
StableToolBench
A new tool learning benchmark aiming at well-balanced stability and reality, based on ToolBench.
Stars: 135
StableToolBench is a new benchmark developed to address the instability of Tool Learning benchmarks. It aims to balance stability and reality by introducing features like Virtual API System, Solvable Queries, and Stable Evaluation System. The benchmark ensures consistency through a caching system and API simulators, filters queries based on solvability using LLMs, and evaluates model performance using GPT-4 with metrics like Solvable Pass Rate and Solvable Win Rate.
README:

Project • Server • Solvable Queries • Inference • StableToolEval • Paper • Citation
Welcome to StableToolBench. Faced with the instability of Tool Learning benchmarks, we developed this new benchmark aiming to balance the stability and reality, based on ToolBench (Qin et al., 2023).
Note that if you have applied a ToolBench key but did not get a response for a long time, please contact Shihao Liang ([email protected]) for further assistance.
- The new API simulation model, named
MirrorAPI, which is trained to simulate more than 7k tools in ToolBench. You can download it from huggingface. - The new FAC evaluation for StableToolBench, which takes final answers only into account.
- [2024.09.15] We found there exist some problems in the inference codes of ToolLLaMA v2 and we update model performance accordingly.
-
[2024.06.19] We update the OpenAI API to the newest version, which also support parallel function calling now. We also updated the model performance evaluation using
gpt-4-turbo-2024-04-09, replacinggpt-4-turbo-preview, which we found may produce unstable evaluations. The inference results (run in Feb 2024) can be found on Huggingface.
Based on the large scale of ToolBench, we introduce the following features to ensure the stability and reality of the benchmark:
- MirrorAPI, which is a trained on real request-response pairs to stably mirror more than 7k API's behaviours.
- Virtual API System, which comprises a caching system and API simulators. The caching system stores API call responses to ensure consistency, while the API simulators, powered by LLMs, are used for unavailable APIs. Note that we keep the large-scale diverse APIs environment from ToolBench.
- A New Set of Solvable Queries. Query solvability is hard to determine on the fly, causing significant randomness and instability. In StableToolBench, we use state-of-the-art LLMs to determine task solvability to filter queries beforehand. We maintain the same query and answer format as ToolBench for seamless transition from it.
- Stable Evaluation System: Implements a two-phase evaluation process using GPT-4 as an automatic evaluator. It involves judging the solvability of tasks and employing metrics like Solvable Pass Rate (SoPR) and Solvable Win Rate (SoWR). Starting with MirrorAPI, we also provide an end-to-end trained evaluator, which takes only input query and final answer into account and gives more stable and straightforward evaluation.
We now provide two simulating systems, the MirrorAPI server and the GPT based caching system.
Before you run any code, please first set up the environment by running pip install -r requirements.txt.
You need to download a set of tools to start the server. You can use either the tool set we crawled on Apr 2024, which you can download from HuggingFace or the tools for the ToolBench/StableToolBench test set, which you can download from ToolBench.
We provide two versions of model, the MirrorAPI, trained for general tool responses, and MirrorAPI-Cache, which is trained on the cache of StableToolBench for better test set tool responses. You can download them from the link above.
To start the server, you need to install vllm. Then you can start a model by running
