
Crane
A Pure Rust based LLM (Any LLM based MLLM such as Spark-TTS) Inference Engine, powering by Candle framework.
Stars: 66
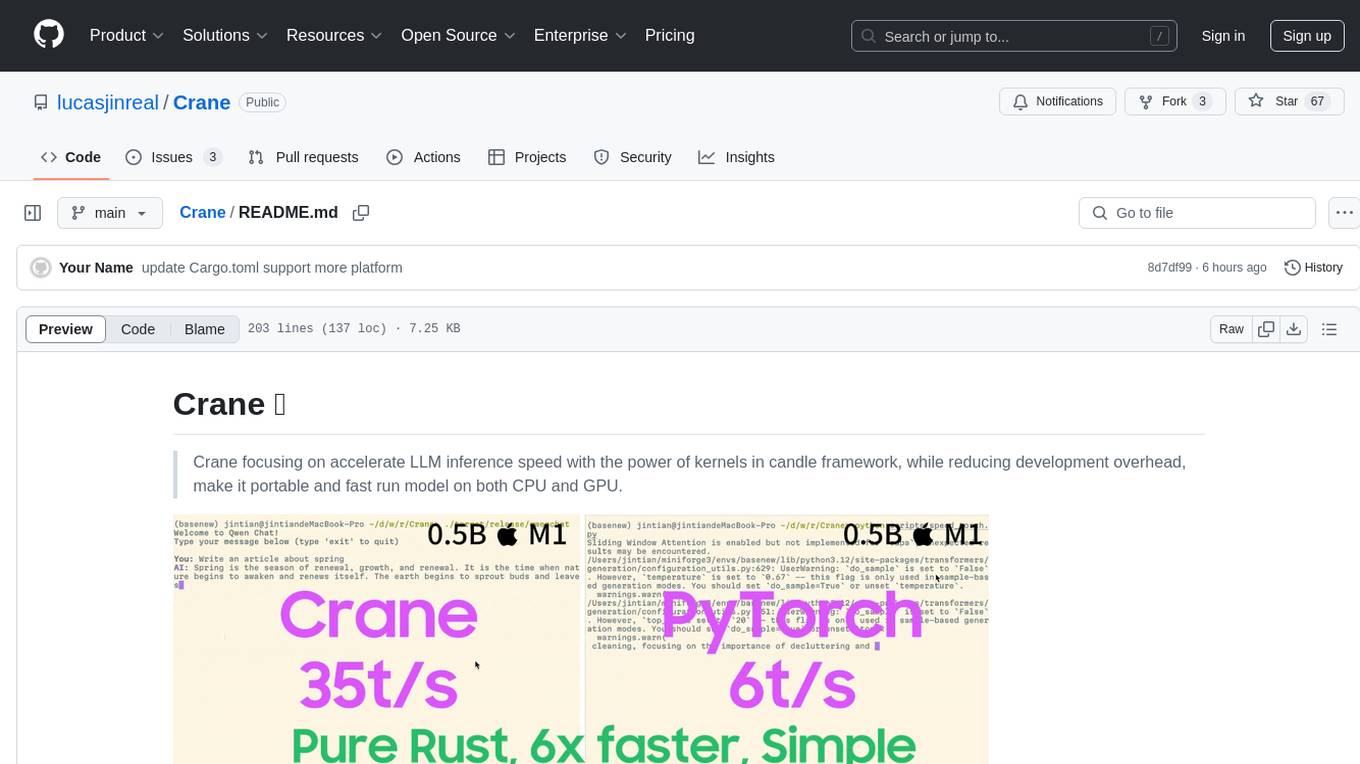
Crane is a high-performance inference framework leveraging Rust's Candle for maximum speed on CPU/GPU. It focuses on accelerating LLM inference speed with optimized kernels, reducing development overhead, and ensuring portability for running models on both CPU and GPU. Supported models include TTS systems like Spark-TTS and Orpheus-TTS, foundation models like Qwen2.5 series and basic LLMs, and multimodal models like Namo-R1 and Qwen2.5-VL. Key advantages of Crane include blazing-fast inference outperforming native PyTorch, Rust-powered to eliminate C++ complexity, Apple Silicon optimized for GPU acceleration via Metal, and hardware agnostic with a unified codebase for CPU/CUDA/Metal execution. Crane simplifies deployment with the ability to add new models with less than 100 lines of code in most cases.
README:
Crane focusing on accelerate LLM inference speed with the power of kernels in candle framework, while reducing development overhead, make it portable and fast run model on both CPU and GPU.

