the activations by positive gradients. Works better especially in lower layers |
| FullGrad | Computes the gradients of the biases from all over the network, and then sums them |
| Deep Feature Factorizations | Non Negative Matrix Factorization on the 2D activations |
| KPCA-CAM | Like EigenCAM but with Kernel PCA instead of PCA |
| FEM | A gradient free method that binarizes activations by an activation > mean + k * std rule. |
| ShapleyCAM | Weight the activations using the gradient and Hessian-vector product. |
| What makes the network think the image label is 'pug, pug-dog' | What makes the network think the image label is 'tabby, tabby cat' | Combining Grad-CAM with Guided Backpropagation for the 'pug, pug-dog' class |
|---|---|---|
 |
 |
 |
| Object Detection | Semantic Segmentation |
|---|---|
 |
 |
| 3D Medical Semantic Segmentation |
|---|
 |



| Explaining the text prompt "a dog" | Explaining the text prompt "a cat" |
|---|---|
 |
 |
| Category | Image | GradCAM | AblationCAM | ScoreCAM |
|---|---|---|---|---|
| Dog |  |
 |
 |
|
| Cat |  |
 |
 |
| Category | Image | GradCAM | AblationCAM | ScoreCAM |
|---|---|---|---|---|
| Dog |  |
 |
 |
|
| Cat |  |
 |
 |
| Category | Image | GradCAM | AblationCAM | ScoreCAM |
|---|---|---|---|---|
| Dog |  |
 |
 |
|
| Cat |  |
 |
 |