vllm serve {model-path} --api-key EMPTY --port 12345 --served-model-name {model-name}
Then you need to fill the model-name, api-key and port you specified in server/config_mirrorapi.yml (or server/config_mirrorapi_cache.yml if you are running MirrorAPI-Cache), along with the tool folder you downloaded tools into. The parameters in the config files are:
-
api_key: The API key for VLLM model. -
api_base: The API base for VLLM models. Normallyhttp://127.0.0.1:{port}/v1 -
model: The {model-name} you specified in VLLM. -
temperature: The temperature for LLM simulation. The default value is 0. -
tools_folder: The tools environment folder path. Default to./tools. -
port: The server port to run on, default to 8080.
Then you can run python main_mirrorapi.py or python main_mirrorapi_cache.py to run the API server.
Our Virtual API server featured two components, the API simulation system with GPT 4 Turbo and the caching system. We provide two methods to use the virtual API system: building from source and using our prebuilt Docker.
To start the server, you need to provide a cache directory and an OpenAI key.
We provide a cache to download from HuggingFace or Tsinghua Cloud. After downloading the cache, unzip the folder into the server folder and ensure the server folder contains tool_response_cache folder and tools folder. The resulting folder of server looks like:
├── /server/
│ ├── /tools/
│ │ └── ...
│ ├── /tool_response_cache/
│ │ └── ...
│ ├── config.yml
│ ├── main.py
│ ├── utils.py
You need to first specify your configurations in server/config.yml before running the server. Parameters needed are:
-
api_key: The API key for OpenAI models. -
api_base: The API base for OpenAI models if you are using Azure. -
model: The OpenAI model to use. The default value is gpt-4-turbo-preview. -
temperature: The temperature for LLM simulation. The default value is 0. -
toolbench_url: The real ToolBench server URL. The default value ishttp://8.218.239.54:8080/rapidapi. -
tools_folder: The tools environment folder path. Default to./tools. -
cache_folder: The cache folder path. Default to./tool_response_cache. -
is_save: A flag to indicate whether to save real and simulated responses into the cache. The new cache is saved at./tool_response_new_cache. -
port: The server port to run on, default to 8080.
Now you can run the server by running:
cd server
python main.py
The server will be run at http://localhost:{port}/virtual.
To use the server, you will further need a toolbench key. You can apply one from this form.
We provide a Dockerfile for easy deployment and consistent server environment. This allows you to run the server on various platforms that support Docker.
Prerequisites:
- Docker installed: https://docs.docker.com/engine/install/
Building the Docker Image:
- Navigate to your project directory in the terminal.
- Build the Docker image using the following command:
docker build -t my-fastapi-server . # Replace 'my-fastapi-server' with your desired image name
docker run -p {port}:8080 my-fastapi-server # Replace 'my-fastapi-server' with your image nameYou can also use our prebuilt Docker image from Docker Hub hosted at https://hub.docker.com/repository/docker/zhichengg/stb-docker/general. Before running the docker, you will need to install docker and download the cache files as described in Building from Source. Then you can run the server using the following command:
docker pull zhichengg/stb-docker:latest
docker run -p {port}:8080 -v {tool_response_cache_path}:/app/tool_response_cache -v {tools_path}:/app/tools -e OPENAI_API_KEY= -e OPENAI_API_BASE= zhichengg/stb-dockerRemember to fill in the port, tool_response_cache_path, and tools_path with your own values. The OPENAI_API_KEY and OPENAI_API_BASE are the OpenAI API key and API base if you are using Azure. The server will be run at http://localhost:{port}/virtual.