Crane (🦩) - Candle-based Rust Accelerated Neural Engine A high-performance inference framework leveraging Rust's Candle for maximum speed on CPU/GPU.
Supported Models:
- 🎙️ TTS Systems:Spark-TTS | Orpheus-TTS (WIP)
- 🧠 Foundation Models:Qwen2.5 series (Base/VL), Basic LLMs
- 🌌 Multimodal Models: Namo-R1, Qwen2.5-VL
Key Advantages:
- 🚀 Blazing-Fast Inference: Outperforms native PyTorch with Candle's optimized kernels;
- 🦀 Rust-Powered: Eliminate C++ complexity while maintaining native performance;
- 🍎 Apple Silicon Optimized: Achieve GPU acceleration via Metal on macOS devices;
- 🤖 Hardware Agnostic: Unified codebase for CPU/CUDA/Metal execution;
-
2025.03.21: 🔥 Qwen2.5 a more transformers liked Rust interface were supported, you now use Crane just like in your python; -
2025.03.19: 🔥 project initialized;
While traditional approaches face limitations:
- PyTorch's suboptimal inference performance
- llama.cpp's complex C++ codebase and model integration
Crane bridges the gap through:
- Candle Framework: Combines Rust's efficiency with PyTorch-like ergonomics
- Cross-Platform Acceleration: Metal GPU support achieves 3-5x speedup over CPU-only
- Simplified Deployment: Add new models with <100 LOC in most cases
💡 Pro Tip: For macOS developers, Crane delivers comparable performance to llama.cpp with significantly lower maintenance overhead. You can use it out of box directly without any GGUF conversion or something like install llama.cpp etc.
Speed up your LLM inference speed on M series Apple Silicon devices to 6x with almost simillar code in your python (No quantization needed!):
use clap::Parser;
use crane_core::{
Msg,
autotokenizer::AutoTokenizer,
chat::Role,
generation::{GenerationConfig, based::ModelForCausalLM, streamer::TextStreamer},
models::{DType, Device, qwen25::Model as Qwen25Model},
};
#[derive(Parser, Debug)]
#[clap(about, version, author)]
struct Args {
#[clap(short('m'), long, default_value = "checkpoints/Qwen2.5-0.5B-Instruct")]
model_path: String,
}
fn main() {
crane_core::utils::utils::print_candle_build_info();
let args = Args::parse();
let dtype = DType::F16;
let device = Device::Cpu;
let tokenizer = AutoTokenizer::from_pretrained(&args.model_path, None).unwrap();
let mut model = Qwen25Model::new(&args.model_path, &device, &dtype).unwrap();
let gen_config = GenerationConfig {
max_new_tokens: 235,
temperature: Some(0.67),
top_p: Some(1.0),
repetition_penalty: 1.1,
repeat_last_n: 1,
do_sample: false,
pad_token_id: tokenizer.get_token("<|end_of_text|>"),
eos_token_id: tokenizer.get_token("<|im_end|>"),
report_speed: true,
};
let chats = [
Msg!(Role::User, "hello"),
Msg!(Role::Assistant, "Hi, how are you?"),
Msg!(Role::User, "I am OK, tell me some truth about Yoga."),
];
let prompt = tokenizer.apply_chat_template(&chats, true).unwrap();
println!("prompt templated: {:?}\n", prompt);
let input_ids = model.prepare_inputs(&prompt).unwrap();
let _ = model.warnmup();
let mut streamer = TextStreamer {
tokenizer: tokenizer.clone(),
buffer: String::new(),
};
let output_ids = model
.generate(&input_ids, &gen_config, Some(&mut streamer))
.map_err(|e| format!("Generation failed: {}", e))
.unwrap();
let res = tokenizer.decode(&output_ids, false).unwrap();
println!("Output: {}", res);
}Above is all the codes you need to run end2end chat in Qwen2.5 in pure Rust, nothing overhead compare with llama.cpp.
Then, your LLM inference is 6X faster on mac without Quantization! Enabling Quantization could be even faster!
For cli chat, run:
# download models of Qwen2.5
mkdir -p checkpoints/
huggingface-cli download Qwen/Qwen2.5-0.5B-Instruct --local-dir checkpoints/Qwen2.5-0.5B-Instruct
cargo run --bin qwenchat --release
To use crane, here are some notes:
-
crane-core: All models comes into core, this is a lib; -
crane: All Apps (runnable AI pipelines, such as Qwen2-Chat, Spark-TTS, Qwen2.5-VL etc), you can build your apps inside it, each app is a binary for demonstration purpose; -
crane-oai: OpenAI API server serving various services in OpenAI format;
-
Make sure latest Rust were installed;
-
Build:
cargo run --bin llmbench --release cargo run --bin qwenchat --release
That's it!
Now you can run LLM extremly fast (about 6x faster than vanilla transformers on M1)!
