Best AI tools for< Port Models >
3 - AI tool Sites
DMSLOG.Ai
DMSLOG.Ai is an AI tool designed for Smart Port terminal optimization, decongestion, and decarbonation. It offers solutions powered by AI, machine learning, and digital twins to transform container terminals into Smart Ports, providing quick ROI, decongestion, and decarbonation. The tool is used globally on a daily basis, offering plug-and-play AI solutions for various terminal operations and carbon footprint monitoring.

mjslackbot.com
mjslackbot.com is a website that provides resources and information related to mjslackbot. Users can find valuable content and details about mjslackbot on this platform. The website aims to offer a comprehensive source of information for individuals interested in mjslackbot and its functionalities.

Vicarious Surgical System
Vicarious Surgical is a company that develops robotic surgical systems. Their system is designed to be minimally invasive, with a focus on abdominal access and visualization through a single port. The system is also designed to be mobile and nimble, with a patient cart that connects with the patient and a surgeon console where the surgeon sits to drive the robotic instruments and enhanced 3D high-definition camera inside the patient.
1 - Open Source AI Tools
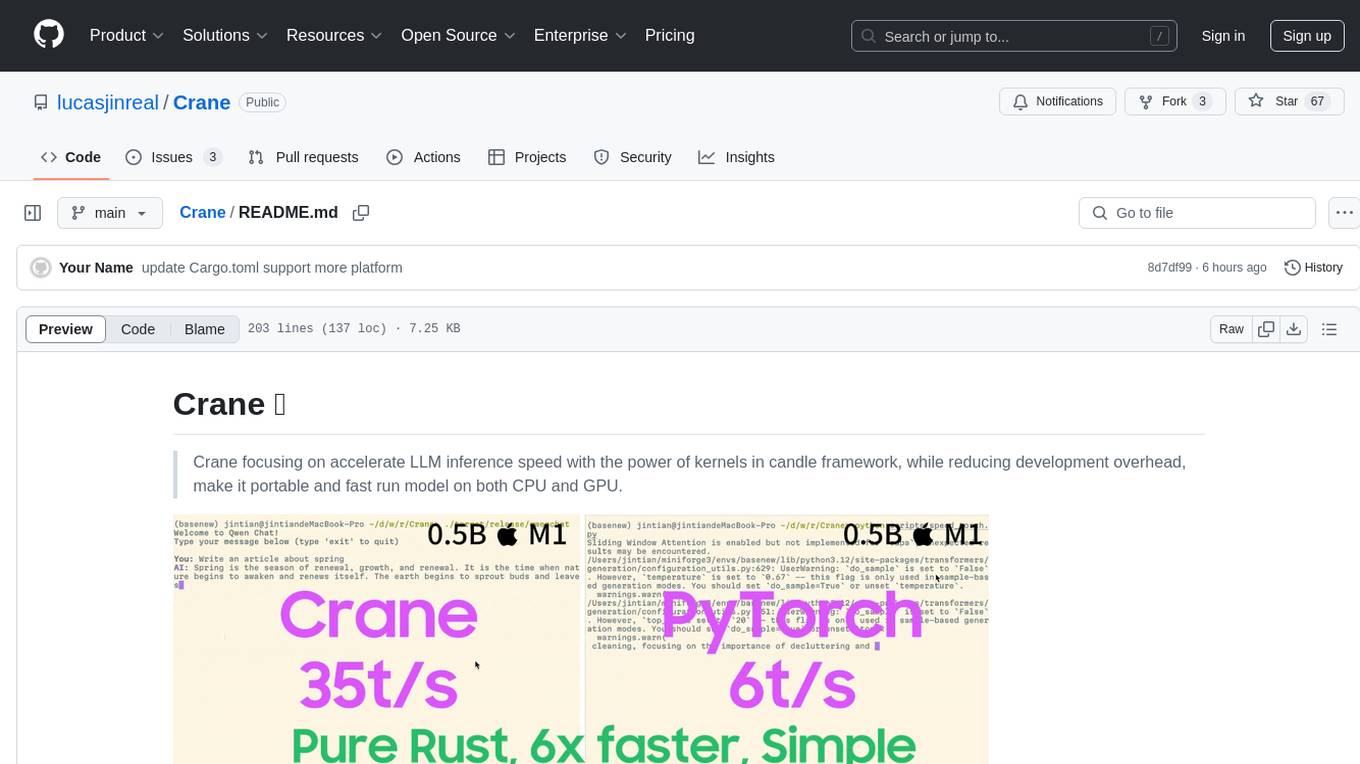
Crane
Crane is a high-performance inference framework leveraging Rust's Candle for maximum speed on CPU/GPU. It focuses on accelerating LLM inference speed with optimized kernels, reducing development overhead, and ensuring portability for running models on both CPU and GPU. Supported models include TTS systems like Spark-TTS and Orpheus-TTS, foundation models like Qwen2.5 series and basic LLMs, and multimodal models like Namo-R1 and Qwen2.5-VL. Key advantages of Crane include blazing-fast inference outperforming native PyTorch, Rust-powered to eliminate C++ complexity, Apple Silicon optimized for GPU acceleration via Metal, and hardware agnostic with a unified codebase for CPU/CUDA/Metal execution. Crane simplifies deployment with the ability to add new models with less than 100 lines of code in most cases.
6 - OpenAI Gpts
3Dスキャンできる場所は知らんけど、ニッチな旅行場所をおすすめするで!
Japanese travel guide with a focus on hidden gems and port towns
Harbor
Nautical and informative expert on harbors, their functions, and significance in trade.


GPT Enseignement Maritime
Ce chat bot est conçu pour enseigner la navigation maritime en demandant d'abord le sujet et le niveau.
COLREGs Commander
Expert in COLREGs for seafarers, offering practical guidance and insights.