You can test the server with
import requests
import json
import os
url = 'http://0.0.0.0:8080/virtual'
data = {
"category": "Artificial_Intelligence_Machine_Learning",
"tool_name": "TTSKraken",
"api_name": "List Languages",
"tool_input": '{}',
"strip": "truncate",
"toolbench_key": ""
}
headers = {
'accept': 'application/json',
'Content-Type': 'application/json',
}
# Make the POST request
response = requests.post(url, headers=headers, data=json.dumps(data))
print(response.text)
The original queries are curated without considering the solvability but judging the solvability with ChatGPT on the fly will cause significant instability. Therefore, we judge the solvability of the original queries with the majority vote of gpt-4-turbo, gemini-pro and claude-2. The filtered queries are saved in solvable_queries.
If you have not set up the environment, please first do so by running pip install -r requirements.txt.
We currently implement all models and algorithms supported by ToolBench. We show ChatGPT (gpt-3.5-turbo-16k) with CoT as an example here. The script is also shown in inference_chatgpt_pipeline_virtual.sh. An example of the results is shown in data_example/answer.
To use ChatGPT, run:
export TOOLBENCH_KEY=""
export OPENAI_KEY=""
export OPENAI_API_BASE=""
export PYTHONPATH=./
export GPT_MODEL="gpt-3.5-turbo-16k"
export SERVICE_URL="http://localhost:8080/virtual"
export OUTPUT_DIR="data/answer/virtual_chatgpt_cot"
group=G1_instruction
mkdir -p $OUTPUT_DIR; mkdir -p $OUTPUT_DIR/$group
python toolbench/inference/qa_pipeline_multithread.py \
--tool_root_dir toolenv/tools \
--backbone_model chatgpt_function \
--openai_key $OPENAI_KEY \
--max_observation_length 1024 \
--method CoT@1 \
--input_query_file solvable_queries/test_instruction/${group}.json \
--output_answer_file $OUTPUT_DIR/$group \
--toolbench_key $TOOLBENCH_KEY \
--num_thread 1We follow the evaluation process of ToolBench. The difference is that we update the evaluation logic of the Pass Rate and Win Rate, resulting in the Solvable Pass Rate and Solvable Win Rate.
The first step is to prepare data. This step is the same as ToolEval in ToolBench.
The following paragraph is adapted from ToolBench.
To evaluate your model and method using ToolEval, you first need to prepare all the model predictions for the six test subsets. Create a directory naming with your model and method, e.g. chatgpt_cot then put each test set's predictions under the directory. The file structure of the directory should be:
├── /chatgpt_cot/
│ ├── /G1_instruction/
│ │ ├── /[email protected]
│ │ └── ...
│ ├── /G1_tool/
│ │ ├── /[email protected]
│ │ └── ...
│ ├── ...
│ ├── /G3_instruction/
│ │ ├── /[email protected]
│ │ └── ...
Then preprocess the predictions by running the following commands:
cd toolbench/tooleval
export RAW_ANSWER_PATH=../../data_example/answer
export CONVERTED_ANSWER_PATH=../../data_example/model_predictions_converted
export MODEL_NAME=virtual_chatgpt_cot
export test_set=G1_instruction
mkdir -p ${CONVERTED_ANSWER_PATH}/${MODEL_NAME}
answer_dir=${RAW_ANSWER_PATH}/${MODEL_NAME}/${test_set}
output_file=${CONVERTED_ANSWER_PATH}/${MODEL_NAME}/${test_set}.json
python convert_to_answer_format.py\
--answer_dir ${answer_dir} \
--method CoT@1 # DFS_woFilter_w2 for DFS \
--output ${output_file}Next, you can calculate the Solvable Pass Rate. Before running the process, you need to specify your evaluation OpenAI key in openai_key.json as follows:
[
{
"api_key": "your_openai_key",
"api_base": "your_organization"
},
...
]Then calculate SoPR with :
cd toolbench/tooleval
export API_POOL_FILE=../../openai_key.json
export CONVERTED_ANSWER_PATH=../../data_example/model_predictions_converted
export SAVE_PATH=../../data_example/pass_rate_results
mkdir -p ${SAVE_PATH}
export CANDIDATE_MODEL=virtual_chatgpt_cot