PR are welcomed right now! Since we need support a brand range of new models, but both Crane and HuggingFace's Candle is very limited model scope, so please join and help!
- How to add a new model?
Generally speaking, you can reference to: crane-core/src/models/siglip2.rs for support new model, and all new added models should placed into crane-core/src/models and add pub mod in crane-core/src/models/mod.rs .
For me, the easiest way is to using Claude 3.7 to help write Rust conversion from pytorch code into Rust Candle code, and then manually fixing issues, once the float values of output are matched, the model can be ready to go.
- How to support a new arch?
As all we know, a TTS model or any model based on LLM, it might consist of different modules, for example, in Spark-TTS, we will have a BiCodec Model before LLM, these module can be made into a separated module, and for Spark-TTS itself, we can gathering all module to inference it correctly.
One can reference to crane-core/src/models/namo2.rs for new arch add, which uses Siglip2, mm_projector, Qwen2.5 to support a VL model.
Here are some speedup compare between Crane can other framework.
f32:
| Model/Platform | mac M1 metal | mac M1 cpu | mac M4 metal | v100 GPU | pytorch |
|---|---|---|---|---|---|
| Qwen2.5-500M | 17.5 t/s | 14 t/s | / | 6.9 t/s | |
| Qwen2.5-VL-3B | / | / | / |
f16:
| Model/Platform | mac M1 metal | mac M1 metal 16 | mac M4 metal 16 | pytorch |
|---|---|---|---|---|
| Qwen2.5-500M | 17.5 t/s | 35 t/s | / | 6.9 t/s |
| Qwen2.5-VL-3B | / | / | / |
- Crane is blazing fast on macOS with metal, useful for you to run local models;
- int8 quantization still on the way, it's even faster!
If you use Crane in your research or projects, please cite using BibTeX:
@misc{Crane,
author = {lucasjinreal},
title = {{Crane: Candle-based Rust Accelerated Neural Engine}},
howpublished = {\url{https://github.com/lucasjinreal/Crane}},
year = {2025}
}For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for Crane
Similar Open Source Tools
Crane
Crane is a high-performance inference framework leveraging Rust's Candle for maximum speed on CPU/GPU. It focuses on accelerating LLM inference speed with optimized kernels, reducing development overhead, and ensuring portability for running models on both CPU and GPU. Supported models include TTS systems like Spark-TTS and Orpheus-TTS, foundation models like Qwen2.5 series and basic LLMs, and multimodal models like Namo-R1 and Qwen2.5-VL. Key advantages of Crane include blazing-fast inference outperforming native PyTorch, Rust-powered to eliminate C++ complexity, Apple Silicon optimized for GPU acceleration via Metal, and hardware agnostic with a unified codebase for CPU/CUDA/Metal execution. Crane simplifies deployment with the ability to add new models with less than 100 lines of code in most cases.
llm-interface
LLM Interface is an npm module that streamlines interactions with various Large Language Model (LLM) providers in Node.js applications. It offers a unified interface for switching between providers and models, supporting 36 providers and hundreds of models. Features include chat completion, streaming, error handling, extensibility, response caching, retries, JSON output, and repair. The package relies on npm packages like axios, @google/generative-ai, dotenv, jsonrepair, and loglevel. Installation is done via npm, and usage involves sending prompts to LLM providers. Tests can be run using npm test. Contributions are welcome under the MIT License.
pipecat
Pipecat is an open-source framework designed for building generative AI voice bots and multimodal assistants. It provides code building blocks for interacting with AI services, creating low-latency data pipelines, and transporting audio, video, and events over the Internet. Pipecat supports various AI services like speech-to-text, text-to-speech, image generation, and vision models. Users can implement new services and contribute to the framework. Pipecat aims to simplify the development of applications like personal coaches, meeting assistants, customer support bots, and more by providing a complete framework for integrating AI services.
spandrel
Spandrel is a library for loading and running pre-trained PyTorch models. It automatically detects the model architecture and hyperparameters from model files, and provides a unified interface for running models.