from pytorch_grad_cam import GradCAM, HiResCAM, ScoreCAM, GradCAMPlusPlus, AblationCAM, XGradCAM, EigenCAM, FullGrad
from pytorch_grad_cam.utils.model_targets import ClassifierOutputTarget
from pytorch_grad_cam.utils.image import show_cam_on_image
from torchvision.models import resnet50
model = resnet50(pretrained=True)
target_layers = [model.layer4[-1]]
input_tensor = # Create an input tensor image for your model..
# Note: input_tensor can be a batch tensor with several images!
# We have to specify the target we want to generate the CAM for.
targets = [ClassifierOutputTarget(281)]
# Construct the CAM object once, and then re-use it on many images.
with GradCAM(model=model, target_layers=target_layers) as cam:
# You can also pass aug_smooth=True and eigen_smooth=True, to apply smoothing.
grayscale_cam = cam(input_tensor=input_tensor, targets=targets)
# In this example grayscale_cam has only one image in the batch:
grayscale_cam = grayscale_cam[0, :]
visualization = show_cam_on_image(rgb_img, grayscale_cam, use_rgb=True)
# You can also get the model outputs without having to redo inference
model_outputs = cam.outputscam.py has a more detailed usage example.
You need to choose the target layer to compute the CAM for. Some common choices are:
- FasterRCNN: model.backbone
- Resnet18 and 50: model.layer4[-1]
- VGG, densenet161 and mobilenet: model.features[-1]
- mnasnet1_0: model.layers[-1]
- ViT: model.blocks[-1].norm1
- SwinT: model.layers[-1].blocks[-1].norm1
If you pass a list with several layers, the CAM will be averaged accross them. This can be useful if you're not sure what layer will perform best.
Methods like GradCAM were designed for and were originally mostly applied on classification models, and specifically CNN classification models. However you can also use this package on new architectures like Vision Transformers, and on non classification tasks like Object Detection or Semantic Segmentation.
The be able to adapt to non standard cases, we have two concepts.
- The reshape transform - how do we convert activations to represent spatial images ?
- The model targets - What exactly should the explainability method try to explain ?
In a CNN the intermediate activations in the model are a mult-channel image that have the dimensions channel x rows x cols, and the various explainabiltiy methods work with these to produce a new image.
In case of another architecture, like the Vision Transformer, the shape might be different, like (rows x cols + 1) x channels, or something else. The reshape transform converts the activations back into a multi-channel image, for example by removing the class token in a vision transformer. For examples, check here
The model target is just a callable that is able to get the model output, and filter it out for the specific scalar output we want to explain.
For classification tasks, the model target will typically be the output from a specific category.
The targets parameter passed to the CAM method can then use ClassifierOutputTarget:
targets = [ClassifierOutputTarget(281)]However for more advanced cases, you might want a different behaviour. Check here for more examples.
Here you can find detailed examples of how to use this for various custom use cases like object detection:
These point to the new documentation jupter-book for fast rendering. The jupyter notebooks themselves can be found under the tutorials folder in the git repository.
-
Notebook tutorial: XAI Recipes for the HuggingFace 🤗 Image Classification Models
-
Notebook tutorial: Deep Feature Factorizations for better model explainability
-
Notebook tutorial: Class Activation Maps for Object Detection with Faster-RCNN
-
Notebook tutorial: Class Activation Maps for Semantic Segmentation
-
Notebook tutorial: Adapting pixel attribution methods for embedding outputs from models
-
Notebook tutorial: May the best explanation win. CAM Metrics and Tuning
from pytorch_grad_cam import GuidedBackpropReLUModel
from pytorch_grad_cam.utils.image import (
show_cam_on_image, deprocess_image, preprocess_image
)
gb_model = GuidedBackpropReLUModel(model=model, device=model.device())
gb = gb_model(input_tensor, target_category=None)
cam_mask = cv2.merge([grayscale_cam, grayscale_cam, grayscale_cam])
cam_gb = deprocess_image(cam_mask * gb)
result = deprocess_image(gb)from pytorch_grad_cam.utils.model_targets import ClassifierOutputSoftmaxTarget
from pytorch_grad_cam.metrics.cam_mult_image import CamMultImageConfidenceChange
# Create the metric target, often the confidence drop in a score of some category
metric_target = ClassifierOutputSoftmaxTarget(281)
scores, batch_visualizations = CamMultImageConfidenceChange()(input_tensor,
inverse_cams, targets, model, return_visualization=True)
visualization = deprocess_image(batch_visualizations[0, :])
# State of the art metric: Remove and Debias
from pytorch_grad_cam.metrics.road import ROADMostRelevantFirst, ROADLeastRelevantFirst