export EVAL_MODEL=gpt-4-turbo-preview
mkdir -p ${SAVE_PATH}/${CANDIDATE_MODEL}
python eval_pass_rate.py \
--converted_answer_path ${CONVERTED_ANSWER_PATH} \
--save_path ${SAVE_PATH}/${CANDIDATE_MODEL} \
--reference_model ${CANDIDATE_MODEL} \
--test_ids ../../solvable_queries_example/test_query_ids \
--max_eval_threads 35 \
--evaluate_times 3 \
--test_set G1_instruction
Note that we use gpt-4-turbo-preview as the standard evaluation model, which provided much better stability than gpt-3.5 series models.
The result files will be stored under the ${SAVE_PATH}.
Then you can calculate the SoWR. The below example takes ChatGPT-CoT as the reference model and ChatGPT-DFS as the candidate model. Note that you need to get both model's pass rate results first.
cd toolbench/tooleval
export API_POOL_FILE=../../openai_key.json
export CONVERTED_ANSWER_PATH=../../data_example/model_predictions_converted
export SAVE_PATH=../../data_example/preference_results
export PASS_RATE_PATH=../../data_example/pass_rate_results
export REFERENCE_MODEL=virtual_chatgpt_cot
export CANDIDATE_MODEL=virtual_chatgpt_dfs
export EVAL_MODEL=gpt-4-turbo-preview
mkdir -p ${SAVE_PATH}
python eval_preference.py \
--converted_answer_path ${CONVERTED_ANSWER_PATH} \
--reference_model ${REFERENCE_MODEL} \
--output_model ${CANDIDATE_MODEL} \
--test_ids ../../solvable_queries_example/test_query_ids/ \
--save_path ${SAVE_PATH} \
--pass_rate_result_path ${PASS_RATE_PATH} \
--max_eval_threads 10 \
--use_pass_rate true \
--evaluate_times 3 \
--test_set G1_instructionThe result files will be stored under the ${SAVE_PATH}.
To run the FAC evaluation, you need to use the converted answer stated above. Then you can run the evaluation by running the following code (also shown in run_fac_eval.sh):
cd toolbench/tooleval
export MODEL_PATH="Your path to the FAC model"
export CONVERTED_ANSWER_PATH=../../data_example/model_predictions_converted
export SAVE_PATH=../../data_example/fac_results
mkdir -p ${SAVE_PATH}
GROUP="The group name"
CANDIDATE_MODEL="Your candidiate model"
python tool_eval.py \
--model_path $MODEL_PATH \
--evaluation_path $MODEL_FILE \
--output_path $SAVE_PATH/$CANDIDATE_MODEL/$GROUP.csv \
--ids ../../solvable_queries_example/test_query_ids/${GROUP}.jsonWe also publish the data and metrics used in the training and evaluation of MirrorAPI. The training and testing data can be found at huggingface. The newly created ToolBench test set used to compare real and simulated data can also be found at huggingface.
We use FastChat to perform LLM-as-a-Judge. The prompt we used can be found at Table 12 of our paper.
Solvable Pass Rate Score
We evaluate the results with gpt-4o.
| Method | I1 Inst | I1 Cat | I1 Tool | I2 Cat | I2 Inst | I3 Inst | Average |
|---|---|---|---|---|---|---|---|
| ToolLLaMA v2 CoT | 28.0±1.9 | 30.5±0.8 | 21.5±0.9 | 19.9±1.0 | 22.3±0.4 | 19.1±0.8 | 22.8±0.8 |
| ToolLLaMA v2 DFS | 28.4±0.9 | 32.5±0.8 | 22.2±1.0 | 22.8±1.5 | 19.2±1.6 | 18.6±1.5 | 22.9±1.4 |
| GPT 4o mini CoT | 27.8±1.4 | 34.9±0.3 | 34.2±0.5 | 24.5±1.0 | 22.3±2.7 | 20.8±1.5 | 25.9±1.7 |
| GPT 4o mini DFS | 26.8±1.4 | 36.4±1.6 | 33.1±1.1 | 25.8±1.7 | 25.8±2.7 | 20.2±0.8 | 26.4±1.6 |
| GPT 4o CoT | 33.3±2.0 | 35.1±0.6 | 33.6±0.8 | 32.5±1.7 | 29.6±1.6 | 27.9±3.5 | 32.0±2.2 |
| GPT 4o DFS | 32.7±1.9 | 42.3±1.3 | 34.6±1.3 | 32.8±1.5 | 28.3±1.3 | 23.0±1.3 | 30.9±1.7 |
FAC Score
| Method | I1 Inst | I1 Cat | I1 Tool | I2 Cat | I2 Inst | I3 Inst | Average |
|---|---|---|---|---|---|---|---|
| ToolLLaMA v2 CoT | 45.4 | 38.6 | 34.2 | 40.3 | 37.7 | 31.1 | 37.9 |
| ToolLLaMA v2 DFS | 47.9 | 40.5 | 31.0 | 40.3 | 34.0 | 31.1 | 37.5 |
| GPT 4o mini CoT | 42.3 | 39.9 | 38.0 | 44.4 | 36.8 | 36.1 | 39.6 |
| GPT 4o mini DFS | 46.0 | 43.8 | 44.3 | 41.1 | 34.9 | 34.4 | 40.8 |
| GPT 4o CoT | 45.4 | 43.8 | 44.3 | 54.0 | 45.3 | 32.8 | 44.3 |
