
AiOS
[CVPR 2024] Official Code for "AiOS: All-in-One-Stage Expressive Human Pose and Shape Estimation
Stars: 121
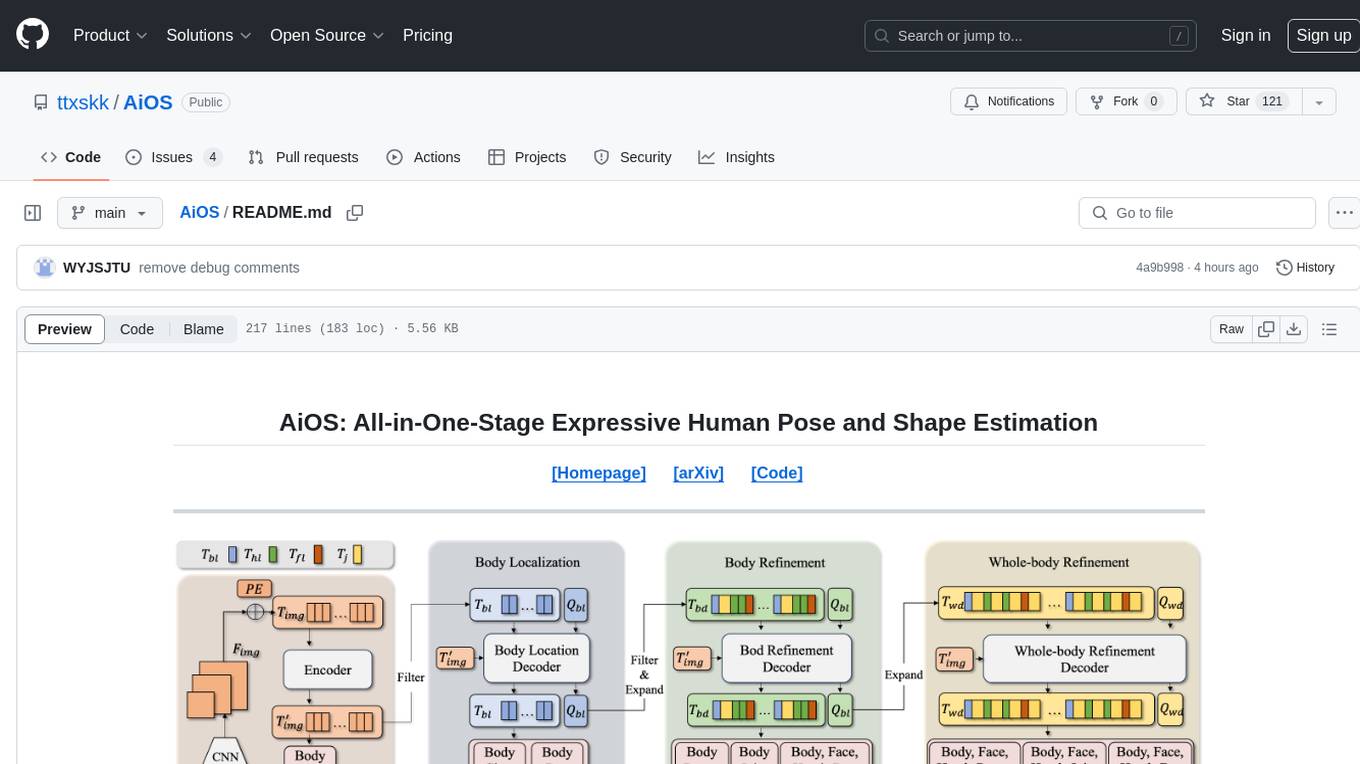
AiOS is a tool for human pose and shape estimation, performing human localization and SMPL-X estimation in a progressive manner. It consists of body localization, body refinement, and whole-body refinement stages. Users can download datasets for evaluation, SMPL-X body models, and AiOS checkpoint. Installation involves creating a conda virtual environment, installing PyTorch, torchvision, Pytorch3D, MMCV, and other dependencies. Inference requires placing the video for inference and pretrained models in specific directories. Test results are provided for NMVE, NMJE, MVE, and MPJPE on datasets like BEDLAM and AGORA. Users can run scripts for AGORA validation, AGORA test leaderboard, and BEDLAM leaderboard. The tool acknowledges codes from MMHuman3D, ED-Pose, and SMPLer-X.
README:
AiOS performs human localization and SMPL-X estimation in a progressive manner. It is composed of (1) the body localization stage that predicts coarse human location; (2) the Body refinement stage that refines body features and produces face and hand locations; (3) the Whole-body Refinement stage that refines whole-body features and regress SMPL-X parameters.
- download datasets for evaluation
- download SMPL-X body models.
- download AiOS checkpoint
- download AGORA validation set Humandata
Organize them according to this datastructure:
AiOS/
├── config/
└── data
├── body_models
└── smplx
| ├──MANO_SMPLX_vertex_ids.pkl
| ├──SMPL-X__FLAME_vertex_ids.npy
| ├──SMPLX_NEUTRAL.pkl
| ├──SMPLX_to_J14.pkl
| ├──SMPLX_NEUTRAL.npz
| ├──SMPLX_MALE.npz
| └──SMPLX_FEMALE.npz
├── cache
├── checkpoint
│ └── aios_checkpoint.pth
├── datasets
│ ├── agora
│ └── bedlam
└── multihuman_data
└── agora_validation_multi_3840_1010.npz
# Create a conda virtual environment and activate it.
conda create -n aios python=3.8 -y
conda activate aios
# Install PyTorch and torchvision.
conda install pytorch==1.10.1 torchvision==0.11.2 torchaudio==0.10.1 cudatoolkit=11.3 -c pytorch -c conda-forge
# Install Pytorch3D
git clone -b v0.6.1 https://github.com/facebookresearch/pytorch3d.git
cd pythorch3d
pip install -v -e .
cd ..
# Install MMCV, build from source
git clone -b v1.6.1 https://github.com/open-mmlab/mmcv.git
cd mmcv
export MMCV_WITH_OPS=1
export FORCE_MLU=1
pip install -v -e .
cd ..
# Install other dependencies
conda install -c conda-forge ffmpeg
pip install -r requirements.txt