cam_metric = ROADMostRelevantFirst(percentile=75)
scores, perturbation_visualizations = cam_metric(input_tensor,
grayscale_cams, targets, model, return_visualization=True)
# You can also average across different percentiles, and combine
# (LeastRelevantFirst - MostRelevantFirst) / 2
from pytorch_grad_cam.metrics.road import ROADMostRelevantFirstAverage,
ROADLeastRelevantFirstAverage,
ROADCombined
cam_metric = ROADCombined(percentiles=[20, 40, 60, 80])
scores = cam_metric(input_tensor, grayscale_cams, targets, model)To reduce noise in the CAMs, and make it fit better on the objects, two smoothing methods are supported:
-
aug_smooth=TrueTest time augmentation: increases the run time by x6.
Applies a combination of horizontal flips, and mutiplying the image by [1.0, 1.1, 0.9].
This has the effect of better centering the CAM around the objects.
-
eigen_smooth=TrueFirst principle component of
activations*weightsThis has the effect of removing a lot of noise.
| AblationCAM | aug smooth | eigen smooth | aug+eigen smooth |
|---|---|---|---|
 |
 |
 |
 |
Usage: python cam.py --image-path <path_to_image> --method <method> --output-dir <output_dir_path>
To use with a specific device, like cpu, cuda, cuda:0, mps or hpu:
python cam.py --image-path <path_to_image> --device cuda --output-dir <output_dir_path>
You can choose between:
GradCAM , HiResCAM, ScoreCAM, GradCAMPlusPlus, AblationCAM, XGradCAM , LayerCAM, FullGrad and EigenCAM.
Some methods like ScoreCAM and AblationCAM require a large number of forward passes, and have a batched implementation.
You can control the batch size with
cam.batch_size =
If you use this for research, please cite. Here is an example BibTeX entry:
@misc{jacobgilpytorchcam,
title={PyTorch library for CAM methods},
author={Jacob Gildenblat and contributors},
year={2021},
publisher={GitHub},
howpublished={\url{https://github.com/jacobgil/pytorch-grad-cam}},
}
https://arxiv.org/abs/1610.02391
Grad-CAM: Visual Explanations from Deep Networks via Gradient-based Localization Ramprasaath R. Selvaraju, Michael Cogswell, Abhishek Das, Ramakrishna Vedantam, Devi Parikh, Dhruv Batra
https://arxiv.org/abs/2011.08891
Use HiResCAM instead of Grad-CAM for faithful explanations of convolutional neural networks Rachel L. Draelos, Lawrence Carin
https://arxiv.org/abs/1710.11063
Grad-CAM++: Improved Visual Explanations for Deep Convolutional Networks Aditya Chattopadhyay, Anirban Sarkar, Prantik Howlader, Vineeth N Balasubramanian
https://arxiv.org/abs/1910.01279
Score-CAM: Score-Weighted Visual Explanations for Convolutional Neural Networks Haofan Wang, Zifan Wang, Mengnan Du, Fan Yang, Zijian Zhang, Sirui Ding, Piotr Mardziel, Xia Hu
https://ieeexplore.ieee.org/abstract/document/9093360/
Ablation-cam: Visual explanations for deep convolutional network via gradient-free localization. Saurabh Desai and Harish G Ramaswamy. In WACV, pages 972–980, 2020
https://arxiv.org/abs/2008.02312
Axiom-based Grad-CAM: Towards Accurate Visualization and Explanation of CNNs Ruigang Fu, Qingyong Hu, Xiaohu Dong, Yulan Guo, Yinghui Gao, Biao Li
https://arxiv.org/abs/2008.00299
Eigen-CAM: Class Activation Map using Principal Components Mohammed Bany Muhammad, Mohammed Yeasin
http://mftp.mmcheng.net/Papers/21TIP_LayerCAM.pdf
LayerCAM: Exploring Hierarchical Class Activation Maps for Localization Peng-Tao Jiang; Chang-Bin Zhang; Qibin Hou; Ming-Ming Cheng; Yunchao Wei
https://arxiv.org/abs/1905.00780
Full-Gradient Representation for Neural Network Visualization Suraj Srinivas, Francois Fleuret
https://arxiv.org/abs/1806.10206
Deep Feature Factorization For Concept Discovery Edo Collins, Radhakrishna Achanta, Sabine Süsstrunk
https://arxiv.org/abs/2410.00267
KPCA-CAM: Visual Explainability of Deep Computer Vision Models using Kernel PCA Sachin Karmani, Thanushon Sivakaran, Gaurav Prasad, Mehmet Ali, Wenbo Yang, Sheyang Tang
https://hal.science/hal-02963298/document
Features Understanding in 3D CNNs for Actions Recognition in Video Kazi Ahmed Asif Fuad, Pierre-Etienne Martin, Romain Giot, Romain Bourqui, Jenny Benois-Pineau, Akka Zemmar
https://arxiv.org/abs/2501.06261
CAMs as Shapley Value-based Explainers Huaiguang Cai
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for pytorch-grad-cam
Similar Open Source Tools
pytorch-grad-cam
This repository provides advanced AI explainability for PyTorch, offering state-of-the-art methods for Explainable AI in computer vision. It includes a comprehensive collection of Pixel Attribution methods for various tasks like Classification, Object Detection, Semantic Segmentation, and more. The package supports high performance with full batch image support and includes metrics for evaluating and tuning explanations. Users can visualize and interpret model predictions, making it suitable for both production and model development scenarios.