auto-news
Auto-News is an automatic news aggregator tool that utilizes Large Language Models (LLM) to pull information from various sources such as Tweets, RSS feeds, YouTube videos, web articles, Reddit, and journal notes. The tool aims to help users efficiently read and filter content based on personal interests, providing a unified reading experience and organizing information effectively. It features feed aggregation with summarization, transcript generation for videos and articles, noise reduction, task organization, and deep dive topic exploration. The tool supports multiple LLM backends, offers weekly top-k aggregations, and can be deployed on Linux/MacOS using docker-compose or Kubernetes.

X-AnyLabeling
X-AnyLabeling is a robust annotation tool that seamlessly incorporates an AI inference engine alongside an array of sophisticated features. Tailored for practical applications, it is committed to delivering comprehensive, industrial-grade solutions for image data engineers. This tool excels in swiftly and automatically executing annotations across diverse and intricate tasks.
dive
Dive is an AI toolkit for Go that enables the creation of specialized teams of AI agents and seamless integration with leading LLMs. It offers a CLI and APIs for easy integration, with features like creating specialized agents, hierarchical agent systems, declarative configuration, multiple LLM support, extended reasoning, model context protocol, advanced model settings, tools for agent capabilities, tool annotations, streaming, CLI functionalities, thread management, confirmation system, deep research, and semantic diff. Dive also provides semantic diff analysis, unified interface for LLM providers, tool system with annotations, custom tool creation, and support for various verified models. The toolkit is designed for developers to build AI-powered applications with rich agent capabilities and tool integrations.
Scrapling
Scrapling is a high-performance, intelligent web scraping library for Python that automatically adapts to website changes while significantly outperforming popular alternatives. For both beginners and experts, Scrapling provides powerful features while maintaining simplicity. It offers features like fast and stealthy HTTP requests, adaptive scraping with smart element tracking and flexible selection, high performance with lightning-fast speed and memory efficiency, and developer-friendly navigation API and rich text processing. It also includes advanced parsing features like smart navigation, content-based selection, handling structural changes, and finding similar elements. Scrapling is designed to handle anti-bot protections and website changes effectively, making it a versatile tool for web scraping tasks.

coreply
Coreply is an open-source Android app that provides texting suggestions while typing, enhancing the typing experience with intelligent, context-aware suggestions. It supports various texting apps and offers real-time AI suggestions, customizable LLM settings, and ensures no data collection. Users can install the app, configure it with an API key, and start receiving suggestions while typing in messaging apps. The tool supports different AI models from providers like OpenAI, Google AI Studio, Openrouter, Groq, and Codestral for chat completion and fill-in-the-middle tasks.

lingo.dev
Replexica AI automates software localization end-to-end, producing authentic translations instantly across 60+ languages. Teams can do localization 100x faster with state-of-the-art quality, reaching more paying customers worldwide. The tool offers a GitHub Action for CI/CD automation and supports various formats like JSON, YAML, CSV, and Markdown. With lightning-fast AI localization, auto-updates, native quality translations, developer-friendly CLI, and scalability for startups and enterprise teams, Replexica is a top choice for efficient and effective software localization.