# Build deformable detr
cd models/aios/ops
python setup.py build install
cd ../../..- Place the mp4 video for inference under
AiOS/demo/ - Prepare the pretrained models to be used for inference under
AiOS/data/checkpoint - Inference output will be saved in
AiOS/demo/{INPUT_VIDEO}_out
cd main
sh scripts/inference.sh {INPUT_VIDEO} {OUTPUT_DIR}
# For inferencing short_video.mp4 with output directory of demo/short_video_out
sh scripts/inference.sh short_video demo| NMVE | NMJE | MVE | MPJPE | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| DATASETS | FB | B | FB | B | FB | B | F | LH/RH | FB | B | F | LH/RH |
| BEDLAM | 87.6 | 57.7 | 85.8 | 57.7 | 83.2 | 54.8 | 26.2 | 28.1/30.8 | 81.5 | 54.8 | 26.2 | 25.9/28.0 |
| AGORA-Test | 102.9 | 63.4 | 100.7 | 62.5 | 98.8 | 60.9 | 27.7 | 42.5/43.4 | 96.7 | 60.0 | 29.2 | 40.1/41.0 |
| AGORA-Val | 105.1 | 60.9 | 102.2 | 61.4 | 100.9 | 60.9 | 30.6 | 43.9/45.6 | 98.1 | 58.9 | 32.7 | 41.5/43.4 |
a. Make test_result dir
mkdir test_resultb. AGORA Validatoin
Run the following command and it will generate a 'predictions/' result folder which can evaluate with the agora evaluation tool
sh scripts/test_agora_val.sh data/checkpoint/aios_checkpoint.pth agora_valb. AGORA Test Leaderboard
Run the following command and it will generate a 'predictions.zip' which can be submitted to AGORA Leaderborad
sh scripts/test_agora.sh data/checkpoint/aios_checkpoint.pth agora_testc. BEDLAM
Run the following command and it will generate a 'predictions.zip' which can be submitted to BEDLAM Leaderborad
sh scripts/test_bedlam.sh data/checkpoint/aios_checkpoint.pth bedlam_testSome of the codes are based on MMHuman3D, ED-Pose and SMPLer-X.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for AiOS
Similar Open Source Tools
AiOS
AiOS is a tool for human pose and shape estimation, performing human localization and SMPL-X estimation in a progressive manner. It consists of body localization, body refinement, and whole-body refinement stages. Users can download datasets for evaluation, SMPL-X body models, and AiOS checkpoint. Installation involves creating a conda virtual environment, installing PyTorch, torchvision, Pytorch3D, MMCV, and other dependencies. Inference requires placing the video for inference and pretrained models in specific directories. Test results are provided for NMVE, NMJE, MVE, and MPJPE on datasets like BEDLAM and AGORA. Users can run scripts for AGORA validation, AGORA test leaderboard, and BEDLAM leaderboard. The tool acknowledges codes from MMHuman3D, ED-Pose, and SMPLer-X.