floneum
Floneum is a graph editor that makes it easy to develop your own AI workflows. It uses large language models (LLMs) to run AI models locally, without any external dependencies or even a GPU. This makes it easy to use LLMs with your own data, without worrying about privacy. Floneum also has a plugin system that allows you to improve the performance of LLMs and make them work better for your specific use case. Plugins can be used in any language that supports web assembly, and they can control the output of LLMs with a process similar to JSONformer or guidance.

CodeGeeX4
CodeGeeX4-ALL-9B is an open-source multilingual code generation model based on GLM-4-9B, offering enhanced code generation capabilities. It supports functions like code completion, code interpreter, web search, function call, and repository-level code Q&A. The model has competitive performance on benchmarks like BigCodeBench and NaturalCodeBench, outperforming larger models in terms of speed and performance.

Consistency_LLM
Consistency Large Language Models (CLLMs) is a family of efficient parallel decoders that reduce inference latency by efficiently decoding multiple tokens in parallel. The models are trained to perform efficient Jacobi decoding, mapping any randomly initialized token sequence to the same result as auto-regressive decoding in as few steps as possible. CLLMs have shown significant improvements in generation speed on various tasks, achieving up to 3.4 times faster generation. The tool provides a seamless integration with other techniques for efficient Large Language Model (LLM) inference, without the need for draft models or architectural modifications.

Cherry_LLM
Cherry Data Selection project introduces a self-guided methodology for LLMs to autonomously discern and select cherry samples from open-source datasets, minimizing manual curation and cost for instruction tuning. The project focuses on selecting impactful training samples ('cherry data') to enhance LLM instruction tuning by estimating instruction-following difficulty. The method involves phases like 'Learning from Brief Experience', 'Evaluating Based on Experience', and 'Retraining from Self-Guided Experience' to improve LLM performance.

Qwen
Qwen is a series of large language models developed by Alibaba DAMO Academy. It outperforms the baseline models of similar model sizes on a series of benchmark datasets, e.g., MMLU, C-Eval, GSM8K, MATH, HumanEval, MBPP, BBH, etc., which evaluate the models’ capabilities on natural language understanding, mathematic problem solving, coding, etc. Qwen models outperform the baseline models of similar model sizes on a series of benchmark datasets, e.g., MMLU, C-Eval, GSM8K, MATH, HumanEval, MBPP, BBH, etc., which evaluate the models’ capabilities on natural language understanding, mathematic problem solving, coding, etc. Qwen-72B achieves better performance than LLaMA2-70B on all tasks and outperforms GPT-3.5 on 7 out of 10 tasks.
dom-to-semantic-markdown
DOM to Semantic Markdown is a tool that converts HTML DOM to Semantic Markdown for use in Large Language Models (LLMs). It maximizes semantic information, token efficiency, and preserves metadata to enhance LLMs' processing capabilities. The tool captures rich web content structure, including semantic tags, image metadata, table structures, and link destinations. It offers customizable conversion options and supports both browser and Node.js environments.

LLM-Pruner
LLM-Pruner is a tool for structural pruning of large language models, allowing task-agnostic compression while retaining multi-task solving ability. It supports automatic structural pruning of various LLMs with minimal human effort. The tool is efficient, requiring only 3 minutes for pruning and 3 hours for post-training. Supported LLMs include Llama-3.1, Llama-3, Llama-2, LLaMA, BLOOM, Vicuna, and Baichuan. Updates include support for new LLMs like GQA and BLOOM, as well as fine-tuning results achieving high accuracy. The tool provides step-by-step instructions for pruning, post-training, and evaluation, along with a Gradio interface for text generation. Limitations include issues with generating repetitive or nonsensical tokens in compressed models and manual operations for certain models.

DB-GPT-Hub
DB-GPT-Hub is an experimental project leveraging Large Language Models (LLMs) for Text-to-SQL parsing. It includes stages like data collection, preprocessing, model selection, construction, and fine-tuning of model weights. The project aims to enhance Text-to-SQL capabilities, reduce model training costs, and enable developers to contribute to improving Text-to-SQL accuracy. The ultimate goal is to achieve automated question-answering based on databases, allowing users to execute complex database queries using natural language descriptions. The project has successfully integrated multiple large models and established a comprehensive workflow for data processing, SFT model training, prediction output, and evaluation.

EmbodiedScan
EmbodiedScan is a holistic multi-modal 3D perception suite designed for embodied AI. It introduces a multi-modal, ego-centric 3D perception dataset and benchmark for holistic 3D scene understanding. The dataset includes over 5k scans with 1M ego-centric RGB-D views, 1M language prompts, 160k 3D-oriented boxes spanning 760 categories, and dense semantic occupancy with 80 common categories. The suite includes a baseline framework named Embodied Perceptron, capable of processing multi-modal inputs for 3D perception tasks and language-grounded tasks.

cambrian
Cambrian-1 is a fully open project focused on exploring multimodal Large Language Models (LLMs) with a vision-centric approach. It offers competitive performance across various benchmarks with models at different parameter levels. The project includes training configurations, model weights, instruction tuning data, and evaluation details. Users can interact with Cambrian-1 through a Gradio web interface for inference. The project is inspired by LLaVA and incorporates contributions from Vicuna, LLaMA, and Yi. Cambrian-1 is licensed under Apache 2.0 and utilizes datasets and checkpoints subject to their respective original licenses.

