
rwkv.cpp
INT4/INT5/INT8 and FP16 inference on CPU for RWKV language model
Stars: 1133
rwkv.cpp is a port of BlinkDL/RWKV-LM to ggerganov/ggml, supporting FP32, FP16, and quantized INT4, INT5, and INT8 inference. It focuses on CPU but also supports cuBLAS. The project provides a C library rwkv.h and a Python wrapper. RWKV is a large language model architecture with models like RWKV v5 and v6. It requires only state from the previous step for calculations, making it CPU-friendly on large context lengths. Users are advised to test all available formats for perplexity and latency on a representative dataset before serious use.
README:
This is a port of BlinkDL/RWKV-LM to ggerganov/ggml.
Besides the usual FP32, it supports FP16, quantized INT4, INT5 and INT8 inference. This project is focused on CPU, but cuBLAS is also supported.
This project provides a C library rwkv.h and a convinient Python wrapper for it.
RWKV is a large language model architecture, with the largest model in the family having 14B parameters. In contrast to Transformer with O(n^2) attention, RWKV requires only state from previous step to calculate logits. This makes RWKV very CPU-friendly on large context lenghts.
RWKV v5 is a major upgrade to RWKV architecture, making it competitive with Transformers in quality. RWKV v5 models are supported.
RWKV v6 is a further improvement to RWKV architecture, with better quality. RWKV v6 models are supported.
Loading LoRA checkpoints in Blealtan's format is supported through merge_lora_into_ggml.py script.
If you use rwkv.cpp for anything serious, please test all available formats for perplexity and latency on a representative dataset, and decide which trade-off is best for you.
In general, RWKV v5 models are as fast as RWKV v4 models, with minor differencies in latency and memory consumption, and with having way higher quality than v4. Therefore, it is recommended to use RWKV v5.
Below table is for reference only. Measurements were made on 4C/8T x86 CPU with AVX2, 4 threads. The models are RWKV v4 Pile 169M, RWKV v4 Pile 1.5B.
| Format | Perplexity (169M) | Latency, ms (1.5B) | File size, GB (1.5B) |
|---|---|---|---|
Q4_0 |
17.507 | 76 | 1.53 |
Q4_1 |
17.187 | 72 | 1.68 |
Q5_0 |
16.194 | 78 | 1.60 |
Q5_1 |
15.851 | 81 | 1.68 |
Q8_0 |
15.652 | 89 | 2.13 |
FP16 |
15.623 | 117 | 2.82 |
FP32 |
15.623 | 198 | 5.64 |
Measurements were made on Intel i7 13700K & NVIDIA 3060 Ti 8 GB. The model is RWKV-4-Pile-169M, 12 layers were offloaded to GPU.
Latency per token in ms shown.
| Format | 1 thread | 2 threads | 4 threads | 8 threads | 24 threads |
|---|---|---|---|---|---|
Q4_0 |
7.9 | 6.2 | 6.9 | 8.6 | 20 |
Q4_1 |
7.8 | 6.7 | 6.9 | 8.6 | 21 |
Q5_1 |
8.1 | 6.7 | 6.9 | 9.0 | 22 |
| Format | 1 thread | 2 threads | 4 threads | 8 threads | 24 threads |
|---|---|---|---|---|---|
Q4_0 |
59 | 51 | 50 | 54 | 94 |
Q4_1 |
59 | 51 | 49 | 54 | 94 |
Q5_1 |
77 | 69 | 67 | 72 | 101 |
Note: since cuBLAS is supported only for ggml_mul_mat(), we still need to use few CPU resources to execute remaining operations.
Measurements were made on CPU AMD Ryzen 9 5900X & GPU AMD Radeon RX 7900 XTX. The model is RWKV-novel-4-World-7B-20230810-ctx128k, 32 layers were offloaded to GPU.
Latency per token in ms shown.
| Format | 1 thread | 2 threads | 4 threads | 8 threads | 24 threads |
|---|---|---|---|---|---|
f16 |
94 | 91 | 94 | 106 | 944 |
Q4_0 |
83 | 77 | 75 | 110 | 1692 |
Q4_1 |
85 | 80 | 85 | 93 | 1691 |
Q5_1 |
83 | 78 | 83 | 90 | 1115 |
Note: same as cuBLAS, hipBLAS only supports ggml_mul_mat(), we still need to use few CPU resources to execute remaining operations.