StableToolBench
StableToolBench is a new benchmark developed to address the instability of Tool Learning benchmarks. It aims to balance stability and reality by introducing features such as a Virtual API System with caching and API simulators, a new set of solvable queries determined by LLMs, and a Stable Evaluation System using GPT-4. The Virtual API Server can be set up either by building from source or using a prebuilt Docker image. Users can test the server using provided scripts and evaluate models with Solvable Pass Rate and Solvable Win Rate metrics. The tool also includes model experiments results comparing different models' performance.
rho
Rho is an AI agent that runs on macOS, Linux, and Android, staying active, remembering past interactions, and checking in autonomously. It operates without cloud storage, allowing users to retain ownership of their data. Users can bring their own LLM provider and have full control over the agent's functionalities. Rho is built on the pi coding agent framework, offering features like persistent memory, scheduled tasks, and real email capabilities. The agent can be customized through checklists, scheduled triggers, and personalized voice and identity settings. Skills and extensions enhance the agent's capabilities, providing tools for notifications, clipboard management, text-to-speech, and more. Users can interact with Rho through commands and scripts, enabling tasks like checking status, triggering actions, and managing preferences.
StableToolBench
StableToolBench is a new benchmark developed to address the instability of Tool Learning benchmarks. It aims to balance stability and reality by introducing features like Virtual API System, Solvable Queries, and Stable Evaluation System. The benchmark ensures consistency through a caching system and API simulators, filters queries based on solvability using LLMs, and evaluates model performance using GPT-4 with metrics like Solvable Pass Rate and Solvable Win Rate.
roam-code
Roam is a tool that builds a semantic graph of your codebase and allows AI agents to query it with one shell command. It pre-indexes your codebase into a semantic graph stored in a local SQLite DB, providing architecture-level graph queries offline, cross-language, and compact. Roam understands functions, modules, tests coverage, and overall architecture structure. It is best suited for agent-assisted coding, large codebases, architecture governance, safe refactoring, and multi-repo projects. Roam is not suitable for real-time type checking, dynamic/runtime analysis, small scripts, or pure text search. It offers speed, dependency-awareness, LLM-optimized output, fully local operation, and CI readiness.
multi-agent-ralph-loop
Multi-agent RALPH (Reinforcement Learning with Probabilistic Hierarchies) Loop is a framework for multi-agent reinforcement learning research. It provides a flexible and extensible platform for developing and testing multi-agent reinforcement learning algorithms. The framework supports various environments, including grid-world environments, and allows users to easily define custom environments. Multi-agent RALPH Loop is designed to facilitate research in the field of multi-agent reinforcement learning by providing a set of tools and utilities for experimenting with different algorithms and scenarios.
specweave