| GPT 4o DFS | 46.6 | 53.6 | 44.9 | 50.0 | 42.5 | 34.4 | 45.3 |
Below are the main results (Inference done in Feb 2024). The win rate for each model is compared with ChatGPT-ReACT. We use gpt-4-turbo-2024-04-09 as the evaluator. Evaluation done in May 2024.
Note that the ToolLLaMA v2 performance is update on 15 Sep 2024 with the new inference codes. Legacy performance can be found here
Solvable Pass Rate:
| Method | I1 Instruction | I1 Category | I1 Tool | I2 Category | I2 Instruction | I3 Instruction | Average |
|---|---|---|---|---|---|---|---|
| GPT-3.5-Turbo-0613 (CoT) | 52.2±1.1 | 47.3±0.6 | 53.6±1.3 | 42.5±2.1 | 35.8±2.0 | 48.1±0.8 | 46.6±1.3 |
| GPT-3.5-Turbo-0613 (DFS) | 60.3±1.3 | 66.2±1.2 | 67.1±0.0 | 59.1±0.4 | 51.3±1.2 | 73.8±2.3 | 63.0±1.1 |
| GPT-4-0613 (CoT) | 45.5±0.4 | 57.4±0.3 | 48.8±0.7 | 43.0±0.7 | 46.5±0.9 | 48.1±1.5 | 48.2±0.8 |
| GPT-4-0613 (DFS) | 57.3±0.6 | 57.3±0.3 | 60.9±1.0 | 57.9±1.0 | 51.3±0.8 | 66.4±2.4 | 58.5±1.0 |
| ToolLLaMA v2 (CoT) | 51.8±0.4 | 53.1±0.6 | 46.4±1.2 | 51.6±1.1 | 48.9±0.4 | 37.2±0.8 | 48.2±0.8 |
| ToolLLaMA v2 (DFS) | 61.0±1.8 | 58.8±0.5 | 45.6±0.9 | 60.3±1.3 | 53.5±1.8 | 48.1±1.5 | 54.6±1.3 |
| GPT-3.5-Turbo-1106 (CoT) | 50.4±0.5 | 45.1±1.4 | 50.8±0.3 | 48.7±0.8 | 42.1±0.4 | 55.7±0.0 | 48.8±0.6 |
| GPT-3.5-Turbo-1106 (DFS) | 62.8±0.3 | 63.9±1.2 | 65.6±0.3 | 56.5±0.7 | 56.9±1.2 | 67.2±1.3 | 62.2±0.8 |
| GPT-4-Turbo-Preview (CoT) | 52.8±1.3 | 56.6±0.9 | 51.9±0.5 | 51.9±1.0 | 52.8±0.8 | 52.5±0.0 | 53.1±0.8 |
| GPT-4-Turbo-Preview (DFS) | 59.2±0.5 | 61.7±0.7 | 65.7±1.0 | 55.6±0.6 | 55.2±0.4 | 66.1±4.3 | 60.6±1.3 |
In this experiment, we run all models once, evaluate them three times, and take the average results.
Solvable Win Rate: (Reference model: ChatGPT-CoT)
| Method | I1 Instruction | I1 Category | I1 Tool | I2 Instruction | I2 Category | I3 Instruction | Average |
|---|---|---|---|---|---|---|---|
| GPT-3.5-Turbo-0613 (DFS) | 60.7 | 67.3 | 59.5 | 63.2 | 62.1 | 75.4 | 64.7 |
| GPT-4-0613 (CoT) | 54.6 | 58.8 | 58.2 | 75.5 | 60.5 | 62.3 | 61.7 |
| GPT-4-0613 (DFS) | 62.6 | 62.7 | 58.2 | 74.5 | 62.9 | 67.2 | 64.7 |
| ToolLLaMA v2 (CoT) | 41.7 | 45.1 | 32.3 | 52.8 | 46.8 | 26.2 | 40.8 |
| ToolLLaMA v2 (DFS) | 42.3 | 51.0 | 31.0 | 67.0 | 54.0 | 31.1 | 54.0 |
| GPT-3.5-Turbo-1106 (CoT) | 47.2 | 47.7 | 44.9 | 50.9 | 54.0 | 62.3 | 51.2 |
| GPT-3.5-Turbo-1106 (DFS) | 55.8 | 53.6 | 51.9 | 68.9 | 59.7 | 68.9 | 59.8 |
| GPT-4-Turbo-Preview (CoT) | 71.2 | 77.1 | 61.4 | 79.2 | 71.8 | 67.2 | 71.3 |
| GPT-4-Turbo-Preview (DFS) | 73.0 | 75.2 | 68.4 | 77.4 | 66.9 | 60.7 | 70.2 |
We run all models once against GPT-3.5-Turbo-0613 + CoT and evaluate them three times. We follow the ToolBench implementation to take the most frequent result for each query during evaluation. |
We thank Jingwen Wu and Yao Li for their contributions to experiments and result presentation. We also appreciate Yile Wang and Jitao Xu for their valuable suggestions during discussions.
@misc{guo2024stabletoolbench,
title={StableToolBench: Towards Stable Large-Scale Benchmarking on Tool Learning of Large Language Models},
author={Zhicheng Guo and Sijie Cheng and Hao Wang and Shihao Liang and Yujia Qin and Peng Li and Zhiyuan Liu and Maosong Sun and Yang Liu},
year={2024},
eprint={2403.07714},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for StableToolBench
Similar Open Source Tools
StableToolBench
StableToolBench is a new benchmark developed to address the instability of Tool Learning benchmarks. It aims to balance stability and reality by introducing features like Virtual API System, Solvable Queries, and Stable Evaluation System. The benchmark ensures consistency through a caching system and API simulators, filters queries based on solvability using LLMs, and evaluates model performance using GPT-4 with metrics like Solvable Pass Rate and Solvable Win Rate.