Requirements: git.
git clone --recursive https://github.com/saharNooby/rwkv.cpp.git
cd rwkv.cpp
Check out Releases, download appropriate ZIP for your OS and CPU, extract rwkv library file into the repository directory.
On Windows: to check whether your CPU supports AVX2 or AVX-512, use CPU-Z.
This option is recommended for maximum performance, because the library would be built specifically for your CPU and OS.
Requirements: CMake or CMake from anaconda, Build Tools for Visual Studio 2019.
cmake .
cmake --build . --config Release
If everything went OK, bin\Release\rwkv.dll file should appear.
Refer to docs/cuBLAS_on_Windows.md for a comprehensive guide.
Refer to docs/hipBLAS_on_Windows.md for a comprehensive guide.
Requirements: CMake (Linux: sudo apt install cmake, MacOS: brew install cmake, anaconoda: cmake package).
cmake .
cmake --build . --config Release
Anaconda & M1 users: please verify that CMAKE_SYSTEM_PROCESSOR: arm64 after running cmake . — if it detects x86_64, edit the CMakeLists.txt file under the # Compile flags to add set(CMAKE_SYSTEM_PROCESSOR "arm64").
If everything went OK, librwkv.so (Linux) or librwkv.dylib (MacOS) file should appear in the base repo folder.
cmake . -DRWKV_CUBLAS=ON
cmake --build . --config Release
If everything went OK, librwkv.so (Linux) or librwkv.dylib (MacOS) file should appear in the base repo folder.
Requirements: Python 3.x with PyTorch.
First, download a model from Hugging Face like this one.
Second, convert it into rwkv.cpp format using following commands:
# Windows
python python\convert_pytorch_to_ggml.py C:\RWKV-4-Pile-169M-20220807-8023.pth C:\rwkv.cpp-169M.bin FP16
# Linux / MacOS
python python/convert_pytorch_to_ggml.py ~/Downloads/RWKV-4-Pile-169M-20220807-8023.pth ~/Downloads/rwkv.cpp-169M.bin FP16
Optionally, quantize the model into one of quantized formats from the table above:
# Windows
python python\quantize.py C:\rwkv.cpp-169M.bin C:\rwkv.cpp-169M-Q5_1.bin Q5_1
# Linux / MacOS
python python/quantize.py ~/Downloads/rwkv.cpp-169M.bin ~/Downloads/rwkv.cpp-169M-Q5_1.bin Q5_1
Requirements: Python 3.x with numpy. If using Pile or Raven models, tokenizers is also required.
To generate some text, run:
# Windows
python python\generate_completions.py C:\rwkv.cpp-169M-Q5_1.bin
# Linux / MacOS
python python/generate_completions.py ~/Downloads/rwkv.cpp-169M-Q5_1.bin
To chat with a bot, run:
# Windows
python python\chat_with_bot.py C:\rwkv.cpp-169M-Q5_1.bin
# Linux / MacOS
python python/chat_with_bot.py ~/Downloads/rwkv.cpp-169M-Q5_1.bin
Edit generate_completions.py or chat_with_bot.py to change prompts and sampling settings.
The short and simple script inference_example.py demostrates the use of rwkv.cpp in Python.
To use rwkv.cpp in C/C++, include the header rwkv.h.
To use rwkv.cpp in any other language, see Bindings section below. If your language is missing, you can try to bind to the C API using the tooling provided by your language.
These projects wrap rwkv.cpp for easier use in other languages/frameworks.
- Golang: seasonjs/rwkv
- Node.js: Atome-FE/llama-node
ggml moves fast, and can occasionally break compatibility with older file formats.
rwkv.cpp will attempt it's best to explain why a model file can't be loaded and what next steps are available to the user.
For reference only, here is a list of latest versions of rwkv.cpp that have supported older formats. No support will be provided for these versions.
-
Q4_2, old layout of quantized formats -
Q4_3,Q4_1_O
See also docs/FILE_FORMAT.md for version numbers of rwkv.cpp model files and their changelog.