SpecWeave is a spec-driven Skill Fabric for AI coding agents that allows programming AI in English. It provides first-class support for Claude Code and offers reusable logic for controlling AI behavior. With over 100 skills out of the box, SpecWeave eliminates the need to learn Claude Code docs and handles various aspects of feature development. The tool enables users to describe what they want, and SpecWeave autonomously executes tasks, including writing code, running tests, and syncing to GitHub/JIRA. It supports solo developers, agent teams working in parallel, and brownfield projects, offering file-based coordination, autonomous teams, and enterprise-ready features. SpecWeave also integrates LSP Code Intelligence for semantic understanding of codebases and allows for extensible skills without forking.
MaskLLM
MaskLLM is a learnable pruning method that establishes Semi-structured Sparsity in Large Language Models (LLMs) to reduce computational overhead during inference. It is scalable and benefits from larger training datasets. The tool provides examples for running MaskLLM with Megatron-LM, preparing LLaMA checkpoints, pre-tokenizing C4 data for Megatron, generating prior masks, training MaskLLM, and evaluating the model. It also includes instructions for exporting sparse models to Huggingface.
SG-Nav
SG-Nav is an online 3D scene graph prompting tool designed for LLM-based zero-shot object navigation. It proposes a framework that constructs an online 3D scene graph to prompt LLMs, allowing direct application to various scenes and categories without the need for training.
Automodel
Automodel is a Python library for automating the process of building and evaluating machine learning models. It provides a set of tools and utilities to streamline the model development workflow, from data preprocessing to model selection and evaluation. With Automodel, users can easily experiment with different algorithms, hyperparameters, and feature engineering techniques to find the best model for their dataset. The library is designed to be user-friendly and customizable, allowing users to define their own pipelines and workflows. Automodel is suitable for data scientists, machine learning engineers, and anyone looking to quickly build and test machine learning models without the need for manual intervention.
ShapeLLM
ShapeLLM is the first 3D Multimodal Large Language Model designed for embodied interaction, exploring a universal 3D object understanding with 3D point clouds and languages. It supports single-view colored point cloud input and introduces a robust 3D QA benchmark, 3D MM-Vet, encompassing various variants. The model extends the powerful point encoder architecture, ReCon++, achieving state-of-the-art performance across a range of representation learning tasks. ShapeLLM can be used for tasks such as training, zero-shot understanding, visual grounding, few-shot learning, and zero-shot learning on 3D MM-Vet.
AIGC_text_detector
AIGC_text_detector is a repository containing the official codes for the paper 'Multiscale Positive-Unlabeled Detection of AI-Generated Texts'. It includes detector models for both English and Chinese texts, along with stronger detectors developed with enhanced training strategies. The repository provides links to download the detector models, datasets, and necessary preprocessing tools. Users can train RoBERTa and BERT models on the HC3-English dataset using the provided scripts.
paperbanana
PaperBanana is an automated academic illustration tool designed for AI scientists. It implements an agentic framework for generating publication-quality academic diagrams and statistical plots from text descriptions. The tool utilizes a two-phase multi-agent pipeline with iterative refinement, Gemini-based VLM planning, and image generation. It offers a CLI, Python API, and MCP server for IDE integration, along with Claude Code skills for generating diagrams, plots, and evaluating diagrams. PaperBanana is not affiliated with or endorsed by the original authors or Google Research, and it may differ from the original system described in the paper.