WordLlama
WordLlama is a fast, lightweight NLP toolkit optimized for CPU hardware. It recycles components from large language models to create efficient word representations. It offers features like Matryoshka Representations, low resource requirements, binarization, and numpy-only inference. The tool is suitable for tasks like semantic matching, fuzzy deduplication, ranking, and clustering, making it a good option for NLP-lite tasks and exploratory analysis.
cifar10-airbench
CIFAR-10 Airbench is a project offering fast and stable training baselines for CIFAR-10 dataset, facilitating machine learning research. It provides easily runnable PyTorch scripts for training neural networks with high accuracy levels. The methods used in this project aim to accelerate research on fundamental properties of deep learning. The project includes GPU-accelerated dataloader for custom experiments and trainings, and can be used for data selection and active learning experiments. The training methods provided are faster than standard ResNet training, offering improved performance for research projects.
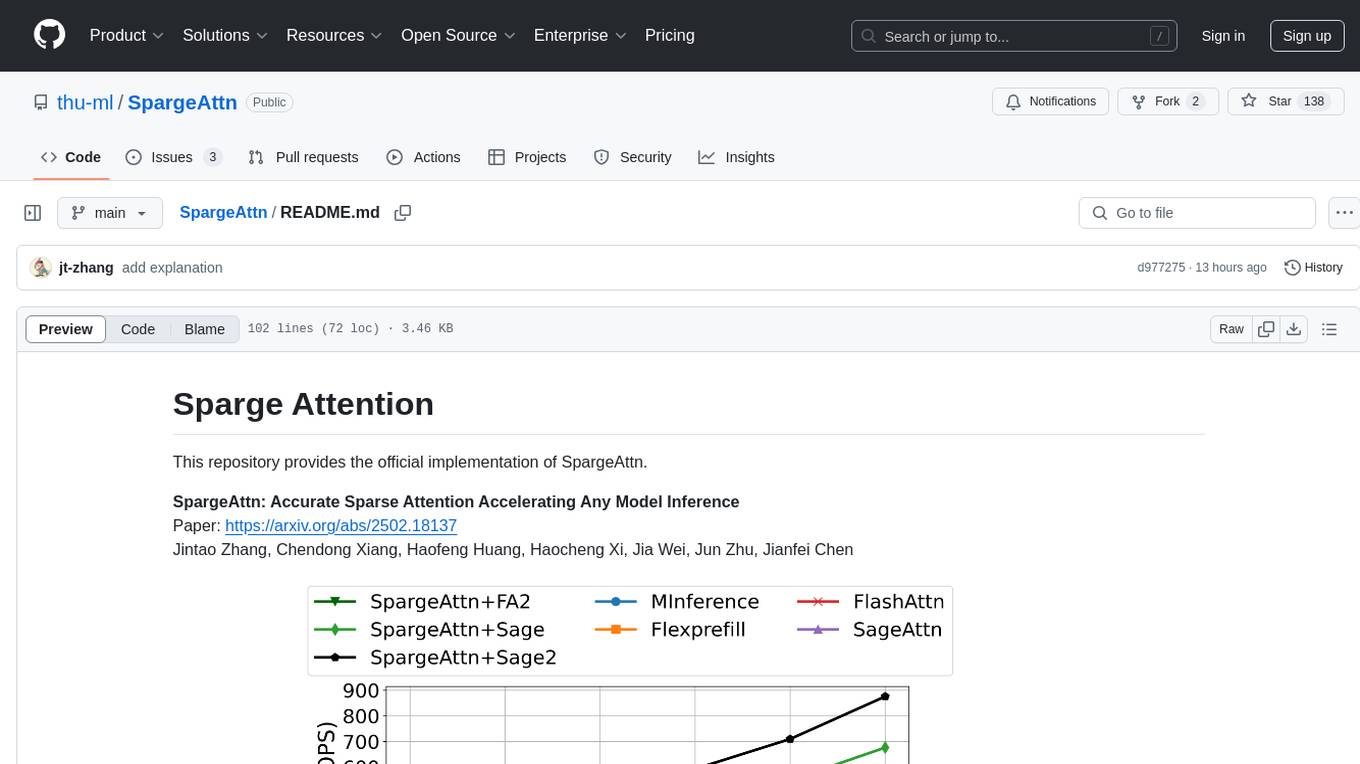
SpargeAttn
SpargeAttn is an official implementation designed for accelerating any model inference by providing accurate sparse attention. It offers a significant speedup in model performance while maintaining quality. The tool is based on SageAttention and SageAttention2, providing options for different levels of optimization. Users can easily install the package and utilize the available APIs for their specific needs. SpargeAttn is particularly useful for tasks requiring efficient attention mechanisms in deep learning models.