Please follow the code style described in docs/CODE_STYLE.md.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for rwkv.cpp
Similar Open Source Tools
rwkv.cpp
rwkv.cpp is a port of BlinkDL/RWKV-LM to ggerganov/ggml, supporting FP32, FP16, and quantized INT4, INT5, and INT8 inference. It focuses on CPU but also supports cuBLAS. The project provides a C library rwkv.h and a Python wrapper. RWKV is a large language model architecture with models like RWKV v5 and v6. It requires only state from the previous step for calculations, making it CPU-friendly on large context lengths. Users are advised to test all available formats for perplexity and latency on a representative dataset before serious use.
ai-elements
AI Elements is a component library built on top of shadcn/ui to help build AI-native applications faster. It provides pre-built, customizable React components specifically designed for AI applications, including conversations, messages, code blocks, reasoning displays, and more. The CLI makes it easy to add these components to your Next.js project.

wa_llm
WhatsApp Group Summary Bot is an AI-powered tool that joins WhatsApp groups, tracks conversations, and generates intelligent summaries. It features automated group chat responses, LLM-based conversation summaries, knowledge base integration, persistent message history with PostgreSQL, support for multiple message types, group management, and a REST API with Swagger docs. Prerequisites include Docker, Python 3.12+, PostgreSQL with pgvector extension, Voyage AI API key, and a WhatsApp account for the bot. The tool can be quickly set up by cloning the repository, configuring environment variables, starting services, and connecting devices. It offers API usage for loading new knowledge base topics and generating & dispatching summaries to managed groups. The project architecture includes FastAPI backend, WhatsApp Web API client, PostgreSQL database with vector storage, and AI-powered message processing.

graphrag-visualizer
GraphRAG Visualizer is an application designed to visualize Microsoft GraphRAG artifacts by uploading parquet files generated from the GraphRAG indexing pipeline. Users can view and analyze data in 2D or 3D graphs, display data tables, search for specific nodes or relationships, and process artifacts locally for data security and privacy.
cortex.cpp
Cortex.cpp is an open-source platform designed as the brain for robots, offering functionalities such as vision, speech, language, tabular data processing, and action. It provides an AI platform for running AI models with multi-engine support, hardware optimization with automatic GPU detection, and an OpenAI-compatible API. Users can download models from the Hugging Face model hub, run models, manage resources, and access advanced features like multiple quantizations and engine management. The tool is under active development, promising rapid improvements for users.
aiosmb
aiosmb is a fully asynchronous SMB library written in pure Python, supporting Python 3.7 and above. It offers various authentication methods such as Kerberos, NTLM, SSPI, and NEGOEX. The library supports connections over TCP and QUIC protocols, with proxy support for SOCKS4 and SOCKS5. Users can specify an SMB connection using a URL format, making it easier to authenticate and connect to SMB hosts. The project aims to implement DCERPC features, VSS mountpoint operations, and other enhancements in the future. It is inspired by Impacket and AzureADJoinedMachinePTC projects.

TPI-LLM
TPI-LLM (Tensor Parallelism Inference for Large Language Models) is a system designed to bring LLM functions to low-resource edge devices, addressing privacy concerns by enabling LLM inference on edge devices with limited resources. It leverages multiple edge devices for inference through tensor parallelism and a sliding window memory scheduler to minimize memory usage. TPI-LLM demonstrates significant improvements in TTFT and token latency compared to other models, and plans to support infinitely large models with low token latency in the future.
gollama
Gollama is a delightful tool that brings Ollama, your offline conversational AI companion, directly into your terminal. It provides a fun and interactive way to generate responses from various models without needing internet connectivity. Whether you're brainstorming ideas, exploring creative writing, or just looking for inspiration, Gollama is here to assist you. The tool offers an interactive interface, customizable prompts, multiple models selection, and visual feedback to enhance user experience. It can be installed via different methods like downloading the latest release, using Go, running with Docker, or building from source. Users can interact with Gollama through various options like specifying a custom base URL, prompt, model, and enabling raw output mode. The tool supports different modes like interactive, piped, CLI with image, and TUI with image. Gollama relies on third-party packages like bubbletea, glamour, huh, and lipgloss. The roadmap includes implementing piped mode, support for extracting codeblocks, copying responses/codeblocks to clipboard, GitHub Actions for automated releases, and downloading models directly from Ollama using the rest API. Contributions are welcome, and the project is licensed under the MIT License.