cactus
Cactus is an energy-efficient and fast AI inference framework designed for phones, wearables, and resource-constrained arm-based devices. It provides a bottom-up approach with no dependencies, optimizing for budget and mid-range phones. The framework includes Cactus FFI for integration, Cactus Engine for high-level transformer inference, Cactus Graph for unified computation graph, and Cactus Kernels for low-level ARM-specific operations. It is suitable for implementing custom models and scientific computing on mobile devices.

EVE
EVE is an official PyTorch implementation of Unveiling Encoder-Free Vision-Language Models. The project aims to explore the removal of vision encoders from Vision-Language Models (VLMs) and transfer LLMs to encoder-free VLMs efficiently. It also focuses on bridging the performance gap between encoder-free and encoder-based VLMs. EVE offers a superior capability with arbitrary image aspect ratio, data efficiency by utilizing publicly available data for pre-training, and training efficiency with a transparent and practical strategy for developing a pure decoder-only architecture across modalities.

EasyEdit
EasyEdit is a Python package for edit Large Language Models (LLM) like `GPT-J`, `Llama`, `GPT-NEO`, `GPT2`, `T5`(support models from **1B** to **65B**), the objective of which is to alter the behavior of LLMs efficiently within a specific domain without negatively impacting performance across other inputs. It is designed to be easy to use and easy to extend.
For similar tasks
AiOS
AiOS is a tool for human pose and shape estimation, performing human localization and SMPL-X estimation in a progressive manner. It consists of body localization, body refinement, and whole-body refinement stages. Users can download datasets for evaluation, SMPL-X body models, and AiOS checkpoint. Installation involves creating a conda virtual environment, installing PyTorch, torchvision, Pytorch3D, MMCV, and other dependencies. Inference requires placing the video for inference and pretrained models in specific directories. Test results are provided for NMVE, NMJE, MVE, and MPJPE on datasets like BEDLAM and AGORA. Users can run scripts for AGORA validation, AGORA test leaderboard, and BEDLAM leaderboard. The tool acknowledges codes from MMHuman3D, ED-Pose, and SMPLer-X.
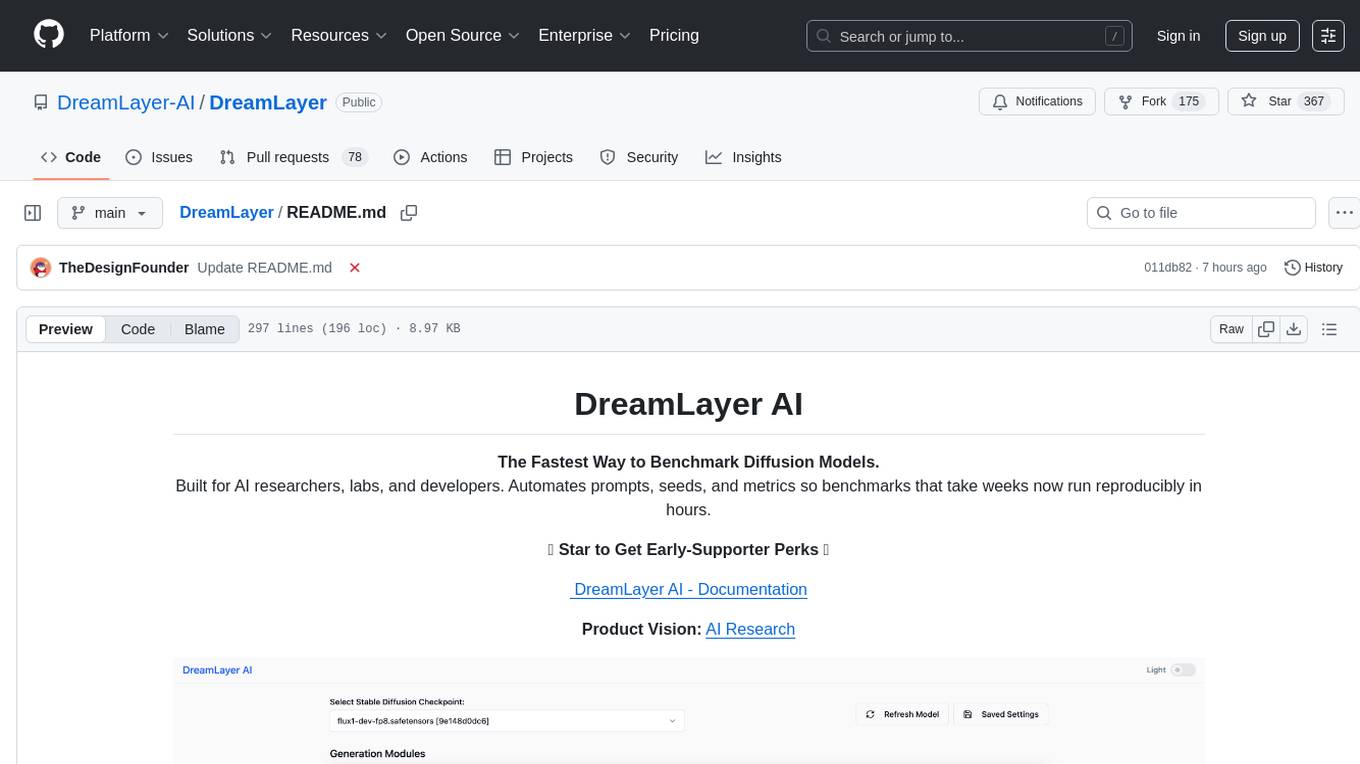
DreamLayer
DreamLayer AI is an open-source Stable Diffusion WebUI designed for AI researchers, labs, and developers. It automates prompts, seeds, and metrics for benchmarking models, datasets, and samplers, enabling reproducible evaluations across multiple seeds and configurations. The tool integrates custom metrics and evaluation pipelines, providing a streamlined workflow for AI research. With features like automated benchmarking, reproducibility, built-in metrics, multi-modal readiness, and researcher-friendly interface, DreamLayer AI aims to simplify and accelerate the model evaluation process.