StableToolBench
StableToolBench is a new benchmark developed to address the instability of Tool Learning benchmarks. It aims to balance stability and reality by introducing features such as a Virtual API System with caching and API simulators, a new set of solvable queries determined by LLMs, and a Stable Evaluation System using GPT-4. The Virtual API Server can be set up either by building from source or using a prebuilt Docker image. Users can test the server using provided scripts and evaluate models with Solvable Pass Rate and Solvable Win Rate metrics. The tool also includes model experiments results comparing different models' performance.

optillm
optillm is an OpenAI API compatible optimizing inference proxy implementing state-of-the-art techniques to enhance accuracy and performance of LLMs, focusing on reasoning over coding, logical, and mathematical queries. By leveraging additional compute at inference time, it surpasses frontier models across diverse tasks.

MooER
MooER (摩耳) is an LLM-based speech recognition and translation model developed by Moore Threads. It allows users to transcribe speech into text (ASR) and translate speech into other languages (AST) in an end-to-end manner. The model was trained using 5K hours of data and is now also available with an 80K hours version. MooER is the first LLM-based speech model trained and inferred using domestic GPUs. The repository includes pretrained models, inference code, and a Gradio demo for a better user experience.
RouterArena
RouterArena is an open evaluation platform and leaderboard for LLM routers, aiming to provide a standardized evaluation framework for assessing the performance of routers in terms of accuracy, cost, and other metrics. It offers diverse data coverage, comprehensive metrics, automated evaluation, and a live leaderboard to track router performance. Users can evaluate their routers by following setup steps, obtaining routing decisions, running LLM inference, and evaluating router performance. Contributions and collaborations are welcome, and users can submit their routers for evaluation to be included in the leaderboard.
skylos
Skylos is a privacy-first SAST tool for Python, TypeScript, and Go that bridges the gap between traditional static analysis and AI agents. It detects dead code, security vulnerabilities (SQLi, SSRF, Secrets), and code quality issues with high precision. Skylos uses a hybrid engine (AST + optional Local/Cloud LLM) to eliminate false positives, verify via runtime, find logic bugs, and provide context-aware audits. It offers automated fixes, end-to-end remediation, and 100% local privacy. The tool supports taint analysis, secrets detection, vulnerability checks, dead code detection and cleanup, agentic AI and hybrid analysis, codebase optimization, operational governance, and runtime verification.
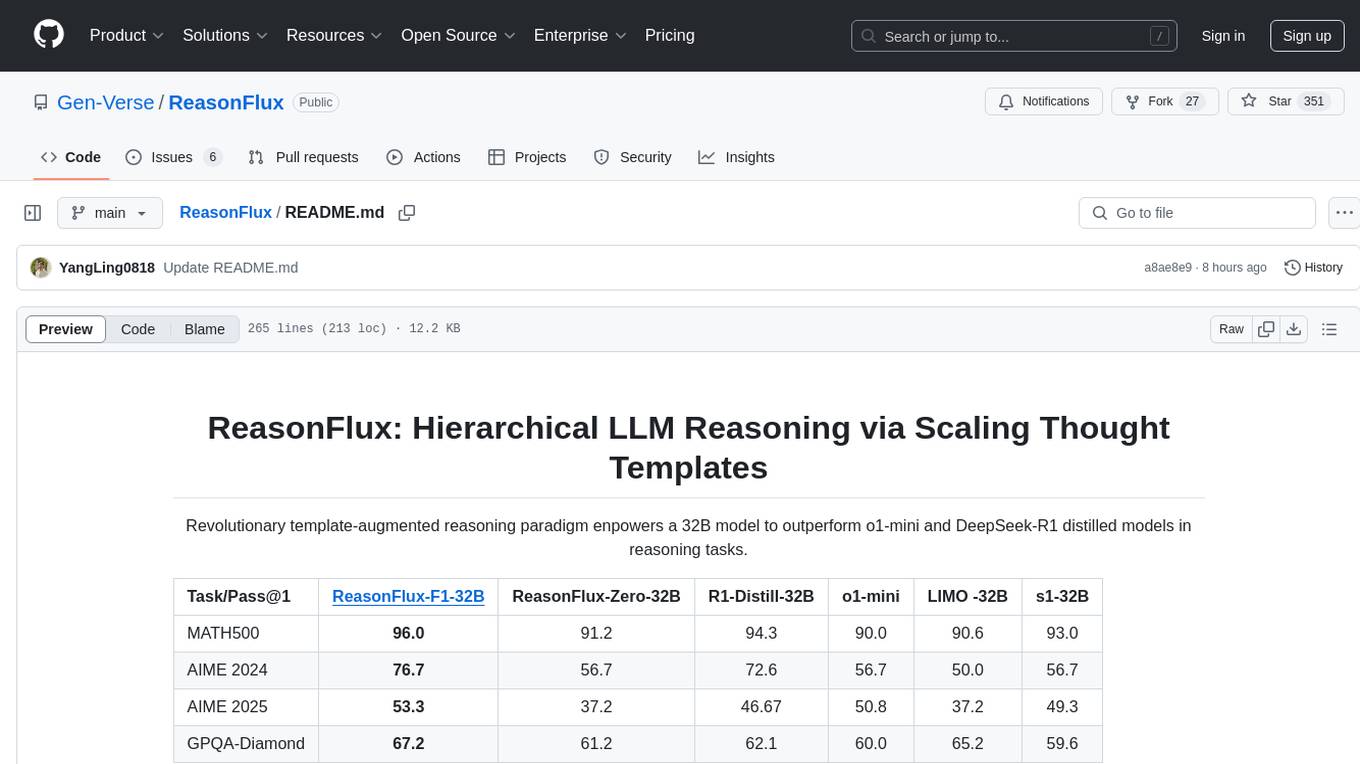
ReasonFlux
ReasonFlux is a revolutionary template-augmented reasoning paradigm that empowers a 32B model to outperform other models in reasoning tasks. The repository provides official resources for the paper 'ReasonFlux: Hierarchical LLM Reasoning via Scaling Thought Templates', including the latest released model ReasonFlux-F1-32B. It includes updates, dataset links, model zoo, getting started guide, training instructions, evaluation details, inference examples, performance comparisons, reasoning examples, preliminary work references, and citation information.