chonkie
Chonkie is a feature-rich, easy-to-use, fast, lightweight, and wide-support chunking library designed to efficiently split texts into chunks. It integrates with various tokenizers, embedding models, and APIs, supporting 56 languages and offering cloud-ready functionality. Chonkie provides a modular pipeline approach called CHOMP for text processing, chunking, post-processing, and exporting. With multiple chunkers, refineries, porters, and handshakes, Chonkie offers a comprehensive solution for text chunking needs. It includes 24+ integrations, 3+ LLM providers, 2+ refineries, 2+ porters, and 4+ vector database connections, making it a versatile tool for text processing and analysis.
foul-play
Foul Play is a Pokémon battle-bot that can play single battles in all generations on Pokemon Showdown. It requires Python 3.10+. The bot uses environment variables for configuration and supports different game modes and battle strategies. Users can specify teams and choose between algorithms like Monte-Carlo Tree Search and Expectiminimax. Foul Play can be run locally or with Docker, and the engine used for battles must be built from source. The tool provides flexibility in gameplay and strategy for Pokémon battles.
Large-Language-Models-play-StarCraftII
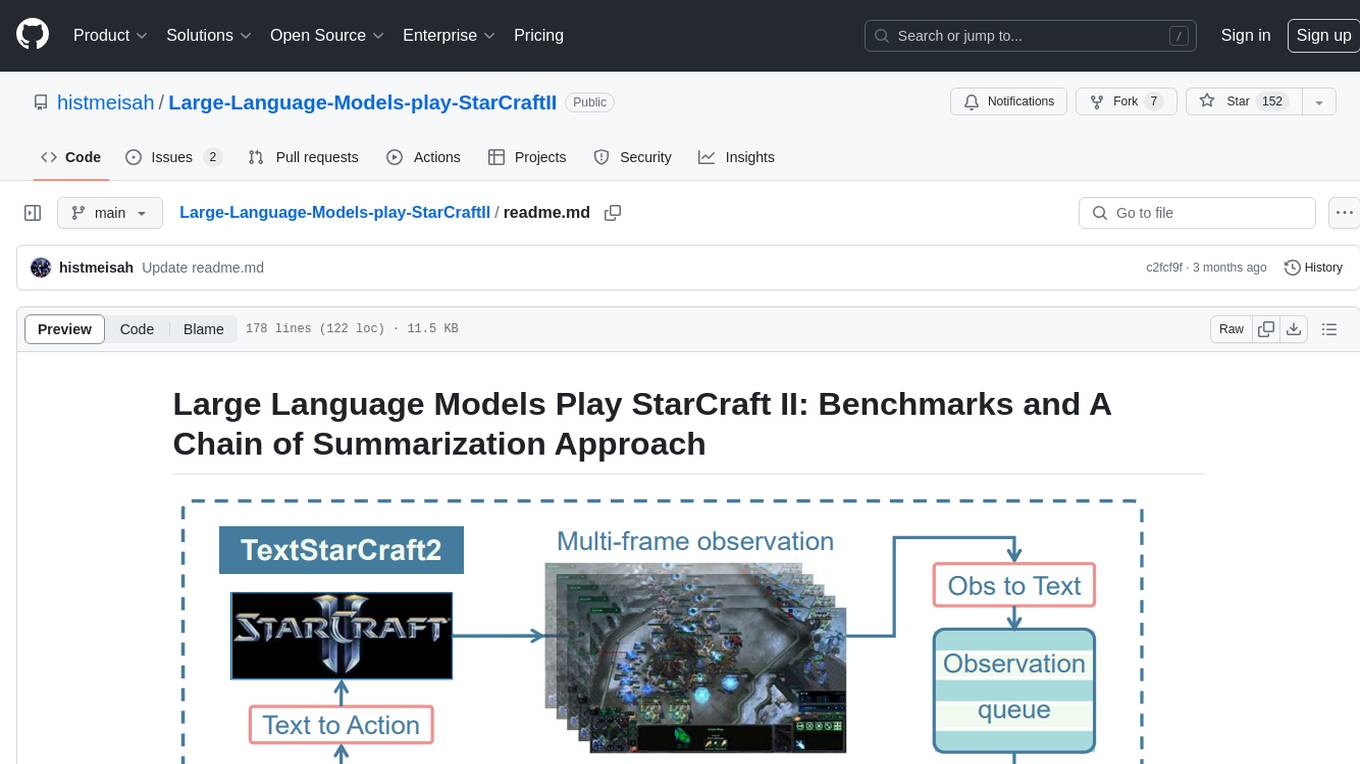
Large Language Models Play StarCraft II is a project that explores the capabilities of large language models (LLMs) in playing the game StarCraft II. The project introduces TextStarCraft II, a textual environment for the game, and a Chain of Summarization method for analyzing game information and making strategic decisions. Through experiments, the project demonstrates that LLM agents can defeat the built-in AI at a challenging difficulty level. The project provides benchmarks and a summarization approach to enhance strategic planning and interpretability in StarCraft II gameplay.