superlinked
Superlinked is a compute framework for information retrieval and feature engineering systems, focusing on converting complex data into vector embeddings for RAG, Search, RecSys, and Analytics stack integration. It enables custom model performance in machine learning with pre-trained model convenience. The tool allows users to build multimodal vectors, define weights at query time, and avoid postprocessing & rerank requirements. Users can explore the computational model through simple scripts and python notebooks, with a future release planned for production usage with built-in data infra and vector database integrations.

easy-dataset
Easy Dataset is a specialized application designed to streamline the creation of fine-tuning datasets for Large Language Models (LLMs). It offers an intuitive interface for uploading domain-specific files, intelligently splitting content, generating questions, and producing high-quality training data for model fine-tuning. With Easy Dataset, users can transform domain knowledge into structured datasets compatible with all OpenAI-format compatible LLM APIs, making the fine-tuning process accessible and efficient.

kernel-memory
Kernel Memory (KM) is a multi-modal AI Service specialized in the efficient indexing of datasets through custom continuous data hybrid pipelines, with support for Retrieval Augmented Generation (RAG), synthetic memory, prompt engineering, and custom semantic memory processing. KM is available as a Web Service, as a Docker container, a Plugin for ChatGPT/Copilot/Semantic Kernel, and as a .NET library for embedded applications. Utilizing advanced embeddings and LLMs, the system enables Natural Language querying for obtaining answers from the indexed data, complete with citations and links to the original sources. Designed for seamless integration as a Plugin with Semantic Kernel, Microsoft Copilot and ChatGPT, Kernel Memory enhances data-driven features in applications built for most popular AI platforms.
HuatuoGPT-o1
HuatuoGPT-o1 is a medical language model designed for advanced medical reasoning. It can identify mistakes, explore alternative strategies, and refine answers. The model leverages verifiable medical problems and a specialized medical verifier to guide complex reasoning trajectories and enhance reasoning through reinforcement learning. The repository provides access to models, data, and code for HuatuoGPT-o1, allowing users to deploy the model for medical reasoning tasks.

OSA
OSA (Open-Source-Advisor) is a tool designed to improve the quality of scientific open source projects by automating the generation of README files, documentation, CI/CD scripts, and providing advice and recommendations for repositories. It supports various LLMs accessible via API, local servers, or osa_bot hosted on ITMO servers. OSA is currently under development with features like README file generation, documentation generation, automatic implementation of changes, LLM integration, and GitHub Action Workflow generation. It requires Python 3.10 or higher and tokens for GitHub/GitLab/Gitverse and LLM API key. Users can install OSA using PyPi or build from source, and run it using CLI commands or Docker containers.

biochatter
Generative AI models have shown tremendous usefulness in increasing accessibility and automation of a wide range of tasks. This repository contains the `biochatter` Python package, a generic backend library for the connection of biomedical applications to conversational AI. It aims to provide a common framework for deploying, testing, and evaluating diverse models and auxiliary technologies in the biomedical domain. BioChatter is part of the BioCypher ecosystem, connecting natively to BioCypher knowledge graphs.
For similar tasks

AutoGPTQ
AutoGPTQ is an easy-to-use LLM quantization package with user-friendly APIs, based on GPTQ algorithm (weight-only quantization). It provides a simple and efficient way to quantize large language models (LLMs) to reduce their size and computational cost while maintaining their performance. AutoGPTQ supports a wide range of LLM models, including GPT-2, GPT-J, OPT, and BLOOM. It also supports various evaluation tasks, such as language modeling, sequence classification, and text summarization. With AutoGPTQ, users can easily quantize their LLM models and deploy them on resource-constrained devices, such as mobile phones and embedded systems.