KwaiAgents
KwaiAgents is a series of Agent-related works open-sourced by the [KwaiKEG](https://github.com/KwaiKEG) from [Kuaishou Technology](https://www.kuaishou.com/en). The open-sourced content includes: 1. **KAgentSys-Lite**: a lite version of the KAgentSys in the paper. While retaining some of the original system's functionality, KAgentSys-Lite has certain differences and limitations when compared to its full-featured counterpart, such as: (1) a more limited set of tools; (2) a lack of memory mechanisms; (3) slightly reduced performance capabilities; and (4) a different codebase, as it evolves from open-source projects like BabyAGI and Auto-GPT. Despite these modifications, KAgentSys-Lite still delivers comparable performance among numerous open-source Agent systems available. 2. **KAgentLMs**: a series of large language models with agent capabilities such as planning, reflection, and tool-use, acquired through the Meta-agent tuning proposed in the paper. 3. **KAgentInstruct**: over 200k Agent-related instructions finetuning data (partially human-edited) proposed in the paper. 4. **KAgentBench**: over 3,000 human-edited, automated evaluation data for testing Agent capabilities, with evaluation dimensions including planning, tool-use, reflection, concluding, and profiling.

vscode-unify-chat-provider
The 'vscode-unify-chat-provider' repository is a tool that integrates multiple LLM API providers into VS Code's GitHub Copilot Chat using the Language Model API. It offers free tier access to mainstream models, perfect compatibility with major LLM API formats, deep adaptation to API features, best performance with built-in parameters, out-of-the-box configuration, import/export support, great UX, and one-click use of various models. The tool simplifies model setup, migration, and configuration for users, providing a seamless experience within VS Code for utilizing different language models.

qserve
QServe is a serving system designed for efficient and accurate Large Language Models (LLM) on GPUs with W4A8KV4 quantization. It achieves higher throughput compared to leading industry solutions, allowing users to achieve A100-level throughput on cheaper L40S GPUs. The system introduces the QoQ quantization algorithm with 4-bit weight, 8-bit activation, and 4-bit KV cache, addressing runtime overhead challenges. QServe improves serving throughput for various LLM models by implementing compute-aware weight reordering, register-level parallelism, and fused attention memory-bound techniques.

EasyEdit
EasyEdit is a Python package for edit Large Language Models (LLM) like `GPT-J`, `Llama`, `GPT-NEO`, `GPT2`, `T5`(support models from **1B** to **65B**), the objective of which is to alter the behavior of LLMs efficiently within a specific domain without negatively impacting performance across other inputs. It is designed to be easy to use and easy to extend.

DeepRetrieval
DeepRetrieval is a tool designed to enhance search engines and retrievers using Large Language Models (LLMs) and Reinforcement Learning (RL). It allows LLMs to learn how to search effectively by integrating with search engine APIs and customizing reward functions. The tool provides functionalities for data preparation, training, evaluation, and monitoring search performance. DeepRetrieval aims to improve information retrieval tasks by leveraging advanced AI techniques.
llm-checker
LLM Checker is an AI-powered CLI tool that analyzes your hardware to recommend optimal LLM models. It features deterministic scoring across 35+ curated models with hardware-calibrated memory estimation. The tool helps users understand memory bandwidth, VRAM limits, and performance characteristics to choose the right LLM for their hardware. It provides actionable recommendations in seconds by scoring compatible models across four dimensions: Quality, Speed, Fit, and Context. LLM Checker is designed to work on any Node.js 16+ system, with optional SQLite search features for advanced functionality.
gollama
Gollama is a tool designed for managing Ollama models through a Text User Interface (TUI). Users can list, inspect, delete, copy, and push Ollama models, as well as link them to LM Studio. The application offers interactive model selection, sorting by various criteria, and actions using hotkeys. It provides features like sorting and filtering capabilities, displaying model metadata, model linking, copying, pushing, and more. Gollama aims to be user-friendly and useful for managing models, especially for cleaning up old models.
rwkv.cpp
rwkv.cpp is a port of BlinkDL/RWKV-LM to ggerganov/ggml, supporting FP32, FP16, and quantized INT4, INT5, and INT8 inference. It focuses on CPU but also supports cuBLAS. The project provides a C library rwkv.h and a Python wrapper. RWKV is a large language model architecture with models like RWKV v5 and v6. It requires only state from the previous step for calculations, making it CPU-friendly on large context lengths. Users are advised to test all available formats for perplexity and latency on a representative dataset before serious use.
roam-code
Roam is a tool that builds a semantic graph of your codebase and allows AI agents to query it with one shell command. It pre-indexes your codebase into a semantic graph stored in a local SQLite DB, providing architecture-level graph queries offline, cross-language, and compact. Roam understands functions, modules, tests coverage, and overall architecture structure. It is best suited for agent-assisted coding, large codebases, architecture governance, safe refactoring, and multi-repo projects. Roam is not suitable for real-time type checking, dynamic/runtime analysis, small scripts, or pure text search. It offers speed, dependency-awareness, LLM-optimized output, fully local operation, and CI readiness.
For similar tasks
StableToolBench
StableToolBench is a new benchmark developed to address the instability of Tool Learning benchmarks. It aims to balance stability and reality by introducing features like Virtual API System, Solvable Queries, and Stable Evaluation System. The benchmark ensures consistency through a caching system and API simulators, filters queries based on solvability using LLMs, and evaluates model performance using GPT-4 with metrics like Solvable Pass Rate and Solvable Win Rate.