mcp-ts-template
The MCP TypeScript Server Template is a production-grade framework for building powerful and scalable Model Context Protocol servers with TypeScript. It features built-in observability, declarative tooling, robust error handling, and a modular, DI-driven architecture. The template is designed to be AI-agent-friendly, providing detailed rules and guidance for developers to adhere to best practices. It enforces architectural principles like 'Logic Throws, Handler Catches' pattern, full-stack observability, declarative components, and dependency injection for decoupling. The project structure includes directories for configuration, container setup, server resources, services, storage, utilities, tests, and more. Configuration is done via environment variables, and key scripts are available for development, testing, and publishing to the MCP Registry.
ovos-installer
The ovos-installer is a simple and multilingual tool designed to install Open Voice OS and HiveMind using Bash, Whiptail, and Ansible. It supports various Linux distributions and provides an automated installation process. Users can easily start and stop services, update their Open Voice OS instance, and uninstall the tool if needed. The installer also allows for non-interactive installation through scenario files. It offers a user-friendly way to set up Open Voice OS on different systems.
StableToolBench
StableToolBench is a new benchmark developed to address the instability of Tool Learning benchmarks. It aims to balance stability and reality by introducing features like Virtual API System, Solvable Queries, and Stable Evaluation System. The benchmark ensures consistency through a caching system and API simulators, filters queries based on solvability using LLMs, and evaluates model performance using GPT-4 with metrics like Solvable Pass Rate and Solvable Win Rate.

MooER
MooER (摩耳) is an LLM-based speech recognition and translation model developed by Moore Threads. It allows users to transcribe speech into text (ASR) and translate speech into other languages (AST) in an end-to-end manner. The model was trained using 5K hours of data and is now also available with an 80K hours version. MooER is the first LLM-based speech model trained and inferred using domestic GPUs. The repository includes pretrained models, inference code, and a Gradio demo for a better user experience.

StableToolBench
StableToolBench is a new benchmark developed to address the instability of Tool Learning benchmarks. It aims to balance stability and reality by introducing features such as a Virtual API System with caching and API simulators, a new set of solvable queries determined by LLMs, and a Stable Evaluation System using GPT-4. The Virtual API Server can be set up either by building from source or using a prebuilt Docker image. Users can test the server using provided scripts and evaluate models with Solvable Pass Rate and Solvable Win Rate metrics. The tool also includes model experiments results comparing different models' performance.
For similar tasks
rwkv.cpp
rwkv.cpp is a port of BlinkDL/RWKV-LM to ggerganov/ggml, supporting FP32, FP16, and quantized INT4, INT5, and INT8 inference. It focuses on CPU but also supports cuBLAS. The project provides a C library rwkv.h and a Python wrapper. RWKV is a large language model architecture with models like RWKV v5 and v6. It requires only state from the previous step for calculations, making it CPU-friendly on large context lengths. Users are advised to test all available formats for perplexity and latency on a representative dataset before serious use.