pgvecto.rs
pgvecto.rs is a Postgres extension written in Rust that provides vector similarity search functions. It offers ultra-low-latency, high-precision vector search capabilities, including sparse vector search and full-text search. With complete SQL support, async indexing, and easy data management, it simplifies data handling. The extension supports various data types like FP16/INT8, binary vectors, and Matryoshka embeddings. It ensures system performance with production-ready features, high availability, and resource efficiency. Security and permissions are managed through easy access control. The tool allows users to create tables with vector columns, insert vector data, and calculate distances between vectors using different operators. It also supports half-precision floating-point numbers for better performance and memory usage optimization.

basiclingua-LLM-Based-NLP
BasicLingua is a Python library that provides functionalities for linguistic tasks such as tokenization, stemming, lemmatization, and many others. It is based on the Gemini Language Model, which has demonstrated promising results in dealing with text data. BasicLingua can be used as an API or through a web demo. It is available under the MIT license and can be used in various projects.
For similar tasks
pytorch-grad-cam
This repository provides advanced AI explainability for PyTorch, offering state-of-the-art methods for Explainable AI in computer vision. It includes a comprehensive collection of Pixel Attribution methods for various tasks like Classification, Object Detection, Semantic Segmentation, and more. The package supports high performance with full batch image support and includes metrics for evaluating and tuning explanations. Users can visualize and interpret model predictions, making it suitable for both production and model development scenarios.
Awesome-explainable-AI
This repository contains frontier research on explainable AI (XAI), a hot topic in the field of artificial intelligence. It includes trends, use cases, survey papers, books, open courses, papers, and Python libraries related to XAI. The repository aims to organize and categorize publications on XAI, provide evaluation methods, and list various Python libraries for explainable AI.
AwesomeResponsibleAI
Awesome Responsible AI is a curated list of academic research, books, code of ethics, courses, data sets, frameworks, institutes, newsletters, principles, podcasts, reports, tools, regulations, and standards related to Responsible, Trustworthy, and Human-Centered AI. It covers various concepts such as Responsible AI, Trustworthy AI, Human-Centered AI, Responsible AI frameworks, AI Governance, and more. The repository provides a comprehensive collection of resources for individuals interested in ethical, transparent, and accountable AI development and deployment.
Awesome-LLM-Interpretability
Awesome-LLM-Interpretability is a curated list of materials related to LLM (Large Language Models) interpretability, covering tutorials, code libraries, surveys, videos, papers, and blogs. It includes resources on transformer mechanistic interpretability, visualization, interventions, probing, fine-tuning, feature representation, learning dynamics, knowledge editing, hallucination detection, and redundancy analysis. The repository aims to provide a comprehensive overview of tools, techniques, and methods for understanding and interpreting the inner workings of large language models.

Awesome-Interpretability-in-Large-Language-Models
This repository is a collection of resources focused on interpretability in large language models (LLMs). It aims to help beginners get started in the area and keep researchers updated on the latest progress. It includes libraries, blogs, tutorials, forums, tools, programs, papers, and more related to interpretability in LLMs.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.