djl
Deep Java Library (DJL) is an open-source, high-level, engine-agnostic Java framework for deep learning. It is designed to be easy to get started with and simple to use for Java developers. DJL provides a native Java development experience and allows users to integrate machine learning and deep learning models with their Java applications. The framework is deep learning engine agnostic, enabling users to switch engines at any point for optimal performance. DJL's ergonomic API interface guides users with best practices to accomplish deep learning tasks, such as running inference and training neural networks.

caikit
Caikit is an AI toolkit that enables users to manage models through a set of developer friendly APIs. It provides a consistent format for creating and using AI models against a wide variety of data domains and tasks.

agents
The LiveKit Agent Framework is designed for building real-time, programmable participants that run on servers. Easily tap into LiveKit WebRTC sessions and process or generate audio, video, and data streams. The framework includes plugins for common workflows, such as voice activity detection and speech-to-text. Agents integrates seamlessly with LiveKit server, offloading job queuing and scheduling responsibilities to it. This eliminates the need for additional queuing infrastructure. Agent code developed on your local machine can scale to support thousands of concurrent sessions when deployed to a server in production.

llm-finetuning
llm-finetuning is a repository that provides a serverless twist to the popular axolotl fine-tuning library using Modal's serverless infrastructure. It allows users to quickly fine-tune any LLM model with state-of-the-art optimizations like Deepspeed ZeRO, LoRA adapters, Flash attention, and Gradient checkpointing. The repository simplifies the fine-tuning process by not exposing all CLI arguments, instead allowing users to specify options in a config file. It supports efficient training and scaling across multiple GPUs, making it suitable for production-ready fine-tuning jobs.

LeanCopilot
Lean Copilot is a tool that enables the use of large language models (LLMs) in Lean for proof automation. It provides features such as suggesting tactics/premises, searching for proofs, and running inference of LLMs. Users can utilize built-in models from LeanDojo or bring their own models to run locally or on the cloud. The tool supports platforms like Linux, macOS, and Windows WSL, with optional CUDA and cuDNN for GPU acceleration. Advanced users can customize behavior using Tactic APIs and Model APIs. Lean Copilot also allows users to bring their own models through ExternalGenerator or ExternalEncoder. The tool comes with caveats such as occasional crashes and issues with premise selection and proof search. Users can get in touch through GitHub Discussions for questions, bug reports, feature requests, and suggestions. The tool is designed to enhance theorem proving in Lean using LLMs.
awesome-local-llms
The 'awesome-local-llms' repository is a curated list of open-source tools for local Large Language Model (LLM) inference, covering both proprietary and open weights LLMs. The repository categorizes these tools into LLM inference backend engines, LLM front end UIs, and all-in-one desktop applications. It collects GitHub repository metrics as proxies for popularity and active maintenance. Contributions are encouraged, and users can suggest additional open-source repositories through the Issues section or by running a provided script to update the README and make a pull request. The repository aims to provide a comprehensive resource for exploring and utilizing local LLM tools.
For similar jobs

promptflow
**Prompt flow** is a suite of development tools designed to streamline the end-to-end development cycle of LLM-based AI applications, from ideation, prototyping, testing, evaluation to production deployment and monitoring. It makes prompt engineering much easier and enables you to build LLM apps with production quality.

deepeval
DeepEval is a simple-to-use, open-source LLM evaluation framework specialized for unit testing LLM outputs. It incorporates various metrics such as G-Eval, hallucination, answer relevancy, RAGAS, etc., and runs locally on your machine for evaluation. It provides a wide range of ready-to-use evaluation metrics, allows for creating custom metrics, integrates with any CI/CD environment, and enables benchmarking LLMs on popular benchmarks. DeepEval is designed for evaluating RAG and fine-tuning applications, helping users optimize hyperparameters, prevent prompt drifting, and transition from OpenAI to hosting their own Llama2 with confidence.