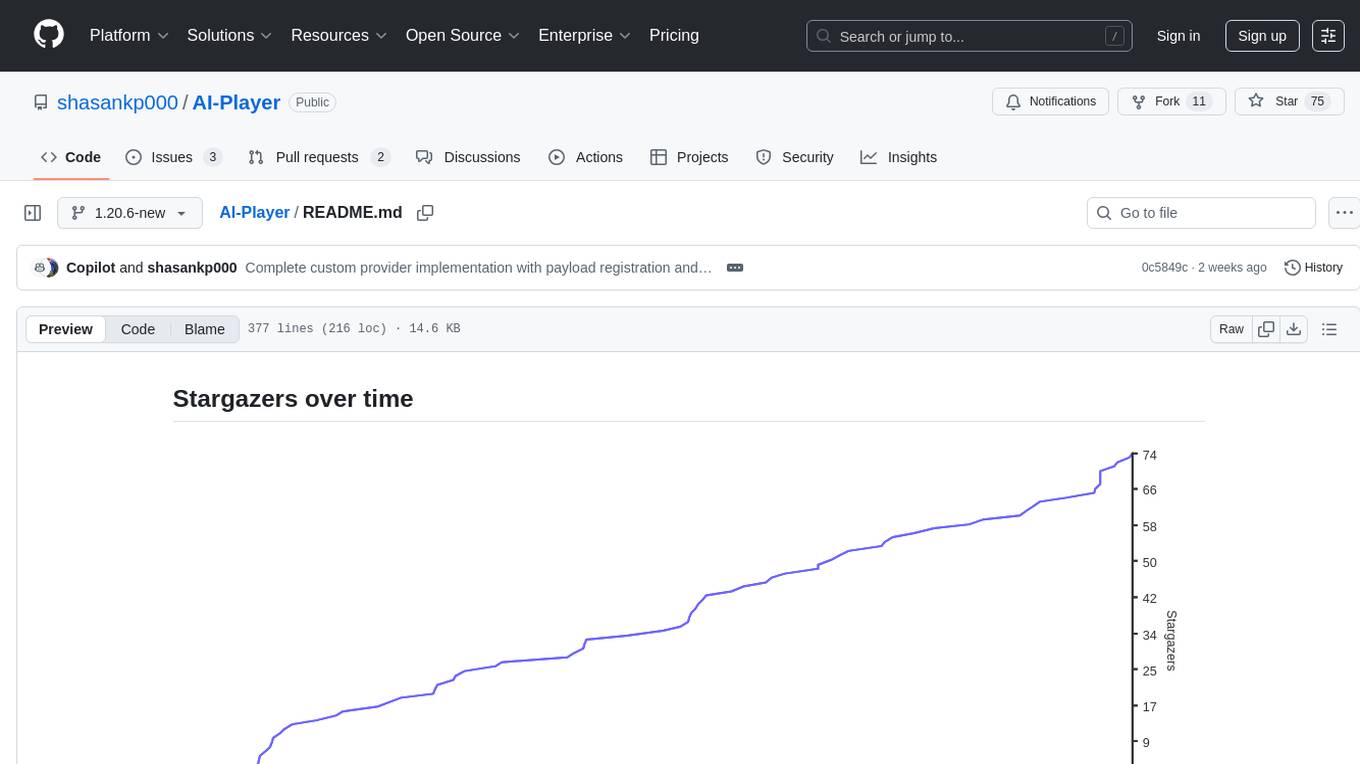
AI-Player
AI-Player is a Minecraft mod that adds an 'intelligent' second player to the game to combat loneliness while playing solo. It aims to enhance gameplay by providing companionship and interactive features. The mod leverages advanced AI algorithms and integrates with external tools to enhance the player experience. Developed with a focus on addressing the social aspect of gaming, AI-Player is a community-driven project that continues to evolve with user feedback and contributions.
fms-fsdp
The 'fms-fsdp' repository is a companion to the Foundation Model Stack, providing a (pre)training example to efficiently train FMS models, specifically Llama2, using native PyTorch features like FSDP for training and SDPA implementation of Flash attention v2. It focuses on leveraging FSDP for training efficiently, not as an end-to-end framework. The repo benchmarks training throughput on different GPUs, shares strategies, and provides installation and training instructions. It trained a model on IBM curated data achieving high efficiency and performance metrics.
UnrealOpenAIPlugin
UnrealOpenAIPlugin is a comprehensive Unreal Engine wrapper for the OpenAI API, supporting various endpoints such as Models, Completions, Chat, Images, Vision, Embeddings, Speech, Audio, Files, Moderations, Fine-tuning, and Functions. It provides support for both C++ and Blueprints, allowing users to interact with OpenAI services seamlessly within Unreal Engine projects. The plugin also includes tutorials, updates, installation instructions, authentication steps, examples of usage, blueprint nodes overview, C++ examples, plugin structure details, documentation references, tests, packaging guidelines, and limitations. Users can leverage this plugin to integrate powerful AI capabilities into their Unreal Engine projects effortlessly.
go-anthropic
Go-anthropic is an unofficial API wrapper for Anthropic Claude in Go. It supports completions, streaming completions, messages, streaming messages, vision, and tool use. Users can interact with the Anthropic Claude API to generate text completions, analyze messages, process images, and utilize specific tools for various tasks.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.