Qwen-TensorRT-LLM
Qwen-TensorRT-LLM is a project developed for the NVIDIA TensorRT Hackathon 2023, focusing on accelerating inference for the Qwen-7B-Chat model using TRT-LLM. The project offers various functionalities such as FP16/BF16 support, INT8 and INT4 quantization options, Tensor Parallel for multi-GPU parallelism, web demo setup with gradio, Triton API deployment for maximum throughput/concurrency, fastapi integration for openai requests, CLI interaction, and langchain support. It supports models like qwen2, qwen, and qwen-vl for both base and chat models. The project also provides tutorials on Bilibili and blogs for adapting Qwen models in NVIDIA TensorRT-LLM, along with hardware requirements and quick start guides for different model types and quantization methods.

stable-diffusion.cpp
The stable-diffusion.cpp repository provides an implementation for inferring stable diffusion in pure C/C++. It offers features such as support for different versions of stable diffusion, lightweight and dependency-free implementation, various quantization support, memory-efficient CPU inference, GPU acceleration, and more. Users can download the built executable program or build it manually. The repository also includes instructions for downloading weights, building from scratch, using different acceleration methods, running the tool, converting weights, and utilizing various features like Flash Attention, ESRGAN upscaling, PhotoMaker support, and more. Additionally, it mentions future TODOs and provides information on memory requirements, bindings, UIs, contributors, and references.

LMOps
LMOps is a research initiative focusing on fundamental research and technology for building AI products with foundation models, particularly enabling AI capabilities with Large Language Models (LLMs) and Generative AI models. The project explores various aspects such as prompt optimization, longer context handling, LLM alignment, acceleration of LLMs, LLM customization, and understanding in-context learning. It also includes tools like Promptist for automatic prompt optimization, Structured Prompting for efficient long-sequence prompts consumption, and X-Prompt for extensible prompts beyond natural language. Additionally, LLMA accelerators are developed to speed up LLM inference by referencing and copying text spans from documents. The project aims to advance technologies that facilitate prompting language models and enhance the performance of LLMs in various scenarios.

Awesome-Efficient-LLM
Awesome-Efficient-LLM is a curated list focusing on efficient large language models. It includes topics such as knowledge distillation, network pruning, quantization, inference acceleration, efficient MOE, efficient architecture of LLM, KV cache compression, text compression, low-rank decomposition, hardware/system, tuning, and survey. The repository provides a collection of papers and projects related to improving the efficiency of large language models through various techniques like sparsity, quantization, and compression.

TensorRT-Model-Optimizer
The NVIDIA TensorRT Model Optimizer is a library designed to quantize and compress deep learning models for optimized inference on GPUs. It offers state-of-the-art model optimization techniques including quantization and sparsity to reduce inference costs for generative AI models. Users can easily stack different optimization techniques to produce quantized checkpoints from torch or ONNX models. The quantized checkpoints are ready for deployment in inference frameworks like TensorRT-LLM or TensorRT, with planned integrations for NVIDIA NeMo and Megatron-LM. The tool also supports 8-bit quantization with Stable Diffusion for enterprise users on NVIDIA NIM. Model Optimizer is available for free on NVIDIA PyPI, and this repository serves as a platform for sharing examples, GPU-optimized recipes, and collecting community feedback.
lightning-bolts
Bolts package provides a variety of components to extend PyTorch Lightning, such as callbacks & datasets, for applied research and production. Users can accelerate Lightning training with the Torch ORT Callback to optimize ONNX graph for faster training & inference. Additionally, users can introduce sparsity with the SparseMLCallback to accelerate inference by leveraging the DeepSparse engine. Specific research implementations are encouraged, with contributions that help train SSL models and integrate with Lightning Flash for state-of-the-art models in applied research.

ms-swift
ms-swift is an official framework provided by the ModelScope community for fine-tuning and deploying large language models and multi-modal large models. It supports training, inference, evaluation, quantization, and deployment of over 400 large models and 100+ multi-modal large models. The framework includes various training technologies and accelerates inference, evaluation, and deployment modules. It offers a Gradio-based Web-UI interface and best practices for easy application of large models. ms-swift supports a wide range of model types, dataset types, hardware support, lightweight training methods, distributed training techniques, quantization training, RLHF training, multi-modal training, interface training, plugin and extension support, inference acceleration engines, model evaluation, and model quantization.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.