lighteval
LightEval is a lightweight LLM evaluation suite that Hugging Face has been using internally with the recently released LLM data processing library datatrove and LLM training library nanotron. We're releasing it with the community in the spirit of building in the open. Note that it is still very much early so don't expect 100% stability ^^' In case of problems or question, feel free to open an issue!

Firefly
Firefly is an open-source large model training project that supports pre-training, fine-tuning, and DPO of mainstream large models. It includes models like Llama3, Gemma, Qwen1.5, MiniCPM, Llama, InternLM, Baichuan, ChatGLM, Yi, Deepseek, Qwen, Orion, Ziya, Xverse, Mistral, Mixtral-8x7B, Zephyr, Vicuna, Bloom, etc. The project supports full-parameter training, LoRA, QLoRA efficient training, and various tasks such as pre-training, SFT, and DPO. Suitable for users with limited training resources, QLoRA is recommended for fine-tuning instructions. The project has achieved good results on the Open LLM Leaderboard with QLoRA training process validation. The latest version has significant updates and adaptations for different chat model templates.

Awesome-Text2SQL
Awesome Text2SQL is a curated repository containing tutorials and resources for Large Language Models, Text2SQL, Text2DSL, Text2API, Text2Vis, and more. It provides guidelines on converting natural language questions into structured SQL queries, with a focus on NL2SQL. The repository includes information on various models, datasets, evaluation metrics, fine-tuning methods, libraries, and practice projects related to Text2SQL. It serves as a comprehensive resource for individuals interested in working with Text2SQL and related technologies.

create-million-parameter-llm-from-scratch
The 'create-million-parameter-llm-from-scratch' repository provides a detailed guide on creating a Large Language Model (LLM) with 2.3 million parameters from scratch. The blog replicates the LLaMA approach, incorporating concepts like RMSNorm for pre-normalization, SwiGLU activation function, and Rotary Embeddings. The model is trained on a basic dataset to demonstrate the ease of creating a million-parameter LLM without the need for a high-end GPU.
StableToolBench
StableToolBench is a new benchmark developed to address the instability of Tool Learning benchmarks. It aims to balance stability and reality by introducing features such as a Virtual API System with caching and API simulators, a new set of solvable queries determined by LLMs, and a Stable Evaluation System using GPT-4. The Virtual API Server can be set up either by building from source or using a prebuilt Docker image. Users can test the server using provided scripts and evaluate models with Solvable Pass Rate and Solvable Win Rate metrics. The tool also includes model experiments results comparing different models' performance.

BetaML.jl
The Beta Machine Learning Toolkit is a package containing various algorithms and utilities for implementing machine learning workflows in multiple languages, including Julia, Python, and R. It offers a range of supervised and unsupervised models, data transformers, and assessment tools. The models are implemented entirely in Julia and are not wrappers for third-party models. Users can easily contribute new models or request implementations. The focus is on user-friendliness rather than computational efficiency, making it suitable for educational and research purposes.

AI-TOD
AI-TOD is a dataset for tiny object detection in aerial images, containing 700,621 object instances across 28,036 images. Objects in AI-TOD are smaller with a mean size of 12.8 pixels compared to other aerial image datasets. To use AI-TOD, download xView training set and AI-TOD_wo_xview, then generate the complete dataset using the provided synthesis tool. The dataset is publicly available for academic and research purposes under CC BY-NC-SA 4.0 license.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.