MegaDetector
MegaDetector is an AI model that identifies animals, people, and vehicles in camera trap images (which also makes it useful for eliminating blank images). This model is trained on several million images from a variety of ecosystems. MegaDetector is just one of many tools that aims to make conservation biologists more efficient with AI. If you want to learn about other ways to use AI to accelerate camera trap workflows, check out our of the field, affectionately titled "Everything I know about machine learning and camera traps".

leapfrogai
LeapfrogAI is a self-hosted AI platform designed to be deployed in air-gapped resource-constrained environments. It brings sophisticated AI solutions to these environments by hosting all the necessary components of an AI stack, including vector databases, model backends, API, and UI. LeapfrogAI's API closely matches that of OpenAI, allowing tools built for OpenAI/ChatGPT to function seamlessly with a LeapfrogAI backend. It provides several backends for various use cases, including llama-cpp-python, whisper, text-embeddings, and vllm. LeapfrogAI leverages Chainguard's apko to harden base python images, ensuring the latest supported Python versions are used by the other components of the stack. The LeapfrogAI SDK provides a standard set of protobuffs and python utilities for implementing backends and gRPC. LeapfrogAI offers UI options for common use-cases like chat, summarization, and transcription. It can be deployed and run locally via UDS and Kubernetes, built out using Zarf packages. LeapfrogAI is supported by a community of users and contributors, including Defense Unicorns, Beast Code, Chainguard, Exovera, Hypergiant, Pulze, SOSi, United States Navy, United States Air Force, and United States Space Force.

llava-docker
This Docker image for LLaVA (Large Language and Vision Assistant) provides a convenient way to run LLaVA locally or on RunPod. LLaVA is a powerful AI tool that combines natural language processing and computer vision capabilities. With this Docker image, you can easily access LLaVA's functionalities for various tasks, including image captioning, visual question answering, text summarization, and more. The image comes pre-installed with LLaVA v1.2.0, Torch 2.1.2, xformers 0.0.23.post1, and other necessary dependencies. You can customize the model used by setting the MODEL environment variable. The image also includes a Jupyter Lab environment for interactive development and exploration. Overall, this Docker image offers a comprehensive and user-friendly platform for leveraging LLaVA's capabilities.

carrot
The 'carrot' repository on GitHub provides a list of free and user-friendly ChatGPT mirror sites for easy access. The repository includes sponsored sites offering various GPT models and services. Users can find and share sites, report errors, and access stable and recommended sites for ChatGPT usage. The repository also includes a detailed list of ChatGPT sites, their features, and accessibility options, making it a valuable resource for ChatGPT users seeking free and unlimited GPT services.

TrustLLM
TrustLLM is a comprehensive study of trustworthiness in LLMs, including principles for different dimensions of trustworthiness, established benchmark, evaluation, and analysis of trustworthiness for mainstream LLMs, and discussion of open challenges and future directions. Specifically, we first propose a set of principles for trustworthy LLMs that span eight different dimensions. Based on these principles, we further establish a benchmark across six dimensions including truthfulness, safety, fairness, robustness, privacy, and machine ethics. We then present a study evaluating 16 mainstream LLMs in TrustLLM, consisting of over 30 datasets. The document explains how to use the trustllm python package to help you assess the performance of your LLM in trustworthiness more quickly. For more details about TrustLLM, please refer to project website.

AI-YinMei
AI-YinMei is an AI virtual anchor Vtuber development tool (N card version). It supports fastgpt knowledge base chat dialogue, a complete set of solutions for LLM large language models: [fastgpt] + [one-api] + [Xinference], supports docking bilibili live broadcast barrage reply and entering live broadcast welcome speech, supports Microsoft edge-tts speech synthesis, supports Bert-VITS2 speech synthesis, supports GPT-SoVITS speech synthesis, supports expression control Vtuber Studio, supports painting stable-diffusion-webui output OBS live broadcast room, supports painting picture pornography public-NSFW-y-distinguish, supports search and image search service duckduckgo (requires magic Internet access), supports image search service Baidu image search (no magic Internet access), supports AI reply chat box [html plug-in], supports AI singing Auto-Convert-Music, supports playlist [html plug-in], supports dancing function, supports expression video playback, supports head touching action, supports gift smashing action, supports singing automatic start dancing function, chat and singing automatic cycle swing action, supports multi scene switching, background music switching, day and night automatic switching scene, supports open singing and painting, let AI automatically judge the content.